
Abstract
Genome-wide association studies (GWASs) have identified many variants associated with complex traits, but identifying the causal gene(s) is a major challenge. In the present study, we present an open resource that provides systematic fine mapping and gene prioritization across 133,441 published human GWAS loci. We integrate genetics (GWAS Catalog and UK Biobank) with transcriptomic, proteomic and epigenomic data, including systematic disease–disease and disease–molecular trait colocalization results across 92 cell types and tissues. We identify 729 loci fine mapped to a single-coding causal variant and colocalized with a single gene. We trained a machine-learning model using the fine-mapped genetics and functional genomics data and 445 gold-standard curated GWAS loci to distinguish causal genes from neighboring genes, outperforming a naive distance-based model. Our prioritized genes were enriched for known approved drug targets (odds ratio = 8.1, 95% confidence interval = 5.7, 11.5). These results are publicly available through a web portal (http://genetics.opentargets.org), enabling users to easily prioritize genes at disease-associated loci and assess their potential as drug targets.
This is a preview of subscription content, access via your institution
Access options
Access Nature and 54 other Nature Portfolio journals
Get Nature+, our best-value online-access subscription
$29.99 / 30 days
cancel any time
Subscribe to this journal
Receive 12 print issues and online access
$209.00 per year
only $17.42 per issue
Buy this article
- Purchase on Springer Link
- Instant access to full article PDF
Prices may be subject to local taxes which are calculated during checkout


Similar content being viewed by others

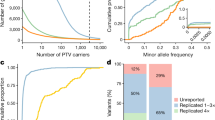
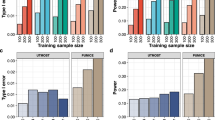
Data availability
Our results are freely available through a web portal (genetics.opentargets.org), GraphQL API or through bulk download. GWAS gold-standard genes: github.com/opentargets/genetics-gold-standards.
Code availability
All analysis code is available open source (Apache license) in the following repositories:
https://github.com/opentargets/genetics-sumstat-data
https://github.com/opentargets/genetics-finemapping
https://github.com/opentargets/genetics-colocalisation
https://github.com/opentargets/genetics-v2d-data
https://github.com/opentargets/genetics-v2g-data
https://github.com/opentargets/genetics-l2g-scoring
References
Hindorff, L. A. et al. Potential etiologic and functional implications of genome-wide association loci for human diseases and traits. Proc. Natl Acad. Sci. USA 106, 9362–9367 (2009).
Altshuler, D., Daly, M. J. & Lander, E. S. Genetic mapping in human disease. Science 322, 881–888 (2008).
Claussnitzer, M. et al. FTO obesity variant circuitry and adipocyte browning in humans. N. Engl. J. Med. 373, 895–907 (2015).
Zhu, Z. et al. Integration of summary data from GWAS and eQTL studies predicts complex trait gene targets. Nat. Genet. 48, 481–487 (2016).
Brænne, I. et al. Prediction of causal candidate genes in coronary artery disease loci. Arterioscler. Thromb. Vasc. Biol. 35, 2207–2217 (2015).
Fachal, L. et al. Fine-mapping of 150 breast cancer risk regions identifies 191 likely target genes. Nat. Genet. 52, 56–73 (2020).
Xue, A. et al. Genome-wide association analyses identify 143 risk variants and putative regulatory mechanisms for type 2 diabetes. Nat. Commun. 9, 2941 (2018).
Okada, Y. et al. Genetics of rheumatoid arthritis contributes to biology and drug discovery. Nature 506, 376–381 (2014).
Fang, H. et al. A genetics-led approach defines the drug target landscape of 30 immune-related traits. Nat. Genet. 51, 1082–1091 (2019).
Hay, M., Thomas, D. W., Craighead, J. L., Economides, C. & Rosenthal, J. Clinical development success rates for investigational drugs. Nat. Biotechnol. 32, 40–51 (2014).
Nelson, M. R. et al. The support of human genetic evidence for approved drug indications. Nat. Genet. 47, 856–860 (2015).
Carvalho-Silva, D. et al. Open Targets Platform: new developments and updates two years on. Nucleic Acids Res. 47, D1056–D1065 (2019).
Koscielny, G. et al. Open Targets: a platform for therapeutic target identification and validation. Nucleic Acids Res. 45, D985–D994 (2017).
Ochoa, D. et al. Open Targets Platform: supporting systematic drug-target identification and prioritisation. Nucleic Acids Res. 49, D1302–D1310 (2021).
GTEx Consortium. et al. Genetic effects on gene expression across human tissues. Nature 550, 204–213 (2017).
Võsa, U. et al. Unraveling the polygenic architecture of complex traits using blood eQTL metaanalysis. Preprint at bioRxiv https://doi.org/10.1101/447367 (2018).
Kerimov, N. et al. A compendium of uniformly processed human gene expression and splicing quantitative trait loci. Nat. Genet. 53, 1290–1299 (2021).
Sun, B. B. et al. Genomic atlas of the human plasma proteome. Nature 558, 73–79 (2018).
Buniello, A. et al. The NHGRI-EBI GWAS Catalog of published genome-wide association studies, targeted arrays and summary statistics 2019. Nucleic Acids Res. 47, D1005–D1012 (2019).
Zhou, W. et al. Efficiently controlling for case-control imbalance and sample relatedness in large-scale genetic association studies. Nat. Genet. 50, 1335–1341 (2018).
Neale Lab. UK Biobank bulk summary statistics. http://www.nealelab.is/uk-biobank (2018).
Yang, J. et al. Conditional and joint multiple-SNP analysis of GWAS summary statistics identifies additional variants influencing complex traits. Nat. Genet. 44, 369–375 (2012).
Wellcome Trust Case Control Consortium. et al. Bayesian refinement of association signals for 14 loci in 3 common diseases. Nat. Genet. 44, 1294–1301 (2012).
Farh, K. K.-H. et al. Genetic and epigenetic fine mapping of causal autoimmune disease variants. Nature 518, 337–343 (2015).
McLaren, W. et al. The Ensembl Variant Effect Predictor. Genome Biol. 17, 122 (2016).
Michailidou, K. et al. Association analysis identifies 65 new breast cancer risk loci. Nature 551, 92–94 (2017).
Kawase, T. et al. PH domain-only protein PHLDA3 is a p53-regulated repressor of Akt. Cell 136, 535–550 (2009).
Giambartolomei, C. et al. Bayesian test for colocalisation between pairs of genetic association studies using summary statistics. PLoS Genet. 10, e1004383 (2014).
Burgess, S. et al. Guidelines for performing Mendelian randomization investigations. Wellcome Open Res. 4, 186 (2020).
Surendran, S. et al. An update on vitamin B12-related gene polymorphisms and B12 status. Genes Nutr. 13, 2 (2018).
Todd, J. A. Evidence that UBASH3 is a causal gene for type 1 diabetes. Eur. J. Hum. Genet. 26, 925–927 (2018).
de Lange, K. M. et al. Genome-wide association study implicates immune activation of multiple integrin genes in inflammatory bowel disease. Nat. Genet. 49, 256–261 (2017).
Mosnier, J.-F. et al. ADAM15 upregulation and interaction with multiple binding partners in inflammatory bowel disease. Lab Invest. 86, 1064–1073 (2006).
Jung, I. et al. A compendium of promoter-centered long-range chromatin interactions in the human genome. Nat. Genet. 51, 1442–1449 (2019).
Andersson, R. et al. An atlas of active enhancers across human cell types and tissues. Nature 507, 455–461 (2014).
Thurman, R. E. et al. The accessible chromatin landscape of the human genome. Nature 489, 75–82 (2012).
Visscher, P. M., Brown, M. A., McCarthy, M. I. & Yang, J. Five years of GWAS discovery. Am. J. Hum. Genet. 90, 7–24 (2012).
Soskic, B. et al. Chromatin activity at GWAS loci identifies T cell states driving complex immune diseases. Nat. Genet. 51, 1486–1493 (2019).
Bycroft, C. et al. The UK Biobank resource with deep phenotyping and genomic data. Nature 562, 203–209 (2018).
Wakefield, J. Bayes factors for genome-wide association studies: comparison with P-values. Genet. Epidemiol. 33, 79–86 (2009).
1000 Genomes Project Consortium et al. A global reference for human genetic variation. Nature 526, 68–74 (2015).
Morales, J. et al. A standardized framework for representation of ancestry data in genomics studies, with application to the NHGRI-EBI GWAS Catalog. Genome Biol. 19, 21 (2018).
Adzhubei, I. A. et al. A method and server for predicting damaging missense mutations. Nat. Methods 7, 248–249 (2010).
Zerbino, D. R. et al. Ensembl 2018. Nucleic Acids Res. 46, D754–D761 (2018).
Karczewski, K. J. et al. The mutational constraint spectrum quantified from variation in 141,456 humans. Nature 581, 434–443 (2020).
Stacey, D. et al. ProGeM: a framework for the prioritization of candidate causal genes at molecular quantitative trait loci. Nucleic Acids Res. 47, e3 (2019).
Type 2 Diabetes Knowledge Portal. http://www.type2diabetesgenetics.org/gene/effectorGeneTable (2019).
Gaulton, A. et al. The ChEMBL database in 2017. Nucleic Acids Res. 45, D945–D954 (2017).
Chen, T. & Guestrin, C. XGBoost. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining—KDD ’16. https://doi.org/10.1145/2939672.2939785 (2016).
Friedman, J. H. Greedy function approximation: a gradient boosting machine. Ann. Stat. 29, 1189–1232 (2001).
Pencina, M. J., D’ Agostino, R. B., D’ Agostino, R. B. & Vasan, R. S. Evaluating the added predictive ability of a new marker: from area under the ROC curve to reclassification and beyond. Stat. Med. 27, 157–172 (2008).
Pencina, M. J., D’Agostino, R. B. Sr & Steyerberg, E. W. Extensions of net reclassification improvement calculations to measure usefulness of new biomarkers. Stat. Med. 30, 11–21 (2011).
Sobczyk, M. K., Gaunt, T. R. & Paternoster, L. MendelVar: gene prioritisation at GWAS loci using phenotypic enrichment of mendelian disease genes. Bioinformatics 37, 1–8 (2021).
Acknowledgements
We thank E. McDonagh, J. Maranville and D. Hulcoop for their useful feedback to improve the paper, and H. Parkinson, J. MacArthur, D. Zerbino and K. Alasoo for their support with the GWAS Catalog and eQTL Catalogue data. This research has been conducted using the UK Biobank Resource. This work was funded by Open Targets. E.M. was funded by JDRF (4-SRA-2017-473-A-N) to the Diabetes and Inflammation Laboratory, University of Oxford. This research was funded in part by a Wellcome Trust grant (no. 206194). For the purpose of Open Access, the authors have applied a CC-BY public copyright license to any author-accepted manuscript version arising from this submission.
Author information
Authors and Affiliations
Contributions
M.G., J.S., E.M. and I.D. wrote the manuscript. E.M. conducted the analysis and designed and built the machine-learning model. E.M., E.M.S. and M.G. prioritized GWASs for curation from the GWAS Catalog. E.M., M.C., A.B., J.H. and E.P. curated and processed the GWASs and functional genomics data. E.B.F., E.M. and M.G. curated the gold standards. G.P., A.M., L.F., A.H., E.P. and M.C. designed and implemented visualizations for analysis. J.S. conducted fine-mapping comparisons and Mendelian disease enrichments. D.O. performed additional analysis. I.D., M.G., J.A.T. and J.C.B. conceived and supervised the study. M.A.K. generated Fig. 1. M.G., E.M., E.M.S., D.W. and E.P. worked on the biological questions and the underlying visualizations in the portal.
Corresponding author
Ethics declarations
Competing interests
J.A.T. is a member of the GSK Human Genetics Advisory Board. E.B.F. is a full-time employee of and shareholder in Pfizer, Inc. E.P. was an employee of Biogen at the time of the work. E.P. is now an employee of AstraZeneca. The remaining authors do not have any competing interests.
Additional information
Peer review information Nature Genetics thanks Guillaume Lettre and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Peer review reports are available.
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data
Extended Data Fig. 1 Difference between fine-mapping methods.
a, Histogram of the absolute difference in the number of variants in the 95% credible set across all loci. The median absolute difference was 7 variants. b, Histogram of the posterior probability at a given locus that is contained in variants shared between the 95% credible sets of the two methods, determined for all loci. The median shared variant probability was 0.70.
Extended Data Fig. 2 Minor allele frequency of the lead variant in 1000 Genomes European samples, stratified by the number of variants in the 95% credible set.
Association signals with smaller credible sets tend to be from lower frequency haplotypes. This effect is especially pronounced for the lowest credible set size bins (1 and 2-5).
Extended Data Fig. 3 Schematic showing how variant to gene distance features are calculated.
Distance to the transcription start site (TSS) is the number of bases from the variant to the TSS of the canonical transcript of the gene as defined by Ensembl. Distance to the gene footprint is the smallest number of base pairs between the variant and any position between the TSS and transcription end site of the canonical transcript. (Calculations, left) Some L2G distance features are an average across variants, weighted by each variant’s posterior probability from fine mapping. (Calculations, right) ‘Neighborhood’ features are defined on a log scale relative to the gene with the best score in that category (here, smallest distance). The negative log is used so that genes with better feature values have higher neighborhood scores.
Extended Data Fig. 4 Missingness.
The fraction of variants with missing values (no annotation in that category) is shown for representative input features of the L2G model.
Extended Data Fig. 5 Histogram of the number of prioritized genes (having L2G score ≥ 0.5) at each locus.
Very few loci have more than one gene prioritized.
Extended Data Fig. 6 Mendelian disease genes with matching phenotypes at GWAS loci are enriched for having high L2G scores.
For nine GWAS traits, we show the distribution of L2G scores for all Mendelian disease genes within 100 kb of a GWAS signal, stratified by whether or not the Mendelian disease has a matching phenotype term with the GWAS trait.
Extended Data Fig. 7 Gene enrichment.
Enrichment of genes with model score ≥ 0.5 for the distance-only models (top 2) or the full L2G model (bottom), stratified by whether the gene is a known drug target in ChEMBL phase ≥ 2, ≥ 3, or ≥ 4. Error bars show the 95% confidence interval from a two-sided Fisher’s exact test. The total numbers of positive gene-indication pairs used were 329, 216 and 159 for phases ≥2, ≥3 and ≥4 respectively. The overall sample size, including positive and negative gene-indication pairs, was 104,934.
Extended Data Fig. 8 Feature distributions.
Each plot shows the mean value of a given predictor across different gold-standard datasets (y-axis) for either gold standard positive genes (GSP, green) or gold standard negative genes (GSN, yellow). GSP genes are more easily distinguished from GSN genes by distance in the manually curated datasets (especially Progem, Fauman_twitter, and T2D).
Supplementary information
Rights and permissions
About this article

Cite this article
Mountjoy, E., Schmidt, E.M., Carmona, M. et al. An open approach to systematically prioritize causal variants and genes at all published human GWAS trait-associated loci. Nat Genet 53, 1527–1533 (2021). https://doi.org/10.1038/s41588-021-00945-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41588-021-00945-5
This article is cited by
-
Integrative single-cell analysis: dissecting CD8 + memory cell roles in LUAD and COVID-19 via eQTLs and Mendelian Randomization
Hereditas (2024)
-
Constructing eRNA-mediated gene regulatory networks to explore the genetic basis of muscle and fat-relevant traits in pigs
Genetics Selection Evolution (2024)
-
Development of a human genetics-guided priority score for 19,365 genes and 399 drug indications
Nature Genetics (2024)
-
Leveraging electronic health records and knowledge networks for Alzheimer’s disease prediction and sex-specific biological insights
Nature Aging (2024)
-
Investigation of genetic determinants of cognitive change in later life
Translational Psychiatry (2024)
