
Abstract
Soil heavy metals exhibit significant spatiotemporal variability and are strongly correlated with other soil heavy metals. Thus, other heavy metals can be used to improve the accuracy of predictions when performing spatiotemporal predictions of soil heavy metals within a given area. In this study, we propose the spatiotemporal cokriging (STCK) method to enable the use of historical sampling points and co-variables in the spatial prediction of soil heavy metals. Moreover, experimental spatiotemporal (ST) semivariogram and ST cross-semivariogram computational methods, a fitting strategy to the ST semivariogram and ST cross-semivariogram models based on the Bilonick model, and the STCK interpolation algorithm are introduced; these methods are based on spatiotemporal kriging (STK) and cokriging (CK). The data used in this study consist of measurements of soil heavy metals from 2010 to 2014 in Wuhan City, China. The results show that the behavior of predictions of the concentrations of heavy metals in soils is physically more realistic, and the prediction uncertainties are slightly smaller, when STCK is used with greater numbers of co-variables and neighboring points.
Similar content being viewed by others

Introduction
Soil plays a very important role in the food chain and hence is a key pathway through which humans come into contact with most pollutants1. This statement is especially true for heavy metals, which have also been identified as co-factors in many diseases2,3. Therefore, there is considerable interest in the best way to monitor soil quality to ensure that soil is managed sustainably4. In recent years, an increasing amount of concern has been directed toward the spatial distribution of soil contamination5,6,7. Previous studies have carried out multivariate analyses, analyses of various pollutant indices, and geostatistical analyses to evaluate the degree of soil pollution by heavy metals using sampling data collected during individual periods. Additionally, some researchers have begun to address the concern over the spatiotemporal (ST) variability in soil heavy metals4,8 and have performed statistical analyses of data collected during field surveys conducted in different years that were performed to characterize the spatial and temporal changes in the concentrations of heavy metals in soils. However, the sampling and analysis procedures used when the status of soil heavy metals within a given area must be continuously monitored are expensive and time-consuming. Therefore, spatiotemporal interpolation is necessary because it enables the use of previous soil sampling points to predict present-day spatial distributions with fewer soil samples.
Spatiotemporal kriging (STK) is a tool that is used to analyze and map ST phenomena using point observations910. The technique is currently used in many research problems and fields, such as the interpolation of soil water and salinity content11,12,13, climatology14, and air quality monitoring15. Most studies use only measurements of the variable of interest. However, after soil samples have been obtained, various heavy metals in the soil can be measured simultaneously. In addition, many studies indicate that correlations exist among the various heavy metals found in soils16,17,18. The use of such relationships in interpolation via cokriging (CK) may decrease prediction uncertainties19.
Based on the above discussion, we believe that it is possible to combine historical sampling points and co-variables to perform predictions of heavy metals. Thus, we propose a spatiotemporal cokriging (STCK) method that is based on STK and CK. The main objective of this study is to predict the ST distribution of soil heavy metals within a study area using STCK. To achieve this objective, the following steps are followed. (1) The methods of obtaining experimental ST semivariograms and ST cross-semivariograms are explored. (2) Models for experimental ST semivariograms and ST cross-semivariograms are fitted. (3) An algorithm for STCK interpolation is proposed. Finally, (4) the accuracy and uncertainty of STCK given different combinations of co-variables and different neighboring points are explored.
Materials
Study area
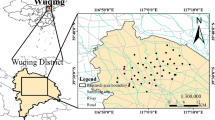
The study area lies to the east of the Qingshan district (latitude 30°37′N, longitude 114°26′E) of Wuhan City, which is the capital of Hubei Province and the largest city in the middle reach of the Yangtze River in China. Since the 1950s, this district has seen considerable industrialization, and it currently contains 133 industrial enterprises above a designated size (with annual business incomes more than 20 million RMB, or approximately 3.3 million U.S. dollars). Some of these industrial enterprises, such as the Wuhan Iron and Steel Corporation, the China First Metallurgical Construction Co., Ltd., and the Wuhan Heavy Casting and Forging plant, are very large and include heavy industries. The land east of this region is used to plant crops and vegetables, such as rice, eggplant, cabbage, cayenne pepper, and other common Chinese vegetables. The history of planting in this area is approximately 30 to 40 years long.
Sample collection and analysis
An extensive investigation of the soil within the study area was carried out in October 2010. In total, 124 topsoil samples were collected at depths of 0–20 cm within the study area. We found that the soil pollution in this area was serious. To monitor the degree of soil contamination, we collected topsoil samples from the study area in October from 2011 to 2014. Forty-five, 48, 55, and 48 soil samples were collected in 2011, 2012, 2013 and 2014, respectively. The spatial distribution of soil sampling points are shown in Fig. 1. At each sampling point, 5 sub-samples were collected at random and mixed to obtain a composite soil sample. Any foreign debris present in the soil samples was manually removed during sample collection. The coordinates of the sample locations were recorded with a GPS. All of the soil samples were air-dried at room temperature and passed through a 100-mesh nylon sieve, which included 100 holes within an area of 1 square inch. The prepared soil samples were then stored in polyethylene bottles for analysis.

Location of the study area and the spatial distribution of soil 86 sampling points during 2010–2014 (created 87 using ArcMap, version 10.2; http://www.esri.com/).
The concentrations of heavy metals, including copper (Cu), cadmium (Cd), lead (Pb), and zinc (Zn), were measured in the soil samples. Approximately 0.5 g of each prepared soil sample was digested using a mixture of nitric acid (HNO3) and perchloric acid (HClO4) in a Teflon beaker on a hot plate. The total concentrations of Cd, Cu, Cr, Pb and Zn in the digested solutions were measured using inductively coupled plasma mass spectrometry (ICP-MS; TMO, USA). The accuracy and precision of the measurements were tested using standard reference materials (GGS-3) obtained from the National Center for Standard Reference Materials of China. All of the soil samples were analyzed at the Key Laboratory of Arable Land Conservation (Middle and Lower Reaches of the Yangtze River) at the Ministry of Chinese Agriculture.
Methods
Spatiotemporal Cokriging
To begin, we consider two ST variables, Z u (x) and Z v (x), which we denote u and v, respectively; both of these variables obey the intrinsic hypothesis. To distinguish between space and time, let Z(x) = {Z(s, t)|s ∈ S, t ∈ T} be a variable that is defined on a geographical domain S ∈ R 2 and a time interval T ∈ R. The aim of this study is to predict the attribute u at a spatiotemporal point (s 0, t 0) where u was not measured. The prediction is based on measurements of u and v at n ST points (s i , t i ), i = 1… n. Note that not all u and v are observed at the same ST points; however, some ST points where u and v can be measured are required.
Under appropriate stationarity assumptions, an estimate of the ST semivariogram may be obtained from the measurements by computing the experimental semivariogram \({\hat{\gamma }}_{uu}({h}_{{\boldsymbol{S}}},{h}_{T})\), \({\hat{\gamma }}_{vv}({h}_{{\boldsymbol{S}}},{h}_{T})\) and the cross-semivariogram \({\hat{\gamma }}_{uv}({h}_{{\boldsymbol{S}}},{h}_{T})\):
where h S and h T are the S and T lags, respectively, and N u (h S , h T ), N v (h S , h T ), and N uv (h S , h T ) are the numbers of pairs in the ST lag for u, v and uv, respectively.
Fitting the models to the ST experimental semivariogram and cross-semivariogram has some additional problems over conventional semivariogram and cross-semivariogram modeling; these problems arise due to the distinct differences between the variations in S and T 10. In this study, we use an extension of the separate-sum models proposed by Bilonick19, in which geometric and zonal anisotropy are applied to the problems arising from the differences in S and T variability. In the Bilonick model, the semivariogram is divided into three parts: an S part, a T part and an ST part that includes only geometric anisotropy and neglects zonal anisotropy. Assuming that these three parts are mutually independent, the semivariogram and cross-semivariogram are the sum of three components:
The ST lag h ST is obtained by introducing a geometric anisotropy ratio α: \({h}_{ST}=\sqrt{{h}_{{\boldsymbol{S}}}^{2}+\alpha {h}_{T}^{2}}\). The advantage of the Bilonick model is that it has S, T and ST components that can be interpreted fairly easily in a physical sense. The disadvantage is that the estimation of the model parameters is challenging. Prior studies estimate the ratio α along with other parameters of the semivariogram10,11. In this study, if the ratio αin every semivariogram or cross-semivariogram is estimated, then each αvalue cannot possibly be the same. This outcome may not be in accordance with the physical significance, given that the spatiotemporal ratios for every variable and every pair of co-variables are not the same. In addition, the ratio αis a very important parameter because it determines how to obtain the spatiotemporal distance between two points in space and time; in particular, it determines which observed points in space and time are used as neighboring points when performing ST predictions. If the ratio αdiffers among the semivariograms or cross-semivariograms, different neighboring points will be determined in different variables or pairs of co-variables. Therefore, the ratio α in all of the semivariograms and cross-semivariograms will be considered to be a single parameter.
When models for the semivariogram and cross-semivariogram are obtained, ST cokriging can be performed. The aim is typically to estimate just one variable, which we may regard as the principal or target variable, at a spatiotemporal point x 0 (s 0 , t 0 ) using data that describe that variable and one or more other variables, which we regard as subsidiary variables. The equations used to perform cokriging in the ST domain are exactly the same as those used in standard S cokriging. The equations can be represented in matrix form. For simplicity, we consider only two variables, u and v. However, the matrices are easily extended to greater numbers of variables. Let Γ uv denote a matrix of semivariances (including cross-semivariances, in which u # v) between sampling points in a neighborhood. Let there be n u places where variable u has been measured and n v places where v has been measured. The order of the matrix is n u × n v :
We denote by b uu and b uv the vectors of semivariances for variable u and the cross-semivariances:
The matrix equation is then:
The estimated value of variable u at the spatiotemporal point x 0 (s 0, t 0) is then the linear sum:
The estimation variance is obtained from:
where λ is the vector of weights and Lagrange multipliers, and b is the right-hand side vector of the matrix equation (9).
Validation and comparison criteria
The results obtained through the use of STCK with different combinations of co-variables and different numbers of neighborhood points are compared. Soil heavy metals are predicted at each of the sites for which measurements are available using the leave-one-out method, which successively deletes the value of each location where the prediction was utilized. This procedure yields pairs of estimated and observed soil heavy metal concentrations. The root mean squared error (RMSE) is then computed from the pairs of estimated and observed soil heavy metals. The RMSE is defined as:
where Z(x j ) is the measured value, and \(\hat{Z}({x}_{j})\) is the predicted value. Smaller RMSE values indicate greater prediction accuracy.
Results and Discussion
Descriptive statistics of soil heavy metals
Descriptive statistics of Cd, Pb, Cu and Zn in the soil samples for each year are presented in Table 1. For Cd, Cu, and Zn, the soil concentrations show steady increases from 2010 to 2014. However, the concentrations of Pb show increases from 2010 to 2013, followed by a small decrease in 2014. Thus, the concentrations of soil heavy metals in the study generally increase over the investigated period.
The normality of Cd, Pb, Cu and Zn at all of the sampling points is tested using the Kolmogorov-Smirnov (K-S) method. The K-S test is a nonparametric test of the equality of continuous, one-dimensional probability distributions that can be used to compare a sample with a reference probability distribution (in this case, a normal distribution). This test examines whether two independent distributions are similar or different by generating cumulative probability distributions for the two distributions. The maximum distance or maximum difference is then entered into the K-S probability function to calculate the probability value. Lower probability values (<0.05) means that it is less likely that the two distributions are similar. Conversely, the higher or closer to 1 the value is, the more similar the two distributions are. The results show that the K-S values are 0.001, 0.000, 0.000, and 0.211 for Cd, Pb, Cu and Zn, respectively. Therefore, the Cd, Pb and Cu data were transformed using base 2 logarithms to achieve normal distributions.
Correlation coefficient analysis
The correlation coefficients were used to determine the relationships among different heavy metals in the soil samples and then to determine the co-variables for each heavy metal while performing the ST interpolation. The Pearson correlation coefficient is a statistical measure of the linear correlation between two variables. This metric takes values between +1 and −1, where 1 indicates total positive linear correlation, 0 indicates no linear correlation, and −1 indicates total negative linear correlation. In this study, Pearson correlation coefficients of the heavy metals in the soil samples are summarized in Table 2. Table 2 shows significantly positive correlations among the four heavy metals. Therefore, the three other types of heavy metals can be treated as co-variables when ST interpolation of one heavy metal is performed using STCK.
The ST semivariogram
Figure 2(a–d) shows the experimental semivariograms and fitting models for LogCu, LogCd, LogPb, and Zn. The semivariance displays similar behavior in the space and time directions. In the S direction, the semivariance increases continuously with increasing distance to 5000 to 6000 m and then decreases to approximately 8000 m. All of the semivariograms in the T direction show continuous and slow increases in semivariance for lags of 0 to 4 years. Figure 2(e–j) shows the experimental cross-semivariogram and fitting models for LogCd × LogCu, LogCd × LogPb, LogCd × Zn, LogCu × LogPb, LogCu× Zn, and LogPb × Zn. For LogCd × LogCu (Fig. 2e), LogCd × Zn (Fig. 2g), LogCu × LogPb (Fig. 2h), and LogCu × Zn (Fig. 2i), the cross-semivariance increases continuously with increasing distance to 5000 to 6000 m and is then steady in the S direction. For LogCd × LogPb (Fig. 2f) and LogPb × Zn (Fig. 2j), in the S direction, the cross-semivariance increases with increasing distance to approximately 2000 m and is then steady. In the T direction, all of the cross-semivariograms display continuous and slow increases for lags of 0 to 4 years.

Experimental ST semivariograms and fitting models for LogCd (a), LogCu(b), LogPb(c), and Zn(d) and experimental ST cross-semivariograms and fitting models for LogCd × LogCu (e), LogCd × LogPb (f), LogCd × Zn (g), LogCu × LogPb (h), LogCu × Zn (i), and LogPb × Zn (j).
Model fitting for ST semivariograms and cross-semivariograms
In this case, 4 semivariogram models and 6 cross-semivariogram models are fitted. The types of models are selected based on the figures showing the experimental ST semivariogram and the different logarithmic ST semivariograms. The T parts of all of the semivariograms and cross-semivariograms are modeled using a linear model. The S and ST parts for all of the semivariograms and cross-semivariograms, except LogCu × LogPb and LogCu × Zn, are modeled using a spherical model. The S and ST parts of LogCu × LogPb are modeled with a Gaussian model. The S and ST parts of LogCu × Zn are modeled with an exponential model. A nugget model is used to represent the nugget value of the semivariogram and the cross-semivariograms; hence, the form of the total ST semivariance for LogCu, LogCd, LogPb, and Zn and the form of the ST cross-semivariance for LogCd × LogCu, LogCd × LogPb, LogCd × Zn, and LogPb × Zn are defined as:
The form of the ST cross-semivariance for LogCu × LogPb is defined as:
The form of the ST cross-semivariance for LogCu × Zn is defined as:
Here, C 0 represents the nugget value of the model; C T represents the slope of T; C S and C ST represents the sill for S and ST; a S and a ST represent the range parameters of S and ST; and
Furthermore, the ratio α should be identical in all of the models. The value of C T is easily calculated using the experimental data. Fitting these 10 models to the experimental data is difficult because 51 parameters must be estimated. We thus use a genetic algorithm to simultaneously estimate these parameters by minimizing a fitness function:
where the weight factor w i is the quotient of the number of pairs in the lag \({\rm{N}}({h}_{{{\boldsymbol{S}}}_{i}},{h}_{{T}_{i}})\) and the square root of the semivariance \(\sqrt{\hat{\gamma }({h}_{{{\boldsymbol{S}}}_{i}},{h}_{{T}_{i}})}\) 10. The method of fitting models using a genetic algorithm was introduced and is described in detail in Yang et al.20. The parameter values resulting from the model fitting procedure are shown in Table 3.
ST interpolation and accuracy evaluation
Based on the methods introduced in section 3.1 and the models of the ST semivariograms and the ST cross-semivariograms (Table 3), STCK is performed for Cd, Cu, Pb and Zn. For example, in the most complex case, Cd is predicted, and all of the other heavy metals, including Cu, Pb, and Zn, are employed as co-variables. The matrix equation (9) is thus extended as follows:
To determine the influence created by the number of neighboring points, we predict the unmeasured ST points using the 4 to 20 nearest ST sampling points around the predicted ST site. The ST distance is determined using formula (16). Because α = 2085 and the spatial distances between the sampling points visited in 2014 are between 400 and 1500 m, manyistorical sampling points are incorporated into the group with the nearest ST sampling points. Consequently, the results of STCK are simultaneously influenced by the historical pollution situation and the correlation factors. We also examine the behavior of the STCK prediction using a different combination of co-variables. For example, considering LogCd, the variations in the prediction variance obtained using different numbers of neighboring points and different combinations of co-variables are shown in Fig. 3.

Average variance obtained using kriging with different numbers of neighboring points and different combinations of co-variables.
Based on Fig. 3, we conclude that the use of greater numbers of co-variables and neighboring points results in reductions in the variance of predictions. The RMSE cross-validation criterion for Cd in 2014 is provided in Fig. 4. The results of comparing the RMSE are generally consistent with the results obtained for prediction variance. The use of additional co-variables results in reduced RMSE values. However, the use of more neighboring points does not always produce reduced RMSE values. In addition, as shown in Fig. 4, the average RMSE of LogCd + LogCu < the average RMSE of LogCd + Zn < the average RMSE of LogCd + LogPb, indicating that the use of co-variables with relatively high correlation coefficients with the major variable results in greater prediction accuracies than the use of co-variables with relatively low correlation coefficients with the major variable.

RMSE as a function of different numbers of neighboring points and different combinations of co-variables.
Figure 5 shows the results of STCK interpolation using three co-variables and 20 neighboring sampling points from 2010 to 2014. The variables, including Cd, Pb, and Cu, are back-transformed to their original scales. Our results reveal a general tendency for elevated concentrations of Cd, Cu and Zn to spread from the southwestern part of the study area to the entire area over time, whereas Pb contamination tends to be concentrated mostly in the northern and western parts. Thus, the ST distributions of heavy metals reveal trends in their ST evolution that can assist in identifying sources of pollution and the directions in which the heavy metals diffuse. For example, based on Fig. 5, we conclude that the sources of the Cd, Cu and Zn pollution are located within the southwestern portion of the study area, i.e., the heavy industrial area of Wuhan City. In addition, the sources of Pb pollution are located within the northern and western parts of the study area.

ST distribution of soil heavy metals within the study area (created using ArcMap, version 10.2; http://www.esri.com/).
Conclusions
In this paper, we present a procedure for carrying out ST predictions of heavy metals based on the STCK method. Soil heavy metals, including Cd, Cu, Pb and Zn, measured in the Qingshan district of Wuhan City in China from 2010 to 2014 are employed as experimental data. The Bilonick model is used to fit ST auto- and cross-variograms, and a genetic algorithm is used to estimate the relevant parameters. The logical ST auto- and cross-variogram models shown in Fig. 2 indicate that the Bilonick model adequately describes the ST variability.
The results of STCK show that the use of additional co-variables improves the ST prediction accuracy; the average RMSE decreases as more co-variables are employed. In addition, the use of co-variables with relatively high correlation coefficients with the major variable results in greater prediction accuracies than the use of co-variables with relatively low correlation coefficients with the major variable. Thus, the use of additional co-variables with relatively high correlation coefficients with the major variable significantly improves the prediction accuracy. In addition, the number of neighboring points affects the prediction accuracy significantly. The use of additional neighboring points results in reduced prediction variance and higher general prediction accuracy.
The results of ST predictions of heavy metals can illustrate trends in ST evolution and can help environmental scientists to infer the locations of pollution sources and the directions in which the heavy metals are diffusing. Suitable environmental governance measures must be proposed.
References
Guagliardi, H., Cicchella, D. & Rosa, R. D. A Geostatistical approach to assess concentration and spatial distribution of heavy metals in urban soils. Water Air Soil Pollute 223, 5983–5998 (2012).
Giaccio, L., Cicchella, D., DeVivo, B., Lombardi, G. & De Rosa, M. Does heavy metal pollution affects semen quality in men? A case of study in the metropolitan area of Naples (Italy). Journal of Geochemical Exploration 112, 218–225 (2012).
Morton-Bermea, O. et al. Assessment of heavy metal pollution in urban topsoils from the metropolitan area of Mexico City. Journal of Geochemical Exploration 101, 218–224 (2009).
Lark, R. M., Bellamy, P. H. & Rawlins., B. G. Spatiotemporal variability of some metal concentrations in the soil of eastern England, and implications for soil monitoring. Geoderma 133, 363–379 (2005).
Guo, G. H., Wu, F. C., Xie, F. Z. & Zhang, R. Q. Spatial distribution and pollution assessment of heavy metals in urban soils from southwest China. Journal of Environmental Sciences 24(3), 410–418 (2012).
Imperato, M. et al. Spatial distribution of heavy metals in urban soils of Naples city (Italy). Environmental Pollution 124, 247–256 (2003).
Chen, T. B. et al. Assessment of heavy metal pollution in surface soils of urban parks in Beijing, China. Chemosphere 60, 542–551 (2005).
D’Emilio, M., Caggiano, R., Macchiato, M., Ragosta, M. & Sabia, S. Soil heavy metal contamination in an industrial area: analysis of the data collected during a decade. Environ Monit Assess 185, 5915–5964 (2013).
Kyriakidis, P. C. & Journel, A. G. Geostatistical space-time model: a review. Mathematical Geology 31, 651–684 (2005).
Snepvangers, J. J. J. C., Heuvelink, G. B. M. & Huisman, J. A. Soil water content interpolation using spatiotemporal kriging with external drift. Geoderma 112, 253–271 (2003).
Jost, G., Heuvelink, G. B. M. & Papritz, A. Analysing the space-time distribution of soil water storage of a forest ecosystem using spatiotemporal kriging. Geoderma 128, 258–273 (2005).
Douaik, A., Meirvenne, M. V. & Toth, T. Soil salinity mapping using spatiotemporal kriging and Bayesian maximum entropy with interval soft data. Geoderma 128, 234–248 (2005).
Bargaoui, Z. K. & Chebbi, A. Comparison of two kriging interpolation methods applied to spatiotemporal rainfall. Journal of Hydrology 365, 56–73 (2009).
Pearce, J. L., Rathbun, S. L., Aguilar-Villalobos, M. & Naeher, L. P. Characterizing the spatiotemporal variability of PM2.5 in Cusco, Peru using kriging with external drift. Atmospheric Environment 43, 2060–2069 (2009).
Zheng, Y. M., Chen, T. B. & He, J. Z. Multivariate geostatistical analysis of heavy metals in topsoil from Beijing, China. Journal of Soils and Sediments 8(1), 51–58 (2008).
Rashed, M. N. Monitoring of contaminated toxic and heavy metals, from mine tailings through age accumulation, in soil and some wild plants at Southeast Egypt. Journal of Hazardous Materials 178(1-3), 739–746 (2010).
Li, X. Y. et al. Heavy metal contamination of urban soil in an old industrial city (shengyang) in Northeast China. Geoderma 192, 50–58 (2013).
Goovaerts, P. Geostatistics for natural resources evaluation. Applied Geostatistics Series. Oxford Univ. Press, Oxford (1997).
Bilonick, R. A. Monthly hydrogen ion deposition maps for the northeastern U.S. from July 1982 to September 1984. Atmospheric Environment 22, 1909–1924 (1988).
Yang, Y., Li, W. D. & He, L. Y. Uniform expression of variogram nested model and parameter estimation in spatial prediction of soil properties. Transactions of the CSAE 27(6), 85–89 (2011).
Acknowledgements
This research was supported by the National Natural Science Foundation of China (Grant No. 41671217) and the Fundamental Research Funds for Central Universities (Grant No. 2662017PY038). The opinions presented in this paper do not constitute an endorsement or approval by the funding agencies and reflect only the personal views of the authors.
Author information
Authors and Affiliations
Contributions
Yong Yang conceived and designed the study. Bei Zhang performed the computations and wrote the manuscript.
Corresponding author
Ethics declarations
Competing Interests
The authors declare that they have no competing interests.
Additional information
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhang, B., Yang, Y. Spatiotemporal modeling and prediction of soil heavy metals based on spatiotemporal cokriging. Sci Rep 7, 16750 (2017). https://doi.org/10.1038/s41598-017-17018-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-017-17018-5
This article is cited by
-
Effectiveness of predicting the spatial distributions of target contaminants of a coking plant based on their related pollutants
Environmental Science and Pollution Research (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
