
Abstract
As the most abundant animals on earth, nematodes are a dominant component of the soil community. They play critical roles in regulating biogeochemical cycles and vegetation dynamics within and across landscapes and are an indicator of soil biological activity. Here, we present a comprehensive global dataset of soil nematode abundance and functional group composition. This dataset includes 6,825 georeferenced soil samples from all continents and biomes. For geospatial mapping purposes these samples are aggregated into 1,933 unique 1-km pixels, each of which is linked to 73 global environmental covariate data layers. Altogether, this dataset can help to gain insight into the spatial distribution patterns of soil nematode abundance and community composition, and the environmental drivers shaping these patterns.
Measurement(s) | Abundance • Nematoda • environmental factor |
Technology Type(s) | Elutriative Centrifugation • computational modeling technique |
Factor Type(s) | geographic location |
Sample Characteristic - Organism | Nematoda |
Sample Characteristic - Environment | soil environment • climate |
Sample Characteristic - Location | Earth (planet) |
Machine-accessible metadata file describing the reported data: https://doi.org/10.6084/m9.figshare.11925843
Similar content being viewed by others

Background & Summary
To generate a global and quantitative understanding of the biogeography of soil organisms, critical players in global biogeochemistry, large and comprehensive datasets are needed. Due to methodological challenges and the labor-intensiveness of characterizing soil biota, many previous studies have focused on a relatively limited number of spatially distinct sampling sites. Whilst these studies are valuable to dissect local and regional scale patterns, they may not hold the depth of information that is needed to feed global-scale models1.
Soil nematodes are present in all trophic levels in the soil food web, play central roles in regulating carbon and nutrient dynamics, control soil microorganism populations2,3,4 and, consequently, are good indicators of biological activity in soils5. Here, we present a dataset of 6,825 spatially distinct soil nematode samples from all terrestrial biomes and continents, an updated version of the dataset that was originally used to create a global map of soil nematode abundance and community composition6. The original version contained 6,759 samples; the updated version that we present here contains 66 additional samples located in Ireland. This dataset can prove useful to disentangle the effects of environmental drivers of soil nematode abundance and community composition across broad spatial scales. The original version of this dataset was used to create a high-resolution map of soil nematode abundance, which revealed that nematodes are present in higher densities in sub-Arctic regions compared to tropical and temperate regions6. Soil properties are the primary drivers of soil nematode abundance, whereas climatic conditions have an indirect effect by altering soil conditions6. The overall latitudinal gradient, with decreasing abundance towards the equator, is the inverse of patterns often observed in aboveground organisms, but is in line with what has been shown for other belowground biota7,8.
Besides data on the total number of nematodes per sample, the dataset contains quantification of the abundance of individuals in different functional groups of soil nematodes classified according to five feeding guilds9: bacterivores, fungivores, herbivores, omnivores, predators. For geospatial mapping, these sampling data were aggregated into 1,933 unique 30 Arc-seconds pixels (~1 km2 at the equator) and combined with 73 global covariate layers including information on soil physiochemical properties, and vegetation, climate, and topographic, anthropogenic, and spectral reflectance information. We intend to continue expanding the dataset and are open to contributions of additional data.
Methods
Data collection
The methods described here are expanded versions of descriptions in our related work6. The dataset encompasses georeferenced data on soil nematode abundances according to trophic groups, which were assigned according to Yeates et al.9. In total, the dataset contains 6,825 georeferenced samples collected in the top 15 cm of soils, including 66 additional samples compared to the dataset used in our related work6. Across all samples, 67.2% originate from natural sites and 32.8% from agricultural or managed sites. Nematodes were extracted from soil using standard elutriation methods, including the Baermann funnel method10, sugar-floatation/centrifugation11,12, decanting and sieving13, Oostenbrink elutriation14, Whitehead tray15 and Seinhorst elutriation16. These methods may include variations of the original methods. Most samples present in the dataset were obtained using the Baermann funnel method, followed by Oostenbrink elutriation and sugar-flotation (Jenkins/Freckman) (Fig. 1). Per-sample method descriptions, sampling depth, and data provider information are available via figshare17. For previously published data, we provide references to the original publications of the respective samples.

Nematode extraction methods used. The majority of the samples were processed using the Baermann funnel method and Oostenbrink elutriation.
Environmental metadata: soil, climate, topography, vegetation, anthropogenic characteristics
For all sampling locations we provide paired environmental metadata, which can be used to provide insight into the environmental drivers of soil nematode abundance and community composition across spatial scales. To do so, we first prepared a covariate stack of 73 layers, for which we downloaded the covariate layers as geotiff files. Next, all layers were resampled and reprojected to a unified pixel grid in EPSG:4326 (WGS84) at 30 arc-seconds resolution. Layers with a higher original pixel resolution were downsampled using a mean aggregation method; layers with a lower original resolution were resampled using simple upsampling (i.e. without interpolation) to align with the higher resolution grid. Next, all layers were converted into a multiband image, i.e. the covariate stack, that was used for pixel sampling.
To prepare the dataset for this purpose, we first need to match the resolution of the dataset to that of the global covariate layer stack that contains the environmental metadata: 30 arc-seconds, which corresponds to approximately 1-km2 at the equator. In this step, we aggregate all data points falling within the same pixel by taking the mean value, resulting in 1,933 unique pixels. We stress that the covariate layer stack has no coverage in Antarctica and therefore the 503 samples located in this region were dropped at the pixel aggregation step. Next, pixel values across the 73 layers were retrieved and stored as a csv file. This dataset is available via figshare17. We stress that, as some covariate layers were reprocessed since the publication of the nematode mapping study6, there are some slight differences in the sampled covariate data in this updated version. The approach is visualized in Fig. 2.

Data processing approach. 6,825 georeferenced samples are included in the raw dataset. These sampling locations represent 1,933 unique 30 arc-seconds pixels (~1 km at the equator), or 1,895 pixels excluding locations falling off the covariate grid. To gain mechanistic insights and discern the major environmental drivers of nematode abundance, these pixels were sampled across 73 global covariate layers.
Full metadata, including descriptions, units, and source information of all global covariate layers are available via figshare17. In short, information about soil texture and physiochemical properties was obtained from SoilGrids18, limited to the upper soil layer (top 15 cm). Climate information was obtained from WorldClim19 (version 2), which includes climate data averaged across 1970–2000 (http://www.worldclim.org/). Plant productivity data (i.e. EVI, NDVI, Gpp, Npp) and spectral reflectance data were obtained from Google Earth Engine (https://developers.google.com/earth-engine/datasets/). Aridity index and potential evapotranspiration layers were obtained from CGIAR20 (version 1) (http://www.cgiar-csi.org/data/global-aridity-and-pet-database). Anthropogenic information (i.e. human development, population density) was obtained from WCS21 (http://wcshumanfootprint.org) and from Tuanmu and Jetz22. Aboveground biomass data was obtained from CDIAC23 (https://cdiac.ess-dive.lbl.gov/epubs/ndp/global_carbon/carbon_documentation.html). Radiation data was obtained from CliMond24 (https://www.climond.org/BioclimRegistry.aspx#BioclimFAQ). WWF Ecoregion classifications were used to categorize sampling locations into biomes (https://www.worldwildlife.org/biome-categories/terrestrial-ecoregions).
Data Records
All data are available via figshare17. Raw nematode abundance data (6,825 samples) are available as a csv file: “nematode_full_dataset_wBiome.csv”. Sample IDs 20001–20066 are samples not present in our related work6. Abundance data aggregated into 30 Arc-seconds pixels (1,933 unique locations), combined with environmental covariate data are available as a csv file: “nematode_abundance_aggregated_wCovar.csv”. Full metadata, including descriptions, units, and source information, of all global covariate layers are available as a csv file: “metadata.csv”.
Technical Validation
Soil nematode abundances are highly variable within and across terrestrial biomes6. On average, the number of nematodes per 100 g dry soil is in the few hundred – few thousand range (median = 859, mean = 2,671), although the highest recorded abundances exceed 20,000 nematodes per 100 g dry soil. Across biomes, bacterivores are the most abundant trophic group and predatory nematodes the least abundant (Table 1). Overall, the highest abundances are observed in tundra (median = 2,695 nematodes per 100 g dry soil), temperate broadleaf forest (median = 2,119) and in boreal forest (median = 2,016) soils. The lowest abundances are observed in Mediterranean forest (median = 374), flooded grasslands (median = 124), Antarctic (median = 89) and hot desert (median = 44) soils (Fig. 3, Table 2). We stress that these numbers slightly differ from the values reported in our accompanying paper6, where we reported the aggregated pixel median values.

Nematode communities vary across biomes. The median and interquartile range of nematode abundances (n = 6,825) per biome from all continents.
As with any global ecological dataset, combining data from many researchers across the world, there is inherent variation in the data. Also, the different nematode extraction methods may vary in their efficiencies25,26. This underscores the need for large datasets for global scale analyses of ecological patterns. When a sufficiently large sample size allows to detect strong patterns through this statistical noise, we can be confident that a biological pattern exists6. As a consequence, there may be limitations to the use of the dataset at finer scales. Yet, by subsetting the dataset by extraction method or region, for example, it can serve as a starting point for local scale studies.
Environmental representativeness of the dataset
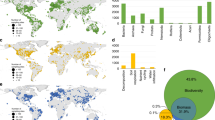
To evaluate the comprehensiveness of the dataset, we explored the environmental conditions that the sampling locations represent. Across individual environmental variables, the samples represent a wide range of environmental conditions (Fig. 4). To gain spatial insight into the environmental representativeness of the dataset, information that is important when comparing observations across spatial scales, we evaluated how the multidimensional environmental space covered by the dataset compares to the global environmental space. To do so, we used a similar approach as in our previous work6. First, we set out to reduce the computational load, as exploring the full stack of 73 global environmental covariate layers across ~210 million terrestrial pixels would require exorbitantly large computing power. To this end, we transformed the set of global environmental covariate layers into Principal Component (PC) space. We reduced the number of selected PCs to 17, collectively explaining more than 90% of variation. Next, we assessed the proportion of the world’s terrestrial pixels falling within convex hulls of the 136 bivariate combinations of the 17 PCs. The resulting map provides a spatially-explicit depiction of the representativeness of the dataset, showing that the majority of the terrestrial pixels fall within these convex hulls, with most of the outliers existing in arid regions such as the Sahara and Arabian Deserts, and in sub-arctic regions such as the far north of Canada and Russia (Fig. 5).

Environmental representativeness of the dataset. The sampled locations represent a wide range of environmental conditions. For illustrative purposes, ten environmental variables were chosen from the full set of 73.

Assessment of the representativeness of the dataset in multivariate environmental space. The map displays the percentage of pixels that fall within the convex hulls of the first 17 principal component spaces (collectively covering >90% of the sample space variation).
Code availability
Code is available via https://github.com/hooge104/2020_global_nematode_dataset.
References
Crowther, T. W. et al. The global soil community and its influence on biogeochemistry. Science 365, eaav0550 (2019).
Crowther, T. W., Boddy, L. & Jones, T. H. Species-specific effects of soil fauna on fungal foraging and decomposition. Oecologia 167, 535–545 (2011).
Ferris, H. Contribution of nematodes to the structure and function of the soil food web. J. Nemat. 42, 63–67 (2010).
Ingham, R. E., Trofymow, J. A., Ingham, E. R. & Coleman, D. C. Interactions of bacteria, fungi, and their nematode grazers: effects on nutrient cycling and plant growth. Ecol. Monogr. 55, 119–140 (1985).
Neher, D. Role of nematodes in soil health and their use as indicators. J. Nemat. 33, 161–168 (2001).
van den Hoogen, J. et al. Soil nematode abundance and functional group composition at a global scale. Nature 572, 194–198 (2019).
Bahram, M. et al. Structure and function of the global topsoil microbiome. Nature 560, 233–237 (2018).
Phillips, H. R. P. et al. Global distribution of earthworm diversity. Science 366, 480–485 (2019).
Yeates, G. W., Bongers, T., De Goede, R. G. M., Freckman, D. W. & Georgieva, S. S. Feeding habits in soil nematode families and genera–an outline for soil ecologists. J. Nematol. 25, 315–331 (1993).
Baermann, G. Eine einfache methode zur auffindung von Ancylostomum (Nematoden) larven in erdproben. Geneeskd Tijdschr Ned Indie 57, 131–137 (1917).
Jenkins, W. R. A rapid centrifugal-flotation technique for separating nematodes from soil. Plant Dis. Rep. 48, 692 (1964).
Freckman, D. W. & Virginia, R. A. Low-diversity antarctic soil nematode communities: distribution and response to disturbance. Ecology 78, 363–369 (1997).
Flegg, J. J. M. Extraction of Xiphinema and Longidorus species from soil by a modification of Cobb’s decanting and sieving technique. Ann. Appl. Biol. 60, 429–437 (1967).
Oostenbrink, M. Estimating nematode populations by some selected methods. Nematology 6, 85–102 (1960).
Whitehead, A. G. & Hemming, J. R. A comparison of some quantitative methods of extracting small vermiform nematodes from soil. Ann.Appl. Biol. 55, 25–38 (1965).
Seinhorst, J., others. The relation between nematode density and damage to plants. Nematologica 11, 137–154 (1965).
van den Hoogen, J. et al. A global database of soil nematode abundance and functional group composition. figshare, https://doi.org/10.6084/m9.figshare.c.4718003 (2020).
Hengl, T. et al. SoilGrids250m: Global gridded soil information based on machine learning. PLoS ONE 12, e0169748 (2017).
Fick, S. E. & Hijmans, R. J. WorldClim 2: new 1-km spatial resolution climate surfaces for global land areas. Int. J. Climatol 37, 4302–4315 (2017).
Zomer, R. J., Trabucco, A., Bossio, D. A. & Verchot, L. V. Climate change mitigation: A spatial analysis of global land suitability for clean development mechanism afforestation and reforestation. Agr. Ecosyst. Environ. 126, 67–80 (2008).
Venter, O. et al. Global terrestrial human footprint maps for 1993 and 2009. Sci. Data 3, 160067 (2016).
Tuanmu, M.-N. & Jetz, W. A global 1-km consensus land-cover product for biodiversity and ecosystem modelling: Consensus land cover. Global Ecol. Biogeogr. 23, 1031–1045 (2014).
Ruesch, A. & Gibbs, H. K. New IPCC Tier-1 global biomass carbon map for the year 2000, https://cdiac.ess-dive.lbl.gov (2008).
Kriticos, D. J. et al. CliMond: global high-resolution historical and future scenario climate surfaces for bioclimatic modelling: CliMond: climate surfaces for bioclimatic modelling. Methods Ecol. Evol. 3, 53–64 (2012).
De Goede, R. G. & Verschoor, B. The nematode extraction efficiency of the Oostenbrink elutriator-cottonwool filter method with special reference to nematode body size and life Strategy. Nematology 2, 325–342 (2000).
Cesarz, S., Schulz, A. E., Beugnon, R. & Eisenhauer, N. Testing soil nematode extraction efficiency using different variations of the Baermann funnel method. Soil Org. 91, 61–72 (2019).
Acknowledgements
We are thankful to Walter S. Andriuzzi and Louise E. Jackson for help in the initial phases of this study and for providing data. This research was supported by a grant from DOB Ecology to T.W.C., a grant from the Netherlands Organization for Scientific Research (grant 016.Veni.181.078) to S.G., grants from NSF (OPP 1115245, 1341736, 0840979) to B.J.A., by a Ramon y Cajal fellow award (RYC-2016-19939) to R.C.H., a grant from UNEP & Global Environment Facility to J.E.C., grants from NERC’s Soil Security Programme to R.D.B. (NE/M017028/1) T.C. (NE/M017036/1), a grant from FAPEMIG/FAPESP/VALE S.A.(CRA-RDP-00136-10) to L.B.C., through the strategic programme UID/BIA/04050/2013 (POCI-01-0145-FEDER-007569) awarded to S.R.C., a grant from CNPq PROTAX (562346/2010-4) to J.M.d.C.C., a grant from DFG (CRC990) to V.K. and S.S., a grant from the MSHE of Russia (AAAA-A17-117112850234-5) to A.A.K., grants from the Chinese Academy of Sciences (XDB15010402) and the National Natural Science Foundation of China (41877047) to Q.L., grants from the National Natural Science Foundation of China (31330011, 31170484) to W.L., grants from NERC (NE/M017036/1) to M.M., grants from the Spanish Ministry of Innovation (CGL2009-14686-C02-01/02, CGL2013-43675-P) to J.A.R.M., grant from the Spanish Ministry of Innovation (RYC-2016-19939) to R.C.H., grants from NSF (DEB-0450537, DEB-1145440) to P.M., T.O.P. and K. Powers, grants from the German Academic Exchange Service (PKZ 91540366) and NAFOSTED (106.05–2017.330) to T.A.D.N., by an ARC Discovery project (DP150104199) to U.N.N., by the National Key Research and Development Program of China (2016YFC0502101) and the National Natural Science Foundation of China (31370632) to K. Pan, a ERC Research Council Advanced grant (ERC-Adv 323020 SPECIALS) to W.H.v.d.P, a grant from the Natural Environment Research Council (NERC) to D.G.W., a grant from BAPHIQ (106AS-9.5.1-BQ-B3) to J.-i.Y., a grant from the Russian Foundation for Basic Research (18-29-05076) to A.V.T. The James Hutton Institute receives financial support from the Scottish Government Rural and Environment Science and Analytical Services (RESAS) division. Investigations in Northwest Russia were carried out under state order for IB KarRC RAS and are partially supported by the Russian Foundation for Basic Research (18-34-00849).
Author information
Authors and Affiliations
Contributions
J.v.d.H., S.G., D.R. and T.W.C. designed and performed the data analyses. S.G., H.F., W.T., D.A.W., R.G.M.d.G., B.J.A., W.A., W.S.A., R.D.B., M.B., R.C.H., J.E.C., T.C., X.C., S.R.C., R.C., J.M.C.C., M.D., L.B.C., D.D., M.E., B.S.G., C.G., K.H., D.K., P.K., A.K., G.K., V.K., A.A.K., Q.L., W-J.L., M.M., M.M., J.A.R.M., E. Matveeva, E.H.M., E. Mzough, C.M., P.M., R.N., T.A.D.N., U.N.N., H.O., J.E.P.R., K.P., V.P., L.P., J.C.P.S., C.P., T.O.P., K.P., C.W.Q., S.R., S.M., S.S., H.S., A.S., A.V.T., J.T., W.H.v.dP., M.V., C.V., L.W., D.H.W., R.A.W., D.G.W., J.-I.Y., O.S. R.B., Z.F., and A.M.K. contributed data. J.v.d.H., S.G. and T.W.C. wrote the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
The Creative Commons Public Domain Dedication waiver http://creativecommons.org/publicdomain/zero/1.0/ applies to the metadata files associated with this article.
About this article

Cite this article
van den Hoogen, J., Geisen, S., Wall, D.H. et al. A global database of soil nematode abundance and functional group composition. Sci Data 7, 103 (2020). https://doi.org/10.1038/s41597-020-0437-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-020-0437-3
This article is cited by
-
Global fine-resolution data on springtail abundance and community structure
Scientific Data (2024)
-
Metagenomics and metatranscriptomics as potential driving forces for the exploration of diversity and functions of micro-eukaryotes in soil
3 Biotech (2023)
-
Temporal changes of topsoil nematode communities in rubber plantations in Ivory Coast in response to logging residue management and legumes introduction
Plant and Soil (2023)
-
Long-Term Plant Community Removal Alters Soil Nematode Communities Mainly Through the Trophic Cascading Effects of Fungal Channel
Journal of Soil Science and Plant Nutrition (2023)
-
Whole-genome sequencing and analysis of Streptomyces strains producing multiple antinematode drugs
BMC Genomics (2022)
