
Abstract
Analysis of chromatin accessibility can reveal transcriptional regulatory sequences, but heterogeneity of primary tissues poses a significant challenge in mapping the precise chromatin landscape in specific cell types. Here we report single-nucleus ATAC-seq, a combinatorial barcoding-assisted single-cell assay for transposase-accessible chromatin that is optimized for use on flash-frozen primary tissue samples. We apply this technique to the mouse forebrain through eight developmental stages. Through analysis of more than 15,000 nuclei, we identify 20 distinct cell populations corresponding to major neuronal and non-neuronal cell types. We further define cell-type-specific transcriptional regulatory sequences, infer potential master transcriptional regulators and delineate developmental changes in forebrain cellular composition. Our results provide insight into the molecular and cellular dynamics that underlie forebrain development in the mouse and establish technical and analytical frameworks that are broadly applicable to other heterogeneous tissues.
This is a preview of subscription content, access via your institution
Access options
Access Nature and 54 other Nature Portfolio journals
Get Nature+, our best-value online-access subscription
$29.99 / 30 days
cancel any time
Subscribe to this journal
Receive 12 print issues and online access
$209.00 per year
only $17.42 per issue
Buy this article
- Purchase on Springer Link
- Instant access to full article PDF
Prices may be subject to local taxes which are calculated during checkout




Similar content being viewed by others

Change history
01 March 2018
In the version of this article initially published online, the accession code was given as GSE1000333. The correct code is GSE100033. The error has been corrected in the print, HTML and PDF versions of the article.
References
Kundaje, A. et al. Integrative analysis of 111 reference human epigenomes. Nature 518, 317–330 (2015).
Consortium, E. P., ENCODE Project Consortium. An integrated encyclopedia of DNA elements in the human genome. Nature 489, 57–74 (2012).
Maurano, M. T. et al. Large-scale identification of sequence variants influencing human transcription factor occupancy in vivo. Nat. Genet. 47, 1393–1401 (2015).
Thurman, R. E. et al. The accessible chromatin landscape of the human genome. Nature 489, 75–82 (2012).
Wu, J. et al. The landscape of accessible chromatin in mammalian preimplantation embryos. Nature 534, 652–657 (2016).
Mo, A. et al. Epigenomic signatures of neuronal diversity in the mammalian brain. Neuron 86, 1369–1384 (2015).
Yue, F. et al. A comparative encyclopedia of DNA elements in the mouse genome. Nature 515, 355–364 (2014).
Gray, L. T. et al. Layer-specific chromatin accessibility landscapes reveal regulatory networks in adult mouse visual cortex. eLife 6, e21883 (2017).
Lister, R. et al. Global epigenomic reconfiguration during mammalian brain development. Science 341, 1237905 (2013).
Gilsbach, R. et al. Dynamic DNA methylation orchestrates cardiomyocyte development, maturation and disease. Nat. Commun. 5, 5288 (2014).
Corces, M. R. et al. Lineage-specific and single-cell chromatin accessibility charts human hematopoiesis and leukemia evolution. Nat. Genet. 48, 1193–1203 (2016).
Cusanovich, D. A. et al. Multiplex single cell profiling of chromatin accessibility by combinatorial cellular indexing. Science 348, 910–914 (2015).
Buenrostro, J. D. et al. Single-cell chromatin accessibility reveals principles of regulatory variation. Nature 523, 486–490 (2015).
Vierstra, J. et al. Mouse regulatory DNA landscapes reveal global principles of cis-regulatory evolution. Science 346, 1007–1012 (2014).
van der Maaten, L. & Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 9, 2579–2605 (2008).
Rodriguez, A. & Laio, A. Machine learning. Clustering by fast search and find of density peaks. Science 344, 1492–1496 (2014).
Zeisel, A. et al. Brain structure. Cell types in the mouse cortex and hippocampus revealed by single-cell RNA-seq. Science 347, 1138–1142 (2015).
La Manno, G. et al. Molecular diversity of midbrain development in mouse, human, and stem cells. Cell 167, 566–580.e19 (2016).
Rousseau, A. et al. Expression of oligodendroglial and astrocytic lineage markers in diffuse gliomas: use of YKL-40, ApoE, ASCL1, and NKX2-2. J. Neuropathol. Exp. Neurol. 65, 1149–1156 (2006).
Pernet, V., Joly, S., Christ, F., Dimou, L. & Schwab, M. E. Nogo-A and myelin-associated glycoprotein differently regulate oligodendrocyte maturation and myelin formation. J. Neurosci. 28, 7435–7444 (2008).
Matcovitch-Natan, O. et al. Microglia development follows a stepwise program to regulate brain homeostasis. Science 353, aad8670 (2016).
Huttner, H. B. et al. The age and genomic integrity of neurons after cortical stroke in humans. Nat. Neurosci. 17, 801–803 (2014).
Su, Y. et al. Neuronal activity modifies the chromatin accessibility landscape in the adult brain. Nat. Neurosci. 20, 476–483 (2017).
Kierdorf, K. et al. Microglia emerge from erythromyeloid precursors via Pu.1- and Irf8-dependent pathways. Nat. Neurosci. 16, 273–280 (2013).
Glasgow, S. M. et al. Mutual antagonism between Sox10 and NFIA regulates diversification of glial lineages and glioma subtypes. Nat. Neurosci. 17, 1322–1329 (2014).
Nord, A. S., Pattabiraman, K., Visel, A. & Rubenstein, J. L. Genomic perspectives of transcriptional regulation in forebrain development. Neuron 85, 27–47 (2015).
Yuan, F. et al. Efficient generation of region-specific forebrain neurons from human pluripotent stem cells under highly defined condition. Sci. Rep. 5, 18550 (2015).
Barbosa, A. C. et al. MEF2C, a transcription factor that facilitates learning and memory by negative regulation of synapse numbers and function. Proc. Natl Acad. Sci. USA 105, 9391–9396 (2008).
Luo, C. et al. Single-cell methylomes identify neuronal subtypes and regulatory elements in mammalian cortex. Science 357, 600–604 (2017).
Martynoga, B., Drechsel, D. & Guillemot, F. Molecular control of neurogenesis: a view from the mammalian cerebral cortex. Cold Spring Harb. Perspect. Biol. 4, a008359 (2012).
Pollen, A. A. et al. Molecular identity of human outer radial glia during cortical development. Cell 163, 55–67 (2015).
McLean, C. Y. et al. GREAT improves functional interpretation of cis-regulatory regions. Nat. Biotechnol. 28, 495–501 (2010).
Subramanian, L. et al. Transcription factor Lhx2 is necessary and sufficient to suppress astrogliogenesis and promote neurogenesis in the developing hippocampus. Proc. Natl Acad. Sci. USA 108, E265–E274 (2011).
Hsu, L. C. et al. Lhx2 regulates the timing of β-catenin-dependent cortical neurogenesis. Proc. Natl. Acad. Sci. USA 112, 12199–12204 (2015).
Castro, D. S. et al. Proneural bHLH and Brn proteins coregulate a neurogenic program through cooperative binding to a conserved DNA motif. Dev. Cell 11, 831–844 (2006).
Castro, D. S. et al. A novel function of the proneural factor Ascl1 in progenitor proliferation identified by genome-wide characterization of its targets. Genes Dev. 25, 930–945 (2011).
Long, J. E., Cobos, I., Potter, G. B. & Rubenstein, J. L. Dlx1&2 and Mash1 transcription factors control MGE and CGE patterning and differentiation through parallel and overlapping pathways. Cereb. Cortex 19, i96–i106 (2009).
Heng, Y. H. et al. NFIX regulates neural progenitor cell differentiation during hippocampal morphogenesis. Cereb. Cortex 24, 261–279 (2014).
Jolma, A. et al. DNA-binding specificities of human transcription factors. Cell 152, 327–339 (2013).
Hori, K. et al. A nonclassical bHLH Rbpj transcription factor complex is required for specification of GABAergic neurons independent of Notch signaling. Genes Dev. 22, 166–178 (2008).
Tian, X., Kai, L., Hockberger, P. E., Wokosin, D. L. & Surmeier, D. J. MEF-2 regulates activity-dependent spine loss in striatopallidal medium spiny neurons. Mol. Cell. Neurosci. 44, 94–108 (2010).
Onorati, M. et al. Molecular and functional definition of the developing human striatum. Nat. Neurosci. 17, 1804–1815 (2014).
Ghisletti, S. et al. Identification and characterization of enhancers controlling the inflammatory gene expression program in macrophages. Immunity 32, 317–328 (2010).
Choksi, S. P., Lauter, G., Swoboda, P. & Roy, S. Switching on cilia: transcriptional networks regulating ciliogenesis. Development 141, 1427–1441 (2014).
Visel, A., Minovitsky, S., Dubchak, I. & Pennacchio, L. A. VISTA Enhancer Browser–a database of tissue-specific human enhancers. Nucleic Acids Res. 35, D88–D92 (2007).
Silberberg, S. N. et al. Subpallial enhancer transgenic lines: a data and tool resource to study transcriptional regulation of GABAergic cell fate. Neuron 92, 59–74 (2016).
Visel, A. et al. A high-resolution enhancer atlas of the developing telencephalon. Cell 152, 895–908 (2013).
Lake, B. B. et al. Neuronal subtypes and diversity revealed by single-nucleus RNA sequencing of the human brain. Science 352, 1586–1590 (2016).
Bailey, T. L., Williams, N., Misleh, C. & Li, W. W. MEME: discovering and analyzing DNA and protein sequence motifs. Nucleic Acids Res. 34, W369–73 (2006).
Heinz, S. et al. Simple combinations of lineage-determining transcription factors prime cis-regulatory elements required for macrophage and B cell identities. Mol. Cell 38, 576–589 (2010).
Amini, S. et al. Haplotype-resolved whole-genome sequencing by contiguity-preserving transposition and combinatorial indexing. Nat. Genet. 46, 1343–1349 (2014).
Buenrostro, J. D., Giresi, P. G., Zaba, L. C., Chang, H. Y. & Greenleaf, W. J. Transposition of native chromatin for fast and sensitive epigenomic profiling of open chromatin, DNA-binding proteins and nucleosome position. Nat. Methods 10, 1213–1218 (2013).
Langmead, B., Trapnell, C., Pop, M. & Salzberg, S. L. Ultrafast and memory-efficient alignment of short DNA sequences to the human genome. Genome Biol. 10, R25 (2009).
Li, H. et al. The Sequence Alignment/Map format and SAMtools. Bioinformatics 25, 2078–2079 (2009).
Habib, N. et al. Div-seq: single-nucleus RNA-seq reveals dynamics of rare adult newborn neurons. Science 353, 925–928 (2016).
Quinlan, A. R. & Hall, I. M. BEDTools: a flexible suite of utilities for comparing genomic features. Bioinformatics 26, 841–842 (2010).
Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Series B Stat. Methodol. 58, 267–288 (1996).
Adey, A. et al. Rapid, low-input, low-bias construction of shotgun fragment libraries by high-density in vitro transposition. Genome Biol. 11, R119 (2010).
Ramírez, F. et al. deepTools2: a next generation web server for deep-sequencing data analysis. Nucleic Acids Res. 44, W160–W165 (2016).
Zhang, Y. et al. Model-based analysis of ChIP-Seq (MACS). Genome Biol. 9, R137 (2008).
Mathelier, A. et al. JASPAR 2016: a major expansion and update of the open-access database of transcription factor binding profiles. Nucleic Acids Res. 44, D110–D115 (2016).
Robinson, M. D., McCarthy, D. J. & Smyth, G. K. edgeR: a Bioconductor package for differential expression analysis of digital gene expression data. Bioinformatics 26, 139–140 (2010).
Tyner, C. et al. The UCSC Genome Browser database: 2017 update. Nucleic Acids Res. 45, D626–D634 (2017).
Acknowledgements
We thank B. Li for bioinformatic support. We thank M. He and T. Osothprarop for providing the Tn5 enzyme. We thank D. Gao for sequencing on the MiSeq. This study was funded in part by the National Human Genome Research Institute (U54HG006997 to B.R.), National Institute Mental Health (1U19MH114831 to B.R., U01MH098977 to K.Z.), NIH (2P50 GM085764 to B.R.), and the Ludwig Institute for Cancer Research (to B.R.). S.P. was supported by a postdoctoral fellowship from the Deutsche Forschungsgemeinschaft (DFG, PR 1668/1-1). R.R. was supported by a Ruth L. Kirschstein National Research Service Award NIH/NCI T32 CA009523. Research conducted at the E.O. Lawrence Berkeley National Laboratory was performed under US Department of Energy Contract DE-AC02-05CH11231, University of California.
Author information
Authors and Affiliations
Contributions
The study was conceived and designed by B.R., S.P., R.F. and K.Z.; it was overseen by B.R. and K.Z. Experiments were performed by S.P., B.C.S. and H.H.; tissue collection by V.A., D.E.D., A.V., L.A.P. and S.P.; sequencing performed by S.K.; computational strategy developed by R.F. and S.P., data analysis performed by S.P., R.F., Yu. Z., R.R., Ya. Z. and D.U.G. The manuscript was written by S.P., R.F. and B.R. A.V., L.A.P. and K.Z. provided input and edited the manuscript. All authors discussed results and commented on the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Additional information
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Integrated supplementary information
Supplementary Figure 1 snATAC-seq protocol optimization.
a. Overview of critical steps for the snATAC-seq procedure for nuclei from frozen tissues. b. IGEPAL-CA630 but not Triton-X100 was sufficient for tagmentation of frozen tissues (n = 1 experiment). c. Tagmentation was facilitated by high salt concentrations in reaction buffer (n = 1 experiment; Wang, Q. et al. Nature protocols, 2013, doi:10.1038/nprot.2013.118: Sos, B. C. et al. Genome biology, 2016, doi:10.1186/s13059-016-0882-7). d. Maximum amount of fragments per nucleus could be recovered when quenching Tn5 by EDTA prior to FANS and denaturation of Tn5 after FANS by SDS. Finally, SDS was quenched by Triton-X100 to allow efficient PCR amplification. e. Increasing tagmentation time from 30 min to 60 min can result in more DNA fragments per nucleus (n = 1 experiment). f. Number of sorted nuclei was highly correlated with the final library concentration. Tn5 loaded with barcoded adapters showed less efficient tagmentation as compared to Tn5 without barcodes. Wells were amplified for 13 cycles, purified and libraries quantified by qPCR using standards with known molarity (n = 1 experiment). g. Tagmentation with barcoded Tn5 was less efficient and resulted in larger fragments than Tn5 (550 bp vs. 300 bp). Ratio for barcoded Tn5 was based on concentration of regular Tn5. h. Doubling the concentration of barcoded Tn5 increased the number of fragments per nucleus by 3 fold. Further increase resulted only in minor improvements (n = 1 experiment). i. Dot blot illustrating the amount of library from 25 nuclei per well. Each well was amplified for 11 cycles and quantified by qPCR. This output was used to calculate the number of required PCR cycles for snATAC-seq libraries to prevent overamplification (n = 28 wells). j. Size distribution of a successful snATAC-seq library from a mixture of E15.5 forebrain and GM12878 cells shows a nucleosomal pattern. SnATAC-seq was performed including all the optimization steps described above with barcoded Tn5 in 96 well format (n = 1 experiment; snATAC libraries for forebrain samples showed comparable nucleosomal patterns: n = 16 experiments).
Supplementary Figure 2 Isolation of single nuclei after tagmentation.
a–d Density plots illustrating the gating strategy for single nuclei. First, big particles were identified (a), then duplicates were removed (b, c) and finally, nuclei were sorted based on high DRAQ7 signal (d), which stains DNA in nuclei. e. Verification of single cell suspension after FANS was done with Trypan Blue staining under a microscope.
Supplementary Figure 3 Overview of snATAC-seq sequencing data and quality filtering for single nuclei.
a. Distribution of insert sizes between reads pairs derived from sequencing of snATAC-seq libraries indicates nucleosomal patterning. b. Individual barcode representation in the final library shows variability between barcodes. c. To assess the probability of two nuclei sharing the same nuclei barcode, single nuclei ATAC-seq was performed on a 1:1 mixture of human GM12878 cells and mouse E15.5 forebrain nuclei. A collision was indicated by < 90% of all reads mapping to either the mouse genome (mm9) or the human genome (hg19). We identified 8.2% of these barcode collision events. d. Read coverage per barcode combination after removal of potential barcodes with less than 1,000 reads. e. Constitutive promoter coverage for each single cell. The red line indicates the constitutive promoter coverage in corresponding bulk ATAC-seq data sets from the same biological sample. Cells with less coverage than the bulk ATAC-seq data set were discarded. f. Fraction of reads falling into peaks for each single nucleus. The red line indicates fraction of reads in peak regions in corresponding bulk ATAC-seq data sets from the same biological sample. Nuclei with lower reads in peak ratios coverage than the bulk ATAC-seq data set were discarded from downstream analysis. For bulk ATAC-seq data generated by the ENCODE consortium were processed (https://www.encodeproject.org/search/?type=Experiment&lab.title=Bing+Ren%2C+UCSD&assay_title=ATAC-seq&organ_slims=brain).
Supplementary Figure 4 snATAC-seq data sets are robust and reproducible.
Pearson correlation of chromatin accessibility profiles from two independent experiments derived from bulk ATAC-seq (left column) and from aggregate snATAC-seq after aggregating single nuclei profiles (middle column) is shown in each plot. In the right column the correlation between bulk ATAC-seq and aggregate snATAC-seq are displayed for the experiment on the first set of forebrain tissues. Data are displayed from forebrain tissues from following time points: a. E11.5, b. E12.5, c. E13.5, d. E14.5, e. E15.5, f. E16.5, g. P0, and h. P56. For bulk ATAC-seq data generated by the ENCODE consortium were processed (https://www.encodeproject.org/search/?type=Experiment&lab.title=Bing+Ren%2C+UCSD&assay_title=ATAC-seq&organ_slims=brain).
Supplementary Figure 5 Clustering strategies, quality control of clusters and clustering result for individual experiments in adult forebrain.
a, b T-SNE visualization of clustering using a distal elements (regions outside 2 kb of refSeq transcriptional start sites) or b promoter regions (KL: Kullback-Leibler divergence reported by t-SNE).c Box plot of read coverage for each cluster (sample size for cluster is EX1: 190, C2: 946, MG: 126, AC: 120, OC: 252, IN2: 320, EX2: 366, EX3: 519, IN1: 195, shuffled: 199; 25% quantile is EX1: 1076, C2: 665, MG: 595, AC: 884.25, OC: 755, IN2: 754, EX2: 106, EX3: 1104, IN1: 881, shuffled: 880; median value is EX1: 1372, C2: 855, MG: 726, AC: 1079, OC: 871, IN2: 899, EX2: 1334, EX3: 1482, IN1: 1102, shuffled: 1178; 75% quantile is EX1: 2045, C2: 1196, MG: 972, AC: 1489, OC: 1188, IN2: 1134, EX2: 1929, EX3: 2102, IN1: 1496, shuffled: 1652) d Box plot of similarity analysis between any two given cells in a cluster. Cluster C2 was discarded before downstream analysis due to low its intra-group similarity (median < 10). As a negative control, randomly shuffled cells were included in the analysis displaying exceptionally low in-group similarity (sample size is EX1: 190, C2:946, MG:126, AC:120, OC: 252, IN2: 320, EX2: 366, EX3: 519, IN1: 195, shuffled: 199; 25% quantile is EX1: 13.34, C2: 6.84, MG: 15.15, AC: 19.89, OC: 20.60, IN2: 9.88, EX2: 10.53, EX3: 11.81, IN1: 12.58, shuffled: 3.02; median is EX1: 16.34, C2: 9.12, MG: 19.68, AC: 24.835, OC: 26.23, IN2: 12.77, EX2: 13.00, EX3: 15.23, IN1: 15.50, shuffled: 4.20; 75% quantile is EX1: 20.07, C2: 11.74, MG: 25.58, AC: 30.860, OC: 32.95, IN2: 16.11, EX2: 16.02, EX3: 19.46, IN1: 19.25, shuffled: 5.56) e, f T-SNE visualization of single cells from e replicate 1 and f replicate 2. The projection and color coding is the same as in Fig. 2d.
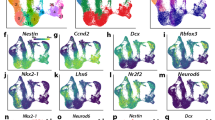
Supplementary Figure 6 Ranking of gene loci (TSS ± 10 kb) compared to other clusters in adult forebrain.
Negative binomial test shows enrichment for a excitatory neuron markers b inhibitory neuron markers c astrocyte markers d oligodendrocyte markers and e microglia markers extending the examples shown in Fig. 2b. Please note for general assignment accessibility profiles for Ex1-3 and IN1/2 were merged, respectively. For each cell type, data from two experiments (n = 2) were used to carry out the negative binomial test.
Supplementary Figure 7 Flow cytometric analysis of adult mouse forebrain and comparison to single-cell RNA-seq data from different brain regions.
a–c Dot blots illustrating nuclei from adult forebrain stained for flow cytometry with Alexa488 conjugated secondary antibodies. a. Displayed are representative blots for experiments without antigen specific primary antibody and b. with antibodies recognizing the post-mitotic neuron marker NeuN22 (n = 3, average ± SEM). c. NeuN negative nuclei were sorted for ATAC-seq experiments and purity (>98%) was confirmed by flow cytometry of the sorted population. d. Relative composition of different forebrain regions derived from single cell RNA-seq shows region specific differences19. e Relative composition derived from snATAC-seq (compare to Fig.2c) of adult forebrain shows values in between.
Supplementary Figure 8 Subclassification of excitatory neurons into hippocampal and cortical neuron types.
a. Hierarchical clustering of aggregate single cell data for excitatory neuron cluster and sorted bulk data sets corresponding to different anatomical regions (grey shaded). b. Chromatin accessibility at marker gene loci. c. K-means clustering of promoter distal genomic elements and enrichment analysis for transcription factor motifs. Statistical test for motif enrichment: One-tailed Fisher's Exact test; displayed p-values are Bonferroni corrected for multiple testing59.
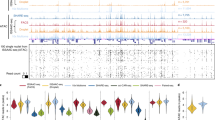
Supplementary Figure 9 Cell-type-specificity and coverage of the cis elements.
a–c Graphs illustrate cell-type specificity of genomic elements as measured by Shannon entropy based on normalized read counts for each cell-type and percentage of nuclei in which a genomic element was called accessible as indicated by presence of at least 1 read overlapping with the element a peak. Analysis was performed for the adult forebrain (P56) against a TSS-proximal genomic elements (TSS - 2kb), b distal elements and c the subset of genomic elements that separated two cell clusters. d Violin plots illustrate higher cell-type specificity for distal elements compared to proximal elements indicated by significantly lower Shannon entropy value (p < 2.2e-16). In addition, all genomic elements that separate two clusters as well as subsets identified from k-means clustering of genomic elements depending on chromatin accessibility in adult forebrain are displayed (related to Fig. 2e). (all proximal peaks n = 14,262 (minimum/median/maximum; 0/1.96/2.08), all distal peaks n = 140,102 (0/1.38/2.08), all differentially accessible peaks n = 4,980 (0.07/1.4/2.06), K1 n = 529 (0.08/1.49/2.06), K2 n = 586 (0.14/1.13/2.04), K3 n = 737 (0.07/1.18/2.05), K4 n = 270 (0.33/1.55/2.01), K5 n = 601 (0.74/1.43/2.05), K6 n = 513 (0.28/1.48/2.05), K7 n = 538 (1.19/1.64/2.02), K8 n = 490 (0.13/1.28/2.05), K9 n = 282 (0.73/1.65/2.02), K10 n = 434 (0.32/1.42/2.04). TSS: transcriptional start site.
Supplementary Figure 10 Distinct chromatin accessibility profiles of two GABAergic neuron clusters.
IN2 is depleted for chromatin accessibility at the genes Pax6 and Dlx1 (a), but enriched for marker genes of medium spiny neurons as compared to IN1 cluster (b).
Supplementary Figure 11 Comparison of chromatin accessibility and differentially methylated regions in neuronal subtypes.
Displayed is the fraction of cell-type specific differentially methylated29 that overlapped with genomic elements accessible in excitatory (EX) and inhibitory neurons (IN). This analysis illustrates that cis regulatory elements specific for inhibitory neurons and excitatory neurons, respectively, could be identified by both methods. Clusters (K) from this study are the same as in Fig. 2e (m: mouse; L: layer; DL: deep layer).
Supplementary Figure 12 Dynamics of chromatin accessibility within distinct cell groups.
a Number of reads in peaks per developmental time point for a specific nuclei cluster. b Number of nuclei per time point for a specific nuclei cluster. For analysis of dynamics only cell clusters with > 3 stages with > 50 nuclei and > 250,000 reads in peaks were considered. c Overview of dynamic elements identified per cell cluster (see methods) d–g K-means clustering and motif enrichment analysis for nuclei clusters with > 200 dynamic genomic elements. Statistical test for motif enrichment: hypergeometric test. P-values were not corrected for multiple testing50. (e: embryonic; RG: Radial glia; EX: Excitatory neuron; IN: Inhibitory neuron; EMP: Erythromyeloid progenitor cell; AC: Astrocyte).
Supplementary Figure 13 Distal genomic element clusters are associated with distinct anatomical locations in the developing forebrain.
Displayed is the enrichment of clusters of open chromatin for enhancers that are active in distinct regions of the developing forebrain (n = 95)47. As expected elements mainly associated with radial glia and excitatory neuron cell-types (Fig. 2e, K1,3,4) were enriched for pallial subregions, whereas inhibitory neuron associated elements (Fig. 2e, K9-11) were enriched in LGE and MGE regions. Clusters with less than 5 overlapping elements were excluded from the analysis. Binomial testing was used for statistical analysis. The p-values were not corrected. Anatomically annotated enhancers: n = 14647; open chromatin regions: K1: n = 880; K3: n = 1838; K4: n = 1015; K5: n = 1276; K9: n = 1042; K10: n = 1238; K11: n = 623.
Supplementary information
Supplementary Text and Figures
Supplementary Figures 1–13
Supplementary Table 4
Overview and categorization of accessible chromatin regions.
Supplementary Table 5
List of oligos used for tagmentation and PCR.
Rights and permissions
About this article

Cite this article
Preissl, S., Fang, R., Huang, H. et al. Single-nucleus analysis of accessible chromatin in developing mouse forebrain reveals cell-type-specific transcriptional regulation. Nat Neurosci 21, 432–439 (2018). https://doi.org/10.1038/s41593-018-0079-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41593-018-0079-3
This article is cited by
-
txci-ATAC-seq: a massive-scale single-cell technique to profile chromatin accessibility
Genome Biology (2024)
-
Deciphering cell types by integrating scATAC-seq data with genome sequences
Nature Computational Science (2024)
-
Simultaneous single-cell analysis of 5mC and 5hmC with SIMPLE-seq
Nature Biotechnology (2024)
-
Dynamic enhancer landscapes in human craniofacial development
Nature Communications (2024)
-
Basal forebrain cholinergic signalling: development, connectivity and roles in cognition
Nature Reviews Neuroscience (2023)
