
Abstract
Screening mammography aims to identify breast cancer at earlier stages of the disease, when treatment can be more successful1. Despite the existence of screening programmes worldwide, the interpretation of mammograms is affected by high rates of false positives and false negatives2. Here we present an artificial intelligence (AI) system that is capable of surpassing human experts in breast cancer prediction. To assess its performance in the clinical setting, we curated a large representative dataset from the UK and a large enriched dataset from the USA. We show an absolute reduction of 5.7% and 1.2% (USA and UK) in false positives and 9.4% and 2.7% in false negatives. We provide evidence of the ability of the system to generalize from the UK to the USA. In an independent study of six radiologists, the AI system outperformed all of the human readers: the area under the receiver operating characteristic curve (AUC-ROC) for the AI system was greater than the AUC-ROC for the average radiologist by an absolute margin of 11.5%. We ran a simulation in which the AI system participated in the double-reading process that is used in the UK, and found that the AI system maintained non-inferior performance and reduced the workload of the second reader by 88%. This robust assessment of the AI system paves the way for clinical trials to improve the accuracy and efficiency of breast cancer screening.
This is a preview of subscription content, access via your institution
Access options
Access Nature and 54 other Nature Portfolio journals
Get Nature+, our best-value online-access subscription
$29.99 / 30 days
cancel any time
Subscribe to this journal
Receive 51 print issues and online access
$199.00 per year
only $3.90 per issue
Buy this article
- Purchase on Springer Link
- Instant access to full article PDF
Prices may be subject to local taxes which are calculated during checkout




Similar content being viewed by others

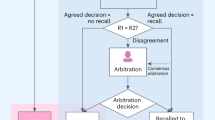
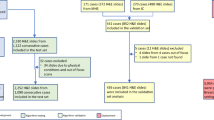
Data availability
The dataset from Northwestern Medicine was used under license for the current study, and is not publicly available. Applications for access to the OPTIMAM database can be made at https://medphys.royalsurrey.nhs.uk/omidb/getting-access/.
Code availability
The code used for training the models has a large number of dependencies on internal tooling, infrastructure and hardware, and its release is therefore not feasible. However, all experiments and implementation details are described in sufficient detail in the Supplementary Methods section to support replication with non-proprietary libraries. Several major components of our work are available in open source repositories: Tensorflow (https://www.tensorflow.org); Tensorflow Object Detection API (https://github.com/tensorflow/models/tree/master/research/object_detection).
References
Tabár, L. et al. Swedish two-county trial: impact of mammographic screening on breast cancer mortality during 3 decades. Radiology 260, 658–663 (2011).
Lehman, C. D. et al. National performance benchmarks for modern screening digital mammography: update from the Breast Cancer Surveillance Consortium. Radiology 283, 49–58 (2017).
Bray, F. et al. Global cancer statistics 2018: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J. Clin. 68, 394–424 (2018).
The Canadian Task Force on Preventive Health Care. Recommendations on screening for breast cancer in average-risk women aged 40–74 years. CMAJ 183, 1991–2001 (2011).
Marmot, M. G. et al. The benefits and harms of breast cancer screening: an independent review. Br. J. Cancer 108, 2205–2240 (2013).
Lee, C. H. et al. Breast cancer screening with imaging: recommendations from the Society of Breast Imaging and the ACR on the use of mammography, breast MRI, breast ultrasound, and other technologies for the detection of clinically occult breast cancer. J. Am. Coll. Radiol. 7, 18–27 (2010).
Oeffinger, K. C. et al. Breast cancer screening for women at average risk: 2015 guideline update from the American Cancer Society. J. Am. Med. Assoc. 314, 1599–1614 (2015).
Siu, A. L. Screening for breast cancer: U.S. Preventive Services Task Force recommendation statement. Ann. Intern. Med. 164, 279–296 (2016).
Center for Devices & Radiological Health. MQSA National Statistics (US Food and Drug Administration, 2019; accessed 16 July 2019); http://www.fda.gov/radiation-emitting-products/mqsa-insights/mqsa-national-statistics
Cancer Research UK. Breast Screening (CRUK, 2017; accessed 26 July 2019); https://www.cancerresearchuk.org/about-cancer/breast-cancer/screening/breast-screening
Elmore, J. G. et al. Variability in interpretive performance at screening mammography and radiologists’ characteristics associated with accuracy. Radiology 253, 641–651 (2009).
Lehman, C. D. et al. Diagnostic accuracy of digital screening mammography with and without computer-aided detection. JAMA Intern. Med. 175, 1828–1837 (2015).
Tosteson, A. N. A. et al. Consequences of false-positive screening mammograms. JAMA Intern. Med. 174, 954–961 (2014).
Houssami, N. & Hunter, K. The epidemiology, radiology and biological characteristics of interval breast cancers in population mammography screening. NPJ Breast Cancer 3, 12 (2017).
Gulshan, V. et al. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. J. Am. Med. Assoc. 316, 2402–2410 (2016).
Esteva, A. et al. Dermatologist-level classification of skin cancer with deep neural networks. Nature 542, 115–118 (2017).
De Fauw, J. et al. Clinically applicable deep learning for diagnosis and referral in retinal disease. Nat. Med. 24, 1342–1350 (2018).
Ardila, D. et al. End-to-end lung cancer screening with three-dimensional deep learning on low-dose chest computed tomography. Nat. Med. 25, 954–961 (2019).
Topol, E. J. High-performance medicine: the convergence of human and artificial intelligence. Nat. Med. 25, 44–56 (2019).
Moran, S. & Warren-Forward, H. The Australian BreastScreen workforce: a snapshot. Radiographer 59, 26–30 (2012).
Wing, P. & Langelier, M. H. Workforce shortages in breast imaging: impact on mammography utilization. AJR Am. J. Roentgenol. 192, 370–378 (2009).
Rimmer, A. Radiologist shortage leaves patient care at risk, warns royal college. BMJ 359, j4683 (2017).
Nakajima, Y., Yamada, K., Imamura, K. & Kobayashi, K. Radiologist supply and workload: international comparison. Radiat. Med. 26, 455–465 (2008).
Rao, V. M. et al. How widely is computer-aided detection used in screening and diagnostic mammography? J. Am. Coll. Radiol. 7, 802–805 (2010).
Gilbert, F. J. et al. Single reading with computer-aided detection for screening mammography. N. Engl. J. Med. 359, 1675–1684 (2008).
Giger, M. L., Chan, H.-P. & Boone, J. Anniversary paper: history and status of CAD and quantitative image analysis: the role of Medical Physics and AAPM. Med. Phys. 35, 5799–5820 (2008).
Fenton, J. J. et al. Influence of computer-aided detection on performance of screening mammography. N. Engl. J. Med. 356, 1399–1409 (2007).
Kohli, A. & Jha, S. Why CAD failed in mammography. J. Am. Coll. Radiol. 15, 535–537 (2018).
Rodriguez-Ruiz, A. et al. Stand-alone artificial intelligence for breast cancer detection in mammography: comparison with 101 radiologists. J. Natl. Cancer Inst. 111, 916–922 (2019).
Wu, N. et al. Deep neural networks improve radiologists’ performance in breast cancer screening. IEEE Trans. Med. Imaging https://doi.org/10.1109/TMI.2019.2945514 (2019).
Zech, J. R. et al. Variable generalization performance of a deep learning model to detect pneumonia in chest radiographs: a cross-sectional study. PLoS Med. 15, e1002683 (2018).
Becker, A. S. et al. Deep learning in mammography: diagnostic accuracy of a multipurpose image analysis software in the detection of breast cancer. Invest. Radiol. 52, 434–440 (2017).
Ribli, D., Horváth, A., Unger, Z., Pollner, P. & Csabai, I. Detecting and classifying lesions in mammograms with deep learning. Sci. Rep. 8, 4165 (2018).
Pisano, E. D. et al. Diagnostic performance of digital versus film mammography for breast-cancer screening. N. Engl. J. Med. 353, 1773–1783 (2005).
D’Orsi, C. J. et al. ACR BI-RADS Atlas: Breast Imaging Reporting and Data System (American College of Radiology, 2013).
Gallas, B. D. et al. Evaluating imaging and computer-aided detection and diagnosis devices at the FDA. Acad. Radiol. 19, 463–477 (2012).
Swensson, R. G. Unified measurement of observer performance in detecting and localizing target objects on images. Med. Phys. 23, 1709–1725 (1996).
Samulski, M. et al. Using computer-aided detection in mammography as a decision support. Eur. Radiol. 20, 2323–2330 (2010).
Brown, J., Bryan, S. & Warren, R. Mammography screening: an incremental cost effectiveness analysis of double versus single reading of mammograms. BMJ 312, 809–812 (1996).
Giordano, L. et al. Mammographic screening programmes in Europe: organization, coverage and participation. J. Med. Screen. 19, 72–82 (2012).
Sickles, E. A., Wolverton, D. E. & Dee, K. E. Performance parameters for screening and diagnostic mammography: specialist and general radiologists. Radiology 224, 861–869 (2002).
Ikeda, D. M., Birdwell, R. L., O’Shaughnessy, K. F., Sickles, E. A. & Brenner, R. J. Computer-aided detection output on 172 subtle findings on normal mammograms previously obtained in women with breast cancer detected at follow-up screening mammography. Radiology 230, 811–819 (2004).
Royal College of Radiologists. The Breast Imaging and Diagnostic Workforce in the United Kingdom (RCR, 2016; accessed 22 July 2019); https://www.rcr.ac.uk/publication/breast-imaging-and-diagnostic-workforce-united-kingdom
Pinsky, P. F. & Gallas, B. Enriched designs for assessing discriminatory performance—analysis of bias and variance. Stat. Med. 31, 501–515 (2012).
Mansournia, M. A. & Altman, D. G. Inverse probability weighting. BMJ 352, i189 (2016).
Ellis, I. O. et al. Pathology Reporting of Breast Disease in Surgical Excision Specimens Incorporating the Dataset for Histological Reporting of Breast Cancer, June 2016 (Royal College of Pathologists, accessed 22 July 2019); https://www.rcpath.org/resourceLibrary/g148-breastdataset-hires-jun16-pdf.html
Chakraborty, D. P. & Yoon, H.-J. Operating characteristics predicted by models for diagnostic tasks involving lesion localization. Med. Phys. 35, 435–445 (2008).
Ellis, R. L., Meade, A. A., Mathiason, M. A., Willison, K. M. & Logan-Young, W. Evaluation of computer-aided detection systems in the detection of small invasive breast carcinoma. Radiology 245, 88–94 (2007).
US Food and Drug Administration. Evaluation of Automatic Class III Designation for OsteoDetect (FDA, 2018; accessed 2 October 2019); https://www.accessdata.fda.gov/cdrh_docs/reviews/DEN180005.pdf
Hanley, J. A. & McNeil, B. J. The meaning and use of the area under a receiver operating characteristic (ROC) curve. Radiology 143, 29–36 (1982).
DeLong, E. R., DeLong, D. M. & Clarke-Pearson, D. L. Comparing the areas under two or more correlated receiver operating characteristic curves: a nonparametric approach. Biometrics 44, 837–845 (1988).
Gengsheng Qin, & Hotilovac, L. Comparison of non-parametric confidence intervals for the area under the ROC curve of a continuous-scale diagnostic test. Stat. Methods Med. Res. 17, 207–221 (2008).
Obuchowski, N. A. On the comparison of correlated proportions for clustered data. Stat. Med. 17, 1495–1507 (1998).
Yang, Z., Sun, X. & Hardin, J. W. A note on the tests for clustered matched-pair binary data. Biom. J. 52, 638–652 (2010).
Fagerland, M. W., Lydersen, S. & Laake, P. Recommended tests and confidence intervals for paired binomial proportions. Stat. Med. 33, 2850–2875 (2014).
Liu, J.-P., Hsueh, H.-M., Hsieh, E. & Chen, J. J. Tests for equivalence or non-inferiority for paired binary data. Stat. Med. 21, 231–245 (2002).
Efron, B. & Tibshirani, R. J. An Introduction to the Bootstrap (Springer, 1993).
Chihara, L. M., Hesterberg, T. C. & Dobrow, R. P. Mathematical Statistics with Resampling and R & Probability with Applications and R Set (Wiley, 2014).
Gur, D., Bandos, A. I. & Rockette, H. E. Comparing areas under receiver operating characteristic curves: potential impact of the “last” experimentally measured operating point. Radiology 247, 12–15 (2008).
Metz, C. E. & Pan, X. “Proper” binormal ROC curves: theory and maximum-likelihood estimation. J. Math. Psychol. 43, 1–33 (1999).
Chakraborty, D. P. Observer Performance Methods for Diagnostic Imaging: Foundations, Modeling, and Applications with R-Based Examples (CRC, 2017).
Obuchowski, N. A. & Rockette, H. E. Hypothesis testing of diagnostic accuracy for multiple readers and multiple tests an anova approach with dependent observations. Commun. Stat. Simul. Comput. 24, 285–308 (1995).
Hillis, S. L. A comparison of denominator degrees of freedom methods for multiple observer ROC analysis. Stat. Med. 26, 596–619 (2007).
Aickin, M. & Gensler, H. Adjusting for multiple testing when reporting research results: the Bonferroni vs Holm methods. Am. J. Public Health 86, 726–728 (1996).
NHS Digital. Breast Screening Programme (NHS, accessed 17 July 2019); https://digital.nhs.uk/data-and-information/publications/statistical/breast-screening-programme
Acknowledgements
We would like to acknowledge multiple contributors to this international project: Cancer Research UK, the OPTIMAM project team and staff at the Royal Surrey County Hospital who developed the UK mammography imaging database; S. Tymms and S. Steer for providing patient perspectives; R. Wilson for providing a clinical perspective; all members of the Etemadi Research Group for their efforts in data aggregation and de-identification; and members of the Northwestern Medicine leadership, without whom this work would not have been possible (M. Schumacher, C. Christensen, D. King and C. Hogue). We also thank everyone at NMIT for their efforts, including M. Lombardi, D. Fridi, P. Lendman, B. Slavicek, S. Xinos, B. Milfajt and others; V. Cornelius, who provided advice on statistical planning; R. West and T. Saensuksopa for assistance with data visualization; A. Eslami and O. Ronneberger for expertise in machine learning; H. Forbes and C. Zaleski for assistance with project management; J. Wong and F. Tan for coordinating labelling resources; R. Ahmed, R. Pilgrim, A. Phalen and M. Bawn for work on partnership formation; R. Eng, V. Dhir and R. Shah for data annotation and interpretation; C. Chen for critically reading the manuscript; D. Ardila for infrastructure development; C. Hughes and D. Moitinho de Almeida for early engineering work; and J. Yoshimi, X. Ji, W. Chen, T. Daly, H. Doan, E. Lindley and Q. Duong for development of the labelling infrastructure. A.D. and F.J.G. receive funding from the National Institute for Health Research (Senior Investigator award). Infrastructure support for this research was provided by the NIHR Imperial Biomedical Research Centre (BRC). The views expressed are those of the authors and not necessarily those of the NIHR or the Department of Health and Social Care.
Author information
Authors and Affiliations
Contributions
A.K., A.D., D.H., D.K., H.M., G.C.C., J.D.F., J.R.L., K.C.Y., L.P., M.H.-B., M. Sieniek, M. Suleyman, R.S., S.M.M., S.S. and T.B. contributed to the conception of the study; A.K., B.R.-P., C.J.K., D.H., D.T., F.J.G., J.D.F., J.R.L., K.C.Y., L.P., M.H.-B., M.C., M.E., M. Sieniek, M. Suleyman, N.A., R.S., S.J., S.M.M., S.S., T.B. and V.G. contributed to study design; D.M., D.T., F.G.-V., G.C.C., H.M., J.D.F., J.G., K.C.Y., L.P., M.H.-B., M.C., M.E., M. Sieniek, S.M.M., S.S. and V.G. contributed to acquisition of the data; A.K., A.D., B.R.-P., C.J.K., F.J.G., H.A., J.D.F., J.G., J.J.R., M. Suleyman, N.A., R.S., S.J., S.M.M., S.S. and V.G. contributed to analysis and interpretation of the data; A.K., C.J.K., D.T., F.J.G., J.D.F., J.G., J.J.R., M. Sieniek, N.A., R.S., S.J., S.M.M., S.S. and V.G. contributed to drafting and revising the manuscript.
Corresponding authors
Ethics declarations
Competing interests
This study was funded by Google LLC and/or a subsidiary thereof (‘Google’). S.M.M., M. Sieniek, V.G., J.G., N.A., T.B., M.C., G.C.C., D.H., S.J., A.K., C.J.K., D.K., J.R.L., H.M., B.R.-P., L.P., M. Suleyman, D.T., J.D.F. and S.S. are employees of Google and own stock as part of the standard compensation package. J.J.R., R.S., F.J.G. and A.D. are paid consultants of Google. M.E., F.G.-V., D.M., K.C.Y. and M.H.-B received funding from Google to support the research collaboration.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data figures and tables
Extended Data Fig. 1 Unweighted evaluation of breast cancer prediction on the US test set.
In contrast to in Fig. 2b, the sensitivity and specificity were computed without the use of inverse probability weights to account for the spectrum enrichment of the study population. Because hard negatives are overrepresented, the specificity of both the AI system and the human readers is reduced. The unweighted human sensitivity and specificity are 48.10% (n = 553) and 69.65% (n = 2,185), respectively.
Extended Data Fig. 2 Performance of the AI system in breast cancer prediction compared to six independent readers, with a 12-month follow-up interval for cancer-positive status.
Whereas the mean reader AUC was 0.750 (s.d. 0.049), the AI system achieved an AUC of 0.871 (95% CI 0.785, 0.919). The AI system exceeded human performance by a significant margin (ΔAUC = +0.121, 95% CI 0.070, 0.173; P = 0.0018 by two-sided ORH method). In this analysis, there were 56 positives of 408 total cases; see Extended Data Table 3. Note that this sample of cases was enriched for patients who had received a negative biopsy result (n = 119), making it a more challenging population for screening. As these external readers were not gatekeepers for follow-up and eventual cancer diagnosis, there was no bias in favour of reader performance at this shorter time horizon. See Fig. 3a for a comparison with a time interval that was chosen to encompass a subsequent screening exam.
Extended Data Fig. 3 Localization (mLROC) analysis.
Similar to Extended Data Fig. 2, but true positives require localization of a malignancy in any of the four mammogram views (see Methods section ‘Localization analysis’). Here, the cancer interval was 12 months (n = 53 positives of 405 cases; see Extended Data Table 3). The dotted line indicates a false-positive rate of 10%, which was used as the right-hand boundary for the pAUC calculation. The mean reader pAUC was 0.029 (s.d. 0.005), whereas that of the AI system was 0.048 (95% CI 0.035, 0.061). The AI system exceeded human performance by a significant margin (ΔpAUC = +0.0192, 95% CI 0.0086, 0.0298; P = 0.0004 by two-sided ORH method).
Extended Data Fig. 4 Evidence for the gatekeeper effect in retrospective datasets.
a, b, Graphs show the change in observed reader sensitivity in the UK (a) and the USA (b) as the cancer follow-up interval is extended. At short intervals, measured reader sensitivity is extremely high, owing to the fact that biopsies are only triggered based on radiological suspicion. As the time interval is extended, the task becomes more difficult and measured sensitivity declines. Part of this decline stems from the development of new cancers that were impossible to detect at the initial screening. However, steeper drops occur when the follow-up window encompasses the screening interval (36 months in the UK; 12 and 24 months in the USA). This is suggestive of what happens to reader metrics when gatekeeper bias is mitigated by another screening examination. In both graphs, the number of positives grows as the follow-up interval is extended. In the UK dataset (a), it increases from n = 259 within 3 months to n = 402 within 39 months. In the US dataset (b), it increases from n = 221 within n = 3 months to 553 within 39 months.
Extended Data Fig. 5 Quantitative evaluation of reader and AI system performance with a 12-month follow-up interval for ground-truth cancer-positive status.
Because a 12-month follow-up interval is unlikely to encompass a subsequent screening exam in either country, reader–model comparisons on retrospective clinical data may be skewed by the gatekeeper effect (Extended Data Fig. 4). See Fig. 2 for comparison with longer time intervals. a, Performance of the AI system on UK data. This plot was derived from a total of 25,717 eligible examples, including 274 positives. The AI system achieved an AUC of 0.966 (95% CI 0.954, 0.977). b, Performance of the AI system on US data. This plot was derived from a total of 2,770 eligible examples, including 359 positives. The AI system achieved an AUC of 0.883 (95% CI 0.859, 0.903). c, Reader performance. When computing reader metrics, we excluded cases for which the reader recommended repeat mammography to address technical issues. In the US data, the performance of radiologists could only be assessed on the subset of cases for which a BI-RADS grade was available.
Supplementary information
Supplementary Information
Supplementary Methods describes development and training of the AI system in greater detail. Supplementary Tables 1-3 and Supplementary Figures 1-5 contain additional results, alternative analyses, and methodological diagrams.
Rights and permissions
About this article

Cite this article
McKinney, S.M., Sieniek, M., Godbole, V. et al. International evaluation of an AI system for breast cancer screening. Nature 577, 89–94 (2020). https://doi.org/10.1038/s41586-019-1799-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41586-019-1799-6
This article is cited by
-
Screening mammography performance according to breast density: a comparison between radiologists versus standalone intelligence detection
Breast Cancer Research (2024)
-
AI-driven decision support systems and epistemic reliance: a qualitative study on obstetricians’ and midwives’ perspectives on integrating AI-driven CTG into clinical decision making
BMC Medical Ethics (2024)
-
Developing, purchasing, implementing and monitoring AI tools in radiology: practical considerations. A multi-society statement from the ACR, CAR, ESR, RANZCR & RSNA
Insights into Imaging (2024)
-
Deep learning in cancer genomics and histopathology
Genome Medicine (2024)
-
Heterogeneity and predictors of the effects of AI assistance on radiologists
Nature Medicine (2024)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
