
Abstract
The shortest path problem is one of the most fundamental networks optimization problems. Nowadays, individuals interact in extraordinarily numerous ways through their offline and online life (e.g., co-authorship, co-workership, or retweet relation in Twitter). These interactions have two key features. First, they have a heterogeneous nature, and second, they have different strengths that are weighted based on their degree of intimacy, trustworthiness, service exchange or influence among individuals. These networks are known as multiplex networks. To our knowledge, none of the previous shortest path definitions on social interactions have properly reflected these features. In this work, we introduce a new distance measure in multiplex networks based on the concept of Pareto efficiency taking both heterogeneity and weighted nature of relations into account. We then model the problem of finding the whole set of paths as a form of multiple objective decision making and propose an exact algorithm for that. The method is evaluated on five real-world datasets to test the impact of considering weights and multiplexity in the resulting shortest paths. As an application to find the most influential nodes, we redefine the concept of betweenness centrality based on the proposed shortest paths and evaluate it on a real-world dataset from two-layer trade relation among countries between years 2000 and 2015.
Similar content being viewed by others


Introduction
Individuals are connected to one other through different interactions such as friendship, conversation, cooperation, and game. Investigating these interactions helps to understand the reason for emergence and development of different societies1. Since the pioneering work on group formation by Moreno in 1932 which took the advantages of graphs in order to graphically represent individuals as nodes and the interaction between them as links2, this approach has attracted the attention of many researchers3, 4. More recently, the heterogeneous nature of social interactions has led to introduce multiplex networks5,6,7,8,9 (for the definition of the multiplex and weighted multiplex network refer to Supplementary Note 1). This concept motivated by the fact that many real-world networks are interact with or depend on other networks10.
Social ties have different strengths: absent, strong or weak11. Interactions also can have positive (e.g., friendship, and collaboration) or negative (e.g., enmity, and hatred) connotation12. This differentiation becomes even more significant if the interactions in large-scale Social Network Sites (SNSs) be taken into consideration. Due to the simplicity of creating new relationships in SNSs, most of these relations have weak strengths without emotional closeness and intimacy13. Ignoring the links diversity in capacity and intensity and considering all of them as a simple binary relation causes oversimplification and loss of information14. This concept motivates many researchers to develop methods for inferring the strength of relations and assign a weight to each link. The weights can correspond to the amount of time which two individuals spend together, services exchange, emotional intensity, the degree of intimacy11, trustworthiness15, and influence16. In this work, we focus only on the influence of the relations as the strength among different nodes (see Supplementary Note 2 for the definition of the influence).
Studies on distance in social networks date back to pioneering works of Simmel17 which defined the concept of the stranger and Bogardus18 which used the concept of social distance in measuring prejudice. However, most of the previous efforts on finding the distance between individuals are based on the degree of separation in single-layer networks (without considering the strength of relations and multiplexity)19, 20. By considering the influence as weight, finding a path between two individuals that maximizing the influence, will return the indirect influence of individuals upon each other21. In multiplex networks, due to the heterogeneity of relations, the concept of the shortest path is different. The heterogeneity in relation types leads to use the concept of Multiple Objective Decision Making (MODM). MODM refers to the process of making decisions in the presence of multiple conflicting objectives (for more information see Supplementary Note 3). In previous work22, we introduced a geodesic distance named Pareto distance to deal with this heterogeneity, but the weighted nature of relations was ignored in that work which may result in non-optimal paths (for an example of finding optimal paths in multiplex networks in presence and absence of influence of relations refer to Supplementary Note 4). Hence, in this work we introduce a new distance measure based on both the multiplexity and weighted nature of relations, named influential Pareto distance. Influential Pareto distance uses the concept of Pareto efficiency and attempts at finding the paths in a multiplex network which have the optimal total weight (e.g., the maximum influence) in each layer separately. We name these paths as influential Pareto paths. By taking the advantages of multimodal transportation and edge-colored graph algorithms, we propose an MODM framework and an exact algorithm to find the whole set of these optimal paths. We also redefined the concept of betweenness centrality based on these paths.
Results
We evaluated our approach on five weighted multiplex datasets from international Trade network23, Twitter24, Sampson Monastery25, Youtube26, and StarWars27. For more information about the datasets including their density and the total weight of each layer refer to Supplementary Note 5.
Influential Pareto paths and the usage of different layers
We claim that by considering the influence of relations, the shortest paths will tend to walk through different layers, which means the search will be effective and the individuals will be reachable through using relations in other layers. To support this claim, we use the network interdependence parameter28, 29 which is a measure for evaluating node reachability in multiplex networks as follows:
where N is the number of nodes, ψ ij is the number of the shortest paths from node i to node j which use the links in two or more layers, and σ ij is the total number of the shortest paths from node i to node j. λ lies between zero (when all the links of each shortest paths belong to only one layer) and one (when all the shortest paths use links belong to more than one layers). In this context, we use the influential Pareto paths to obtain the network interdependence parameter for all datasets (see Fig. 1(a)). We also calculate the average number of inter-layer switches for these paths in Fig. 1(b). The results show that all datasets (except for Twitter which has a very low density) have a high value for the network interdependence parameter and the average number of switches. Hence, these influential Pareto paths are compatible with the nature of multiplexity and utilize different layers. One of the inevitable consequences of this compatibility is using these paths in order to find the most influential nodes in multiplex networks.

Characteristics of influential Pareto paths. (a) Representation of the network interdependence parameter for influential Pareto paths in five datasets. (b) Representation of the average number of inter-layer switches. (c) The fraction of participation of each layer in the influential Pareto paths. (d) Representation of the domination percentage of influential Pareto paths by the paths with minimum number of links traversed in each layer, for each pair of nodes for four datasets; and the total domination percentage of influential Pareto paths. The white points show that there are no paths between two pairs of nodes.
Multiplex influential betweenness centrality
Identifying the main influencers and key players in complex networks has a variety of applications in different fields such as finding epidemic and innovation spreading patterns, cascading failure, and propagation of information30,31,32. Some recent studies on single-layer networks, capitalized on nonbacktracking (NB) matrix33 in order to find the influencers. Martin et al.34 introduced a new centrality measure based on NB matrix to avoid the localization phenomena which arises in eigenvector centrality measure and causes this measure to have a low efficiency. Morone and Makse35 mapped the spreading and immunization problems into optimal percolation. Afterward, utilizing a modified NB matrix, they defined the problem of finding the set of optimal influencers as the minimum set of nodes which minimizes the largest eigenvalue of this matrix.
More recently, some studies have focused on finding influential nodes in the existence of different types of relations (i.e., multiplexity)36, 37. Pei et al.38 show that despite the common belief about the importance of social links in information spreading, the effect of other factors and interaction types are also crucial. Hence, in order to find influential nodes for an efficient promotion strategy, different interaction types among individuals must be considered. Domenico et al.36 redefined some existing centrality measures such as eigenvector and PageRank centralities to work with multiple types of relations, based on the random walk process on these networks. They also defined a path in a multiplex network as a sequence of links starting from a node in layer x and ends in a node in layer y, and defined a betweenness centrality measure based on this definition of the path. The drawback of this path definition is ignorance of the heterogeneity of the relations and dealing with all links in different layers in the same manner.
Here we investigate the role of influential Pareto paths on finding the most influential nodes in multiplex networks. For this, we redefine the concept of node betweenness centrality measure. We define the multiplex influential betweenness centrality of node i in multiplex network as the number of influential Pareto paths between any two nodes that contains node i. Since influential Pareto paths walk through different layers, the nodes with more participation in other layers will have more multiplex influential betweenness centrality and their ranking will be higher. Hence, this measure will present a better ranking for nodes in multiplex network based on their participation in different layers. Figure 2 shows the values of this measure for every node in Trade dataset. The bar charts show this measure for four years (for each year, the percentage of multiplex influential betweenness of each node compared to others is calculated) for 30 countries which have the most Gross Domestic Product (GDP) value. The countries are listed based on their GDP values in 2015 from left to right.

Representation of multiplex influential betweenness centrality for every node in Trade dataset. The bars show the percentage of multiplex influential betweenness centrality of 30 countries for four years. The countries are listed based on their GDP values in 2015 from left to right.
Figure 3 shows the importance of countries based on our multiplex influential betweenness centrality measure between the years 2000 and 2015 for fifteen countries which have the most multiplex influential betweenness in the year 2015. This figure shows that there was a significant increment for the importance of China from 2000 to 2015. However, countries like Japan, Great Britain, and the USA has a decrement in their multiplex importance in trade network. Russia also undergoes a significant decrement in its importance in 2014. Some other countries like Italy have a stable ranking from 2000 to 2015.

Percentage of multiplex influential betweenness centrality, by country (2000–2015).
Role of weak layers in the shortest paths
The effect of weak layers in multiplex networks first discussed by Lee et al.39 on cascading failure process in these networks. Weak layers in a multiplex network are those layers with minimal total weights of relations. In order to compute the importance of each layer in optimal paths, we calculate the percentage of participation of each layer in influential Pareto paths based on the percentage of links belonged to each layer. Figure 1(c) shows the importance of layers for five datasets. Our results show that the weak layers play an important role in optimal paths. For example, for the Trade dataset the total weight for secondary industry sector is 9.27 trillion US$ and for primary industry sector is equal to 14.75 trillion US$ which means the secondary industry sector is a weak layer in trade among countries. However, most of the links traversed in influential Pareto paths belongs to this weaker layer. In Sampson dataset, as another example, the weakest layer is Praising layer with the total weight of 77. However, this weak layer plays the most important role in optimal paths and has the highest percentage of participation.
Influential Pareto paths and the minimum number of links
Another question that requires more attention is “are influential Pareto paths longer than those paths with the minimum number of links traversed in each layer?”. In other words, how many of influential Pareto paths will be dominated by those paths with the minimum number of links traversed in each layer considering only the hop counts. Our results in Fig. 1(d) show that most of the influential Pareto paths (more than 80%) become dominated in different datasets. This means that the influential Pareto paths are not always the shorter ones. The total domination percentage depends on the density of the networks. As it can be seen, for denser datasets (i.e., Trade and Sampson) the total domination percentage is smaller than those with lower density (i.e., StarWars and Youtube). Hence, the influential Pareto paths are more differentiated from shortest paths in low-dense multiplex networks.
Discussion
In this work, we focus on the problem of finding shortest paths in multiplex networks, a generic term that we use to refer to a number of network models involving multiple types of relationships. While shortest paths in single networks has received considerable attention, this problem in the context of multiplex networks is still a young research area. In current work, we introduced a new distance metric based on the both relations strength and heterogeneity of relations, named influential Pareto distance. We also proposed a multiple objective decision making framework and an exact algorithm to find the whole set of these optimal shortest paths. We name these paths as influential Pareto paths. We evaluate the resulting shortest paths in term of different aspects as network interdependence, average inter-layer switches, role of weak layers, and the length of paths. We also redefined the concept of betweenness centrality based on the influential Pareto paths. Since we observed influential Pareto paths walk through different layers, this new definition presents a better node centrality ranking in multiplex network. Using the proposed metric, we computed the importance of different countries in terms of international trade networks which is a two-layer multiplex network.
Since the problem of finding influential Pareto paths in multiplex networks belongs to the class of NP-completeness, our proposed exact algorithm has limitation for applying to more complex and larger networks. Hence, We proposed a method based on the well-known Nondominated Sorting Genetic Algorithm II (NSGA-II)40 framework in order to find the near-optimal solutions in lower time complexity, and evaluated the resulting solutions set of this approach based on different parameters and different performance measures. (see Supplementary Note 7). Some information around the comparision of characteristic of optimal paths in presence and absence of strength of relations has shown in Supplementary Note 6.
Methods
Influential Pareto Distance and Influential Pareto Paths
Positive weights need to be maximized through the path and negative weights need to be minimized. The weights can also be multiplicative or additive through the path. However, regardless of minimization or maximization of multiplicative or additive weights, all of such problems can be transformed into a minimization problem of additive weights through the path. Suppose that Θ is a multiplicative metric and we want to find a path P from source node S to destination node D maximizes this metric. Hence, we will have:
which is equivalent to the following statement (taking the logarithm):
Thus, in the case of influence, by changing the influence of each link to \(log(1/I({x}_{i}))\) (see Supplementary Note 2), the problem will be transformed into the minimization problem of additive weights through the path.
Definition 1 (Influential multiplex path length). The influential multiplex path length of path p on L networks is defined as a set (s 1, s 2, …, s l , …, s L ), where s l is the summation of weights of links traversed in layer l.
Definition 2 (Influential Pareto distance). Consider all paths from source node S to destination node D and let IMP(S, D) be the set of all influential multiplex path lengths of these paths. The influential Pareto distance from S to D is defined as the set \(SP\subseteq IMP\) such that \(\forall p\in SP\nexists p^{\prime} \in IMP:p^{\prime} \,\preccurlyeq \,p\).
The notion \(\preccurlyeq \) shows the domination relation. The influential Pareto distance corresponds to objective space and is equivalent to Pareto front. Each member of influential Pareto distance can be a map from many paths in decision space. We name the set of all paths in decision space mapped onto influential Pareto distance members in objective space as influential Pareto paths set which is equivalent to Pareto set.
Method for finding influential Pareto paths set in multiplex networks using MODM framework
Here, we propose a method for finding the whole set of influential Pareto paths. For this, we consider three main phases according to Fig. 4. The phase 2, contains two steps as follows:
-
1.
We ascribe to each link in the multiplex network a weight vector \({W}_{{(ij)}^{\gamma }}=({w}_{{(ij)}^{\gamma }}^{1},{w}_{{(ij)}^{\gamma }}^{2},\ldots ,{w}_{{(ij)}^{\gamma }}^{L})\) where L is the number of layers, and construct a new multiplex network \(\vec{G}^{\prime\prime} \).
-
2.
For each link in network \(\vec{G}^{\prime\prime} \), if it belongs to layer l, we set l-th weight of the link equals to the weight of the link in \(\vec{G}^{\prime} \) and set all the other weights of that weight vector equals to zero (Fig. 5).
Figure 4 
Different phases of our proposed method in order to find influential Pareto path set in weighted multiplex networks.
Figure 5 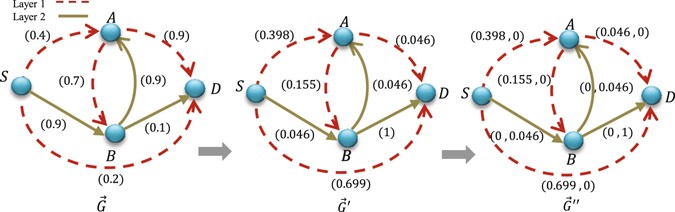
Construction of graph \(\vec{G}^{\prime\prime} \) for the two-layer weighted multiplex network. \(\vec{G}\) is a two-layer multiplex network with influence on each link. \(\vec{G}^{\prime} \) is the graph constructed by changing the influence of each link based on \(log(1/I({x}_{i}))\) in order to transform the problem onto the problem of minimization of additive weights. \(\vec{G}^{\prime\prime} \) is the multiplex network with multiple weights on each link constructed from \(\vec{G}^{\prime} \).


At phase three, Supplementary Algorithm 1 will apply to the graph \(\vec{G}^{\prime\prime} \). This algorithm will find the set of multiobjective shortest paths (MOSP) from S to D in \(\vec{G}^{\prime\prime} \), which is itself the influential Pareto path set for graph \(\vec{G}^{\prime} \). Afterward, the influential Pareto distance set can simply infer from this set. Since most of the algorithms on finding MOSP work on single-layer networks, we improve one of the existing exact algorithms of MOSP in single-layer networks to work with multiplex networks.
MOSP algorithms in single-layer networks can be restricted to four following species: exact, heuristic, approximate, and meta-heuristic41,42,43,44. Many of these algorithms (especially heuristic and approximate ones) assume that the weights are nonzero. Hence they cannot be generalized for our problem which most of the weights are zero. In order to find MOSP in graph \(\vec{G}^{\prime\prime} \), we improved an exact label-setting algorithm presented by Martin and Santos45 to works with different types of links. The mathematical formulation of the problem is as follow:
Suppose that we construct the multiplex graph \(\vec{G}^{\prime\prime} \) with a vector of weights \({W}_{{(ij)}^{\gamma }}=({w}_{{(ij)}^{\gamma }}^{1},{w}_{{(ij)}^{\gamma }}^{2},\ldots ,{w}_{{(ij)}^{\gamma }}^{L})\) on each link. Assume that X is a vector consisting of \({x}_{ij}^{\gamma }\), where \({x}_{ij}^{\gamma }=1\) indicates that (i, j)γ is a link on the path and \({x}_{ij}^{\gamma }=0\) otherwise. Then a path is composed of the links with \({x}_{ij}^{\gamma }=1\). The problem of finding multiobjective shortest path from S to D in multiplex network \(\vec{G}^{\prime\prime} \) can be formulated as follows:
Subject to
This problem belongs to the class of multiobjective combinatorial optimization (MOCO) and is NP-complete. The pseudocode of our extension of Martin and Santos exact algorithm using the notion from Garroppo et al.46 described in Supplementary Note 8.
References
Levine, D. & Simmel, G. Georg Simmel on Individuality and Social Forms. Heritage of Sociology Series (University of Chicago Press, 1972).
Moreno, J. & Jennings, H. Who shall survive?: A new approach to the problem of human interrelations. Nervous and mental disease monograph series (Nervous and mental disease publishing co., 1934).
Kramer, A. D. I., Guillory, J. E. & Hancock, J. T. Experimental evidence of massive-scale emotional contagion through social networks. Proceedings of the National Academy of Sciences 111, 8788–8790, doi:10.1073/pnas.1320040111 (2014).
Guimera, R., Sales-Pardo, M. & Amaral, L. A. Classes of complex networks defined by role-to-role connectivity profiles. Nature Physics 3, 63–69, doi:10.1038/nphys489 (2007).
Battiston, F., Nicosia, V. & Latora, V. Structural measures for multiplex networks. Physical Review E 89, 032804, doi:10.1103/PhysRevE.89.032804 (2014).
Boccaletti, S. et al. The structure and dynamics of multilayer networks. Physics Reports 544, 1–122, doi:10.1016/j.physrep.2014.07.001 (2014).
Kivelä, M. et al. Multilayer networks. Journal of Complex Networks 2, 203–271, doi:10.1093/comnet/cnu016 (2014).
De Domenico, M., Granell, C., Porter, M. A. & Arenas, A. The physics of spreading processes in multilayer networks. Nature Physics (2016).
Salehi, M. et al. Spreading processes in multilayer networks. IEEE Transactions on Network Science and Engineering 2, 65–83, doi:10.1109/TNSE.2015.2425961 (2015).
Gao, J., Buldyrev, S. V., Stanley, H. E. & Havlin, S. Networks formed from interdependent networks. Nature Physics 8, 40–48, doi:10.1038/nphys2180 (2012).
Granovetter, M. S. The Strength of Weak Ties. American Journal of Sociology 78, 1360–1380, doi:10.1086/225469 (1973).
Szell, M., Lambiotte, R. & Thurner, S. Multirelational organization of large-scale social networks in an online world. Proceedings of the National Academy of Sciences 107, 13636–13641, doi:10.1073/pnas.1004008107 (2010).
Xiang, R., Neville, J. & Rogati, M. Modeling relationship strength in online social networks. In Proceedings of the 19th International Conference on World Wide Web, 981–990 (ACM, 2010).
Barrat, A., Barthelemy, M., Pastor-Satorras, R. & Vespignani, A. The architecture of complex weighted networks. Proceedings of the National Academy of Sciences of the United States of America 101, 3747–3752, doi:10.1073/pnas.0400087101 (2004).
Al-Oufi, S., Kim, H.-N. & Saddik, A. E. A group trust metric for identifying people of trust in online social networks. Expert Systems with Applications 39, 13173–13181, 10.1016/j.eswa.2012.05.084, URL http://www.sciencedirect.com/science/article/pii/S0957417412008007 (2012).
Hangal, S., MacLean, D., Lam, M. S. & Heer, J. All friends are not equal: Using weights in social graphs to improve search. In Workshop on Social Network Mining & Analysis, ACM KDD (2010).
Simmel, G. & Wolff, K. H. The Sociology of Georg Simmel (Free Press, 1964).
Wark, C. & Galliher, J. F. Emory bogardus and the origins of the social distance scale. The American Sociologist 38, 383–395, doi:10.1007/s12108-007-9023-9 (2007).
Kleinberg, J. M. Navigation in a small world. Nature 406, 845–845, doi:10.1038/35022643 (2000).
Boguná, M., Krioukov, D. & Claffy, K. C. Navigability of complex networks. Nature Physics 5, 74–80, doi:10.1038/nphys1130 (2009).
Liu, L., Tang, J., Han, J., Jiang, M. & Yang, S. Mining topic-level influence in heterogeneous networks. In Proceedings of the 19th ACM International Conference on Information and Knowledge Management, CIKM ’10, 199–208 (ACM, New York, NY, USA, 2010).
Magnani, M. & Rossi, L. Pareto Distance for Multi-layer Network Analysis. In Greenberg, A., Kennedy, W. & Bos, N. (eds) Social Computing, Behavioral-Cultural Modeling and Prediction, vol. 7812 of Lecture Notes in Computer Science, 249–256 (Springer Berlin Heidelberg, 2013).
UN Comtrade Database. http://comtrade.un.org (Accessed: 09-12-2016).
Omodei, E., De Domenico, M. & Arenas, A. Characterizing interactions in online social networks during exceptional events. arXiv preprint arXiv:1506.09115 (2015).
Sampson, S. F. A novitiate in a period of change: An experimental and case study of social relationships (Cornell University, 1968).
Tang, L., Wang, X. & Liu, H. Uncoverning groups via heterogeneous interaction analysis. In 2009 Ninth IEEE International Conference on Data Mining, 503–512 (IEEE, 2009).
StarWars network. https://github.com/evelinag/StarWars-social-network/tree/master/networks (Accessed: 09-03-2016).
Morris, R. G. & Barthelemy, M. Transport on coupled spatial networks. Physical Review Letters 109, 128703, doi:10.1103/PhysRevLett.109.128703 (2012).
Nicosia, V., Bianconi, G., Latora, V. & Barthelemy, M. Growing multiplex networks. Physical Review Letters 111, 058701, doi:10.1103/PhysRevLett.111.058701 (2013).
Kitsak, M. et al. Identification of influential spreaders in complex networks. Nature Physics 6, 888–893, doi:10.1038/nphys1746 (2010).
Malliaros, F. D., Rossi, M.-E. G. & Vazirgiannis, M. Locating influential nodes in complex networks. Scientific Reports 6 (2016).
Gómez-Gardeñes, J., Lotero, L., Taraskin, S. & Pérez-Reche, F. Explosive contagion in networks. Scientific Reports 6 (2016).
Hashimoto, K.-i. Zeta functions of finite graphs and representations of p-adic groups. Automorphic forms and geometry of arithmetic varieties, 211–280 (1989).
Martin, T., Zhang, X. & Newman, M. Localization and centrality in networks. Physical Review E 90, 052808, doi:10.1103/PhysRevE.90.052808 (2014).
Morone, F. & Makse, H. A. Influence maximization in complex networks through optimal percolation. Nature 524, 65–68, doi:10.1038/nature14604 (2015).
De Domenico, M., Solé-Ribalta, A., Omodei, E., Gómez, S. & Arenas, A. Ranking in interconnected multilayer networks reveals versatile nodes. Nature communications 6, 6868, doi:10.1038/ncomms7868 (2015).
Buldyrev, S. V., Parshani, R., Paul, G., Stanley, H. E. & Havlin, S. Catastrophic cascade of failures in interdependent networks. Nature 464, 1025–1028, doi:10.1038/nature08932 (2010).
Pei, S., Muchnik, L., Tang, S., Zheng, Z. & Makse, H. A. Exploring the complex pattern of information spreading in online blog communities. PloS one 10, e0126894, doi:10.1371/journal.pone.0126894 (2015).
Lee, K.-M. & Goh, K.-I. Strength of weak layers in cascading failures on multiplex networks: case of the international trade network. Scientific Reports 6 (2016).
Deb, K., Pratap, A., Agarwal, S. & Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Transactions on Evolutionary Computation 6, 182–197, doi:10.1109/4235.996017 (2002).
Tarapata, Z. Selected multicriteria shortest path problems: An analysis of complexity, models and adaptation of standard algorithms. International Journal of Applied Mathematics and Computer Science 17, 269–287, doi:10.2478/v10006-007-0023-2 (2007).
Warburton, A. Approximation of pareto optima in multiple-objective, shortest-path problems. Operations Research 35, 70–79, doi:10.1287/opre.35.1.70 (1987).
Tung, C. T. & Chew, K. L. A multicriteria pareto-optimal path algorithm. European Journal of Operational Research 62, 203–209, doi:10.1097/jnr.0000000000000056 (1992).
Tsaggouris, G. & Zaroliagis, C. Multiobjective optimization: Improved fptas for shortest paths and non-linear objectives with applications. Theory of Computing Systems 45, 162–186, doi:10.1007/s00224-007-9096-4 (2009).
Martins, E. d. Q. V. & Santos, J. The labeling algorithm for the multiobjective shortest path problem. Departamento de Matematica, Universidade de Coimbra, Portugal, Tech. Rep. TR-99/005 (1999).
Garroppo, R. G., Giordano, S. & Tavanti, L. A survey on multi-constrained optimal path computation: Exact and approximate algorithms. Computer Networks 54, 3081–3107, doi:10.1016/j.comnet.2010.05.017 (2010).
Acknowledgements
This research was in part supported by a grant from IPM (No. CS1394-4-32). M.J. is supported by Australian Research Council through projects No. DE140100620 and DP170102303.
Author information
Authors and Affiliations
Contributions
S.Gh. and M.S. contribute equally in this work. They conceived the study, performed the experiments, analysed the data, and wrote the manuscript. M.M. and M.J. analysed the results and wrote the paper. All authors approved the final version of the manuscript.
Corresponding author
Ethics declarations
Competing Interests
The authors declare that they have no competing interests.
Additional information
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ghariblou, S., Salehi, M., Magnani, M. et al. Shortest Paths in Multiplex Networks. Sci Rep 7, 2142 (2017). https://doi.org/10.1038/s41598-017-01655-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-017-01655-x
This article is cited by
-
The rise and fall of countries in the global value chains
Scientific Reports (2022)
-
Understanding bikeability: a methodology to assess urban networks
Transportation (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
