
Abstract
Compositional analyses have long been used to determine the geological sources of artefacts. Geochemical “fingerprinting” of artefacts and sources is the most effective way to reconstruct strategies of raw material and artefact procurement, exchange or interaction systems, and mobility patterns during prehistory. The efficacy and popularity of geochemical sourcing has led to many projects using various analytical techniques to produce independent datasets. In order to facilitate access to this growing body of data and to promote comparability and reproducibility in provenance studies, we designed Pofatu, the first online and open-access database to present geochemical compositions and contextual information for archaeological sources and artefacts in a form that can be readily accessed by the scientific community. This relational database currently contains 7759 individual samples from archaeological sites and geological sources across the Pacific Islands. Each sample is comprehensively documented and includes elemental and isotopic compositions, detailed archaeological provenance, and supporting analytical metadata, such as sampling processes, analytical procedures, and quality control.
Measurement(s) | isotopic composition • chemical composition • contextual information for archaeological sources • contextual information for stone artefacts |
Technology Type(s) | digital curation • computational modeling technique |
Factor Type(s) | archaeological provenance • artefact attribute |
Sample Characteristic - Location | Region (Papua New Guinea) • Vanuatu Islands • Solomon Islands • Fiji islands • Tonga Archipelago • Samoa • American Samoa • Wallis and Futuna Islands • Tuvalu Islands • Tokelau Islands • Rotuma Island Group • Cook Islands • Society Islands • Marquesas Islands • Archipel des Tuamotu • Gambier Islands • Austral Islands • Pitcairn, Henderson, Ducie and Oeno Islands • Easter Island • State of Hawaii • Micronesia • New Zealand |
Machine-accessible metadata file describing the reported data: https://doi.org/10.6084/m9.figshare.12073116
Similar content being viewed by others
Background & Summary
Extracting, transforming, and distributing natural resources and finished goods between individuals and groups has always been an important aspect of technological, economic, and social behaviors in human societies1,2,3,4. Such material aspects of cultures can be inferred with the help of provenance studies, by reconstructing the movements of materials and artefacts across space. For this purpose, archaeologists have regularly used petrographic and geochemical analyses for more than 40 years for characterising the geological provenance of raw materials and stone artefacts and for reconstructing patterns of exchange based on hard evidence5,6,7. Geochemical techniques have proven to be the most efficient and reliable way to fingerprint raw material sources and artefacts thereby providing reproducible and comparable results8,9,10. Furthermore, geochemical data are quantitative and can therefore be examined with statistical methods11,12 or by using, for example, well-known principles of petrogenesis and mantle source evolution.
Due to the improvement of analytical techniques and the increasing use of geochemical sourcing, the production and publication of archaeological compositional data have grown exponentially. It is now recognized that using large source data compilations can lead to more efficient and cost-effective research planning7,10,13. Sharing source data compilations facilitates assigning unambiguous provenance to artefacts because it enables a better understanding of geochemical variability of sources throughout a given study region and also shows potential geochemical differences between sources14, especially for artefacts found in either very homogeneous or complex petrogenetic contexts15,16,17. Furthermore, accessing large geochemical datasets of archaeological artefacts will lead to more robust and large-scope modelling of prehistoric exchange systems18,19,20. However, the current lack of appropriate global data management platform makes it difficult to access and reference relevant archaeological datasets and often induces duplication of individual endeavors.
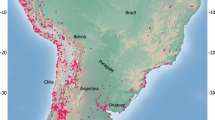
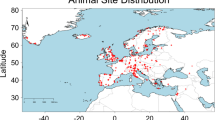
In this data descriptor, we introduce the Pofatu Database, a curated and open-access database of geochemical data on archaeological materials and sources supported by comprehensive contextual information about individual samples and artefacts, including about the archaeological provenance, and a thorough description of analytical procedures. The goals of the database are (i) to provide easy access to published compositional data of archaeological sources and artefacts, (ii) to assemble contextual archaeological information for each individual sample, (iii) to facilitate reuse of existing data and encourage the appropriate crediting of original data sources, and (iv) to ensure reproducibility and comparability by documenting instrumental details, analytical procedures and reference materials used for calibration purposes or quality control. We provide compositional data as well as contextual metadata for 7759 individual samples with a current focus on archaeological sites across the Pacific Islands (Fig. 1). Our vision is an inclusive and collaborative data resource to activate an operational framework for data sharing in archaeometry, that will progressively include more datasets, and initiate a more global project similar to other online repositories for geological materials already available through a wide geoinformatics network21,22,23,24. Furthermore, by using common non-proprietary file formats (CSV) and an open source system for storage and version control (Git and GitHub repository), the Pofatu Database provides an analysis-friendly environment that enables transparency and built-in reproducibility of analytical tasks25.

Locations of samples already released in the Pofatu Database.
Methods
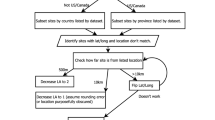
The data can be accessed and downloaded from the Zenodo archive (https://doi.org/10.5281/zenodo.3670127) and browsed in the Pofatu web application (https://pofatu.clld.org/). The database was designed to contain geochemical compositional data and extensive contextual metadata (sample identification, archaeological provenance, analytical methods, and related bibliographical references), which we compiled to ensure further reuse and reinterpretation of previous provenance analyses (Fig. 2).

Structure of the Pofatu Database.
The compositional data contains all analytical values for major oxide and trace element compositions, radiogenic and stable isotope ratios, and geochronology. Sample metadata involves the creation of unique identifiers, and a description of sample condition and preparation. Archaeological metadata provides information on the geographical, cultural and stratigraphic context of the parent artefacts (name, category and attributes), the collection origin (collector, date and nature of field research, storage location), and a description of the site and stratigraphic context (name, code, context, stratigraphic position). The reference metadata lists all bibliographical sources of the data and metadata information26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127,128,129,130,131,132,133,134,135,136,137,138,139,140,141,142,143,144,145,146,147,148,149,150,151,152,153,154,155,156,157,158,159,160,161,162,163,164,165,166,167,168,169,170,171,172,173. Methodological metadata ensure a control on data quality and include information about the preparation of samples analytical procedure (technique, laboratory, analyst) as well as the accuracy and reproducibility of published analyses (errors, precision, standard values, correction procedures).
Data acquisition
All data and metadata in the Pofatu Database and included in this data descriptor release are linked with published resources. Geochemical datasets are extracted from peer-reviewed material, while contextual metadata include information gathered from peer-reviewed articles, monographs, book chapters, and publicly available institutional reports. Original sources are coded in the repository and available as a BibTeX database file, suitable for importing into reference management software. Geochemical datasets are associated with a method identifier, which is unique and defined based on the set of available methodological metadata for a specific set of values.
The process of data acquisition includes:
Data submission: Data and metadata are gathered and stored in normalized tables linked by foreign keys. These interrelated tables each contain sets of information on (i) Data source, (ii) Sample and archaeological provenance, (iii) Compositional data, (iv) Primary analytical and method-specific metadata. The Pofatu Database is frequently curated and updated on a regular basis. New datasets and complementary information on previously documented datasets can be submitted using the Data Submission Template and Guidelines available online (https://pofatu.clld.org/about).
Data validation: The content of each table is handled manually but several fields are constrained by ontologies, which are built-in form validation in the submission template. Data is also validated using functionality implemented in the Python package pypofatu, which imposes suitable constraints on data like geographic coordinates.
Data output: The manually curated “raw” data undergoes an automated processing workflow (implemented in the Python package pypofatu) to create output formats ready for distribution.
For long-term accessibility, the data is converted to a set of interrelated CSV files, described by metadata encoded as JSON-LD (cf. https://www.w3.org/TR/json-ld/, accessed January 30, 2020), following the World Wide Web Consortium (W3C) recommendations174,175. Because the compiled data is exclusively made of line-based text files (in CSV format), it is well-suited for long-term access since it has the lowest requirements on processing software, and provides for a transparent history of changes with the version control software Git (cf. https://git-scm.com/, accessed January 30, 2020).
Data Records
A release of the Pofatu Database is available from the Zenodo archive176. Details of the parameters and measurements reported in the database are summarized in Online-only Table 1. Unique identifiers for samples, artefacts and analytical methods were created for each data record, and used as primary and foreign keys to define relationships between tables.
Technical Validation
Quality control of data and editorial procedures include:
Data review: Database contributors who submit a new dataset are asked to be the editor of that specific dataset and to engage in a review of potential missing or inaccurate data. The content of new datasets is systematically cross-checked with the content of original sources and with potentially related content. Authors are contacted when information is missing or when clarifications are needed.
Duplicate detection: Since Pofatu assigns semantic, unique identifiers to the objects in the database, and links data from additional tables using these keys (following the recommendations by Wilson and colleagues177), data consistency can be checked automatically, e.g. detecting multiple conflicting measurements of the same parameter in the same analysis, or conflicting sample metadata.
Users feedback: Data and metadata issues can be reported to pofatu@shh.mpg.de. Editors will be contacted if an issue with one of their datasets is reported.
Usage Notes
The Pofatu Database provides an analysis-friendly environment178 that enables transparency and built-in reproducibility of analytical tasks that can be achieved through freely available softwares or web browsers25.
Since the metadata provided with the csv-formatted data files has information about data types as well as relations between the tables making up the dataset, it is automatically loaded into an SQLite database (cf. https://sqlite.org/appfileformat.html, accessed January 29, 2020) for the convenience of the users. This SQLite database is contained in a single file document that can be queried with a high-level query language, has accessible content, is cross-platform, performant, and can be used with multiple programming languages.
The Python package pypofatu used for curating the dataset also provides functionality (built-in SQLite driver) that enables access and queries of the data with Python programs or the pypofatu API, and facilitates running SQL queries against the SQLite database.
Complex queries can be created in various ways and with different computing environments:
-
using SQL command line
-
using SQL browsers such as SQLite manager or SQLite reader
-
using R, with SQL codes in a notebook or packages such as sqldf or dplyr179,180
-
using the Datasette tool181
Data usage instructions are provided in the GitHub repository where the dataset is curated (cf. https://github.com/pofatu/pofatu-data, accessed February 6, 2020). A “cookbook” collects shareable pieces of code and how-to instructions to query the relational database (cf. https://github.com/pofatu/pofatu-data/blob/master/doc/cookbook.md, accessed February 6, 2020), and users are invited to contribute with the “recipes” they used for “cooking” with Pofatu.
Code availability
The pypofatu Python package is open-source software, maintained on GitHub and distributed via the Python Package Index (https://pypi.org/project/pypofatu), with released versions archived with Zenodo182. The two output formats listed above are created and stored as part of the GitHub repository where the dataset is curated (https://github.com/pofatu/pofatu-data/releases/tag/v1.0.0), and each release of the dataset is also archived on Zenodo176. Additionally, the dataset is loaded into a clld183 web application, providing an online, browsable user interface for “window-shopping”, before downloading and using the dataset locally.
Released versions of the Pofatu dataset meet the requirements on FAIR data as laid out by Wilkinson and colleagues177. The data is findable thanks to Zenodo’s integration in the research data landscape on the web, and the metadata we provide. It is accessible via the DOI doled out by Zenodo. “It is interoperable due to the open standards” used to encode the data and reusable because it is provided under an open CC-BY license.
References
Renfrew, C. Trade and Culture Process in European Prehistory. Current Anthropology 10, 151–169 (1969).
Sahlins, M. D. Stone Age Economics. (Aldine-Atherton, 1972).
Earle, T. K. & Ericson, J. E. Exchange Systems in Prehistory. (Academic Press, 1977).
Appadurai, A. The Social Life of Things. (Cambridge University Press, 1986).
Ericson, J. E. & Earle, T. K. Contexts for Prehistoric Exchange. (Elsevier, 1982).
Weisler, M. Prehistoric Long-Distance Interaction in Oceania: An Interdisciplinary Approach. (New Zealand Archaeological Association, 1997).
Glascock, M. D. Geochemical Sourcing. In Encyclopedia of Geoarchaeology (ed. Gilbert, A. S.) 303–309 (Springer Netherlands, 2017).
Glascock, M. D. Geochemical Evidence for Long-Distance Exchange. (Bergin and Garvey, 2002).
Dillian, C. D. & White, C. L. Trade and Exchange. (Springer New York, 2010).
Shackley, M. S. X-Ray Fluorescence Spectrometry (XRF) in Geoarchaeology. (Springer New York, 2011).
Baxter, M. J. Statistical Modelling of Artefact Compositional Data. Archaeometry 43, 131–147 (2001).
Papageorgiou, I., Baxter, M. J. & Cau, M. A. Model-based Cluster Analysis of Artefact Compositional Data. Archaeometry 43, 571–588 (2001).
Avino, P. & Rosada, A. Mediterranean and Near East obsidian reference samples to establish artefacts provenance. herit sci 2, 16 (2014).
Weigand, P. C., Harbottle, G. & Sayre, E. V. Turquoise Sources and Source analysis: Mesoamerica and the Southwestern USA. In Exchange Systems in Prehistory (eds. Earle, T. K. & Ericson, J. E.) 15–34 (Academic Press, 1977).
Clark, G. et al. Stone tools from the ancient Tongan state reveal prehistoric interaction centers in the Central Pacific. PNAS 111, 10491–10496 (2014).
Hermann, A. et al. Combined geochemical and geochronological analyses of stone artefacts provide unambiguous evidence of intra- and inter-island interactions in Polynesia. Journal of Archaeological Science: Reports 13, 75–87 (2017).
Weisler, M. I. et al. Cook Island artifact geochemistry demonstrates spatial and temporal extent of pre-European interarchipelago voyaging in East Polynesia. Proc. Natl. Acad. Sci. U.S.A 113, 8150–8155 (2016).
Golitko, M., Meierhoff, J., Feinman, G. M. & Williams, P. R. Complexities of collapse: the evidence of Maya obsidian as revealed by social network graphical analysis. Antiquity 86, 507–523 (2012).
Phillips, S. C. & Gjesfjeld, E. Evaluating Adaptive Network Strategies with Geochemical Sourcing Data: A Case Study from the Kuril Islands. In Network Analysis in Archaeology: New Approaches to Regional Interaction (ed. Knappett, C.) (Oxford University Press, 2013).
Ladefoged, T. N. et al. Social network analysis of obsidian artefacts and Māori interaction in northern Aotearoa New Zealand. Plos One 14, e0212941 (2019).
Pearce, N. J. G. et al. A Compilation of New and Published Major and Trace Element Data for NIST SRM 610 and NIST SRM 612 Glass Reference Materials. Geostandards Newsletter 21, 115–144 (1997).
Lehnert, K., Su, Y., Langmuir, C. H., Sarbas, B. & Nohl, U. A global geochemical database structure for rocks. Geochem. Geophys. Geosyst. 1, 1012 (2000).
Jochum, K. P. et al. GeoReM: A New Geochemical Database for Reference Materials and Isotopic Standards. Geostandards and Geoanalytical Research 29, 333–338 (2005).
Sarbas, B. The GEOROC Database as Part of a Growing Geoinformatics Network. In Geoinformatics 2008—Data to Knowledge, Proceedings (eds. Brady, S. R., Sinha, A. K. & Gundersen, L. C.) 42–43 (2008).
Marwick, B. Computational Reproducibility in Archaeological Research: Basic Principles and a Case Study of Their Implementation. J Archaeol Method Theory 24, 424–450 (2017).
McAlister, A. & Allen, M. S. Basalt geochemistry reveals high frequency of prehistoric tool exchange in low hierarchy Marquesas Islands (Polynesia). Plos One 12, e0188207 (2017).
McAlister, A. J. Methodological issues in the geochemical characterisation and morphological analysis of stone tools: a case study from Nuku Hiva, Marquesas Islands, east Polynesia. (Auckland University, 2011).
Molle, G. & Hermann, A. An Atoll in History: Archaeological Research on Teti’aroa (Society Islands). Final Report Phase 1. (2016).
Hermann, A., Bollt, R. & Conte, E. The Atiahara site revisited: An early coastal settlement in Tubuai (Austral Islands, French Polynesia). Archaeology in Oceania 51, 31–44 (2016).
Hermann, A. Les industries lithiques pré-européennes de Polynésie centrale: savoir-faire et dynamiques techno-économiques. (Université de Polynésie Française, 2013).
Weisler, M. I. The Settlement of Marginal Polynesia: New Evidence from Henderson Island. Journal of Field Archaeology 21, 83–102 (1994).
Sinoto, Y. H. An analysis of Polynesian migrations based on the archaeological assessments. Journal de la Société des océanistes 39, 57–67 (1983).
Green, R. C., Green, K., Rappaport, R. A., Rappaport, A. & Davidson, J. M. Archeology on the island of Mo’orea, French Polynesia. (New York, 1967).
Anderson, A., Conte, E., Clark, G., Sinoto, Y. & Petchey, F. Renewed excavations at Motu Paeao, Maupiti Island, French Polynesia: preliminary results. New Zealand journal of archaeology 21, 47–66 (1999).
Collerson, K. D. & Weisler, M. I. Stone adze compositions and the extent of ancient Polynesian voyaging and trade. Science 317, 1907–1911 (2007).
Weisler, M. I. & Woodhead, J. D. Basalt Pb isotope analysis and the prehistoric settlement of Polynesia. Proc. Natl. Acad. Sci. U.S.A. 92, 1881–1885 (1995).
Best, S., Sheppard, P., Green, R. & Parker, R. Necromancing the Stone: Archaeologists and Adzes in Samoa. Journal of the Polynesian Society 101, 45–85 (1992).
Kirch, P. V. & Hunt, T. L. The To’aga Site: Three Millennia of Polynesian Occupation in the Manu’a Islands, American Samoa. (Archaeological Research Facility, University of California, Berkeley, 1993).
Weisler, M. I. Hard Evidence for Prehistoric Interaction in Polynesia. Current Anthropology 39, 521–532 (1998).
Conte, E. & Molle, G. Reinvestigating a key site for Polynesian prehistory: new results from the Hane dune site, Ua Huka (Marquesas). Archaeology in Oceania 49, 121–136 (2014).
Na mea kahiko no Kahikinui: Studies in the archaeology of Kahikinui, Maui. (University of California, 1997).
Cleghorn, P. L., Weisler, M., Dye, T. & Sinton, J. A preliminary petrographic study of Hawaiian stone adze quarries. Journal of the Polynesian Society 94, 235–251 (1985).
Mc Coy, P., Makanani, A. & Sinoto, A. Archaeological investigations of the Pu’u Moiwi adze quarry complex, Kaho’olawe. 204 (1993).
Field, M. G. J. S. & Graves, M. W. A New Chronology for Pololu Valley, Hawai’i Island: Occupational History and Agricultural Development. Radiocarbon 50, 205–222 (2008).
Tuggle, H. D. & Tomonari-Tuggle, M. J. Prehistoric Agriculture in Kohala, Hawaii. Journal of Field Archaeology 7, 297–312 (1980).
Best, S. Tokelau archaeology: a preliminary report of an initial survey and excavations. Bulletin of the Indo-Pacific Prehistory Association 8, 104–118 (1988).
Green, R. C. Southeast Solomons fieldwork. Asian Perspectives 15, 197–199 (1972).
Leach, F. & Davidson, J. M. The Archaeology of Taumako: a Polynesian Outlier in the Eastern Solomon Islands. (New Zealand Journal of Archaeology Special Publication, 2008).
Poulsen, J. A Contribution to the Prehistory of the Tongan Islands. (Australian National University, 1967).
Best, S. At the halls of the mountain kings. Fijian and Samoan fortifications: Comparison and analysis. Journal of the Polynesian Society 102, 385–447 (1993).
Best, S. B. Lakeba: The prehistory of a Fijian island. (University of Auckland, 1984).
Hunt, T. L. & Kirch, P. V. An archaeological survey of the Manu’a islands, American Samoa. Journal of the Polynesian Society 97, 153–183 (1988).
Best, S. B. Lakeba: The prehistory of a Fijian island. (University of Michigan Press, 1989).
Clark, J. T. The Eastern Tutuila Archaeological Project, 1988. Final Report. (1988).
Rieth, T. M., Morrison, A. E. & Addison, D. J. The Temporal and Spatial Patterning of the Initial Settlement of Sāmoa. The Journal of Island and Coastal Archaeology 3, 214–239 (2008).
The Early Prehistory of Fiji. vol. Terra Australis 31 (ANU Press, 2009).
Natland, J. H. & Turner, D. L. Age progression and petrological development of Samoan shield volcanoes: evidence from K-Ar ages, lava compositions and mineral studies. In Geological Investigations of the Northern Melanesian Borderland 139–171 (Circum- Pacific Council for Energy and Resources, 1985).
Green, R. C. & Davidson, J. M. Archaeology in Western Samoa, 2 Vol. (Auckland Institute and Museum, 1974).
Clark, J. T. & Herdrich, D. J. Prehistoric Settlement System in Eastern Tutuila, American Samoa. Journal of the Polynesian Society 102, 147–185 (1993).
Clark, J. T. Radiocarbon Dates from American Samoa. Radiocarbon 35, 323–330 (1993).
Leach, H. & Witter, D. Further investigations at the Tatagamatau Site, American Samoa. New Zealand Journal of Archaeology 12, 51–83 (1990).
Weisler, M. I. & Kirch, P. V. Interisland and interarchipelago transfer of stone tools in prehistoric Polynesia. Proc. Natl. Acad. Sci. U.S.A. 93, 1381–1385 (1996).
Rolett, B. V., West, E. W., Sinton, J. M. & Iovita, R. Ancient East Polynesian voyaging spheres: new evidence from the Vitaria Adze Quarry (Rurutu, Austral Islands). Journal of Archaeological Science 53, 459–471 (2015).
Kahn, J. G., Sinton, J., Mills, P. R. & Lundblad, S. P. X-ray fluorescence analysis and intra-island exchange in the Society Island archipelago (Central Eastern Polynesia). Journal of Archaeological Science 40, 1194–1202 (2013).
Kirch, P. V., Mills, P. R., Lundblad, S. P., Sinton, J. & Kahn, J. G. Interpolity exchange of basalt tools facilitated via elite control in Hawaiian archaic states. PNAS 109, 1056–1061 (2012).
Walter, R. The Southern Cook Islands in Eastern Polynesian prehistory. (University of Auckland, 1990).
Winterhoff, E. Q., Wozniak, J. A., Ayres, W. S. & Lash, E. Intra-Island Source Variability on Tutuila, American Samoa and Prehistoric Basalt Adze Exchange in Western Polynesia-Island Melanesia. Archaeology in Oceania 42, 65–71 (2007).
Fankhauser, B., Clark, G. & Anderson, A. Characterisation and sourcing of archaeological adzes and flakes from Fiji. In The Early Prehistory of Fiji (eds. Clark, G. & Anderson, A.) vol. Terra Australis 31 373–406 (ANU Press, 2009).
Walter, R. & Sheppard, P. J. The Ngati Tiare Adze Cache: further evidence of prehistoric contact between West Polynesia and the Southern Cook Islands. Archaeology in Oceania 31, 33–39 (1996).
Turner, M. & Bonica, D. Following the Flake Trail: Adze production on the Coromandel East Coast, New Zealand. New Zealand Journal of Archaeology 16, 5–32 (1994).
Johnson, P. R. Elemental Analysis of Fine-Grained Basalt Sources from the Samoan Island of Tutuila: Applications of Energy Dispersive X-Ray Fluorescence (EDXRF) and Instrumental Neutron Activation Analysis (INAA) Toward an Intra-Island Provenance Study. In X-Ray Fluorescence Spectrometry (XRF) in Geoarchaeology (ed. Shackley, M. S.) 143–160 (Springer New York, 2011).
Leach, H. & Witter, D. Tataga-Matau “rediscovered”. New Zealand Journal of Archaeology 9, 33–54 (1987).
Mintmier, M. A., Mills, P. R. & Lundblad, S. P. Energy-Dispersive X-Ray Fluorescence analysis of Haleakalā basalt adze quarry materials, Maui, Hawai’i. Journal of Archaeological Science 39, 615–623 (2012).
Weisler, M. I. Technological, petrographic, and geochemical analysis of the Kapohaku adze quarry, Lana’i, Hawai’ian Islands. New Zealand Journal of Archaeology 12, 29–50 (1990).
McCoy, P. C. The Mauna Kea Adze Quarry Project: A Summary of the 1975 Field Investigations. Journal of the Polynesian Society 86, 223–244 (1977).
Weisler, M. I., Kirch, P. V. & Endicott, J. M. The Mata’are basalt source: Implications for prehistoric interaction studies in the Cook Islands. Journal of the Polynesian Society 103, 203–216 (1994).
Weisler, M. I. et al. Determining the geochemical variability of fine-grained basalt sources/quarries for facilitating prehistoric interaction studies in Polynesia. Archaeology in Oceania 51, 158–167 (2016).
Charleux, M., McAlister, A., Mills, P. R. & Lundblad, S. P. Non-destructive XRF Analyses of Fine-grained Basalts from Eiao, Marquesas Islands. Journal of Pacific Archaeology 5, 75–89 (2014).
Kirch, P. V. et al. Human ecodynamics in the Mangareva Islands: a stratified sequence from Nenega-Iti Rock Shelter (site AGA-3, Agakauitai Island). Archaeology in Oceania 50, 23–42 (2015).
Kahn, J. G. & Kirch, P. V. Monumentality and Ritual Materialization in the Society Islands: The Archaeology of a Major Ceremonial Complex in the’Opunohu Valley, Mo’orea. (Bishop Museum Press, 2014).
Kahn, J. G., Mills, P. R., Lundblad, S. P., Holson, J. & Kirch, P. V. Tool Production at the Nu’u Quarry, Maui, Hawaiian Islands: Manufacturing Sequences and Energy-Dispersive X-Ray Fluorescence Analyses. New Zealand Journal of Archaeology 30, 135–165 (2008).
Ishimura, T. & Inoue, T. Archaeological Excavations at the Si’utu Midden Site, Savai’i Island. Journal of Samoan Studies 2, 43–56 (2006).
Ottino, P. Un site ancien aux îles Marquises: l’abri-sous-roche d’Anapua, à Ua Pou. Journal de la Société des Océanistes 41, 33–37 (1985).
Rolett, B. V. & Conte, E. Renewed investigation of the Ha’atuatua dune (Nukuhiva, Marquesas Islands): A key site in Polynesian prehistory. Journal of the Polynesian Society 104, 195–228 (1995).
Suggs, R. C. The Archaeology of Nuku Hiva, Marquesas Islands, French Polynesia (1961).
Weisler, M. I. Long-distance interaction in prehistoric Polynesia: three case studies. (University of California, 1993).
Weisler, M. A quarried landscape in the Hawaiian Islands. World Archaeology 43, 298–317 (2011).
Sinton, J. & Sinoto, Y. H. A geochemical database for Polynesian adze studies. In Prehistoric Long-Distance Interaction in Oceania: An Interdisciplinary Approach (ed. Weisler, M. I.) 194–204 (New Zealand Archaeological Association, 1997).
Sheppard, P. J., Walter, R. K. & Parker, R. J. Basalt sourcing and the development of Cook Islands exchange systems. In Prehistoric Long-Distance Interaction in Oceania: An Interdisciplinary Approach (ed. Weisler, M. I.) 85–110 (New Zealand Archaeological Association, 1997).
Rolett, B. V., Conte, E., Pearthree, E. & Sinton, J. Marquesan voyaging: archaeometric evidence for inter-island contact. In Prehistoric Long-Distance Interaction in Oceania: An Interdisciplinary Approach (ed. Weisler, M. I.) 134–148 (New Zealand Archaeological Association, 1997).
Ayres, W. S., Wozniak, J. A., Robbins, G. & Suafo’a, E. Archaeology in American Samoa: Maloata, Malaeimi and Malaeloa. In Pacific 2000: Proceedings of the Fifth International Conference on Easter Island and the Pacific (eds. Stevenson, C. M., Lee, G. & Morin, F. J.) 227–235 (2001).
Winterhoff, E. Q. The Political Economy of Ancient Samoan Basalt Adze Production and Linkages to Social Status. (University of Oregon, 2007).
Tangatatau Rockshelter (Mangaia, Southern Cook Islands): The Evolution of an Eastern Polynesian Socio-ecosystem. (Cotsen Institute of Archaeology Press, 2017).
Simpson, D. F. & Dussubieux, L. A collapsed narrative? Geochemistry and spatial distribution of basalt quarries and fine–grained artifacts reveal communal use of stone on Rapa Nui (Easter Island). Journal of Archaeological Science: Reports 18, 370–385 (2018).
Simpson, D. F., Weisler, M. I. S. T., Pierre, E. J., Feng, Y. & Bolhar, R. The archaeological documentation and geochemistry of the Rua Tokitoki adze quarry and the Poike fine-grain basalt source on Rapa Nui (Easter Island): Rua Tokitoki quarry and Poike basalt source on Rapa Nui. Archaeology in Oceania 53, 15–27 (2018).
Walter, R. Anai’o: The Archaeology of a Fourteenth Century Polynesian Community in the Cook Islands. (New Zealand Archaeological Association, 1998).
Green, R. C. Preliminary report for the American Museum of Natural History on archaeological research in the Gambier Isles (Mangareva) July 2, 1959 to December 6, 1959. Manuscript on file. (1960).
Weisler, M. I. Chemical characterization and provenance of Manu’a adze material using a non-destructive X-ray fluorescence technique. In The To’aga Site: Three Millennia of Polynesian Occupation in the Manu’a Islands, American Samoa (eds. Kirch, P. V. & Hunt, T. L.) 167–186 (Archaeological Research Facility, University of California, Berkeley, 1993).
Kirch, P. V., Hunt, T. L., Nagaoka, L. & Tyler, J. An Ancestral Polynesian occupation site at To’aga, Ofu Island, American Samoa. Archaeology in Oceania 25, 1–15 (1990).
Emory, K. P. Material Culture of the Tuamotu Archipelago. (1975).
Clark, G. Archaeological and palaeoenvironmental investigations on Yacata Island, northern Lau, Fiji. Domodomo: Fiji Museum Quarterly 13, 29–47 (2001).
Winterhoff, E. Q. Ma’a a Malaeloa: A Geochemical Investigation of a New Basalt Quarry Source in Tutuila, American Samoa. (University of Oregon, 2003).
Poulsen, J. Early Tongan prehistory: the Lapita period on Tongatapu and its relationships. (Department of Prehistory, Research School of Pacific Studies, 1987).
Felgate, M. W., Sheppard, P. J. & Wilmshurst, J. M. Geochemical characteristics of the Tahanga archaeological quarry complex. Archaeology in New Zealand 44, 215–240 (2001).
Kneebone, B. The Sharpest Tool in the Shed: A Morphological, Typological and Geochemical Analysis of Stone Adzes from the Auckland (Tamaki) Region, New Zealand. (University of Auckland, 2018).
Davidson, J. & Leach, F. Archaeological excavations at Pig Bay (N38/21, R10/22), Motutapu Island, Auckland, New Zealand, in 1958 and 1959. Records of the Auckland Museum 52, 9–38 (2017).
Davidson, J. M. Excavation of an ‘undefended’ site, N38/37, on Motutapu island, New Zealand. Records of the Auckland Institute and Museum 7, 31–60 (1970).
Davidson, J. M. Archaeological investigations on Motutapu Island, New Zealand: Introduction to recent fieldwork, and further results. Records of the Auckland Institute and Museum 9, 1–14 (1972).
Davidson, J. Archaeological investigations at Maungarei: A large Mäori settlement on a volcanic cone in Auckland, New Zealand. Tuhinga, Records of the Museum of New Zealand Te Papa Tongarewa 22, 19–100 (2011).
Campbell, M., Hudson, B. & Cruickshank, A. Section 18 investigations of the Long Bay Restaurant site, R10/1374, Long Bay Regional Park, Auckland (HPA authority 2014/506). (2014).
Campbell, M. The NRD site: the archaeology. (2011).
Leahy, A. Excavations at Taylor’s Hill, R11/96, Auckland. Records of the Auckland Institute and Museum 28, 33–68 (1991).
Leahy, A. Excavations at site N38/30, Motutapu Island, New Zealand. Records of the Auckland Institute and Museum 7, 61–82 (1970).
Sewell, B. Further excavations at the Westfield site (R11/898), Tamaki, Auckland. (1992).
Furey, L. The excavation of Westfield (R11/898), South Auckland. Records of the Auckland Institute and Museum 23, 1–24 (1986).
McCoy, M. D., Alderson, H. A., Hemi, R., Cheng, H. & Edwards, R. L. Earliest direct evidence of monument building at the archaeological site of Nan Madol (Pohnpei, Micronesia) identified using 230Th/U coral dating and geochemical sourcing of megalithic architectural stone. Quaternary Research 86, 295–303 (2016).
Ayres, W. S., Goles, G. G. & Beardsley, F. R. Provenance study of lithic materials in Micronesia. In Prehistoric Long-Distance Interaction in Oceania: An Interdisciplinary Approach (ed. Weisler, M. I.) 53–67 (New Zealand Archaeological Association, 1997).
McCoy, M. D. & Athens, J. S. Sourcing the Megalithic Stones of Nan Madol: an XRF Study of Architectural Basalt Stone from Pohnpei, Federated States of Micronesia. JPA 3 (2011).
Ayres, W. S. & Mauricio, R. Stone Adzes from Pohnpeian, Micronesia. Archaeology in Oceania 22, 27–31 (1987).
McCoy, M. D., Alderson, H. A. & Thompson, A. A new archaeological field survey of the site of Nan Madol, Pohnpei. Rapa Nui Journal 29, 5–22 (2015).
Stevenson, C. M., Ladefoged, T. N., Haoa, S., Chadwick, O. & Puleston, C. Prehistoric Obsidian Exchange on Rapa Nui. The Journal of Island and Coastal Archaeology 8, 108–121 (2013).
Stevenson, C. M., Shaw, L. C. & Cristino, C. Obsidian Procurement and Consumption on Easter Island. Archaeology in Oceania 19, 120–124 (1984).
Hermann, A., Molle, G., Maury, R., Liorzou, C. & McAlister, A. Geochemical sourcing of volcanic materials imported into Teti’aroa Atoll shows multiple long-distance interactions in the Windward Society Islands, French Polynesia. Archaeology in Oceania 54, 184–199 (2019).
McCoy, M. D. et al. Geochemical Sourcing of New Zealand Obsidians by Portable X-Ray Fluorescence from 2011 to 2018. Journal of Open Archaeology Data 7, 1 (2019).
Cruickshank, A. A Qualitative and Quantitative Analysis of the Obsidian Sources on Aotea (Great Barrier Island), and their Archaeological Significance. (University of Auckland, 2011).
Kneebone, B. Spatial Interactions and Communications: A Geochemical Analysis of Obsidian from the Tamaki region. (University of Auckland, 2016).
Lawrence, M., McCoy, M. D., Barber, I. & Walter, R. Geochemical sourcing of obsidians from the Pūrākaunui site, South Island, New Zealand. Archaeology in Oceania 49, 158–163 (2014).
McCoy, M. D. & Carpenter, J. Strategies for Obtaining Obsidian in Pre-European Contact Era New Zealand. Plos One 9 (2014).
McCoy, M. D., Ladefoged, T. N., Codlin, M. & Sutton, D. G. Does Carneiro’s circumscription theory help us understand Maori history? An analysis of the obsidian assemblage from Pouerua Pa, New Zealand (Aotearoa). Journal of Archaeological Science 42, 467–475 (2014).
Walter, R., Brooks, E., Greig, K. & Hurford, J. Excavations at Kahukura, Murihiku. Journal of Pacific Archaeology 9, 59–82 (2018).
McCoy, M. D. & Robles, H. N. The Geographic Range of Interaction Spheres During the Colonization of New Zealand (Aotearoa): New Evidence for Obsidian Circulation in Southern New Zealand. The Journal of Island and Coastal Archaeology 11, 285–293 (2016).
Maxwell, J. J., McCoy, M. D., Tromp, M., Hoffmann, A. & Barber, I. G. The Difficult Place of Deserted Coasts in Archaeology: New Archaeological Research on Cooks Beach (Pukaki), Coromandel Peninsula, New Zealand. The Journal of Island and Coastal Archaeology 13, 1–20 (2017).
Reepmeyer, C. & Clark, G. Post-Colonization Interaction Between Vanuatu and Fiji Reconsidered: The Re-Analysis of Obsidian from Lakeba Island, Fiji. Archaeometry 52, 1–18 (2010).
Carpenter, J. Archaeological Monitoring of Archaeological Site Q06/567. Preliminary Report. Unpublished report for the Whangarei District Council. (2010).
Carpenter, J. Smugglers and Bream Head Track Upgrade. Preliminary Report for HPT Authority 2007/97. Unpublished report for the Department of Conservation (2009).
Barber, I. G. Archaeological assessment of an eroding site complex No. I44-21 at Purakaunui Inlet, Otago. Archaeology in New Zealand 45, 153–170 (2002).
Anderson, A. J. A fourteenth-century fishing camp at Purakanui Inlet, Otago. Journal of the Royal Society of New Zealand 11, 201–221 (1981).
Gay, J. W. Selected Artefact Assemblages from Purakaunui (144/21) Excavated during 2001, 2002 and 2003. (University of Otago, 2004).
Sutton, D., Furey, L. & Marshall, Y. The Archaeology of Pouerua. (Auckland University Press, 2003).
Brassey, R. An analysis of some lithic artefact assemblages from Pouerua, Northland. (University of Auckland, 1985).
Garland, J. & Wadsworth, T. An Archaeological Survey of Catlins Lake and Estuary, Southland. Archaeology in New Zealand 27–38 (2019).
Davidson, J. The Prehistory of New Zealand. (Longman Paul, 1984).
Smith, I. Preliminary Report on Excavations at Pleasant River Mouth (J43/1) (1993).
Anderson, A., Smith, I. W. G. & Allingham, B. Shag River mouth: the archaeology of an early southern Maori village. (Australian National University, 1996).
Skinner, H. D. Excavations at Little Papanui, Otago Peninsula. Journal of the Polynesian Society 69, 187–198 (1960).
Leach, H. & Hamel, J. Archaic and Classic Maori Relationships at Long Beach, Otago: the Artefacts and Activity Areas. New Zealand Journal of Archaeology 3, 109–141 (1981).
Brooks, E., Walter, R. & Jacomb, C. Southland Coastal Heritage Inventory Project Waiparua Head to Rowallan Burn. (2008).
Hamel, J. The archaeology of Otago. (Department of Conservation, 2001).
Teviotdale, D. The material culture of the Moa-Hunters in Murihiku. Journal of the Polynesian Society 41, 81–120 (1932).
Campbell, M. et al. The Torpedo Bay excavations: Volume 1, the pre-European Maori site (HPA authority 2009/275). (2018).
Davidson, J. The Prehistory of Motutapu Island, New Zealand: Five Centuries of Polynesian Occupation in a Changing Landscape. Journal of the Polynesian Society 87, 327–337 (1978).
Hoffmann, A. Investigation of archaeological site T11/2789, Cooks Beach (Pukaki), Mercury Bay: final report. HNZ authorities 2015/867 & 2015/1022. (2017).
Hermann, A., Maury, R. C. & Liorzou, C. Traçabilité des matières premières lithiques dans les assemblages archéologiques polynésiens: le cas de Tubuai (Archipel des Australes, Polynésie française). Géologue 172, 80–83 (2012).
Reepmeyer, C. Characterising volcanic glass sources in the Banks Islands, Vanuatu. Archaeology in Oceania 43, 120–127 (2008).
Reepmeyer, C. The obsidian sources and distribution systems emanating from Gaua and Vanua Lava in the Banks Islands of Vanuatu. (Australian National University, 2009).
Reepmeyer, C., Clark, G. & Sheppard, P. Obsidian Source Use in Tongan Prehistory: New Results and Implications. The Journal of Island and Coastal Archaeology 7, 255–271 (2012).
Reepmeyer, C., Spriggs, M., Bedford, S. & Ambrose, W. Provenance and Technology of Lithic Artifacts from the Teouma Lapita Site, Vanuatu. Asian Perspectives 49, 205–225 (2010).
Valentin, F. & Clark, G. Early Polynesian mortuary behaviour at the Talasiu site, Kingdom of Tonga. Journal of Pacific Archaeology 4, 1–14 (2013).
Clark, G. & Reepmeyer, C. Stone architecture, monumentality and the rise of the early Tongan chiefdom. Antiquity 88, 1244–1260 (2014).
Bedford, S., Spriggs, M., Buckley, H., Valentin, F. & Regenvanu, R. The Teouma Lapita Site, South Efate, Vanuatu: A summary of three Field seasons (2004–2006). In Lapita: Ancestors and Descendants (eds. Sheppard, P. J., Thomas, T. & Summerhayes, G. R.) 215–234 (New Zealand Archaeological Association, 2009).
Weisler, M. I., Mendes, W. P. & Hua, Q. A Prehistoric Quarry/Habitation Site on Moloka’i and a Discussion of an Anomalous Early Date on the Polynesian Introduced Candlenut (kukui, Aleurites moluccana). Journal of Pacific Archaeology 6, 37–57 (2015).
Weisler, M. et al. A New Major Adze Quarry from Nānākuli, O’ahu: Implications for Interaction Studies in Hawai’i. Journal of Pacific Archaeology 4, 35–57 (2013).
Golitko, M., Schauer, M. & Terrell, J. E. Obsidian acquisition on the Sepik coast of northern Papua New Guinea during the last two Millennia. In Pacific Archaeology: Documenting the Past 50,000 Years (eds. Summerhayes, G. R. & Buckley, H.) 43–57 (University of Otago, 2013).
Dixon, B., Major, M., Carpenter, A., Stine, C. & Longton, B. Lithic tool production and dryland planting adaptations to regional agricultural intensification: preliminary evidence from leeward Moloka’i, Hawai’i. Bishop Museum Occasional Papers 39, 1–19 (1994).
Terrell, J. E. Archaeological Surveys (Exploring Prehistory on the Sepik Coast of Papua New Guinea). Fieldiana Anthropology 42, 35–68 (2011).
Terrell, J. E. Archaeological Excavations (Exploring Prehistory on the Sepik Coast of Papua New Guinea). Fieldiana Anthropology 42, 69–86 (2011).
McKinlay, J. R. Elletts Mountain Excavation 1973–74. NZHPT Newsletter 3, 4–6 (1974).
McKinlay, J. R. Elletts Mountain Excavation 1974–75. NZHPT Newsletter 5, 6 (1975).
McKinlay, J. R. Elletts Mountain Excavation. NZHPT Newsletter 19, 6 (1983).
Weisler, M. I. Henderson Island prehistory: colonization and extinction on a remote Polynesian island. Biological Journal of the Linnean Society 56, 377–404 (1995).
Métraux, A. Ethnology of Easter Island. (1940).
Maury, R. C., Guille, G., Guillou, H., Blais, S. & Brousse, R. Notice explicative, feuille Rurutu et Tubuai, Polynésie française. (BRGM, 2000).
Bellwood, P. Archaeological Research in the Cook Islands. (B.P. Bishop Museum, 1978).
Pollock, R., Tennison, J., Kellogg, G. & Herman, I. Metadata Vocabulary for Tabular Data. https://www.w3.org/TR/tabular-metadata/ (2015).
Tennison, J., Kellogg, G. & Herman, I. Model for Tabular Data and Metadata on the Web. https://www.w3.org/TR/tabular-data-model/ (2015).
Hermann, A. & Forkel, R. pofatu/pofatu-data: Pofatu, a curated and open-access database for geochemical sourcing of archaeological materials. Zenodo https://doi.org/10.5281/zenodo.3670127 (2020).
Wilkinson, M. D. et al. The FAIR Guiding Principles for scientific data management and stewardship. Scientific Data 3 (2016).
Wilson, G. et al. Good enough practices in scientific computing. PLOS Computational Biology 13, 1–20 (2017).
Grothendieck, G. sqldf: Manipulate R Data Frames Using SQL. (2017).
Wickham, H. The Split-Apply-Combine Strategy for Data Analysis. Journal of Statistical Software 40, 1–29 (2011).
Willison, S. Datasette. Zenodo https://doi.org/10.5281/zenodo.2698171 (2019).
Forkel, R. pofatu/pypofatu: Python package to curate Pofatu data. Zenodo https://doi.org/10.5281/zenodo.3628155 (2020).
Forkel, R. et al. clld/clld: cllda - a toolkit for cross-linguistic databases. Zenodo https://doi.org/10.5281/zenodo.3609219 (2017).
Acknowledgements
Financial, administrative, and conceptual support for the Pofatu Database was provided by the Department of Linguistic and Cultural Evolution (MPI-SHH, Jena) and its director Prof Russell Gray. Australian Research Council grants DP0986542, DP0773909, and LE0989067 to Prof Marshall Weisler and colleagues.
Author information
Authors and Affiliations
Contributions
A.H. and R.F. conceived and designed the Pofatu database. A.H. wrote the data descriptions and compiled the data with feedback and specialist contributions from all authors. R.F. conceptualized and designed the implementation. A.H. and R.F. wrote the first draft of the manuscript, which was then revised and approved by all authors.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Online-only Table
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
The Creative Commons Public Domain Dedication waiver http://creativecommons.org/publicdomain/zero/1.0/ applies to the metadata files associated with this article.
About this article

Cite this article
Hermann, A., Forkel, R., McAlister, A. et al. Pofatu, a curated and open-access database for geochemical sourcing of archaeological materials. Sci Data 7, 141 (2020). https://doi.org/10.1038/s41597-020-0485-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-020-0485-8
