
Abstract
Surface electroencephalography is a standard and noninvasive way to measure electrical brain activity. Recent advances in artificial intelligence led to significant improvements in the automatic detection of brain patterns, allowing increasingly faster, more reliable and accessible Brain-Computer Interfaces. Different paradigms have been used to enable the human-machine interaction and the last few years have broad a mark increase in the interest for interpreting and characterizing the “inner voice” phenomenon. This paradigm, called inner speech, raises the possibility of executing an order just by thinking about it, allowing a “natural” way of controlling external devices. Unfortunately, the lack of publicly available electroencephalography datasets, restricts the development of new techniques for inner speech recognition. A ten-participant dataset acquired under this and two others related paradigms, recorded with an acquisition system of 136 channels, is presented. The main purpose of this work is to provide the scientific community with an open-access multiclass electroencephalography database of inner speech commands that could be used for better understanding of the related brain mechanisms.
Measurement(s) | brain activity • inner speech command |
Technology Type(s) | electroencephalography |
Sample Characteristic - Organism | Homo sapiens |
Machine-accessible metadata file describing the reported data: https://doi.org/10.6084/m9.figshare.16783987
Similar content being viewed by others
Background & Summary
Brain-Computer Interfaces (BCIs) are a promising technology for improving the quality of life of people who have lost the capability to either communicate or interact with their environment1. A BCI provides an alternative way of interaction to such individuals, by decoding the neural activity and transforming it into control commands for triggering wheelchairs, prosthesis, spellers or any other virtual interface device2,3. In BCI applications, neural activity is typically measured by electroencephalography (EEG), since it is a non-invasive technique, the measuring devices can be easily portable and the EEG signals have high time resolution1,2.
Different paradigms have been used in order to establish communication between a user and a device. Some of the most widely adopted paradigms are P3004, steady-state visual evoked potentials (SSVP)5 and motor imagery6. Although the use of these paradigms have resulted in great advances in EEG-based BCI systems, for some applications, they are still unable to lead to efficient ways for controlling devices. This is so mainly because they turned out to be too slow or they required a large effort from the users, restricting the applicability of BCIs in real-life and long-term applications.
In this context, BCIs based on speech-related paradigms, silent, imagined or inner speech, seek to find a solution to the aforementioned limitations, as they provide a more natural way for controlling external devices. Speech production is one of the most complex brain processes performed by human beings since it requires the interaction of several cortical, basal and subcortical brain regions7,8. Most language models and theories agree on the fact that speech involves auditory processing, semantic and syntactic processing as well as motor planning and articulation processes8,9,10,11. Although major and clear theoretical differences exist between the three paradigms mentioned above, they are quite often inconsistently and misleadingly referred to in the literature. In this article, we present a description of the main characteristics of each one of those three paradigms.
-
Silent speech refers to the articulation produced during normal speech, but with no sound emitted. It is usually measured using motion-capturing devices, imaging techniques or by measuring the activity of muscles, and not only from brain signals12,13,14. In addition, Cooney et al.15 proposed a similar paradigm called “Intended speech”, where participants not having the capability to emit sound, are asked to perform speech.
-
Imagined speech is similar to silent speech but it is produced without any articulatory movements, just like in motor imagery of speaking. Here, the participant must feel as if he/she is producing speech13, mainly focusing on the different articulatory gestures. This paradigm was widely explored using EEG16,17,18,19,20,21, electrocorticography (ECoG) signals22,23,24 and magnetoencephalography25. In DaSalla et al.16, the vowels /a/ and /u/ were carefully selected, as they have the most different articulation processes. The requested actions were: “imagine mouth opening and imagine vocalization” for the vowel /a/ and “imagine lip rounding and imagine vocalization” for the vowel /u/. In Pressel et al.17 the requested action was: “imagine the pronunciation or pronounce the word given as cue.”. Finally, the classes (prompts) used in Zhao et al.18 were selected to have different articulations, as the authors mention: “These prompts were chosen to maintain a relatively even number of nasals, plosives, and vowels, as well as voiced and unvoiced phonemes”.
-
Inner speech is defined as the internalized process in which the person thinks in pure meanings, generally associated with an auditory imagery of own inner “voice”. It is also referred to as verbal thinking, inner speaking, covert self-talk, internal monologue, internal speech and internal dialogue. Unlike imagined and silent speech, no phonological properties and turn-taking qualities of an external dialogue are retained13,26. Compared to brain signals in the motor system, language processing appears to be more complex and involves neural networks of distinct cortical areas engaged in phonological or semantic analysis, speech production and other processes23,27. Different studies investigates inner speech, as they benefit some aspects of the paradigm, using EEG28,29,30, ECoG23, functional Magnetic Resonance Imaging (fMRI) and positron emission tomography scan31,32,33,34. In D’Zmura et al.28, participants were instructed to “think the imagined speech without any vocal or subvocal activity”. Furthermore, as the cues were giving with auditory stimulus, auditory processes of inner speech may be benefit: “During this initial period, subjects heard through Stax electrostatic earphones either a spoken ‘ba’ or a spoken ‘ku’ followed by a train of clicks”. In Deng et al.29 participants were instructed to “imagine speaking the cued syllable”, and the cues were also presented with auditory stimulus. Furthermore, no motor activity analysis was carried out in those papers. Finally, in Suppes et al.30, participants performed both auditory comprehension: were participants were instructed to “passively but carefully listen to the spoken words and try to comprehend them” and inner speech (called “Internal speech” in the paper), were participants were asked to “to silently ‘say’ the word immediately after seeing it”.
Another paradigm related to the inner speech is the so-called “auditory comprehension”30,35,36. In this paradigm, instead of actively producing the speech imagination, the individual passively listens to someone else’s speech. It has already been explored using EEG30,37, ECoG38,39 and fMRI40,41. Although this paradigm is not particularly useful for real BCI applications, it has contributed to the understanding of neural processes associated with speech-related paradigms.
While publicly available datasets for imagined speech17,18 and for motor imagery42,43,44,45,46 do exist, to the best of our knowledge there is not a single publicly available EEG dataset for the inner speech paradigm. In addition, the dataset presented by Zhao et al.18 was recorded with a 64 channels acquisition system and all participants were native or advanced English speakers. On the other hand, in the dataset presented in Pressel et al.17, where all participants were native Spanish speakers, the acquisition system had only six channels, highly restricting spatial analysis. As mentioned before, both datasets were focused on the imagined speech paradigm rather than on inner speech. In order to improve the understanding of inner speech and its applications in real BCIs systems, we have built a multi speech-related BCI dataset consisting of EEG recordings from ten naive BCI users, performing four mental tasks in three different conditions: inner speech, pronounced speech and visualized condition. All paradigms and the requested actions are explained in detail in the BCI Interaction Conditions Section. This dataset will allow future users to explore whether inner speech activates similar mechanisms as pronounced speech or whether it is closer to visualizing a spatial location or movement. Each participant performed between 475 and 570 trials in a single day recording, obtaining a dataset with more than 9 hours of continuous EEG data recording, with over 5600 trials.
Methods
Participants
The experimental protocol was approved by the “Comité Asesor de Ética y Seguridad en el Trabajo Experimental” (CEySTE, CCT-CONICET, Santa Fe, Argentina, https://santafe.conicet.gov.ar/ceyste/). Ten healthy right-handed participants, four females and six males with mean age = 34 (std = 10 years), with no hearing loss, no speech loss, and with no neurological, movement, or psychiatric disorders, joined the experiment and gave their written informed consent. All participants were native Spanish speakers. None of the individuals had any previous BCI experience, and participated in approximately two hours of recording. In this work, the participants are identified by aliases “sub-01” through “sub-10”. Detailed information about the participants can be found in Table 1.
Experimental procedures
The study was conducted in an electrically shielded room. The participants were seated in a comfortable chair in front of a computer screen where the visual cues were presented. In order to familiarize the participant with the experimental procedure and the room environment, all steps of the experiment were explained, while the EEG headcap and the external electrodes were placed. The setup process took approximately 45 minutes. Figure 1 shows the main experiment setup.

Experiment setup. Both computers, PC1 and PC2, were located outside the acquisition room. PC1 runs the stimulation protocol while communicating to PC2 every cue displayed. PC2 received the sampled EEG data from the acquisition system and tagged the events with the information received from PC1. At the end of the recording, a.bdf file was created and saved.
The stimulation protocol was designed using Psychtoolbox-347 running in MatLab48 and was executed on a computer, referred to as PC1 in Fig. 1. The protocol displayed the visual cues to the participants in the Graphic User Interface (GUI). The screen’s background was light-grey coloured in order to prevent dazzling and eye fatigue.
Each individual participated in one single recording day comprising three consecutive sessions, as shown in Fig. 2. A self-selected break period between sessions, to prevent boredom and fatigue, was given (inter-session break). At the beginning of each session, a fifteen seconds baseline was recorded where the participant was instructed to relax and stay as still as possible. Within each session, five stimulation runs were presented. Those runs correspond to the different proposed conditions: pronounced speech, inner speech and visualized condition (see Section BCI Interaction Conditions). At the beginning of each run, the condition was announced in the computer screen for a period of 3 seconds. In all cases, the order of the runs was: one pronounced speech, two inner speech and two visualized conditions. A one minute break between runs was given (inter-run break).

Organization of the recording day for each participant.
The classes were specifically selected considering a natural BCI control application with the Spanish words: “arriba”, “abajo”, “derecha”, “izquierda” (i.e.“up”, “down”, “right”, “left”, respectively). The trial’s class (word) was randomly presented. Each participant had 200 trials in both the first and the second sessions. Nevertheless, depending on the willingness and tiredness, not all participants performed the same number of trials in the third session.
Figure 3 describes the composition of each trial, together with the relative and cumulative times. Each trial began at time t = 0 s with a concentration interval of 0.5 s. The participant had been informed that a new visual cue would soon be presented. A white circle appeared in the middle of the screen and the participant had been instructed to fix his/her gaze on it and not to blink, until it disappeared at the end of the trial. At time t = 0.5 s the cue interval started. A white triangle pointing to either right, left, up or down was presented. The pointing direction of the cue corresponded to each class. After 0.5 s, i.e. at t = 1 s, the triangle disappeared from the screen, moment at which the action interval started. The participants were instructed to start performing the indicated task right after the visual cues disappeared and the screen showed only the white circle. After 2.5 s of action interval, i.e. at t = 3.5 s, the white circle turned blue, and the relax interval began. The participant had been previously instructed to stop performing the activity at this moment, but not to blink until the blue circle disappears. At t = 4.5 s the blue circle vanished, meaning that the trial has ended. A rest interval, with a variable duration of between 1.5 s and 2 s, was given between trials.

Trial workflow. The screen presented to the participant in each time interval was plotted on the top arrow of the figure. Relative and global time were plotted above and below the arrow, respectively.
To evaluate each participant’s attention, a concentration control was randomly added to the inner speech and the visualized condition runs. The control task consisted of asking the participant, after some randomly selected trials, which was the direction of the last class shown. The participant had to select the direction using the keyboard arrows. No time limit was given to reply to these questions and the protocol continued after the participant pressed any of the four arrow keys. Visual feedback was provided indicating whether the question was correctly or incorrectly answered.
Data acquisition
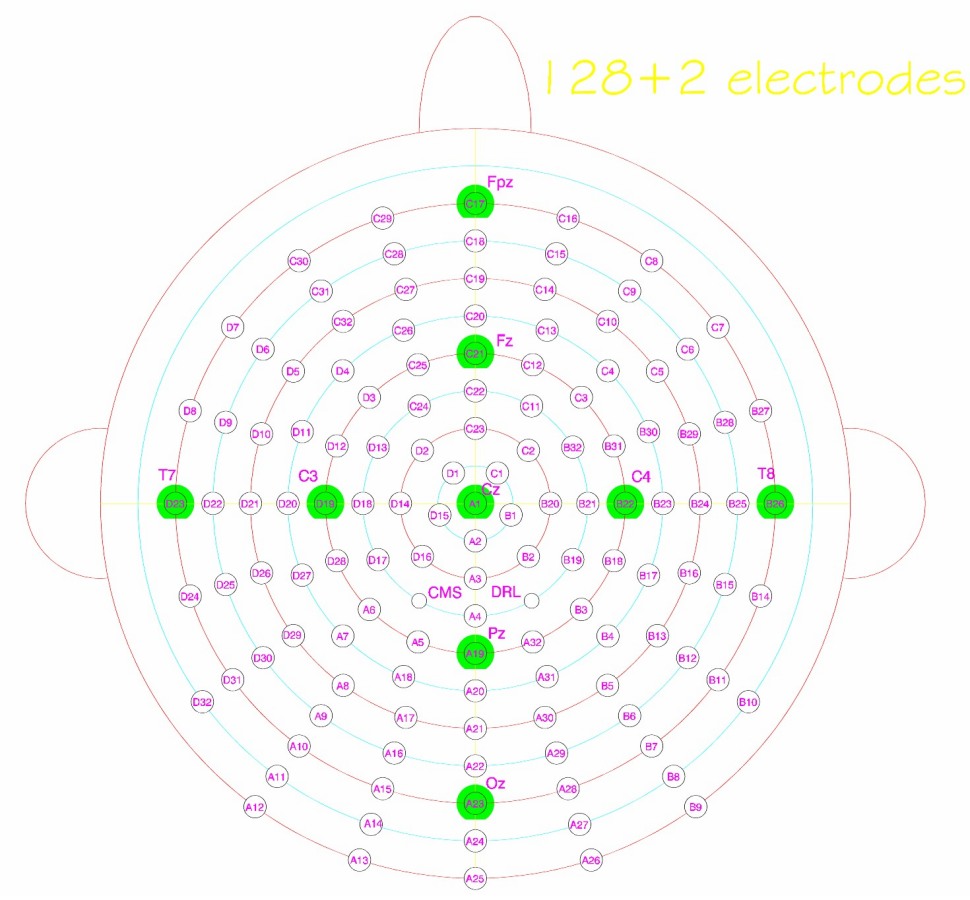
Electroencephalography (EEG), Electrooculography (EOG) and Electromyography (EMG) data were acquired using a BioSemi ActiveTwo high resolution biopotential measuring system (https://www.biosemi.com/products.htm). For data acquisition, 128 active EEG channels and 8 external active EOG/EMG channels with a 24 bits resolution and a sampling rate of 1024 Hz were used. BioSemi also provides standard EEG head caps of different sizes with pre-fixed electrode positions. A cap of appropriate size was chosen for each participant by measuring the head circumference with a measuring tape. Each EEG electrode was placed in the corresponding marked position in the cap and the gap between the scalp and the electrodes was filled with a conductive SIGNAGEL® gel.
Signals in the EOG/EMG channels were recorded using a flat-type active electrode, filled with the same conductive gel and taped with a disposable adhesive disk. External electrodes are referred from “EXG1” to “EXG8”. Electrodes EXG1 and EXG2 were both used as a no-neural activity reference channels, and were placed in the left and right lobe of each ear, respectively. Electrodes EXG3 and EXG4 were located over the participant’s left and right temples, respectively, and were intended to capture horizontal eye movement. Electrodes EXG5 and EXG6 aimed to capture vertical eye movement, mainly blinking movements. Those electrodes were placed above and below the right eye, respectively. Finally, electrodes EXG7 and EXG8 were placed over the superior and inferior right orbicularis oris, respectively. Those electrodes were aimed to capture mouth movement in the pronounced speech and to provide a way for controlling that no movement was made during the inner speech and visualization condition runs.
The software used for recording was ActiView, developed also by BioSemi. It provides a way of checking the electrode impedance and the general quality of the incoming data. It was carefully checked that the impedance of each electrode was less than 40 Ω before starting any recording session. Only a digital 208 Hz low-pass filter was used during acquisition time (no high-pass filter was used).
Once the recording of each session was finished, a.bdf file was created and stored in computer PC2. This file contains the continuous recording of the 128 EEG channels, the 8 external channels and the tagged events.
BCI interaction conditions
The design of the dataset was made having in mind as main objectives the decoding and understanding of the processes involved in the generation of inner speech, as well as the analysis of its potential use in BCI applications. As described in the “Background & Summary” Section, the generation of inner speech involves several complex neural networks interactions. With the objective of localizing the main activation sources and analyzing their connections, we asked the participants to perform the experiment under three different conditions: inner speech, pronounced speech and visualized condition.
Inner speech
Inner speech is the main condition in the dataset and it is aimed to detect the brain’s electrical activity related to a participant’s thought about a particular word. In the inner speech runs, each participant was indicated to imagine his/her own voice as if he/she was giving a direct order to the computer, repeating the corresponding word until the white circle turned blue. Each participant was explicitly asked not to focus on the articulation gestures. Also, each participant was instructed to stay as still as possible and not to move the mouth nor the tongue. For the sake of natural imagination, no rhythm cue was provided.
Pronounced speech
Although motor activity is mainly related to the imagined speech paradigm, inner speech may also show activity in the motor regions. The pronounced speech condition was proposed with the purpose of finding motor regions involved in the pronunciation matching those activated during the inner speech condition. In the pronounced speech runs, each participant was indicated to repeatedly pronounce aloud the word corresponding to each visual cue, as if he/she was giving a direct order to the computer. Like in the inner speech runs, no rhythm cue was provided.
Visualized condition
Since the selected words have a high visual and spatial component, and with the objective of finding any activity related to that being produced during inner speech, the visualized condition was proposed. It is timely to mention that the main neural centers related to spatial thinking are located in the occipital and parietal regions49. Also, it has been demonstrated that the spatial attention have a significant impact on the SSVP amplitude50. In the visualized condition runs, the participants were indicated to focus on mentally moving the circle appearing at the center of the screen in the direction indicated by the visual cue.
Data processing
In order to restructure the continuous raw data into a more compact dataset and to facilitate their use, a transformation procedure was proposed. Such processing was implemented in Python, mainly using the MNE library51, and the code along with the raw data are available, so any interested reader can easily change the processing setup as desired (see Code Availability Section).
Raw data loading
A function that rapidly allows loading of the raw data corresponding to a particular participant and session, was developed. The raw data stored in the.bdf file contains records of the complete EEG and external electrodes signals as well as the tagged events.
Events checking and correction
The first step of the signal processing procedure was checking for correct tagging of events in the signals. Missing tags were detected and a correction method was proposed. The method detects and completes the sequences of events. After the correction, no tags were missing and all the events matched those sent from PC1.
Re-reference
As BioSemi is a “reference free” acquisition system, the Common-Mode (CM) voltage is recorded in all channels, thus a re-reference step is needed. This procedure was made by means of the specific MNE re-reference function, using channels EXG1 and EXG2. The aforementioned function creates a virtual channel, averaging both EXG1 and EXG2, and then subtracting the virtual channel from each one of the rest of the acquired channels. This step eliminates the CM voltage, and helps to reduce both line noise (50 Hz) and body potential drifts.
Digital filtering
The data were filtered with a zero-phase bandpass finite impulse response filter using the corresponding MNE function. The lower and upper bounds were set to 0.5 and 100 Hz, respectively. This broad band filter aims to keep the data as raw as possible, allowing future users the possibility of filtering the data in their desired bands. A Notch filter in 50 Hz was also applied.
Epoching and decimation
The data were decimated four times, obtaining a final sampling rate of 254 Hz. Then, the continuous recorded data were epoched, keeping only the 4.5 s length signals corresponding to the time window between the beginning of the concentration interval and the end of the relaxation interval. The matrices of dimension [channels × samples] corresponding to each trial, were stacked in a final tensor of size [trials × channels × samples].
Independent components analysis
Independent Components Analysis (ICA) is a standard and widely used blind source separation method for removing artifacts from EEG signals52,53,54. For our dataset, ICA processing was performed only on the EEG channels, using the MNE implementation of the infomax ICA55. No Principal Component Analysis (PCA) was applied and 128 sources were captured. Correlation with the EXG channels was used to determine the sources related to blink, gaze and mouth movement, which were neglected in the process of reconstructing the EEG signals, for obtaining the final dataset.
Electromyography control
The EMG control aims to determine whether a participant moved his/her mouth during the inner speech or visualized condition runs. The simplest approach to find EMG activity is the single threshold method56. The baseline period was used as a basal activity. The signals coming from the EXG7 and EXG8 channels were rectified and bandpass filtered between 1 and 20 Hz57,58,59. The power in a sliding window of 0.5 s length with a time step of 0.05 s was calculated as implemented in Peterson et al.60. The power values were obtained by the following equation,
where x[·] denotes the signal being considered, and s, S are the initial and final samples of the window, respectively. For every window, a scalar value was obtained after computing the power. Those scalar values were then stacked in a vector called Vpb. Finally the mean and standard deviations of those values were calculated and used to construct a decision threshold defined as follows:
In Eq. 2, γ is an appropriately chosen parameter. According to Micera et al.61 γ = 3 is a reasonable choice. The same procedure was repeated for both channels and the mean power in the action interval of every trial was calculated. Then, if one of those values, for either the EXG7 or EXG8 channels was above the threshold, the corresponding trial was tagged as “contaminated”.
A total of 115 trials were tagged as contaminated, which represents a 2.5% of the inspected trials. The number of tagged trials is shown in Table 2. The tagged trials and their mean power corresponding to EXG7 and EXG8 were also stored in a report file. In order to reproduce the decision threshold, the mean and standard deviation power for the baseline for the corresponding session were also stored in the same report file.
The developed script performing the described control is publicly available and interested readers can use it to conduct different analyses.
Ad-hoc tags correction
After session 1, participant sub-03 claimed that, due to a missinterpretation, he performed only one inner speech run and three visualized condition runs. The condition tag was appropriately corrected. In addition, in session 3, the same participant performed three inner speech runs and only one visualized condition, aiming to balance the uneven number of trials by condition.
Data Records
All data files, including the raw recordings, can be accessed at the OpenNeuro repository62. All files are contained in a main folder called “Inner Speech Dataset”, structured as depicted in Fig. 4, organized and named using the EEG data extension of BIDS recommendations63,64. The final dataset folder is composed of ten subfolders containing the session raw data, each one corresponding to a different participant. There is an additional folder, containing five files obtained after the proposed processing: EEG data, Baseline data, External electrodes data, Events data and a Report file. We now proceed to describe the contents of each one of these five files along with the raw data.

Final dataset structure, files, and naming.
Raw data
The raw data file contains the continuous recording of the entire session for all 136 channels. The mean duration of the recordings is 1554 seconds. The.bdf file contains all the EEG/EXG data and the tagged events with further information about the recording sampling rate, the names of the channels and the recording filters, among other information. The raw events are obtained from the raw data file and contain the tags sent by PC1, synchronized with the recorded signals. Each event code, its ID and description are depicted in Table 3. A spurious event, of unknown origin, with ID 65536 appeared at the beginning of the recording and also it randomly appeared within some sessions. This event has no correlation with any sent tag and it was removed in the “Events Check” step of the processing. The raw events are stored in a three column matrix, where the first column contains the time stamp information, the second has the trigger information, and the third column contains the event ID.
Electroencephalography data
Each EEG data file, stored in.fif format, contains the acquired data for each participant and session, after processing as described above. Each one of these files contains an MNE Epoched object, with the EEG data information of all trials in the corresponding session. The dimension of the corresponding tensor data is [Trials × 128 × 1154]. The number of trials changed among participants in each session, as explained in the “Data Aquisition” Section. The number of channels used for recording was 128 while the number of samples was 1154, each one of them corresponding to 4.5 s of signal acquisition with a final sampling rate of 256 Hz. A total of 1128 pronounced speech trials, 2236 inner speech trials and 2276 visualization condition trials, were acquired, distributed as shown in Table 4. Also, the detailed number of trials acquired in each block, divided by runs and participants, is included in Tables SI-1, SI-2 and SI-3 of the Supplementary Information Section.
External electrodes data
Each one of the EXG data files contains the data acquired by the external electrodes after the described processing was applied, with the exception of the ICA processing. They were saved in.fif format. The corresponding data tensor has dimension [Trials × 8 × 1154]. Here, the number of EXG trials equals the number of EEG data trials, 8 corresponds to the number of external electrodes used, while 1154 corresponds to the number samples of 4.5 s of signal recording at a final sampling rate of 256 Hz.
Events data
Each event data file (in.dat format) contains a four column matrix where each row corresponds to one trial. The first two columns were obtained from the raw events, by deleting the trigger column (second column of the raw events) and renumbering the classes 31, 32, 33, 34 as 0, 1, 2, 3, respectively. Finally, the last two columns correspond to condition and session number, respectively. Thus, the resulting final structure of the events data file is as depicted in Table 5.
Baseline data
Each baseline data file (in.fif format) contains a data tensor of dimension [1 × 136 × 3841]. Here, 1 corresponds to the only recorded baseline in each session, 136 corresponds to the total number of EEG + EXG channels (128 + 8), while 3841 corresponds to the numbers of seconds of signal recording (15) times the final sampling rate (256 Hz). Through a visual inspection it was observed that the recorded baselines of participant sub-03 in session 3 and participant sub-08 in session 2, were highly contaminated.
Report
The report file (in.pkl format) contains general information about the participant and the particular results of the session processing. Its structure is depicted in Table 6.
Technical Validation
Attentional monitoring
The evaluation of the participant’s attention was performed on the inner speech and the visualized condition runs. It was aimed to monitor their concentration on the requested activity. The results of the evaluation showed that participants correctly followed the task, as they performed very few mistakes (Table 7; mean = 0.5, std 0.62). Participants sub-01 and sub-10 claimed that they had accidentally pressed the keyboard while answering the first two questions in session 1. Also, after the first session, participant sub-01 indicated that he/she felt that the questions were too many, reason for which, for the subsequent participants, the number of questions was reduced, in order to prevent participants from getting tired.
Event related potentials
It is well known that Event Related Potentials (ERPs) are manifestations of typical brain activity produced in response to certain stimuli. As different visual cues were presented during our stimulation protocol, we expected to find brain activity modulated by those cues. Moreover, we expected this activity to have no correlation with the condition nor with the class and to be found across all participants. In order to show the existence of ERPs, an average over all participants, for each one of the channels at each instant of time, was computed using all the available trials (Nave = 5640), for each one of the 128 channels. The complete time window average, with marks for each described event is shown in Fig. 5. Between t = 0.1 s and t = 0.2 s a positive-negative-positive wave appears, as it is clearly shown in Fig. 5a. A similar behavior is observed between t = 0.6 s and t = 0.7 s, but now with a more pronounced potential deflection, reflecting the fact that the white triangle (visual cue) appeared at t = 0.5 s (see Fig. 5b). At time t = 1 s, the triangle disappeared and only the white fixation circle remained. As shown in Fig. 5c, a pronounced negative potential started just a few miliseconds before the triangle vanished. It is reasonable to believe that this ERP is related to the motor and cognitive preparation of the participants for executing the requested action. The signal appears to be mostly stable for the rest of the action interval. As seen in Fig. 5d, a positive peak appears between t = 3.8 s and t = 3.9 s, in response to the white circle turning blue, instant at which the relax interval begins.

Global participant average trial and interval plots; all the channels were plotted with a color reference location. (a,b) Concentration interval. (b,c) Cue interval. (c,d) Action interval. (d) End Relax interval.
For a more detailed analysis, instead of taking the time average of all trials (all together) we calculated the time average for all the trials belonging to each one of the three conditions, separately. All of the previously described ERPs remained present in the individual plots of Fig. 6. The pronounced speech signals seem to have more noise in the action interval than both the inner speech and the visualized condition signals. Also, pronounce speech signals present two moments of more intense activity, approximately at 1.8 and 2.6 s. This is most likely due to the fact that, despite the signal pre-processing, some EMG noise remains.

Global average trial for each class. Vertical black lines correspond to interval boundaries, as in Fig. 5. Top row: Inner speech, Middle row: Pronounced speech. Bottom row: Visualized condition.
Time-frequency representation
With the objective of finding and analyzing further differences and similarities between the three conditions, a Time-Frequency Representation (TFR) was obtained by means of a wavelet transform65. This representation is performed via a Morlet Wavelet transformation which returns a complex number. The MNE implementation returns the signal power and the inter trial coherence as the real and imaginary part of the TFR, respectively. This kind of analysis allows to detect changes in the signal characteristics across frequency and time. The corresponding implementation is available in the file “TFR_representations.py”, at our GitHub repository (see Code Availability Section).
Inter trial coherence
By means of the TFR, the Inter Trial Coherence (ITC) was calculated for all 5640 trials (all together). A stronger coherence was found within the concentration, cue and relax intervals, mainly at lower frequencies (see Fig. 7). Also, the beginning of the action interval presents a strong coherence. This could be a result of the modulated activity generated by the disappearance of the cue.

Inter Trials Coherence.Vertical black lines correspond to interval boundaries, as in Fig. 5. (a) Inner speech trials. (b) Visualized condition trials. (c) Pronounced speech trials (d) Global Average.
Now, as in the “Event Related Potentials” Section, instead of taking the ITC of all trials (all together) we calculated the ITC for all the trials belonging to each one of the three conditions, separately. Of the three conditions, pronounced speech appears to have a slightly more intense global coherence at around 1.8 s and 2.6 s, mainly at lower frequencies (0.5 to 3 Hz). A careful observation of the time average results of the Pronounced speech condition presented in Fig. 6, allows us to conjecture that such an increase in activity is the result of a quite natural pace in the articulation of generated sounds, and the aforementioned moments represent the times at which the participants, on average, match their pronunciation. Inner speech and visualized condition show consistently lower coherence during the action interval (see Fig. 7a and Fig. 7b).
Averaged power spectral density
Using all available trials for each condition, the Averaged Power Spectral Density (APSD) between 0.5 and 100 Hz was computed. This APSD is defined as the average between all PSDs of the 128 channels. Figure 8 shows all APSD plots, in which shaded areas correspond to ±1 std of all channels. As shown in the Inter Trial Coherence Section, all trials have a strong coherence up to t = 1.5 s. Therefore, comparisons were made only in the action interval between 1.5 and 3.5 s. As it can be seen, the plots in Fig. 8 show a peak in the alpha band [8–12 Hz] for all conditions, as it was to be expected, with a second peak in the beta band [12–30 Hz]. Also, from the staked plot it is possible to see that at high frequencies (beta-gamma), pronounced speech shows higher power than both the inner speech and the visualized condition. That higher activity is most likely related to the brain motor activity and muscular artifacts. Finally, a narrow depression at 50 Hz appears, corresponding to the Notch filter applied during data processing.

Power spectral density for all conditions. (a) Top Left: Inner speech. (b) Top Right: Visualized condition. (c) Bottom left: Pronounced speech. (d) Bottom right: Staked plot.
Spatial distribution
In order to detect regions where neural activity between conditions is markedly different, the differences in the power in the main frequency bands between each pair of conditions were computed. The aim of the subtractions is to minimize the effects of protocol activity, which are common to every paradigm, boosting the activity produced exclusively by the requested mental tasks. Like in the Averaged Power Spectral Density section, the time window used was 1.5–3.5 s. The Power Spectral Density (PSD) was added to the analysis to further explore regions of interest. Shaded areas on the PSD graphics in Fig. 9 corresponds to ±1 std of the different channels used. No shaded area is shown when only one channel was used to compute the PSD.

Power difference between conditions. Left column: alpha band comparisons. Right column: beta band comparison.Time window used in all comparisons to compute the PSD: 1.5 to 3.5 s. Channels used to compute the PSD: (a) A4, A5, A19, A20 and A32. (b) B16, B22, B24 and B29. (c) D10, D19, D21 and D26. (d) A17, A20, A21, A22 and A30. (e) B16, B22, B24 and B29. (f) D10, D19, D21 and D26. (g) A10. (h) B7. (i) A13. (j) A26.
The top row of Fig. 9 shows a comparison between inner and pronounced speech. The plots show the difference between the computed activity of inner speech and pronounced speech trials. In the alpha band, a major activity in the inner speech trials can be clearly seen in the central occipital/parietal region. The PSD shown in panel “a” was calculated using channels A4, A5, A19, A20 and A32 (BioSemi nomenclature for a head cap with 128 channels - https://www.biosemi.com/pics/cap_128_layout_medium.jpg) and shows a difference of approximately 1 dB at 11 Hz. On the other hand, in the beta band, the spatial distribution of the power differences shows an increased temporal activity for the pronounced condition, consistent with muscular activity artifacts. Here, the PSD was calculated using channels B16, B22, B24 and B29 for panel “b” and channels D10, D19, D21 and D26 for panel “c”. Pronounced speech shows higher power in the whole beta band with a more prominent difference in the central left area.
The middle row of Fig. 9 shows a comparison of the visualized condition and pronounced speech. Here, the plots show the difference between the computed activity for trials corresponding to the first paradigm and those corresponding to the second paradigm. In the alpha band, the visualized condition trials present a larger difference in the central parietal regions and a more subtle difference in the lateral occipital regions. The PSD was calculated using channels A17, A20, A21, A22 and A30, panel “d”. Here again, a difference of about 1 dB at 11 Hz can be observed. In the beta band, an intense activity in the central laterals regions appears for the pronounced condition. For this band, the PSD shown in panels “e” and “f” were calculated using the same channels as those for “b” and “c”, respectively. As seen, power for pronounced speech trials is higher than for the visualized condition ones in the whole beta band, mainly in the left central region. This result is consistent with the fact that the occipital region is related to the visual activity while the central lateral region is related to the motor activity.
Finally, a comparison of the inner speech with the visualized condition is shown in the bottom row of Fig. 9, where the difference between the computed activity of inner speech and visualized condition trials is plotted. Visualized condition trials exhibit a stronger activity in the laterals occipital regions in both the alpha and beta bands. This was to be expected since the visualized condition, containing a stronger visual component, generates marked occipital activity. Interesting, inner speech trials show a broad although subtle higher power in the alpha band in a more parietal region. For the alpha band, the PSDs showed in panel “g” and “h” were computed using channels A10 and B7 for the left and right plots respectively. In both plots, the peak corresponding to the inner speech condition is markedly higher than the one corresponding to the visualized condition. For the beta band, the PSD showed in panel “i” and “j” was calculated using channels A13 and A26 for the left and right PSD plots, respectively. As it can be observed, the power for the visualized condition trials in the whole beta band is higher than the inner speech power. It is timely to mention that no significant activity was presented in the central regions for neither of both conditions.
Limitations and final remarks
In this work we aim to provide a novel EEG dataset, acquired in three different speech related conditions, accounting for 5640 total trials and more than 9 hours of continuous recording. To the best of our knowledge, there is no other dataset recorded with native Spanish speakers and acquired with a high dense (128 + 8) acquisition system.
In regard to the limitations of this dataset, it is important to mention that even though the participants were specifically instructed to imagine their own voice and explicitly requested not to focus on the muscular activity, as in any other endogenous BCI paradigm, there is no guarantee at all that the mental activity executed by a participant was in fact the correct one. Furthermore, as all the participants were naive BCI users, it may not had been possible for them to clearly differentiate between different components of the speech. In the same direction it is worth mentioning that, even though all participants received the same instructions, their interpretation and posterior executed mental activity may vary across individuals. It is also important to remark that, until today, there is not enough evidence to support that imagined speech and inner speech generate distinguishable brain processes. And even if they in fact do, it is not clear that distinguishable features could be captured with current Electroencephalography technologies. Nonetheless, inner speech is clearly a more natural way of controlling a BCI, since the participant does not need to focus on the articulatory gestures.
Although the pronounced speech trials were most likely contaminated with muscular activity, providing the raw EEG data along with the EMG recordings will allow to develop and test EMG denoising algorithms. As mentioned before, no trials were discarded from the dataset in the “Electromyography control” Section nor in the “Attentional Monitoring” Section, so letting future users decide whether or not to include them in their analyses. Not providing rhythmic cues to benefit the participant’s natural pace, could also produce a variation in the the timing of the pronunciation and imagination across trials. This phenomenon is likely to happen, since it is not natural to recite or think about one word at the time. Nevertheless, this is an issue that will also appear in any real BCI application. Much further analysis needs to be performed in order to determine if the participants changed their pace over the trials, and if they did, what the impact of this phenomenon in the decoding performance could be. It is important to remark that the references to the related papers in the field in regard to their executed paradigms, constitutes just a first classification attempt and further analysis needs to be done. This is so mainly because the description of the requested actions is not always clearly detailed and the difference between imagined and inner speech are not always taken into account in those articles.
Finally, we strongly believe that providing not just the raw data, but also the processed data, along with all the implementation codes will be of great benefit to the scientific community.
Usage Notes
The processing script was developed in Python 3.766, using the MNE-python package v0.21.051, NumPy v1.19.267, Scipy v.1.5.268, Pandas v1.1.269 and Pickle v4.070. The main script, “InnerSpeech_processing.py”, contains all the described processing steps and it can be modified to obtain different processing results, as desired. In order to facilitate data loading and processing, six more scripts defining functions are also provided.
The stimulation protocols were developed using Psychtoolbox-347 in MatLab R2017b48. The auxiliary functions, including the parallel port communication needed to send the tags from PC1 to BioSemi Active 2, were also developed in MatLab. The execution of the main script, called “Stimulation_protocol.m”, shows the visual cue in the screen to the participant, and sends, via parallel port, the event being shown. The parallel port communication was implemented in the function “send_value_pp.m”. The main parameter that has to be controlled in the parallel communication is the delay needed after sending each value. This delay allows the port to send and receive the sended value. Although we used a delay of 0.01 s, it can be changed as desired for other implementations.
Code availability
In line with reproducible research philosophy, all codes used in this paper are publicly available and can be accessed at https://github.com/N-Nieto/Inner_Speech_Dataset. The stimulation protocol and the auxiliary MatLab functions are also available. The code was run in PC1, and shows the stimulation protocol to the participants while sending the event information to PC2, via parallel port. The processing Python scripts are also available. The repository contains all the auxiliary functions to facilitate the load, use and processing of the data, as described above. By changing a few parameters in the main processing script, a completely different process can be obtained, allowing any interested user to easily build his/her own processing code. Additionally, all scripts for generating the Time-Frequency Representations and the plots here presented, are also available.
References
Wolpaw, J. R., Birbaumer, N., McFarland, D. J., Pfurtscheller, G. & Vaughan, T. M. Brain-computer interfaces for communication and control. Clinical Neurophysiology 113, 767–791 (2002).
Nicolas-Alonso, L. F. & Gomez-Gil, J. Brain computer interfaces, a review. Sensors 12, 1211–1279 (2012).
Holz, E. M., Botrel, L., Kaufmann, T. & Kübler, A. Long-term independent brain-computer interface home use improves quality of life of a patient in the locked-in state: a case study. Archives of Physical Medicine and Rehabilitation 96, S16–S26 (2015).
McCane, L. M. et al. P300-based brain-computer interface (BCI) event-related potentials (ERPs): People with amyotrophic lateral sclerosis (ALS) vs. age-matched controls. Clinical Neurophysiology 126, 2124–2131 (2015).
Allison, B. Z. et al. Towards an independent brain–computer interface using steady state visual evoked potentials. Clinical Neurophysiology 119, 399–408 (2008).
Ahn, M. & Jun, S. C. Performance variation in motor imagery brain–computer interface: a brief review. Journal of Neuroscience Methods 243, 103–110 (2015).
Blank, S. C., Scott, S. K., Murphy, K., Warburton, E. & Wise, R. J. Speech production: Wernicke, broca and beyond. Brain 125, 1829–1838 (2002).
Lieberman, P. The evolution of human speech: Its anatomical and neural bases. Current anthropology 48, 39–66 (2007).
Timmers, I., van den Hurk, J., Di Salle, F., Rubio-Gozalbo, M. E. & Jansma, B. M. Language production and working memory in classic galactosemia from a cognitive neuroscience perspective: future research directions. Journal of inherited metabolic disease 34, 367–376 (2011).
Hickok, G. Computational neuroanatomy of speech production. Nature reviews neuroscience 13, 135–145 (2012).
Timmers, I., Jansma, B. M. & Rubio-Gozalbo, M. E. From mind to mouth: event related potentials of sentence production in classic galactosemia. PLoS One 7, e52826 (2012).
Denby, B. et al. Silent speech interfaces. Speech Communication 52, 270–287 (2010).
Schultz, T. et al. Biosignal-based spoken communication: A survey. IEEE/ACM Transactions on Audio, Speech, and Language Processing 25, 2257–2271 (2017).
Gonzalez-Lopez, J. A., Gomez-Alanis, A., Martín-Doñas, J. M., Pérez-Córdoba, J. L. & Gomez, A. M. Silent speech interfaces for speech restoration: A review. IEEE Access (2020).
Cooney, C., Folli, R. & Coyle, D. Neurolinguistics research advancing development of a direct-speech brain-computer interface. IScience 8, 103–125 (2018).
DaSalla, C. S., Kambara, H., Sato, M. & Koike, Y. Single-trial classification of vowel speech imagery using common spatial patterns. Neural Networks 22, 1334–1339 (2009).
Pressel-Coreto, G., Gareis, I. E. & Rufiner, H. L. Open access database of EEG signals recorded during imagined speech. In 12th International Symposium on Medical Information Processing and Analysis (SIPAIM), https://doi.org/10.1117/12.2255697 (2016).
Zhao, S. & Rudzicz, F. Classifying phonological categories in imagined and articulated speech. In 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 992–996, https://doi.org/10.1109/ICASSP.2015.7178118 (IEEE, 2015).
Brigham, K. & Kumar, B. V. Imagined speech classification with EEG signals for silent communication: a preliminary investigation into synthetic telepathy. In 2010 4th International Conference on Bioinformatics and Biomedical Engineering, 1–4 (IEEE, 2010).
Sereshkeh, A. R., Trott, R., Bricout, A. & Chau, T. Online EEG classification of covert speech for brain-computer interfacing. International Journal of Neural Systems 27, 1750033 (2017).
Cooney, C., Korik, A., Raffaella, F. & Coyle, D. Classification of imagined spoken word-pairs using convolutional neural networks. In The 8th Graz BCI Conference, 2019, 338–343 (2019).
Leuthardt, E. C., Schalk, G., Wolpaw, J. R., Ojemann, J. G. & Moran, D. W. A brain–computer interface using electrocorticographic signals in humans. Journal of Neural Engineering 1, 63 (2004).
Pei, X., Barbour, D. L., Leuthardt, E. C. & Schalk, G. Decoding vowels and consonants in spoken and imagined words using electrocorticographic signals in humans. Journal of Neural Engineering 8, 046028 (2011).
Guenther, F. H. et al. A wireless brain-machine interface for real-time speech synthesis. PLoS ONE 4 (2009).
Dash, D., Ferrari, P. & Wang, J. Decoding imagined and spoken phrases from non-invasive neural (meg) signals. Frontiers in neuroscience 14, 290 (2020).
Alderson-Day, B. & Fernyhough, C. Inner speech: development, cognitive functions, phenomenology, and neurobiology. Psychological Bulletin 141, 931 (2015).
Indefrey, P. & Levelt, W. J. The spatial and temporal signatures of word production components. Cognition 92, 101–144 (2004).
D’Zmura, M., Deng, S., Lappas, T., Thorpe, S. & Srinivasan, R. Toward EEG sensing of imagined speech. In International Conference on Human-Computer Interaction, 40–48 (Springer, 2009).
Deng, S., Srinivasan, R., Lappas, T. & D’Zmura, M. EEG classification of imagined syllable rhythm using Hilbert spectrum methods. Journal of Neural Engineering 7, 046006 (2010).
Suppes, P., Lu, Z.-L. & Han, B. Brain wave recognition of words. Proceedings of the National Academy of Sciences 94, 14965–14969 (1997).
Fiez, J. A. & Petersen, S. E. Neuroimaging studies of word reading. Proceedings of the National Academy of Sciences 95, 914–921 (1998).
Price, C. J. The anatomy of language: contributions from functional neuroimaging. The Journal of Anatomy 197, 335–359 (2000).
Hickok, G. & Poeppel, D. The cortical organization of speech processing. Nature Reviews Neuroscience 8, 393–402 (2007).
McGuire, P. et al. Functional anatomy of inner speech and auditory verbal imagery. Psychological Medicine 26, 29–38 (1996).
Hubbard, T. L. Auditory imagery: empirical findings. Psychological Bulletin 136, 302 (2010).
Martin, S. et al. Decoding spectrotemporal features of overt and covert speech from the human cortex. Frontiers in Neuroengineering 7, 14 (2014).
Suppes, P., Han, B. & Lu, Z.-L. Brain-wave recognition of sentences. Proceedings of the National Academy of Sciences 95, 15861–15866 (1998).
Pasley, B. N. et al. Reconstructing speech from human auditory cortex. PLoS Biology 10 (2012).
Cheung, C., Hamilton, L. S., Johnson, K. & Chang, E. F. The auditory representation of speech sounds in human motor cortex. eLife 5, e12577 (2016).
Mitchell, T. M. et al. Predicting human brain activity associated with the meanings of nouns. Science 320, 1191–1195 (2008).
Huth, A. G., De Heer, W. A., Griffiths, T. L., Theunissen, F. E. & Gallant, J. L. Natural speech reveals the semantic maps that tile human cerebral cortex. Nature 532, 453–458 (2016).
Kaya, M., Binli, M. K., Ozbay, E., Yanar, H. & Mishchenko, Y. A large electroencephalographic motor imagery dataset for electroencephalographic brain computer interfaces. Scientific Data 5, 180211 (2018).
Ofner, P. et al. Attempted arm and hand movements can be decoded from low-frequency EEG from persons with spinal cord injury. Scientific Reports 9, 1–15 (2019).
Ofner, P., Schwarz, A., Pereira, J. & Müller-Putz, G. R. Upper limb movements can be decoded from the time-domain of low-frequency EEG. PLoS ONE 12, e0182578 (2017).
Tangermann, M. et al. Review of the BCI competition IV. Frontiers in Neuroscience 6, 55 (2012).
Höhne, J. et al. Motor imagery for severely motor-impaired patients: Evidence for brain-computer interfacing as superior control solution. PLoS ONE 9, 1–11, https://doi.org/10.1371/journal.pone.0104854 (2014).
Brainard, D. H. The psychophysics toolbox. Spatial vision 10, 433–436 (1997).
MATLAB. version 7.10.0 (R2010a) (The MathWorks Inc., Natick, Massachusetts, 2010).
Kandel, E. R. et al. Principles of neural science, vol. 5 (McGraw-hill New York, 2000).
Morgan, S., Hansen, J. & Hillyard, S. Selective attention to stimulus location modulates the steady-state visual evoked potential. Proceedings of the National Academy of Sciences 93, 4770–4774 (1996).
Gramfort, A. et al. MNE software for processing MEG and EEG data. Neuroimage 86, 446–460 (2014).
Jung, T.-P. et al. Extended ICA removes artifacts from electroencephalographic recordings. Advances in Neural Information Processing Systems 894–900 (1998).
Vorobyov, S. & Cichocki, A. Blind noise reduction for multisensory signals using ICA and subspace filtering, with application to EEG analysis. Biological Cybernetics 86, 293–303 (2002).
Makeig, S., Bell, A. J., Jung, T.-P. & Sejnowski, T. J. Independent component analysis of electroencephalographic data. In Advances in Neural Information Processing Systems, 145–151 (1996).
Bell, A. J. & Sejnowski, T. J. An information-maximization approach to blind separation and blind deconvolution. Neural Computation 7, 1129–1159 (1995).
Thexton, A. A randomisation method for discriminating between signal and noise in recordings of rhythmic electromyographic activity. Journal of Neuroscience Methods 66, 93–98 (1996).
Porcaro, C., Medaglia, M. T. & Krott, A. Removing speech artifacts from electroencephalographic recordings during overt picture naming. NeuroImage 105, 171–180 (2015).
Laganaro, M. & Perret, C. Comparing electrophysiological correlates of word production in immediate and delayed naming through the analysis of word age of acquisition effects. Brain Topography 24, 19–29 (2011).
Ganushchak, L. Y. & Schiller, N. O. Motivation and semantic context affect brain error-monitoring activity: an event-related brain potentials study. Neuroimage 39, 395–405 (2008).
Peterson, V., Galván, C., Hernández, H. & Spies, R. A feasibility study of a complete low-cost consumer-grade brain-computer interface system. Heliyon 6, e03425 (2020).
Micera, S., Vannozzi, G., Sabatini, A. & Dario, P. Improving detection of muscle activation intervals. IEEE Engineering in Medicine and Biology Magazine 20, 38–46 (2001).
Nieto, N., Peterson, V., Rufiner, H., Kamienkowski, J. & Spies, R. Inner Speech, OpenNeuro, https://doi.org/10.18112/openneuro.ds003626.v2.1.0 (2021).
Gorgolewski, K. J. et al. The brain imaging data structure, a format for organizing and describing outputs of neuroimaging experiments. Scientific Data 3, 1–9 (2016).
Pernet, C. R. et al. EEG-BIDS, an extension to the brain imaging data structure for electroencephalography. Scientific Data 6, 1–5 (2019).
Mallat, S. A wavelet tour of signal processing (Elsevier, 1999).
Van Rossum, G. & Drake, F. L. Python 3 Reference Manual (CreateSpace, Scotts Valley, CA, 2009).
Oliphant, T. E. A guide to NumPy, vol. 1 (Trelgol Publishing USA, 2006).
Virtanen, P. et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nature Methods 17, 261–272, https://doi.org/10.1038/s41592-019-0686-2 (2020).
McKinney, W. et al. Data structures for statistical computing in Python. In Proceedings of the 9th Python in Science Conference, vol. 445, 51–56 (Austin, TX, 2010).
Van Rossum, G. The Python Library Reference, release 3.8.2 (Python Software Foundation, 2020).
Acknowledgements
This research was funded in part by Consejo Nacional de Investigaciones Científicas y Técnicas, CONICET, Argentina, through PIP 2014–2016 No. 11220130100216-CO, the Agencia Nacional de Promoción Científica y Tecnológica through PICT-2017 – 4596 and by Universidad Nacional del Litoral, UNL, through CAI + D-UNL 2016 PIC No.50420150100036LI and CAI + D 2020, number 50620190100069LI. We would like to thank the Laboratorio de Neurociencia, Universidad Torcuato Di Tella (Buenos Aires, Argentina) for giving us access to the facilities where the experiments were performed. Also, we will like to thank all the participants for their willingness and time, and María José Schmidt for produce and edit the images presented in this article.
Author information
Authors and Affiliations
Contributions
N.N. acquired the data, developed all codes, ran all the experiments and wrote the manuscript. V.P. helped to acquire the data, provided technical feedback for designing the experiments, analyzed results and reviewed the manuscript. H.R. provided technical feedback for designing the experiments, analyzed results and reviewed the manuscript. J.K. acquired the data, provided technical feedback for designing the experiments, analyzed results and reviewed the manuscript. R.S. analyzed results, wrote and reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
The Creative Commons Public Domain Dedication waiver http://creativecommons.org/publicdomain/zero/1.0/ applies to the metadata files associated with this article.
About this article

Cite this article
Nieto, N., Peterson, V., Rufiner, H.L. et al. Thinking out loud, an open-access EEG-based BCI dataset for inner speech recognition. Sci Data 9, 52 (2022). https://doi.org/10.1038/s41597-022-01147-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-022-01147-2
This article is cited by
-
A magnetoencephalography dataset during three-dimensional reaching movements for brain-computer interfaces
Scientific Data (2023)
-
EEG-based BCI Dataset of Semantic Concepts for Imagination and Perception Tasks
Scientific Data (2023)
-
Bimodal electroencephalography-functional magnetic resonance imaging dataset for inner-speech recognition
Scientific Data (2023)

{kind=link}