
Abstract
The neuroimaging community is steering towards increasingly large sample sizes, which are highly heterogeneous because they can only be acquired by multi-site consortia. The visual assessment of every imaging scan is a necessary quality control step, yet arduous and time-consuming. A sizeable body of evidence shows that images of low quality are a source of variability that may be comparable to the effect size under study. We present the MRIQC Web-API, an open crowdsourced database that collects image quality metrics extracted from MR images and corresponding manual assessments by experts. The database is rapidly growing, and currently contains over 100,000 records of image quality metrics of functional and anatomical MRIs of the human brain, and over 200 expert ratings. The resource is designed for researchers to share image quality metrics and annotations that can readily be reused in training human experts and machine learning algorithms. The ultimate goal of the database is to allow the development of fully automated quality control tools that outperform expert ratings in identifying subpar images.
Design Type(s) | data validation objective • source-based data transformation objective • anatomical image analysis objective |
Measurement Type(s) | Image Quality |
Technology Type(s) | digital curation |
Factor Type(s) | |
Sample Characteristic(s) | Homo sapiens • brain |
Machine-accessible metadata file describing the reported data (ISA-Tab format)
Similar content being viewed by others

Background & Summary
Ensuring the quality of neuroimaging data is a crucial initial step for any image analysis workflow because low-quality images may obscure the effects of scientific interest1,2,3,4. Most approaches use manual quality control (QC), which entails screening every single image of a dataset individually. However, manual QC suffers from at least two problems: unreliability and time-consuming nature for large datasets. Unreliability creates great difficulty in defining objective exclusion criteria in studies and stems from intrinsically large intra-rater and inter-rater variabilities5. Intra-rater variability derives from aspects such as training, subjectivity, varying annotation settings and protocols, fatigue or bookkeeping errors. The difficulty in calibrating between experts lies at the heart of inter-rater variability. In addition to the need for objective exclusion criteria, the current neuroimaging data deluge makes the manual QC of every magnetic resonance imaging (MRI) scan impractical. For these reasons, there has been great interest in automated QC5,6,7,8, which is progressively gaining attention9,10,11,12,13,14,15,16 with the convergence of machine learning solutions. Early approaches5,6,7,8 to objectively estimate image quality have employed “image quality metrics” (IQMs) that quantify variably interpretable aspects of image quality8,9,10,11,12,13 (e.g., summary statistics of image intensities, signal-to-noise ratio, coefficient of joint variation, Euler angle, etc.). The approach has been shown sufficiently reliable in single-site samples8,11,12,13, but it does not generalize well to new images acquired at sites unseen by the decision algorithm9. Decision algorithms do not generalize to new datasets because the large between-site variability as compared to the within-site variability of features poses a challenging harmonization problem17,18, similar to “batch-effects” in genomic analyses19. Additional pitfalls limiting fully automated QC of MRI relate to the small size of databases that include quality annotations, and the unreliability of such annotations (or “labels noise”). As described previously, rating the quality of every image in large databases is an arduous, unreliable, and costly task. The convergence of limited size of samples annotated for quality and the labels noise preclude the definition of normative, standard values for the IQMs that work well for any dataset, and also, the generalization of machine learning solutions. Keshavan et al.15 have recently proposed a creative solution to the problem of visually assessing large datasets. They were able to annotate over 80,000 bidimensional slices extracted from 722 brain 3D images using BraindR, a smartphone application for crowdsourcing. They also proposed a novel approach to the QC problem by training a convolutional neural network on BraindR ratings, with excellent results (area under the curve, 0.99). Their QC tool performed as well as MRIQC9 (which uses IQMs and a random forests classifier to decide which images should be excluded) on their single-site dataset. By collecting several ratings per screened entity, they were able to effectively minimize the labels noise problem with the averaging of expert ratings. As limitations to their work, we would count the use of 2D images for annotation and the use of a single-site database. In sum, automating QC requires large datasets collected across sites, and rated by many individuals in order to ensure generalizability.
Therefore, the MRIQC Web-API (web-application program interface) provides a unique platform to address the issues raised above. The database collects two types of records: i) IQMs alongside corresponding metadata extracted by MRIQC (or any other compatible client) from T1w (T1-weighted), T2w (T2-weighted) and BOLD (blood-oxygen-level-dependent) MRI images; and ii) manual quality ratings from users of the MRIQC software. It is important to note that the original image data are not transferred to the MRIQC Web-API.
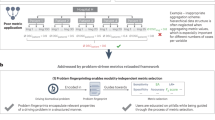
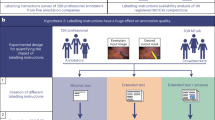
Within fourteen months we have collected over 50,000 and 60,000 records of anatomical and functional IQMs, respectively (Fig. 1). These IQMs are extracted and automatically submitted (unless the user opts out) with MRIQC (Fig. 2). Second, we leverage the efficiency of MRIQC’s reports in assessing individual 3D images with a simple interface that allows experts to submit their ratings with a few clicks (Fig. 3). This assessment protocol avoids clerical errors from the operator, as ratings are automatically handled and registered. In other words, MRIQC users are building a very large database with minimal effort every day. As only the IQMs and manual ratings are crowdsourced (i.e. images are not shared), data collection is not limited to public datasets only. Nonetheless, unique image checksums are stored in order to identify matching images. Therefore, such checksums allow users to find public images that IQMs and/or ratings derive from. The presented resource is envisioned to train automatic QC tools and to develop human expert training programs.

A rapidly growing MRI quality control knowledge base. The database has accumulated over 50,000 records of IQMs generated for T1-weighted (T1w) images and 60,000 records for BOLD images. Records presented are unique, i.e. after exclusion of duplicated images.

Experimental workflow to generate the database. A dataset is processed with MRIQC. Processing finishes with a POST request to the MRIQC Web API endpoint with a payload containing the image quality metrics (IQMs) and some anonymized metadata (e.g. imaging parameters, the unique identifier for the image data, etc.) in JSON format. Once stored, the endpoint can be queried to fetch the crowdsourced IQMs. Finally, a widget (Fig. 3) allows the user to annotate existing records in the MRIQC Web API.

MRIQC visual reports and feedback tool. The visual reports generated with MRIQC include the “Rate Image” widget. After screening of the particular dataset, the expert can assign one quality level (among “exclude”, “poor”, “acceptable”, and “excellent”) and also select from a list of MR artifacts typically found in MRI datasets. When the annotation is finished, the user can download the ratings to their local hard disk and submit them to the Web API.
Methods
Here we describe an open database that collects both IQM vectors extracted from functional and anatomical MRI scans, along with quality assessments done by experts based on visual inspection of images. Although it was envisioned as a lightweight web-service tailored to MRIQC, the database is able to receive new records from any other software, provided they are able to correctly query the API (application programming interface).
Data generation and collection workflow
The overall framework involves the following workflow (summarized in Fig. 2):
-
1.
Execution of MRIQC and submission of IQMs: T1w, T2w, and BOLD images are processed with MRIQC, which computes a number of IQMs (described in section Technical Validation). The IQMs and corresponding metadata are formatted in JavaScript Object Notation (JSON), and MRIQC automatically submits them to a representational state transfer (REST) or RESTful endpoint of the Web-API. Users can opt-out if they do not wish to share their IQMs.
-
2.
JSON records are received by the endpoint, validated, and stored in the database. Each record includes the vector of IQMs, a unique checksum calculated on the original image, and additional anonymized metadata and provenance.
-
3.
Visualization of the individual reports: MRIQC generates dynamic HTML (hypertext markup language) reports that speed up the visual assessment of each image of the dataset. Since its version 0.12.2, MRIQC includes a widget (see Fig. 2) that allows the researcher to assign a quality rating to the image being screened.
-
4.
Crowdsourcing expert quality ratings: the RESTful endpoint receives the quality ratings, which are linked to the original image via their unique identifier.
-
5.
Retrieving records: the database can be queried for records with any HTTP (HyperText Transfer Protocol) client or via the web using our interface: https://mriqc.nimh.nih.gov/. Additionally, a snapshot of the database at the time of writing has been deposited to FigShare20.
Data Records
A full data snapshot of the database at the time of submission is available at FigShare20. Alternatively, data are accessible via DataLad21 with the dataset https://github.com/oesteban/mriqc-webapi-snapshot. Table 1 describes the structure of the dataset being released.
To obtain the latest updated records, the database can be programmatically queried online to get all the currently stored records through its RESTful API.
MRIQC reports, generated for all T1w images found in OpenfMRI are available for expert training at https://mriqc.s3.amazonaws.com/index.html#openfmri/.
Technical Validation
MRIQC extends the list of IQMs from the quality assessment protocol10 (QAP), which was constructed from a careful review of the MRI and medical imaging literature. The technical validity of measurements stored to the database is demonstrated by our previous work9 on the MRIQC client tool and its documentation website: https://mriqc.readthedocs.io/en/latest/measures.html. Definitions for the anatomical IQMs are given in Table 2, and for functional IQMs in Table 3. Finally, the structure of data records containing the manual QC feedback is summarized in Table 4.
Limitations
The main limitation of the database resides in that a substantial fraction of the records (e.g., around 50% for the BOLD IQMs) miss important information about imaging parameters. The original cause is that such information was not encoded with the input dataset being fed into MRIQC. However, as BIDS is permeating the current neuroimaging workflow we can expect BIDS datasets to become more complete, thereby allowing MRIQC to submit such valuable information to the Web API. Moreover, the gradual adoption of better DICOM-to-BIDS conversion tools such as HeuDiConv22, which automatically encodes all relevant fields in the BIDS structure, will surely help minimize this issue.
During the peer-review process of this manuscript, one reviewer identified a potential problem casting float numbers into integers on the content of the “bids_MagneticFieldStrength” field of all records. The bug was confirmed and consequently fixed on the MRIQC Web-API, and all records available on the database snapshot deposited at FigShare have been amended. When retrieving records directly from the Web-API, beware that those with creation date prior to Jan 16, 2019, require a revision of the tainted field. Similarly, the reviewer identified some 1,600 records with an echo-time (TE) value 30.0 with a repetition time (TR) of 2.0, which indicates that TE was misspecified in milliseconds (BIDS mandates seconds). Problematic data points can be (and are) present in the data, and there is likely no setup that could fully rule out the inclusion of misidentified results, although the automation in conversion above mentioned will surely minimize this problem.
Usage Notes
Primarily, the database was envisioned to address three use-cases:
-
1.
Sampling the distribution of IQMs and imaging parameters across datasets (including both publicly available and private), and across scanning sites.
-
2.
Ease the image QC process, crowdsourcing its outcomes.
-
3.
Training machines and humans.
These potential usages are revised with finer detail in the following. Note this resource is focused on quality control (QC), rather than quality assessment (QA). While QC focuses on flagging images that may endanger downstream analysis for their bad quality (i.e., identifying outliers), QA identifies issues that degrade all image’s quality (i.e., improving the overall quality of images after a problem spotted in the scanning device or acquisition protocol -via QC of actual images- is fixed).
Collecting IQMs and imaging parameters
Based on this information, researchers can explore questions such as the relationship of particular imaging parameters (e.g. MR scan vendor, or more interestingly, the multi-band acceleration factor of newest functional MRI sequences) with respect to the signal-to-noise ratio or the power of N/2 aliasing ghosts. Jupyter notebooks demonstrating examples of this use-case are available at https://www.kaggle.com/chrisfilo/mriqc/kernels.
Crowdsourcing an optimized assessment process
To our knowledge, the community lacks a large database of multi-site MRI annotated for quality that permits the application of machine learning techniques to automate QC. As Keshavan et al. have demonstrated, minimizing the time cost and fatigue load along with the elimination of bookkeeping tasks in the quality assessment of individual MR scans enables collection and annotation of massive datasets. The graphical user interface for this use-case is presented in Fig. 2.
A database to train machines and humans
Training machines
As introduced before, the major bottleneck in training models that can predict a quality score for an image or identify specific artifacts, without problems to generalize across MR scanners and sites, is the small size of existing datasets with corresponding quality annotations. Additionally, these annotations, if they exist, are done with extremely varying protocols. Thus, the ability of the presented database to crowdsource quality ratings assigned by humans after visual inspection addresses both problems. The availability of multi-site, large samples with crowdsourced quality annotations that followed a homogeneous protocol (the MRIQC reports) will allow building models that overperform the random forests classifier of MRIQC9, in the task of predicting the quality rating a human would have assigned to an image, given a vector of IQMs (i.e., from IQMs to quality labels). Matching public image checksums, this resource will also enable to train end-to-end (from images to quality labels) deep-learning solutions.
Training humans
Institutions can use the resource to train their experts and compare their assessments across themselves and against the existing quality annotations corresponding to publicly available datasets. Programs for training experts on quality assessment can be designed to leverage the knowledge shared via the proposed database.
Code Availability
The MRIQC Web API is available under the Apache-2.0 license. The source code is accessible through GitHub (https://github.com/poldracklab/mriqcwebapi).
MRIQC is one possible client to generate IQMs and submit rating feedback. It is available under the BSD 3-clause license. The source code is publicly accessible through GitHub (https://github.com/poldracklab/mriqc).
References
Power, J. D., Barnes, K. A., Snyder, A. Z., Schlaggar, B. L. & Petersen, S. E. Spurious but systematic correlations in functional connectivity MRI networks arise from subject motion. NeuroImage 59, 2142–2154, https://doi.org/10.1016/j.neuroimage.2011.10.018 (2012).
Yendiki, A., Koldewyn, K., Kakunoori, S., Kanwisher, N. & Fischl, B. Spurious group differences due to head motion in a diffusion MRI study. NeuroImage 88, 79–90, https://doi.org/10.1016/j.neuroimage.2013.11.027 (2014).
Reuter, M. et al. Head motion during MRI acquisition reduces gray matter volume and thickness estimates. NeuroImage 107, 107–115, https://doi.org/10.1016/j.neuroimage.2014.12.006 (2015).
Alexander-Bloch, A. et al. Subtle in-scanner motion biases automated measurement of brain anatomy from in vivo MRI. Hum. Brain Mapp. 37, 2385–2397, https://doi.org/10.1002/hbm.23180 (2016).
Gardner, E. A. et al. Detection of degradation of magnetic resonance (MR) images: Comparison of an automated MR image-quality analysis system with trained human observers. Acad. Radiol. 2, 277–281, https://doi.org/10.1016/S1076-6332(05)80184-9 (1995).
Woodard, J. P. & Carley-Spencer, M. P. No-Reference image quality metrics for structural MRI. Neuroinformatics 4, 243–262, https://doi.org/10.1385/NI:4:3:243 (2006).
Gedamu, E. L., Collins, D. I. & Arnold, D. L. Automated quality control of brain MR images. J. Magn. Reson. Imaging. 28, 308–319, https://doi.org/10.1002/jmri.21434 (2008).
Mortamet, B. et al. Automatic quality assessment in structural brain magnetic resonance imaging. Magn. Reson. Med. 62, 365–372, https://doi.org/10.1002/mrm.21992 (2009).
Esteban, O. et al. MRIQC: Advancing the automatic prediction of image quality in MRI from unseen sites. PLoS ONE. 12, e0184661, https://doi.org/10.1371/journal.pone.0184661 (2017).
Shehzad, Z. et al. The Preprocessed Connectomes Project Quality Assessment Protocol - a resource for measuring the quality of MRI data. In INCF Neuroinformatics, https://doi.org/10.3389/conf.fnins.2015.91.00047 (2015).
Pizarro, R. A. et al. Automated Quality Assessment of Structural Magnetic Resonance Brain Images Based on a Supervised Machine Learning Algorithm. Front. Neuroinformatics. 10, https://doi.org/10.3389/fninf.2016.00052 (2016).
Backhausen, L. L. et al. Quality Control of Structural MRI Images Applied Using FreeSurfer—A Hands-On Workflow to Rate Motion Artifacts. Front. Neurosci. 10, https://doi.org/10.3389/fnins.2016.00558 (2016).
Alfaro-Almagro, F. et al. Image processing and Quality Control for the first 10,000 brain imaging datasets from UK Biobank. NeuroImage, https://doi.org/10.1016/j.neuroimage.2017.10.034 (2017).
White, T. et al. Automated quality assessment of structural magnetic resonance images in children: Comparison with visual inspection and surface-based reconstruction. Hum. Brain Mapp. 39, 1218–1231, https://doi.org/10.1002/hbm.23911 (2018).
Keshavan, A., Yeatman, J. & Rokem, A. Combining citizen science and deep learning to amplify expertise in neuroimaging. Preprint at, https://doi.org/10.1101/363382 (2018).
Klapwijk, E. T., van de Kamp, F., van der Meulen, M., Peters, S. & Wierenga, L. M. Qoala-T: A supervised-learning tool for quality control of FreeSurfer segmented MRI data. NeuroImage 189, 116–129, https://doi.org/10.1016/j.neuroimage.2019.01.014 (2019).
Fortin, J.-P. et al. Harmonization of cortical thickness measurements across scanners and sites. NeuroImage 167, 104–120, https://doi.org/10.1016/j.neuroimage.2017.11.024 (2018).
Nielson, D. M. et al. Detecting and harmonizing scanner differences in the ABCD study - annual release 1.0. Preprint at. https://doi.org/10.1101/309260 (2018).
Leek, J. T. et al. Tackling the widespread and critical impact of batch effects in high-throughput data. Nat. Rev. Genet. 11, 733–739, https://doi.org/10.1038/nrg2825 (2010).
Esteban, O. et al. MRIQC WebAPI - Database snapshot. figshare, https://doi.org/10.6084/m9.figshare.7097879.v4 (2019).
Halchenko, Y. et al. Open Source Software: DataLad. Zenodo. https://doi.org/10.5281/zenodo.1000098 (2017).
Halchenko, Y. O. et al. Open Source Software: Heudiconv. Zenodo, https://doi.org/10.5281/zenodo.1306159 (2018).
Ganzetti, M., Wenderoth, N. & Mantini, D. Intensity Inhomogeneity Correction of Structural MR Images: A Data-Driven Approach to Define Input Algorithm Parameters. Front. Neuroinformatics. 10, https://doi.org/10.3389/fninf.2016.00010 (2016).
Magnotta, V. A., Friedman, L. & Birn, F. Measurement of Signal-to-Noise and Contrast-to-Noise in the fBIRN Multicenter Imaging Study. J. Digit. Imaging. 19, 140–147, https://doi.org/10.1007/s10278-006-0264-x (2006).
Dietrich, O., Raya, J. G., Reeder, S. B., Reiser, M. F. & Schoenberg, S. O. Measurement of signal-to-noise ratios in MR images: Influence of multichannel coils, parallel imaging, and reconstruction filters. J. Magn. Reson. Imaging. 26, 375–385, https://doi.org/10.1002/jmri.20969 (2007).
Atkinson, D., Hill, D. L. G., Stoyle, P. N. R., Summers, P. E. & Keevil, S. F. Automatic correction of motion artifacts in magnetic resonance images using an entropy focus criterion. IEEE Trans. Med. Imaging. 16, 903–910, https://doi.org/10.1109/42.650886 (1997).
Friedman, L. et al. Test–retest and between-site reliability in a multicenter fMRI study. Hum. Brain Mapp. 29, 958–972, https://doi.org/10.1002/hbm.20440 (2008).
Fonov, V. et al. Unbiased average age-appropriate atlases for pediatric studies. NeuroImage 54, 313–327, https://doi.org/10.1016/j.neuroimage.2010.07.033 (2011).
Krüger, G. & Glover, G. H. Physiological noise in oxygenation-sensitive magnetic resonance imaging. Magn. Reson. Med. 46, 631–637, https://doi.org/10.1002/mrm.1240 (2001).
Saad, Z. S. et al. Correcting Brain-Wide Correlation Differences in Resting-State FMRI. Brain Connect. 3, 339–352, https://doi.org/10.1089/brain.2013.0156 (2013).
Giannelli, M., Diciotti, S., Tessa, C. & Mascalchi, M. Characterization of Nyquist ghost in EPI-fMRI acquisition sequences implemented on two clinical 1.5 T MR scanner systems: effect of readout bandwidth and echo spacing. J. Appl. Clin. Med. Phys. 11 (2010).
Acknowledgements
This work was supported by the Laura and John Arnold Foundation (R.A.P. and K.J.G.), the NIH (grant NBIB R01EB020740, Satrajit S. Ghosh), NIMH (R24MH114705 and R24MH117179, R.A.P.; ZICMH002884, Peter Bandettini; and ZICMH002960, A.G.T.), and NINDS (U01NS103780, R.A.P.).
Author information
Authors and Affiliations
Contributions
O.E. - Data curation, investigation, software, validation, visualization, writing & editing. R.W.B. - Conceptualization, investigation, software, validation, visualization, writing & editing. D.M.N. - Data curation, investigation, infrastructure, software, validation, writing & editing. J.C.V. - Investigation, infrastructure, software, validation, writing & editing. S.M. - Funding acquisition, infrastructure, resources, supervision, writing & editing. A.G.T. - Funding acquisition, infrastructure, resources, supervision, writing & editing. R.A.P. - Funding acquisition, resources, supervision, writing & editing. K.J.G. - Conceptualization, investigation, software, validation, resources, supervision, writing & editing.
Corresponding author
Ethics declarations
Competing Interests
The authors declare no competing interests.
Additional information
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
ISA-Tab metadata file
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
The Creative Commons Public Domain Dedication waiver http://creativecommons.org/publicdomain/zero/1.0/ applies to the metadata files associated with this article.
About this article

Cite this article
Esteban, O., Blair, R.W., Nielson, D.M. et al. Crowdsourced MRI quality metrics and expert quality annotations for training of humans and machines. Sci Data 6, 30 (2019). https://doi.org/10.1038/s41597-019-0035-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-019-0035-4
This article is cited by
-
Multimodal neuroimaging data from a 5-week heart rate variability biofeedback randomized clinical trial
Scientific Data (2023)
-
Arterial hypertension and β-amyloid accumulation have spatially overlapping effects on posterior white matter hyperintensity volume: a cross-sectional study
Alzheimer's Research & Therapy (2023)
-
A Chinese multi-modal neuroimaging data release for increasing diversity of human brain mapping
Scientific Data (2022)
-
Caltech Conte Center, a multimodal data resource for exploring social cognition and decision-making
Scientific Data (2022)
-
How Machine Learning is Powering Neuroimaging to Improve Brain Health
Neuroinformatics (2022)
