
Abstract
Globe-LFMC is an extensive global database of live fuel moisture content (LFMC) measured from 1,383 sampling sites in 11 countries: Argentina, Australia, China, France, Italy, Senegal, Spain, South Africa, Tunisia, United Kingdom and the United States of America. The database contains 161,717 individual records based on in situ destructive samples used to measure LFMC, representing the amount of water in plant leaves per unit of dry matter. The primary goal of the database is to calibrate and validate remote sensing algorithms used to predict LFMC. However, this database is also relevant for the calibration and validation of dynamic global vegetation models, eco-physiological models of plant water stress as well as understanding the physiological drivers of spatiotemporal variation in LFMC at local, regional and global scales. Globe-LFMC should be useful for studying LFMC trends in response to environmental change and LFMC influence on wildfire occurrence, wildfire behavior, and overall vegetation health.
Design Type(s) | database creation objective • cross validation objective • physiological process monitoring objective |
Measurement Type(s) | moisture content trait |
Technology Type(s) | digital curation |
Factor Type(s) | geographic location • environmental feature |
Sample Characteristic(s) | Earth (Planet) • United States of America • French Republic |
Machine-accessible metadata file describing the reported data (ISA-Tab format)
Similar content being viewed by others
Background & Summary
Live Fuel Moisture Content (LFMC) is the water content of live foliage relative to its dry mass, which influences vegetation susceptibility to wildfire1. Vegetation with high LFMC takes longer to ignite and leaf water acts as a heat sink, slowing down the rate of fire spread and reducing fire intensity2,3. LFMC as a measure of plant water status also has important implications for assessing drought stress in natural vegetation4, determining over and under watering practices in agricultural crops5, and assessing vegetation health6 and wildlife habitat suitability7.
Field sampling and gravimetric methods are the most direct way to estimate LFMC. These methods require in situ destructive collection of a representative sample of leaf/shoot material, which is then weighed fresh, oven-dried and reweighed to determine dry matter mass. Field sampling is labour-intensive and sampling sites must be carefully selected to represent spatial variation in LFMC and vegetation types. Sampling must also be repeated over time to capture temporal variation in LFMC. Consequently, the compilation of a database capturing broad-scale spatial and temporal variability in LFMC is not feasible with the resources of a single organization or research group. Remote sensing data provide the opportunity to predict LFMC over large areas at fine spatial and temporal resolutions, but these data also require field samples for calibration and validation1. Given the large cost of collecting field measurements of LFMC over large areas or long time periods, an international effort to compile and share existing field observations in a global database would help overcome a key constraint for the improvement and validation of LFMC remote sensing methods.
Individual universities, research centres and government departments have started to organize and share their time series of field-sampled LFMC data. For example, the U.S. National Fuel Moisture Database8 (NFMD, http://www.wfas.net/nfmd/public/index.php) is a web-based query system that enables users to view live- and dead- fuel moisture data. Chuvieco9 made available a database (FMC_UAH v1.1, http://www.geogra.uah.es/emilio/FMC_UAH.html) composed of 880 LFMC samples taken at different campaigns from 1996 to 2010 in Spain. Since 1996, the French National Forest Service (ONF) has been sampling and freely sharing weekly LFMC (www.reseauhydrique.dpfm.fr) on 35 geolocalized sites, recently quality-checked and made available by Duché et al.10,11. However, while a large number of LFMC datasets have been published in the refereed literature, much of the source data has not previously been made available to the research community.
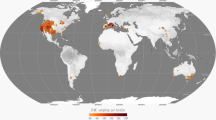
We present Globe-LFMC12, the most comprehensive global database of in situ destructive sampling measurements of LFMC. Globe-LFMC is a compilation of 161,717 field measurements carried out at 1,383 sampling sites in 11 countries from 1977 to 2018 (Fig. 1). The database is properly documented, georeferenced and publicly accessible. When available, each record has an accompanying reference. We have made all names of sampling sites and species names consistent. We have also removed duplicates and corrected inconsistencies in the LFMC data. Additionally, the database reports on the protocol used to obtain each LFMC value. Finally, we also used remote sensing to assess the heterogeneity of vegetation greenness surrounding site coordinates, since highly heterogeneous areas within a specific satellite footprint may not be suitable for the calibration or validation of remote sensing products).

Geographical distribution of LFMC samples in Globe-LFMC. Sample plots locations, and the number of observation included in the database per country as indicated by colours in the legend (Figure created with QGIS19). A majority of samples were collected in the Western US, France, Spain and Australia.
This database will lead to further advances in modeling and monitoring of spatial and temporal variation in LFMC. It should also allow evaluation of LFMC estimation methods, providing guidance for end-users in determining which LFMC estimation methods best fit their specific application. The database will also assist investigation of spatial variability in LFMC across the plant, local, and regional scales, and allow improved sampling strategies to capture spatial and temporal variation. The database can also be used to calibrate dynamic global vegetation models, eco-physiological models of plant drying as well as understanding the environmental and physiological drivers of LFMC. Finally, the database may be useful for exploring LFMC trends in response to environmental change and LFMC influence on wildfire occurrence, wildfire behaviour and overall vegetation health.
Methods
Globe-LFMC unifies existing LFMC data created and provided by researchers and agencies in different countries (Fig. 1). All of the data presented in the database were collected by in situ destructive sampling of leaf material or, occasionally, small twigs (<0.6 cm). After the mass of fresh samples was determined, samples were dried in an oven until the water was evaporated, and then the sample was reweighed to determine dry mass. LFMC is typically calculated as the percentage of water mass with respect to dry mass, and can thus be over 100%.
The sampling methods for the different data sources were slightly different in terms of the equipment used to collect the samples, the drying temperature and time and other protocols for data acquisition or processing. Globe-LFMC summarizes the sampling methods used via a unique code (see Data Records paragraph), and the detailed description of the methodology can be found in the citation of each code included in the database.
Overall, only the LFMC from leaves or small terminal twigs (<0.6 cm) was considered and added to the database. Occasionally information about other vegetation components was recorded in the source data but this information was omitted in Globe-LFMC because leaves are generally the dominant component when viewing vegetation from above and thus contribute the most to the spectral signal observed by an airborne/spaceborne sensor. Moreover, any quality control flags in the source data indicating low-quality data led to the omission of the corresponding LFMC values in Globe-LFMC.
LFMC values from samples corresponding to the same date, species and site were recorded as a mean value. This approach allowed us to maintain consistent information on every single species sampled at the same plot. However, in some instances, the sampler collected and weighed different species together in the same sample. In those situations, the “Species collected” database field contains a list of species instead of a single species. Sometimes the species were reported with their common names or with typos in the original datasets, in which case the correct genus and species was substituted.
There were some entries where the same site name was used for more than one set of geographic coordinates. In order to have a single LFMC value for each species-date-site combination, the names were modified by adding an identifier (e.g. an increasing number or the state abbreviation). Conversely, we found some entries where two or more different site names corresponded to identical geographic. Those names were unified creating a new name (e.g. from “A” and “B” to “A–B”, where A and B are two different names, or from “C1” and “C2” to “C”, where C corresponds to the word that was in common in the C1 and C2 names). Plots with missing geographic coordinates were not added to the final database.
Most of the information provided came from the original datasets, but a few columns were added to the database to provide additional insight into site characteristics. A column was added for “Land Cover” that provides information on the land cover class at the sample site obtained from the 2015 ESA Climate Change global land cover map at 300 m spatial resolution for the year 2015 (http://maps.elie.ucl.ac.be/CCI/viewer/download.php). Columns were also added for “NDVI SDmin”, “NDVI SDmax”, “NDVI CVmin” and “NDVI CVmax”. These refer to the minimum and maximum Standard Deviation and the Coefficient of Variation of the Normalised Difference of Vegetation Index (NDVI)13 within a 500 m square buffer centred on the geographic coordinate of each site. These NDVI-derived statistics were computed as indicators of the heterogeneity of the sampling sites and the area surrounding them. Filtering out heterogeneous sites may be a key site selection criteria for calibration and validation of LFMC predictions from coarser spatial resolution remote sensing products. Both NDVI Standard Deviation and Coefficient of Variation were computed from Landsat 8 Operational Land Imager data using Google Earth Engine14. Monthly mean NDVI maps were created using USGS Landsat 8 Surface Reflectance Tier 1 data and masking the pixels marked as cloud, cloud shadows, or snow, for each month for 2015 (the same year of the ESA land cover map used for the characterization of the land cover type of each site). For each of the 12 monthly maps, the standard deviation and the mean were computed within the 500 m × 500 m window. If 20% or more of NDVI values within the window were missing due to cloud and snow masking, no NDVI value was reported for that month. Consequently, every site was assigned 12 NDVI standard deviation values (one for each month) and 12 NDVI mean values. Globe-LFMC contains the minimum and maximum Standard Deviation and the Coefficient of Variation of NDVI values of every site. Finally, we also added information on slope and altitude for some sampling plots.
Description of google earth engine code
Google Earth Engine14 was used to compute the NDVI statistics added to Globe-LFMC. The input of the program is a point shapefile (“samplePlotsShapefile”, extensions.cpg, .dbf, .prj, .shp, .shx) representing the location of each Globe-LFMC site. This shapefile is available as additional data in figshare12 (see Code Availability). To run this GEE code the shapefile needs to be uploaded into the GEE Assets and, then, imported into the Code Editor with the name “plots” (without quotation marks).
The outputs of the program are 12 “.csv” files, each corresponding to a month of the year 2015. Every file contains the following statistics for the 500 × 500 m2 buffers around the coordinates of the Globe-LFMC site: NDVI SD, NDVI mean, the count of total pixels and the unmasked pixels.
The computation of NDVI statistics is performed on U.S. Geological Survey Landsat 8 Surface Reflectance Tier 1 images (https://developers.google.com/earth-engine/datasets/catalog/LANDSAT_LC08_C01_T1_SR).
Data Records
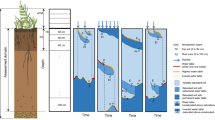
The compiled data are available in a single database in Excel format with three different interrelated spreadsheets; “Contact”, “LFMCdata” and “Protocol12” (Fig. 2). A description of the fields in each spreadsheet can be found in Tables 1, 2 and 3. Each data record represents the LFMC measurement taken at a sampling site (Sitename) at a specific time and has a unique record identification code: C(contact_id)_(Sitename _id)_(record_id). These details allow users to select and download discrete datasets for their area of interest, and to identify the contact person for each data entry.

The linkage between Globe-LFMC spreadsheets.
We plan to publish updates to LFMC-Globe as new data become available in the future. Scientists interested in sharing their data can contact the corresponding author of this manuscript to get instructions on how to share their data.
Technical Validation
The database represents a range of countries and land cover types containing LFMC values that range from 0.21–549% (Table 4). A majority of samples were collected in the Western US, due to extensive government sampling programs for assessing wildfire danger, with some time series stretching back decades. Large numbers of samples were also collected in France, Spain and Australia (Table 4). The land cover type with the largest number of observations and sites is “Tree cover, needle-leaved, evergreen, closed to open (>15%)” followed by “Shrubland”, “Grassland” and “Cropland-rainfed” (Table 5).
Data in the database have been checked for possible replications and errors. We validated the data by checking their consistency with expected LFMC ranges, noting that it is out of the scope of this paper to provide detail LFMC trend analysis as this will be the objective of future work. Globe-LFMC contains values lower than 30% which are specific to dead fuels15. Those values mostly come from partially or fully cured grassland and herbaceous plots but were also occasionally recorded in other landcovers (Table 4 and Fig. 3). If we don’t take into account those occasional outliers, the distribution of LFMC for species with significant numbers of observations (Fig. 3) shows consistency with established knowledge on the seasonal pattern of LFMC according to the type of vegetation, their strategies to cope with drought16 and their pyro-ecophysiological traits17,18. For example, Eucalyptus is a genus which includes over seven hundred species of broad-leaved trees, usually evergreen and native to Australia. Because Eucalyptus trees have roots up to more than 2.5 m in length and adapted ecophysiological traits, they can draw water from deep in the soil profile to avoid drought and therefore their LFMC only fluctuates around a value of 100% across seasons. Similarly, Quercus ilex is an evergreen broad-leaved oak native of the Mediterranean region with similar strategies. Conversely, Quercus gambelii is a deciduous broad-leaved tree widespread in western North America that shows greater LFMC variability, with values in summer significantly lower than in spring. Finally, Artemisia tridentata (drought deciduous/evergreen shrub of western North America), Cistus monspeliensis (evergreen Mediterranean shrub) and grasslands present the strongest seasonality with the highest values in spring, lowest (<30%) in summer and intermediate in autumn and winter.

Boxplots representing the seasonal LFMC of some of the species with more observations. The number of observations used to compute each box has been added. The range of dates used to identify each season was defined using the astronomical Universal Time-based equinoxes and solstices. For the countries of the northern hemisphere, Spring was considered to be between 20 March and 19 June, Summer between 20 June and 21 September, Autumn between 22 September and 20 December, Winter between 21 December and 19 March; while, in the southern hemisphere, Spring was considered to be between 22 September and 20 December, Summer between 21 December and 19 March, Autumn between 20 March and 19 June, Winter between 20 June and 21 September. (Boxplots created with Matplotlib20 library).
Usage Notes
Users of the database are encouraged to look at the available photos of the sites, whose names can be found in the “LFMC data” spreadsheet. The photos are contained in the zip folder named “photos of sites”.
If the database is to be used for remote sensing products calibration or validation, fields for minimum and maximum “NDVI SD” and “NDVI CV” are recommended to be explored for a selection of the most homogenous sites.
An extra database in Excel format (“References&Changes_LFMC.xlsx”, at figshare)12 with two spreadsheets “References” and “Changes to USA National FM db” contain information on references, copyright notices and list the changes to the original datasets. We provide this information in case a researcher would like to compare the values shown here to the original databases.
Code Availability
The Google Earth Engine (GEE)14 code and the shapefile “samplePlotsShapefile” (extensions.cpg, .dbf, .prj, .shp, .shx), used for computing the NDVI statistics are part of the data and files uploaded together with Globe-LFMC into figshare12. This code can only be run if the user has access to a Google account and to GEE.
Change history
29 November 2019
An amendment to this paper has been published and can be accessed via a link at the top of the paper.
References
Yebra, M. et al. A global review of remote sensing of live fuel moisture content for fire danger assessment: moving towards operational products. Remote Sens. Environ. 136, 455–468 (2013).
Rossa, C. G., Veloso, R. & Fernandes, P. M. A laboratory-based quantification of the effect of live fuel moisture content on fire spread rate. Int. J. Wildland Fire 25, 569 (2016).
Pimont, F., Ruffault, J., Martin-StPaul, N. K. & Dupuy, J.-L. Why is the effect of live fuel moisture content on fire rate of spread underestimated in field experiments in shrublands? Int. J. Wildland Fire 28, 127 (2019).
Dennison, P. E. et al. Modeling seasonal changes in live fuel moisture and equivalent water thickness using a cumulative water balance index. Remote Sens. Environ. 88, 442–452 (2003).
Cheng, T. et al. Detection of diurnal variation in orchard canopy water content using MODIS/ASTER airborne simulator (MASTER) data. Remote Sens. Environ. 132, 1–12 (2013).
Royle, D. D. & Lathrop, R. G. Monitoring hemlock forest health in New Jersey using Landsat TM data and change detection techniques. For. Sci. 43, 327–335 (1997).
Briscoe, N. J., Kearney, M. R., Taylor, C. A. & Wintle, B. A. Unpacking the mechanisms captured by a correlative species distribution model to improve predictions of climate refugia. Glob. Change Biol. 22, 2425–2439 (2016).
United States Government. National Fuel Moisture Database, http://www.wfas.net/nfmd/public/index.php (2009).
Chuvieco, E. et al. Field fuel moisture measurements on Spanish study sites. Department of Geography, University of Alcalá, Spain, http://www.geogra.uah.es/emilio/FMC_UAH.html (2011).
Duché, Y., Savazzi, R., Toutchkov, M. & Cabanne, E. Multisite and multispecies live fuel moisture content (LFMC) series in the french Mediterranean since 1996. Zenodo, https://doi.org/10.5281/zenodo.162978 (2017).
Martin-Stpaul, N. et al. Live fuel moisture content (LFMC) time series for multiple sites and species in the French Mediterranean area since 1996. Ann. For. Sci. 75, 57 (2018).
Yebra, M. et al. Globe-LFMC, a global plant water status database for vegetation ecophysiology and wildfire applications. figshare. https://doi.org/10.6084/m9.figshare.c.4526810 (2019).
Rouse, J. W., Haas, R. H., Schell, J. A., Deering, D. W. & Harlan, J. C. Monitoring the Vernal Advancement and Retrogradation (Green Wave Effect) of Natural Vegetation. Report No. E75-10354, NASA-CR-144661, RSC-1978-4 (National Aeronautics and Space Administration, 1974).
Gorelick, N. et al. Google Earth Engine: planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 202, 18–27 (2017).
Chuvieco, E., Aguado, I. & Dimitrakopoulos, A. P. Conversion of fuel moisture content values to ignition potential for integrated fire danger assessment. Can. J. For. Res. 34, 2284–2293 (2004).
Volaire, F. A unified framework of plant adaptive strategies to drought: crossing scales and disciplines. Glob. Change Biol. 24, 2929–2938 (2018).
Jolly, W. & Johnson, D. Pyro-ecophysiology: shifting the paradigm of live wildland fuel research. Fire 1, 8 (2018).
Pivovaroff, A. L. et al. The effect of ecophysiological traits on live fuel moisture content. Fire 2, 12 (2019).
QGIS Development Team. QGIS Geographic Information System, version 3.8.0. Open Source Geospatial Foundation Project, https://qgis.org/en/site/ (2019).
Hunter, J. D. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 9, 90–95 (2007).
Acknowledgements
This project was a result of a big collaboration effort that did not receive specific funding. We would like to acknowledge the ESA CCI Land Cover project for the provision of the Land cover maps and the U.S. Geological Survey’s Earth Resources Observation for the provision of Landsat 8 data.
Author information
Authors and Affiliations
Contributions
M.Y. provided the idea. M.Y. and E.C. designed the database. All authors contributed to provide published or unpublished data. M.Y. and G.S. harmonized the datasets, wrote the first version of the manuscript and produced the figures and tables. All authors contributed to the final version of the manuscript.
Corresponding author
Ethics declarations
Competing Interests
The authors declare no competing interests.
Additional information
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
ISA-Tab metadata file
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
The Creative Commons Public Domain Dedication waiver http://creativecommons.org/publicdomain/zero/1.0/ applies to the metadata files associated with this article.
About this article

Cite this article
Yebra, M., Scortechini, G., Badi, A. et al. Globe-LFMC, a global plant water status database for vegetation ecophysiology and wildfire applications. Sci Data 6, 155 (2019). https://doi.org/10.1038/s41597-019-0164-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-019-0164-9
This article is cited by
-
Globe-LFMC 2.0, an enhanced and updated dataset for live fuel moisture content research
Scientific Data (2024)
-
Live fuel moisture content time series in Catalonia since 1998
Annals of Forest Science (2021)
-
Fire Danger Observed from Space
Surveys in Geophysics (2020)
-
Satellite Remote Sensing Contributions to Wildland Fire Science and Management
Current Forestry Reports (2020)
