
Abstract
The data described in this paper were collected in two watersheds – Azuga-suba watershed in Angacha woreda (district) of Southern Nations, Nationalities and Peoples (SNNP) region and Yesir watershed of Bure woreda (district) of the Amhara region – in Ethiopia. The data were collected from 379 households with the main objective being to assess the factors constraining the adoption of sustainable land management technologies (SLMT) that enhance soil organic carbon sequestration. The data were collected using a structured questionnaire that was designed in SurveyCTO. The data cleaning and analysis was done using STATA SE version 14. This data can be used by researchers to assess the extent of adoption of SLMTs in Ethiopia by, for example, comparing the North and the South regions of Ethiopia. It can also be used to assess the probability of adoption as well as the benefit and costs of adopting SLMTs in Ethiopia both at farm and plot level.
Measurement(s) | Socioeconomic Factors • Access • wealth • plot specific information • agricultural process • forestry • soil conservation activity • Demographics |
Technology Type(s) | Survey |
Sample Characteristic - Environment | farm • farm soil |
Sample Characteristic - Location | Ethiopia |
Machine-accessible metadata file describing the reported data: https://doi.org/10.6084/m9.figshare.11830887
Similar content being viewed by others
Background & Summary
Soil degradation is the main reason for the continued poor agricultural productivity in sub-Saharan Africa (SSA)1 with degraded agricultural land accounting for 65%. This is mainly due to low nutrient application, soil erosion, acidification and sodification2. With the population of the SSA projected to double by the year 20503, soil degradation and low agricultural productivity pose a threat to the human population. Soil degradation is attributed to reduced soil organic carbon (SOC)4 that enhances soil fertility by improving soil water holding capacity, cation exchange capacity & soil aggregation and reducing the soil susceptibility to crusting and soil erosion5,6. Loss of SOC is mainly attributed to land-use changes especially the conversion of natural vegetated lands such as forests and grasslands to cultivated land. Evidence from published research shows that conversion of marginal lands may not lower SOC stocks, instead, application of sustainable land management technologies (SLMTs) that encourage constant retention of stubble in the soil may lead to the build-up of SOC at a high percentage with time7,8.
Sustainable land management technologies (SLMTs) ensures sustainable agricultural production and livelihoods, in the long run, improving the standards of living of households and improving agricultural productivity9,10,11. Developing countries have been making constant efforts to increase farmers’ adoption of SLMTs. In Ethiopia for example, programs such as Poverty Reduction Strategic Paper I, Plan for Accelerated and Sustained Development to End Poverty (PASDEP), Agricultural Transformation Programs (ATP), Agricultural Growth Program (AGP), Production Safety Net programs (PSNPs), Food Security programs, and many other programs and projects have been implemented over the past decades12,13,14,15. Despite these efforts, adoption of SLMTs has remained low and farmers continue to practice conventional farming that leads to the continued depletion of SOC with continued soil degradation affecting agronomic productivity5.
Past research on the factors affecting the adoption of SLMTs in Kenya and Ethiopia show that factors that constrain adoption of SLMTs include farming technologies adopted by households, agro-ecological variations, plot characteristics, farmer social-economic characteristics and institutional assistance16,17,18. Social-economic characteristics that are known to affect the adoption of SLMTs include; education level of the household head, farming experience, gender, plot size, tenure security, membership in farmer groups, agricultural extension, distance to plots, market access, credit access, livestock ownership and household size19,20 while biophysical characteristics include, plot slope, rainfall, soil type and soil erosion21. Through the years of constant effort-making from the government, non-governmental institutions and individual efforts, farmers have adopted the SLMTs at a lower percentage. This study seeks to find out the extent that farmers have adopted the SLMTs and the factors that constrain the adoption. The data described in this paper were used to evaluate the extent of adoption of SLMTs and what constraints their adoption. The data contains information on socio-economic factors, plot-specific characteristics, institutional factors, wealth ranking, marketing, and information relating to the access to infrastructure that supports farmers’ development22. The data also contains information on the types of crops grown and animals kept, their productivity and marketing.
The survey tool that was used to collect the data was reviewed thoroughly and approved by the Internal Review Board (IRB) of the International Centre for Tropical Agriculture (CIAT) before the study was carried out similar to22. In addition, each farmer was asked to sign a consent form as an indication that they were willing to be interviewed. The sampled areas represented the highland areas of Ethiopia characterized by an annual rainfall of above 1000 mm and where farmers practice mixed cropping and livestock farming systems. Therefore, this data can be used in a broader category to assess the dimensions of household financial, human, physical and social capital in the study sites and other areas with similar characteristics to the study sites as represented. It could also be used for comparison with similar household-level surveys in other study sites. In a similar study as was used in this research, the data can be utilized to carry out further research on the extent of adoption of specific SLMTs, the probability of adoption in the study, reasons behind farmers’ decision to implement particular SLMTs, and benefits and costs of adopting SLMTs by farmers.
Methods
Data collection
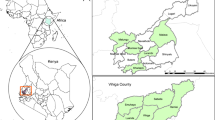
The data were collected from households drawn from two watersheds Yesir and Azuga-Suba. Yesir watershed is located in Bure district (Woreda), Western Gojjam Administrative Zone in Amahara Region, while the Azuga-Suba watershed is located in Kembata Tembaro Woreda, and Wolaita Administrative Zone in the Southern Region (Fig. 1).

A map of Ethiopia showing the studied watersheds and the sampled pastoral areas.
A two-stage, multistage sampling technique was utilized to generate the sample. The central aim of the sampling design was to obtain households that were representative of the various household groups and landscapes of the two watersheds. In the first stage, the Kebele Administrations (also referred to as Pastoral associations (PA) which is the lowest administrative structure in the watershed (a watershed comprised of several PAs) were categorized into three zones: PAs in the upper zone, middle and lower zones. In line with this, one PA on the upper zone, two PAs in the middle zone and one PA from the lower zone of the watershed were randomly selected from the existing PAs in each category summing up to four PAs per watershed. Two PAs were selected in the middle zones due to high population distribution in these zones. Accordingly, households that have a plot of land within the watershed in the four selected PAs were used as the sampling frame. In the second stage, and using this sample frame, the numbers of sample households in each PA were allocated as a proportion to the number of households in the PAs. Accordingly, 161 households in the four PAs in Azuga-suba watershed and 218 households in the four PAs in Yesir watershed were drawn randomly from the PAs household roster which gives a total sample of 379 households. The selected households represented various levels of wealth categories with different socioeconomic and biophysical characteristics. In order to avoid missing responses, only those households that had a plot of land in the watershed were included in the sampling. When the selected household was not accessible, he/she was replaced by the next household in the list. The distribution of sampled households across watersheds and PAs was as summarized in Table 1.
Household data from the sample households were collected using a structured questionnaire. The main focus of the questionnaire was key household characteristics that are known and/or expected to influence the adoption of SOC enhancing land management practices and included detailed questions on the various SOC enhancing practices. The enumerators involved in this study were trained for one day followed by pre-testing of the tool to ensure that they understood the questions properly as well as how to key in SurveyCTO. The enumerators were also made aware of the common mistakes that may occur during the survey. Data collection was carried out by six enumerators in each watershed. The collected data was checked by the supervisors on a daily basis and appropriate correction measures were taken.
Data Records
This data are available as.dta, Rdata or as tab-delimited. .dta opens in Stata and from it can be converted into other formats such as .csv or.xls formats, Rdata opens in R while tab-delimited format can be opened in excel and converted into .csv or xls formats. Missing values were identified with a dot, which is the universal manner of denoting missing values in Stata. The data is stored in the Harvard Dataverse Repository under the International Center for Tropical Agriculture (CIAT) Dataverse (CGIAR)23.
The data were arranged as in the survey questionnaire that was divided into six sections containing 10 parts namely; household characteristics, details about household demography, household wealth indicators liquidation, household’s access to infrastructural services, plots of land owned and operated, input use, soil conservation and agroforestry activities, access to output markets, access to credit and access to extension services. The sections were Household characteristics, Plot level data, About carbon enhancing practices, Market participation and credit access, Social capital and contact information. The introductory part involved the collection of general information of the study area. Part one of section one covered household characteristics including the respondent’s name, gender, place of birth and years of farming for the household head. Part two gave the details of all household members; age, schooling, work, marital status and participation in farming activities. Part three collected details on wealth indicators including livestock holding while part four collated information about household’s access to infrastructures.
Section two contained two parts: parts five and six. Part five contained plot-level data such as the number of plots owned, the number of plots operated in 2017, size of each plot, type of crops grown on each plot, farm activities, yield per crop, residue management, soil type, slope, distance of the plots from the households, soil erosion, soil and water conservation activities and land ownership. Data on input use, quantity, and purchasing price were contained in part 6.
Section three contained only part seven with information on soil and water conservation, agroforestry activities and factors enhancing soil organic carbon.
Section four contained part eight to 10. Part 8 had details on farmers’ access to output markets, crops sold, their quantities and their market prices, while part nine contained data on access to credit services. Part 10 contained details on access to extension services. This was followed by section five and six.
In this survey, the household head was targeted but in case of his/her absence, other respondents such as the wife or any other respondent with over 18 years of age and more than five years’ experience in farming were interviewed. Table 2 below shows the description of the dataset as per the questionnaire with the themes that were generated from the questionnaire22.
Technical Validation
The data described above are cross-sectional and were obtained by interviewing individual farmers. For plot level biophysical and social-economic information, it was difficult to ascertain the ability of the tool to collect quality information as most of it was based on farmers’ perceptions and proxies. For example, in plot-level information as presented in Table 2, plot sizes were obtained from the farmers’ perception of the sizes of each plot and in some cases the enumerators had been trained to ask the total farm size and divide it into the number of plots in the farm, in case the farmer did not know the size of their plots, this would be provided in local units which would later be converted into standard units. Tenure security was represented by the farmer owning a title deed, distance to the plot would be a farmer estimation of the number of minutes they would take to walk to a specific plot, the plot slope was divided into two categories, plain and sloppy while the soil type was divided into three categories, loamy, sandy and clay and enumerators trained to differentiate each by looking at it or by the farmers colour description.
It is normal for this sort of information to have a few issues, for example, missing data or under or over-reporting. To correct this challenge, SurveyCTO was utilized whereby all the required information was captured exhaustively by giving options of choice as well as multiple categories covering all variables anticipated to be collected. This involved conducting focus group discussions and key informant interviews before the tool development and coding in the SurveyCTO, to ensure that responses to each question were captured well. The over and under-reporting of various variables such as output and price were also checked against the average outputs in the region as well as the prevailing market prices. Addition information was also collected on notebooks and later incorporated into the tool to enhance the quality of data.
Usage Notes
The data is available in Stata data format and can be opened using Stata program Version 13 and above. In case a user has an older version of Stata, a means of converting the data to a compatible form is provided in Stata. For those who do not have access to Stata software, Statistical Package for Social Sciences (SPSS) software can also be utilized to open the data, under the import tab provided they specify that the data is in Stata data format (.dta). In addition to this, R an open-source software can also be used by exporting this data to comma-separated values (.csv) and importing it into R. The questionnaire that was used to collect the data is also provided together with the data to facilitate ease of understanding of the data.
References
Zingore, S., Mutegi, J., Agesa, B., Desta, L. T. & Kihara, J. Soil degradation in sub-Saharan Africa and crop production options for soil rehabilitation. Better Crops 99, 24–26 (2015).
Food and Agriculture Organisation (FAO) and Intergovernmental Technical Panel on Soils (ITPS). Regional Assessment Of Soil Changes In Africa South Of The Sahara. Main Report. (FAO & ITPS, 2015).
Food and Agricultural Organization (FAO). The Future Of Food And Agriculture - Trends And Challenges. (FAO, 2017).
Lal, R. Restoring soil quality to mitigate soil degradation. Sustainability 7, 5875–5895 (2015).
Lal, R. Enhancing crop yields in the developing countries through the restoration of the soil organic carbon pool in agricultural lands. Land Degrad. Dev. 17, 197–209 (2006).
National Research Council. Soil And Water Quality: An Agenda For Agriculture. (The National Academies Press, 1993).
Manna, M. C. et al. Influence Of Different Land-use Management on Soil Biological Properties And Other C Fractions Under Semi-Arid Benchmark Soils Of India. Global Theme on Agro-ecosystems Report no. 41. (International Crops Research Institute for the Semi-Arid Tropics (ICRISAT), 2008).
Paustian, K., Six, J., Elliott, E. T. & Hunt, H. W. Management options for reducing CO2 emissions from agricultural soils. Biogeochemistry 48, 147–163 (2000).
Lal, R. Sequestering carbon in soils of agro-ecosystems. Food Policy 36, S33–S39 (2011).
Pretty, J. N. et al. Resource-conserving agriculture increases yields in developing countries. Environ. Sci. Technol. 40, 1114–1119 (2006).
Ringius, L. Soil Carbon Sequestration And The CDM Opportunities And Challenges For Africa Center For International Climate And Environmental Research. Center for International Climate and Environmental Research (CICERO) Report 1999:7 (UNEP Collaborating Centre on Energy and Environment (UCCEE), 1999).
U.S. Government’s Global Hunger & Food Security Initiative. Global Food Security Strategy (GFSS) Ethiopia Country Plan. (Feed the Future, 2018).
Fock, A. Agricultural Growth Project (Agp) Project Information Document (Pid) Appraisal Stage. Report No. AB5416 (Ministry of Agriculture and rural development - Ethiopia (MoARD), 2010).
Ministry of Finance and Economic Development (MoFED). A Plan For Accelerated And Sustained Development To End Poverty (PASDEP). (MoFED, 2006).
Teshome, A. Agriculture, Growth And Poverty Reduction In Ethiopia: Policy Processes Around The New PRSP (PASDEP). A paper for the Future Agricultures Consortium Workshop (University of Sussex, 2006).
Etsay, H., Negash, T. & Aregay, M. Factors that influence the implementation of sustainable land management practices by rural households in Tigrai region, Ethiopia. Ecol. Process. 8, 14 (2019).
Kassie, M., Zikhali, P., Manjur, K. & Edwards, S. Adoption of sustainable agriculture practices: Evidence from a semi-arid region of Ethiopia. Nat. Resour. Forum 33, 189–198 (2009).
Liu, T., Bruins, R. & Heberling, M. Factors influencing farmers’ adoption of best management practices: A review and synthesis. Sustainability 10, 432 (2018).
Nyangena, W. Social determinants of soil and water conservation in rural Kenya. Environ. Dev. Sustain. 10, 745–767 (2008).
Tenge, A. J., De Graaff, J. & Hella, J. P. Social and economic factors affecting the adoption of soil and water conservation in West Usambara highlands, Tanzania. Land Degrad. Dev. 15, 99–114 (2004).
Riar, A. et al. A diagnosis of biophysical and socio-economic factors influencing farmers’ choice to adopt organic or conventional farming systems for cotton production. Front. Plant Sci. 8, 1289 (2017).
Kanyenji, G. M., Ng’ang’a, S. K. & Girvetz, E. H. Survey data on factors that influence the adoption of soil carbon enhancing practices in Western Kenya. Sci. Data, https://doi.org/10.1038/s41597-020-0374-1 (2020).
Ng’ang’a, S. K., Gelaw, F., Nguru, W. M., Kanyenji, G. M. & Girvetz, E. An integrated approach for understanding the factors that facilitate or constrain the adoption of soil carbon enhancing practices in East Africa, Kenya and Ethiopia. Harvard Dataverse https://doi.org/10.7910/DVN/QTACSN (2019).
Acknowledgements
This work was carried out as part of a project to scale up soil carbon enhancement interventions for food security and climate across complex landscapes in Kenya and Ethiopia funded by the Federal Ministry for Economic Cooperation and Development, Germany (BMZ/GTZ - Project No. 16.7860.6e001.00; Contract No. 81206681). The project was undertaken as part of the CGIAR Research Programs on Water, Land and Ecosystems (WLE). This work was also carried out as part of the Consultative Group on International Agricultural Research Program on Climate Change, Agriculture and Food Security (CCAFS).
Author information
Authors and Affiliations
Contributions
W.N. and F.G. organized the data collection, processing, and quality control of the data sets in this paper. W.N. also organized and wrote the data paper. G.M.K. assisted in the data processing and quality control of the data sets. S.K.N. assisted with the overall review during the development of this data paper, as well as in editing the manuscript, while G.E. assisted with editing, and acquisition of resources that facilitated the collection of the data and the development of this manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
The Creative Commons Public Domain Dedication waiver http://creativecommons.org/publicdomain/zero/1.0/ applies to the metadata files associated with this article.
About this article

Cite this article
Nguru, W.M., Ng’ang’a, S.K., Gelaw, F. et al. Survey data on factors that constrain the adoption of soil carbon enhancing technologies in Ethiopia. Sci Data 7, 93 (2020). https://doi.org/10.1038/s41597-020-0431-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-020-0431-9
This article is cited by
-
Assessment of trade-offs, quantity, and biochemical composition of organic materials and farmer's perception towards vermicompost production in smallholder farms of Ethiopia
Journal of Material Cycles and Waste Management (2022)
