
Abstract
We describe an architecture for organizing, integrating and sharing neurophysiology data within a single laboratory or across a group of collaborators. It comprises a database linking data files to metadata and electronic laboratory notes; a module collecting data from multiple laboratories into one location; a protocol for searching and sharing data and a module for automatic analyses that populates a website. These modules can be used together or individually, by single laboratories or worldwide collaborations.
Similar content being viewed by others


Main
Improving technology allows neurophysiologists to record ever larger datasets. The need for technologies to organize and share these data is growing as scientists begin to assemble into large, international teams. The International Brain Laboratory (IBL) is a collaboration studying the computations supporting decision-making in the mouse1. We have developed modular data-management tools that enable individual laboratories and collaborations to manage experimental subject colonies and track subject- and experiment-level metadata; integrate data from multiple laboratories in a central store for sharing inside or outside the collaboration; access shared data through a programmatic interface; and process incoming data through pipelines that automatically populate a website.
Current neurophysiological datasets comprise multiple recordings from multiple subjects, recorded using diverse devices. These data must be preprocessed, time-aligned and integrated with data such as locations of recording electrodes before they can be used to draw scientific conclusions2,3,4,5,6,7,8. Distributed collaborations pose distinct challenges: while public data release must wait for careful quality control, scientists within the collaboration require immediate access to specific data. This store must be searchable and allow downloading and also revision of individual items, because preprocessing and quality control methods are still evolving9,10,11.
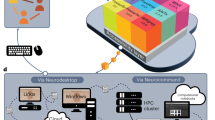
We addressed these problems with an architecture consisting of four modules (Fig. 1). The first module is a web interface for colony management and electronic laboratory notebook that links files arising from each experiment to relevant metadata. The second module integrates data from multiple laboratories into a central database and bulk data store, providing immediate access while allowing updates of individual items. The third automatically runs analyses on newly arrived data, providing results via a web interface. The fourth allows standardization, access and sharing of the data. Full documentation can be found at https://docs.internationalbrainlab.org/ and through links at https://www.internationalbrainlab.com/tools.

The Alyx database links colony management and electronic laboratory notebook metadata to experimental data files on a laboratory data server. Data from several laboratories are integrated on a central server, and a distributed job management system coordinates preprocessing on laboratory servers. Data are accessed via the ONE protocol, with adapters for Neurodata Without Borders12,14 and DataJoint13, which also performs pipelined analyses for automatic display on a website. Globus, DataJoint and Neurodata Without Borders logos used with permission.
To manage data within each laboratory, we developed Alyx, a relational database that links colony management, metadata and laboratory notes to experimental data files. A web graphical user interface allows users to enter metadata as it arrives (such as birth, weaning, genotyping, surgeries or experiments), and a REST application programming interface (API) allows experiment control software to automatically enter metadata. Bulk data files are stored on a laboratory server and linked to experiment and subject metadata in the Alyx database. This tool can be used by single laboratories as well as collaborations: it was developed in one member laboratory before IBL’s founding, and is now used by several laboratories worldwide for non-IBL work. A link to an Alyx user guide can be found via our main documentation page (https://docs.internationalbrainlab.org).
Integrating data between laboratories raises challenges of size and complexity. Large-scale electrophysiology produces hundreds of gigabytes per experiment, for which we have designed a threefold lossless compression algorithm (https://github.com/int-brain-lab/mtscomp) (Supplementary Note 1). A single IBL experiment generates over 150 raw and processed data files. We have devised conventions for organizing and naming these files, termed the Open Neurophysiology Environment (ONE) (Supplementary Note 2; https://one.internationalbrainlab.org), which formalizes how to encode cross-references between files, time synchronization and versioning, and allows local and remote access via an API. ONE provides a way to standardize and share data from individual laboratories, by specifying standard filenames for common data types (Supplementary Note 3) and defining conventions for naming laboratory-specific data files (https://github.com/int-brain-lab/ONE/blob/main/docs/Open_Neurophysiology_Environment_Filename_Convention.pdf). Files from several laboratories are integrated by uploading nightly from laboratory servers to a central server using Globus Online12, coordinated by a central Alyx database that also stores metadata from all laboratories.
Neurophysiology data require preprocessing, such as spike sorting and video analysis. We developed a task management system that uses computers in member laboratories as a processing pool. Computers query the Alyx database for a list of outstanding preprocessing tasks, determined by a dependency graph. Because Alyx is accessed through http, this works despite different universities’ diverse firewall policies, and allows monitoring, logging and restarting all preprocessing tasks. Higher-level analyses are automatically run on newly preprocessed data using DataJoint13, which runs automated analyses and places the results on a website, including summaries of behavioral performance, allowing scientists to monitor training progress, and basic analyses of spike trains. While manual curation of the full dataset will be required before public release, an illustrative curated subset of these data is available on a public website (https://data.internationalbrainlab.org).
To access data, an API allows users to search experiments and load data from the ONE files directly into Python (Supplementary Note 3). This API allows both collaborations and individual laboratories to share data using the same standard. A large collaboration can host files on a server such as Amazon Web Services, and run an Alyx server that allows users to rapidly search and selectively download the data. Individual laboratories can release data compatible with the same API by ‘uploading and forgetting’ a zip of ONE files to a site such as FigShare, for users to download (instructions at https://github.com/int-brain-lab/ONE/blob/main/docs/Open_Neurophysiology_Environment_Filename_Convention.pdf). Users can also access data via Neurodata Without Borders13,14 using software that translates from the ONE standard (https://github.com/catalystneuro/IBL-to-nwb; Supplementary Table 1), or through DataJoint15. A comparison of these and other sharing systems is in Supplementary Note 4. The analyses in a recently published paper1 were made using this system, and an additional example is provided below for evaluating training time.
The IBL architecture was designed for our large-scale collaboration, but its modular design allows components to be used by individual laboratories and smaller-scale collaborations. The Alyx system provides easy-to-use colony management and electronic laboratory notebook features for laboratories or collaborations, linking experimental files to this metadata. The ONE conventions allow data to be organized within a laboratory and shared externally, using standards that scale to large collaborations. Larger collaborations can also benefit from other features such as the automated analyses for web display. We hope that these tools, and additional software we have provided (Supplementary Table 1), will help pave the way forward to an era in which data from neurophysiology laboratories are integrated and shared on a routine basis.
To demonstrate how this system can manage data and metadata, integrate them across laboratories and analyze the results, we evaluated the importance of multiple variables for predicting the time required for mice to complete behavioral training.
Mice were on a visual discrimination task using the standard IBL training pipeline1. Training was considered complete when performance met criteria for the fraction of correct responses, number of completed trials and fitted psychometric parameters, for three consecutive sessions. Behavior on reaching this criterion was similar across mice, but the training time required for mice to meet these criteria was variable, ranging from 5 to 57 training sessions (Fig. 2a). We used the data architecture described above to investigate which factors might predict this variability. Because comprehensive data and metadata from all laboratories were integrated in a centralized and standardized manner, we could quickly perform these analyses.

a, Histogram of the number of training sessions taken to reach the IBL ‘trained’ criterion (n = 116 mice). Vertical dashed lines represent the split of the data in quartiles. b, Cross-validated confusion matrix of a random forest classifier, trained to predict training-time quantile from multiple behavioral features. Rows represent the true quartile and columns represent the predicted quartile; results were normalized over the number of mice of the corresponding true quartile (row). c, Prediction accuracy for a classifier that uses all features (full classifier), and a classifier that uses only task performance change across the first five training sessions (task performance change classifier). Horizontal lines show classifier performance; boxplots show distribution of performance scores over random shuffles of the training-time labels (n = 100 shuffles). d, Importance of each feature in predicting training time. Boxplots show the distribution of importance scores obtained across multiple permutations (n = 10 permutations). In all boxplots, the box shows median and interquartile range, whiskers show range and points show individual observations. RT denotes median reaction time.
We investigated whether training time could be predicted from several classes of variables. The first class was subject features: the sex of the animal, the age, weight and weight loss (relative to prewater-restriction weight) on training start. The second was rig ambient measures: temperature, relative humidity and air pressure, averaged across all training sessions. Third, some institute-specific experimental conditions such as the type of light cycle mice were housed in, the protein content of the homecage food and the weekend water regime in place (water restriction versus 2% free homecage citric acid water16). Fourth, metrics assessed from early training sessions including: task performance; median reaction time; total number of trials on the first training session; the changes in those values over the first five training sessions; the total sum of trials performed over the first five training sessions; the variance in the sign of the daily performance change across the first five training sessions; the number of wheel movements per second and the average wheel displacement bias (averaged across the first five training sessions).
A random forest classifier accurately predicted time to reach the performance criterion for each mouse from this feature set (Fig. 2a). Time to criterion was grouped into quartiles and classification accuracy was evaluated by tenfold cross-validation, producing a confusion matrix comparing the predicted and actual quartile for each mouse (Fig. 2b), summarized by an F1 score (Fig. 2c). When trained with all available features, the classifier predicted the true quartile more often than any other (Fig. 2b), with accuracy around two times higher than when trained after randomly shuffling quartile labels (Fig. 2c).
To investigate the importance of each feature, we performed a permutation test on each of the features. The importance of each feature was assessed by the decrease in the classifier’s accuracy after randomly shuffling that feature’s values across all mice. This revealed that one predictor variable was more important than all others: the task performance change across the first five training sessions (Fig. 2d): that is, the percentage correct achieved on session five minus the percentage correctly achieved on session 1. Site-specific features that are hard to standardize across locations, such as food protein content and humidity, were not important to the classifier’s accuracy. The only predictive feature not related to task performance in early days was age.
Given the importance of the 5-day performance change feature compared to the remaining ones, we further evaluated the accuracy of a classifier trained only with this one feature (Fig. 2c). Prediction using only this feature was nearly as accurate as the full classifier, although including other predictor variables resulted in a 14% increase in accuracy.
This large-scale analysis was made possible by the ease and speed of accessing large amounts of behavioral data saved in a standard manner. The obtained results showed that tracking changes in performance during the first few training days was enough to predict training time above chance level, with even better accuracy achieved when also considering other behavioral metrics. The ability to predict final training time after only five training sessions could allow automated decisions about when to drop a subject from the training pipeline.
Methods
The experimental methods used to collect the data analyzed in this paper are described in ref. 1.
For the analysis described in this paper, we accessed the behavioral data using the public DataJoint protocol. Mice selected for the analysis consisted of all mice trained according to the standard IBL training pipeline, up until 23 March 2020. Mice were excluded from the analyses if they were dropped from the pipeline before reaching the end of training. Training was considered complete when performance met criteria for the fraction of correct responses, number of completed trials and fitted psychometric parameters, for three consecutive sessions1.
A random forest classifier was used to assess whether training time could be predicted from several classes of variables: subject features, rig ambient measures, institute-specific experimental conditions and performance metrics from early training sessions. For that, data were processed and organized as a design matrix with shape number of mice × number of variables. For each mouse, we included the following variables: (1) sex; (2) age at the start of training; (3) weight at the start of training; (4) weight loss at the start of training, calculated as the weight fraction relative to the prewater-restriction weight; (5) whether the mouse was housed on an inverted or noninverted light cycle scheme; (6) the percentage of protein content of the homecage food; (7) weekend water regime in place: whether mice were on a traditional water restriction regime or on had free access to 2% free homecage citric acid water16; (8) the training rig temperature, averaged across the first five training sessions; (9) the training rig relative humidity, averaged across the first five training sessions; (10) the training rig air pressure, averaged across the first five training sessions; (11) the fraction of correct responses on the first training session; (12) median reaction time on the first training session; (13) total number of trials on the first training session; (14) difference in fraction of correct responses between first and fifth training sessions; (15) difference in the median reaction time between the first and fifth training sessions; (16) difference in the total number of trials between the first and fifth training sessions; (17) total number of trials performed over the first five training sessions; (18) the variance in the sign of the daily performance change across the first five training sessions (daily performance change was computed as the difference in the fraction of correct responses across consecutive sessions); (19) the amount of wheel movement per second averaged across the first five training sessions and (20) the wheel displacement bias averaged across the first five training sessions (wheel displacement bias was calculated as the amount of wheel displacement divided by the total amount of wheel movement). Missing data that prevented the calculation of any of the above metrics led to the exclusion of the corresponding mouse from the analyses. The predicted variable was the training-time quartile of the mouse. Training time was calculated as the number of training sessions until training completion. The quartiles of the distribution were calculated after exclusion of mice with missing data.
To assess whether training time could be predicted from the listed variables, a random forest classifier was trained on the data, using tenfold cross-validation. For that, scikit-learn functions RanfomForestClassifier and KFold were used. Prediction accuracy of the classifier was computed using the F1-score function. The F1 score reaches 1 for the highest accuracy value and 0 for the worst. It is calculated according to the following formula:
Classifier performance was compared with that of a classifier trained on a control dataset in which quartile labels were randomly shuffled (n = 100 shuffles).
To investigate the importance of each feature to the classifier’s performance, we performed a permutation test on each of the features. The importance of each feature was assessed by the decrease in the classifier’s accuracy (F1 score) after randomly shuffling that feature’s values across mice (n = 10 repetitions).
Finally, we further evaluated the accuracy of a classifier trained only on the most important feature, as concluded from the permutation test: the difference in fraction of correct responses between first and fifth training sessions.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
All IBL data are available online using the access protocols described in this manuscript. For further information see https://www.internationalbrainlab.com/data. The specific data used to create Fig. 2 can be accessed by the code that created this figure, available at https://github.com/int-brain-lab/paper-data-architecture.
Code availability
All code described in this paper is freely available and is listed in Supplementary Table 1 along with links to their respective repositories. The behavior data were collected using Bonsai and pyBpod, available at https://github.com/int-brain-lab/iblrig. Metadata were stored in a custom database available at https://github.com/cortex-lab/alyx. The data were processed using the custom data pipelines ibllib (https://github.com/int-brain-lab/ibllib) and DataJoint (https://datajoint.io/). The data were accessed using ONE (https://one.internationalbrainlab.org) and DataJoint (https://github.com/int-brain-lab/IBL-pipeline).
References
The International Brain Laboratory. et al. Standardized and reproducible measurement of decision-making in mice. eLife 10, e63711 (2021).
Pachitariu, M. et al. Suite2p: beyond 10,000 neurons with standard two-photon microscopy. Preprint at bioRxiv https://doi.org/10.1101/061507 (2016).
Mathis, A. et al. DeepLabCut: markerless pose estimation of user-defined body parts with deep learning. Nat. Neurosci. 21, 1281–1289 (2018).
Giovannucci, A. et al. CaImAn an open source tool for scalable calcium imaging data analysis. eLife 8, e38173 (2019).
Vogelstein, J. T. et al. Fast nonnegative deconvolution for spike train inference from population calcium imaging. J. Neurophysiol. 104, 3691–704 (2010).
Pachitariu, M., Steinmetz, N. A., Kadir, S. N., Carandini, M. & Harris, K. D. in Advances in Neural Information Processing Systems 29 (eds. Lee, D. D. et al.) 4448–4456 (Curran Associates, Inc., 2016).
Wiltschko, A. B. et al. Revealing the structure of pharmacobehavioral space through motion sequencing. Nat. Neurosci. 23, 1433–1443 (2020).
Vogelstein, J. T. et al. Discovery of brainwide neural-behavioral maps via multiscale unsupervised structure learning. Science 344, 386–392 (2014).
Siegle, J. H. et al. Survey of spiking in the mouse visual system reveals functional hierarchy. Nature 592, 86–92 (2021).
Hill, D. N., Mehta, S. B. & Kleinfeld, D. Quality metrics to accompany spike sorting of extracellular signals. J. Neurosci. 31, 8699–705 (2011).
Harris, K. D., Quiroga, R. Q., Freeman, J. & Smith, S. L. Improving data quality in neuronal population recordings. Nat. Neurosci. 19, 1165–1174 (2016).
Foster, I. Globus Online: accelerating and democratizing science through cloud-based services. IEEE Internet Comput. 15, 70–73 (2011).
Rübel, O. et al. The Neurodata Without Borders ecosystem for neurophysiological data science. eLife 11, e78362 (2022).
Teeters, J. L. et al. Neurodata Without Borders: creating a common data format for neurophysiology. Neuron 88, 629–634 (2015).
Yatsenko, D. et al. DataJoint: managing big scientific data using MATLAB or Python. Preprint at bioRxiv https://doi.org/10.1101/031658 (2015).
Urai, A. E. et al. Citric acid water as an alternative to water restriction for high-yield mouse behavior. eNeuro 8, ENEURO.0230-20.2020 (2021).
Acknowledgements
This work was supported by the Wellcome Trust (grant no. 209558 to IBL, 216324 to IBL) and Simons Foundation (to IBL).
Author information
Authors and Affiliations
Consortia
Contributions
N.B. supported the conceptualization and worked on data curation of data, metadata and the pipeline; funding acquisition, project administration (meeting coordination and attendance), resources (computing and data storage), software, validation (pipeline, core, quality control, database and analysis libraries), writing the original draft and review and editing. G.A.C. was responsible for data curation and helped with writing user guides detailing how to enter metadata in Alyx, as well as software, validation (acted as naive user tester for ONE and DataJoint) and project administration (gathered and reported users’ requirements). A.K.C. contributed to project administration, funding acquisition, writing and revising. E.E.J.D.W. was responsible for the investigation and contributed to analyses for example use of data as well as writing and creating the figures and draft text. M.F. worked on the software and contributed to implementation of backend data infrastructure and analysis libraries, the data curation and contributed to curating datasets and assuring quality assurance. K.D.H. contributed to design of overall data architecture, and to Alyx and ONE systems, as well as to project administration, funding acquisition, writing and revising. J.M.H. worked on the software and contributed to implementation of backend data infrastructure, analysis libraries and continuous integration, as well as data curation and contributed to dataset curation and quality assurance. M.M.S. worked on the conceptualization and contributed to the development of dataset types related to video and their quality control metrics. M.H. contributed to the design and development of Alyx. I.C.L. worked on the investigation and performed analyses for the example use case of the data architecture as well as helping to write the original draft. C.R. contributed to design and implementation of overall data architecture, and to Alyx and ONE systems. M.S. contributed to the design and implementation of the IBL Data Portal website. S.S. contributed to the design and implementation of the DataJoint pipeline and the IBL JupyterHub. N.A.S. contributed to the design, testing, and development of Alyx, of dataset types, and of software tools for working with them. E.Y.W. contributed to the design and implementation of the DataJoint pipeline and the IBL Data Portal. S.J.W. contributed to the design of data structures for histological alignment. O.W. worked on the software and implemented the backend data infrastructure, the validation/methodology, designed the full loop integration tests to allow maintenance of the codebase, data curation and fixed and updated erroneous datasets. M.J.W. worked on the software and contributed to the design, testing and implementation of Alyx, its dataset types and of software tools that work with them, the validation, contributed to the design and implementation of continuous integration and quality assurance systems and contributed to writing, reviewing and editing the text and Supplementary Notes.
Corresponding author
Ethics declarations
Competing interests
The authors declare the following competing interests: E.Y.W. holds equity ownership in Vathes LLC, which provides development and consulting for the framework (DataJoint) described in this work. E.Y.W., M.S. and S.S were employees of Vathes LLC at the time the work in this paper was done. The remaining authors declare no competing interests.
Peer review
Peer review information
Nature Methods thanks Joshua Vogelstein and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Primary Handling Editor: Nina Vogt, in collaboration with the Nature Methods team.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Supplementary Information
Supplementary Notes 1–5 and Tables 1 and 2.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
The International Brain Laboratory., Bonacchi, N., Chapuis, G.A. et al. A modular architecture for organizing, processing and sharing neurophysiology data. Nat Methods 20, 403–407 (2023). https://doi.org/10.1038/s41592-022-01742-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41592-022-01742-6
This article is cited by
-
Editorial: On the Economics of Neuroscientific Data Sharing
Neuroinformatics (2023)
