
Abstract
The coronavirus disease 2019 (COVID-19) pandemic markedly changed human mobility patterns, necessitating epidemiological models that can capture the effects of these changes in mobility on the spread of severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2)1. Here we introduce a metapopulation susceptible–exposed–infectious–removed (SEIR) model that integrates fine-grained, dynamic mobility networks to simulate the spread of SARS-CoV-2 in ten of the largest US metropolitan areas. Our mobility networks are derived from mobile phone data and map the hourly movements of 98 million people from neighbourhoods (or census block groups) to points of interest such as restaurants and religious establishments, connecting 56,945 census block groups to 552,758 points of interest with 5.4 billion hourly edges. We show that by integrating these networks, a relatively simple SEIR model can accurately fit the real case trajectory, despite substantial changes in the behaviour of the population over time. Our model predicts that a small minority of ‘superspreader’ points of interest account for a large majority of the infections, and that restricting the maximum occupancy at each point of interest is more effective than uniformly reducing mobility. Our model also correctly predicts higher infection rates among disadvantaged racial and socioeconomic groups2,3,4,5,6,7,8 solely as the result of differences in mobility: we find that disadvantaged groups have not been able to reduce their mobility as sharply, and that the points of interest that they visit are more crowded and are therefore associated with higher risk. By capturing who is infected at which locations, our model supports detailed analyses that can inform more-effective and equitable policy responses to COVID-19.
Similar content being viewed by others


Main
In response to the COVID-19 crisis, stay-at-home orders were enacted in many countries to reduce contact between individuals and slow the spread of the SARS-CoV-29. Since then, public officials have continued to deliberate over when to reopen, which places are safe to return to and how much activity to allow10. Answering these questions requires epidemiological models that can capture the effects of changes in mobility on virus spread. In particular, findings of COVID-19 superspreader events11,12,13,14 motivate models that can reflect the heterogeneous risks of visiting different locations, whereas well-reported disparities in infection rates among different racial and socioeconomic groups2,3,4,5,6,7,8 require models that can explain the disproportionate effect of the virus on disadvantaged groups.
To address these needs, we construct fine-grained dynamic mobility networks from mobile-phone geolocation data, and use these networks to model the spread of SARS-CoV-2 within 10 of the largest metropolitan statistical areas (hereafter referred to as metro areas) in the USA. These networks map the hourly movements of 98 million people from census block groups (CBGs), which are geographical units that typically contain 600–3,000 people, to specific points of interest (POIs). As shown in Supplementary Table 1, POIs are non-residential locations that people visit such as restaurants, grocery stores and religious establishments. On top of each network, we overlay a metapopulation SEIR model that tracks the infection trajectories of each CBG as well as the POIs at which these infections are likely to have occurred. This builds on prior research that models disease spread using aggregate15,16,17,18,19, historical20,21,22 or synthetic mobility data23,24,25; separately, other studies have analysed mobility data in the context of COVID-19, but without an underlying model of disease spread26,27,28,29,30.
Combining our epidemiological model with these mobility networks allows us to not only accurately fit observed case counts, but also to conduct detailed analyses that can inform more-effective and equitable policy responses to COVID-19. By capturing information about individual POIs (for example, the hourly number of visitors and median visit duration), our model can estimate the effects of specific reopening strategies, such as only reopening certain POI categories or restricting the maximum occupancy at each POI. By modelling movement from CBGs, our model can identify at-risk populations and correctly predict, solely from mobility patterns, that disadvantaged racial and socioeconomic groups face higher rates of infection. Our model thus enables the analysis of urgent health disparities; we use it to highlight two mobility-related mechanisms that drive these disparities and to evaluate the disparate effect of reopening on disadvantaged groups.
Mobility network model
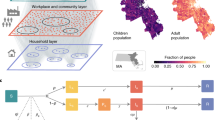
We use data from SafeGraph, a company that aggregates anonymized location data from mobile applications, to study mobility patterns from 1 March to 2 May 2020. For each metro area, we represent the movement of individuals between CBGs and POIs as a bipartite network with time-varying edges, in which the weight of an edge between a CBG and POI represents the number of visitors from that CBG to that POI during a given hour (Fig. 1a). SafeGraph also provides the area in square feet of each POI, as well as its category in the North American industry classification system (for example, fitness centre or full-service restaurant) and median visit duration in minutes. We validated the SafeGraph mobility data by comparing the dataset to Google mobility data (Supplementary Fig. 1 and Supplementary Tables 2, 3) and used iterative proportional fitting31 to derive POI–CBG networks from the raw SafeGraph data. Overall, these networks comprise 5.4 billion hourly edges between 56,945 CBGs and 552,758 POIs (Extended Data Table 1).

a, The mobility network captures hourly visits from each CBG to each POI. The vertical lines indicate that most visits are between nearby POIs and CBGs. Visits dropped markedly from March to April, as indicated by the lower density of grey lines. Mobility networks in the Chicago metro area are shown for 13:00 on two Mondays, 2 March 2020 (top) and 6 April 2020 (bottom). b, We overlaid a disease-spread model on the mobility network, with each CBG having its own set of SEIR compartments. New infections occur at both POIs and CBGs, with the mobility network governing how subpopulations from different CBGs interact as they visit POIs. c, Left, to test the out-of-sample prediction, we calibrated the model on data before 15 April 2020 (vertical black line). Even though its parameters remain fixed over time, the model accurately predicts the case trajectory in the Chicago metro area after 15 April using the mobility data (r.m.s.e. on daily cases = 406 for dates ranging from 15 April to 9 May). Right, model fit was further improved when we calibrated the model on the full range of data (r.m.s.e. on daily cases = 387 for the dates ranging from 15 April to 9 May). d, We fitted separate models to 10 of the largest US metro areas, modelling a total population of 98 million people; here, we show full model fits, as in c (right). In c and d, the blue line represents the model predictions and the grey crosses represent the number of daily reported cases; as the numbers of reported cases tend to have great variability, we also show the smoothed weekly average (orange line). Shaded regions denote the 2.5th and 97.5th percentiles across parameter sets and stochastic realizations. Across metro areas, we sample 97 parameter sets, with 30 stochastic realizations each (n = 2,910); see Supplementary Table 6 for the number of sets per metro area.
We overlay a SEIR model on each mobility network15,20, in which each CBG maintains its own susceptible (S), exposed (E), infectious (I) and removed (R) states (Fig. 1b). New infections occur at both POIs and CBGs, with the mobility network governing how subpopulations from different CBGs interact as they visit POIs. We use the area, median visit duration and time-varying density of infectious individuals for each POI to determine the hourly infection rate of that POI. The model has only three free parameters that scale: (1) transmission rates at POIs, (2) transmission rates at CBGs and (3) the initial proportion of exposed individuals (Extended Data Table 2); all three parameters remain constant over time. We calibrate a separate model for each metro area using the confirmed case counts from The New York Times by minimizing the root mean square error (r.m.s.e.) to daily incident cases32. Our model accurately fits observed daily case counts in all 10 metro areas from 8 March to 9 May 2020 (Fig. 1c, d). In addition, when calibrated on only the case counts up to 14 April, the model predicts case counts reasonably well on the held-out time period of 15 April–9 May 2020 (Fig. 1c and Extended Data Fig. 1a). Our key technical finding is that the dynamic mobility network allows even our relatively simple SEIR model with just three static parameters to accurately fit observed cases, despite changing policies and behaviours during that period.
Mobility reduction and reopening plans
We can estimate the impact of mobility-related policies by constructing a hypothetical mobility network that reflects the expected effects of each policy, and running our SEIR model forward with this hypothetical network. Using this approach, we assess a wide range of mobility reduction and reopening strategies.
The magnitude of mobility reduction is at least as important as its timing
Mobility in the USA dropped sharply in March 2020: for example, overall POI visits in the Chicago metro area fell by 54.7% between the first week of March and the first week of April 2020. We constructed counterfactual mobility networks by scaling the magnitude of mobility reduction down and by shifting the timeline earlier and later, and applied our model to the counterfactual networks to simulate the resulting infection trajectories. Across metro areas, we found that the magnitude of mobility reduction was at least as important as its timing (Fig. 2a and Supplementary Tables 4, 5): for example, if the mobility reduction in the Chicago metro area had been only a quarter of the size, the predicted number of infections would have increased by 3.3× (95% confidence interval, 2.8–3.8×), compared with a 1.5× (95% confidence interval, 1.4–1.6×) increase had people begun reducing their mobility one full week later. Furthermore, if no mobility reduction had occurred at all, the predicted number of infections in the Chicago metro area would have increased by 6.2× (95% confidence interval, 5.2–7.1×). Our results are in accordance with previous findings that mobility reductions can markedly reduce infections18,19,33,34.

The Chicago metro area is used as an example; results for all metro areas are included in Extended Data Figs. 3, 4, Supplementary Figs. 10, 15–24 and Supplementary Tables 4, 5, as indicated. a, Counterfactual simulations (left) of past reductions in mobility illustrate that the magnitude of the reduction (middle) was at least as important as its timing (right) (Supplementary Tables 4, 5). b, The model predicts that most infections at POIs occur at a small fraction of superspreader POIs (Supplementary Fig. 10). c, Left, the cumulative number of predicted infections after one month of reopening is plotted against the fraction of visits lost by partial instead of full reopening (Extended Data Fig. 3); the annotations within the plot show the fraction of maximum occupancy that is used as the cap and the horizontal red line indicates the cumulative number of predicted infections at the point of reopening (on 1 May 2020). Compared to full reopening, capping at 20% of the maximum occupancy in Chicago reduces the number of new infections by more than 80%, while only losing 42% of overall visits. Right, compared to uniformly reducing visits, the reduced maximum occupancy strategy always results in a smaller predicted increase in infections for the same number of visits (Extended Data Fig. 4). The horizontal grey line at 0% indicates when the two strategies result in an equal number of infections, and we observe that the curve falls well below this baseline. The y axis plots the relative difference between the predicted number of new infections under the reduced occupancy strategy compared to a uniform reduction. d, Reopening full-service restaurants has the largest predicted impact on infections, due to the large number of restaurants as well as their high visit densities and long dwell times (Supplementary Figs. 15–24). Colours are used to distinguish the different POI categories, but do not have any additional meaning. All results in this figure are aggregated across 4 parameter sets and 30 stochastic realizations (n = 120). Shaded regions in a–c denote the 2.5th to 97.5th percentiles; boxes in d denote the interquartile range and data points outside this range are shown as individual dots.
A minority of POIs account for the majority of the predicted infections
We next investigated whether it matters how we reduce mobility—that is, to which POIs. We computed the number of infections that occurred at each POI in our simulations from 1 March to 2 May 2020, and found that the majority of the predicted infections occurred at a small fraction of superspreader POIs; for example, in the Chicago metro area, 10% of POIs accounted for 85% (95% confidence interval, 83–87%) of the predicted infections at the POIs (Fig. 2b and Supplementary Fig. 10). Certain categories of POIs also contributed far more to infections (for example, full-service restaurants and hotels), although our model predicted time-dependent variation in how much each category contributed (Extended Data Fig. 2). For example, restaurants and fitness centres contributed less to the predicted number of infections over time, probably because of lockdown orders to close these POIs, whereas grocery stores remained steady or even grew in their contribution, which is in agreement with their status as essential businesses.
Reopening with a reduced maximum occupancy
If a minority of POIs produce the majority of infections, then reopening strategies that specifically target high-risk POIs should be especially effective. To test one such strategy, we simulated reopening on 1 May, and modelled the effects of reducing the maximum occupancy in which the numbers of hourly visits to each POI returned to their ‘normal’ levels from the first week of March but were capped if they exceeded a fraction of the maximum occupancy of that POI35. Full reopening without reducing the maximum occupancy produced a spike in the predicted number of infections: in the Chicago metro area, our models projected that an additional 32% (95% confidence interval, 25–35%) of the population would be infected by the end of May (Fig. 2c). However, reducing the maximum occupancy substantially reduced the risk without sharply reducing overall mobility: capping at 20% of the maximum occupancy in the Chicago metro area reduced the predicted number of new infections by more than 80% but only lost 42% of overall visits, and we observed similar trends across other metro areas (Extended Data Fig. 3). This result highlights the nonlinearity of the predicted number of infections as a function of the number of visits: one can achieve a disproportionately large reduction in infections with a small reduction in visits. Furthermore, in comparison to a different reopening strategy, in which the number of visits to each POI was uniformly reduced from their levels in early March, reducing the maximum occupancy always resulted in fewer predicted infections for the same number of total visits (Fig. 2c and Extended Data Fig. 4). This is because reducing the maximum occupancies takes advantage of the time-varying visit density within each POI, disproportionately reducing visits to the POI during the high-density periods with the highest risk, but leaving visit counts unchanged during periods with lower risks. These results support previous findings that precise interventions, such as reducing the maximum occupancy, may be more effective than less targeted measures, while incurring substantially lower economic costs36.
Relative risk of reopening different categories of POIs
Because we found that certain POI categories contributed far more to predicted infections in March (Extended Data Fig. 2), we also expected that reopening some POI categories would be riskier than reopening others. To assess this, we simulated reopening each category in turn on 1 May 2020 (by returning its mobility patterns to early March levels, as above), while keeping all other POIs at their reduced mobility levels from the end of April. We found large variation in predicted reopening risks: on average across metro areas, full-service restaurants, gyms, hotels, cafes, religious organizations and limited-service restaurants produced the largest predicted increases in infections when reopened (Extended Data Fig. 5d). Reopening full-service restaurants was associated with a particularly high risk: in the Chicago metro area, we predicted an additional 595,805 (95% confidence interval, 433,735–685,959) infections by the end of May, more than triple that of the POI category with the next highest risk (Fig. 2d). These risks are summed over all POIs in the category, but the relative risks after normalizing by the number of POIs were broadly similar (Extended Data Fig. 5c). These categories were predicted to be have a higher risk because, in the mobility data, their POIs tended to have higher visit densities and/or visitors stayed there longer (Supplementary Figs. 15–24).
Demographic disparities in infections
We characterize the differential spread of SARS-CoV-2 along demographic lines by using US census data to annotate each CBG with its racial composition and median income, then tracking predicted infection rates in CBGs with different demographic compositions: for example, within each metro area, comparing CBGs in the top and bottom deciles for income. We use this approach to study the mobility mechanisms behind disparities and to quantify how different reopening strategies affect disadvantaged groups.
Predicting disparities from mobility data
Despite having access to only mobility data and no demographic information, our models correctly predicted higher risks of infection among disadvantaged racial and socioeconomic groups2,3,4,5,6,7,8. Across all metro areas, individuals from CBGs in the bottom decile for income had a substantially higher likelihood of being infected by the end of the simulation, even though all individuals began with equal likelihoods of infection (Fig. 3a). This predicted disparity was driven primarily by a few POI categories (for example, full-service restaurants); far greater proportions of individuals from lower-income CBGs than higher-income CBGs became infected in these POIs (Fig. 3c and Supplementary Fig. 2). We similarly found that CBGs with fewer white residents had higher predicted risks of infection, although results were more variable across metro areas (Fig. 3b). In the Supplementary Discussion, we confirm that the magnitude of the disparities that our model predicts is generally consistent with real-world disparities and further explore the large predicted disparities in Philadelphia, that stem from substantial differences in the POIs that are frequented by higher- versus lower-income CBGs. In the analysis below, we discuss two mechanisms that lead higher predicted infection rates among lower-income CBGs, and we show in Extended Data Fig. 6 and Extended Data Table 4 that similar results hold for racial disparities as well.

a, In every metro area, our model predicts that people in lower-income CBGs are likelier to be infected. b, People in non-white CBGs area are also likelier to be infected, although results are more variable across metro areas. For c–f, the Chicago metro area is used as an example, but references to results for all metro areas are provided for each panel. c, The overall predicted disparity is driven by a few POI categories such as full-service restaurants (Supplementary Fig. 2). d, One reason for the predicted disparities is that higher-income CBGs were able to reduce their mobility levels below those of lower-income CBGs (Extended Data Fig. 6). e, Within each POI category, people from lower-income CBGs tend to visit POIs that have higher predicted transmission rates (Extended Data Table 3). The size of each dot represents the average number of visits per capita made to the category. The top 10 out of 20 categories with the most visits are labelled, covering 0.48–2.88 visits per capita (hardware stores–full-service restaurants). f, Reopening (at different levels of reduced maximum occupancy) leads to more predicted infections in lower-income CBGs than in the overall population (Extended Data Fig. 3). In c–f, purple denotes lower-income CBGs, yellow denotes higher-income CBGs and blue represents the overall population. Aside from d and e, which were directly extracted from mobility data, all results in this figure represent predictions aggregated over model realizations. Across metro areas, we sample 97 parameter sets, with 30 stochastic realizations each (n = 2,910); see Supplementary Table 6 for the number of sets per metro area. Shaded regions in c and f denote the 2.5th–97.5th percentiles; boxes in (a, b) denote the interquartile range; data points outside the range are shown as individual dots.
Lower-income CBGs saw smaller reductions in mobility
A first mechanism producing disparities was that, across all metro areas, lower-income CBGs did not reduce their mobility as sharply in the first few weeks of March 2020, and these groups showed higher mobility than higher-income CBGs for most of March–May (Fig. 3d and Extended Data Fig. 6). For example, in April, individuals from lower-income CBGs in the Chicago metro area had 27% more POI visits per capita than those from higher-income CBGs. Category-level differences in visit patterns partially explained the infection disparities within each category: for example, individuals from lower-income CBGs made substantially more visits per capita to grocery stores than did those from higher-income CBGs (Supplementary Fig. 3) and consequently experienced more predicted infections for that category (Supplementary Fig. 2).
POIs visited by lower-income CBGs have higher transmission rates
Differences in visits per capita do not fully explain the infection disparities: for example, cafes and snack bars were visited more frequently by higher-income CBGs in every metro area (Supplementary Fig. 3), but our model predicted that a larger proportion of individuals from lower-income CBGs were infected at cafes and snack bars in the majority of metro areas (Supplementary Fig. 2). We found that even within a POI category, the predicted transmission rates at POIs frequented by individuals fom lower-income CBGs tended to be higher than the corresponding rates for those from higher-income CBGs (Fig. 3e and Extended Data Table 3), because POIs frequented by individuals from lower-income CBGs tended to be smaller and more crowded in the mobility data. As a case study, we examined grocery stores in further detail. In eight of the ten metro areas, visitors from lower-income CBGs encountered higher predicted transmission rates at grocery stores than visitors from higher-income CBGs (median transmission rate ratio of 2.19) (Extended Data Table 3). We investigated why one visit to the grocery store was predicted to be twice as dangerous for an individual from a lower-income CBG: the mobility data showed that the average grocery store visited by individuals from lower-income CBGs had 59% more hourly visitors per square foot, and their visitors stayed 17% longer on average (medians across metro areas). These findings highlight how fine-grained differences in mobility patterns—how often people go out and which POIs that they go to—can ultimately contribute to marked disparities in predicted infection outcomes.
Reopening plans must account for disparate effects
Because disadvantaged groups suffer a larger burden of infection, it is critical to not only consider the overall impact of reopening plans but also their disparate effects on disadvantaged groups specifically. For example, our model predicted that full reopening in the Chicago metro area would result in an additional 39% (95% confidence interval, 31–42%) of the population of CBGs in the bottom income decile being infected within a month, compared to 32% (95% confidence interval, 25–35%) of the overall population (Fig. 3f; results for all metro areas are shown in Extended Data Fig. 3). Similarly, Supplementary Fig. 4 illustrates that reopening individual POI categories tends to have a larger predicted effect on lower-income CBGs. More stringent reopening plans produce smaller absolute disparities in predicted infections—for example, we predict that reopening at 20% of the maximum occupancy in Chicago would result in additional infections for 6% (95% confidence interval, 4–8%) of the overall population and 10% (95% confidence interval, 7–13%) of the population in CBGs in the bottom income decile (Fig. 3f)—although the relative disparity remains.
Discussion
The mobility dataset that we use has limitations: it does not cover all populations, does not contain all POIs and cannot capture sub-CBG heterogeneity. Our model itself is also parsimonious, and does not include all real-world features that are relevant to disease transmission. We discuss these limitations in more detail in the Supplementary Discussion. However, the predictive accuracy of our model suggests that it broadly captures the relationship between mobility and transmission, and we thus expect our broad conclusions—for example, that people from lower-income CBGs have higher infection rates in part because they tend to visit denser POIs and because they have not reduced mobility by as much (probably because they cannot work from home as easily4)—to hold robustly. Our fine-grained network modelling approach naturally extends to other mobility datasets and models that capture more aspects of real-world transmission, and these represent interesting directions for future work.
Our results can guide policy-makers that seek to assess competing approaches to reopening. Despite growing concern about racial and socioeconomic disparities in infections and deaths, it has been difficult for policy-makers to act on those concerns; they are currently operating without much evidence on the disparate effects of reopening policies, prompting calls for research that both identifies the causes of observed disparities and suggests policy approaches to mitigate them5,8,37,38. Our fine-grained mobility modelling addresses both these needs. Our results suggest that infection disparities are not the unavoidable consequence of factors that are difficult to address in the short term, such as differences in preexisting conditions; on the contrary, short-term policy decisions can substantially affect infection outcomes by altering the overall amount of mobility allowed and the types of POIs reopened. Considering the disparate effects of reopening plans may lead policy-makers to adopt policies that can drive down infection densities in disadvantaged neighbourhoods by supporting, for example, more stringent caps on POI occupancies, emergency food distribution centres to reduce densities in high-risk stores, free and widely available testing in neighbourhoods predicted to be high risk (especially given known disparities in access to tests2), improved paid leave policy or income support that enables essential workers to curtail mobility when sick, and improved workplace infection prevention for essential workers, such as high-quality personal protective equipment, good ventilation and physical distancing when possible. As reopening policies continue to be debated, it is critical to build tools that can assess the effectiveness and equity of different approaches. We hope that our model, by capturing heterogeneity across POIs, demographic groups and cities, helps to address this need.
Methods
The Methods is structured as follows. We describe the datasets that we used in the ‘Datasets’ section and the mobility network that we derived from these datasets in the ‘Mobility network’ section. In the ‘Model dynamics’ section, we discuss the SEIR model that we overlaid on the mobility network; in the ‘Model calibration’ section, we describe how we calibrated this model and quantified uncertainty in its predictions. Finally, in the ‘Analysis details’ section, we provide details on the experimental procedures used for our analyses of mobility reduction, reopening plans and demographic disparities.
Datasets
SafeGraph
We use data provided by SafeGraph, a company that aggregates anonymized location data from numerous mobile applications. SafeGraph data captures the movement of people between CBGs, which are geographical units that typically contain a population of between 600 and 3,000 people, and POIs such as restaurants, grocery stores or religious establishments. Specifically, we use the following SafeGraph datasets.
First, we used the Places Patterns39 and Weekly Patterns (v1)40 datasets. These datasets contain, for each POI, hourly counts of the number of visitors, estimates of median visit duration in minutes (the ‘dwell time’) and aggregated weekly and monthly estimates of the home CBGs of visitors. We use visitor home CBG data from the Places Patterns dataset: for privacy reasons, SafeGraph excludes a home CBG from this dataset if fewer than five devices were recorded at the POI from that CBG over the course of the month. For each POI, SafeGraph also provides their North American industry classification system category, as well as estimates of its physical area in square feet. The area is computed using the footprint polygon SafeGraph that assigns to the POI41,42. We analyse Places Patterns data from 1 January 2019 to 29 February 2020 and Weekly Patterns data from 1 March 2020 to 2 May 2020.
Second, we used the Social Distancing Metrics dataset43, which contains daily estimates of the proportion of people staying home in each CBG. We analyse Social Distancing Metrics data from 1 March 2020 to 2 May 2020.
We focus on 10 of the largest metro areas in the United States (Extended Data Table 1). We chose these metro areas by taking a random subset of the SafeGraph Patterns data and selecting the 10 metro areas with the most POIs in the data. The application of the methods described in this paper to the other metro areas in the original SafeGraph data should be straightforward. For each metro area, we include all POIs that meet all of the following requirements: (1) the POI is located in the metro area ; (2) SafeGraph has visit data for this POI for every hour that we model, from 00:00 on 1 March 2020 to 23:00 on 2 May 2020; (3) SafeGraph has recorded the home CBGs of visitors to this POI for at least one month from January 2019 to February 2020; (4) the POI is not a ‘parent’ POI. Parent POIs comprise a small fraction of POIs in the dataset that overlap and include the visits from their ‘child’ POIs: for example, many malls in the dataset are parent POIs, which include the visits from stores that are their child POIs. To avoid double-counting visits, we remove all parent POIs from the dataset. After applying these POI filters, we include all CBGs that have at least one recorded visit to at least ten of the remaining POIs; this means that CBGs from outside the metro area may be included if they visit this metro area frequently enough. Summary statistics of the post-processed data are shown in Extended Data Table 1. Overall, we analyse 56,945 CBGs from the 10 metro areas, and more than 310 million visits from these CBGs to 552,758 POIs.
SafeGraph data have been used to study consumer preferences44 and political polarization45. More recently, it has been used as one of the primary sources of mobility data in the USA for tracking the effects of the COVID-19 pandemic26,28,46,47,48. In Supplementary Methods section 1, we show that aggregate trends in SafeGraph mobility data match the aggregate trends in Google mobility data in the USA49, before and after the imposition of stay-at-home measures. Previous analyses of SafeGraph data have shown that it is geographically representative—for example, it does not systematically overrepresent individuals from CBGs in different counties or with different racial compositions, income levels or educational levels50,51.
US census
Our data on the demographics of the CBGs comes from the American Community Survey (ACS) of the US Census Bureau52. We use the 5-year ACS data (2013–2017) to extract the median household income, the proportion of white residents and the proportion of Black residents of each CBG. For the total population of each CBG, we use the most-recent one-year estimates (2018); one-year estimates are noisier but we wanted to minimize systematic downward bias in our total population counts (due to population growth) by making them as recent as possible.
The New York Times dataset
We calibrated our models using the COVID-19 dataset published by the The New York Times32. Their dataset consists of cumulative counts of cases and deaths in the USA over time, at the state and county level. For each metro area that we modelled, we sum over the county-level counts to produce overall counts for the entire metro area. We convert the cumulative case and death counts to daily counts for the purposes of model calibration, as described in the ‘Model calibration’ section.
Data ethics
The dataset from The New York Times consists of aggregated COVID-19-confirmed case and death counts collected by journalists from public news conferences and public data releases. For the mobility data, consent was obtained by the third-party sources that collected the data. SafeGraph aggregates data from mobile applications that obtain opt-in consent from their users to collect anonymous location data. Google’s mobility data consists of aggregated, anonymized sets of data from users who have chosen to turn on the location history setting. Additionally, we obtained IRB exemption for SafeGraph data from the Northwestern University IRB office.
Mobility network
Definition
We consider a complete undirected bipartite graph \({\mathscr{G}}=({\mathscr{V}}, {\mathcal E} )\) with time-varying edges. The vertices \({\mathscr{V}}\) are partitioned into two disjoint sets \({\mathscr{C}}=\{{c}_{1},\ldots ,{c}_{m}\}\), representing m CBGs, and \({\mathscr{P}}=\{{p}_{1},\ldots ,{p}_{n}\}\), representing n POIs. From US census data, each CBG ci is labelled with its population \({N}_{{c}_{i}}\), income distribution, and racial and age demographics. From SafeGraph data, each POI pj is similarly labelled with its category (for example, restaurant, grocery store or religious organization), its physical size in square feet \({a}_{{p}_{j}}\), and the median dwell time \({d}_{{p}_{j}}\) of visitors to pj. The weight \({w}_{ij}^{(t)}\) on an edge (ci, pj) at time t represents our estimate of the number of individuals from CBG ci visiting POI pj at the tth hour of simulation. We record the number of edges (with non-zero weights) in each metro area and for all hours from 1 March 2020 to 2 May 2020 in Extended Data Table 1. Across all 10 metro areas, we study 5.4 billion edges between 56,945 CBGs and 552,758 POIs.
Overview of the network estimation
The central technical challenge in constructing this network is estimating the network weights \({W}^{(t)}\,=\,\{{w}_{ij}^{(t)}\}\) from SafeGraph data, as this visit matrix is not directly available from the data. Our general methodology for network estimation is as follows.
First, from SafeGraph data, we derived a time-independent estimate \(\bar{W}\) of the visit matrix that captures the aggregate distribution of visits from CBGs to POIs from January 2019 to February 2020.
Second, because visit patterns differ substantially from hour to hour (for example, day versus night) and day to day (for example, before versus after lockdown), we used current SafeGraph data to capture these hourly variations and to estimate the CBG marginals U(t), that is, the number of people in each CBG who are out visiting POIs at hour t, as well as the POI marginals V(t), that is, the total number of visitors present at each POI pj at hour t.
Finally, we applied the iterative proportional fitting procedure (IPFP) to estimate an hourly visit matrix W(t) that is consistent with the hourly marginals U(t) and V(t) but otherwise ‘as similar as possible’ to the distribution of visits in the aggregate visit matrix \(\bar{W}\), in terms of Kullback–Leibler divergence.
IPFP is a classic statistical method31 for adjusting joint distributions to match prespecified marginal distributions, and it is also known in the literature as biproportional fitting, the RAS algorithm or raking53. In the social sciences, it has been widely used to infer the characteristics of local subpopulations (for example, within each CBG) from aggregate data54,55,56. IPFP estimates the joint distribution of visits from CBGs to POIs by alternating between scaling each row to match the hourly row (CBG) marginals U(t) and scaling each column to match the hourly column (POI) marginals V(t). Further details about the estimation procedure are provided in Supplementary Methods section 3.
Model dynamics
To model the spread of SARS-CoV-2, we overlay a metapopulation disease transmission model on the mobility network defined in the ‘Mobility Network’ section. The transmission model structure follows previous work15,20 on epidemiological models of SARS-CoV-2 but incorporates a fine-grained mobility network into the calculations of the transmission rate. We construct separate mobility networks and models for each metropolitan statistical area.
We use a SEIR model with susceptible (S), exposed (E), infectious (I) and removed (R) compartments. Susceptible individuals have never been infected, but can acquire the virus through contact with infectious individuals, which may happen at POIs or in their home CBG. They then enter the exposed state, during which they have been infected but are not infectious yet. Individuals transition from exposed to infectious at a rate inversely proportional to the mean latency period. Finally, they transition into the removed state at a rate inversely proportional to the mean infectious period. The removed state represents individuals who can no longer be infected or infect others, for example, because they have recovered, self-isolated or died.
Each CBG ci maintains its own SEIR instantiation, with \({S}_{{c}_{i}}^{(t)}\), \({E}_{{c}_{i}}^{(t)}\), \({I}_{{c}_{i}}^{(t)}\) and \({R}_{{c}_{i}}^{(t)}\) representing how many individuals in CBG ci are in each disease state at hour t, and \({N}_{{c}_{i}}={S}_{{c}_{i}}^{(t)}+{E}_{{c}_{i}}^{(t)}+{I}_{{c}_{i}}^{(t)}+{R}_{{c}_{i}}^{(t)}\). At each hour t, we sample the transitions between states as follows:
where \({\lambda }_{{p}_{j}}^{(t)}\) is the rate of infection at POI pj at time t; \({w}_{ij}^{(t)}\), the ijth entry of the visit matrix from the mobility network (see ‘Mobility network’), is the number of visitors from CBG ci to POI pj at time t; \({\lambda }_{{c}_{i}}^{(t)}\) is the base rate of infection that is independent of visiting POIs; δE is the mean latency period; and δI is the mean infectious period.
We then update each state to reflect these transitions. Let \(\Delta {S}_{{c}_{i}}^{(t)}={S}_{{c}_{i}}^{(t+1)}-{S}_{{c}_{i}}^{(t)}\) and likewise for \(\Delta {E}_{{c}_{i}}^{(t)}\), \(\Delta {I}_{{c}_{i}}^{(t)}\) and \(\Delta {R}_{{c}_{i}}^{(t)}\). Then, we make the following updates:
The number of new exposures
We separate the number of new exposures \({N}_{{S}_{{c}_{i}}\to {E}_{{c}_{i}}}^{(t)}\) in CBG ci at time t into two parts: cases from visiting POIs, which are sampled from \({\rm{Pois}}(({S}_{{c}_{i}}^{(t)}/{N}_{{c}_{i}}){\sum }_{j=1}^{n}{\lambda }_{{p}_{j}}^{(t)}{w}_{ij}^{(t)})\), and other cases not captured by visiting POIs, which are sampled from \({\rm{B}}{\rm{i}}{\rm{n}}{\rm{o}}{\rm{m}}({S}_{{c}_{i}}^{(t)},{\lambda }_{{c}_{i}}^{(t)})\).
First, we calculate the number of new exposures from visiting POIs. We assume that any susceptible visitor to POI pj at time t has the same independent probability \({\lambda }_{{p}_{j}}^{(t)}\) of being infected and transitioning from the susceptible (S) to the exposed (E) state. As there are \({w}_{ij}^{(t)}\) visitors from CBG ci to POI pj at time t, and we assume that a \({S}_{{c}_{i}}^{(t)}/{N}_{{c}_{i}}\) fraction of them are susceptible, the number of new exposures among these visitors is distributed as \({\rm{b}}{\rm{i}}{\rm{n}}{\rm{o}}{\rm{m}}({w}_{ij}^{(t)}{S}_{{c}_{i}}^{(t)}/{N}_{{c}_{i}},{\lambda }_{{p}_{j}}^{(t)})\approx {\rm{P}}{\rm{o}}{\rm{i}}{\rm{s}}({\lambda }_{{p}_{j}}^{(t)}{w}_{ij}^{(t)}{S}_{{c}_{i}}^{(t)}/{N}_{{c}_{i}})\). The number of new exposures among all outgoing visitors from CBG ci is therefore distributed as the sum of the above expression over all POIs, \({\rm{Pois}}(({S}_{{c}_{i}}^{(t)}/{N}_{{c}_{i}}){\sum }_{j=1}^{n}{\lambda }_{{p}_{j}}^{(t)}{w}_{ij}^{(t)})\).
We model the infection rate at POI pj at time t, \({\lambda }_{{p}_{j}}^{(t)}={\beta }_{{p}_{j}}^{(t)}({I}_{{p}_{j}}^{(t)}/{V}_{{p}_{j}}^{(t)})\), as the product of its transmission rate \({\beta }_{{p}_{j}}^{(t)}\) and proportion of infectious individuals \({I}_{{p}_{j}}^{(t)}/{V}_{{p}_{j}}^{(t)}\), where \({V}_{{p}_{j}}^{(t)}={\sum }_{i=1}^{m}{w}_{ij}^{(t)}\) is the total number of visitors to pj at time t. We model the transmission rate at POI pj at time t as
where \({a}_{{p}_{j}}\) is the physical area of pj, and ψ is a transmission constant (shared across all POIs) that we fit to data. The inverse scaling of transmission rate with area \({a}_{{p}_{j}}\) is a standard simplifying assumption57. The dwell time fraction \({d}_{{p}_{j}}\in [0,1]\) is what fraction of an hour an average visitor to pj at any hour will spend there (Supplementary Methods section 3); it has a quadratic effect on the POI transmission rate \({\beta }_{{p}_{j}}^{(t)}\) because it reduces both the time that a susceptible visitor spends at pj and the density of visitors at pj. With this expression for the transmission rate \({\beta }_{{p}_{j}}^{(t)}\), we can calculate the infection rate at POI pj at time t as
For sufficiently large values of ψ and a sufficiently large proportion of infected individuals, the expression above can sometimes exceed 1. To address this, we simply clip the infection rate to 1. However, this occurs very rarely for the parameter settings and simulation duration that we use.
Finally, to compute the number of infectious individuals at pj at time t, \({I}_{{p}_{j}}^{(t)}\), we assume that the proportion of infectious individuals among the \({w}_{kj}^{(t)}\) visitors to pj from a CBG ck mirrors the overall density of infections \({I}_{{c}_{k}}^{(t)}/{N}_{{c}_{k}}\) in that CBG, although we note that the scaling factor ψ can account for differences in the ratio of infectious individuals who visit POIs. This gives
In addition to the new exposures from infections at POIs, we model a CBG-specific base rate of new exposures that is independent of POI visit activity. This captures other sources of infections, for example, household infections or infections at POIs that are absent from the SafeGraph data. We assume that at each hour, every susceptible individual in CBG ci has a base probability \({\lambda }_{{c}_{i}}^{(t)}\) of becoming infected and transitioning to the exposed state, where
is the product of the base transmission rate βbase and the proportion of infectious individuals in CBG ci. βbase is a constant (shared across all CBGs) that we fit to data.
By adding all of the above together, the expression for the distribution of the overall number of new exposures in CBG ci at time t becomes
The number of new infectious and removed cases
We model exposed individuals as becoming infectious at a rate that is inversely proportional to the mean latency period δE. At each time step t, we assume that each exposed individual has a constant, time-independent probability of becoming infectious, with
Similarly, we model infectious individuals as transitioning to the removed state at a rate that is inversely proportional to the mean infectious period δI, with
We estimate δE = 96 h (refs. 20,58) and δI = 84 h (ref. 20) based on previous studies.
Model initialization
In our experiments, t = 0 is the first hour of 1 March 2020. We approximate the infectious I and removed R compartments at t = 0 as initially empty, with all infected individuals in the exposed E compartment. We further assume that the same expected initial prevalence p0 occurs in every CBG ci. At t = 0, every individual in the metro area has the same independent probability p0 of being exposed E instead of susceptible S. We thus initialize the model state by setting
Aggregate mobility and no-mobility baseline models
To test whether the detailed mobility network is necessary, or whether our model is simply making use of aggregate mobility patterns, we tested an alternative SEIR model that uses the aggregate number of visits made to any POI in the metro area in each hour, but not the breakdown of visits between specific CBGs to specific POIs. Like our model, the aggregate mobility model also captures new cases from visiting POIs and a base rate of infection that is independent of POI visit activity; thus, the two models have the same three free parameters (ψ, scaling transmission rates at POIs; βbase, the base transmission rate ; and p0, the initial fraction of infected individuals). However, instead of having POI-specific rates of infection, the aggregate mobility model captures only a single probability that a susceptible person from any CBG will become infected due to a visit to any POI at time t; we make this simplification because the aggregate mobility model no longer has access to the breakdown of visits between CBGs and POIs. This probability \({\lambda }_{{\rm{POI}}}^{(t)}\) is defined as
where m is the number of CBGs, n is the number of POIs, I(t) is the total number of infectious individuals at time t, and N is the total population size of the metro area. For the base rate of infections in CBGs, we assume the same process as in our network model: the probability \({\lambda }_{{c}_{i}}^{(t)}\) that a susceptible person in CBG ci will become infected in their CBG at time t is equal to βbase times the current infectious fraction of ci (equation (11)). Putting it together, the aggregate mobility model defines the number of new exposures in CBG ci at time t as
All other dynamics remain the same between the aggregate mobility model and our network model, and we calibrated the models in the same way, which we describe in the ‘Model calibration’ section. We found that our network model substantially outperformed the aggregate mobility model in predictions of out-of-sample cases: on average across metro areas, the out-of-sample r.m.s.e. of our best-fit network model was only 58% that of the best-fit aggregate mobility model (Extended Data Fig. 1). This demonstrates that it is not only general mobility patterns, but specifically the mobility network that allows our model to accurately fit observed cases.
Next, to determine the extent to which mobility data could aid in modelling the case trajectory, we compared our model to a baseline SEIR model that does not use mobility data and simply assumes that all individuals within an metro area mix uniformly. In this no-mobility baseline, an individual’s risk of being infected and transitioning to the exposed state at time t is
where I(t) is the total number of infectious individuals at time t, and N is the total population size of the metro area. As above, the other model dynamics are identical, and for model calibration we performed a similar grid search over βbase and p0. As expected, we found both the network and aggregate mobility models outperformed the no-mobility model on out-of-sample case predictions (Extended Data Fig. 1).
Model calibration and validation
Most of our model parameters can either be estimated from SafeGraph and US census data, or taken from previous studies (see Extended Data Table 2 for a summary). This leaves three model parameters that do not have direct analogues in the literature, and that we therefore need to calibrate with data: (1) the transmission constant in POIs, ψ (equation (9)); (2) the base transmission rate, βbase (equation (11)); and (3) the initial proportion of exposed individuals at time t = 0, p0 (equation (16)).
In this section, we describe how we fitted these parameters to published numbers of confirmed cases, as reported by The New York Times. We fitted models for each metro area separately.
Selecting parameter ranges for ψ, β base and p 0
We select parameter ranges for the transmission rate factors ψ and βbase by checking whether the model outputs match plausible ranges of the basic reproduction number R0 before lockdown, as R0 has been the study of substantial previous work on SARS-CoV-259. Under our model, we can decompose R0 = Rbase + RPOI, where RPOI describes transmission due to POIs and Rbase describes the remaining transmission (as in equation (12)). We first establish plausible ranges for Rbase and RPOI before translating these into plausible ranges for βbase and ψ.
We assume that Rbase ranges from 0.1 to 2. Rbase models transmission that is not correlated with activity at POIs in the SafeGraph dataset, including within-household transmission and transmission at POI categories that are not well-captured in the SafeGraph dataset. We chose the lower limit of 0.1 because beyond that point, base transmission would only contribute minimally to overall R, whereas previous studies have suggested that within-household transmission is a substantial contributor to overall transmission60,61,62. Household transmission alone is not estimated to be sufficient to tip the overall R0 above 1; for example, a single infected individual has been estimated to cause an average of 0.32 (0.22–0.42) secondary within-household infections60. However, because Rbase may also capture transmission at POIs that are not captured in the SafeGraph dataset, to be conservative, we chose an upper limit of Rbase = 2; as we describe below, the best-fit models for all 10 metro areas have Rbase < 2, and 9 out of 10 have Rbase < 1. We allow RPOI to range from 1 to 3, which corresponds to allowing R0 = RPOI + Rbase to range from 1.1 to 5. This is a conservatively wide range, as a previous study59 estimated a pre-lockdown R0 of 2–3.
To determine the values of Rbase and RPOI that a given pair of βbase and ψ imply, we seeded a fraction of index cases and then ran the model on looped mobility data from the first week of March to capture pre-lockdown conditions. We initialized the model by setting p0, the initial proportion of exposed individuals at time t = 0, to p0 = 10−4, and then sampling in accordance with equation (16). Let N0 be the number of initial exposed individuals sampled. We computed the number of individuals that these N0 index cases went on to infect through base transmission, Nbase, and POI transmission, NPOI, which gives
We averaged these quantities over stochastic realizations for each metro area. Supplementary Figure 6 shows that, as expected, Rbase is linear in βbase and RPOI is linear in ψ. Rbase lies in the plausible range when βbase ranges from 0.0012 to 0.024, and RPOI lies in the plausible range (for at least one metro area) when ψ ranges from 515 to 4,886; we therefore consider these parameter ranges when fitting the model.
The extent to which SARS-CoV-2 infections had spread in the USA by the start of our simulation (1 March 2020) is currently unclear63. To account for this uncertainty, we allow p0 to vary across a large range between 10−5 and 10−2. As described in the next section, we verified that case count data for all metro areas can be fit using parameter settings for βbase, ψ and p0 within this range.
Fitting to the number of confirmed cases
Using the parameter ranges described above, we grid-searched over ψ, βbase and p0 to find the models that best fit the number of confirmed cases reported by The New York Times32. For each metro area, we tested 1,500 different combinations of ψ, βbase and p0 in the parameter ranges specified above, with parameters linearly spaced for ψ and βbase and logarithmically spread for p0.
In the ‘Model dynamics’ section, we directly model the number of infections but not the number of confirmed cases. To estimate the number of confirmed cases, we assume that an rc = 0.1 proportion20,58,64,65,66 of infections will be confirmed, and moreover that they will confirmed exactly δc = 168 h (7 days)20,66 after becoming infectious. From these assumptions, we can calculate the predicted number of newly confirmed cases across all CBGs in the metro area on day d,
where m indicates the total number of CBGs in the metro area and for convenience we define \({N}_{{E}_{{c}_{i}}\to {I}_{{c}_{i}}}^{(\tau )}\), the number of newly infectious people at hour τ, to be 0 when τ < 1.
From the dataset of The New York Times, we have the reported number of new cases \({\hat{N}}_{{\rm{cases}}}^{({\rm{day}}\,d)}\) for each day d, summed over each county in the metro area. We compare the reported number of cases and the number of cases that our model predicts by computing the r.m.s.e. between each of the D = ⌊T/24⌋ days of our simulations,
For each combination of model parameters and for each metro area, we quantify the model fit with the data from The New York Times by running 30 stochastic realizations and averaging their r.m.s.e. Note that we measure model fit based on the daily number of new reported cases (as opposed to the cumulative number of reported cases)67.
Our simulation spans 1 March to 2 May 2020, and we use mobility data from that period. However, because we assume that cases will be confirmed δc = 7 days after individuals become infectious, we predict the number of cases with a 7-day offset, from 8 March to 9 May 2020.
Parameter selection and uncertainty quantification
Throughout this paper, we report aggregate predictions from different parameter sets of ψ, βbase and p0, and multiple stochastic realizations. For each metro area, we: (1) find the best-fit parameter set, that is, with the lowest average r.m.s.e. on daily incident cases over stochastic realizations; (2) select all parameter sets that achieve an r.m.s.e. (averaged over stochastic realizations) within 20% of the r.m.s.e. of the best-fit parameter set; and (3) pool together all predictions across those parameter sets and all of their stochastic realizations, and report their mean and 2.5–97.5th percentiles.
On average, each metro area has 9.7 parameter sets that achieve an r.m.s.e. within 20% of the best-fitting parameter set (Supplementary Table 6). For each parameter set, we have results for 30 stochastic realizations.
This procedure corresponds to rejection sampling in an approximate Bayesian computation framework15, for which we assume an error model that is Gaussian with constant variance; we pick an acceptance threshold based on what the best-fit model achieves; and we use a uniform parameter grid instead of sampling from a uniform prior. It quantifies uncertainty from two sources. First, the multiple realizations capture stochastic variability between model runs with the same parameters. Second, simulating with all parameter sets that are within 20% of the r.m.s.e. of the best fit captures uncertainty in the model parameters ψ, βbase and p0. This procedure is equivalent to assuming that the posterior probability over the true parameters is uniformly spread among all parameter sets within the 20% threshold.
Model validation on out-of-sample cases
We validate our models by showing that they predict the number of confirmed cases on out-of-sample data when we have access to corresponding mobility data. For each metro area, we split the available dataset from the The New York Times into a training set (spanning from 8 March 2020 to 14 April 2020) and a test set (spanning from 15 April 2020 to 9 May 2020). We fit the model parameters ψ, βbase and p0, as described in the ‘Mobility network’ section, but using only the training set. We then evaluate the predictive accuracy of the resulting model on the test set. When running our models on the test set, we still use mobility data from the test period. Thus, this is an evaluation of whether the models can accurately predict the number of cases, given mobility data, in a time period that was not used for model calibration. Extended Data Figure 1 shows that our network model fits the out-of-sample case data fairly well, and that our model substantially outperforms alternative models that use aggregated mobility data (without a network) or do not use mobility data at all (see ‘Aggregate mobility and no-mobility baseline models’). Note that we only use this train/test split to evaluate out-of-sample model accuracy. All other results are generated using parameter sets that best fit the entire dataset, as described above.
Analysis details
In this section, we include additional details about the experiments that underlie the figures in the paper. We do not include explanations for figures that are completely described in the main text.
Counterfactuals of mobility reduction
Associated with Fig. 2a and Supplementary Tables 4, 5. To simulate what would have happened if we changed the magnitude or timing of mobility reduction, we modified the real mobility networks from 1 March to 2 May 2020, and then ran our models on the hypothetical data. In Fig. 2a, we report the total number of people per 100,000 of the population ever infected (that is, in the exposed, infectious and removed states) by the end of the simulation.
To simulate a smaller magnitude of mobility reduction, we interpolate between the mobility network from the first week of simulation (1–7 March 2020), which we use to represent typical mobility levels, and the actual observed mobility network for each week. Let W(t) represent the observed visit matrix at the tth hour of simulation, and let f(t) = t mod 168 map t to its corresponding hour in the first week of simulation, since there are 168 h in a week. To represent the scenario in which people had committed to α ∈ [0, 1] times the actual observed reduction in mobility, we construct a visit matrix \({\tilde{W}}_{\alpha }^{(t)}\) that is an α-convex combination of W(t) and Wf(t),
If α is 1, then \({\tilde{W}}_{\alpha }^{(t)}={W}^{(t)}\), and we use the actual observed mobility network for the simulation. On the other hand, if α = 0, then \({\tilde{W}}_{\alpha }^{(t)}={W}^{f(t)}\), and we assume that people did not reduce their mobility levels at all by looping the visit matrix for the first week of March throughout the simulation. Any other α ∈ [0, 1] interpolates between these two extremes.
To simulate changing the timing of mobility reduction, we shift the mobility network by d ∈ [−7, 7] days. Let T represent the last hour in our simulation (2 May 2020, 23:00), let f(t) = t mod 168 map t to its corresponding hour in the first week of simulation as above, and similarly let g(t) map t to its corresponding hour in the last week of simulation (27 April–2 May 2020). We construct the time-shifted visit matrix \({\tilde{W}}_{d}^{(t)}\)
If d is positive, this corresponds to starting mobility reduction d days later; if we imagine time on a horizontal line, this shifts the time series to the right by 24d hours. However, doing so leaves the first 24d hours without visit data, so we fill it in by reusing visit data from the first week of simulation. Likewise, if d is negative, this corresponds to starting mobility reduction d days earlier, and we fill in the last 24d hours with visit data from the last week of simulation.
Distribution of predicted infections across POIs
Associated with Fig. 2b, Extended Data Fig. 2 and Supplementary Fig. 10. We run our models on the observed mobility data from 1 March–2 May 2020 and record the number of predicted infections that occur at each POI. Specifically, for each hour t, we compute the number of expected infections that occur at each POI pj by taking the number of susceptible people who visit pj in that hour multiplied by the POI infection rate \({\lambda }_{{p}_{j}}^{(t)}\) (equation (9)). In Fig. 2b and Supplementary Fig. 10, we sort the POIs by their total predicted number of infections (summed over hours) and plot the cumulative distribution of infections over this ordering of POIs. In Extended Data Fig. 2, we select the POI categories that contribute the most to predicted infections and plot the daily proportion of POI infections each category accounted for (summed over POIs within the category) over time.
Reducing mobility by capping maximum occupancy
Associated with Figs. 2c and Extended Data Fig. 3. We implemented two partial reopening strategies: one that uniformly reduced visits at POIs to a fraction of full activity, and the other that ‘capped’ the number of hourly visits at each POI to a fraction of the maximum occupancy of that the POI. For each reopening strategy, we started the simulation on 1 March 2020 and ran it until 30 May 2020, using the observed mobility network from 1 March to 30 April 2020, and then using a hypothetical post-reopening mobility network from 1 May to 30 May 2020, corresponding to the projected impact of that reopening strategy. Because we only have observed mobility data from 1 March to 2 May 2020, we impute the missing mobility data up to 30 May 2020 by looping mobility data from the first week of March, as in the above analysis on the effect of past reductions in mobility. Let T represent the last hour for which we have observed mobility data (2 May 2020, 23:00). To simplify the notation, we define
where, as above, f(t) = t mod 168. This function leaves t unchanged if there is observed mobility data at time t, and otherwise maps t to the corresponding hour in the first week of our simulation.
To simulate a reopening strategy that uniformly reduced visits to an γ fraction of their original level, where γ ∈ [0, 1], we constructed the visit matrix
where τ represents the first hour of reopening (1 May 2020, 00:00). In other words, we use the actual observed mobility network up until hour τ, and then subsequently simulate an γ fraction of full mobility levels.
To simulate the reduced occupancy strategy, we first estimated the maximum occupancy Mpj of each POI pj as the maximum number of visits that it ever had in one hour, across all of 1 March–2 May 2020. As in previous sections, let \({w}_{ij}^{(t)}\) represent the ijth entry in the observed visit matrix W(t), that is, the number of people from CBG ci who visited pj in hour t, and let \({V}_{{p}_{j}}^{(t)}\) represent the total number of visitors to pj in that hour, that is, \({\sum }_{i}{w}_{ij}^{(t)}\). We simulated capping at a β fraction of maximum occupancy, where β ∈ [0, 1], by constructing the visit matrix \({\tilde{W}}_{\beta }^{(t)}\) for which the ijth entry is
This corresponds to the following procedure: for each POI pj and time t, we first check whether t < τ (reopening has not started) or whether \({V}_{{p}_{j}}^{(t)}\le \beta {M}_{{p}_{j}}\) (the total number of visits to pj at time t is below the allowed maximum \(\beta {M}_{{p}_{j}}\)). If so, we leave \({w}_{ij}^{h(t)}\) unchanged. Otherwise, we compute the scaling factor \(\frac{\beta {M}_{{p}_{j}}}{{V}_{{p}_{j}}^{(t)}}\) that would reduce the total visits to pj at time t down to the allowed maximum \(\beta {M}_{{p}_{j}}\), and then scale down all visits from each CBG ci to pj proportionately. For both reopening strategies, we calculate the predicted increase in cumulative incidence at the end of the reopening period (30 May 2020) compared to the start of the reopening period (1 May 2020).
Relative risk of reopening different categories of POIs
Associated with Fig. 2d, Extended Data Fig. 5 and Supplementary Figs. 11, 15–24. We study separately the reopening of the 20 POI categories with the most visits in SafeGraph data. In this analysis, we follow previous studies28 and do not study four categories: ‘child day-care services’ and ‘elementary and secondary schools’ (because children under 13 are not well-tracked by SafeGraph); ‘drinking places (alcoholic beverages)’ (because SafeGraph seems to undercount these locations28) and ‘nature parks and other similar institutions’ (because boundaries and therefore areas are not well-defined by SafeGraph). We also exclude ‘general medical and surgical hospitals’ and ‘other airport operations’ (because hospitals and air travel both involve many additional risk factors that our model is not designed to capture). We do not filter out these POIs during model fitting (that is, we assume that people visit these POIs, and that transmissions occur there) because including them still increases the proportion of overall mobility that our dataset captures; we simply do not analyse these categories, because we wish to be conservative and only focus on categories for which we are most confident that we are capturing transmission faithfully.
This reopening analysis is similar to the previous experiments on reducing maximum occupancy versus uniform reopening (see ‘Reducing mobility by capping maximum occupancy’). As above, we set the reopening time τ to 1 May 2020, 00:00. To simulate reopening a POI category, we take the set of POIs in that category, \({\mathscr{V}}\), and set their activity levels after reopening to that of the first week of March. For POIs not in the category \({\mathscr{V}}\), we keep their activity levels after reopening the same, that is, we simply repeat the activity levels of the last week of our data (27 April–2 May 2020): This gives us the visit matrix \({\tilde{W}}^{(t)}\) with entries
As in the above reopening analysis, f(t) maps t to the corresponding hour in the first week of March, and g(t) maps t to the corresponding hour in the last week of our data. For each category, we calculate the predicted difference between (1) the cumulative fraction of people who have been infected by the end of the reopening period (30 May 2020) and (2) the cumulative fraction of people infected by 30 May 2020 had we not reopened the POI category (that is, if we simply repeated the activity levels of the last week of our data). This seeks to model the increase in cumulative incidence by the end of May from reopening the POI category. In Extended Data Fig. 5 and Supplementary Figs. 15–24, the bottom right panel shows the predicted increase for the category as a whole, and the bottom left panel shows the predicted increase per POI (that is, the total increase divided by the number of POIs in the category).
Per-capita mobility
Associated with Fig. 3d, Extended Data Fig. 6 and Supplementary Fig. 3. Each group of CBGs (for example, the bottom income decile) comprises a set \({\mathscr{U}}\) of CBGs that fit the corresponding criteria. In Fig. 3d and Extended Data Fig. 6, we show the daily per-capita mobilities of different pairs of groups (broken down by income and by race). To measure the per-capita mobility of a group on day d, we take the total number of visits made from those CBGs to any POI, \({\sum }_{{c}_{i}\in {\mathscr{U}}}{\sum }_{{p}_{j}\in {\mathscr{P}}}{\sum }_{t=24d}^{24d+23}{w}_{ij}^{(t)}\), and divide it by the total population of the CBGs in the group, \({\sum }_{{c}_{i}\in {\mathscr{U}}}{N}_{{c}_{i}}\). In Supplementary Fig. 3, we show the total number of visits made by each group to each POI category, accumulated over the entire data period (1 March–2 May 2020) and then divided by the total population of the group.
Average predicted transmission rate of a POI category
Associated with Fig. 3e and Extended Data Tables 3, 4. We compute the predicted average hourly transmission rate experienced by a group of CBGs \({\mathscr{U}}\) at a POI category \({\mathscr{V}}\) as
where, as above, \({\beta }_{{p}_{j}}^{(t)}\) is the transmission rate at POI pj in hour t (equation (8)), \({w}_{ij}^{(t)}\) is the number of visitors from CBG ci at POI pj in hour t, and T is the last hour in our simulation. This represents the expected transmission rate encountered during a visit by someone from a CBG in group \({\mathscr{U}}\) to a POI in category \({\mathscr{V}}\).
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this paper.
Data availability
Inferred hourly mobility networks as well as the estimated models are available at the project website (http://covid-mobility.stanford.edu). Raw census data (https://www.census.gov/programs-surveys/acs), case and death counts from The New York Times (https://github.com/nytimes/covid-19-data) and Google mobility data (https://www.google.com/covid19/mobility/) are also publicly available. Mobile phone mobility data are freely available to researchers, non-profit organizations and governments through the SafeGraph COVID-19 Data Consortium (https://www.safegraph.com/covid-19-data-consortium).
Code availability
Code is publicly available at the project website (http://covid-mobility.stanford.edu).
References
Buckee, C. O. et al. Aggregated mobility data could help fight COVID-19. Science 368, 145–146 (2020).
Wilson, C. These graphs show how COVID-19 is ravaging New York City’s low-income neighborhoods. Time (15 April 2020).
Garg, S. et al. Hospitalization rates and characteristics of patients hospitalized with laboratory-confirmed coronavirus disease 2019 — COVID-NET, 14 states, March 1—30, 2020. MMWR Morb. Mortal. Wkly Rep. 69, 458–464 (2020).
Reeves, R. V. & Rothwell, J. Class and COVID: How the Less Affluent face Double Risks. https://www.brookings.edu/blog/up-front/2020/03/27/class-and-covid-how-the-less-affluent-face-double-risks/ (The Brookings Institution, 2020).
Pareek, M. et al. Ethnicity and COVID-19: an urgent public health research priority. Lancet 395, 1421–1422 (2020).
Dorn, A. V., Cooney, R. E. & Sabin, M. L. COVID-19 exacerbating inequalities in the US. Lancet 395, 1243–1244 (2020).
Yancy, C. W. COVID-19 and African Americans. J. Am. Med. Assoc. 323, 1891–1892 (2020).
Chowkwanyun, M. & Reed, A. L. Jr. Racial Health Disparities and Covid-19 — caution and context. N. Engl. J. Med. 383, 201–203 (2020).
Flaxman, S. et al. Estimating the effects of non-pharmaceutical interventions on COVID-19 in Europe. Nature 584, 257–261 (2020).
Rojas, R. & Delkic, M. As states reopen, governors balance existing risks with new ones. The New York Times (17 May 2020).
Endo, A., Abbott, S., Kucharski, A. J. & Funk, S. Estimating the overdispersion in COVID-19 transmission using outbreak sizes outside China. Wellcome Open Res. 5, 67 (2020).
Adam, D. C. et al. Clustering and superspreading potential of SARS-CoV-2 infections in Hong Kong. Nat. Med. https://doi.org/10.1038/s41591-020-1092-0 (2020).
Park, S. Y. et al. Coronavirus disease outbreak in call center, South Korea. Emerg. Infect. Dis. 26, 1666–1670 (2020).
Bi, Q. et al. Epidemiology and transmission of COVID-19 in 391 cases and 1286 of their close contacts in Shenzhen, China: a retrospective cohort study. Lancet Infect. Dis. 20, 911–919 (2020).
Chinazzi, M. et al. The effect of travel restrictions on the spread of the 2019 novel coronavirus (COVID-19) outbreak. Science 368, 395–400 (2020).
Jia, J. S. et al. Population flow drives spatio-temporal distribution of COVID-19 in China. Nature 582, 389–394 (2020).
Pei, S., Kandula, S. & Shaman, J. Differential effects of intervention timing on COVID-19 spread in the United States. Preprint at https://doi.org/10.1101/2020.05.15.20103655 (2020).
Lai, S. et al. Effect of non-pharmaceutical interventions to contain COVID-19 in China. Nature 585, 410–413 (2020).
Badr, H. S. et al. Association between mobility patterns and COVID-19 transmission in the USA: a mathematical modelling study. Lancet Infect. Dis. 20, 1247–1254 (2020).
Li, R. et al. Substantial undocumented infection facilitates the rapid dissemination of novel coronavirus (SARS-CoV-2). Science 368, 489–493 (2020).
Pei, S. & Shaman, J. Initial simulation of SARS-CoV2 spread and intervention effects in the continental US. Preprint at https://doi.org/10.1101/2020.03.21.20040303 (2020).
Aleta, A. et al. Modelling the impact of testing, contact tracing and household quarantine on second waves of COVID-19. Nat. Hum. Behav. 4, 964–971 (2020).
Duque, D. et al. Timing social distancing to avert unmanageable COVID-19 hospital surges. Proc. Natl Acad. Sci. USA 177, 19873–19878 (2020).
Block, P. et al. Social network-based distancing strategies to flatten the COVID-19 curve in a post-lockdown world. Nat. Hum. Behav. 4, 588–596 (2020).
Karin, O. et al. Adaptive cyclic exit strategies from lockdown to suppress COVID-19 and allow economic activity. Preprint at https://doi.org/10.1101/2020.04.04.20053579 (2020).
Gao, S. et al. Mapping county-level mobility pattern changes in the United States in response to COVID-19. SIGSPATIAL Special 12, 16–26 (2020).
Klein, B. et al. Assessing Changes in Commuting and Individual Mobility in Major Metropolitan Areas in the United States during the COVID-19 Outbreak. https://www.networkscienceinstitute.org/publications/assessing-changes-in-commuting-and-individual-mobility-in-major-metropolitan-areas-in-the-united-states-during-the-covid-19-outbreak (2020).
Benzell, S. G., Collis, A. & Nicolaides, C. Rationing social contact during the COVID-19 pandemic: transmission risk and social benefits of US locations. Proc. Natl Acad. Sci. USA 117, 14642–14644 (2020).
Baicker, K. et al. Is it safer to visit a coffee shop or a gym? The New York Times (6 May 2020).
Hsiang, S. et al. The effect of large-scale anti-contagion policies on the COVID-19 pandemic. Nature 584, 262–267 (2020).
Deming, W. E. & Stephan, F. F. On a least squares adjustment of a sampled frequency table when the expected marginal totals are known. Ann. Math. Stat. 11, 427–444 (1940).
The New York Times. Coronavirus (COVID-19) Data in the United States. https://github.com/nytimes/covid-19-data (2020).
Tian, H. et al. An investigation of transmission control measures during the first 50 days of the COVID-19 epidemic in China. Science 368, 638–642 (2020).
Watts, D. J., Muhamad, R., Medina, D. C. & Dodds, P. S. Multiscale, resurgent epidemics in a hierarchical metapopulation model. Proc. Natl Acad. Sci. USA 102, 11157–11162 (2005).
California Department of Public Health. COVID-19 Industry Guidance: Retail. https://covid19.ca.gov/pdf/guidance-retail.pdf (2020).
Birge, J., Candogan, O. & Feng, Y. Controlling epidemic spread: reducing economic losses with targeted closures. BFI Working Paper No. 2020-57 (8 May 2020).
Webb Hooper, M., Nápoles, A. M. & Pérez-Stable, E. J. COVID-19 and racial/ethnic disparities. J. Am. Med. Assoc. 323, 2466–2467 (2020).
Laurencin, C. T. & McClinton, A. The COVID-19 pandemic: a call to action to identify and address racial and ethnic disparities. J. Racial Ethn. Health Disparities 7, 398–402 (2020).
SafeGraph. Places Schema. https://docs.safegraph.com/docs/places-schema (2020).
SafeGraph. Weekly Patterns. https://docs.safegraph.com/docs/weekly-patterns (2020).
SafeGraph. Using SafeGraph Polygons to Estimate Point-Of-Interest Square Footage. https://www.safegraph.com/blog/using-safegraph-polygons-to-estimate-point-of-interest-square-footage (2019).
SafeGraph. Guide to Points-of-Interest Data: POI Data FAQ. https://www.safegraph.com/points-of-interest-poi-data-guide (2020).
SafeGraph. Social Distancing Metrics. https://docs.safegraph.com/docs/social-distancing-metrics (2020).
Athey, S. et al. Estimating heterogeneous consumer preferences for restaurants and travel time using mobile location data. In AEA Papers and Proceedings Vol. 108, 64–67 (2018).
Chen, M. K. & Rohla, R. The effect of partisanship and political advertising on close family ties. Science 360, 1020–1024 (2018).
Farboodi, M., Jarosch, G. & Shimer, R. Internal and external effects of social distancing in a pandemic. NBER Working Paper 27059 https://doi.org/10.3386/w27059 (National Bureau Of Economic Research, 2020).
Killeen, B. D. et al. A county-level dataset for informing the United States’ response to COVID-19. Preprint at https://arxiv.org/abs/2004.00756 (2020).
Allcott, H. et al. Polarization and public health: partisan differences in social distancing during the coronavirus pandemic. NBER Working Paper 26946 https://doi.org/10.3386/w26946 (National Bureau Of Economic Research, 2020).
Google. COVID-19 Community Mobility Reports. https://google.com/covid19/mobility/ (2020).
Athey, S. et al. Experienced Segregation. Working Paper 3785 https://gsb.stanford.edu/faculty-research/working-papers/experienced-segregation (2019).
Squire, R. F. What about Bias in the SafeGraph Dataset? https://safegraph.com/blog/what-about-bias-in-the-safegraph-dataset (2019).
US Census Bureau. American Community Survey (ACS) https://census.gov/programs-surveys/acs (published 30 January 2020).
Bishop, Y. M., Fienberg, S. E. & Holland, P. W. Discrete Multivariate Analysis: Theory and Practice (MIT Press, 1975).
Birkin, M. & Clarke, M. Synthesis—a synthetic spatial information system for urban and regional analysis: methods and examples. Environ. Plann. A 20, 1645–1671 (1988).
Wong, D. W. The reliability of using the iterative proportional fitting procedure. Prof. Geogr. 44, 340–348 (1992).
Simpson, L. & Tranmer, M. Combining sample and census data in small area estimates: iterative proportional fitting with standard software. Prof. Geogr. 57, 222–234 (2005).
Hu, H., Nigmatulina, K. & Eckhoff, P. The scaling of contact rates with population density for the infectious disease models. Math. Biosci. 244, 125–134 (2013).
Kucharski, A. J. et al. Early dynamics of transmission and control of COVID-19: a mathematical modelling study. Lancet Infect. Dis. 20, 553–558 (2020).
Park, M., Cook, A. R., Lim, J. T., Sun, Y. & Dickens, B. L. A systematic review of COVID-19 epidemiology based on current evidence. J. Clin. Med. 9, 967 (2020).
Curmei, M. et al. Estimating household transmission of SARS-CoV-2. Preprint at https://doi.org/10.1101/2020.05.23.20111559 (2020).
Li, W. et al. The characteristics of household transmission of COVID-19. Clin. Infect. Dis. 71, 1943–1946 (2020).
Gudbjartsson, D. F. et al. Spread of SARS-CoV-2 in the Icelandic population. N. Engl. J. Med. 382, 2302–2315 (2020).
Carey, B. & Glanz, J. Hidden outbreaks spread through U.S. cities far earlier than Americans knew, estimates say. The New York Times (23 April 2020).
Bommer, C. & Vollmer, S. Average Detection Rate of SARS-CoV-2 Infections is Estimated Around Nine Percent. https://www.uni-goettingen.de/en/606540.html (2020).
Javan, E., Fox, S. J. & Meyers, L. A. The unseen and pervasive threat of COVID-19 throughout the US. Preprint at https://doi.org/10.1101/2020.04.06.20053561 (2020).
Perkins, T. A. et al. Estimating unobserved SARS-CoV-2 infections in the United States. Proc. Natl Acad. Sci. USA 117, 22597–22602 (2020).
King, A. A., Domenech de Cellès, M., Magpantay, F. M. & Rohani, P. Avoidable errors in the modelling of outbreaks of emerging pathogens, with special reference to Ebola. Proc. R. Soc. Lond. B 282, 20150347 (2015).
Acknowledgements
We thank Y.-Y. Ahn, R. Appel, C. Chen, J. Feng, N. Fishman, S. Fullerton, T. Hashimoto, M. Kraemer, P. Liang, M. Lipsitch, K. Loh, D. Ouyang, R. Rosenfeld, S. Sagawa, J. Steinhardt, R. Tibshirani, J. Ugander, D. Vrabac, seminar participants and Stanford’s Computer Science and Civil Society for support and comments; and N. Singh, R. F. Squire, J. Williams-Holt, J. Wolf, R. Yang and others at SafeGraph for mobile phone mobility data and feedback. This research was supported by US National Science Foundation under OAC-1835598 (CINES), OAC-1934578 (HDR), CCF-1918940 (Expeditions), IIS-2030477 (RAPID), Stanford Data Science Initiative, Wu Tsai Neurosciences Institute and Chan Zuckerberg Biohub. S.C. was supported by an NSF Fellowship. E.P. was supported by a Hertz Fellowship. P.W.K. was supported by the Facebook Fellowship Program. J.L. is a Chan Zuckerberg Biohub investigator.
Author information
Authors and Affiliations
Contributions
S.C., E.P. and P.W.K. performed computational analysis. All authors jointly analysed the results and wrote the paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Peer review information Nature thanks Moritz Kraemer, Marc Lipsitch and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data figures and tables
Extended Data Fig. 1 Mobility-based epidemiological model and its predictions.
a–c, Predicted (blue) and true (orange) daily case counts for our model (a), which uses hourly mobility networks, an SEIR model (b) that uses hourly aggregated mobility data and a baseline SEIR model (c) that does not use mobility data (see Methods, ‘Aggregate mobility and no-mobility baseline models’ for details). Incorporating mobility information improves out-of-sample fit and using a mobility network, instead of an aggregate measure of mobility, further improves fit: on average across metro areas, the out-of-sample error (r.m.s.e.) of our best-fit network model was only 58% that of the best-fit aggregate mobility model. All three models are calibrated on observed case counts before 15 April 2020 (vertical black line). The grey crosses represent the daily reported cases; as they tend to have great variability, we also show the smoothed weekly average (orange line). Shaded regions denote the 2.5th and 97.5th percentiles across sampled parameters and stochastic realizations.
Extended Data Fig. 2 Distribution of POI infections over time.
We selected the POI categories that our models predicted to contribute the most to infections, and plotted the predicted proportion of POI infections that each category accounted for over time. Our model predicts time-dependent variation of where transmissions may have occurred. For example, full-service restaurants (blue) and fitness centres (brown) contributed less to predicted infections over time, probably due to lockdown orders closing these POIs, whereas grocery stores remained steady or even grew in their predicted contribution, probably because they remained open as essential businesses. Hotels and motels (yellow) also feature in these plots; most notably, the model predicts a peak in their contributed infections in Miami around mid-March, which aligns with college spring break, as Miami is a popular vacation spot for students. The proportions are stacked in these plots, and the y axes are truncated at 0.7 because every plot would only show ‘other’ from 0.7 to 1.0.
Extended Data Fig. 3 Trade-off between new infections and visits lost from reopening.
We simulate reduced maximum occupancy reopening starting on 1 May 2020 and run the simulation until the end of the month. Each dot represents the level of occupancy reduction: for example, capping visits at 50% of the maximum occupancy. The y coordinate represents the predicted number of new infections incurred after reopening (per 100,000 population) and the x coordinate represents the fraction of visits lost from partial reopening compared to full reopening. Shaded regions denote the 2.5th and 97.5th percentiles across parameter sets and stochastic realizations. In four metro areas, the predicted cost of new infections from reopening is roughly similar for lower-income CBGs and the overall population, but in five metro areas, the lower-income CBGs incur more predicted infections from reopening. Notably, New York City (NYC) is the only metro area in which this trend is reversed; this is because the model predicts that such a high fraction—65% (95% confidence interval, 62–68%)—of lower-income CBGs in NYC had been infected before reopening that after reopening, only a minority of the lower-income population is still susceptible (in comparison, the second highest fraction infected before reopening was 31% (95% confidence interval, 28–35%) for Philadelphia, and the rest ranged from 1 to 14%).
Extended Data Fig. 4 Reduced maximum occupancy versus uniform reduction reopening.
In comparison to partially reopening by uniformly reducing visits, the reduced maximum occupancy strategy—which disproportionately targets POIs during their most risky high-density periods—always results in a smaller predicted increase in infections for the same number of visits. The y axis plots the relative difference between the predicted increase in cumulative infections (from 1 May to 30 May 2020) under the reduced occupancy strategy compared to the uniform reduction strategy. The shaded regions denote the 2.5th and 97.5th percentiles across the sampled parameters and stochastic realizations.
Extended Data Fig. 5 POI attributes in all 10 metro areas combined.
a, b, The POIs from all metro areas are pooled and the quantities from the mobility data are shown. a, The distribution of dwell time. b, The average number of hourly visitors divided by the area of the POI in square feet. Each point represents one POI; boxes depict the interquartile range across POIs; data points outside the range are shown as individual dots. c, d, The data are pooled across model realizations from all metro areas and model predictions are shown for the increase in infections (per 100,000 population) because of reopening a POI category. c, Data per POI. d, Data for the category as a whole. Each point represents a model realization; boxes depict the interquartile range across realizations; data points outside the range are shown as individual dots. Across MSAs, we model 552,758 POIs in total, and we sample 97 parameters and 30 stochastic realizations (n = 2,910); see Supplementary Table 6 for the number of sets per metro area. Colours are used to distinguish the different POI categories, but do not have any additional meaning.
Extended Data Fig. 6 Daily per-capita mobility over time.
a, b, We compare mobility in the lowest and highest deciles of CBGs based on median household income (a) and the percentage of white residents (b). See Methods, ‘Analysis details’ for details.
Supplementary information
Supplementary Information
The Supplementary Information contains four sections: Supplementary Methods, Supplementary Discussion, Supplementary Tables, and Supplementary Figures. The Supplementary Methods section describes (1) our comparison of SafeGraph mobility data to Google mobility data, where we find high correlation; (2) sensitivity analyses of the model (e.g., modifying CBG and POI transmission rates, fitting to deaths instead of cases) and tests of model identifiability, (3) a detailed description of how we estimated dynamic mobility networks from raw SafeGraph data using iterative proportional fitting. The Supplementary Discussion section covers (1) further discussion of the racial and socioeconomic disparities predicted by our model; (2) limitations of the model and mobility dataset. There are 6 Supplementary Tables, which provide more details about the SafeGraph data, the comparison to Google mobility data, and additional model results. There are 24 Supplementary Figures, which include additional results about predicted disparities, results from all sensitivity analyses and identifiability checks, and POI attributes and predicted reopening risks for every POI category and metro area.
Rights and permissions
About this article

Cite this article
Chang, S., Pierson, E., Koh, P.W. et al. Mobility network models of COVID-19 explain inequities and inform reopening. Nature 589, 82–87 (2021). https://doi.org/10.1038/s41586-020-2923-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41586-020-2923-3
This article is cited by
-
Medical education during the COVID-19 pandemic: a reflection on the JHUSOM experience
BMC Medical Education (2024)
-
Understanding post-pandemic spatiotemporal differences in the recovery of metro travel behavior among different groups by considering the built environment
Journal of Engineering and Applied Science (2024)
-
Association between vaccination rates and COVID-19 health outcomes in the United States: a population-level statistical analysis
BMC Public Health (2024)
-
Urban mobility and the experienced isolation of students
Nature Cities (2024)
-
Temporal dynamics of public transportation ridership in Seoul before, during, and after COVID-19 from urban resilience perspective
Scientific Reports (2024)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
