
Abstract
Measuring the abundances of carbon and oxygen in exoplanet atmospheres is considered a crucial avenue for unlocking the formation and evolution of exoplanetary systems1,2. Access to the chemical inventory of an exoplanet requires high-precision observations, often inferred from individual molecular detections with low-resolution space-based3,4,5 and high-resolution ground-based6,7,8 facilities. Here we report the medium-resolution (R ≈ 600) transmission spectrum of an exoplanet atmosphere between 3 and 5 μm covering several absorption features for the Saturn-mass exoplanet WASP-39b (ref. 9), obtained with the Near Infrared Spectrograph (NIRSpec) G395H grating of JWST. Our observations achieve 1.46 times photon precision, providing an average transit depth uncertainty of 221 ppm per spectroscopic bin, and present minimal impacts from systematic effects. We detect significant absorption from CO2 (28.5σ) and H2O (21.5σ), and identify SO2 as the source of absorption at 4.1 μm (4.8σ). Best-fit atmospheric models range between 3 and 10 times solar metallicity, with sub-solar to solar C/O ratios. These results, including the detection of SO2, underscore the importance of characterizing the chemistry in exoplanet atmospheres and showcase NIRSpec G395H as an excellent mode for time-series observations over this critical wavelength range10.
Similar content being viewed by others

Main
We obtained a single-transit observation of WASP-39b using the NIRSpec11,12 G395H grating on 30–31 July 2022 between 21:45 and 06:21 UTC using the Bright Object Time Series mode. WASP-39b is a hot (Teq = 1,120 K), low-density giant planet with an extended atmosphere. Previous spectroscopic observations have shown prominent atmospheric absorption by Na, K and H2O (refs. 3,4,13,14,15), with tentative evidence of CO2 from infrared photometry4. Atmospheric models fitted to the spectrum have inferred metallicities (amount of heavy elements relative to the host star) from 0.003 to 300 times solar3,15,16,17,18,19,20, which makes it difficult to ascertain the formation pathway of the planet21,22. The host, WASP-39, is a G8-type star that shows little photometric variability23 and has nearly solar elemental abundance patterns24. The quiet host and extended planetary atmosphere make WASP-39b an ideal exoplanet for transmission spectroscopy25. The transmission spectrum of WASP-39b was observed as part of the JWST Transiting Exoplanet Community Director’s Discretionary Early Release Science (JTEC ERS) Program26,27 (ERS-1366; principal investigators Natalie M. Batalha, Jacob L. Bean and Kevin B. Stevenson), which uses four instrument configurations to test their capabilities and provide lessons learned for the community.
The NIRSpec G395H data were recorded with the 1.6″ × 1.6″ fixed slit aperture using the SUB2048 subarray and NRSRAPID readout pattern, with spectra dispersed across both the NRS1 and NRS2 detectors. Over the roughly 8-h duration of the observation, a total of 465 integrations were taken, centred around the 2.8-h transit. We obtained 70 groups per integration, resulting in an effective integration time of 63.14 s. During the observation, the telescope experienced a ‘tilt event’, a spontaneous and abrupt change in the position of one or more mirror segments, causing changes in the point spread function (PSF) and hence jumps in flux28. The tilt event occurred mid-transit, affecting approximately three integrations and resulted in a noticeable step in the flux time series, the size of which is dependent on wavelength (Fig. 1 and Methods). The tilt event also affects the PSF, with the full width at half maximum (FWHM) of the spectral trace showing a step-function-like shape (see Extended Data Figs. 2 and 3).

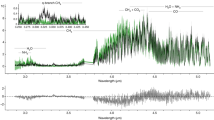
a, Raw, uncorrected broadband light curves from the NRS1 (purple) and NRS2 (red) detectors, demonstrating the lack of dominant systematic trends in the light curves. The inset shows the drop in flux (grey-shaded region) caused by a mirror-tilt event, resulting in a distinct change in flux between NRS1 and NRS2 after the tilt event (see Extended Data Figs. 2 and 3). b, Pixel intensity map of the spectroscopic light curves after correction for the tilt event and further instrument systematics. c, Light-curve precision obtained per spectroscopic bin (black) compared with 1 and 2 times photon noise expectations (grey dashed lines) and the measured precision on the transit depth (blue). The gap between the two detectors (3.72–3.82 μm) is highlighted in the middle and bottom plots. All data shown are from fitting pipeline 1 (see Methods).
We produced several reductions of the observations using independent analysis pipelines (see Methods). For each reduction, we created broadband and spectroscopic light curves in the ranges 2.725–3.716 μm for NRS1 and 3.829–5.172 μm for NRS2 using 10-pixel-wide bins (≈0.007 μm, median resolution R ≈ 600), excluding the detector gap between 3.717–3.823 μm. The light curves show a settling ramp during the first ten integrations (≈631.4 s), with a linear slope across the entire observation for NRS1. We otherwise see no substantial systematic trends and achieve improvements in precision from raw uncorrected to fitted broadband light curves of 1.63 to 1.03 times photon noise for NRS1 and 1.95 to 1.31 times for NRS2. The flux jump caused by the mirror-tilt event could be corrected by detrending against the spectral trace x and y positional shifts, normalizing the light curves or fitting the light curves with a step function (see Methods). We produced several fits from each set of light curves, resulting in a total of 11 independently measured transmission spectra. Figure 1 demonstrates that our spectroscopic light curves achieve precisions close to photon noise, with a median precision of 1.46 times photon noise across the full wavelength range (see Extended Data Fig. 4).
We show transmission spectra from several combinations of independent reductions and light-curve-fitting routines in Fig. 2, along with the weighted average of all 11 transmission spectra with the unweighted mean uncertainty produced by our analyses (see Methods). We find that using different combinations of reduction and fitting methods results in consistent transmission spectra (see Methods and Extended Data Fig. 5). Although we see some artefacts at the edges of the detectors (see Fig. 3, bottom panel) that may be caused by uncharacterized systematics, these only affect a small number of wavelength bins. Our resulting averaged NIRSpec G395H spectrum shows increased absorption towards bluer wavelengths short of 3.7 μm and a prominent absorption feature between 4.2 and 4.5 μm, along with a smaller-amplitude absorption feature at 4.1 μm and a narrow feature around 4.56 μm.

We show the resultant spectra from five out of 11 independent fitting pipelines, which used distinct analysis methods to demonstrate the robust structure of the spectrum (see Methods for details on each fitting pipeline and comparative statistics). The black points show the weighted-average transmission spectrum computed from the transit depth values in each bin weighted by 1/σ2, in which σ is the uncertainty on the data point from each of the 11 fitting pipelines. The error bars were computed from the unweighted mean uncertainty in each bin (see Extended Data Fig. 5). All spectra show consistent broadband absorption short of 3.7 μm, around 4.1 μm and from 4.2 to 4.5 μm.

a, Spectra from the three models. b, Their residuals. The models are dominated by absorption from H2O and CO2 with a grey-cloud-top pressure corresponding to ≈1 mbar. The models find that the data are best explained by 3–10 times solar metallicity (M/H) and sub-solar to solar C/O (C/O = 0.30–0.46). The extra absorption owing to SO2, seen in the spectrum around 4.1 μm, is not included in the RCTE model grids and causes a marked impact on the χ2/N (see Fig. 4).
We compared the weighted-average G395H transmission spectrum to three grids of 1D radiative–convective–thermochemical equilibrium (RCTE) atmosphere models of WASP-39b (see Methods and Extended Data Table 2), containing a total of 10,308 model spectra. The best-fit models from each grid provide a reduced chi-square per data point (χ2/N) of 1.08–1.20 for our 344-data-point transmission spectrum (Fig. 3). The increased absorption at blue wavelengths across NRS1 is consistent with absorption from H2O (at 21.5σ; see Methods), whereas the large bump in absorption between 4.2 and 4.5 μm (ref. 29) can be attributed to CO2 (28.5σ). H2O and CO2 are expected atmospheric constituents for near-solar atmospheric metallicities, with the CO2 abundance increasing nonlinearly with higher metallicity30. The spectral feature at 4.56 μm (3.3σ) is unidentified at present but does not correlate with any obvious detector artefacts and is reproduced by several independent analyses. The absorption feature at 4.1 μm is also not seen in the RCTE model grids. After an exhaustive search for possible opacity sources (S.-M. Tsai et al., manuscript in preparation), described in the corresponding NIRSpec PRISM analysis31, we interpret this feature as SO2 (4.8σ), as it is the best candidate at this wavelength.
Although SO2 would have volume mixing ratios (VMRs) of less than 10−10 throughout most of the observable atmosphere in thermochemical equilibrium, coupled photochemistry of H2S and H2O can produce SO2 on giant exoplanets, with the resulting SO2 mixing ratio expected to increase with increasing atmospheric metallicity32,33,34. We find that a VMR of approximately 10−6 of SO2 is required to fit the spectral feature at 4.1 μm in the transmission spectrum of WASP-39b, consistent with lower-resolution NIRSpec PRISM observations of this planet31 and previous photochemical modelling of super-solar metallicity giant exoplanets34,35. Figure 4 shows a breakdown of the contributing opacity sources for the lowest χ2/N best-fit model (PICASO 3.0) with VMR = 10−5.6 injected SO2. The inclusion of SO2 in the models results in an improved χ2/N and is detected at 4.8σ (see Methods), confirming its presence in the atmosphere of WASP-39b.

a, The lowest χ2/N best-fitting model (PICASO in Fig. 3) with an injected abundance of 10−5.6 (VMR) SO2. We also show this model with a selection of the anticipated absorbing species and the cloud opacity removed to indicate their contributions to the model. The inclusion of SO2 in the model decreases the χ2/N from 1.08 (shown in Fig. 3) to 1.02, resulting in a 4.8σ detection (see Extended Data Table 3). b–e, The effect of removing the corresponding molecular opacity from the spectrum (shaded region). Our best-fit model is also affected by minor opacities from CO, H2S, OCS and CH4, although their spectral features cannot be robustly detected in the spectrum. We show a model without CO and CH4 in a to demonstrate this, with the minor contribution by CO also highlighted in e.
We also look for evidence of CH4, CO, H2S and OCS (carbonyl sulfide) because their near-solar chemical equilibrium abundances could result in a contribution to the spectrum. We see no evidence of CH4 in our spectrum between 3.0 and 3.6 μm (ref. 23), which is indicative of C/O < 1 (ref. 36) and/or photochemical destruction34,37. With regards to CO, H2S and OCS, we were unable to conclusively confirm their presence with these data. In particular, CO, H2O, OCS and our modelled cloud deck all have overlapping opacity, which creates a pseudo-continuum from 4.6 to 5.1 μm (see Figs. 3 and 4). Therefore, we were unable to unambiguously identify the individual contributions from CO and other molecules over this wavelength region at the resolution presented in this work.
Our models show an atmosphere enriched in heavy elements, with best-fit parameters ranging from 3 to 10 times solar metallicity, given the spacing of individual model grids (see Methods). The spectra also indicate C/O ratios ranging from sub-solar to solar depending on the grid used, informed by the relative strength of absorption from carbon-bearing molecules to oxygen-bearing molecules. The interpretation of the relatively high resolution and precision of the G395H spectrum seems to be sensitive to the treatment of aerosols in the model, with one grid preferring 3 times solar metallicity when using a wavelength-dependent cloud opacity and physically motivated vertical cloud distribution38 but 10 times solar metallicity when assuming a grey cloud. In general, forward model grids fit the main features of the data but do not place statistically significant constraints on many of the atmospheric parameters (see Methods). Future interpretation of the JTEC ERS WASP-39b data with Bayesian retrieval analyses will provide robust confidence intervals for these planetary properties and explore the degree to which these data are sensitive to modelling assumptions (for example, chemical equilibrium versus disequilibrium) and parameter degeneracies (for example, clouds versus atmospheric metallicity).
We are able to strongly rule out an absolute C/O ≥ 1 scenario (χ2/N ≥ 3.97), which has previously been proposed for gas-dominated accretion at wide orbital radii beyond the CO2 ice line at which the gas may be carbon-rich39. Our C/O upper limit, therefore, suggests that WASP-39b may have either formed at smaller orbital radii with gas-dominated accretion or that the accretion of solids enriched the atmosphere of WASP-39b with oxygen-bearing species2. The level of metal enrichment (3–10 times solar) is consistent with similar measurements of Jupiter and Saturn40,41, potentially suggesting core-accretion formation scenarios42, and is consistent with upper limits from interior-structure modelling43. These NIRSpec G395H transmission spectroscopy observations demonstrate the promise of robustly characterizing the atmospheric properties of exoplanets with JWST unburdened by substantial instrumental systematics, unravelling the nature and origins of exoplanetary systems.
Methods
Data reduction
We produced several analyses of stellar spectra from the Stage 1 2D spectral images produced using the default STScI JWST Calibration Pipeline44 (‘rateints’ files) and by means of customized runs of the STScI JWST Calibration Pipeline with user-defined inputs and processes for steps such as the ‘jump detection’ and ‘bias subtraction’ steps.
Each pipeline starts with the raw ‘uncal’ 2D images that contain group-level products. As we noticed that the default superbias images were of poor quality, we produced two customized runs of the JWST Calibration Pipeline, using either the default bias step or a customized version. The customized step built a pseudo-bias image by computing the median pixel value in the first group across all integrations and then subtracted the new bias image from all groups. We note that the poor quality of the default superbias images affects NRS1 more notably than NRS2, and this method could be revised once a better superbias is available.
Before ramp fitting, both our standard and custom bias step runs of the edited JWST Calibration Pipeline ‘destriped’ the group-level images to remove so-called ‘1/f noise’ (correlated noise arising from the electronics of the readout pattern, which appears as column striping in the subarray images11,12). Our group-level destriping step used a mask of the trace 15σ from the dispersion axis for all groups within an integration, ensuring that a consistent set of pixels is masked within a ramp. The median values of non-masked pixels in each column were then computed and subtracted for each group.
The results of our customized runs of the JWST Calibration Pipeline are a set of custom group-level destriped products and custom bias-subtracted group-level destriped products. In both cases, the ramp-jump detection threshold of the JWST Calibration Pipeline was set to 15σ (as opposed to the default of 4σ), as it produced the most consistent results at the integration level. In both custom runs of the JWST Calibration Pipeline, all other steps and inputs were left at the default values.
For all analyses, wavelength maps from the JWST Calibration Pipeline were used to produce wavelength solutions, verified against stellar absorption lines, for both detectors. The mid-integration times in BJDTDB were extracted from the image headers for use in producing light curves. None of our data-reduction pipelines performed a flat-field correction, as the available flat fields were of poor quality and unexpectedly removed portions of the spectral trace. In general, we found that 1/f noise can be corrected at either the group or integration levels to similar effect; however, correction at the group level with a repeated column-by-column cleaning step at the integration level probably results in cleaner 1D stellar spectra. This was particularly true for NRS2, owing to the limited number of columns in which the unilluminated region on the detector extends both above and below the spectral trace, as shown in Extended Data Fig. 1.
Below we detail each of the independent data-reduction pipelines used to produce the time series of stellar spectra from our G395H observations.
ExoTiC-JEDI pipeline
We used the Exoplanet Timeseries Characterisation - JWST Extraction and Diagnostics Investigator (ExoTiC-JEDI45) pipeline on our custom group-level destriped products, treating each detector separately. Using the data-quality flags produced by the JWST Calibration Pipeline, we replaced any pixels identified as bad, saturated, dead, hot, low quantum efficiency or no gain value with the median value of surrounding pixels. We also searched each integration for pixels that were spatial outliers from the median of the surrounding 20 pixels in the same row by 6σ (to remove permanently affected ‘bad’ pixels) or outliers from the median of that pixel in the surrounding ten integrations in time by 20σ (to identify high-energy short-term effects such as cosmic rays) and replaced the outliers with the median values. To obtain the trace position and FWHM, we fitted a Gaussian to each column of an integration, finding a median standard deviation of 0.7 pixels. A fourth-order polynomial was fitted through the trace centres and the widths, which were smoothed with a median filter, to obtain a simple aperture region. This region extended 5 times the FWHM of the spectral trace, above and below the centre, corresponding to a median aperture width of 7 pixels. To remove any remaining 1/f and background noise from each integration, we subtracted the median of the unilluminated region in each column by masking all pixels that were 5 pixels away from the aperture. For each integration, the counts in each row and column of the aperture region were summed using an intrapixel extraction, taking the relevant fractional flux of the pixels at the edge of the aperture and cross-correlated to produce x-pixel and y-pixel shifts for detrending (see Extended Data Fig. 2). On average, the x-pixel shift represents movement of 1 × 10−4 and 8 × 10−6 of a pixel for NRS1 and NRS2, respectively. The aperture column sums resulted in 1D stellar spectra with errors calculated from photon noise after converting from data numbers using the gain factor. This reduction is denoted hereafter as ExoTiC-JEDI [V1].
We produced further 1D stellar spectra from both the custom group-level destriped product and custom bias-subtracted group-level destriped products using the ExoTiC-JEDI pipeline as described above, but with further cleaning by repeating the spatial outliers step. The reduction with further cleaning using the custom group-level destriped products is hence denoted as ExoTiC-JEDI [V2] and the reduction with further cleaning using the custom bias-subtracted group-level destriped products is hence denoted as ExoTiC-JEDI [V3].
Tiberius pipeline
We used the Tiberius pipeline, which builds on the LRG-BEASTS spectral reduction and analysis pipelines15,46,47, on our custom group-level destriped products. For each detector, we created bad-pixel masks by manually identifying hot pixels in the data. We then combined them with pixels flagged as greater than 3σ above the defined background. Before identifying the spectral trace, we interpolated each column of the detectors onto a grid 10 times finer than the initial spatial resolution. This step reduces the noise in the extracted data by improving the extraction of flux at the sub-pixel level, particularly where the edges of the photometric aperture bisect a pixel. We also interpolated over the bad pixels using their nearest-neighbouring pixels in x and y.
We traced the spectra by fitting Gaussians at each column and used a running median, calculated with a moving box with a width of five data points, to smooth the measured centres of the trace. We fitted these smoothed centres with a fourth-order polynomial, removed points that deviated from the median by 3σ and refitted with a fourth-order polynomial. To remove any residual background flux not captured by the group-level destriping, we fitted a linear polynomial along each column, masking the stellar spectrum. This was defined by an aperture with a width of 4 pixels centred on the trace. We also masked an extra 7 pixels on either side of the aperture so that the background was not fitting the wings of the stellar PSF and we clipped any pixels in the background that deviated by more than 3σ from the mean for that particular column and frame. After removing the background in each column, the stellar spectra were then extracted by summing within a 4-pixel-wide aperture and correcting for pixel oversampling caused by the interpolation onto a finer grid, as described above. The uncertainties in the stellar spectra were calculated from the photon noise before background subtraction.
transitspectroscopy pipeline
We used the transitspectroscopy pipeline48 on the ‘rateints’ products of the JWST Calibration Pipeline, treating each detector separately. The trace position was found from the median integration by cross-correlating each column with a Gaussian function, removing outliers using a median filter with a 10-pixel-wide window and smoothing the trace with a spline. We removed 1/f noise from the ‘rateints’ products by masking all pixels within 10 pixels from the centre of the trace and calculating and removing the median value from all columns. We then used optimal extraction49 to obtain the 1D stellar spectra, with a 5-pixel-wide aperture above and below the trace. This allowed us to treat bad pixels and cosmic rays that had not been accounted for or masked in the ‘rateints’ products in an automated fashion. To monitor systematic trends in the observations, we also calculated the trace centre as described above and the FWHM for all integrations. The FWHM was calculated at each column and at each integration by first subtracting each column to half the maximum value in it, with a spline used to interpolate the profile. The roots of this profile were then found to estimate the FWHM.
Eureka! pipeline
We used two customized versions of the Eureka! pipeline50, which combines standard steps from the JWST Calibration Pipeline with an optimal extraction scheme to obtain the time series of stellar spectra.
The first Eureka! reduction used our custom group-level destriped products and applied Stages 2 and 3 of Eureka! Stage 2, a wrapper of the JWST Calibration Pipeline, followed the default settings up to the flat fielding and photometric calibration steps, which were both skipped. Stage 3 of Eureka! was then used to perform the background subtraction and extraction of the 1D stellar spectra. We started by correcting for the curvature of NIRSpec G395H spectra by shifting the detector columns by whole pixels, to bring the peak of the distribution of the counts in each column to the centre of our subarray. To ensure that this curvature correction was smooth, we computed the shifts in each column for each integration from the median integration frame in each segment and applied a running median to the shifts obtained for each column. The pixel shifts were applied with periodic boundary conditions, such that pixels shifted upwards from the top of the subarray appeared at the bottom after the correction, ensuring no pixels were lost. We applied a column-by-column background subtraction by fitting and subtracting a flat line to each column of the curvature-corrected data frames, obtained by fitting all pixels further than six pixels from the central row. We also performed a double iteration of outlier rejection in time with a threshold of 10σ, along with a 3σ spatial outlier-rejection routine, to ensure that bad pixels were not biasing our background correction. These outlier-rejection thresholds were selected to remove clear outliers in the data and provide a balance with the background subtraction step. We performed optimal extraction using an extraction profile defined from the median frame, the central nine rows of our subarray (four rows on either side of the central row). We also measured the vertical shift in pixels of the spectrum from one integration to the other using cross-correlation and the average PSF width at each integration, obtained by adding all columns together and fitting a Gaussian to the profile to estimate its width. This reduction is henceforth denoted as Eureka! [V1].
The second Eureka! reduction (Eureka! [V2]) used the ‘rateints’ outputs of the JWST Calibration Pipeline and applied Stage 2 of Eureka! as described above, with a modified version of Stage 3. In this reduction, we corrected the curvature of the trace using a spline and found the centre of the trace using the median of each column. We removed 1/f noise by subtracting the mean from each column, excluding the region 6 pixels away from the trace, sigma-clipping outliers at 3σ. We extracted the 1D stellar spectra using a 4-pixel-wide aperture on either side of the trace centre.
Limb-darkening
Limb-darkening is a function of the physical structure of the star that results in variations in the specific intensity of the light from the centre of the star to the limb, such that the limb looks darker than the centre. This is because of the change in depth of the stellar atmosphere being observed. At the limb of the star, the region of the atmosphere being observed at slant geometry is at higher altitudes and lower density, and thus lower temperatures, compared with the deeper atmosphere observed at the centre of the star, at which hotter, denser layers are observed. The effect of limb-darkening is most prominent at shorter wavelengths, resulting in a more U-shaped light curve compared with the flat-bottomed light curves observed at longer wavelengths. To account for the effects of limb-darkening on the time-series light curves, we used analytical approximations for computing the ratio of the mean intensity to the central intensity of the star. The most commonly used limb-darkening laws for exoplanet transit light curves are the quadratic, square-root and nonlinear four-parameter laws51:
Quadratic:
Square-root:
Nonlinear four-parameter:
in which I(1) is the specific intensity in the centre of the disk, u1, u2, s1, s2, c1, c2, c3 and c4 are the limb-darkening coefficients and μ = cos(γ), in which γ is the angle between the line of sight and the emergent intensity.
The limb-darkening coefficients depend on the particular stellar atmosphere and therefore vary from star to star. For consistency across all of the light-curve fitting, we used 3D stellar models52 for Teff = 5,512 K, log(g) = 4.47 cgs and Fe/H = 0.0, along with the instrument throughput to determine I and μ. As instrument commissioning showed that the throughput was higher than the pre-mission expectations53, a custom throughput was produced from the median of the measured ExoTiC-JEDI [V2] stellar spectra, divided by the stellar model and Gaussian smoothed.
For the limb-darkening coefficients that were held fixed, we used the values computed using the ExoTiC-LD54,55 package, which can compute the linear, quadratic and three-parameter and four-parameter nonlinear limb-darkening coefficients51,56. To compute and fit for the coefficients from the square-root law, we used previously outlined formalisms57,58. We highlight that we do not see any dependence in our transmission spectra on the limb-darkening procedure used across our independent reductions and analyses.
Light-curve fitting
From the time series of extracted 1D stellar spectra, we created our broadband transit light curves by summing the flux over 2.725–3.716 μm for NRS1 and 3.829–5.172 μm for NRS2. For the spectroscopic light curves, we used a common 10-pixel binning scheme within these wavelength ranges to generate a total of 349 spectroscopic bins (146 for NRS1 and 203 for NRS2). We also tested wider and narrower binning schemes but found that 10-pixel-wide bins achieved the best compromise between the noise in the spectrum and showcasing the abilities of G395H across analyses. In our analyses, we treated the NRS1 and NRS2 light curves independently to account for differing systematics across the two detectors. To construct the full NIRSpec G395H transmission spectrum of WASP-39b, we fitted the NRS1 and NRS2 broadband and spectroscopic light curves using 11 independent light-curve-fitting codes, which are detailed below. When starting values were required, all analyses used the same system parameters37. In many of our analyses, we detrended the raw broadband and spectroscopic light curves using the time-dependent decorrelation parameters for the change in the FWHM of the spectral trace or the shift in x-pixel and y-pixel positions (Extended Data Fig. 2). We also used various approaches to account for the mirror-tilt event, which we found to have a smaller effect at longer wavelengths (Extended Data Fig. 3).
Using fitting pipeline 1, we measured a centre of transit time (T0) of T0 = 2,459,791.612039 ± 0.000017 BJDTDB and T0 = 2,459,791.6120689 ± 0.000021 BJDTDB computed from the NRS1 and NRS2 broadband light curves, respectively; most of the fitting pipelines obtained T0 within 1σ of the quoted uncertainty.
For each of our analyses, we computed the expected photon noise from the raw counts taking into account the instrument read noise (16.18 e− on NRS1 and 17.75 e− on NRS2), gain (1.42 for NRS1 and 1.62 for NRS2) and the background counts (which are found to be negligible after cleaning) and compared it to the final signal-to-noise ratio in our light curves (see Fig. 1). We also determine the level of white and red noise in our spectroscopic light curves by computing the Allan deviation59, which is used to measure the deviation from the expected photon noise by binning the data into successively smaller bins (that is, fewer data points per bin) and calculating the signal-to-noise ratio achieved60. Extended Data Fig. 4 shows the Allan deviation for three of the 11 reductions performed on the data (see the ExoTiC-ISM noise_calculator function54).
Although there is a general consensus across each of the data analyses, by comparing the results of each fitting pipeline, we were better able to evaluate the impact of different approaches to the data reduction, such as the removal of bad pixels. For future studies, we recommend the application of several pipelines that use differing analysis methods, such as the treatment of limb-darkening, systematic effects and noise removal. No single pipeline presented on its own can fully evaluate the measured impact of each effect, given the differing strategies, targets and potential for chance events such as a mirror tilt with each observation. In particular, attention should be paid to 1/f noise removal at the group versus integration levels for observations with fewer groups per integration than this study.
Below, we detail each of our 11 fitting pipelines and summarise them in Extended Data Table 1.
Fitting pipeline 1: ExoTiC-JEDI
We fitted the broadband and spectroscopic light curves produced from the ExoTIC-JEDI [V3] stellar spectra using the least-squares optimizer, scipy.optimize lm (ref. 61). We simultaneously fitted a batman transit model62 with a constant baseline and systematics models for data pre-tilt and post-tilt event, fixing the centre of transit time T0, the ratio of the semi-major axis to stellar radius a/R⋆ and the inclination i to the broadband light-curve best-fit values. The systematics models included a linear regression on x and y, for which x and y are the measured trace positions in the dispersion and cross-dispersion directions, respectively. We accounted for the tilt event by normalizing the light curve pre-tilt by the median pre-transit flux and normalizing the light curve post-tilt by the median post-transit flux. We discarded the first 15 integrations and the three integrations during the tilt event. Fourteen-pixel columns were discarded owing to outlier pixels directly on the trace. We fixed the limb-darkening coefficients to the four-parameter nonlinear law.
Fitting pipeline 2: Tiberius
We used the broadband light curves generated from the Tiberius stellar spectra and fitted for the ratio of the planet to stellar radii Rp/R⋆, as well as i, T0, a/R⋆, the quadratic law limb-darkening coefficient u1 and the systematics model parameters, the x-pixel and y-pixel shifts, FWHM and sky background, with the period P, the eccentricity e and u2 fixed. We used uniform priors for all the fitted parameters. Our analytic transit light-curve model was generated with batman. We fitted our broadband light curve with a transit + systematics model using a Gaussian process (GP)63,64, implemented through george65, and a Markov chain Monte Carlo method, implemented through emcee66. For our Tiberius spectroscopic light curves, we held a/R⋆, i and T0 fixed to the values determined from the broadband light-curve fits and applied a systematics correction from the broadband light-curve fit to aid in fitting the mirror-tilt event. We fitted the spectroscopic light curves using a GP with an exponential squared kernel for the same systematics detrending parameters detailed above. We used a Gaussian prior for a/R⋆ and uniform priors for all other fitted parameters.
Fitting pipeline 3: Aesop
We used transit light curves from the ExoTiC-JEDI [V1] stellar spectra and fit the broadband and spectroscopic light curves using the least-squares minimizer LMFIT67. We fitted each light curve with a two-component function consisting of a transit model (generated using batman) multiplied by a systematics model. Our systematics model included the x-pixel and y-pixel positions on the detector (x, y, xy, x2 and y2). To capture the amplitude of the tilt event in our systematics model, we carried out piecewise linear regression on the out-of-transit baseline pre-tilt and post-tilt. We first fit the broadband light curve by fixing P and e and fitting for T0, a/R⋆, i, Rp/R⋆, stellar baseline flux and systematic trends using wide uniform priors. For the spectroscopic light curves, we fixed T0, a/R⋆ and i to the best-fit values from the broadband light curve and fit for Rp/R⋆. We held the nonlinear limb-darkening coefficients fixed.
Fitting pipeline 4: transitspectroscopy
We fit the broadband and spectroscopic light curves produced from the transitspectroscopy stellar spectra, running juliet68 in parallel with the light-curve-fitting module of the transitspectroscopy pipeline48 with dynamic nested sampling through dynesty69 and analytical transit models computed using batman. We fit the broadband light curves for NRS1 and NRS2 individually, fixing P, e and ω and fitting for the impact parameter b, as well as T0, a/R⋆, Rp/R⋆, extra jitter and the mean out-of-transit flux. We also fitted two linear regressors, a simple slope and a ‘jump’ (a regressor with zeros before the tilt event and ones after the tilt event), scaled to fit the data. We fitted the square-root-law limb-darkening coefficients using the Kipping sampling scheme. We fitted the spectroscopic light curves at the native resolution of the instrument, fixing T0, a/R⋆ and b. We used the broadband light-curve systematics model for the spectroscopic light curve, with wide uniform priors for each wavelength bin, and set truncated normal priors for the square-root-law limb-darkening coefficients. We also fitted a jitter term added in quadrature to the error bars at each wavelength with a log-uniform prior between 10 and 1,000 ppm. We computed the mean of the limb-darkening coefficients by first computing the nonlinear coefficients from ATLAS models70 and passing them through the SPAM algorithm71. We binned the data into 10-pixel-wavelength bins after fitting the native-resolution light curves.
Fitting pipeline 5: ExoTEP
We fitted the transit light curves from the Eureka! [V1] stellar spectra using the ExoTEP analysis framework72,73,74,75. ExoTEP uses batman to generate analytical light-curve models, adds an analytical instrument systematics model along with a photometric scatter parameter and fits for the best-fit parameters and their uncertainties using emcee. Before fitting, we cleaned the light curves by running ten iterations of 5σ clipping using a running median of window length 20 on the flux, x-pixel and y-pixel shifts and the ‘ydriftwidth’ data product from Eureka! Stage 3 (the average spatial PSF width at each integration). Our systematics model consisted of a linear trend in time with a ‘jump’ (constant offset) after the tilt event. The ‘ydriftwidth’ was used before the fit to locate the tilt event. We used a running median of ‘ydriftwidth’ to search for the largest offset and flagged every data point after the tilt event so that they would receive a constant ‘jump’ offset in our systematics model. We also removed the first point of the tilt event in our fits, as it was not captured by the ‘jump’ model. We fitted the broadband light curves, fitting for Rp/R⋆, photometric scatter, T0, b, a/R⋆, the quadratic limb-darkening coefficients and the systematics model parameters (normalization constant, slope in time and constant ‘jump’ offset). We used uninformative flat priors on all the parameters. The orbital parameters were fixed to the best-fit broadband light curve values for the subsequent spectroscopic light-curve fits.
Fitting pipeline 6
We fitted transit light curves from the ExoTiC-JEDI [V1] stellar spectra using a custom lmfit light-curve-fitting code. The final systematic detrending model included a batman analytical transit model multiplied by a systematics model consisting of a linear stellar baseline term, a linear term for the x-pixel and y-pixel shifts and an exponential ramp function. The tilt event was accounted for by decorrelating the light curves with the y-pixel shifts, using a (1 + constant × y-shift) term with the constant fitted for in each light curve. For the broadband light-curve fits, we fixed P and fitted for T0, i, Rp/R⋆, a/R⋆, x-pixel and y-pixel shifts and the exponential ramp amplitude and timescale. We fixed the nonlinear limb-darkening coefficients. For the spectroscopic light-curve fits, we fixed the values of T0, i and a/R⋆ and the exponential ramp timescale to the broadband light-curve-fit values, and fitted for Rp/R⋆, the x-pixel and y-pixel shifts and the ramp amplitude. Wide, uniform priors were used on all the fitting parameters in both the broadband and spectroscopic light-curve fits.
Fitting pipeline 7
We fitted transit light curves from the Eureka! [V2] stellar spectra, using PyLightcurve (ref. 75) to generate the transit model with emcee as the sampler. We calculated the nonlinear four-parameter limb-darkening coefficients using ExoTHETyS (ref. 76), which relies on PHOENIX 2012–2013 stellar models77,78, and fixed these in our fits to the precomputed theoretical values. Our full transit + systematics model included a transit model multiplied by a second-order polynomial in the time domain. We accounted for the tilt event by subtracting the mean of the last 30 integrations of the pre-transit data from the mean of the first 30 integrations of the post-transit data, to account for the jump in flux, shifting the post-transit light curve upwards by the jump value. We fitted for the systematics (the parameters of the second-order polynomial), Rp/R⋆ and T0. We used uniform priors for all the fitted parameters. We adopted the root mean square of the out-of-transit data as the error bars for the light-curve data points to account for the scatter in the data.
Fitting pipeline 8
We used the transit light curves generated from the ExoTiC-JEDI [V1] stellar spectra. We fit the broadband light curves with a batman transit model multiplied by a second-order systematics model as a function of x-pixel and y-pixel shifts. We fixed both of the quadratic limb-darkening coefficients for each wavelength bin. We fitted for Rp/R⋆, i, T0 and a/R⋆, using wide uninformed priors, and ran our fits using emcee. For the spectroscopic light-curve fits, we fixed i and a/R⋆ to the broadband light-curve best-fit values and fitted for an extra error term added in quadrature.
Fitting pipeline 9
We used the transit light curves from the ExoTiC-JEDI [V1] stellar spectra. We fixed both of the quadratic limb-darkening coefficients and fitted the light curves with a batman transit model multiplied by a systematics model of a second-order function of x-pixel and y-pixel shifts. We fixed the best-fit broadband light-curve values for T0, a/R⋆ and i for the spectroscopic light-curve fits and fitted for Rp/R⋆ using emcee for each 10-pixel bin, with the walkers initialized in a tight cluster around the best-fit solution from a Levenberg–Marquardt minimization. For both the broadband and spectroscopic light curves, we also fit for an extra per-point error term.
Fitting pipeline 10
We fitted the transit light curves from the ExoTiC-JEDI [V2] stellar spectra and performed our model fitting using automatic differentiation implemented with JAX (ref. 79). We used a GP systematics model with a time-dependent Matérn (ν = 3/2) kernel and a variable white-noise jitter term. The mean function consists of a linear trend in time plus a sigmoid function to account for the drop in measured flux that occurred mid-transit owing to the mirror-tilt event. For the transit model, we used the exoplanet package80, making use of previously developed light-curve models81,82. For the GP systematics component, a generalization of the algorithm used by the celerite package83 was adapted for JAX. We fixed both of the quadratic limb-darkening coefficients. For the initial broadband light-curve fit, both NRS1 and NRS2 were fitted simultaneously. All transit parameters were shared across both light curves, except for Rp/R⋆, which was allowed to vary for NRS1 and NRS2 independently. We fitted for T0, the transit duration b and both Rp/R⋆ values. For the spectroscopic light-curve fits, all transit parameters were then fixed to the maximum-likelihood values determined from the broadband fit, except for Rp/R⋆, which was allowed to vary for each wavelength bin. Uncertainties for the transit model parameters, including Rp/R⋆, were assumed to be Gaussian and estimated using the Fisher information matrix at the location of the maximum-likelihood solution, which was computed exactly using the JAX automatic differentiation framework.
Fitting pipeline 11: Eureka!
We used transit light curves from the Eureka! [V2] time-series stellar spectra with the open-source Eureka! code to estimate the best-fit transit parameters and their uncertainties using a Markov chain Monte Carlo method fit to the data (implemented by emcee). A linear trend in time was used as a systematics model and a step function was used to account for the tilt event. We fixed a/R⋆, i, T0 and the time of the tilt event to the best-fit values from the NRS1 broadband light curve, with the three integrations during the tilt event clipped from the light curve. We fitted for Rp/R⋆, both quadratic limb-darkening coefficients, the linear time trend and the magnitude of the step from the tilt event, with uniform priors for both the magnitude of the step and the limb-darkening coefficients.
Transmission spectral analysis
On the basis of the independent light-curve fits described above, we produced 11 transmission spectra from our NIRSpec G395H observations using several analyses and fitting methods. Extended Data Table 1 shows a breakdown of the different steps used in each fitting pipeline. In this work, three different 2D spectral image products were used, producing seven different 1D stellar spectra. Eleven different fitting pipelines using five different limb-darkening methods were then applied. Each of these fitting pipelines resulted in an independent analysis of the observations and 11 comparative transmission spectra. Extended Data Fig. 5 details comparative information for all 11 analyses to quantify their similarities and differences.
We computed the standard deviation of the 11 spectra in each wavelength bin and compared this to the mean uncertainty obtained in that bin. The average standard deviation in each bin across all fitting pipelines was 199 ppm, compared with an average uncertainty of 221 ppm (which ranged from 131 to 625 ppm across the bins). The computed standard deviation in each bin across all pipelines ranged from 85 to 1,040 ppm, with greater than 98% of the bins having a standard deviation lower than 500 ppm. We see an increase in scatter at longer wavelengths, with the structure of the scatter following closely with the measured stellar flux, for which throughput beyond 3.8 μm combines with decreasing stellar flux. The unweighted mean uncertainty of all 11 transmission spectra follows a similar structure to the standard deviation, with the uncertainty increasing at longer wavelengths. The uncertainties from each fitting pipeline are consistent to within 3σ of each other, with the uncertainty per bin typically overestimated compared with the mean uncertainty across all reductions.
From all 11 transmission spectra, we computed a weighted-average transmission spectrum using the transit depth values from all reductions in each bin weighted by 1/variance (1/σ2, in which σ is the uncertainty on the data point from each reduction). For this weighted-average transmission spectrum, the unweighted mean of the uncertainties in each bin was used to represent the error bar on each point. By using the weighted average of all 11 independently obtained transmission spectra, we therefore do not apply infinite weight to any one reduction in our interpretation of the atmosphere. Although the weighted average could be sensitive to any one spectrum with underestimated uncertainties, we find that our uncertainties are typically overestimated compared with the average. Similarly, we chose to use the mean rather than the median of the transmission spectral uncertainties, as this results in a more conservative estimate of the uncertainties in each bin. We find that all of the 11 transmission spectra are within 2.95σ of the weighted-average transmission spectrum without applying offsets.
We calculated normalized transmission spectrum residuals for each fitting pipeline by subtracting the weighted-average spectrum and dividing by the uncertainty in each bin. We generated histograms of the normalized transmission spectrum residuals and used the mean and standard deviation of the residuals to compute a normalized probability density function (PDF). We performed a Kolmogorov–Smirnov test on each of the normalized residuals and found that they are all approximately symmetric around their means, with normal distributions. This confirms that they are Gaussian in shape, with the null hypothesis that they are not Gaussian strongly rejected in the majority of cases (see Extended Data Fig. 5).
The PDFs of the residuals indicate three distinct clusters of computed spectra based on their deviations from the mean and their spreads. The first cluster is negatively offset by less than 200 ppm and corresponds to fitting pipelines that used extracted stellar spectra and that underwent further cleaning steps (for example, ExoTiC-JEDI [V3]). The second cluster is positively offset from the mean by about 120 ppm and contains most of the transmission spectra produced. We see no obvious trends in this group to any specific reduction or fitting process. The final cluster is centred around the mean but has a broad distribution, suggesting a larger scatter both above and below the average transmission spectrum. This is probably the result of uncleaned outliers or marginal offsets between NRS1 and NRS2. These transmission spectra demonstrate that the 11 independent fitting pipelines are able to accurately reproduce the same transmission spectral feature structures, further highlighting the minimized impact of systematics on the time-series light curves. We suspect that the minor differences resulting from different reduction products and fitting pipelines are linked to the superbias and treatment of 1/f noise. We anticipate that the impacts of these will be improved with new superbias images, expected to be released soon by STScI, and with more detailed investigation into the impact of 1/f noise at the group level beyond the scope of this work.
Model comparison
To identify spectral absorption features, we compared the resulting weighted-average transmission spectrum of WASP-39b to several 1D RCTE atmosphere models from three independent model grids. Each forward model is computed on a set of common physical parameters (for example, metallicity, C/O ratio, internal temperature and heat redistribution), shown in Extended Data Table 2. Additionally, each model grid contains different prescriptions for treating certain physical effects (for example, scattering aerosols). Although each grid contains different opacity sources from varying line lists (see Extended Data Table 2), they each consider all of the main molecular and atomic species84. Each model transmission spectrum from the grids was binned to the same resolution as that of the observations to compute the χ2 per data point, with a wavelength-independent transit depth offset as the free parameter. In general, the forward model grids fit the main features of the data but are unable to place statistically significant constraints on many of the atmospheric parameters, owing to both the finite nature of the forward model grid spacing13 and the insensitivity of some of these parameters to the 3–5-μm transmission spectrum of WASP-39b (for example, >100 K differences in interior temperature provided nearly identical χ2/N).
ATMO
We used the ATMO RCTE grid85,86,87,88, which consists of model transmission spectra for different day–night energy redistribution factors, atmospheric metallicities, C/O ratios, haze factors and grey cloud factors with a range of line lists and pressure-broadening sources88. In total, there were 5,160 models. Within this grid, we find the best-fit model to have 3 times solar metallicity, with a C/O ratio of 0.35 and a grey cloud opacity 5 times the strength of H2 Rayleigh scattering at 350 nm and a χ2/N = 1.098 for N = 344 data points and only fitting for an absolute altitude change in y.
PHOENIX
We calculated a grid of transmission spectra using the PHOENIX atmosphere model89,90,91, varying the heat redistribution of the planet, atmospheric metallicity, C/O ratio, internal temperature, the presence of aerosols and the atmospheric chemistry (equilibrium or rainout). Opacities used include the BT2 H2O line list92, as well as HITRAN for 129 other main molecular absorbers93 and Kurucz and Bell data for atomic species94. The HITRAN line lists available in this version of PHOENIX are often complete only at room temperature, which may be the cause of the apparent shift in the CO2 spectral feature compared with the other grids that primarily use HITEMP and ExoMol lists. This shift is the cause of the difference in χ2 between PHOENIX and the other model grids. In total, there were 1,116 models. Within this grid, the best-fit model has 10 times solar metallicity, a C/O ratio of 0.3, an internal temperature of 400 K, rainout chemistry and a cloud deck top at 0.3 mbar. The best-fit model has a χ2/N = 1.203 for N = 344 data points.
PICASO 3.0 and Virga
We used the open-source radiative–convective equilibrium model PICASO 3.0 (refs. 95,96), which has its heritage in the Fortran-based EGP mode97,98, to compute a grid of 1D pressure–temperature models for WASP-39b. The opacity sources included in PICASO 3.0 are listed in Extended Data Table 2. Of the 29 molecular opacity sources included, the line lists of notable molecules used were: H2O (ref. 99), CO2 (ref. 100), CH4 (ref. 101) and CO (ref. 102). The parameters varied in this grid of models include the interior temperature of the planet (Tint), atmospheric metallicity, C/O ratio and the dayside-to-nightside heat redistribution factor (see Extended Data Table 2), with correlated-k opacities98,103. In total, there were 192 cloud-free models. We include the effect of clouds in two ways. First, we post-processed the pressure–temperature profile using the cloud model Virga95,104, which follows from previously developed methodologies38, in which we included three condensable species (MnS, Na2S and MgSiO3). Virga requires a vertical mixing parameter, Kzz (cm2 s−1), and a vertically constant sedimentation efficiency parameter, fsed. In general, fsed controls the vertical extent of the cloud opacity, with low values (fsed < 1) creating large, vertically extended cloud decks with small particle sizes. In total, there were 3,840 cloudy models. The best fit from our grid with Virga-computed clouds has 3 times solar metallicity, solar C/O (0.458) and fsed = 0.6, which results in a χ2/N = 1.084.
As well as the grid fit, we also use the PICASO framework to quantify the feature-detection significance. In this method, we are able to incorporate clouds on the fly using the fitting routine PyMultiNest105. We fit for each of the grid parameters using a nearest-neighbour technique and a radius scaling to account for the unknown reference pressure, giving five parameters in total. When fitting for clouds, we either fit for Kzz and fsed in the Virga framework (seven parameters in total) or we fit for the cloud-top pressure corresponding to a grey cloud deck with infinite opacity (six parameters in total). These results are described in the following section.
Feature-detection significance
From the chemical equilibrium results of the single best-fit models, the molecules that could potentially contribute to the spectrum based on their abundances and 3–5-μm opacity sources are H2 and He (via continuum) and CO, H2O, H2S, CO2 and CH4. More minor sources of opacity with VMR abundances <1 ppm are molecules such as OCS and NH3. For example, removing H2S, NH3 and OCS from the single best-fit PICASO 3.0 model increases the chi-square value by less than 0.002. Therefore, we focus on computing the statistical significance of only H2O, SO2, CO2, CH4 and CO.
To quantify the statistical significance, we performed two different tests. First, we used a Gaussian residual fitting analysis, as used in other JTEC ERS analyses23,29,31. In this method, we subtracted the best-fit model without a specific opacity source from the weighted-average spectrum of WASP-39b, isolating the supposed spectral feature. We then fit a three-parameter or four-parameter Gaussian curve to the residual data using a nested sampling algorithm to calculate the Bayesian evidence106. For H2O and CO, the extra transit depth offset parameter for the Gaussian fit was necessary to account for local mismatch of the fit to the continuum, whereas only a mean, standard deviation and scale parameter were required for a residual fit to the other molecules. We then compared this to the Bayesian evidence of a flat line to find the Bayes factor between a model that fits the spectral feature versus a model that excludes the spectral feature. These fits are shown in Extended Data Fig. 6.
Although the Gaussian residual fitting method is useful for quantifying the presence of potentially unknown spectral features, it cannot robustly determine the source of any given opacity. We therefore used the Bayesian fitting routine from PyMultiNest in the PICASO 3.0 framework to refit the grid parameters, while excluding the opacity contribution from the species in question. Then, we compared the significance of the molecule through a Bayes factor analysis107. Those values are shown in Extended Data Table 3.
We find significant evidence (>3σ) for H2O, CO2 and SO2. In general, the two methods only agree well for molecules whose contribution has a Gaussian shape (that is, SO2 and CO2). For example, for CO2, we find decisive 28.5σ and 26.9σ detections for the Bayes factor and Gaussian analysis, respectively. Similarly, for H2O, we find 21.5σ and 16.5σ detections, respectively. The evidence for SO2 is less substantial, but both methods give significant detections of 4.8σ and 3.5σ, respectively. Although the Gaussian fitting method found a broad 1-μm-wide residual in the region of CO (that is, >4.5 μm), its shape was unlike that seen with the PRISM data31. CO remained undetected with the Bayesian fitting analysis and therefore we are unable to robustly confirm evidence of CO. Similarly, no evidence for CH4 was found23. Gaussian residual fitting in the region of CH4 absorption only found a very broad inverse Gaussian and so is not included in Extended Data Table 3.
SO2 absorption
We performed an injection test with the PICASO best-fit model in the PyMultiNest fitting framework to determine the abundance of SO2 required to match the observations. We add SO2 opacity using the ExoMol line list108, without rerunning the RCTE model to self-consistently compute a new climate profile. Fitting for the cloud deck dynamically, without SO2, produces a single best estimate of 10 times solar metallicity, sub-solar C/O (0.229), resulting in a marginally worse χ2/N = 1.11. With SO2, the single best fit tends back to 3 times solar metallicity, solar C/O. This suggests that cloud treatment and the exclusion of spectrally active molecules have an effect on the resultant physical interpretation of bulk atmospheric parameters. Ultimately, if we fit for SO2 in our PyMultiNest framework with the Virga cloud treatment, we obtain 3 times solar metallicity, solar C/O, log SO2 = −5.6 ± 0.1 (SO2 = 2.5 ± 0.65 ppm) and χ2/N = 1.02, which is our single best-fit model (shown in Fig. 4). For context, an atmospheric metallicity of 3–10 times solar would provide a thermochemical equilibrium abundance of 72–240 ppm H2S, the presumed source for photochemically produced SO2 (ref. 36).
To confirm the plausibility of SO2 absorption to explain the 4.1-μm spectral feature, we also computed models with prescribed, vertically uniform SO2 VMRs of 0, 1, 5 and 10 ppm using the structure from the best-fit PHOENIX model (10 times solar metallicity, C/O = 0.3). We calculated ad hoc spectra using the gCMCRT radiative transfer code109 with the ExoMol SO2 line list108 (see Extended Data Fig. 7). Linearly interpolating the models with respect to the SO2 abundance and performing a Levenberg–Marquardt regression gave a best-fit value of 4.6 ± 0.67 ppm. Inserting this abundance of SO2 into the best-fit PHOENIX model improves the χ2/N from 1.2 to 1.08.
Future atmospheric retrievals can provide a more statistically robust measurement for the SO2 abundance and add extra information from the similar absorption seen in the PRISM transmission spectrum29,31.
4.56-μm feature
A 0.08-μm-wide bump in transit depth centred at 4.56 μm is not fit by any of the model grids. This feature, picked up by the resolution of G395H, is not clearly seen in other ERS observations of WASP-39b. Following the same Gaussian residual fitting procedure as described above, we found a feature significance of 3.3σ (see Extended Data Fig. 6). To identify possible opacity sources in the atmosphere of WASP-39b that might be the cause of this absorption, we compared the feature with CH4 (ref. 110), C2H2 (ref. 111), C2H4 (ref. 112), C2H6 (ref. 113), CO (ref. 114), CO2 (ref. 100), CS2 (ref. 113), CN (ref. 115), HCN (ref. 116), HCl (ref. 113), H2S (ref. 117), HF (ref. 118), H3+ (ref. 119), LiCl (ref. 115), NH3 (ref. 120), NO (ref. 114), NO2 (ref. 113), N2O (ref. 114), N2 (ref. 121), NaCl (ref. 122), OCS (ref. 113), PH3 (ref. 123), PN (ref. 124), PO (ref. 125), SH (ref. 126), SiS (ref. 127), SiH4 (ref. 128), SiO (ref. 129), the X–X state of SO (ref. 130), SO2 (ref. 108), SO3 (ref. 108) and isotopologues of H2O, CH4, CO2 and CO, but did not find a convincing candidate that showed opacity at the correct wavelength or the correct width. The narrowness of the feature suggests that it could be a very distinct Q-branch, in which the rotational quantum number in the ground state is the same as the rotational quantum number in the excited state. However, of the molecules we explored, there were no candidates with a distinct Q-branch at this wavelength whose P-branch and R-branch did not obstruct the neighbouring CO2 and continuum-like CO + H2O opacity.
We also note that many of these species lack high-temperature line-list data, making it difficult to definitively rule out such species. For example, OCS, SO and CS2 are available in HITRAN2020 (ref. 113) but not in ExoMol131. Furthermore, if photochemistry is important for WASP-39b, as indicated by the presence of SO2, then there may be many species out of equilibrium that may contribute to the transit spectrum, some of which do not have high-temperature opacity data at present (such as OCS, NH2 or HSO). Future observations over this wavelength region of this and other planets may confirm or refute the presence of this unknown absorber.
Data availability
The data used in this paper are associated with JWST programme ERS 1366 (observation #4) and are available from the Mikulski Archive for Space Telescopes (MAST; https://mast.stsci.edu). Science data processing version (SDP_VER) 2022_2a generated the uncalibrated data that we downloaded from MAST. We used JWST Calibration Pipeline software version (CAL_VER) 1.5.3 with modifications described in the text. We used calibration reference data from context (CRDS_CTX) 0916, except as noted in the text. All the data and models presented in this publication can be found at https://doi.org/10.5281/zenodo.7185300.
Code availability
The codes used in this publication to extract, reduce and analyse the data are as follows; STScI JWST Calibration Pipeline44 (https://github.com/spacetelescope/jwst), Eureka!50 (https://eurekadocs.readthedocs.io/en/latest/), ExoTiC-JEDI45 (https://github.com/Exo-TiC/ExoTiC-JEDI), juliet68 (https://juliet.readthedocs.io/en/latest/), Tiberius15,46,47, transitspectroscopy48 (https://github.com/nespinoza/transitspectroscopy). Furthermore, these made use of batman62 (http://lkreidberg.github.io/batman/docs/html/index.html), celerite83 (https://celerite.readthedocs.io/en/stable/), chromatic (https://zkbt.github.io/chromatic/), dynesty69 (https://dynesty.readthedocs.io/en/stable/index.html), emcee66 (https://emcee.readthedocs.io/en/stable/), exoplanet80 (https://docs.exoplanet.codes/en/latest/), ExoTEP72,73,74, ExoTHETyS76 (https://github.com/ucl-exoplanets/ExoTETHyS), ExoTiC-ISM54 (https://github.com/Exo-TiC/ExoTiC-ISM), ExoTiC-LD55 (https://exotic-ld.readthedocs.io/en/latest/), george65 (https://george.readthedocs.io/en/latest/), JAX79 (https://jax.readthedocs.io/en/latest/), LMFIT67 (https://lmfit.github.io/lmfit-py/), PyLightcurve75 (https://github.com/ucl-exoplanets/pylightcurve), PyMC3 (ref. 132) (https://docs.pymc.io/en/v3/index.html) and Starry81 (https://starry.readthedocs.io/en/latest/), each of which use the standard Python libraries astropy133,134, matplotlib135, numpy136, pandas137, scipy61 and xarray138. The atmospheric models used to fit the data can be found at ATMO85,86,87,88, PHOENIX89,90,91, PICASO95,96 (https://natashabatalha.github.io/picaso/), Virga95,104 (https://natashabatalha.github.io/virga/) and gCMCRT109 (https://github.com/ELeeAstro/gCMCRT).
References
Öberg, K. I., Murray-Clay, R. & Bergin, E. A. The effects of snowlines on C/O in planetary atmospheres. Astrophys. J. Lett. 743, L16 (2011).
Mordasini, C., van Boekel, R., Mollière, P., Henning, T. & Benneke, B. The imprint of exoplanet formation history on observable present-day spectra of hot Jupiters. Astrophys. J. 832, 41 (2016).
Sing, D. K. et al. A continuum from clear to cloudy hot-Jupiter exoplanets without primordial water depletion. Nature 529, 59–62 (2016).
Wakeford, H. R. et al. The complete transmission spectrum of WASP-39b with a precise water constraint. Astron. J. 155, 29 (2018).
Alam, M. K. et al. The Hubble Space Telescope PanCET program: an optical to infrared transmission spectrum of HAT-P-32Ab. Astron. J 160, 51 (2020).
Birkby, J. L. Exoplanet atmospheres at high spectral resolution. Preprint at https://arxiv.org/abs/1806.04617 (2018).
Line, M. R. et al. A solar C/O and sub-solar metallicity in a hot Jupiter atmosphere. Nature 598, 580–584 (2021).
Pelletier, S. et al. Where is the water? Jupiter-like C/H ratio but strong H2O depletion found on τ Boötis b using SPIRou. Astron. J 162, 73 (2021).
Faedi, F. et al. WASP-39b: a highly inflated Saturn-mass planet orbiting a late G-type star. Astron. Astrophys. 531, A40 (2011).
Batalha, N. E. & Line, M. R. Information content analysis for selection of optimal JWST observing modes for transiting exoplanet atmospheres. Astron. J 153, 151 (2017).
Jakobsen, P. et al. The Near-Infrared Spectrograph (NIRSpec) on the James Webb Space Telescope. I. Overview of the instrument and its capabilities. Astron. Astrophys. 661, A80 (2022).
Birkmann, S. M. et al. The Near-Infrared Spectrograph (NIRSpec) on the James Webb Space Telescope. IV. Capabilities and predicted performance for exoplanet characterization. Astron. Astrophys. 661, A83 (2022).
Fischer, P. D. et al. HST hot-Jupiter transmission spectral survey: clear skies for cool Saturn WASP-39b. Astrophys. J. 827, 19 (2016).
Nikolov, N. et al. VLT FORS2 comparative transmission spectroscopy: detection of Na in the atmosphere of WASP-39b from the ground. Astrophys. J. 832, 191 (2016).
Kirk, J. et al. LRG-BEASTS: transmission spectroscopy and retrieval analysis of the highly inflated Saturn-mass planet WASP-39b. Astron. J. 158, 144 (2019).
Barstow, J. K., Aigrain, S., Irwin, P. G. & Sing, D. K. A consistent retrieval analysis of 10 hot Jupiters observed in transmission. Astrophys. J. 834, 50 (2017).
Pinhas, A., Madhusudhan, N., Gandhi, S. & MacDonald, R. H2O abundances and cloud properties in ten hot giant exoplanets. Mon. Not. R. Astron. Soc. 482, 1485–1498 (2019).
Tsiaras, A. et al. A population study of gaseous exoplanets. Astron. J 155, 4 (2018).
Welbanks, L. et al. Mass–metallicity trends in transiting exoplanets from atmospheric abundances of H2O, Na, and K. Astrophys. J. Lett. 887, L20 (2019).
Kawashima, Y. & Min, M. Implementation of disequilibrium chemistry to spectral retrieval code ARCiS and application to 16 exoplanet transmission spectra. Indication of disequilibrium chemistry for HD 209458b and WASP-39b. Astron. Astrophys. 656, A90 (2021).
Shibata, S., Helled, R. & Ikoma, M. The origin of the high metallicity of close-in giant exoplanets. Combined effects of resonant and aerodynamic shepherding. Astron. Astrophys. 633, A33 (2020).
Helled, R. & Morbidelli, A. in ExoFrontiers: Big Questions in Exoplanetary Science (ed. Madhusudhan, N.) (IOP Publishing, 2021).
Ahrer, E.-M. et al. Early Release Science of the exoplanet WASP-39b with JWST NIRCam. Nature https://doi.org/10.1038/s41586-022-05590-4 (2023).
Polanski, A. S., Crossfield, I. J., Howard, A. W., Isaacson, H. & Rice, M. Chemical abundances for 25 JWST exoplanet host stars with KeckSpec. Res. Notes AAS 6, 155 (2022).
Mullally, S. E., Rodriguez, D. R., Stevenson, K. B. & Wakeford, H. R. The Exo.MAST table for JWST exoplanet atmosphere observability. Res. Notes AAS 3, 193 (2019).
Stevenson, K. B. et al. Transiting exoplanet studies and community targets for JWST’s Early Release Science Program. Publ. Astron. Soc. Pac. 128, 094401 (2016).
Bean, J. L. et al. The Transiting Exoplanet Community Early Release Science Program for JWST. Publ. Astron. Soc. Pac. 130, 114402 (2018).
Rigby, J. et al. The science performance of JWST as characterized in commissioning. Preprint at https://arxiv.org/abs/2207.05632 (2023).
JWST Transiting Exoplanet Community Early Release Science Team. Identification of carbon dioxide in an exoplanet atmosphere. Nature https://doi.org/10.1038/s41586-022-05269-w (2022).
Lodders, K. & Fegley, B. Atmospheric chemistry in giant planets, brown dwarfs, and low-mass dwarf stars: I. Carbon, nitrogen, and oxygen. Icarus 155, 393–424 (2002).
Rustamkulov, R. et al. Early Release Science of the exoplanet WASP-39b with JWST NIRSpec PRISM. Nature https://doi.org/10.1038/s41586-022-05677-y (2023).
Zahnle, K. et al. Atmospheric sulfur photochemistry on hot Jupiters. Astrophys. J. Lett. 701, L20 (2009).
Hobbs, R. et al. Sulfur chemistry in the atmospheres of warm and hot Jupiters. Mon. Not. R. Astron. Soc. 506, 3186–3204 (2021).
Tsai, S.-M. et al. A comparative study of atmospheric chemistry with VULCAN. Astrophys. J. 923, 264 (2021).
Polman, J., Waters, L.B.F.M., Min, M., Miguel, Y. & Khorshid, N. H2S and SO2 detectability in hot Jupiters. Sulphur species as indicators of metallicity and C/O ratio. Astron. Astrophys. https://doi.org/10.1051/0004-6361/202244647 (in the press).
Moses, J. I., Madhusudhan, N., Visscher, C. & Freedman, R. S. Chemical consequences of the C/O ratio on hot Jupiters: examples from WASP-12b, CoRoT-2b, XO-1b, and HD 189733b. Astrophys. J. 763, 25 (2012).
Moses, J. I. et al. Disequilibrium carbon, oxygen, and nitrogen chemistry in the atmospheres of HD 189733b and HD 209458b. Astrophys. J. 737, 15 (2011).
Ackerman, A. S. & Marley, M. S. Precipitating condensation clouds in substellar atmospheres. Astrophys. J. 556, 872 (2001).
Mousis, O., Aguichine, A., Helled, R., Irwin, P. G. J. & Lunine, J. I. The role of ice lines in the formation of Uranus and Neptune. Philos. Trans. R. Soc. A 378, 20200107 (2020).
Wong, M. H., Mahaffy, P. R., Atreya, S. K., Niemann, H. B. & Owen, T. C. Updated Galileo probe mass spectrometer measurements of carbon, oxygen, nitrogen, and sulfur on Jupiter. Icarus 171, 153–170 (2004).
Fletcher, L. N., Orton, G. S., Teanby, N. A., Irwin, P. G. J. & Bjoraker, G. L. Methane and its isotopologues on Saturn from Cassini/CIRS observations. Icarus 199, 351–367 (2009).
Pollack, J. B. et al. Formation of the giant planets by concurrent accretion of solids and gas. Icarus 124, 62–85 (1996).
Thorngren, D. & Fortney, J. J. Connecting giant planet atmosphere and interior modeling: constraints on atmospheric metal enrichment. Astrophys. J. Lett. 874, L31 (2019).
Bushouse, H. et al. JWST Calibration Pipeline (1.6.2). Zenodo https://doi.org/10.5281/zenodo.7041998 (2022).
Alderson, L., Grant, D., Wakeford, H. Exo-TiC/ExoTiC-JEDI: v0.1-beta-release. Zenodo https://doi.org/10.5281/zenodo.7185855 (2022).
Kirk, J. et al. LRG-BEASTS III: ground-based transmission spectrum of the gas giant orbiting the cool dwarf WASP-80. Mon. Not. R. Astron. Soc. 474, 876 (2018).
Kirk, J. et al. ACCESS and LRG-BEASTS: a precise new optical transmission spectrum of the ultrahot Jupiter WASP-103b. Astronom. J. 162, 34 (2021).
Espinoza, N. TransitSpectroscopy (0.3.11). Zenodo https://doi.org/10.5281/zenodo.6960924 (2022).
Marsh, T. R. The extraction of highly distorted spectra. Publ. Astron. Soc. Pac. 101, 1032 (1989).
Bell, T. J. et al. Eureka!: An end-to-end pipeline for JWST time-series observations. J. Open Source Softw. 7, 4503 (2022).
Claret, A. A new non-linear limb-darkening law for LTE stellar atmosphere models. Calculations for −5.0 ≤ log[M/H] ≤ +1, 2000 K ≤ Teff ≤ 50000 K at several surface gravities. Astron. Astrophys. 363, 1081–1190 (2000).
Magic, Z., Chiavassa, A., Collet, R. & Asplund, M. The STAGGER-grid: a grid of 3D stellar atmosphere models. IV. Limb darkening coefficients. Astron. Astrophys. 573, A90 (2015).
Space Telescope Science Institute. JWST User Documentation (JDox) website. https://jwst-docs.stsci.edu/ (2016).
Laginja, I. & Wakeford, H. ExoTiC-ISM: a Python package for marginalised exoplanet transit parameters across a grid of systematic instrument models. J. Open Source Softw. 5, 2281 (2020).
Wakeford, H. & Grant, D. Exo-TiC/ExoTiC-LD: ExoTiC-LD v2.1 Zenodo https://doi.org/10.5281/zenodo.6809899 (2022).
Sing, D. K. Stellar limb-darkening coefficients for CoRot and Kepler. Astron. Astrophys. 510, A21 (2010).
Kipping, D. M. Efficient, uninformative sampling of limb-darkening coefficients for two-parameter laws. Mon. Not. R. Astron. Soc. 435, 2152–2160 (2013).
Espinoza, N. & Jordán, A. Limb darkening and exoplanets – II. Choosing the best law for optimal retrieval of transit parameters. Mon. Not. R. Astron. Soc. 457, 3573–3581 (2016).
Allan, D. W. Statistics of atomic frequency standards. Proc. IEEE 54, 221–230 (1966).
Pont, F., Zucker, S. & Queloz, D. The effect of red noise on planetary transit detection. Mon. Not. R. Astron. Soc. 373, 231–242 (2006).
Virtanen, P. et al. SciPy 1.0: fundamental algorithms for scientific computing in Python. Nat. Methods 17, 261–272 (2020).
Kreidberg, L. batman: BAsic Transit Model cAlculatioN in Python. Publ. Astron. Soc. Pac. 127, 1161 (2015).
Gibson, N. P. et al. A Gaussian process framework for modelling instrumental systematics: application to transmission spectroscopy. Mon. Not. R. Astron. Soc. 419, 2683–2694 (2012).
Gibson, N. P. Reliable inference of exoplanet light-curve parameters using deterministic and stochastic systematics models. Mon. Not. R. Astron. Soc. 445, 3401–3414 (2014).
Ambikasaran, S., Foreman-Mackey, D., Greengard, L., Hogg, D. W. & O’Neil, M. Fast direct methods for Gaussian processes. IEEE Trans. Pattern Anal. Mach. Intell. 38, 252–265 (2015).
Foreman-Mackey, D. et al. emcee v3: a Python ensemble sampling toolkit for affine-invariant MCMC. J. Open Source Softw. 4, 1864 (2019).
Newville, M. et al. LMFIT: non-linear least-square minimization and curve-fitting for Python. Zenodo https://doi.org/10.5281/zenodo.11813 (2014).
Espinoza, N., Kossakowski, D. & Brahm, R. juliet: a versatile modelling tool for transiting and non-transiting exoplanetary systems. Mon. Not. R. Astron. Soc. 490, 2262–2283 (2019).
Speagle, J. S. DYNESTY: a dynamic nested sampling package for estimating Bayesian posteriors and evidences. Mon. Not. R. Astron. Soc. 493, 3132–3158 (2020).
Kurucz, R. L. Model atmospheres for g, f, a, b, and o stars. Astrophys. J. Suppl. Ser. 40, 1–340 (1979).
Howarth, I. D. On stellar limb darkening and exoplanetary transits. Mon. Not. R. Astron. Soc. 418, 1165–1175 (2011).
Benneke, B. et al. Spitzer observations confirm and rescue the habitable-zone super-Earth K2-18b for future characterization. Astrophys. J. 834, 187 (2017).
Benneke, B. et al. A sub-Neptune exoplanet with a low-metallicity methane-depleted atmosphere and Mie-scattering clouds. Nat. Astron. 3, 813–821 (2019).
Benneke, B. et al. Water vapor and clouds on the habitable-zone sub-Neptune exoplanet K2-18b. Astrophys. J. Lett. 887, L14 (2019).
Tsiaras, A. et al. Detection of an atmosphere around the super-Earth 55 Cancri e. Astrophys. J. 820, 99 (2016).
Morello, G. et al. ExoTETHyS: tools for exoplanetary transits around host stars. J. Open Source Softw. 5, 1834 (2020).
Claret, A., Hauschildt, P. H. & Witte, S. New limb-darkening coefficients for PHOENIX/1D model atmospheres. I. Calculations for 1500 K ≤ Teff ≤ 4800 K Kepler, CoRot, Spitzer, uvby, UBVRIJHK, Sloan, and 2MASS photometric systems. Astron. Astrophys. 546, A14 (2012).
Claret, A., Hauschildt, P. H. & Witte, S. New limb-darkening coefficients for PHOENIX/1D model atmospheres. II. Calculations for 5000 K ≤ Teff ≤ 10 000 K Kepler, CoRot, Spitzer, uvby, UBVRIJHK, Sloan, and 2MASS photometric systems. Astron. Astrophys 552, A16 (2013).
Bradbury, J. et al. JAX: Autograd and XLA. Astrophysics Source Code Library. https://ascl.net/2111.002 (2021).
Foreman-Mackey, D. et al. exoplanet-dev/exoplanet: exoplanet v0.5.0. Zenodo https://doi.org/10.5281/zenodo.4737444 (2020).
Luger, R. et al. STARRY: analytic occultation light curves. Astron. J 157, 64 (2019).
Agol, E., Luger, R. & Foreman-Mackey, D. Analytic planetary transit light curves and derivatives for stars with polynomial limb darkening. Astron. J 159, 123 (2020).
Foreman-Mackey, D., Agol, E., Ambikasaran, S. & Angus, R. Fast and scalable Gaussian process modeling with applications to astronomical time series. Astron. J 154, 220 (2017).
Sharp, C. & Burrows, A. Atomic and molecular opacities for brown dwarf and giant planet atmospheres. Astrophys. J. Suppl. Ser. 168, 140 (2007).
Tremblin, P. et al. Fingering convection and cloudless models for cool brown dwarf atmospheres. Astrophys. J. Lett. 804, L17 (2015).
Drummond, B. et al. The effects of consistent chemical kinetics calculations on the pressure-temperature profiles and emission spectra of hot Jupiters. Astron. Astrophys. 594, A69 (2016).
Goyal, J. M. et al. A library of ATMO forward model transmission spectra for hot Jupiter exoplanets. Mon. Not. R. Astron. Soc. 474, 5158 (2018).
Goyal, J. M. et al. A library of self-consistent simulated exoplanet atmospheres. Mon. Not. R. Astron. Soc. 498, 4680 (2020).
Hauschildt, P. H., Allard, F. & Baron, E. The NextGen model atmosphere grid for 3000 ≤ Teff ≤ 10,000 K. Astrophys. J. 512, 377 (1999).
Barman, T. S., Hauschildt, P. H. & Allard, F. Irradiated planets. Astrophys. J. 556, 885–895 (2001).
Lothringer, J. D. & Barman, T. The PHOENIX exoplanet retrieval algorithm and using H− opacity as a probe in ultrahot Jupiters. Astron. J 159, 289 (2020).
Barber, R. J., Tennyson, J., Harris, G. J. & Tolchenov, R. N. A high-accuracy computed water line list. Mon. Not. R. Astron. Soc. 368, 1087–1094 (2006).
Rothman, L. S. et al. The HITRAN 2008 molecular spectroscopic database. J. Quant. Spectrosc. Radiat. Transfer 110, 533–572 (2009).
Kurucz, R. & Bell, B. Atomic line data. CD-ROM no. 23 (Smithsonian Astrophysical Observatory, 1995).
Batalha, N. E., Marley, M. S., Lewis, N. K. & Fortney, J. J. Exoplanet reflected-light spectroscopy with PICASO. Astrophys. J. 878, 70 (2019).
Mukherjee, S., Batalha, N. E., Fortney, J. J. & Marley, M. S. PICASO 3.0: a one-dimensional climate model for giant planets and brown dwarfs. Astrophys. J. 942, 71 (2023).
Fortney, J. J., Marley, M. S., Lodders, K., Saumon, D. & Freedman, R. Comparative planetary atmospheres: models of TrES-1 and HD 209458b. Astrophys. J. 627, L69–L72 (2005).
Marley, M. S. et al. The Sonora brown dwarf atmosphere and evolution models. I. Model description and application to cloudless atmospheres in rainout chemical equilibrium. Astrophys. J. 920, 85 (2021).
Polyansky, O. L. et al. ExoMol molecular line lists XXX: a complete high-accuracy line list for water. Mon. Not. R. Astron. Soc. 480, 2597–2608 (2018).
Huang, X., Gamache, R. R., Freedman, R. S., Schwenke, D. W. & Lee, T. J. Reliable infrared line lists for 13 CO2 isotopologues up to E′=18,000 cm−1 and 1500 K, with line shape parameters. J. Quant. Spectrosc. Radiat. Transfer 147, 134–144 (2014).
Yurchenko, S. N., Amundsen, D. S., Tennyson, J. & Waldmann, I. P. A hybrid line list for CH4 and hot methane continuum. Astron. Astrophys. 605, A95 (2017).
Li, G. et al. Rovibrational line lists for nine isotopologues of the CO molecule in the X1Σ+ ground electronic state. Astrophys. J. Suppl. Ser. 216, 15 (2015).
Lupu, R., Freedman, R., Gharib-Nezhad, E., Visscher, C. & Molliere, P. Correlated k coefficients for H2-He atmospheres; 196 spectral windows and 1460 pressure-temperature points. Zenodo https://doi.org/10.5281/zenodo.5590989 (2021).
Rooney, C. M., Batalha, N. E., Gao, P. & Marley, M. S. A new sedimentation model for greater cloud diversity in giant exoplanets and brown dwarfs. Astrophys. J. 925, 33 (2022).
Buchner, J. PyMultiNest: Python interface for MultiNest. Astrophysics Source Code Library. https://www.ascl.net/1606.005 (2016).
Skilling, J. Nested sampling. AIP Conf. Proc. 735, 395–405 (2004).
Trotta, R. Bayes in the sky: Bayesian inference and model selection in cosmology. Contemp. Phys. 49, 71–104 (2008).
Underwood, D. S. et al. ExoMol molecular line lists – XIV. The rotation–vibration spectrum of hot SO2. Mon. Not. R. Astron. Soc. 459, 3890–3899 (2016).
Lee, E. K. et al. 3D radiative transfer for exoplanet atmospheres. gCMCRT: a GPU-accelerated MCRT code. Astrophys. J. 929, 180 (2022).
Hargreaves, R. J. et al. An accurate, extensive, and practical line list of methane for the HITEMP database. Astrophys. J. Suppl. Ser. 247, 55 (2020).
Chubb, K. L., Tennyson, J. & Yurchenko, S. N. ExoMol molecular line lists – XXXVII. Spectra of acetylene. Mon. Not. R. Astron. Soc. 493, 1531–1545 (2020).
Mant, B. P., Yachmenev, A., Tennyson, J. & Yurchenko, S. N. ExoMol molecular line lists – XXVII. Spectra of C2H4. Mon. Not. R. Astron. Soc. 478, 3220–3232 (2018).
Gordon, I. E. et al. The HITRAN2020 molecular spectroscopic database. J. Quant. Spectrosc. Radiat. Transfer 277, 107949 (2022).
Rothman, L. S. et al. HITEMP, the high-temperature molecular spectroscopic database. J. Quant. Spectrosc. Radiat. Transfer 111, 2139–2150 (2010).
Bernath, P. F. MoLLIST: molecular line lists, intensities and spectra. J. Quant. Spectrosc. Radiat. Transfer 240, 106687 (2020).
Harris, G. J., Tennyson, J., Kaminsky, B. M., Pavlenko, Y. V. & Jones, H. R. A. Improved HCN/HNC linelist, model atmospheres and synthetic spectra for WZ Cas. Mon. Not. R. Astron. Soc. 367, 400–406 (2006).
Azzam, A. A. A., Tennyson, J., Yurchenko, S. N. & Naumenko, O. V. ExoMol molecular line lists – XVI. The rotation–vibration spectrum of hot H2S. Mon. Not. R. Astron. Soc. 460, 4063–4074 (2016).
Coxon, J. A. & Hajigeorgiou, P. G. Improved direct potential fit analyses for the ground electronic states of the hydrogen halides: HF/DF/TF, HCl/DCl/TCl, HBr/DBr/TBr and HI/DI/TI. J. Quant. Spectrosc. Radiat. Transfer 151, 133–154 (2015).
Mizus, I. I. et al. ExoMol molecular line lists – XX. A comprehensive line list for H3+. Mon. Not. R. Astron. Soc. 468, 1717–1725 (2017).
Coles, P. A., Yurchenko, S. N. & Tennyson, J. ExoMol molecular line lists – XXXV. A rotation–vibration line list for hot ammonia. Mon. Not. R. Astron. Soc. 490, 4638–4647 (2019).
Western, C. M. et al. The spectrum of N2 from 4,500 to 15,700 cm−1 revisited with PGOPHER. J. Quant. Spectrosc. Radiat. Transfer 219, 127–141 (2018).
Barton, E. J. et al. ExoMol molecular line lists V: the ro-vibrational spectra of NaCl and KCl. Mon. Not. R. Astron. Soc. 442, 1821–1829 (2014).
Sousa-Silva, C., Al-Refaie, A. F., Tennyson, J. & Yurchenko, S. N. ExoMol line lists – VII. The rotation–vibration spectrum of phosphine up to 1500 K. Mon. Not. R. Astron. Soc. 446, 2337–2347 (2015).
Yorke, L., Yurchenko, S. N., Lodi, L. & Tennyson, J. Exomol molecular line lists – VI. A high temperature line list for phosphorus nitride. Mon. Not. R. Astron. Soc. 445, 1383–1391 (2014).
Prajapat, L. et al. ExoMol molecular line lists – XXIII. Spectra of PO and PS. Mon. Not. R. Astron. Soc. 472, 3648–3658 (2017).
Gorman, M. N., Yurchenko, S. N. & Tennyson, J. ExoMol molecular line lists XXXVI: X 2Π – X 2Π and A 2Σ+ – X 2Π transitions of SH. Mon. Not. R. Astron. Soc. 490, 1652–1665 (2019). (2019).
Upadhyay, A., Conway, E. K., Tennyson, J. & Yurchenko, S. N. ExoMol line lists XXV: a hot line list for silicon sulphide, SiS. Mon. Not. R. Astron. Soc. 477, 1520–1527 (2018).
Owens, A., Yachmenev, A., Thiel, W., Tennyson, J. & Yurchenko, S. N. ExoMol line lists – XXII. The rotation–vibration spectrum of silane up to 1200 K. Mon. Not. R. Astron. Soc. 471, 5025–5032 (2017).
Barton, E. J., Yurchenko, S. N. & Tennyson, J. ExoMol line lists – II. The ro-vibrational spectrum of SiO. Mon. Not. R. Astron. Soc. 434, 1469–1475 (2013).
Brady, R. P., Yurchenko, S. N., Kim, G. S., Somogyi, W. & Tennyson, J. An ab initio study of the rovibronic spectrum of sulphur monoxide (SO): diabatic vs. adiabatic representation. Phys. Chem. Chem. Phys. 24, 24076–24088 (2022).
Tennyson, J. et al. The 2020 release of the ExoMol database: molecular line lists for exoplanet and other hot atmospheres. J. Quant. Spectrosc. Radiat. Transfer 255, 107228 (2020).
Salvatier, J., Wiecki, T. V. & Fonnesbeck, C. Probabilistic programming in Python using PyMC3. PeerJ Comput. Sci. 2, e55 (2016).
The Astropy Collaboration et al.Astropy: a community Python package for astronomy. Astron. Astrophys. 558, A33 (2013).
The Astropy Collaboration et al.The Astropy Project: building an open-science project and status of the v2.0 core package. Astron. J 156, 123 (2018).
Hunter, J. D. Matplotlib: a 2D graphics environment. Comput. Sci. Eng. 9, 90–95 (2007).
Harris, C. R. et al. Array programming with NumPy. Nature 585, 357–362 (2020).
McKinney, W. pandas: a foundational Python library for data analysis and statistics. In PyHPC 2011: Python for High Performance and Scientific Computing Vol. 14, 1–9 (2011).
Hoyer, S. & Hamman, J. xarray: N-D labeled arrays and datasets in Python. J. Open Res. Softw. 5, 10 (2017).
Espinoza, N. et al. Spectroscopic time-series performance of JWST/NIRSpec from commissioning observations. Preprint at https://arxiv.org/abs/2211.01459 (2022).
Caffau, E., Ludwig, H. G., Steffen, M., Freytag, B. & Bonifacio, P. Solar chemical abundances determined with a CO5BOLD 3D model atmosphere. Sol. Phys. 258, 255–269 (2011).
Asplund, M., Grevesse, N., Sauval, A. J. & Scott, P. The chemical composition of the Sun. Preprint at https://arxiv.org/abs/0909.0948 (2022).
Lodders, K., Palme, H. & Gail, H.-P. Abundances of the elements in the solar system. Preprint at https://arxiv.org/abs/0901.1149 (2022).
Acknowledgements
This work is based on observations made with the NASA/ESA/CSA JWST. The data were obtained from the Mikulski Archive for Space Telescopes at the Space Telescope Science Institute, which is operated by the Association of Universities for Research in Astronomy, Inc., under NASA contract NAS 5-03127 for the JWST. These observations are associated with programme JWST-ERS-01366. Support for programme JWST-ERS-01366 was provided by NASA through a grant from the Space Telescope Science Institute, which is operated by the Association of Universities for Research in Astronomy, Inc., under NASA contract NAS 5-03127. L.A. acknowledges funding from STFC grant ST/W507337/1 and from the University of Bristol School of Physics PhD Scholarship Fund.
Author information
Authors and Affiliations
Contributions
All authors played a substantial role in one or more of the following: development of the original proposal, management of the project, definition of the target list and observation plan, analysis of the data, theoretical modelling and preparation of this manuscript. Some specific contributions are listed as follows. N.M.B., J.L.B. and K.B.S. provided overall programme leadership and management. L.A. and H.R.W. led the efforts for this manuscript. D.K.S., E.M.-R.K., H.R.W., I.J.M.C., J.L.B., K.B.S., L.K., M.L.-M., M.R.L., N.M.B., V.P. and Z.K.B.-T. made notable contributions to the design of the programme. K.B.S. generated the observing plan, with input from the team. E.S. and N.E. provided instrument expertise. B.B., E.M.-R.K., H.R.W., I.J.M.C., J.L.B., L.K., M.L.-M., M.R.L., N.M.B. and Z.K.B.-T. led or co-led working groups and/or contributed to important strategic planning efforts, such as the design and implementation of the prelaunch Data Challenges. A.L.C., D.K.S., E.S., N.E., N.P.G. and V.P. generated simulated data for prelaunch testing of methods. L.A., H.R.W., M.K.A., N.E.B. and J.D.L. contributed substantially to the writing of this manuscript, along with contributions in Methods from J.A.R., S.B., M.D., N.E., L.F., J.M.G., D.G., J.I., T.M.-E., P.-A.R. and N.L.W. L.A., H.R.W., M.K.A., J.A.R., S.B., M.D., N.E., L.F., D.G., J.I., T.M.-E., P.-A.R. and N.L.W. contributed to the development of data-analysis pipelines and/or provided the data-analysis products used in this analysis, that is, reduced the data, modelled the light curves and/or produced the planetary spectrum, with further contributions from J.Brande, T.D. and L.R.-R. J.D.L., N.E.B., J.M.G., E.K.H.L. and R.H. generated theoretical model grids for comparison with data. H.R.W., J.D.L. and N.E.B. generated figures for this manuscript. M.L.-M., K.D.C., N.P.G., L.K., M.L., J.I.M. and E.S. provided substantial feedback to the manuscript, coordinating comments from all other authors. T.D. is a LSSTC Catalyst Fellow, N.H.A. and A.D.F. are NSF Graduate Research Fellows, J.Kirk is an Imperial College Research Fellow, R.J.M., M.M., D.P., J.D.T. and L.W. are NHFP Sagan Fellows and B.V.R. is a 51 Pegasi b Fellow.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature thanks Norio Narita and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data figures and tables
Extended Data Fig. 1 The throughput and spectral trace for WASP-39 across NRS1 and NRS2.
a, Normalized throughput of NRS1 and NRS2 detectors (as custom produced; see Methods, ‘Limb-darkening’), which shows the cutoff at short wavelengths. b, 2D spectral images of the trace produced from the ExoTiC-JEDI [V1] reduction before cleaning steps. The aspect ratio has been stretched in the y direction to show the structure of the trace over the 32-pixel-wide subarray more clearly. The NRS2 spectral position is slightly offset from that of NRS1, as the NRS2 subarray was moved following commissioning to ensure that the centre of the spectral trace fell fully on the detector and did not fall off the top-right corner139.
Extended Data Fig. 2 Time-dependent decorrelation parameters.
a, The change in the FWHM of the spectral trace at selected wavelengths. This change does not correspond to any high-gain antenna movements and is attributed to a large mirror-tilt event. These measurements demonstrate that the mirror-tilt event has a wavelength dependence. Changes to the PSF have a larger impact at short wavelengths, as the PSF of the spectrum increases with wavelength139. b,c, The change in the x-pixel and y-pixel position of the spectral trace as functions of time, respectively. Positional shifts are calculated by cross-correlating the spectral trace with a template to measure sub-pixel movement on the detector. The y-position shift clearly shows a link to the mirror-tilt event.
Extended Data Fig. 3 Normalized flux offset of the stellar baseline before and after the tilt event as a function of wavelength for NRS1 and NRS2.
Purple denotes NRS1 and orange denotes NRS2. The normalized flux offset is calculated per pixel by measuring the median flux in the stellar baseline before and after the transit and calculating the difference. These differences are then normalized by the before-transit flux and plotted on a common scale. Overplotted are the data binned to a resolution of 10 pixels to match our presented transmission spectra (Fig. 2). We also show a linear fit to each detector to better quantify the decreasing tilt flux amplitude with increasing wavelength (NRS1 = −0.00073374x + 0.00707344, NRS2 = −0.00067165x + 0.00588128).
Extended Data Fig. 4 Normalized root-mean-squared binning statistic for three of the 11 reductions detailed in Methods.
In each subplot, the red line shows the expected relationship for perfect Gaussian white noise. The black lines show the observed noise from each spectroscopic light curve for pipelines 1, 3 and 5. To compare bins and noise levels, values for all bins in each pipeline are normalized by dividing by the value for a bin width of 1.
Extended Data Fig. 5 Comparison between all fitting pipelines performed on the spectroscopic light curves.
a, The underlying grey data points show the standard deviation between all transmission spectra per spectral bin. The black line shows the unweighted mean uncertainty on the transit depth per bin. Spikes in the uncertainties correspond to spectral bins with higher standard deviations, probably because of differences in pixel-flagging or sigma-clipping at the light-curve level. b, Gaussian PDFs of the normalized transmission spectrum residuals, showing the mean offset and the spread relative to the weighted-average transmission spectrum. c, Histograms of the normalized transmission spectrum residuals aligned to zero by subtracting the mean of the distribution that was used to generate the PDF above. In panels b and c, the coloured lines and numbers correspond to the fitting pipeline used to obtain each transmission spectrum, as summarized in Extended Data Table 1. The dashed lines correspond to the fitting pipeline results presented in Fig. 2, demonstrating that they are drawn from across the distribution.
Extended Data Fig. 6 Gaussian versus flat-line fits to the residual transmission spectrum for CO2, H2O, SO2 and the 4.56-μm feature.
Shown after all other absorption from the best-fit model is subtracted from the data. Each of the Gaussian fits has a higher Bayesian evidence than the flat-line fits, indicating a detection, although to varying degrees of significance.
Extended Data Fig. 7 Model transmission spectra of WASP-39b with PHOENIX and gCMCRT with varying abundances of SO2.
Model transmission spectra compared with the observed spectral feature at 4.1 μm in the G395H data. At wavelengths short of 3.95 μm, which is outside the SO2 band, all models overlap, further suggesting that the data can be explained by the presence of SO2 in the atmosphere. By interpolating these 10 times solar metallicity models, we find a best-fit SO2 abundance of 4.6 ± 0.67 ppm. With the best-fit PICASO 3.0 at 3 times solar metallicity, we find an SO2 abundance of 2.5 ± 0.65 ppm.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Alderson, L., Wakeford, H.R., Alam, M.K. et al. Early Release Science of the exoplanet WASP-39b with JWST NIRSpec G395H. Nature 614, 664–669 (2023). https://doi.org/10.1038/s41586-022-05591-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41586-022-05591-3
This article is cited by
-
SO2, silicate clouds, but no CH4 detected in a warm Neptune
Nature (2024)
-
Sulfur dioxide in the mid-infrared transmission spectrum of WASP-39b
Nature (2024)
-
Analogous response of temperate terrestrial exoplanets and Earth’s climate dynamics to greenhouse gas supplement
Scientific Reports (2023)
-
High atmospheric metal enrichment for a Saturn-mass planet
Nature (2023)
-
No thick carbon dioxide atmosphere on the rocky exoplanet TRAPPIST-1 c
Nature (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
