
Abstract
With the development and application of super rice breeding, elite rice hybrids with super high-yielding potential have been widely developed in last decades in China. Xieyou9308 is one of the most famous super hybrid rice varieties. To uncover the genetic mechanism of Xieyou9308’s high yield potential, a recombinant inbred line (RIL) population derived from cross of XieqingzaoB and Zhonghui9308 was re-sequenced and investigated on the grain yield (GYD) and its three component traits, number of panicles per plant (NP), number of filled grains per panicle (NFGP), and grain weight (GW). Unconditional and conditional genome-wide association analysis, based on a linear mixed model with epistasis and gene-environment interaction effects, were conducted, using ~0.7 million identified SNPs. There were six, four, seven, and seven QTSs identified for GYD, NP, NFGP, and GW, respectively, with accumulated explanatory heritability varying from 43.06% to 48.36%; additive by environment interactions were detected for GYD, some minor epistases were detected for NP and NFGP. Further, conditional genetic mapping analysis for GYD given its three components revealed several novel QTSs associated with yield than that were suppressed in our unconditional mapping analysis.
Similar content being viewed by others

Introduction
Rice is a fundamentally important staple crop, and improving rice yields has remained a major goal in world agriculture. Super hybrid rice shows great advantages in grain yield and biomass in comparison with conventional rice varieties. Since its inception in China in 1996, super rice breeding program has achieved tremendous increases in rice yields1. Xieyou9308 is one of the most famous super hybrid rice varieties with a grain yield as high as 12.23 t/ha1. However, the genetic basis underlying this high yield potential remains largely unclear. In order to fuel the further successes of super rice breeding programs, continued efforts to dissect the genetic basis of economically-important traits will be necessary.
Economically, the most important agronomic trait for rice is grain yield (GYD). GYD exhibits complex genetics, as it is known to be an integrated quantitative trait that is influenced variously by yield component traits and by the environment. Several QTL linkage mapping studies with Xieyou9308 have used conventional molecular markers to explore the causal loci that are responsible for the phenotypic variation of economically-important traits2,3,4. However, owing to the insufficient density of polymorphism markers, the QTLs reported in these studies could typically only be localized to very large chromosomal regions, where still may harbor considerable amounts of genetic variants5. This restricts the consequent application of these QTLs in marker assisted breeding to some extent.
Partly impelled by advances in sequencing technologies and the resulting improvements in genotyping, genome-wide association study (GWAS) strategy has become one of the primary approaches used to identify causal genes underlying phenotypic variation. GWAS is particularly attractive because it offers hope for rapidly narrowing the region where a causal gene might lie. Although pioneered by human geneticists, GWAS is also being appealingly applied to plants including rice6,7,8,9,10,11,12. Huang et al.9 re-sequenced 517 rice landraces and used GWAS methods to analyze putative causal relationships between 14 agronomic traits and ~3.6 million SNPs, from which they identified three loci associated with tiller number, two loci associated with spikelet number, two loci associated with grain width, and five loci associated with grain length. A subsequent study from Huang et al.12 reported 32 new loci associated with 11 agronomic traits based on a natural population of 950 worldwide rice varieties. Another GWAS based on 413 diverse accessions of O. sativa from 82 countries identified 234 loci associated with 34 agronomic traits using 44,100 identified SNP variants11.
These studies confirm that GWAS is a powerful approach that can be used in rice to identify genetic variants associated with complex traits with high resolution. However, most of these studies were focused on detecting genetic variant exhibiting additive genetic effects without consideration of gene-environmental and gene-gene interactions which were thought to be very important for complex traits. In addition, the cryptic population structure in the rice natural population (collected landraces) which would increase the false positive associations also haunted the researchers. Moreover, although increasing numbers of association studies have attempted to map the casual genes for yield traits of rice, most of these studies dissected traits separately, without considering genetic correlations between traits. As yield traits are known to be interrelated, exploring genetic correlations among these traits should provide additional insights into the genetic basis of grain yield. Conditional genetic analysis is a methodology first introduced by Zhu13 to study developmental quantitative genetics; it was later extended for the analysis of the genetic contributions of component traits to an integrated trait at the molecular level14, 15.
In this study, the derived recombinant inbred line (RIL) population of Xieyou9308, which should theoretically have no deleterious issues relating to population structure, were re-sequenced and used for both genome-wide association mapping and for conditional association mapping for GYD and its three constitutive traits. The analysis was based on a saturated mixed linear model that included both epistasis and gene-environmental interactions. Further, a conditional methodology was adopted to identify additional candidate regions that likely contribute to grain yield. Our results provided some information that should be of use in efforts seeking genetic improvement of yield potential in rice.
Results
Phenotypic variation of yield traits and their inter-correlations
As shown in Table 1, all four traits varied widely among the RI lines (CV = 9.88~27.51% in E1, and 10.23~25.36% in E2), with the NFGP trait showing the largest variation and the GW trait showing the smallest variation for both locations. Additionally, significant differences in mean values were detected at the 0.05 significance level (Tukey’s test) for the GYD, NP, and NFGP traits between the two environments. All four traits segregated continuously (Fig. 1), and the NP and NFGP exhibited approximately bimodal distributions, probably suggesting the existence of complex genetic bases underlying these two traits. The inter-correlations in phenotypic values and genotypic values between any two of the four traits are presented in Table 2. Significant positive correlations were observed between GYD and its three components: GYD had relatively higher positive correlations with NFGP than with NP, and insignificant positive correlation with GW. In contrast, the component traits were negatively correlated with each other. There was an especially strong negative correlation between NP and NFGP, which indicated that it will likely be necessary to conduct conditional mapping as the variation caused by these two components could be counteracted by the opposite effects during the formation of the final yield trait.

The phenotypic distribution of grain yield and yield components. The histograms for phenotypes from each experiment location Hangzhou (top panel), Lingshui (middle panel), and their together (bottom panel) were plotted; and each column represents one phenotype (from left to right: grain yield (GYD), number of panicles (NP), number of filled grains per panicle (NFGP), grain weight (GW)).
Genome-wide association analyses for four yield traits
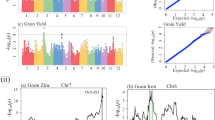
In total, there were 24 SNPs detected significantly (6 SNPs for GYD, 4 SNPs for NP, 7 SNPs for NFGP, and 7 SNPs for GW) with accumulated explanatory heritabilities varying from 43.06% to 48.36%. There was an additive by environment interaction detected in grain yield (GYD), and some epistatic effects were detected for NP and NFGP (Table 3; Fig. 2).

Genetic architecture of detected QTSs for grain yield and yield components in both the unconditional mapping and conditional mapping analyses. Circle = QTX individual additive effect; Line between two QTXs = epistasis effects; Red = general effects across two environments; Blue = general and environment-specific effects.
As shown in Table 3, for GYD, there were 6 significant SNPs located on 4 chromosomes, together accounting for 43.06% of the phenotypic variation. All QTSs except one (rs5137246 on chromosome 6), showed large negative additive effects with individual contributions to the heritability in a range from 4.01% to 10.91%. The negative additive genetic effects indicated that the paternal homozygous genotype (QQ, Q here referred to as the allele from ZH9308) would decrease the grain yield, while the corresponding maternal allele homozygotes (qq) would increase the grain yield. The QTS located on chromosome 4 (rs8203251) exhibited the largest main additive (h 2 = 10.91%), and additive by environment interaction which showed opposite genetic effects in the two different locations. For NP, the total heritability (43.35%) mainly consisted of additive heritability (41.03%) from 4 QTSs whose individual heritability was quite large, especially for rs28989077 (h 2 = 18.54%). The remaining heritability was from one pair of additive by additive epistasis effects (rs20829501/rs9429313). All the main additive effects were negative; only one epistasis was positive, and its genetic effect size was relatively small as compared with the main additive effects (Table 3).
For NFGP, unlike the aforementioned two traits, most detected QTSs showed positive and modest-size additive effects, suggesting that the paternal-allele homozygotes (QQ) in these detected SNP loci would increase the number of filled grains. Additionally, there was a pair of positive epistasis interactions (rs645267/rs23681930) detected; and their individual main additive exhibited opposing genetic effects (rs645267 was negative while rs23681930 was positive). For GW, 7 SNPs, all with only additive effects, were found; in aggregate, these QTSs accounted for 48.36% of phenotypic variation. Of particular note, the SNP located on chromosome 3 (rs18572583) contributed 15.19% of the phenotypic variation and should thus be considered to be a very important candidate locus for subsequent breeding efforts.
Conditional association mapping for GYD given its component trait
All significant QTSs with additive effects for yield conditioned on each of its components are presented in Table 4. There were 10, 7, and 5 QTSs detected, respectively, for yield conditioned on number of panicles (GYD|NP), yield conditioned on number of filled grains per panicle (GYD|NFGP), and yield conditioned on grain weight (GYD|GW). For GYD|NP, two QTSs (rs8203251 and rs26302731) were remained to be detected and eight novel conditional QTSs were identified in comparison with unconditional yield mapping (Tables 3 and 4). For the two overlapping QTSs, rs26302731 was supposed to be independent upon NP, as there was no significant difference in additive effects in the 95% confidence interval between unconditional and conditional mapping (data not shown), while rs8203251 was supposed to be involved in variation of NP as the additive by environment interaction failed to be detected in the conditional mapping (Fig. 2), even though the additive main effect was still similar. The eight novel conditional QTSs exhibited modest-sized effects, with individual contributions to phenotypic variation ranging from 2.31% to 6.58%. Similar results were observed for GYD|NFGP; most detected QTSs (5 out of 7) were novel loci that were supposed to be suppressed by the given component trait in the unconditional mapping results. This might be true because the conditional analysis could exclude the impact of the given component trait on the target trait and thus reveal the genes masked by an antagonist or repressor in the component trait. A different phenomenon was observed in GYD|GW mapping that only a small number of additional QTSs (2 SNPs) which were supposed to be suppressed by grain weight was detected. The small number of novel QTSs in the GYD|GW mapping may mainly result from the counterbalance between the two remaining components and partly from the relatively weak correlation between grain yield and grain weight. These results at the molecular level showed good agreement with those obtained using genotypic or phenotypic correlation analysis.
Comparing the results of the unconditional and conditional association mapping for GYD (Table 4 and Fig. 2), three possible scenarios were evident : (1) An unconditional QTS was still detected under conditional mapping, generally with some fluctuation in genetic effect size, indicating this particular QTS was independent of (i.e., no significant difference in genetic effect size between unconditional and conditional mapping), or was partially correlated with, the corresponding given component trait; (2) A previously-detected unconditional QTS was totally absent under conditional mapping, suggesting that this QTS may be associated with the final grain yield through the corresponding given conditional component trait; (3) Some novel QTSs were detected under conditional mapping, suggesting that these QTSs might have been suppressed by the corresponding given component trait in the unconditional mapping analysis. As shown in Table 4, the rs8203251 locus was the only locus detected in the unconditional mapping and in all three of the conditional mappings; it seemed to be partially-correlated with NP and NFGP but independent of GW, as the difference in genetic effects was not significant (data not shown). Three QTSs were detected both in the unconditional mapping and at least one conditional mapping: rs26302731 was independent of NP but had high correlations with both NFGP and GW; rs17926420 was independent of both NFGP and GW but was highly correlated with NP; rs26662491 was independent of GW but had high correlations with both NP and NFGP. Two QTSs, rs5137246 and rs12354751, were totally absent in the three conditional mappings, suggesting they were highly correlated with the three component traits simultaneously. There was also a batch of novel QTSs associated with GYD that were detected through different conditional mappings. As shown in Table 4, in general, these novel QTSs did not exhibit a large effect size and were likely suppressed by some other QTSs associated with the other traits.
Bioinformatics analysis for candidacy of genes
According to the latest version of rice genome annotation (MSU Rice Genome Annotation Project Release 7, http://rice.plantbiology.msu.edu/index.shtml), of the 39 significantly QTSs detected for yield traits from the unconditional and conditional mapping, 18 QTSs were located within known annotated genes (Table 5). Five of these were identified simply as genes encoding hypothetical proteins or expressed proteins. The remaining genes were found to encode particular enzymes, domains, transcription factors, and transposon or retrotransposon proteins, which might function in important roles in plant development. For instance, the LOC_Os06g43680 gene harboring the QTS rs26302731 associated with grain yield (detected both by conditional and unconditional mapping) putatively encodes the palmitoyltransferase TIP1, which was revealed by prior studies16, 17 to be involved in a number of processes including root hair and pollen tube growth in Arabidopsis. Another conditional QTS, rs3063720, is located in the LOC_Os10g06030 gene. This gene encodes a rice wall-associated kinase (OsWAK) that is known to play a critical role in communication between the plant cell wall and the cytoplasm18 and has been shown via functional studies in Arabidopsis to be involved in various functions such as cell expansion19, 20. The QTS rs28989077 associated with NP is located in the LOC_Os03g50780 gene, which encodes a protein containing a PHD finger domain. PHD finger domains are thought to play an important role in the regulation of chromatin or transcription21, 22. SNP rs20829501 is another NP-associated QTS in the LOC_Os07g34770 gene. A previous study23 reported that the function of LOC_Os07g34770 may relate to rice seed dormancy, but evidence for its possible association with NP is, to our knowledge, new in the literature. In addition, the rest of the detected QTSs that are not located in known genes but they are near some sensible genes. For instance, rs41315645, found in our study to be related to filled-grain numbers, is located ~12 kb downstream of the LOC_Os01g71310 gene, which exhibits the same gene function as the known cloned gene Gn1a (MSU: LOC_Os01g10110, http://www.ricedata.cn/gene/). Gn1a encodes a cytokinin oxidase/dehydrogenase that degrades bioactive cytokinins; and reduced expression of Gn1a can lead to the accumulation of cytokinins and thus increase the number of grains24.
Discussion
In the last decade, genome-wide association method have been a primary tool for dissecting complex traits, especially for human diseases. Such methods have also become appealing and affordable in plant research programs owing to dramatically-reduced costs for genomic technology services. Even though genome-wide association studies (GWASs) have led to some promising scientific discoveries, they have encountered the ‘missing heritability’ problem. This refers to the situation where identified genetic variants (mainly SNPs) only explain a small proportion of the expected heritability estimated from classical pedigree analyses. It has been suggested that the failure to evaluate genetic interactions (epistasis, gene-by-environment interactions) is a reasonable explanation for this phenomenon25, 26. In this study, a saturated model based on a mixed linear model approach was adopted to identify additive, additive by additive epistasis, and their interactions with environment effects simultaneously. Gene-by-environment interactions were detected for GYD (Table 3), which might partly account for the significant differences for mean of grain yield in the two environments that we observed in our phenotypic analysis (Table 1). There was also one pair of epistasis detected separately for NP and NFGP, which is consistent with the inference from the phenotypic distribution analysis that the non-normal distribution implied the existence of non-additive effects. Even though the genetic interactions did not contribute to a large degree of heritability (~2.0%) in this study, a relatively large total heritability (~45%) was observed for each trait. This large heritability might result from our use of controlled experimental population for association mapping, which compromised the resolution to some extent whereas acquired the advantage of well-controlled population structure and thus increased the explainable heritability. In addition, this study based on the RIL population derived from Xieyou9308 can only reveal part of the genetic basis for its high yield potential because all the RIL lines are theoretically homozygous genotypes and it can hardly address the genetic basis for heterosis which mainly rises from heterozygotes. Thus, for further investigation of the genetic basis for heterosis, the immortalized F2 (IF2) population that is generated from random mating of recombinant inbred (RI) strains would be ideal, since it contains more heterozygous loci as well as more kinds of combination of genes in different positions on genome which are basic requirements for analyzing dominance, dominance-related epistasis effects.
Conditional analysis is another important tool used to increase the extent of explainable heritability in GWAS by identifying additional secondary association signals conditioned on the primary associated signals27,28,29. Here, we adopted this methodology to analyze the genetic interrelationships between rice yield and its three components, and further detected some additional QTSs for final yield by conditioning on its component traits. Grain yield in rice can be viewed as the integration of some quantitative component traits, which, as proposed by Piepho30, can be represented by observed primary characters like number of panicles (NP), number of filled grains (NFGP) and grain weight (GW). This integrated character also complicates the causal gene mapping for final grain yield, especially because of the negative correlations between the components. Thus, it has been thought more effective to dissect its component traits individually, as these probably have simpler genetic control and can exclude the influence of the other components. In this study, we first performed genome-wide association mapping for all four traits separately. There were a total of 24 significant unconditional QTSs detected and the two or three highly significant QTSs for each trait were found to be located within or near annotated genes, most of which are predicted to have functions conceivably associated with target traits (Table 3, Table 5). Although quite high phenotypic correlations were observed between grain yield and some of its components (NP and NFGP), there were no coincident QTSs detected for grain yield and its components. Conditional analysis was conducted to complement our understanding of the relationships between the causal and resultant traits and to reveal some novel candidate loci for yield traits. We found 21 SNPs that significantly affected yield, among which 6 were revealed by the unconditional mapping and 19 by the conditional mapping (Table 4). SNP rs8203251 on chromosome 4 was the only QTS for yield that could be detected without the influence of any individual component. The QTSs rs5137246 and rs12354751 were undetectable in the conditional mapping, which indicates the close correlation between these two loci and yield component traits. 3 QTSs (rs26302731, rs17926420, and rs26662491) could be detected both in conditional and unconditional mapping; the remaining 15 were novel conditional QTSs; 8 of them were located within annotated genes. These results suggested that conditional mapping can help to identify more QTSs for grain yield.
As for practical breeding, we detected some high potential candidates for these yield traits. For grain yield, rs26302731 appears to be a reliable candidate locus due to its high heritability (h 2 = 9.34%) and corresponding gene functional analysis in Arabidopsis, which revealed its regulation role for plant cell growth16. Additionally, the conditional mapping analysis indicated that rs26302731 is supposed to be independent of the panicle number trait. The QTS rs8203251 is another reliable candidate locus, although it was not located in an annotated gene. It is quite special; it is the only QTS found to be independent of all three components and to exhibit a very high heritability (h 2 = 10.91%). The nearest gene to it was LOC_Os04g14620 (715 bp away) that encodes a retrotransposon protein belonging to the Ty3-gypsy subclass. Retrotransposons seemed ubiquitous in our results, as they were associated with all four yield traits (the corresponding QTSs are rs9429313 associated with NP, rs29922937 associated with NFGP, rs18572583 associated with GW and rs28377293 associated with GYD conditioned NFGP as showed in Table 5). The QTSs rs28989077 and rs20829501 are two reliable candidate loci for panicle number; both have high individual heritability (h 2 = 18.54% and h 2 = 11.39%, respectively) and conceivable gene functions as described in candidate gene analysis section. The QTS rs41315645 is highly correlated with filled-grain number (h 2 = 8.16%) and near a gene (~12 kb away and there is no SNP in this gene) that exhibits the same function as the cloned gene Gn1a which has been demonstrated to have a function in influencing grain number24; it should thus be considered a quite reliable candidate for grain number in this population. Novel loci from the conditional mapping also have high potential to be reliable candidates for grain yield along with the analysis of corresponding gene function. For instance, rs3063720 is located in the OsWAK gene; studies in Arabidopsis have shown that this gene functions in cell expansion during plant development19, 20 and thus it is a high potential candidate for breeding.
Methods
Plant Materials and SNP Genotyping
A recombinant inbred line (RIL) mapping population consisting of 138 F13 lines was developed from the super hybrid Xieyou9308 via the single seed descent (SSD) method, with XieqingzaoB (XQZB) (female) as the maintainer line and Zhonghui9308 (ZH9308) (male) as the restorer line. The inbred lines were planted in Lingshui, Hainan province and in Hangzhou, Zhejiang province in 2009, respectively. Four rice yield traits, including grain yield per plant (GYD), panicle number per plant (NP), number of filled-grains per panicle (NFGP), and the weight of 1000 grains (GW) were measured. Based on the mixed linear model approach implemented in the software of QGAStation31, the total genotypic values were predicted for the calculation of genetic correlation between traits. Calculations of the summary statistics of the phenotypic data, as well as analysis of the data distributions and correlation coefficients were performed using the R (v3.2.2) statistical software32.
DNA re-sequencing was conducted at the Beijing Genome Institute (BGI) for the 138 inbred lines with 2X coverage and the parent lines with 10X coverage. The latest version of the Nipponbare sequence was used as the reference genome. Subsequently, sequence alignment was performed between the re-sequencing data and the reference genome using BWA software33. SNPs were identified between the individuals and the reference genome by using SAMtools software34, with settings as follows: base quality ≥30, mapping quality ≥20, and the maximum sequence depth ≤1000. Finally, a total of 701,867 SNPs were identified for the 138 RILs and used in the subsequent association studies. The filtration of SNPs and LD pattern analysis have been demonstrated in our another study35 based on this RIL population. It has shown that the LD decay rate was estimated approximately 1,000 kb on whole genome-wide. It is noteworthy that associations in this population would not be affected by population structure issues, as these progenies are from the same ancestry (the cross of XQZB and ZH9308), and the relatedness among these lines is distributed evenly (r ≈ 0.5 for any two individuals).
Genetic Models and Statistical Analysis
In this study, we adopted a saturated genetic model with additive (a) and additive by additive epistasis (aa) as fixed effects, the environment (e) which is mostly uncontrollable as random effects, and thus their interactions (ae, aae) also as random effects. The genetic model for the phenotypic value of the k-th genotype in the h-th environment (y hk ) can be expressed by the following mixed linear model,
Where, μ is the population mean; a i is the additive effect of the i-th gene (QTS) with coefficient x ik , fixed effect; aa ij is the additive by additive epistasis effect of the i-th QTS and the j-th QTS with coefficient x ik · x jk , fixed effect; e h is the main effect of the h-th environment, random effect; ae hi is the additive by environment interaction effect of the i-th QTS and the h-th environment with coefficient u hik (=x hik ), random effect; aae hij is the interaction effect of the aa ij and the h-th environment with coefficient u hijk (=x hik · x hjk )), random effect; and ε hk is the random residual effect of the k-th line in the h-th environment.
Based on the above mixed linear model, both unconditional and conditional genetic mapping were performed for grain yield and its three components. For conditional association mapping, the conditional phenotypic values of grain yield given its components (T1|T2) were first produced by software of QGAStation 2.031 which implemented the mixed model approach for the conditional analysis of quantitative traits as described by Zhu13, where the T1|T2 means trait 1 conditioned on trait 2. GMDR-GPU36 was then employed for preliminary filtering for both of the association mapping approaches due to the heavy computational burden resulting from the detection of two-dimensional interactions for a very large number of SNPs. During the process, both the single-locus effects and two-loci interaction effects were tested for each trait in each environment using the GMDR-GPU, and the ~400 top candidate SNPs (setting the “-m 400” option in GMDR-GPU) potentially associated with the trait were kept for each chromosome according to their testing accuracy from high to low. Finally, based on the screened SNP subsets, association mappings were conducted for each trait using the mixed linear approach implemented in QTXNetwork37 software. In this procedure, first significant testing for each individual SNP and for all possible SNP pairs were performed using F-test which is permutation-based to control the experiment-wise type I error rate at 0.05, and then stepwise model selection was conducted to pick out the relatively high explanatory significant candidates for the final full model (1). Finally, all the parameters and corresponding standard errors of model (1) were estimated via Markov chain Monte Carlo (MCMC) with 20,000 Gibbs sampler iterations. Based on the estimated genetic component effects (additive, epistasis, and their interaction effects with environment), the heritability of each QTS in each genetic component was calculated and the summation of all detected QTSs for the trait is regarded as the total heritability.
References
Cheng, S. H. et al. Super hybrid rice breeding in china: Achievements and prospects. Journal Of Integrative Plant Biology 49, 805–810, doi:10.1111/j.1672-9072.2007.00514.x (2007).
Liang, Y. S. et al. Mapping of qtls associated with important agronomic traits using three populations derived from a super hybrid rice xieyou9308. Euphytica 184, 1–13, doi:10.1007/s10681-011-0456-4 (2012).
XiHong, S. et al. Dissection of qtls for panicle traits in recombinant inbred lines derived from super hybrid rice, xieyou 9308. Chinese Journal of Rice Science 23, 354–362 (2009).
Wang, H. M. et al. Identification of qrl7, a major quantitative trait locus associated with rice root length in hydroponic conditions. Breeding Science 63, 267–274, doi:10.1270/jsbbs.63.267 (2013).
Mackay, T. F. C., Stone, E. A. & Ayroles, J. F. The genetics of quantitative traits: challenges and prospects. Nature Reviews Genetics 10, 565–577, doi:10.1038/nrg2612 (2009).
Thornsberry, J. M. et al. Dwarf8 polymorphisms associate with variation in flowering time. Nature Genetics 28, 286–289, doi:10.1038/90135 (2001).
Agrama, H. A., Eizenga, G. C. & Yan, W. Association mapping of yield and its components in rice cultivars. Molecular Breeding 19, 341–356, doi:10.1007/s11032-006-9066-6 (2007).
Atwell, S. et al. Genome-wide association study of 107 phenotypes in arabidopsis thaliana inbred lines. Nature 465, 627–631, doi:10.1038/nature08800 (2010).
Huang, X. H. et al. Genome-wide association studies of 14 agronomic traits in rice landraces. Nature Genetics 42, 961–U76, doi:10.1038/ng.695 (2010).
Kump, K. L. et al. Genome-wide association study of quantitative resistance to southern leaf blight in the maize nested association mapping population. Nature Genetics 43, 163–U120, doi:10.1038/ng.747 (2011).
Zhao, K. et al. Genome-wide association mapping reveals a rich genetic architecture of complex traits in oryza sativa. Nat Commun 2, 467, doi:10.1038/ncomms1467 (2011).
Huang, X. H. et al. Genome-wide association study of flowering time and grain yield traits in a worldwide collection of rice germplasm. Nature Genetics 44, 32–U53, doi:10.1038/ng.1018 (2012).
Zhu, J. Analysis of conditional genetic-effects and variance-components in developmental genetics. Genetics 141, 1633–1639 (1995).
Guo, L. B. et al. Dissection of component qtl expression in yield formation in rice. Plant Breeding 124, 127–132, doi:10.1111/j.1439-0523.2005.01093.x (2005).
Cao, G. & Zhu, J. Conditional genetic analysis on quantitative trait loci for yield and its components in rice. Life Sci J 4, 71–76 (2007).
Hemsley, P. A., Kemp, A. C. & Grierson, C. S. The tip growth defective1 s-acyl transferase regulates plant cell growth in arabidopsis. Plant Cell 17, 2554–63, doi:10.1105/tpc.105.031237 (2005).
Hemsley, P. A. Protein s-acylation in plants (review). Mol Membr Biol 26, 114–25, doi:10.1080/09687680802680090 (2009).
Kohorn, B. D. Waks; cell wall associated kinases - commentary. Current Opinion In Cell Biology 13, 529–533, doi:10.1016/S0955-0674(00)00247-7 (2001).
Lally, D., Ingmire, P., Tong, H. Y. & He, Z. H. Antisense expression of a cell wall-associated protein kinase, wak4, inhibits cell elongation and alters morphology. Plant Cell 13, 1317–1331, doi:10.1105/TPC.010075 (2001).
Wagner, T. A. & Kohorn, B. D. Wall-associated kinases are expressed throughout plant development and are required for cell expansion. Plant Cell 13, 303–318, doi:10.1105/tpc.13.2.303 (2001).
Aasland, R., Gibson, T. J. & Stewart, A. F. The phd finger - implications for chromatin-mediated transcriptional regulation. Trends In Biochemical Sciences 20, 56–59, doi:10.1016/S0968-0004(00)88957-4 (1995).
Bienz, M. The phd finger, a nuclear protein-interaction domain. Trends In Biochemical Sciences 31, 35–40, doi:10.1016/j.tibs.2005.11.001 (2006).
Qin, H. D. et al. Transcriptomics analysis identified candidate genes colocalized with seed dormancy qtls in rice (oryza sativa l.). Journal Of Plant Biology 53, 330–337, doi:10.1007/s12374-010-9120-0 (2010).
Ashikari, M. et al. Cytokinin oxidase regulates rice grain production. Science 309, 741–5, doi:10.1126/science.1113373 (2005).
Hemani, G., Knott, S. & Haley, C. An evolutionary perspective on epistasis and the missing heritability. Plos Genetics 9, e1003295, doi:10.1371/journal.pgen.1003295 (2013).
Haig, D. Does heritability hide in epistasis between linked snps? European Journal of Human Genetics 19, 123–123, doi:10.1038/ejhg.2010.161 (2011).
Ripke, S. et al. Genome-wide association study identifies five new schizophrenia loci. Nature Genetics 43, 969–U77, doi:10.1038/ng.940 (2011).
Psychiatric, G. C. B. D. W. G. Large-scale genome-wide association analysis of bipolar disorder identifies a new susceptibility locus near odz4. Nat Genet 43, 977–83, doi:10.1038/ng.943 (2011).
Yang, J. et al. Conditional and joint multiple-snp analysis of gwas summary statistics identifies additional variants influencing complex traits. Nature Genetics 44, 369–U170, doi:10.1038/ng.2213 (2012).
Piepho, H.-P. A simple procedure for yield component analysis. Euphytica 84, 43–48, doi:10.1007/BF01677555 (1995).
Chen, G. B., Zhu, Z. X., Zhang, F. T. & Zhu, J. Quantitative genetic analysis station for the genetic analysis of complex traits. Chinese Science Bulletin 57, 2721–2726, doi:10.1007/s11434-012-5108-0 (2012).
Team, R. C. R: A language and environment for statistical computing. R Foundation for Statistical Computing Vienna, Austria, URL https://www.R-project.org/ (2015).
Li, H. & Durbin, R. Fast and accurate short read alignment with burrows-wheeler transform. Bioinformatics 25, 1754–1760, doi:10.1093/bioinformatics/btp324 (2009).
Li, H. et al. The sequence alignment/map format and samtools. Bioinformatics 25, 2078–2079, doi:10.1093/bioinformatics/btp352 (2009).
Zhou, L. et al. Dissection of genetic architecture of rice plant height and heading date by multiple-strategy-based association studies. Scientific Reports 6 (2016).
Zhu, Z. X. et al. Development of gmdr-gpu for gene-gene interaction analysis and its application to wtccc gwas data for type 2 diabetes. Plos One 8 (2013).
Zhang, F.-T. et al. Mixed linear model approaches of association mapping for complex traits based on omics variants. Scientific Reports (2015).
Acknowledgements
This study was supported in part by the project of the National Sci-Tech Support Plan (2011BAD35B02), the Major Sci-Tech Programs of Zhejiang Province (2012C12901-3), the National Natural Science Foundation grants 31101203, 31521064 and 31671570, the National Science Foundation grant DMS1462990, and the Bill and Melinda Gates Foundation Project.
Author information
Authors and Affiliations
Contributions
H.X., S.C. and L.C. conceived the ideas; Y.Z., X.S., D.C., W.W., X.Z., Q.L. and A.Z. conducted the field trials and collected the data; Y.Z. and L.Z. analyzed the data. The manuscript was written by L.Z. and improved by H.X. and X.L.
Corresponding authors
Ethics declarations
Competing Interests
The authors declare that they have no competing interests.
Additional information
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhang, Y., Zhou, L., Shen, X. et al. Genetic dissection of yield traits in super hybrid rice Xieyou9308 using both unconditional and conditional genome-wide association mapping. Sci Rep 7, 824 (2017). https://doi.org/10.1038/s41598-017-00938-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-017-00938-7
This article is cited by
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
