
Abstract
Partners are often similar in terms of their physical and behavioural traits, such as their education, political affiliation and height. However, it is currently unclear what exactly causes this similarity—partner choice, partner influence increasing similarity over time or confounding factors such as shared environment or indirect assortment. Here, we applied Mendelian randomization to the data of 51,664 couples in the UK Biobank and investigated partner similarity in 118 traits. We found evidence of partner choice for 64 traits, 40 of which had larger phenotypic correlation than causal effect. This suggests that confounders contribute to trait similarity, among which household income, overall health rating and education accounted for 29.8, 14.1 and 11.6% of correlations between partners, respectively. Finally, mediation analysis revealed that most causal associations between different traits in the two partners are indirect. In summary, our results show the mechanisms through which indirect assortment increases the observed partner similarity.
Similar content being viewed by others
Main
People in partnerships are more similar to one another than randomly sampled pairs. Partners tend to be similar with respect to traits such as various anthropometric measures (body mass index (BMI) and height), socioeconomic factors, behaviours (religious views1 and social attitudes2), lifestyle (diet, smoking habits and hobbies) and even disease risk3,4,5,6,7,8,9,10.
Several different causes can explain this phenotypic similarity. First, people actively look for partners who are similar to them11,12, a phenomenon known as assortative mating (AM). Second, phenotypic similarity can reflect trait convergence during the partnership. In this case, traits become more similar over time because partners share a household or they influence each other’s behaviour13,14,15. Third, partner similarity may be caused by confounders at the time of partner choice (or later), such as shared sociocultural environment and geographical barriers16,17,18 (Fig. 1). Indirect assortment is a special case of the latter, where the confounder is the correlated trait which people use in direct partner selection19.

a, Illustrates a trait (given by the colour blue) which shows increased similarity between partners, either directly (through mate choice) or due to confounding factors such as shared geography, cultural or religious status or socioeconomic measures. Subsequently, this trait may also undergo postmating convergence, which could be due to direct causal influence from one partner on the other (that is, through imitation or influence) or due to confounding factors such as shared environment. b, Illustrates a trait which shows increased similarity among couples (given by the blue trait); however, this assortment is only observed because of a causal effect (α) that exists between another trait (shown in red) acting on the blue trait. For example, if direct assortment occurs under a trait such as BMI (that is, couples intentionally select partners of similar BMI as themselves), phenotypic correlation will also be observed at all traits which have a causal effect on BMI, such as blood pressure, fasting glucose and so on.
In couples, one person’s genome correlates with certain traits of their partner20, and one study found evidence of direct genetic associations between the genome of an individual and the phenotypes of their partner. This finding suggests that partner heritability of a trait cannot be explained by between-trait correlation alone21. Overall, causes and consequences of phenotypic assortment remain unresolved.
The causes of partner similarity matter for the fields such as behavioural science, population genetics and public health. For instance, high phenotypic similarity could imply genetic similarity. In this case, otherwise independent gene variants would become correlated and would ultimately increase genotype homozygocity22. Partner similarity also affects the studies of genetic associations; it increases the estimates of heritability23 and genetic correlation24, even in ACE (additive, common environment and unique environment) models25. Moreover, partner similarity can introduce collider bias in within-spouse association models26.
Similar to classical epidemiological studies where it is difficult to discern causal factors from confounders, mere phenotypic similarity within couples poses interpretational challenges. Mendelian randomization (MR) is a special case of instrumental variable (IV) analysis, whereby genetic markers are used as instruments to infer causal relationship. Because of the random allocation of genetic variants at birth, MR can infer causality between an exposure and an outcome27, avoiding reverse causality and confounding.
In this work, we used MR to study causality in couples where the exposure and outcome traits belong to different people (Fig. 2a). This concept is different from classical MR designs within individuals, such as the study of BMI causally affecting the risk for coronary artery disease28. The authors of ref. 29 used an approach similar to ours to study partner similarity in alcohol use. They showed that phenotypic correlation in couples does not increase with age and there was a difference between correlation and the direct causal effect29.

a, Illustrates the causal effect among couples with a single trait \((\alpha _{x_{\mathrm{i}} \to x_{\mathrm{p}}})\), where G represents genetic variant(s), X represents a single trait (in an index individual (Xi) and a partner (Xp)) and U represents confounding factors that are not associated with genetic variance owing to the random distribution of alleles at conception. Throughout the paper subscript i and p refer to the index and the partner, respectively. b, Directed acyclic graph illustrates the impact a confounder (trait Y) could have on the phenotypic correlation between partners for a given trait X (\(r_{x_{\mathrm{i}}x_{\mathrm{p}}}\)). Correlation due to confounding can be calculated as \(C = \alpha _{y \to x}^2 \times \alpha _y\). c, Represents the expanded causal network involving two traits and the various estimated causal paths from trait X of an index case (\(X_{\mathrm{i}}\)) to a phenotype Y in the partner (\(Y_{\mathrm{p}}\)) given by ω, γ and ρ. Cross-trait causal effects from \(X_{\mathrm{i}}\) to \(Y_{\mathrm{p}}\) (ω) can be summarized by three possible (non-independent) scenarios: (1) \(X_{\mathrm{i}}\) could exert a causal effect on \(X_{\mathrm{p}}\), followed by \(X_{\mathrm{p}}\) having a causal effect on \(Y_{\mathrm{p}}\) in the partner alone (γ); (2) the reverse could occur whereby \(X_{\mathrm{i}}\) has a causal effect on \(Y_{\mathrm{i}}\) in the index alone, followed by a causal effect of \(Y_{\mathrm{i}}\) case on \(Y_{\mathrm{p}}\) (ρ); or (3) there could be other mechanisms, either acting directly or through other unmeasured or unconsidered variables. To quantify ρ, we first estimated the causal effect of \(Y_{\mathrm{i}}\) on \(Y_{\mathrm{p}}\) in MVMR (not illustrated) to exclude any residual effect of X on phenotype Y from index to partner. These three scenarios could also act in some combination. Therefore, the ω estimate would capture the paths of γ, ρ and other mechanisms combined. In both a and c, cross-partner causal effects are given by blue arrows and same-person causal effects are given by green arrows.
Here, we applied MR to estimate the causal effects between partners for 118 traits. We studied direct effects on trait similarity, the impact of time couples have lived together and the role of confounders. Finally, we explored how cross-trait partner similarity emerges by dissecting them to direct and indirect parts.
Results
This study analysed data from the UK Biobank (UKBB) cohort, a prospective population-based study with over 500,000 adult participants. Among them, 51,664 couples were identified and selected according to a procedure described in the Methods and Supplementary Fig. 1. Starting from 1,278 available phenotypes, we selected those with between-partner (Pearson) correlation larger than 0.1 and having at least five valid instruments. Pearson and Spearman correlations led to very consistent estimates (Supplementary Fig. 2). These were further filtered (Methods and Supplementary Fig. 3) to yield 118 traits to analyse.
Effect of sex, age and time spent together
Among the 118 phenotypes tested, we identified 64 significant (P < 0.05/66) causal effects in partners after adjusting for the effective number of tests (66) (Supplementary Table 1). We also examined the Cochran’s heterogeneity Q statistic to identify traits with high heterogeneity and found no evidence of heterogeneity in the MR estimates (all P > 0.05/66). We assessed the 64 significant results for sex differences but did not identify any after adjusting for the effective number of tests among the remaining traits based on their pairwise correlation matrix (P < 0.05/29).
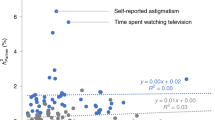
To identify if partner traits converge over time, we explored the impact of age and time spent together (proxied by the amount of time at the same address) among the 64 significant traits in both men and women separately and both sexes combined. Using linear regression of MR estimates versus the median of the five age and/or time spent together bins, we detected no significant results in the sex-combined results after adjustment for the number of effective tests (P < 0.05/66). We also examined the Pearson phenotypic correlation within the different bins and assessed for the presence of a trend using linear models (phenotypic correlation versus median bin) for all 118 phenotypes. Two traits showed a significant (P < 0.05/66) trend across the bins according to time spent together, namely body fat percentage (slope = −0.0018, P = 1.96 × 10−5) and forced expiratory volume in 1 second (slope = −0.0043, P = 2.98 × 10−4). In both cases, the correlation decreased as time spent together increased. We found two other traits that showed a significant trend across the bins by median age, namely previous smoking status (slope = 0.0011, P = 6.9 × 10−4) and aspirin use (slope = 0.0015, P = 1.8 × 10−4). In this case, for both phenotypes, the slope increased as median age increased (Fig. 3 and Supplementary Table 1). Using Spearman correlation yielded consistent results (all P < 0.05/66).

a–d, Scatterplots show the phenotypic correlation for four selected traits among couples within different bins. Couples were binned by time spent together (proxied by the time lived at the same household) (a,b) and median age (c,d). The four panels show correlations for four different traits: forced expiratory volume (a), body fat percentage (b), previous smoker (c) and aspirin use (d).
Causal effects versus raw phenotypic correlations
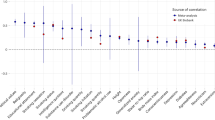
To better understand the nature of phenotypic assortment, we assessed whether there were any discrepancies between the causal effect estimates within couples (𝛼̂) and observational correlations (𝑟̂). Using MR, the causal effects between partners (within couples) were estimated for 118 phenotypes. These traits were selected based on their elevated correlation between partners and sufficient (more than five) valid IVs, making them suitable for MR analysis. Using a two-tailed Z test to gauge the statistical significance of the difference between the estimates (with test P-value denoted by Pdiff), we compared (standardized) causal MR effects to the raw phenotypic correlation among couples to identify any traits where the correlation was different than the MR estimate. After adjusting for the effective number of tested traits (P < 0.05/66), we identified 43 traits which showed different phenotypic correlation compared to MR estimate (Fig. 4a and Supplementary Table 1). Of these, three had a larger MR estimate compared to correlation (time spent watching television, comparative height size at age 10 and overall health rating), while the remaining 40 traits had a larger (absolute) correlation compared to MR estimate. These included place of birth, north coordinate (NC; \({\hat{r}} = 0.58\) versus \({\hat{\alpha}} = 0.33\), Pdiff = 2.47 × 10−18), systolic blood pressure (\({\hat{r}} = 0.16\) versus \({\hat{\alpha}} = 0.05\), Pdiff = 4.89 × 10−9), height (\({\hat{r}} = 0.25\) versus \({\hat{\alpha}} = 0.21\), Pdiff = 6.63 × 10−6), forced vital capacity (\({\hat{r}} = 0.25\) versus \({\hat{\alpha}} = 0.13\), Pdiff = 5.62 × 10−16), basal metabolic rate (\({\hat{r}} = 0.21\) versus \({\hat{\alpha}} = 0.16\), Pdiff = 9.78 × 10−7) and basophil count (\({\hat{r}} = 0.47\) versus \({\hat{\alpha}} = 0\), Pdiff = 1.76 × 10−38) (Fig. 4a).

a, Scatterplot shows the within-couple standardized MR estimates (\(\alpha _{x_{\mathrm{i}} \to x_{\mathrm{p}}}\)) versus the phenotypic correlation among couples \((r_{x_{\mathrm{i}}x_{\mathrm{p}}})\). The centre of the confidence interval (CI) is the estimate for the corresponding parameter and error bars represent 95% CIs. A two-tailed Z test was used to test for a significant difference between the estimates. After adjusting for the number of effective tests (P < 0.05/66), 43 significant differences were identified (shown in dark blue), where 3 traits showed larger MR estimates compared to correlation and 40 traits showed larger correlation compared to MR estimates. The identity line is shown in black. Labelled pairs are discussed in the main text. b, Scatterplot shows the difference in phenotypic correlation and MR estimate versus the Csum value (estimating the correlation induced by measured (uncorrelated) confounders) for each trait where the phenotypic correlation was greater than the MR estimate (number of traits = 39); error bars represent 95% CIs. The identity line is shown in black. FVC, forced vital capacity; NC, north coordinate; SBP, systolic blood pressure.
Significant differences could be indicative of the presence of confounders (either negative or positive) driving the observed phenotypic correlation. Thus, for traits where couple correlation was significantly different than MR causal estimates, we sought to identify potential confounders which may, in part, explain the discrepant estimates. For the three traits where correlation was less than the MR estimate, we searched for negative confounders (that is, negative \({\upalpha}_{y_{\mathrm{i}} \to y_{\mathrm{p}}}\)) but did not identify any.
Conversely, for traits where the correlation was greater than the MR estimate, we searched for positive confounders and found many potential positive confounders. Namely, the mean number of potential confounders from our set of 117 candidates was 22.56, with a maximum of 39; there was only one trait for which we did not identify any potential confounders (Supplementary Table 2). For instance, for systolic blood pressure, we identified 29 (correlated) potential confounders, which may explain the larger phenotypic correlation (\({\hat{r}} = 0.16\)) as compared to MR effect (\({\hat{\alpha}} = 0.05\)). These potential confounders included physical activity, BMI, lung fitness measures and overall health rating. For weight (\({\hat{r}} = 0.23\) versus \({\hat{\alpha}} = 0.19\)), we found 30 potential confounders, including anthropometric traits (such as leg, trunk and arm fat mass) and various behavioural traits which are reflective of exercise patterns, such as time spent watching television, walking pace and phone use, among many others (Supplementary Table 2). Many of the 40 traits with larger phenotypic correlation compared to MR estimates included blood cell counts and/or percentages (such as white blood cell (leucocyte) count, neutrophil count, monocyte count and percentage and reticulocyte percentage and count). The potential confounders for these traits were highly overlapping, including physical activity level, anthropometric traits, smoking and health rating (Supplementary Table 2). Other notable confounders included measures of physical activity for forced vital capacity; smoking status and fitness measures for basal metabolic rate; and measures of body size for hand grip strength.
Finally, for each confounder we calculated the correlation due to confounding (C) as described above (Methods and Figs. 1b and 2b) and summed up these C values for all uncorrelated confounders. We then, for each trait, compared the difference in estimates (that is, \({\hat{r}} - {\hat{\alpha}}\)) to the estimated value Csum (Fig. 4b). One can observe some traits (for example, systolic blood pressure) where the difference between partner correlation and causal effects can be well explained by the tested confounders, but for the majority of the traits, the observed confounders are not sufficient to account for the discrepancy (for example, basophil count has strong positive confounders missing).
Major confounders of trait correlations
Next, we assessed the impact of potential confounders on trait correlation in couples by calculating the ratio of correlation due to confounding over the raw phenotypic correlation among couples averaged across all traits tested (Supplementary Table 3). While geographical location (using place of birth north/east coordinates) was found to have a negligible impact on phenotypic correlations (mean confounding ratio 1%), household income (mean confounding ratio 29.8%), age completed full-time education (mean confounding ratio 11.6%) and physical activity levels (measured using the variable ‘leisure/social activities: sport club or gym’; mean confounding ratio 17.1%) had an important confounding impact on raw phenotypic correlation among couples (Fig. 5).

a–f, Scatterplots of couple correlation due to confounding versus the phenotypic trait correlation among couples for selected potential confounder traits (Z). The couple correlation due to confounding for each trait X was calculated for each confounder Y as \(C = \alpha _{y \to x}^2 \times \alpha _{y_{\mathrm{i}} \to y_{\mathrm{p}}}\). In the case of birthplace coordinates, C values were summed across the two (independent) north and east coordinates. The centre of the CI is the estimator value and the error bars represent the 95% CI. These confidence intervals for the correlations shown on the x axis are based on the number of couples shown in the ‘n_pairs’ column of Supplementary Table 2. The CI for confounder-induced correlation was computed as 1.96 times the s.e. of the estimator \({\hat{\alpha}} _{y \to x}^2 \times {\hat{\alpha}} _{y_{\mathrm{i}} \to y_{\mathrm{p}}}\), the computation of which is described in the Methods. For each trait in the pipeline, we tested how the contribution of six confounder traits (average total household income before tax (a), current tobacco smoking (b), age completed full-time education (c), overall health rating (d), sports club or gym user (e) and place of birth coordinates (f)) could impact the phenotypic couple correlation. The identity line is shown in black.
Cross-trait assortment
We sought to identify the mechanisms underlying partner similarity by comparing three estimated paths from a phenotype in the index case (\(X_{\mathrm{i}}\)) to another phenotype in its partner (\(Y_{\mathrm{p}}\)) as illustrated in Fig. 2c. The total causal effect between \(X_{\mathrm{i}}\) and \(Y_{\mathrm{p}}\) (denoted by ω) can be split up into three components: (1) AM through X (that is, \(X_{\mathrm{i}} \to X_{\mathrm{p}}\)) followed by a causal effect between X and Y in the partner (that is, \(X_{\mathrm{p}} \to Y_{\mathrm{p}}\)), their product being denoted by γ; (2) causal effect between X and Y in the index individual (that is, \(X_{\mathrm{i}} \to Y_{\mathrm{i}}\)), followed by AM through Y (that is, \(Y_{\mathrm{i}} \to Y_{\mathrm{p}}\)), their product being denoted by ρ; and (3) any remaining effect of \(X_{\mathrm{i}}\) on \(Y_{\mathrm{p}}\).
We computed within-couple cross-trait causal effect estimates \(X_{\mathrm{i}} \to X_{\mathrm{p}}\) (that is, \({\hat{\omega}}\)) for all combinations of trait pairs (\(X,Y\)). Of these, we identified 1,327 significant MR effects (\(p_{\hat{\omega}}\) < 0.05/[662]) among couples, which were reduced to 1,088 pairs after removing pairs with phenotypic correlation >0.8 (a summary of a set of pruned traits can be found in Supplementary Table 4). Several relationships were almost completely dominated by ρ (AM through the outcome) and others dominated by γ (AM through the exposure). Specifically, we found 326 relationships which were significantly different between ρ and γ, of which 89 (27.3%) showed larger effects through ρ and the other 237 (72.7%) showed larger effects through γ. For instance, we found causal relationships between partners for leg fat percentage on the time spent watching television and BMI on overall health rating, all dominated by ρ.
On the other hand, we found some causal relationships between partners which were primarily dominated by γ (AM through the exposure), including comparative height at age 10 (that is ‘When you were 10 years old, compared to average would you describe yourself as shorter, taller, average’), forced vital capacity and standing height on hand grip strength. Finally, we found other pairs where neither ρ nor γ captured the relationship (that is, \({\hat{\omega}}\) was significantly larger than both estimates), including BMI effect on partner’s systolic and/or diastolic blood pressure.
Finally, we estimated the contribution of the first two components (\({\hat{\gamma}}\) and \({\hat{\rho}}\)) contributing to these significant cross-trait effects and compared their contribution to the total effect using standard linear regression (Fig. 6 and Supplementary Table 5). Paired t test comparing \({\hat{\gamma}}\) and \({\hat{\rho}}\) effect estimates revealed that \({\hat{\gamma}}\) (AM through X) is stronger (P = 1.1 × 10−5) in general compared to \({\hat{\rho}}\) (AM through Y). When we summed up the effects of \({\hat{\gamma}}\) and \({\hat{\rho}}\), we found that the sum was significantly larger than \({\hat{\omega}}\). However, these two effects seemed to be correlated, carrying potentially shared signals. Hence, we first residualized \({\hat{\rho}}\) for the effects of \({\hat{\gamma}}\) (\(\widehat {\rho _{{\mathrm{resid}}}}\)) to ensure independence between the two estimates and then added \(\widehat {\rho _{{\mathrm{resid}}}}\) to \({\hat{\gamma}}\) (\(\widehat {\rho _{{\mathrm{resid}}}} + {\hat{\gamma}}\)). We found no significant difference between \({\hat{\omega}}\) and the sum of \(\widehat {\rho _{{\mathrm{resid}}}} + {\hat{\gamma}}\) in this analysis and with data points in general falling near the identity line, suggesting that \({\hat{\omega}}\) was capturing the paths given by \({\hat{\gamma}}\) and \({\hat{\rho}}\). Indeed, linear regression results revealed that 76% of the total effect (\({\hat{\omega}}\)) can be explained by the two paths (\(\widehat {\rho _{{\mathrm{resid}}}} + {\hat{\gamma}}\)) and that the \(\widehat {\rho _{{\mathrm{resid}}}} + {\hat{\gamma}}\) is on average very close to the total effect.

a–d, We estimated various causal effect paths (ρ, γ and ω, see Fig. 2c) from a phenotype of the index case (\(X_{\mathrm{i}}\)) to another phenotype of its partner (\(Y_{\mathrm{p}}\)) for the 1,088 trait pairs with significant MR effects among couples (\(p_{\hat{\omega}}\) < 0.05/[662]) and trait pair correlation <0.8. Panel (a) provides a scatter plot for 𝜌̂ against 𝛾̂ ; panel (b) for 𝜔̂ against 𝜌̂; panel (c) for 𝜔̂ against 𝛾̂ and panel (d) for 𝜔̂ against \(\widehat {\rho _{\mathrm{resid}}} + {\hat{\gamma}}\). The solid black line represents the linear regression fit. Dark blue dots indicate trait pairs with significant (after Bonferroni, BF, correction) difference between the respective parameters shown in the scatter plot, while light blue one mark the remaining traits. To calculate \(\widehat {\rho _{{\mathrm{resid}}}} + {\hat{\gamma}}\), we residualized \({\hat{\rho}}\) for the effects of \({\hat{\gamma}}\) (\(\widehat {\rho _{{\mathrm{resid}}}}\)) to ensure complete independence between the estimates and then added \(\widehat {\rho _{{\mathrm{resid}}}}\) to \({\hat{\gamma}}\) (\(\widehat {\rho _{{\mathrm{resid}}}} + {\hat{\gamma}}\)). e, A box plot comparing the coefficients of the estimates among the trait pairs after removing 19 trait pairs where the sign did not match between any combination of the four coefficients. In the box plots, the lower and upper hinges correspond to the first and third quartiles and the middle bar corresponds to the median; the upper whisker is the largest point smaller than 1.5 times the interquartile range above the third quartile; the lower whisker is defined analogously. We used a two-sided paired t test to compare the presented estimates (\({\hat{\rho}} ,{\hat{\gamma}} ,{\widehat{{\rho} _{{\mathrm{resid}}}}} + {\hat{\gamma}}\) and \({\hat{\omega}}\)).
The extent of bias in the MR estimates
In the Methods, we formulated a general model that accommodates parental effects and direct, indirect assortment (Fig. 7). We then, assuming this model, derived the analytical formula for the bias of cross-sample MR estimates, which shows its exact dependence on each model parameter. Here, we explored the extent of the bias under realistic ranges of model parameters and visualized it in Fig. 8. First, we observed (Fig. 8a) that \(r_{\mathrm{G}}\) (the correlation of the genotype between partners) has little impact on the bias (since it is limited by the heritability and the genetic correlation) compared to direct environmental assortment (\(r_{\mathrm{E}}\)), and they contribute additively. A similar relationship can be observed (Fig. 8b) for the parental genetic- (\(s_{\mathrm{G}}\)) and parental trait effects (\(s_{\mathrm{X}}\)) on the offspring’s environment; the impact of the former is dwarfed by the latter for the same reason. Unsurprisingly, the largest bias emerges when both the \(r_{\mathrm{E}}\) and \(s_{\mathrm{X}}\) are the largest (Fig. 8c). This can be complemented by \(r_{\mathrm{E}}\) combined with parental genetic effects on the offspring’s environment (\(s_{\mathrm{G}}\)) (Fig. 8d).

The diagram represents the underlying joint model of parental effects and assortment. A focal trait (X) has genetic (G) and envionmental (E) components, with effect size g and e, respectively. Their subscripts can be O, F or M, referring to the offspring, the father or the mother, respectively. The superscripts can be either i or p, indicating the index individual or its partner. We allowed parental genetics, parental environment and the parental trait each to influence the offspring’s environment, with corresponding direct effect strengths sG, sE and sX, respectively. Finally, couples are formed under direct assortments acting on G, E and X, leading to correlations rG, rE and rX, respectively.

We plotted the bias of the cross-sample MR estimates as a function of the proposed model parameters. Parameter \(r_{\mathrm{G}}\) refers to direct genetic assortment, \(r_{\mathrm{E}}\) to direct environmental assortment, \(s_{\mathrm{G}}\) to direct parental genetic effect and \(s_{\mathrm{X}}\) to direct parental trait effect. The different panels show the extent of bias when different pairs of parameters were covaried: \(r_{\mathrm{G}},r_{\mathrm{E}}\) (a), \(s_{\mathrm{G}},s_{\mathrm{X}}\) (b), \(r_{\mathrm{E}},s_{\mathrm{X}}\) (c) and \(s_{\mathrm{G}},r_{\mathrm{E}}\) (d).
Overall, when direct environmental or genetic assortment is moderate, parental effects lead to negligible bias in the causal effect estimate between \(X_{\mathrm{O}}^{\mathrm{i}}\) and \(X_{\mathrm{O}}^{\mathrm{p}}\). This is why we focused our real data analysis efforts on identifying such X-associated (confounding) factors for which direct assortment may occur, so that \(r_{\mathrm{E}}\) (and hence, the MR bias) could be limited.
Discussion
In this article, we studied causal relationships behind trait similarity within couples by applying MR to the UKBB data. We analysed 118 traits, representing a wide range of anthropometric-, behavioural- and disease-related traits. Among the 118 phenotypes tested, we found widespread evidence of causal effects among partners. In particular, we identified 64 same-trait causal effects within partners (of 118 traits) and no evidence of heterogeneity among same-trait couple MR estimates (\(\alpha _{x_{\rm{i}} \to x_{\rm{p}}}\)). This suggests that associations between a person’s genotype and their partner’s phenotype are primarily acting indirectly through the cross-partner causal relationship between the trait(s) associated with the genotype, rather than the presence of a direct effect for index genotype to the partner’s phenotype.
Our results suggest that fitness and anthropometric measures are important initially (at the time of mate choice), but their correlation decreases with time; the longer partners stay together, the less important it gets to remain similar. On the other hand, we found that couples become more similar with respect to smoking cessation and aspirin use as their age increases. As age and time spent together are highly correlated, it is difficult to distinguish whether this is an effect of convergence or of age-dependent partner choice. We did not find any significant trends of causal MR effects on time spent together or by age. While this could be because of limitations such as statistical power, this is consistent with previous reports which suggest that initial partner choice is more important than convergence9,30,31,32.
Deriving an analytical formula for the bias in the cross-partner MR estimation allowed a detailed analysis of model parameters that contribute most to such potential bias. Our analysis revealed that the largest contribution to the bias is direct environmental assortment combined with strong parental effects. This conclusion prompted us to explore potential confounders for each examined trait.
When investigating the impact of common confounders on our entire panel of phenotypes (that is, fixing a confounder and assessing its widespread impact on all single-trait AM), we found that household income, age completed education and participant of a sport club or gym are important confounders, explaining on average 29.8, 11.6 and 17.1% of the phenotypic couple correlations among traits tested, respectively. These results also suggest that phenotypic correlations in couples are significantly confounded and point to a relatively few key traits which are driving observed partner similarity. These confounder traits are strongly intertwined and hence correlated, therefore elucidating that the key driver is not feasible with the data at hand. Overall, we noticed that the tested confounders are not sufficient to account for the gap between couple correlations and causal effects or the latter being incorrectly estimated. Of note, phenotypic correlations in couples are impacted differently by measurement noise than causal effect estimates. While the former estimates are attenuated by a factor of \(\frac{{{\mathrm{Var}}(y)}}{{{\mathrm{Var}}\left(y \right) + s^2}}\) in case the true phenotype y is measured with a noise with variance s2, the causal effect estimates do not change noticeably because the exposure and outcome effects are equally diluted. This could lead to an underestimation of confounding effects in our results and may explain why for three traits we observed larger causal effect than correlation.
Our findings investigating cross-trait assortment suggest that causal effects from \(X_{\mathrm{i}}\) to \(Y_{\mathrm{p}}\) are primarily driven by AM through X (that is, \(X_{\rm{i}} \to X_{\rm{p}}\)) followed by a causal effect within the partner from X to Y (that is, \(X_{\mathrm{p}} \to Y_{\mathrm{p}}\)). In contrast, a less likely path would be the inverse, whereby the presence of a causal effect from X to Y in an index case is then followed by Y being passed directly from index to partner. These results were expected, as it is more reasonable for couples to influence each other at the exposure level rather than the outcome level, especially since often outcome traits (such as diseases) appear much later than mate choice.
We found 1,088 significant cross-trait causal effects within couples (ω), which can be summarized by three categories: (1) driven by assortment on the exposure (\(\omega = \gamma\)), (2) driven by assortment on the outcome (\(\omega = \rho\)) and (3) not explained by either (that is, ω being greater than both ρ and γ). Of note, there were fewer cases in category 3, where the causal effect from \(X_{\mathrm{i}}\) to \(Y_{\mathrm{p}}\) was not captured by γ or ρ, suggestive of either a direct effect \(X_{\mathrm{i}}\) to \(Y_{\mathrm{p}}\) or indirect effects through variables we have not explored. An example from the first category involves a positive causal effect of time spent watching television on BMI driven by the fact that partners causally influence each other with respect to time spent watching television, which, in turn, has an impact on BMI at the individual level. On the other hand, an example of the second category includes a positive causal relationship from height to education, with a stronger path through ρ, whereby height (a proxy for ‘dynastic’ wealth) increases educational attainment (found previously33) within a single individual and AM subsequently occurs via education level. Finally, as an example for category 3, we found a negative causal effect of never having smoked on leucocyte count within partners, such that leucocyte count was higher among individuals with partners who smoked. While we also identified a significant effect through γ (AM through smoking), the effect was much stronger through ω. These findings suggest that there could be a direct effect from index partner by way of secondhand smoke. These results are consistent with previous work showing higher white blood cell count in smokers34, which might already be achieved by secondhand smoking.
This study has limitations which should be acknowledged. First, to increase statistical power and robustness, we focused on traits available in the UKBB with significant correlation among couples and more than five valid IVs. As a result, anthropometric traits constituted a larger proportion of our traits under study and represent a large percentage of our significant findings. Other phenotypes, such as behavioural and lifestyle traits, were included but had less statistical power due to lower couple correlation and fewer IVs.
Second, using our data, we could not find strong evidence for couple convergence over time. This can be due to these effects being weak or the available data being suboptimal. Indeed, we used data on both age and time together (proxied by time at the same address) to answer this question, but these are poor proxies of the relevant traits. To properly disentangle the relationship between AM and convergence, additional longitudinal data including phenotypes at the time of partner selection would be necessary. A complementary approach could be to contrast genetic and phenotypic correlations; however, it is hard to tell whether differences reflect postmating effects or different (genetic and environmental) correlation to traits under primary assortment20.
Third, we have not explored indirect causal paths from \(X_{\mathrm{i}}\) to \(X_{\mathrm{p}}\) through another variable (Z) measured in either individual. Given the limited evidence of direct cross-trait, cross-partner effects, the most likely such path would be \(X_{\mathrm{i}} \to Z_{\mathrm{i}} \to Z_{\mathrm{p}} \to X_{\mathrm{p}}\), leading to an indirect effect of \(\alpha _{X \to Z}\alpha _{Z \to X}\alpha _{Z_{\mathrm{i}} \to Z_{\mathrm{p}}}\). This implies a bidirectional causal effect between X and Z (within the same individual), but their product is expected to negligible35. Also, while assortment/convergence through the exposure (γ) and the outcome (ρ) represents independent paths from Xi to Yp, our results suggest that the computed effects using MR estimates are not perfectly independent. This could potentially be because of the overlap in genetic instruments or bidirectional causal effect between them or because both estimates depend on the causal effect from X to Y. To the best of our ability, we tried to mitigate this bias by (1) using a multivariable Mendelian randomization (MVMR) approach to remove effects of X on Y in the calculation of ρ and (2) first residualizing γ for effects of ρ to ensure independence before summation of the effects. Finally, we were limited to the available traits and white British samples in the UKBB. AM and partner selection are often population specific36. Therefore, our findings may not generalize to other populations, and more diverse biobanks are needed to systematically explore the heterogeneity in assortative behaviour.
In summary, we have surveyed 118 complex traits with significant couple correlation in the UKBB and explored the major contributors to the observed couple similarity: partner selection, couple convergence and confounding. We found that cross-trait assortment can largely be explained by single-trait assortments between either trait and substantial causal effects between these traits. Our findings provide insights into possible mechanisms underlying observed partner similarity patterns at an unprecedented scale and resolution.
Methods
All analyses were run using the R software (v.3.6.3).
Sample selection and couple definition
This study used the UKBB cohort, a prospective population-based study with over 500,000 adult participants. UKBB has approval from the North West Multi-Centre Research Ethics Committee as a Research Tissue Bank approval. This approval means that researchers do not require separate ethical clearance and can operate under the Research Tissue Bank approval. UKBB also possesses a Human Tissue Authority licence, so a separate Human Tissue Authority licence is not required by researchers who receive samples from the resource.
Couples were identified and selected according to the following procedure. The initial UKBB sample comprised 502,616 individuals. First, participants were filtered to only genotyped, white, unrelated individuals according to the genetic quality control (QC) file. Redacted samples and participants who removed consent were also excluded. After filtering, 337,138 participants remained. Within this sample, we retained individuals coming from households with exactly two unrelated, opposite sex individuals, leaving 108,898 participants. Finally, using the data at data field 6,141, ‘How are people in household related to participant’ pairs were filtered to only include couples who had both responded ‘Husband, wife, or partner’, leaving 103,328 participants or 51,664 couples for downstream analyses (Supplementary Fig. 1). Note that some studies have used more stringent criteria for couple definition. For example, Yengo et al.22 additionally requested couples to have been recruited in the same centre, living in the same location, for the same amount of time, living with the same number of people with the same household income, same Townsend deprivation, same number of smokers and so on. Howe et al.29 used a very similar definition to ours (resulting in 10% fewer couples than us); however, they restricted their analyses to only couples who reported to live at the same address for the same amount of time. We believe that discrepancies in self-reported data can occur frequently (due to misunderstanding, misreporting) and hence, decided to use a more liberal couple definition to increase sample size at the cost of minor misclassification.
MR
MR uses genetic variants as IVs to assess the presence of a causal relationship. The random distribution of genetic variants at birth reduces the possibility of confounding or reverse causation as explanations for the link between the exposure and outcome in the same way that the random allocation of a therapy in a randomized controlled trial minimizes this risk. MR relies on three core assumptions for the genetic variants. First, IVs must be associated with the exposure of interest (the relevance assumption). Second, IVs must not be associated with any confounder in the exposure–outcome relationship (the exchangeability assumption). Third, IVs must not affect the outcome except through the exposure (the exclusion restriction assumption). There are several methods to estimate the causal effect using MR, the simplest being the Wald method, whereby a ratio is taken between the variant–outcome association and the variant–risk factor association. A natural extension of this approach, known as the inverse-variance weighted (IVW) method, combines multiple IVs, applied in this report37. The causal effect of exposure X on the outcome Y, using k genetic variants, is given by
with the corresponding variance \({\mathrm{Var}}\left( {\hat{\alpha} } \right) = \frac{1}{{\mathop {\sum}\limits_k {(\beta _k^X)^2(\sigma _k^Y)^{ - 2}} }}\), where \(\beta _k^X\) and \(\beta _k^Y\) represent the estimated effects of genetic variant k on X and Y, respectively, and \(\sigma _k^Y\) represents the standard error of \(\beta _k^Y\). Here, we extended the framework of MR to situations where the exposure and the outcome are measured in different individuals. More specifically, our exposure was a trait of an index individual, and the outcome was the same (or another) trait in its partner.
Phenotype selection and processing
We used an agnostic, phenome-wide approach for selecting phenotypes. Specifically, we first selected phenotypes which were analysed by the Neale group and which had men, women and joint summary statistics available (http://www.nealelab.is/uk-biobank/). This list was intersected with our internal database (application number 16389), leaving 1,278 phenotypes available for analysis. Phenotypes were processed in the filtered QC dataset (n = 337,138) according to a slightly modified version of the PHEnome Scan ANalysis Tool (PHESANT) pipeline to accommodate the phenotypes that we had available in our database38. Continuous variables were transformed to a normal distribution using a rank-preserving inverse normal quantile transformation, while ordinal and binary traits were recategorized according to PHESANT documentation (for example, categories with fewer than ten participants were removed). We then filtered these phenotypes as follows. First, to focus on traits with some indication of assortment, we computed the raw phenotypic correlation (\(r_{x_{\mathrm{i}}x_{\mathrm{p}}}\), where x refers to trait X, i represents the index person and p is its partner) among couples and removed phenotypes with a Pearson correlation of <0.1. To ensure that inverse normal quantile transformation was not significantly impacting the correlations of each trait, we also calculated the correlation between partners for each trait using the nonparametric Spearman correlation and found consistent estimates (Supplementary Fig. 2). Second, we removed phenotypes that had fewer than five valid IVs for MR. IVs were defined based on an association P < 5 × 10−8 in the joint Neale summary statistics, after pruning for independence (based on a clumping procedure performed in PLINK39 with the options –clump-kb 10000 and –clump-r2 0.001 using the 1000 Genomes European samples as a reference). Third, using the sex-specific summary statistics, the IV heterogeneity between sexes was calculated. IVs that showed (Bonferroni-corrected) significant evidence of heterogeneity between sexes were excluded (P < 0.05/[number of IVs]). After this procedure, phenotypes were again filtered to those with at least five valid IVs remaining. Fourth, dietary phenotypes were removed due to high correlation among these phenotypes (due to the shared household), insufficient power, problems with reverse causation and difficult interpretation40. Finally, we manually removed several duplicated and redundant phenotypes. Specifically, (1) left-side body traits (highly correlated with right side) were removed; (2) we retained only one of the duplicated phenotypes for BMI and weight (retaining UKBB data fields 21001 and 21002, respectively); and (3) all ‘qualifications’ data were removed (corresponding to UKBB field 6,138) due to the availability of finer-scale correlated variables, such as ‘age completed full-time education’ (data field 845). This ad hoc procedure was meant to capture only major redundancies. After this process, 118 phenotypes remained for analysis (Supplementary Fig. 3).
Estimation of single-trait causal effects in couples
To investigate the causal effect of a trait in one individual on the same trait of their partner, we performed couple-specific MR analyses. Specifically, the trait in the index case was used as the exposure and the same trait in the partner was used as the outcome trait. The effect of genetic variants on the exposure was obtained from the Neale summary statistics using the full UKBB sample. Instruments for each trait were selected as described above: that is, being both genome-wide significant (P < 5 × 10−8) and pruned for independence. Next, we estimated the effects of single-nucleotide polymorphisms (SNPs) on the outcomes of interest by testing the association between each genetic instrument measured in the index individual with the phenotype measured in the partner using the UKBB partner dataset described above. In other words, for each phenotype, the corresponding genetic data for the IVs were obtained from the index case, while the phenotypes (dependent variable) were taken from the corresponding partner. All SNP trait estimates were estimated in men and women separately (that is, using the sex-specific Neale summary statistics or two separate models in the couple data), adjusting for age and the first 40 genetic principal components of both the index and partner. To mimic the Neale models, we performed linear regression of SNP effects on phenotypes, regardless of data type (including binary). Continuous phenotypes were scaled to have mean of zero and s.d. of one before regression, while ordinal and binary phenotypes were left as processed by PHESANT.
To estimate the causal effect of a trait from an index case to a partner (\(\alpha _{x_{\mathrm{i}} \to x_{\mathrm{p}}}\), we combined the effects of genetic instruments on the exposure (from Neale) with effects on the outcomes (measured among couples) in an MR framework using the IVW method (Fig. 2a)37. To estimate the causal effects in both sexes combined, SNP effects were first meta-analysed across sexes using fixed effects models before performing MR (rather than meta-analysing the MR estimates directly) to minimize weak instrument bias41. Effects of the genetic estimates on both the exposure and outcome were first standardized (such that the squared effect size represents the explained variance) to allow for seamless comparison across traits and to the raw phenotype correlation. Significance was determined by adjusting for the number of effective tests based on the correlation matrix of phenotypes tested42, resulting in 66 independent tests. The significance threshold was adapted accordingly as P < 0.05/66.
After estimating single-trait causal effects in couples, we used a two-tailed Z test to identify traits with a significant difference between the MR estimate and the phenotypic correlation in couples. For each trait with discrepant estimates, we tested the causal effect of each of the remaining 117 phenotypes in our pipeline (\(Y_1, \ldots ,Y_{117}\)) on the focal trait of interest (X) using MR (\(\alpha _{y \to x}\)). These same-person MR estimates were calculated using meta-analysed sex-specific Neale estimates for both the SNP exposure and SNP outcome effects using the IVW method. Before performing each same-person MR, genetic variants were first filtered for evidence of reverse causality at a threshold of P < 0.001 (Steiger filter)43, whereby SNPs were removed if the standardized SNP effect on the outcome was stronger than the effect on the exposure based on a one-tailed t test at a significance level of P < 0.001. SNP effects were standardized before calculating MR effects.
We then explored those potential confounders, \(Y_1, Y_2, \dots, Y_{117}\), with a significant impact on X (P < 0.05/66). As the confounding impact of each \(Y_k\) involves a within-couple effect (\({\upalpha}_{y_{\mathrm{i}} \to y_{\mathrm{p}}}\)), as illustrated in Fig. 2b, we further filtered the remaining \(Y_k\) traits to those with a significant within-couple MR effect (P < 0.05/[number of remaining \(Y_k\)]). The couple correlation induced by confounder Y can be expressed as \(\alpha _{y \to x}^2 \times \alpha _{y_{\mathrm{i}} \to y_{\mathrm{p}}}\). We restricted confounders to only those that had a correlation with X less than 0.8 to avoid using meaninglessly similar traits to X. Since potential confounders may be correlated, one could use MVMR to assess the joint contribution of these confounders on the couple correlation for trait X. This, however, led to numerical instability, and we decided to rather prune confounders (\(r^2 < 0.1\), prioritizing for larger \({\hat{\alpha}}_{y \to x}^2 {\hat{\alpha}}_{y_{\mathrm{i}} \to y_{\mathrm{p}}}\) values) and obtain \({\hat{\alpha}} _{y \to x}\) estimated from univariable MR, where IVs were pruned for independence (\(r^2 < 0.001\)). Finally, we plugged in the obtained causal effect estimates for the m remaining confounder traits (\(Y_1,Y_2, \ldots ,Y_m\)) on X, (\({\hat{\alpha}} _{Y_1 \to {{X}}},{\hat{\alpha}} _{Y_2 \to {{X}}}, \ldots ,{\hat{\alpha}} _{Y_m \to {{X}}}\)), into the estimator of the correlation induced by these confounders to get the estimate of total confounding \(C = \mathop {\sum }\limits_{{j} = 1}^{{{\mathrm{m}}}} {\hat{\alpha}}_{\left({Y_j} \right)_{{{\mathrm{i}}}} \to \left({Y_j} \right)_{{{\mathrm{p}}}}} ({\hat{\alpha}}_{Y_j \to {{X}}})^2\). The variance of such a sum was estimated as the sum of the variances of the individual terms (since they are uncorrelated). The variance of \(({\hat{\alpha}}_{Y_j \to {{X}}})^2\) was approximated by assuming \({\hat{\alpha}}_{Y_j \to {{X}}}\) following a normal distribution and used the general formula of \({\mathrm{Var}}\left({X^2} \right) = 4\mu ^2\sigma ^2 + 2\sigma ^4\) for \(X\approx N(\mu ,\sigma ^2)\). The variance of the product of \({\hat{\alpha}}_{\left( {Y_j} \right)_{{{\mathrm{i}}}} \to \left( {Y_j} \right)_{{{\mathrm{p}}}}}\) and \(({\hat{\alpha}}_{Y_j \to {{X}}})^2\) was estimated based on the formula for the variance of the product of independent random variables: \({\mathrm{Var}}\left( {XY} \right) = {\mathrm{Var}}\left( X \right){\mathrm{Var}}\left( Y \right) + {\mathrm{Var}}\left( X \right)E^2\left( Y \right) + {\mathrm{Var}}(Y)E^2\left( X \right)\).
The role of confounders on trait correlation in couples
We sought to explore the impact of potential confounders on mate choice by calculating the trait correlations between partners that are due to confounding. We considered the impact of the following confounders (Y) on the partner correlations of the remaining 117 traits selected by our pipeline: average household income, age completed full-time education, sports club or gym user, current tobacco smoking, overall health rating, and north and east birth place coordinates (UKBB data fields 738; 845; 6160; 1239; 2178; 129; and 130, respectively). The choice of these traits was somewhat ad hoc, mostly driven by previous evidence for driving trait similarities and themselves showing strong couple correlation in the UKBB. Using the single-trait causal effects in couples and the same-person MR estimates, correlation due to founding was calculated for each pair \((Y,X)\) as \(C = \alpha _{y \to x}^2 \alpha _{y_{\mathrm{i}} \to y_{\mathrm{p}}}\) (Fig. 2b). These confounding estimates were finally contrasted to the couple correlation values to explore the extent that each Y may confound couple correlations by examining the ratio between the two estimates (that is, \(\frac{C}{{\mathrm{cor}}(X_{\mathrm{i}},X_{\mathrm{p}})}\)). Birthplace coordinates (east–west and north–south) were considered together and their invoked trait correlations were summed up, as they are orthogonal by definition.
Trait convergence over time
Trait similarity in couples can be driven by both mate choice and/or trait convergence over time spent together. To tease out the contribution of these different sources, we explored whether the cross-partner causal effects change as a function of the length of the relationship and age. The length of relationship was proxied by the minimum value of the ‘length of time at current address’ (data field 699) for the two partners. To estimate the effect of age, we took the median age of couples. For each of the two derived variables, we split the couples into five roughly equal-sized bins (using the ‘smart_cut’ function from the cutr R package). We first estimated the phenotypic correlation of each trait within couples of each bin. Next, for each single-trait MR described above, analyses were run in the full sample as well as in the different bins. Of the significant results identified in the sex-combined analysis above, we tested to see if there was any significant difference in MR estimates among the bins. Binned MR estimates were computed using the SNP outcome effect estimated in each bin separately, and the SNP outcome effects used the same SNP exposure effects from Neale. Analyses were run in each sex separately and combined (meta-analysed at the SNP level). As above, SNP effects were standardized before calculating MR estimates. To assess for the presence of a trend across bins, we tested the significance of the slope of a linear model of bin-specific correlations and bin-specific MR estimates, inversely weighted by the SE, versus the bin centre (that is, the median age or time spent together for the given bin). Multiple testing was, as described above, adapted based on the effective number of tests but restricted to traits which showed significant causal effects in the joint (both sexes combined), nonbinned MR (resulting in a threshold of P < 0.05/29).
Estimation of cross-trait causal effects in couples
Using the same process as in the AM analysis involving a single trait, we also sought to investigate causal effects within couples involving two traits (\(\alpha _{x_{\mathrm{i}} \to y_{\mathrm{p}}}\)). In other words, two different traits were used as exposure and outcome to determine the causal effects of trait X (in the index individual) on trait Y (in the partner). Here, we only considered trait combinations with phenotypic correlation of <0.8 (estimated in the entire UKBB, n = 337,138) to avoid too closely related traits. The same set of SNPs was used as in the same-person MR (that is, first filtered for the presence of reverse causality). As in the single-trait MR, SNP exposure effects were obtained from the Neale summary statistics and SNP outcome effects were estimated in the couple-derived dataset. MR models were run in both sexes separately and jointly (meta-analysing the SNP effects before performing MR analyses). Significance was determined based on the squared effective number of tests (P < 0.05/[662]).
Comparison of paths from index to partner
There are several independent paths through which a trait in an index case could exert a causal effect on another trait in the partner. We wanted to explore if one path was more dominant, in general, and if there was evidence for the presence of direct effects (or indirect effects with additional traits involved). Restricting to Bonferroni-significant trait pairs (with phenotypic correlation of <0.8) from the couple MR, we sought to explore the various paths through which a phenotype X in an index case (Xi) could causally impact a phenotype Y in the partner (Yp) as illustrated in Fig. 2c. With the exception of exposure traits that directly alter the environment of their partner, such as smoking creating the presence of secondhand smoke, Xi is unlikely to have a direct effect on another Yp. Alternatively, Xi might indirectly impact Yp by inducing changes in Xp, which in turn, impacts Yp. For instance, increased BMI in an index case is not expected to directly increase cardiovascular disease risk in their partner but rather, to modify the partner’s risk through first increasing their BMI. To explore this intuition, we dissected the causal effect from Xi to Yp (ω) into three possible (nonindependent) mechanisms. First, Xi could exert a causal effect on Xp, followed by Xp having a causal effect on Yp in the partner alone (γ). Second, the reverse could occur, whereby \(X_i\) has a causal effect on Yi in the index alone, followed by a causal effect of Yi case on Yp (ρ). Third, there could be other mechanisms, either acting directly or through other unmeasured/considered variables. These three scenarios could also act in some combination. In this way, the ω estimate would capture the paths of γ, ρ and other mechanisms combined.
Using the same-person MR estimates that were calculated as described above, we estimated γ and ρ representing the various paths from Xi to Yp and contrasted them to the total cross-trait cross-partner effect ω. To quantify γ, the single-trait couple causal effect estimate (that is, from the regression \(X_{\mathrm{p}} \sim X_{\mathrm{i}}\)) was multiplied by the same-individual causal estimate (that is, \(\alpha _{x \to y}\) from \(Y \sim X\)). To quantify ρ, we first estimated the causal effect of Yi on Yp in MVMR to exclude any residual effect of X on phenotype Y from index to partner. Specifically, Yp was used as the independent variable with both Yi and Xi as independent variables (that is, the MVMR was \(Y_{\mathrm{p}} \sim Y_{\mathrm{i}} + X_{\mathrm{i}}\)). We included both IVs from X and Y, pruned for independence (performed in PLINK with the options –clump-kb 10000 and –clump-r2 0.001 using the 1000 Genomes European samples as a reference). We took the coefficient of Yi as the direct causal effect from Yi to Yp (\(\alpha _{y_{\mathrm{i}} \to y_{\mathrm{p}}}\)) and multiplied this by the same-individual causal estimate (\(\alpha _{x \to y}\)). Finally, we estimated ω directly from our cross-trait couple MR framework (\(\alpha _{x_{\mathrm{i}} \to y_{\mathrm{p}}}\)). We compared the estimates of γ, ρ and ω using a Z test to assess their difference and using linear regression with the intercept forced through the origin to determine their relationship. Finally, we quantified the proportion of ω that could not be explained by the paths quantified by γ and ρ. As γ and ρ are not perfectly independent, potentially due to correlation between X and Y or pleiotropic limitations of MR, we estimated the extent of dependence via the correlation between ρ and γ across the different trait pairs. To account for the duplicate signals due to this correlation, we removed the effects of γ from ρ by keeping the residuals from the linear regression \(\rho \sim \gamma\). We then estimated the proportion of variance explained (\(R^2\)) of ω jointly by γ and the residualised ρ.
Biases in the causal effect estimation
Violations of the MR assumptions are different in applications like ours, where the exposure and outcome are the same trait but measured in different individuals. Hartwig et al.44 explored the impact of AM on MR but for the classical setting of testing different traits in the same individual. Therefore, we set up a model (Fig. 7) specific to causal effect estimations where exposures and outcomes are the same traits but in different individuals (couples) to examine the potential issues. We have allowed for a more complex set of MR violations, which we describe below.
The model focuses on trait X in the offspring (O) (\(X_{\mathrm{O}}^{\mathrm{i}}\)) and that in the partner (\(X_{\mathrm{O}}^{\mathrm{p}}\)). Analogously, we denoted the same trait in the offspring’s mother and father with subscripts M and F. These traits are influenced by direct genetic effects (\(G_{\mathrm{O}}^{\mathrm{i}}\)) and direct (non-genetic) environmental effects (\(E_{\mathrm{O}}^{\mathrm{i}}\)), with effect sizes g and e, respectively. Everything derived below works the same way even if \(G_{\mathrm{O}}^{\mathrm{i}}\) represents a single SNP (and hence, \(E_{\mathrm{O}}^{\mathrm{i}}\) is heritable). The offspring environment is influenced by the parental environment (\(E_{\mathrm{P}}^{\mathrm{i}}\)), the parental genes (\(G_{\mathrm{P}}^{\rm{i}}\)) and the parental trait (\(X_{\mathrm{P}}^{\mathrm{i}}\)). Parental characteristics (\(G,E,X\)) are simply defined as a rescaled average of the maternal and paternal traits: that is, \(X_{\mathrm{P}}^{\mathrm{i}}\) = \((X_{\mathrm{M}}^{\mathrm{i}} + X_{\mathrm{F}}^{\mathrm{i}})/\sqrt {2 \left({1 + {\mathrm{cor}}(X_{\mathrm{M}}^{\mathrm{i}},X_{\mathrm{F}}^{\mathrm{i}})} \right.}\) to ensure that the trait variance is equal to 1, i.e. \({\mathrm{Var}}(X_{\mathrm{P}}^{\rm{i}}) = 1\). Note that this simplification assumes that paternal and maternal effects are identical, which holds in general32. The direct causal effects of \(G_{\mathrm{P}}^{\mathrm{i}},E_{\mathrm{P}}^{\mathrm{i}}\) and \(X_{\mathrm{P}}^{\mathrm{i}}\) on \(E_{\mathrm{O}}^{\mathrm{i}}\) are denoted by \(s_{\mathrm{G}},s_{\mathrm{E}}\) and \(s_{\mathrm{X}}\), respectively. By definition, the correlation between mean parental genotype and offspring genotype is \(1/\sqrt 2\). Parental traits (\(E_{\mathrm{P}}^{\mathrm{i}},X_{\mathrm{P}}^{\mathrm{i}}\)) cannot modify offspring genotype; thus, they can influence \(X_{\mathrm{O}}^{\mathrm{i}}\) only via its environmental component (\(E_{\mathrm{O}}^{\mathrm{i}}\)). The same description holds for all corresponding variables of the partner. Finally, \(X_{\mathrm{O}}^{\mathrm{i}}\) and \(X_{\mathrm{O}}^{\mathrm{p}}\) are paired such that predefined correlations between \(G,E\) and \(X\) are satisfied. For this, direct assortment coefficients \(r_{\mathrm{G}},r_{\mathrm{E}}\) and \(r_{\mathrm{X}}\) are defined between \(G,E\) and X, respectively.
As can be seen from Fig. 7, parental effects induce a correlation of \(\left( {\frac{1}{{\sqrt 2 }}} \right) (s_{\mathrm{G}} + s_{\mathrm{X}}\times g)\) between the offspring genotype (\(G_{\mathrm{O}}^{\mathrm{i}}\)) and the offspring environment (\(E_{\mathrm{O}}^{\mathrm{i}}\)). Also, one can note that the total couple correlation for X can arise from three independent sources: direct X assortment (\(r_{\mathrm{X}}\)), through direct assortment for \(E\) (\(r_{\mathrm{E}} \times e^2\)) and through direct assortment through \(G\) (\(r_{\mathrm{G}} \times g^2\)). Thus, the expected correlation between \(X_{\mathrm{O}}^{\mathrm{i}}\) and \(X_{\mathrm{O}}^{\mathrm{p}}\) is \(r_{\mathrm{X}} + r_{\mathrm{E}} \times e^2 + r_{\mathrm{G}} \times g^2\). Similarly, the expected correlation between \(E_{\mathrm{O}}^{\mathrm{i}}\) and \(E_{\mathrm{O}}^{\mathrm{p}}\) is \(r_{\mathrm{E}} + r_{\mathrm{X}} \times e^2 + r_{\mathrm{G}} \left( {\left( {\frac{1}{{\sqrt 2 }}} \right) (s_{\mathrm{G}} + g \times s_{\mathrm{X}})} \right)^2\) and between \(G_{\mathrm{O}}^{\mathrm{i}}\) and \(G_{\mathrm{O}}^{\mathrm{p}}\) is \(r_{\mathrm{G}} + r_{\mathrm{X}} \times g^2 + r_{\mathrm{E}} \left( {\left( {\frac{1}{{\sqrt 2 }}} \right) (s_{\mathrm{G}} + g \times s_{\mathrm{X}})} \right)^2\).
Under this model, the expected effect of the index genotype on the index trait is
while the expected effect of the index genotype on its partner’s trait is
Therefore, the expectation of the estimated causal effect \(X_{\mathrm{O}}^{\mathrm{i}} \to X_{\mathrm{O}}^{\mathrm{p}}\) can be written as
Several parameters in this model can lead to the violation of MR assumptions
-
Violation 1 (\({{{\boldsymbol{s}}}}_{{{\bf{{{G}}}}}} \ne 0\)): this violation implies that parental genetics directly impact offspring environment (not through E or X). Such violation would most likely happen if \(G_{\mathrm{P}}^{\mathrm{i}}\) impacts another parental phenotype \(Y_{\mathrm{P}}^{\mathrm{i}}\) which has an impact on \(E_{\mathrm{O}}^{\mathrm{i}}:\) that is, \(s_{\mathrm{G}} = g \cdot r_{\mathrm{G}}\left( {X,Y} \right) s_Y\). Here, \(r_{\mathrm{G}}\left( {X,Y} \right)\) refers to the genetic correlation between traits X and Y. The formula assumes that the effect of \(G_{\mathrm{P}}^{\mathrm{i}}\) to a secondary trait (Y) is expected to be its genetic effect on the primary trait (X) multiplied by their genetic correlation.
-
Violation 2 (\({{{\boldsymbol{s}}}}_{{{\bf{{{X}}}}}} \ne 0\)): this violation is the classical parental rearing (or in other terms, dynasty) effect.
-
Violation 3 (\({{{\boldsymbol{s}}}}_{{\bf{E}}} \ne 0\)): this violation does not lead to MR bias since there is no path from the offspring genotype to the offspring environment through the parental environment.
-
Violation 4 \(\left({{{\boldsymbol{r}}}}_{{\bf{G}}} \ne 0\right):\) this violation allows direct assortment based on index and partner genetics, which most likely happens due to assortment for another trait (Y). Hence, its typical size is \(r_{\mathrm{G}} = (g \times r_{\mathrm{G}}\left( {X,Y} \right))^2 r_Y\). Here, we made a similar assumption as for Violation 1. One (toy) example for such scenario could be educational attainment (X), whose genetic component is strongly associated with intelligence, for which additional assortment occurs.
-
Violation 5 (\({{{\boldsymbol{r}}}}_{{{\bf{{{E}}}}}} \ne 0\)): this violation allows direct assortment based on the environment of the index and partner. A simplified example for this scenario is trait X being BMI and E representing ‘going to the gym’. In such case, beyond AM for BMI, people are more likely to choose their partners from the gym (selecting for fitter individuals); hence; the environment has an additional direct effect of the partner’s BMI.
To gauge the extent of the MR bias in realistic parameter settings, we have visualized the bias for a wide range of parameters. We set \(r_{\mathrm{X}} = 0.2\), the heritability to 20% (hence, \(g = \sqrt {0.2}\) and \(e = \sqrt {1 - 0.2}\)). Then, two of the remaining four crucial parameters (\(s_{\mathrm{G}},s_{\mathrm{X}};r_{\mathrm{E}},r_{\mathrm{G}}\)) were fixed and the other two were varied. For example, the chosen range for \(r_{\mathrm{G}}\) assumed a value of \(r_{\mathrm{G}}\left( {X,Y} \right) = 0.3\) and \(r_Y\) range of [−0.3, 0.3] using the abovementioned formula of \(r_{\mathrm{G}} = (g \times r_{\mathrm{G}}\left( {X,Y} \right))^2 r_Y\). Similarly, we used the formula \(s_{\mathrm{G}} = g \times r_{\mathrm{G}}\left( {X,Y} \right) s_Y\) to justify the explored range for \(s_{\mathrm{G}}\), with \(r_{\mathrm{G}}\left( {X,Y} \right) = 0.3\) and \(s_Y\) between −0.3 and 0.3.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The UK Biobank data are available through the standard UK Biobank application procedure (https://www.ukbiobank.ac.uk/enable-your-research/apply-for-access). The household information can be separately requested from the UK Biobank access team, as it is not part of the variables listed on the showcase (https://biobank.ndph.ox.ac.uk/showcase/index.cgi). The 1000 Genomes European genetic data can be downloaded from http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/.
Code availability
Custom code is available at https://github.com/jennysjaarda/proxyMR.
References
Willoughby, E. A. et al. Parent contributions to the development of political attitudes in adoptive and biological families. Psychol. Sci. 32, 2023–2034 (2021).
Kandler, C., Bleidorn, W. & Riemann, R. Left or right? Sources of political orientation: the roles of genetic factors, cultural transmission, assortative mating, and personality. J. Pers. Soc. Psychol. 102, 633–645 (2012).
Silventoinen, K., Kaprio, J., Lahelma, E., Viken, R. J. & Rose, R. J. Assortative mating by body height and BMI: Finnish twins and their spouses. Am. J. Hum. Biol. 15, 620–627 (2003).
Maes, H. H., Neale, M. C. & Eaves, L. J. Genetic and environmental factors in relative body weight and human adiposity. Behav. Genet. 27, 325–351 (1997).
Keller, M.C. The genetic correlation between height and IQ: shared genes or assortative mating? PLoS Genet. 9, e1003451 (2013).
Mare, R. D. Five decades of educational assortative mating. Am. Sociological Rev. 56, 15–32 (1991).
Agrawal, A. et al. Assortative mating for cigarette smoking and for alcohol consumption in female Australian twins and their spouses. Behav. Genet. 36, 553–566 (2006).
Buss, D. M. Marry someone who is similar to us in almost every variable. Am. Sci. 73, 47–51 (1985).
Watson, D. et al. Match makers and deal breakers: analyses of assortative mating in newlywed couples. J. Personal. 72, 1029–1068 (2004).
Hippisley-Cox, J. Married couples’ risk of same disease: cross sectional study. Brit. Med. J. 325, 636–636 (2002).
Buss, D. M. et al. International preferences in selecting mates. J. Cross-Cultural Psychol. 21, 5–47 (1990).
Buss, D. M. & Barnes, M. Preferences in human mate selection. J. Personal. Soc. Psychol. 50, 559–570 (1986).
Anderson, C., Keltner, D. & John, O. P. Emotional convergence between people over time. J. Personal. Soc. Psychol. 84, 1054–1068 (2003).
Gonzaga, G. C., Campos, B. & Bradbury, T. Similarity, convergence, and relationship satisfaction in dating and married couples. J. Personal. Soc. Psychol. 93, 34–48 (2007).
Humbad, M. N., Donnellan, M. B., Iacono, W. G., McGue, M. & Burt, S. A. Is spousal similarity for personality a matter of convergence or selection? Personal. Individ. Differen. 49, 827–830 (2010).
Risch, N. Ancestry-related assortative mating in Latino populations. Genome Biology 10, R132 (2009).
Sebro, R., Peloso, G. M., Dupuis, J. & Risch, N. J. Structured mating: patterns and implications. PLoS Genet. 13, e1006655 (2017).
Abdellaoui, A. et al. Genetic correlates of social stratification in Great Britain. Nat. Hum. Behav. 3, 1332–1342 (2019).
Rawlik, K., Canela-Xandri, O. & Tenesa, A. Indirect assortative mating for human disease and longevity. Heredity 123, 106–116 (2019).
Robinson, M. R. et al. Genetic evidence of assortative mating in humans. Nat. Hum. Behav. 1, 0016 (2017).
Xia, C., Canela-Xandri, O., Rawlik, K. & Tenesa, A. Evidence of horizontal indirect genetic effects in humans. Nat. Hum. Behav. 5, 399–406 (2020).
Yengo, L. et al. Imprint of assortative mating on the human genome. Nat. Hum. Behav. 2, 948–954 (2018).
Border, R. Assortative mating biases marker-based heritability estimators. Nat. Commun. 13, 660 (2022).
Border, R. et al. Cross-trait assortative mating is widespread and inflates genetic correlation estimates. Science 378, 754–761 (2022).
Beauchamp, J. P., Cesarini, D., Johannesson, M., Lindqvist, E. & Apicella, C. On the sources of the height–intelligence correlation: new insights from a bivariate ACE model with assortative mating. Behav. Genet 41, 242–252 (2011).
Howe, L. J. et al. Assortative mating and within-spouse pair comparisons. PLoS Genet. 17, e1009883 (2021).
Lawlor, D. A. et al. Mendelian randomization: using genes as instruments for making causal inferences in epidemiology. Stat. Med. 27, 1133–1163 (2008).
Holmes, M. V. et al. Causal effects of body mass index on cardiometabolic traits and events: a Mendelian randomization analysis. Am. J. Hum. Genet 94, 198–208 (2014).
Howe, L.J. Genetic evidence for assortative mating on alcohol consumption in the UK Biobank. Nat. Commun. 10, 5039 (2019).
Mascie-Taylor, C. G. N. Spouse similarity for IQ and personality and convergence. Behav. Genet. 19, 223–227 (1989).
Caspi, A., Herbener, E. S. & Ozer, D. J. Shared experiences and the similarity of personalities: a longitudinal study of married couples. J. Personal. Soc. Psychol. 62, 281–291 (1992).
Yengo, L. et al. No evidence for social genetic effects or genetic similarity among friends beyond that due to population stratification: a reappraisal of Domingue et al (2018). Behav. Genet. 50, 67–71 (2019).
Tyrrell, J. Height, body mass index, and socioeconomic status: Mendelian randomisation study in UK Biobank. BMJ 352, i582 (2016).
Pedersen, K. M. et al. Smoking and increased white and red blood cells: a Mendelian randomization approach in the Copenhagen General Population Study. Arter. Thromb. Vasc. Biol. 39, 965–977 (2019).
Darrous, L., Mounier, N. & Kutalik, Z. Simultaneous estimation of bi-directional causal effects and heritable confounding from GWAS summary statistics. Nat. Commun. 12, 7274 (2021).
Stulp, G., Simons, M.J., Grasman, S. & Pollet, T.V. Assortative mating for human height: a meta-analysis. Am. J. Hum. Biol. 29, e22917 (2017).
Burgess, S., Butterworth, A. & Thompson, S. G. Mendelian randomization analysis with multiple genetic variants using summarized data. Genet. Epidemiol. 37, 658–665 (2013).
Millard, L. A. C., Davies, N. M., Gaunt, T. R., Smith, G. D. & Tilling, K. Software application profile: PHESANT: a tool for performing automated phenome scans in UK Biobank. Int. J. Epidemiol. 47, 29–35 (2018).
Purcell, S. et al. PLINK: a tool set for whole-genome association and population-based linkage analyses. Am. J. Hum. Genet. https://doi.org/10.1086/519795 (2007).
Pirastu, N. et al. Using genetic variation to disentangle the complex relationship between food intake and health outcomes. PLoS Genet. 18, e1010162 (2022).
Burgess, S., Small, D. S. & Thompson, S. G. A review of instrumental variable estimators for Mendelian randomization. Stat. Methods Med. Res. 26, 2333–2355 (2017).
Gao, X., Starmer, J. & Martin, E. R. A multiple testing correction method for genetic association studies using correlated single nucleotide polymorphisms. Genet. Epidemiol. 32, 361–369 (2008).
Hemani, G., Tilling, K. & Davey Smith, G. Orienting the causal relationship between imprecisely measured traits using GWAS summary data. PLoS Genet. 13, e1007081 (2017).
Hartwig, F. P., Davies, N. M. & Davey Smith, G. Bias in Mendelian randomization due to assortative mating. Genet Epidemiol. 42, 608–620 (2018).
Acknowledgements
For computations, we used the CHUV HPC cluster. We thank C. Auwerx, M. Sadler and A. van der Graaf for their valuable feedback on the manuscript. This research has been conducted using the UK Biobank Resource under Application Number 16389. Z.K. was funded by the Swiss National Science Foundation (310030-189147). The funders had no role in study design, data collection and analysis, decision to publish or preparation of the manuscript.
Funding
Open access funding provided by University of Lausanne.
Author information
Authors and Affiliations
Contributions
Z.K. devised and directed the project. J.S. and Z.K. contributed to the mathematical derivations, design and implementation of the research; to the analysis of the results; and to the writing of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Human Behaviour thanks Laurence Howe, Emily Willoughby and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Supplementary Information
Supplementary Figs. 1–3.
Supplementary Table 1
Summary of all age- and sex-specific results for all 118 traits. Phenotypic correlation among couples (pheno_couple_r2, pheno_couple_r, pheno_couple_r_se), MR estimates (n_exposure, n_outcome, IVW_beta, IVW_se, IVW_pval), differences between phenotypic estimates and MR estimates (couple_r_versus_IVW_diff_pval), sex-specific MR estimates and differences (sex_het_pval, IVW_beta_male, IVW_se_male, IVW_pval_male and female), and model estimates to assess the trend across bins by both age and time spent together for (1) MR estimates (weighted by SE), (2) Pearson correlations and (3) Spearman correlations (column names are given as bin_slope_beta, bin_slope_se, bin_slope_pval, with suffixes MR_wt, pearson and spearman to denote the different models and age and time_together to denote the different binning category). Note that n_pairs refers to the number of couples who each have data for the specified phenotype to compute couple correlations (couple_r2, couple_r and so on), n_exposure refers to the number of participants in the Neale models (sample size summed across men and women models) and n_outcome refers to the number of participants in the models estimating the effect of SNPs on the outcome of interest. Specifically, the model estimated the association between each genetic instrument measured in the index individual with the phenotype measured in the partner using the UKBB partner data set described. As these models were performed in males and females separately and do not require phenotype information for each partner, the result n_outcome is larger than n_pairs. All P values presented in this table come from two-sided P values.
Supplementary Table 2
Summary of the identified potential confounders. Of the 40 traits showing phenotypic correlations significantly larger than MR estimates, we were able to identify at least one potential confounder for all but one trait. Potential confounders were pruned to only those that had correlation with any other potential confounder (\(Y_{m}\)) <0.1, and the resulting C statistics were summed (C-sum).
Supplementary Table 3
Summary of the global confounding impact of six selected traits on phenotypic couple correlations. The confounding ratio corresponds to the ratio of correlation due to confounding over phenotypic correlation in couples (that is, \({\mathrm{C}}/{\mathrm{cor}}({\mathrm{X}}_{{\mathrm{i}}},{\mathrm{X}}_{{\mathrm{p}}})\), where \({\mathrm{C}} = {\upalpha}_{{\mathrm{y}} \to {\mathrm{x}}}^2 \times {\upalpha}_{{\mathrm{y}}_{{\mathrm{i}}} \to {\mathrm{y}}_{{\mathrm{p}}}}\)).
Supplementary Table 4
Summary of the 1,088 significant two-trait MR associations. Results are pruned such that pair A–B and C–D and if max(corr(A,C)corr(B,D),corr(A,D) × corr(B,C)) > 0.8, then one pair is dropped, prioritized by lower \(p_{{\hat{\omega}}}\). P values were computed based on a Z test (estimate difference divided by the s.e. of the parameter estimate differences).
Supplementary Table 5
Summary of the linear regression results comparing different mediated and total effects between traits across partners. P values come from a normal linear regression of this model of the form V ≈ ω + 0.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sjaarda, J., Kutalik, Z. Partner choice, confounding and trait convergence all contribute to phenotypic partner similarity. Nat Hum Behav 7, 776–789 (2023). https://doi.org/10.1038/s41562-022-01500-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41562-022-01500-w
This article is cited by
-
Genetic similarity between relatives provides evidence on the presence and history of assortative mating
Nature Communications (2024)
-
Participation bias in the UK Biobank distorts genetic associations and downstream analyses
Nature Human Behaviour (2023)
