
Abstract
During the onset of the COVID-19 pandemic, the COVIDiSTRESS Consortium launched an open-access global survey to understand and improve individuals’ experiences related to the crisis. A year later, we extended this line of research by launching a new survey to address the dynamic landscape of the pandemic. This survey was released with the goal of addressing diversity, equity, and inclusion by working with over 150 researchers across the globe who collected data in 48 languages and dialects across 137 countries. The resulting cleaned dataset described here includes 15,740 of over 20,000 responses. The dataset allows cross-cultural study of psychological wellbeing and behaviours a year into the pandemic. It includes measures of stress, resilience, vaccine attitudes, trust in government and scientists, compliance, and information acquisition and misperceptions regarding COVID-19. Open-access raw and cleaned datasets with computed scores are available. Just as our initial COVIDiSTRESS dataset has facilitated government policy decisions regarding health crises, this dataset can be used by researchers and policy makers to inform research, decisions, and policy.
Measurement(s) | demographics • social status • identity • perceived stress • loneliness • stressors • support • compliance • social norms • vaccine attitude • vaccine willingness • trust • resilience • conspiratorial thinking • anti-expert sentiment scale (AESS) • moral foundations • emotional regulation |
Technology Type(s) | survey |
Similar content being viewed by others

Background & Summary
The COVIDiSTRESS Global Survey (https://osf.io/2ftma/) was one of the largest studies regarding the global impact of COVID-19 during the initial months of the 2020 pandemic1,2,3. While other large-scale studies regarding the psychological impact of COVID-19 exist, most either focused on specific subsets of the population4 or specific countries5,6,7,8. The COVID-19 Global Survey was translated into 47 languages and administered in 179 countries. The Consortium generated a rich dataset that has resulted in a comprehensive understanding of the global effects of the pandemic1,2. The project highlighted not only the benefits of large-scale data collection using this method9, but also resulted in multiple publications and informed policy decisions within the first year10,11.
The current survey is an extension of the COVIDiSTRESS Consortium project to assess the global impact of COVID-19 approximately one year after the initial survey. This expands research from the initial COVIDiSTRESS Global Survey, in which we found that trust in government is linked to compliance with measures to reduce the impact of COVID-192. Results from the COVIDiSTRESS study have corroborated other recent findings12. We used the same large-scale data collection methods as the initial survey. It was our goal to address questions that were left unanswered in the initial study and include countries that were not previously assessed.
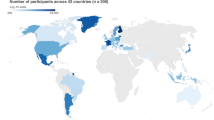
One limitation of the initial study was the inability to collect sufficient data in certain regions. As can be seen in Fig. 1, although the first dataset had impressive global representation, less than 200 responses were received in Russia as well as most countries in Africa and Central Asia. Therefore, these regions became a priority for the second wave of data collection. The present survey for the dataset described here was released with the goals of addressing diversity, equity, and inclusion by working with a diverse group of over 150 researchers across the globe who collaborated to translate the survey into 48 languages and dialects and launched the survey locally in 137 countries.

Map of data collected during the initial COVIDiSTRESS Global Survey. Only countries with more than 200 participants in the original survey are indicated. Image reproduced from Yamada et al. (2021)1, under the Creative Commons Attribution 4.0 International Licence.
In addition to questions about stress, loneliness, and trust in government, we added new items to the dataset to accommodate new policy developments, new information (and misinformation) about COVID-19, and attitudes about the newly released vaccines. Specifically, we collected demographic information and assessed social norms, compliance behaviours, vaccine hesitancy and attitudes, individuals’ stress and resilience, trust in scientists and the healthcare systems, moral values, and information acquisition and misperceptions regarding COVID-19.
This is a large-scale project with multiple hypotheses. Here we describe only the methods and details about the open-access dataset, available through the Open Science Framework. Specific hypotheses and analyses using the survey data will appear in separate publications.
Methods
Participants
A total of 20,601 people from 137 countries accessed an online survey link to respond to questions about their experience with COVID-19 during the summer of 2021. After data cleaning, 15,740 individuals met the inclusion criteria: provided informed consent, 18 or more years of age, passed the attention check, and did not complete the entire survey in under three minutes. The countries represented in the cleaned and raw datasets are portrayed in Fig. 2. For convenience, demographic characteristics for countries with over 200 responses remaining in the cleaned dataset are presented in Table 1.

Map of data collected for the COVIDiSTRESS II Dataset (N = 15,740). Light pink: Countries with 200 or more participants in the cleaned dataset. Medium Pink: Countries with 100 or more, but less than 200 participants in the cleaned dataset. Salmon: Countries with 30 or more, but less than 100 participants in the cleaned dataset. Dark Pink: Countries with less than 30 participants in the cleaned dataset. Dark Red: Countries only with participants in the raw dataset. Note that small countries may not be represented. Map was created by Angélique Blackburn using mapchart.net, an open-access site created by Minas under the Creative Commons Attribution-ShareAlike 4.0 International License, and is published under the same license as the original work.
Participants were recruited through concentrated local efforts by a team of over 150 international researchers, including word of mouth, press releases, TV, email lists, and social media. Data was collected anonymously, and participants volunteered without monetary compensation. All participants reported being over the age of 18. Demographic data, including responses by country, will be discussed below and can be found in Tables 1–5. For ease of comparison, population equivalents have been provided in these tables aside demographic data for the population in this study.
Materials
Survey overview
The full survey in English can be accessed directly at https://osf.io/az7s5/. The full list of variables included in the survey as well as the response options participants used to answer the survey are also available at OSF | COVIDiSTRESS Global Survey - Round II https://osf.io/36tsd/.
This survey contains a combination of validated scales and modified questions, each of which can be analyzed for relationships with other variables and across countries. The survey was divided into two sections: main variables presented to all participants at the beginning and optional variables in the second half. In this way, participants could opt to exit the survey after the main variables at the end of the first half or continue to the second half of the study. The survey also contained one attention check item to ensure that participants were paying attention.
For the greatest comparability across studies, some variables, the translation process, recruitment, and data collection procedures mirrored the method used for the initial COVIDiSTRESS Global Survey as closely as possible (see https://osf.io/2ftma/)1.
Variables
The survey contained individual items as well as previously validated, modified, and newly-designed scales. A full list of these variables and composite scales can be found with the data files. In brief, the first half of the survey contained demographic information including age, gender, residing country, birth country, education, occupation, work location, study location, relationship status, dependents, living situation with cohabiting adults and/or children, whether children were being home schooled, and socioeconomic status. It also contained single items regarding personal experience with COVID-19 and vaccine willingness, as well as the following scales: an adapted MacArthur Scale of Subjective Social Status (SSS-fam)13,14; Identity (4 items adapted from identity categories identified in previous research15,16) the Perceived Stress Scale (PSS-10; 10 items17), Loneliness Scale (SLON-3; 3 items as part of the extended PSS-10), Stressors (18 items, adapted from primary and secondary stress categories18), Perceived Support Scale (3 items adapted from a scale of perceived social support during a natural disaster19), Compliance (8 items adapted from surveys about compliance with measures to reduce the spread of the flu and pandemics15,20), Social Norms (16 items linked to the compliance scale), Vaccine Attitudes (6 items adapted from the Vaccine Attitude Question Battery21), and Trust in institutions including the government, health care, and science (7 items1). The second half of the survey included the Brief Resilience Scale (6 items22, the five item version of the Intolerance of Uncertainty Scale (IUS-5; 5 items23), an 8 item Scale of Information Acquisition Regarding COVID-19 adapted from previous research about popular sources of health information24,25, Misperceptions about COVID-19 (6 items created based on common misperceptions and studies of misperceptions26), the Conspiratorial Thinking Scale (4 items26,27), Anti-Expert Sentiment (3 items created by Consortium experts in the field based on previous research26), 11 items from the Moral Foundations Questionnaire28,29, and the Emotion Regulation Questionnaire (8 items30).
Ethical considerations and diversity, equity, and inclusion in survey creation
The Consortium conducted ethics meetings to ensure that survey questions were culturally and internationally inclusive. Our aim was to create an inclusive survey to capture a diverse population, including individuals from regions underrepresented in the original study. To protect participants and avoid sensitive or potentially damaging information collection, participants were not asked whether they had been diagnosed with COVID-19, whether they had been vaccinated, or other aspects of their medical status. In addition, care was taken during drafting of the survey to ensure that no questions about vaccine attitudes were written as leading questions or in ways that might influence vaccine attitudes. Finally, data collection was anonymous–we did not collect data that would allow identification of participants. Ethical approval for this study was obtained at the University of Salford (UK), as well as local ethical approval where required.
Translation
The survey was translated into 40 languages and adapted to the dialects of different regions, for a total of 48 versions. These languages and dialects with their codes in the related files are as follows: Afrikaans (AF), Arabic (AR), Bulgarian (BG), Bosnian (BS), Czech (CS), Danish (DA), Dari (DAR), German (DE), Greek (EL), English/American (EN-AM), Spanish-Bolivia (ES-BO), Spanish-Colombia (ES-CO), Spanish-Costa Rica (ES-CR), Spanish-Ecuador (ES-EC), Spanish-EU (ES-ES), Spanish-Guatemala (ES-G), Spanish-Honduras (ES-HN), Spanish-Mexico (ES-MX), Spanish-Uruguay (ES-UG), Estonian (ET), Farsi (FA), Finnish (FI), French (FR), Hindi (HI), Indonesian (ID), Italian (IT), Japanese (JA), Korean (KO), Nepali (NE), Dutch (NL), Norwegian (NO), Polish (PL), Portuguese (PT), Portuguese-Brazilian (PT-BR), Russian (RU), Sinhala (SIN), Slovak (SK), Albanian (SQI), Serbian (SR), Montenegrin (SR-ME), Swedish (SV), Swahili-Kenya (SW), Tamil (TA), Turkish (TR), Ukrainian (UK), Urdu (UR), Chinese - Simplified (ZH-S), Chinese - Traditional Taiwan (ZH-T). Translations were completed in teams following the three-step verification WHO method: forward translation from English, back-translation into English, and verification, as explained in the original study9. Whenever possible, a different translator performed each of the three steps.
Data collection
Data was collected in Qualtrics. Links were generated for each language so researchers could use local recruitment methods to distribute the survey in the local language. The survey was launched online in multiple countries simultaneously, with rolling additions as the survey was translated into more languages.
The survey was available from the 10th of June to the 22nd of August 2021, with the following extensions. Active data collection in Russia opened from May 28, 2021 through May 31, 2021, due to a need to collect the data in these countries before government restrictions regarding collection changed and active collection occurred in Uganda from May 29th, 2021 through June 30th, 2021 due to local team availability. Both Russia and Uganda were still open for participants throughout the main survey, however active data collection had ceased. Collection in Colombia and Sweden continued through August 29, 2021, for local ethical and team availability reasons. As such, the data is categorized as Russia/Uganda, Sweden/Colombia, and Main Dataset. All data was merged in the final dataset (https://osf.io/36tsd/).
Data Records
Data files
All data files can be found online at the Open Science Framework: OSF | COVIDiSTRESS Global Survey - Round II, under Final Data set [cleaned] COVIDiSTRESS II31. This folder contains a copy of the survey and author list. Along with a “Data used for cleaning” subfolder containing the three raw data files separated according to data collection dates and extensions (with corresponding files containing the numerical version of the data rather than choice text), we have provided a final cleaned data subfolder in which all raw data has been merged, invalid cases were excluded, and the data scales were re-coded. The first final cleaned file containing all data, “Final_COVIDiSTRESS_Vol2_Cleaned.csv,” is the primary file described herein; an additional file cleaned for SPSS is also contained in this folder. The R code used to clean the data is also available in the Codebook subfolder.
A separate folder for weekly data uploads comprises all raw data as collected each week throughout the study. The data collection registration files contain information about available translations and a detailed list of the measured variables with relevant notes about individual items and scale creation. Researchers may find it easiest to use the measured variables document in conjunction with the copy of the survey to obtain items for each variable of interest.
As most researchers will be interested in the Final COVIDiSTRESS Cleaned datafile, this file is described in more detail throughout this descriptor. This file contains the cleaned output of the Qualtrics survey with columns representing output in the order of the survey presentation, with additional columns at the end for calculated values as described in the Codebook and below. One row of data is available for each participant who was not excluded. It should be noted that all real, consenting participants are included in this file as long as they passed the attention check and participated for more than three minutes. Pilot subjects and excluded participants were removed as described below. Thus, while the technical validation performed here highlights countries with larger samples, researchers can access and use data for any valid participants based on their research design.
Data cleaning
Both individual items and composite scores are present in the final cleaned dataset. Composite scores were calculated using the mean value for individual items. It should be noted that in some cases where validated scales were used, the scoring might differ from that in the original publications. In addition, use of composite scores is only justified once measurement invariance is achieved; while this information has been provided to allow researchers to determine useful variables for further analyses, further scale validation is critical.
Corrections were made to the raw dataset as follows:
-
Data sets were combined to include those with extensions and the time zone was set to UTC. Columns were converted from character to numeric formats.
-
Text responses were replaced with numeric values for Likert-type items.
-
We filtered out cases without consent, test cases (100 cases), cases accessed through the preview link (4 cases), cases in which the respondent failed the attention check (1659 cases), and cases in which participants completed the survey in less than three minutes (but retained those who did not complete the survey).
-
Data was recoded to align with the original scoring in previous studies. In particular, the Trust Scale was recoded from percentages to a 0–10 scale. The Perceived Stress Scale was recoded to a scale from 0–4.
-
For the following items and scales, a neutral option was included on the survey: Vaccine Willingness, Identity, Perceived Support, Vaccine Attitudes, Emotions, and Moral Values. We created two versions for each of these scales and items–one with neutrals coded as 0 and the other with neutrals coded as the middle point of the response scale. Any composite scores were averaged after recoding individual items.
-
“Not Applicable” (NA) responses to certain questions (numerical value = 99) were recoded in a separate column as NAppl (Not applicable) in order to store information about those who selected this option, as it is different from truly missing data. This applied to the stressors, social influence, and compliance items.
-
Mean composite scores were calculated for the following variables:
-
Perceived Stress Scale (PSS-10): Four items were reverse scored (items 4, 5, 7, and 8) and a mean of 10 items was calculated.
-
Perceived Loneliness Scale (SLON-3): The scale was initially coded as an extension of the PSS-10 scale. For clarity, the items were renamed from perceived_stress_sca_11 through perceived_stress_sca_13 to Scale_SLON_1 through Scale_SLON_3 and averaged.
-
Perceived Support Scale (PSUP-3): Three items were averaged. Two versions of this composite were calculated with neutrals coded both as zero and as midpoints on the scale.
-
Vaccine Attitudes Scale: Two items were reverse scored (items 4 and 5) and six items were averaged; two versions of this composite were calculated with neutrals coded both as zero and as midpoints on the scale.
-
Resilience Scale: Three items were reverse scored (items 2, 4 and 6) and all six items were averaged.
-
Uncertainty: Five items were averaged.
-
Technical Validation
Given that this is a large-scale survey distributed by numerous researchers all over the world, we had limited control over the total number of responses per country. In line with the first COVIDiSTRESS Global Survey project, in order to be considered for country-level analyses, a country needed at least 30 respondents for detecting both the effects of individual- and country-level predictors. In addition, a goal of 200 participants per country was set. The sample size considerations mirrored the first COVIDiSTRESS global survey project and were based on power simulation results for required sample size and group size to detect such effects with 80% statistical power32.
In order to be considered as a valid participant for the present analyses by country, a respondent must have reported their country of residence and submitted valid responses for the variables treated in each analysis. For inclusion in global analyses of a given variable, the participant only needed to submit valid responses for that variable. Participants were included in descriptive analyses for a given survey if they answered questions on that survey. If they selected a not applicable (NA) option for some items, these items were not included in their individual average. For reliability analyses, participants were only included if they answered all items on a given scale. Reliability testing was only performed for scales in which participants all received identical items. Items on the misperceptions and social norms scales were randomly selected from matched blocks of questions, so reliability testing was not conducted for these scales. Convergent validity will be further tested in follow-up pre-registered hypotheses tests of correlations between related variables.
For all composite scores used for this technical validation, neutral values were retained as the midpoint of the scale where they existed in the previous survey. After data cleaning and scale-wise exclusion of participants who did not complete any items on a given scale, additional scale composites were calculated in MS Excel/SPSS.
Demographic characteristics
Data was collected from 137 countries, presented in Fig. 2 and coded according to the number of participants. A total of 28 countries had more than 200 participants, and 63 countries had more than 30 participants. After data cleaning, a total of 120 countries were represented with 25 countries each containing greater than 200 participants, 35 countries with over 100 participants, and 54 countries with more than 30 participants. The number of responses for both raw and cleaned data for countries with 30 or more participants are presented in Supplementary Table 1. Henceforth, all analyses are presented for the cleaned dataset only. Demographic information and response rate characteristics are presented for countries with more than 200 participants in Tables 1 through 5. Response rates are presented in Table 1. The following characteristics have been assessed by country: age and gender (Table 2), education (Table 3), marital status (Table 4), and COVID-19 history (Table 5). Additional demographic information can be obtained from the cleaned dataset.
We recognize that this dataset is not fully generalizable to all populations. It is important to note that this study was conducted as an expansion in the scope of the initial COVIDiSTRESS study (https://osf.io/z39us/)1 with the goal of reaching participants in underrepresented areas of the initial COVIDiSTRESS study: Russia, Africa, and Central Asia. There were over 200 respondents from Africa, 254 from Kyrgyzstan, and 2260 from Russia.
Composite scoring and reliability testing of scales
Descriptive statistics and reliability testing for all scales combined across all countries are presented in Table 6. Cronbach’s alpha33 was calculated for each scale and determined to be unacceptable below 0.6, low but reliable from 0.6 to 0.7, respectable between 0.7 and 0.8, and good above 0.8, as is customary34,35,36 and recommended for maximal internal consistency of survey items without redundancy37,38. All scales have respectable internal reliability (Cronbach’s alpha > 0.7) for the full sample, except Moral Values (in which all subscales were combined, naturally reducing Cronbach’s alpha) and primary stressors, both of which neared 0.7 (0.694 and 0.689, respectively; Fig. 3). While a Cronbach’s alpha value below 0.7 would be expected for scales that are not unidimensional35, further factor analyses are recommended before using these two scales.

Reliability Values for Each Scale. Overall Cronbach’s alpha values for each survey are represented for the full dataset for each scale. Values for countries with N > 200 are represented on the z-axis to exhibit reliability across sub-samples.
COM_Identity_4
The composite score for the Identity Scale was computed by averaging the four Identity items pertaining to identifying with family, local community, one’s country, and humanity. The basic descriptive statistics of the Identity Scale are summarized in Table 7. Specifically, 15,549 respondents completed this survey (98.8% of the participants). The composite scale score ranges from 1 to 7, with a mean value of 4.83 (SD = 1.12). The internal consistency of the scale, as measured by Cronbach’s alpha is 0.740 and ranges from 0.608 to 0.819.
COM_Primary_Stressors_4
The composite score for the Primary Stressors Scale was computed by averaging 4 items pertaining to primary stressors related to the participant or their family members catching COVID-19, as well as the ability to travel and meet with friends and family. The basic descriptive statistics of the Primary Stressors Scale are summarized in Table 8. Specifically, 15,549 respondents completed this survey with valid responses (98.8% of the participants). The composite scale score ranges from 0 to 4, with a mean value of 1.88 (SD = 1.02). Because respondents were presented with a not applicable option, only those who answered all questions with numerical responses (N = 14,842; 94.3% of participants) were included in the reliability analysis. The internal consistency of the scale, as measured by Cronbach’s alpha is 0.689 and ranges from 0.530 to 0.747.
COM_Secondary_Stressors_14
The composite score for the Secondary Stressors Scale was computed by averaging 14 items pertaining to secondary stressors related to COVID-19’s impact on work, finances, education, relationships, and safety. Four of these items were presented to all participants, and the remainder were conditionally presented based on demographic information. The basic descriptive statistics of the Secondary Stressors Scale are summarized in Table 9. Specifically, 10,516 respondents completed this survey with valid responses (66.8% of the participants). The composite scale score ranges from 0 to 4, with a mean value of 1.44 (SD = 1.00). Because respondents were presented with a not applicable option, only those who answered all questions with numerical responses on the Likert scale (N = 9183; 58.3% of participants) were included in the reliability analysis. The internal consistency of the scale, as measured by Cronbach’s alpha is 0.729 and ranges from 0.540 to 0.805.
COM_PSUP_3
The composite score for the Perceived Support Scale (PSUP-3) was computed by averaging the three items regarding support networks. The basic descriptive statistics of the scale are summarized in Table 10. Specifically, 15,690 respondents completed this survey (99.7% of the participants). The composite scale score ranges from 1 to 7, with a mean value of 5.05 (SD = 1.44). The internal consistency of the scale, as measured by Cronbach’s alpha is 0.861 and ranges from 0.739 to 0.935.
COM_Compliance
The composite score for the Compliance Scale was computed by averaging 8 items pertaining to compliance with guidelines to reduce the spread of COVID-19. The basic descriptive statistics of the Compliance Scale are summarized in Table 11. Specifically, 15,530 respondents completed this survey with valid responses (98.7% of the participants). The composite scale score ranges from 1 to 7, with a mean value of 5.26 (SD = 1.08). Because respondents were presented with a not applicable option, only those who answered all questions with numerical responses (N = 12,099; 76.9%) were included in the reliability analysis. The internal consistency of the scale, as measured by Cronbach’s alpha is 0.741 and ranges from 0.355 to 0.846.
COM_SocialNorms
The Social Influence Norms Scale contained 16 items across two corresponding blocks; 2 items from each block were randomly presented to each participant. To compute the composite score, two items were reverse scored (item 7 from each block) and the 4 items for each participant were averaged. A total of 15,344 respondents completed the survey with valid responses (97.5% of participants). The composite scale score ranges from 1 to 7, with a mean value of 5.17 (SD = 1.38). Descriptive statistics for this scale are summarized in Table 12.
COM_Trust
The composite score for the Trust Scale was computed by averaging seven items pertaining to trust in national government, health and security, scientists, and the World Health Organization. The basic descriptive statistics of the scale are summarized in Table 13. A total of 15,068 respondents completed this survey (95.7% of the participants). The composite scale score ranges from 0 to 10, with a mean value of 5.01 (SD = 2.35). The internal consistency of the scale, as measured by Cronbach’s alpha is 0.901 and ranges from 0.589 to 0.931.
COM_Misperceptions
Six items regarding misperceptions about COVID-19 were divided into 3 blocks, with 1 item randomly presented to participants from each block. Two items were reversed scored (items 1 and 2) and the three presented items were averaged for each participant. The composite score for the Misperceptions Scale was computed by averaging three (of six total) items. The basic descriptive statistics of the scale are summarized in Table 14. A total of 13,099 respondents completed this survey (83.2% of the participants). The composite scale score ranges from 1 to 7, with a mean value of 2.27 (SD = 1.21).
COM_Conspiratorial
The composite score for the Conspiratorial Thinking Scale was computed by averaging four items about conspiratorial thinking. The basic descriptive statistics of the scale are summarized in Table 15. A total of 12,981 respondents completed this survey (82.5% of the participants). The composite scale score ranges from 1 to 7, with a mean value of 3.65 (SD = 1.52). The internal consistency of the scale, as measured by Cronbach’s alpha is 0.845 and ranges from 0.669 to 0.894.
COM_AntiExpert
The composite score for the Anti-Expert Sentiment Scale was computed by averaging three items. The basic descriptive statistics of the scale are summarized in Table 16. A total of 12,939 respondents completed this survey (82.2% of the participants). The composite scale score ranges from 1 to 7, with a mean value of 2.88 (SD = 1.26). The internal consistency of the scale, as measured by Cronbach’s alpha is 0.732 and ranges from 0.412 to 0.783.
COM_MoralValues
The composite score for the Moral Values Scale was computed by averaging 11 items. The basic descriptive statistics of the scale are summarized in Table 17. A total of 12,860 respondents completed this survey (81.7% of the participants). The composite scale score ranges from 1 to 7, with a mean value of 5.06 (SD = 0.76). The internal consistency of the scale, as measured by Cronbach’s alpha is 0.694, and ranges from 0.601 to 0.777. However, it should be noted that all subscales of were combined for this analysis. Separating by subscale according to the original scale28,29 is recommended for future analyses using this data.
COM_EmotionalRegulation
The composite score for the Emotion Regulation Scale was computed by averaging eight items. The basic descriptive statistics of the scale are summarized in Table 18. A total of 12,898 respondents completed this survey (81.9% of the participants). The composite scale score ranges from 1 to 7, with a mean value of 4.36 (SD = 0.95). The internal consistency of the scale, as measured by Cronbach’s alpha is 0.713 and ranges from 0.541 to 0.873.
COM_PSLON_3
The composite score for the Loneliness Scale (SLON-3) was computed by averaging three items of the extended PSS-10 Scale. The basic descriptive statistics of the scale are summarized in Table 19. A total of 15,661 respondents completed this survey (99.5% of the participants). The composite scale score ranges from 0 to 4, with a mean value of 1.61 (SD = 1.09). The internal consistency of the scale, as measured by Cronbach’s alpha is 0.881 and ranges from 0.836 to 0.934.
COM_PSS_10
The composite score for the Perceived Stress Scale (PSS-10) was computed by averaging 10 items about stress in the past month, four of which were reverse scored (items 4, 5, 7, and 8). The basic descriptive statistics of the scale are summarized in Table 20. A total of 15,612 respondents completed this survey (99.2% of the participants). The composite scale score ranges from 0 to 4, with a mean value of 1.87 (SD = 0.69). The internal consistency of the scale, as measured by Cronbach’s alpha is 0.872 and ranges from 0.810 to 0.924.
COM_VaccineAttitudes
The composite score for the Vaccine Attitudes Scale was computed by averaging six items about vaccine hesitancy, after reverse scoring two items (items 4 and 5. The basic descriptive statistics of the scale are summarized in Table 21. A total of 15,293 respondents completed this survey (97.2% of the participants). The composite scale score ranges from 1 to 7, with a mean value of 4.99 (SD = 1.33). The internal consistency of the scale, as measured by Cronbach’s alpha is 0.842 and ranges from 0.256 to 0.900.
COM_Resilience
The composite score for the Brief Resilience Scale was computed by averaging six items about resilience, three of which were reverse scored (items 2, 4 and 6). The basic descriptive statistics of the scale are summarized in Table 22. A total of 13,248 respondents completed this survey (84.2% of the participants). The composite scale score ranges from 1 to 7, with a mean value of 4.34 (SD = 1.24). The internal consistency of the scale, as measured by Cronbach’s alpha is 0.869 and ranges from 0.760 to 0.931.
COM_Uncertainty
The composite score for the Intolerance of Uncertainty Scale (IUS-5) was computed by averaging five items about desire for certainty. The basic descriptive statistics of the scale are summarized in Table 23. A total of 13,202 respondents completed this survey (83.9% of the participants). The composite scale score ranges from 1 to 5, with a mean value of 2.77 (SD = 0.81). The internal consistency of the scale, as measured by Cronbach’s alpha is 0.734 and ranges from 0.558 to 0.827.
Usage Notes
We recommend that any interested researchers use the cleaned version of data (available at https://osf.io/36tsd/ under the CC-By Attribution 4.0 International license). Before using the dataset, we recommend consulting the R codebook and accompanying measured variables list. Variables can be used individually or with the calculated composites. To identify individuals from a specific country, the variable, ‘residing_country,’ should be used.
Composite scores were obtained for some variables using means, but it should be noted that for some validated scales used in this survey, other methods of computation were indicated in the original publications. Therefore, the raw dataset is available so that these scales can be recalculated as needed. In the raw data, a value of 99 means that the item does not apply for that individual; this distinction between not applicable and missing data has been preserved in the cleaned dataset in columns containing the extension “NAppl.” Neutral values were also added to some scales. Composite scores were calculated by coding neutral responses both as midpoint values (as presented in the survey) and as zero value responses. This was for the convenience of researchers using the data, but it should be noted that all technical validations were performed on data with neutrals coded as midpoints–as they were presented to participants.
Due to snowball and convenience sampling methods, the samples in the present dataset are not fully representative of the population in each country. To address this issue, we recommend selection of participants for analysis using a stratified quota sampling method in which data is weighted by the demographics of each country being analysed. For more information on this method, please refer to the original COVIDiSTRESS Global Survey descriptor1.
It should be noted that whenever possible, the same methods, variables, and coding were used in this study as in the first COVIDiSTRESS Global Survey study to facilitate comparisons across studies. In addition, the original dataset was lacking data from some regions, so concentrated efforts were made to recruit participants from areas that were underrepresented in the first survey. That said, while some of the scales were used in both studies, the full set of scales administered in this study differed from the COVIDiSTRESS Global Survey in 2020 in order to address the changing landscape of the pandemic (e.g., adding sections about vaccine hesitancy). Because both the scale and the participants differed across COVIDiSTRESS studies, these datasets can be compared, but we recommend caution when combining data across surveys.
Code availability
The data cleaning notebook and list of variables can be obtained freely here: https://doi.org/10.17605/OSF.IO/36TSD31. The data was imported and cleaned using the R software qualtRics, data.table, tidyverse, and multicon. Before analysing the data, it should be noted that invalid cases were excluded and the response options for some variables were recoded to numeric values measuring the degree of agreement (see data cleaning above for details). In some of these options, a neutral value was added to the response options and scored in two different ways. For data quality reasons, we also employed an attention check and filtered data in regard to this check.
Change history
04 January 2023
A Correction to this paper has been published: https://doi.org/10.1038/s41597-022-01896-0
References
Yamada, Y. et al. COVIDiSTRESS Global Survey dataset on psychological and behavioural consequences of the COVID-19 outbreak. Sci. Data 8, 1–23, https://doi.org/10.1038/s41597-020-00784-9 (2021).
Lieberoth, A. et al. Stress and worry in the 2020 coronavirus pandemic: relationships to trust and compliance with preventive measures across 48 countries in the COVIDiSTRESS global survey. R. Soc. Open Sci. 8, 200589, https://doi.org/10.1098/rsos.200589 (2021).
COVIDiSTRESS Consortium. COVIDiSTRESS global survey. Open Science Framework, https://doi.org/10.17605/OSF.IO/Z39US (2020).
Schuster, C. et al. Responding to COVID-19 through surveys of public servants. Public. Adm. Rev. 80, 792–796, https://doi.org/10.1111/puar.13246 (2020).
Lim, J. M. et al. Population anxiety and positive behaviour change during the COVID-19 epidemic: Cross-sectional surveys in Singapore, China and Italy. Influenza and other Respir. Viruses 15, 45–55, https://doi.org/10.1111/irv.12785 (2021).
Aran, M. A., Aktakke, N., Kibar, Z. S. & Üçkardeşler, E. How to assess the child poverty and distributional impact of COVID-19 using household budget surveys: An application using Turkish data. Eur. J. Dev. Res. https://doi.org/10.1057/s41287-021-00451-8 (2021).
Wise, J. Covid-19: Surveys indicate low infection level in community. BMJ (Clinical Res. Ed.) 369, m1992, https://doi.org/10.1136/bmj.m1992 (2020).
Willie, M. M. & Skosana, E. COVID-19 Vaccines Report Medical Schemes Member Survey Policy, Research and Monitoring Council for Medical Schemes (2021).
Yamada, Y. et al. Remarks on rapid, remote international collaborations under lockdown. Nature, Research Data at Springer (2021).
Yamada, Y. et al. COVIDiSTRESS: One of the world’s largest consortia of researchers for investigating psychological, social, and behavioral consequences of the COVID-19 pandemic. Nature, Research Data at Springer (2021).
Den Faglige Referencegruppe Nationalt Varslingssystem til Risikovurdering og Tiltag til Håndtering af COVID-19. Vurdering Vedrørende Genåbning fra Faglig Referencegruppe til COVID-19 Nationalt Varslingssystem. (2021).
Tyson, A., Johnson, C. & Funk, C. U.S. public now divided over whether to get COVID-19 vaccine. (2020).
Goodman, E. et al. Adolescents’ perceptions of social status: development and evaluation of a new indicator. Pediatrics 108, E31, https://doi.org/10.1542/peds.108.2.e31 (2001).
Adler, N. E., Epel, E. S., Castellazzo, G. & Ickovics, J. R. Relationship of subjective and objective social status with psychological and physiological functioning: preliminary data in healthy white women. Health Psychol. 19, 586–592, https://doi.org/10.1037//0278-6133.19.6.586 (2000).
Vignoles, V. L., Jaser, Z., Taylor, F. & Ntontis, E. Harnessing shared identities to mobilize resilient responses to the COVID-19 pandemic. Political Psychol. 42, 817–826, https://doi.org/10.1111/pops.12726 (2021).
Postmes, T., Haslam, S. A. & Jans, L. A single-item measure of social identification: reliability, validity, and utility. Br. J. Soc. Psychol. 52, 597–617, https://doi.org/10.1111/bjso.12006 (2013).
Cohen, S., Kamarck, T. & Mermelstein, R. A global measure of perceived stress. J. Health Soc. Behav. 24, 385–396, https://doi.org/10.2307/2136404 (1983).
Lock, S. et al. Secondary stressors and extreme events and disasters: a systematic review of primary research from 2010-2011. PLoS Curr.4, https://doi.org/10.1371/currents.dis.a9b76fed1b2dd5c5bfcfc13c87a2f24f (2012).
Kaniasty, K. & Norris, F. H. In search of altruistic community: patterns of social support mobilization following Hurricane Hugo. Am. J. Community Psychol. 23, 447–477, https://doi.org/10.1007/bf02506964 (1995).
Rubin, G. J. et al. The design of a survey questionnaire to measure perceptions and behaviour during an influenza pandemic: the Flu TElephone Survey Template (FluTEST). (NIHR Journals Library, 2014).
Guess, A. M., Nyhan, B., O’Keeffe, Z. & Reifler, J. The sources and correlates of exposure to vaccine-related (mis)information online. Vaccine 38, 7799–7805, https://doi.org/10.1016/j.vaccine.2020.10.018 (2020).
Smith, B. W. et al. The brief resilience scale: assessing the ability to bounce back. Int. J. Behav. Med. 15, 194–200, https://doi.org/10.1080/10705500802222972 (2008).
Bottesi, G. et al. A short-form version of the Intolerance of Uncertainty Scale: Initial developmetn of the IUS-5. https://doi.org/10.31234/osf.io/b62wf (2020).
Brown-Johnson, C. G. et al. Trust in health information sources: Survey analysis of variation by sociodemographic and tobacco use status in Oklahoma. Public Health Surveill. 4, e8, https://doi.org/10.2196/publichealth.6260 (2018).
Plaster, A. N., Painter, J. E., Tjersland, D. H. & Jacobsen, K. H. University students’ knowledge, attitudes, and sources of information about Zika Virus. J. Community Health 43, 647–655, https://doi.org/10.1007/s10900-017-0463-z (2018).
Uscinski, J. E. et al. Why do people believe COVID-19 conspiracy theories? The Harvard Kennedy School (HKS) Misinformation Review https://doi.org/10.37016/mr-2020-015 (2020).
Uscinski, J. E., Klofstad, C. & Atkinson, M. D. What drives conspiratorial beliefs? The role of informational cues and predispositions. Political Res. Q. 69, 57–71, https://doi.org/10.1177/1065912915621621 (2016).
Graham, J. et al. Mapping the moral domain. J. Pers. Soc. Psychol. 101, 366–385, https://doi.org/10.1037/a0021847 (2011).
Graham, J., Haidt, J. & Nosek, B. A. Liberals and conservatives rely on different sets of moral foundations. J. Pers. Soc. Psychol. 96, 1029–1046, https://doi.org/10.1037/a0015141 (2009).
Balzarotti, S. The emotion regulation questionnaire: Factor structure and measurement invariance in an Italian sample of community dwelling adults. Current Psychology, https://doi.org/10.1007/s12144-019-00426-3 (2019).
COVIDiSTRESS Consortium II. COVIDiSTRESS Global Survey - Round II. Open Science Framework https://doi.org/10.17605/OSF.IO/36TSD (2021).
Arend, M. G. & Schäfer, T. Statistical power in two-level models: A tutorial based on Monte Carlo simulation. Psychol. Methods 24, 1–19, https://doi.org/10.1037/met0000195 (2019).
Cronbach, L. J. Coefficient alpha and the internal structure of tests. Psychometrika 16, 297–334 (1951).
Blackburn, A. M. A Study of the Relationship between Code Switching and the Bilingual Advantage: Evidence that language use modulates neural indices of language processing and cognitive control Ph.D. Neurobiology thesis, University of Texas at San Antonio, (2013).
Taber, K. S. The use of Cronbach’s Alpha when developing and reporting research instruments in science education. Res. Sci. Edu. 48, 1273–1296, https://doi.org/10.1007/s11165-016-9602-2 (2018).
Gierveld, J. D. J. & Tilburg, T. V. A 6-item scale for overall, emotional, and social loneliness: Confirmatory tests on survey data. Res.Aging 28, 582–598, https://doi.org/10.1177/0164027506289723 (2006).
DeVellis, R. F. Scale Development: Theory and Applications. Second edn, (SAGE Publications, 2003).
Nunnally, J. C. Psychometric theory. 2nd edn, (McGraw-Hill, 1978).
United Nations, Department of Economic and Social Affairs, Population Division. World Population Prospects 2019: Volume II: Demographic Profiles. (2019).
The World Bank. World Development Indicators, Population, female (% of total population). https://data.worldbank.org/indicator/SP.POP.TOTL.FE.ZS (2019).
UNESCO Institute for Statistics. The World Bank. Educational attainment, at least completed upper secondary, population 25+, total (%) (cumulative), https://data.worldbank.org/indicator/SE.SEC.CUAT.UP.ZS (2021).
Barro, R. & Lee, J.-W. A New Data Set of Educational Attainment in the World, 1950-2010. Journal of Development Economics 104, 184–198 (2013).
Ortiz-Ospina, E. & Roser, M. Marriages and Divorces, https://ourworldindata.org/marriages-and-divorces (2020).
Dong, E., Du, H. & Gardner, L. An interactive web-based dashboard to track COVID-19 in real time. The Lancet Infectious Diseases 20, 533–534, https://doi.org/10.1016/S1473-3099(20)30120-1 (2020).
Ritchie, H. et al. Coronavirus Pandemic (COVID-19), https://ourworldindata.org/coronavirus (2020).
Acknowledgements
The COVIDiSTRESS Consortium would like to acknowledge the contributions of friends and collaborators in translating and sharing the COVIDiSTRESS survey, as well as the study participants. Data analysis was supported by Texas A&M International University (TAMIU) Research Grant, TAMIU Act on Ideas, and the TAMIU Advancing Research and Curriculum Initiative (TAMIU ARC) awarded by the US Department of Education Developing Hispanic-Serving Institutions Program (Award # P031S190304). Data collection by Dmitrii Dubrov was supported within the framework of the Basic Research Program at HSE University, RF.
Author information
Authors and Affiliations
Consortia
Contributions
Contributions from all the authors are listed in the supplementary material (Supplementary Table 2).
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Blackburn, A.M., Vestergren, S. & the COVIDiSTRESS II Consortium. COVIDiSTRESS diverse dataset on psychological and behavioural outcomes one year into the COVID-19 pandemic. Sci Data 9, 331 (2022). https://doi.org/10.1038/s41597-022-01383-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-022-01383-6
This article is cited by
-
Exploring the role of country-level gender equality in the link between relationship status and perceived social support across 49 countries
Scientific Reports (2024)
-
Familydemic Cross Country and Gender Dataset on work and family outcomes during COVID-19 pandemic
Scientific Data (2023)
-
Investigating measurement invariance of the Emotion Regulation Questionnaire-8 (ERQ-8) across 29 countries
Current Psychology (2023)
-
Predictors of compliance with COVID-19 guidelines across countries: the role of social norms, moral values, trust, stress, and demographic factors
Current Psychology (2023)
