
Abstract
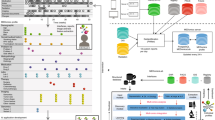
Phenotypes are the foundation for clinical and genetic studies of disease risk and outcomes. The growth of biobanks linked to electronic medical record (EMR) data has both facilitated and increased the demand for efficient, accurate, and robust approaches for phenotyping millions of patients. Challenges to phenotyping with EMR data include variation in the accuracy of codes, as well as the high level of manual input required to identify features for the algorithm and to obtain gold standard labels. To address these challenges, we developed PheCAP, a high-throughput semi-supervised phenotyping pipeline. PheCAP begins with data from the EMR, including structured data and information extracted from the narrative notes using natural language processing (NLP). The standardized steps integrate automated procedures, which reduce the level of manual input, and machine learning approaches for algorithm training. PheCAP itself can be executed in 1–2 d if all data are available; however, the timing is largely dependent on the chart review stage, which typically requires at least 2 weeks. The final products of PheCAP include a phenotype algorithm, the probability of the phenotype for all patients, and a phenotype classification (yes or no).
This is a preview of subscription content, access via your institution
Access options
Access Nature and 54 other Nature Portfolio journals
Get Nature+, our best-value online-access subscription
$29.99 / 30 days
cancel any time
Subscribe to this journal
Receive 12 print issues and online access
$259.00 per year
only $21.58 per issue
Buy this article
- Purchase on Springer Link
- Instant access to full article PDF
Prices may be subject to local taxes which are calculated during checkout







Similar content being viewed by others


Data availability
The datasets generated or analyzed in this protocol can be downloaded from https://celehs.github.io/PheCAP/.
Code availability
The R package and code referenced in this protocol can be downloaded from https://celehs.github.io/PheCAP/.
References
Brownstein, J. S. et al. Rapid identification of myocardial infarction risk associated with diabetes medications using electronic medical records. Diabetes Care 33, 526–531 (2010).
Denny, J. C. et al. Systematic comparison of phenome-wide association study of electronic medical record data and genome-wide association study data. Nat. Biotechnol. 31, 1102–1110 (2013).
Kurreeman, F. et al. Genetic basis of autoantibody positive and negative rheumatoid arthritis risk in a multi-ethnic cohort derived from electronic health records. Am. J. Hum. Genet. 88, 57–69 (2011).
Liao, K. P. et al. Associations of autoantibodies, autoimmune risk alleles, and clinical diagnoses from the electronic medical records in rheumatoid arthritis cases and non-rheumatoid arthritis controls. Arthritis Rheumatol. 65, 571–581 (2013).
Canela-Xandri, O. et al. An atlas of genetic associations in UK Biobank. Nat. Genet. 50, 1593–1599 (2018).
Gaziano, J. M. et al. Million Veteran Program: a mega-biobank to study genetic influences on health and disease. J. Clin. Epidemiol. 70, 214–223 (2016).
Banda, J. M. et al. Electronic phenotyping with APHRODITE and the Observational Health Sciences and Informatics (OHDSI) data network. AMIA Jt. Summit. Transl. Sci. Proc. 2017, (48–57 (2017).
Kho, A. N. et al. Electronic medical records for genetic research: results of the eMERGE consortium. Sci. Transl. Med. 3, 79re71 (2011).
Kirby, J. C. et al. PheKB: a catalog and workflow for creating electronic phenotype algorithms for transportability. J. Am. Med. Inform. Assoc. 23, 1046–1052 (2016).
O’Malley, K. J. et al. Measuring diagnoses: ICD code accuracy. Health Serv. Res. 40, 1620–1639 (2005).
Liao, K. P. et al. Electronic medical records for discovery research in rheumatoid arthritis. Arthritis Care. Res. 62, 1120–1127 (2010).
Liao, K. P. et al. Development of phenotype algorithms using electronic medical records and incorporating natural language processing. BMJ 350, h1885 (2015).
Yu, S. et al. Surrogate-assisted feature extraction for high-throughput phenotyping. J. Am. Med. Inform. Assoc. 24, e143–e149 (2017).
Yu, S. et al. Toward high-throughput phenotyping: unbiased automated feature extraction and selection from knowledge sources. J. Am. Med. Inform. Assoc. 22, 993–1000 (2015).
Castro, V. M. et al. Validation of electronic health record phenotyping of bipolar disorder cases and controls. Am. J. Psychiatry 172, 363–372 (2015).
Murphy, S. N. et al. Serving the enterprise and beyond with informatics for integrating biology and the bedside (i2b2). J. Am. Med. Inform. Assoc. 17, 124–130 (2010).
Son, J. H. et al. Deep phenotyping on electronic health records facilitates genetic diagnosis by clinical exomes. Am. J. Hum. Genet. 103, 58–73 (2018).
Rasmussen, L. V. et al. Design patterns for the development of electronic health record-driven phenotype extraction algorithms. J. Biomed. Inform. 51, 280–286 (2014).
Basile, A. O. et al. Informatics and machine learning to define the phenotype. Expert. Rev. Mol. Diagn. 18, 219–226 (2018).
Ananthakrishnan, A. N. et al. Improving case definition of Crohn’s disease and ulcerative colitis in electronic medical records using natural language processing: a novel informatics approach. Inflamm. Bowel. Dis. 19, 1411–1420 (2013).
Carroll, R. J. et al. Portability of an algorithm to identify rheumatoid arthritis in electronic health records. J. Am. Med. Inform. Assoc. 19, e162–e169 (2012).
Xia, Z. et al. Modeling disease severity in multiple sclerosis using electronic health records. PLoS One 8, e78927 (2013).
Ananthakrishnan, A. N. et al. Association between reduced plasma 25-hydroxy vitamin D and increased risk of cancer in patients with inflammatory bowel diseases. Clin. Gastroenterol. Hepatol. 12, 821–827 (2014).
Cai, T. et al. The association between arthralgia and vedolizumab using natural language processing. Inflamm. Bowel. Dis. 24, 2242–2246 (2018).
Liao, K. P. et al. Association between low density lipoprotein and rheumatoid arthritis genetic factors with low density lipoprotein levels in rheumatoid arthritis and non-rheumatoid arthritis controls. Ann. Rheum. Dis. 73, 1170–1175 (2014).
Kurreeman, F. A. et al. Use of a multiethnic approach to identify rheumatoid- arthritis-susceptibility loci, 1p36 and 17q12. Am. J. Hum. Genet. 90, 524–532 (2012).
Okada, Y. et al. Genetics of rheumatoid arthritis contributes to biology and drug discovery. Nature 506, 376–381 (2014).
Ananthakrishnan, A. N. et al. Common genetic variants influence circulating vitamin D levels in inflammatory bowel diseases. Inflamm. Bowel. Dis. 21, 2507–2514 (2015).
Sinnott, J. A. et al. Improving the power of genetic association tests with imperfect phenotype derived from electronic medical records. Hum. Genet. 133, 1369–1382 (2014).
Halpern, Y. et al. Electronic medical record phenotyping using the anchor and learn framework. J. Am. Med. Inform. Assoc. 23, 731–740 (2016).
Agarwal, V. et al. Learning statistical models of phenotypes using noisy labeled training data. J. Am. Med. Inform. Assoc. 23, 1166–1173 (2016).
Yu, S. et al. Enabling phenotypic big data with PheNorm. J. Am. Med. Inform. Assoc. 25, 54–60 (2018).
Lindberg, D. A. et al. The Unified Medical Language System. Methods Inf. Med. 32, 281–291 (1993).
Jupp, S., Burdett, T., Leroy, C. & Parkinson, H. A new ontology lookup service at EMBL-EBI. CEUR Workshop Proc. 1546, 118–119 (2015).
Savova, G. K. et al. Mayo clinical Text Analysis and Knowledge Extraction System (cTAKES): architecture, component evaluation and applications. J. Am. Med. Inform. Assoc. 17, 507–513 (2010).
Goryachev, S. et al. A suite of natural language processing tools developed for the I2B2 project. AMIA Annu. Symp. Proc. 2006, 931 (2006).
Liu, H. D., Wagholikar, K., Jonnalagadda, S. & Sohn, S. Integrated cTAKES for concept mention detection and normalization. In CEUR Workshop Proceedings, Vol. 1179 (CEUR-WS, 2013).
Aronson, A. R. Effective mapping of biomedical text to the UMLS Metathesaurus: the MetaMap program. Proc. AMIA Symp. 17-21 (2001).
Yu, S. et al. NILE: fast natural language processing for electronic health records. Preprint at https://arxiv.org/abs/1311.6063 (2013).
Manning, C. et al. The Stanford CoreNLP natural language processing toolkit. In Proceedings of 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, 55-60 (Association for Computational Linguistics, 2014).
Chapman, W. W. et al. A simple algorithm for identifying negated findings and diseases in discharge summaries. J. Biomed. Inform. 34, 301–310 (2001).
Castro, V. M. et al. Large-scale identification of patients with cerebral aneurysms using natural language processing. Neurology 88, 164–168 (2017).
Castro, V. M. et al. Identification of subjects with polycystic ovary syndrome using electronic health records. Reprod. Biol. Endocrinol. 13, 116 (2015).
Jorge, A. et al. Identifying lupus patients in electronic health records: development and validation of machine learning algorithms and application of rule-based algorithms. Semin. Arthritis Rheum. 49, 84–90 (2019).
Perlis, R. H. et al. Using electronic medical records to enable large-scale studies in psychiatry: treatment resistant depression as a model. Psychol. Med. 42, 41–50 (2012).
Doss, J., Mo, H., Carroll, R. J., Crofford, L. J. & Denny, J. C. Phenome-wide association study of rheumatoid arthritis subgroups identifies association between seronegative disease and fibromyalgia. Arthritis Rheumatol. 69, 291–300 (2017).
Geva, A. et al. A computable phenotype improves cohort ascertainment in a pediatric pulmonary hypertension registry. J. Pediatr. 188, 224–231 (2017).
Acknowledgements
We thank R. Eastwood for her assistance with figure design and Z. He for establishing the PheCAP website. We gratefully acknowledge support for this project from the NIH (P30 AR 072577; Tianrun C., C.H., J.H., Tianxi C., and K.P.L.) and a VA Office of Research and Development VA Merit Award (I01-CX001025; K.C., Y.L.H., J.H., D.G., C.O., J.M.G.); past support for i2b2 from the NIH (U54 LM008748; A.N.A., Z.X., S.Y.S., V.G., V.C., E.W.K., R.M.P., P.S., G.S., S.C., S.N.M., I.K., Tianxi C., and K.P.L.) and support from grant R01 HG009174 (V.G., V.C., and S.N.M.). A.N.A. received support from the Crohn’s and Colitis Foundation, the NIH, and Pfizer. Z.X. received support from the NIH (NINDS098023). S.H. received support from grant T32 AR 007530. K.P.L. received support from the Harold and DuVal Bowen Fund.
Author information
Authors and Affiliations
Contributions
Y.Z., Tianrun C., S.Y., C.H., J.S., A.N.A., Z.X., S.Y.S., V.G., V.C., N.L., E.W.K., R.M.P., P.S., G.S., S.C., S.N.M., I.K., Tianxi C., and K.P.L. contributed to the development of pipeline; Y.Z., Tianrun C., S.Y., C.H., J.S., N.L., and Tianxi C. contributed to the development of the R package and software development used in this protocol; Y.Z., Tianrun C., K.C., C.H., J.S., J. Huang, Y.-L.H., A.N.A., Z.X., S.Y.S., V.G., V.C., N.L., J. Honerlaw, S.H., D.G., P.S., G.S,. S.C., C.O., S.N.M., J.M.G., I.K., Tianxi C., and K.P.L. contributed to the validation of and enhancements to the pipeline; Y.Z., Tianrun C., S.Y., C.H., J.S., V.G., V.C., G.S., Tianxi C., and K.P.L. drafted the manuscript; all authors contributed to revisions and proofreading of the manuscript.
Corresponding author
Ethics declarations
Competing interests
R.M.P. is employed at Celgene; however, his contributions to the protocol were performed while at Brigham and Women’s Hospital. The remaining authors declare no competing interests.
Additional information
Peer review information Nature Protocols thanks Juan Banda and other anonymous reviewer(s) for their contribution to the peer review of this work.
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Related links
Key references using this protocol
Xia, Z. et al. PLoS One 8, e78927 (2013): https://doi.org/10.1371/journal.pone.0078927
Liao, K. P. et al. Ann. Rheum. Dis. 73, 1170–1175 (2014): https://doi.org/10.1136/annrheumdis-2012-203202
Liao, K. P. et al. BMJ 350, h1885 (2015): https://doi.org/10.1136/bmj.h1885
Ananthakrishnan, A. N. et al. Inflamm. Bowel Dis. 22, 151–158 (2016): https://doi.org/10.1097/MIB.0000000000000580
Supplementary information
Rights and permissions
About this article

Cite this article
Zhang, Y., Cai, T., Yu, S. et al. High-throughput phenotyping with electronic medical record data using a common semi-supervised approach (PheCAP). Nat Protoc 14, 3426–3444 (2019). https://doi.org/10.1038/s41596-019-0227-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41596-019-0227-6
This article is cited by
-
Mitigating Bias in Clinical Machine Learning Models
Current Treatment Options in Cardiovascular Medicine (2024)
-
Potential pitfalls in the use of real-world data for studying long COVID
Nature Medicine (2023)
-
Introducing AI to the molecular tumor board: one direction toward the establishment of precision medicine using large-scale cancer clinical and biological information
Experimental Hematology & Oncology (2022)
-
Visualizing novel connections and genetic similarities across diseases using a network-medicine based approach
Scientific Reports (2022)
-
Semi-supervised approach to event time annotation using longitudinal electronic health records
Lifetime Data Analysis (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
