
Abstract
The extent to which working memory training improves performance on untrained tasks is highly controversial. Here we address this controversy by testing the hypothesis that far transfer may depend on near transfer using mediation models in three separate randomized controlled trials (RCTs). In all three RCTs, totalling 460 individuals, performance on untrained N-back tasks (near transfer) mediated transfer to Matrix Reasoning (representing far transfer) despite the lack of an intervention effect in RCTs 2 and 3. Untrained N-back performance also mediated transfer to a working memory composite, which showed a significant intervention effect (RCT 3). These findings support a model of N-back training in which transfer to untrained N-back tasks gates further transfer (at least in the case of working memory at the construct level) and Matrix Reasoning. This model can help adjudicate between the many studies and meta-analyses of working memory training that have provided mixed results but have not examined the relationship between near and far transfer on an individual-differences level.
Similar content being viewed by others


Main
The potential that working memory (WM) training can transfer to untrained tasks that differ substantially from the training task (‘far transfer’) has generated substantial excitement with regard to better understanding the causal relationship between WM and related cognitive processes1,2,3,4,5,6, as well as to applied domains where such training can benefit health and well-being7,8,9,10. In particular, the effectiveness of WM training to improve fluid intelligence has been a controversial and highly debated topic, with some meta-analyses showing a small but significant positive effect on fluid intelligence11,12,13,14,15, while others argue that there is no evidence of generalization to fluid intelligence after training16,17. A difficulty in reconciling across different studies is that individual differences in performance and learning are ubiquitous in this literature and impact the average benefits18. Furthermore, training procedures and outcome measures differ greatly across studies, making meaningful comparisons challenging19.
One of the most common tasks used in these WM training studies is the N-back, an updating task that correlates significantly with measures of higher-level cognition, such as Matrix Reasoning20,21,22,23,24. While there is little doubt that N-back training leads to improved performance on untrained N-back tasks13,25,26,27, the extent to which this reflects the generation of performance strategies rather than improvement in monitoring and updating of WM content, or improved inhibition of items that are no longer relevant, remains unknown25. If we assume the former, we have little reason to expect post-test improvement on tasks that are not of the same structure as the N-back, such as Matrix Reasoning. However, if N-back training leads to enhanced efficiency of updating and/or inhibitory control (IC) processes, such far transfer effects would be plausible. From a theoretical perspective, ‘near’ transfer is thought to occur when the training task and outcome measure share many overlapping features and presumably recruit similar processes, whereas ‘far’ transfer refers to improved performance on outcome measures that share fewer features with the training task. While the boundaries between near and far transfer are not clear and probably fall on a continuum28, several meta-analyses of WM training studies have demonstrated that near transfer effects are more readily observable and show larger effect sizes than far transfer effects13,14. Likewise, neuroimaging research suggests that the frontostriatal system mediates near transfer effects, whereas the dorso- and ventrolateral prefrontal cortices seem to employ domain-general networks that facilitate learning more widely5.
Here we go beyond merely examining the effects of N-back training on Matrix Reasoning to attempt to understand how these effects occur in the first place29. We use mediation models because they represent a powerful tool for making theoretical predictions about causal mechanisms when applied to experimental data30. Specifically, we first present the results of a Retrospective study in which mediation models were used to evaluate whether the effects of N-back training on Matrix Reasoning are transmitted via changes in an untrained variant of the N-back. In addition, we used an IC task as a control measure for our analyses. Even though improvement in the training task itself may also serve as a useful mediator31, this information is not available for control groups, nor is it necessarily indicative of near transfer. We hypothesized that N-back training groups would improve on Matrix Reasoning (far transfer) compared with no-contact control groups, and furthermore that this effect would be mediated by post-test performance on an untrained N-back task (near transfer). This model enabled us to account for individual differences in responsiveness to WM training and subsequent transfer to untrained tasks, and to demonstrate that transfer to Matrix Reasoning tasks is completely mediated by near transfer in two independent randomized control trials (RCTs) collected over two academic years. Since demand characteristics during training and potential placebo effects were not controlled for in the Retrospective study, we further report the results of a double-blind, pre-registered Replication study with an active control group in which we replicate the finding that performance on untrained N-back tasks mediates transfer to Matrix Reasoning and extend the discussion to other tasks and domains.
Results
Retrospective study (RCT 1 and RCT 2)
Conventional general linear model analyses test for differences in means of different groups on one independent variable and therefore cannot be used to test our theoretical model in which a given training intervention leads to far transfer completely or partially through near transfer gains. Instead, we use mediation models with the following hypothesized sequence of events: random group assignment (N-back training or control group) affects untrained N-back performance, which subsequently affects Matrix Reasoning performance. As a control analysis, performance on the Countermanding task (which also showed some training-related benefits) is entered as a parallel mediator to pit competing mechanisms against each other. We first evaluate the Retrospective study as a whole sample and then apply parallel two-mediator models separately for each RCT.
Whole sample
The linear regression results shown in Table 1 provide evidence that training group was a statistically significant predictor of post-test performance on Matrix Reasoning, even after controlling for pre-test performance on Matrix Reasoning, N-back and Countermanding. All variables except training group (0 = no-contact control, 1 = N-back training) were z-transformed to account for study-specific differences in unit of measurement.
After post-test N-back and Countermanding were added as parallel mediators (Fig. 1a), the total effect (TE) of training group on post-test Matrix Reasoning performance remained statistically significant (TE = 0.23; s.e. = 0.10; p = 0.02); the 95% confidence interval (CI) of this effect was [0.03, 0.43], with a partially standardized effect size (ESp.s.) of 0.21, and a coefficient of determination (R2) of 0.50. Training group was a statistically significant predictor of performance on post-test N-back (B = 1.05; p < 0.001; 95% CI [0.80, 1.31]), and post-test N-back was in turn a statistically significant predictor of performance on post-test Matrix Reasoning (B = 0.18; p < 0.001; 95% CI [0.09, 0.28]). A bootstrap CI for the indirect effect (IE) based on 5,000 bootstrap samples did not include zero (IE = 0.19; s.e. = 0.05; 95% CI [0.09, 0.31]), providing evidence for statistically significant mediation via post-test N-back. While training group was a statistically significant predictor of post-test reaction time (RT) performance on the Countermanding task (B = −0.25; p = 0.01; 95% CI [−0.46, −0.05]), we found no statistically significant evidence that post-test Countermanding performance predicted post-test Matrix Reasoning (B = 0.07; p = 0.214; 95% CI [−0.04, 0.19]) nor any evidence of a statistically significant IE of training group on post-test Matrix Reasoning with Countermanding performance as a mediator (IE = −0.02; s.e. = 0.02; 95% CI [−0.06, 0.01]). Moreover, the two IEs, via post-test N-back and via post-test Countermanding, were statistically significantly different from each other (IE = 0.21; s.e. = 0.06; 95% CI [0.09, 0.34]). These results suggest that the causal effect of training group (no-contact control or N-back training) on Matrix Reasoning is mediated by the extent to which participants improve on near transfer. To determine the reproducibility of these results, the same analyses were conducted on the two independent RCTs.

a, Retrospective study, whole sample (n = 271). b, Retrospective study, RCT 1 (n = 94). c, Retrospective study, RCT 2 (n = 177). In all models, the independent variable is training group (N-back training or no-contact control), the mediators are post-test N-back and Countermanding performance, and the dependent variable is post-test Matrix Reasoning performance. The path coefficients are standardized regression coefficients with p values reported in parentheses. Bold text indicates statistical significance. No corrections for multiple comparisons were made. The covariates (not displayed) were pre-test N-back, pre-test Countermanding and pre-test Matrix Reasoning.
RCT 1
In RCT 1, the linear regression results revealed that training group was a statistically significant predictor of post-test Matrix Reasoning (B = 0.05; p = 0.048; 95% CI [0.00, 0.10]; R2 = 0.50) after controlling for pre-test Matrix Reasoning, N-back and Countermanding. In the mediation analysis (Fig. 1b), the TE of training group on Matrix Reasoning was also statistically significant (TE = 0.40; s.e. = 0.20; p = 0.048; 95% CI [0.003, 0.79]; ESp.s. = 0.35; R2 = 0.50). Training group predicted performance on post-test N-back (B = 1.07; p < 0.001; 95% CI [0.50, 1.63]), which in turn predicted performance on post-test Matrix Reasoning (B = 0.17; p = 0.023; 95% CI [0.02, 0.32]). A bootstrap CI for the specific IE did not include zero (IE = 0.19; s.e. = 0.09; 95% CI [0.03, 0.40]), providing evidence for statistically significant mediation. In contrast, there was no statistically significant evidence that performance on the Countermanding task mediated the relationship between training group and Matrix Reasoning (IE = −0.02; s.e. = 0.04; 95% CI [−0.12, 0.05]). The two IEs differed significantly from each other (IE = 0.20; s.e. = 0.11; 95% CI [0.01, 0.46]).
RCT 2
In RCT 2, the linear regression results provided no statistically significant evidence that training group predicted post-test Matrix Reasoning (B = 0.03; p = 0.15; 95% CI [−0.01, 0.07]; R2 = 0.51) after controlling for pre-test Matrix Reasoning, N-back and Countermanding. Likewise, in the mediation analysis (Fig. 1c), there was no evidence of a statistically significant TE of training group on Matrix Reasoning (TE = 0.17; s.e. = 0.12; p = 0.15; 95% CI [−0.06, 0.40]; ESp.s. = 0.16; R2 = 0.51). Nevertheless, training group was a statistically significant predictor of performance on post-test N-back (B = 1.06; p < 0.001; 95% CI [0.77, 1.34]), and post-test N-back was in turn a statistically significant predictor of performance on post-test Matrix Reasoning (B = 0.20; p = 0.002; 95% CI [0.07, 0.32]) after controlling for baseline performance on each test. At post-test, all three outcome measures correlated significantly with each other (Supplementary Table 1), yet only the IE through the N-back task was significant (IE = 0.21; s.e. = 0.07; 95% CI [0.07, 0.36]), whereas there was no evidence of a significant IE through the Countermanding task (IE = −0.02; s.e. = 0.02; 95% CI [−0.07, 0.02]). The two IEs differed significantly from each other (IE = 0.23; s.e. = 0.09; 95% CI [0.07, 0.41]).
Consider two participants from this RCT who were assigned to the same training condition and who showed a similar training gain of about two N-levels (S102gain = 2.25; S105gain = 2.17) yet showed very different transfer to Matrix Reasoning: S105 showed no change at post-test relative to pre-test in terms of accuracy, whereas S102 showed improved accuracy at post-test. Examining the untrained N-back results reveals that S105 did not show evidence of near transfer, which may explain the lack of transfer to Matrix Reasoning, whereas S102 showed near transfer. In this case, training gain has little predictive validity towards Matrix Reasoning outcomes. It remains to be determined why these participants showed such different patterns of results, but it is possible that individual differences in strategy sophistication32 and/or motivation33 affected training outcomes.
Alternative mediation models
To test the hypothesis that N-back gains also mediate other aspects of transfer, we tested whether post-test N-back mediated the relationship between training group and post-test Countermanding performance (Extended Data Fig. 1). This was found in the whole sample (IE = −0.23; s.e. = 0.09; 95% CI [−0.42, −0.08]) and in RCT 2 (IE = −0.28; s.e. = 0.12; 95% CI [−0.55, −0.08]), but there was no statistically significant evidence that post-test N-back mediated the relationship between training group and post-test Countermanding in RCT 1 (IE = −0.19; s.e. = 0.12; 95% CI [−0.46, 0.01]).
Specific training effects and near transfer—N-back
Substantial individual differences in N-back performance were observed both as a function of training progression and at pre/post-test. For the N-back training groups, the mean N-level on the first day of training ranged from 2.00 to 6.44 in RCT 1 and from 1.12 to 4.84 in RCT 2. While these results suggest large individual differences in performance of all groups, training gain showed even greater variability: on the last day of training, the mean N-level ranged from 1.76 to 11.37 in RCT 1 and from 2.00 to 11.00 in RCT 2, with increasing variability as a function of training time (Extended Data Fig. 2). Larger training gain was associated with larger gains on the untrained N-back task in both RCTs (Supplementary Table 2).
No evidence of statistically significant baseline differences between N-back training and control groups was observed for the untrained N-back task (average accuracy across 2-back and 3-back levels; called Near Transfer hereafter) within each RCT (Supplementary Table 3). In RCT 1, pre-test accuracy on the Near Transfer task ranged from 0.42 to 0.93 in the no-contact control group and from 0.18 to 1.0 in the N-back training group. In RCT 2, pre-test accuracy on the Near Transfer task ranged from 0.22 to 0.82 for the no-contact control group and from 0.27 to 0.85 for the N-back training group. When we examined pre–post effect sizes (ES) across RCTs 1 and 2, the no-contact control groups showed little or no improvement at post-test relative to pre-test on Near Transfer, whereas the N-back training groups showed a substantial increase in accuracy on this task (ES = 0.80 to 0.92) (Table 2).
Far transfer effects
At pre-test, Near Transfer performance showed a statistically significant relationship with Countermanding and Matrix Reasoning performance in RCTs 1 and 2 (Supplementary Table 4; see Extended Data Fig. 3 for the scatter plots). Post-test scatter plots demonstrating relationships among the main outcome measures are shown in Extended Data Fig. 4 for RCT 1 and in Extended Data Fig. 5 for RCT 2. No evidence of statistically significant baseline differences between the N-back training and control groups was observed for Matrix Reasoning or Countermanding (Supplementary Table 3). The two N-back training groups showed small performance benefits on Matrix Reasoning (ES = 0.43 to 0.49), whereas the control groups showed negligible change in performance (ES < 0.20). Furthermore, the N-back training groups, but not the control groups, showed a decrease in average RT on incongruent trials of the Countermanding task, an index of IC, particularly in RCT 2 (ES = 0.44) (Table 2).
Given that near and far transfer effects were measured with single tasks, we recognize that the results might still reflect task-specific learning to some extent, and as such, we make no claims on the mental constructs of WM, response inhibition and fluid intelligence. Furthermore, due to the use of no-contact controls, it is possible that some of the performance advantage of the N-back training groups stems from non-specific characteristics of the training protocol, such as participant and/or experimenter expectancies and experimenter contact34. Even though a recent meta-analysis found no meaningful performance difference between no-contact and active controls35, we decided to conduct a pre-registered, double-blind Replication study using an active control group to control for these effects. Furthermore, we expanded the test battery to extend the analyses to other outcome measures and to be able to generate composite scores for each domain.
Pre-registered Replication study (RCT 3)
In RCT 3, the analytical sample consisted of 189 participants: 128 participants completed 20 sessions of N-back training, whereas 61 participants completed 20 sessions of general knowledge training (active control). The N-back training group showed similar gains on Near Transfer (ES = 1.52), Matrix Reasoning (ES = 0.46) and Countermanding (ES = 0.39) (Table 3) as the training groups in the Retrospective study (RCT 1 and RCT 2). The basic assessment battery was expanded to include four additional WM tasks (Running Span, Sequencing, Simple Span and Complex Span), one additional measure of executive function (UCancellation) and three additional measures of spatial reasoning (ETS Surface Development, ETS Space Relations and DAT Form Board) to be able to construct composite scores in the three domains of interest. We first present a replication of the two-mediator parallel model, followed by models in which composite scores are entered as mediators and, finally, models in which a composite score represents the outcome variable.
On the basis of the linear regression results (Table 1), we found no statistically significant evidence that training group predicted post-test performance on Matrix Reasoning after controlling for pre-test performance on Matrix Reasoning, N-back and Countermanding. Likewise, in the mediation analysis (Fig. 2a), there was no evidence of a significant TE of training group on Matrix Reasoning (TE = 0.07; s.e. = 0.11; p = 0.51; 95% CI [−0.14, 0.28]; ESp.s. = 0.07; R2 = 0.60). Note that a simple association between independent and dependent variables is not necessary for mediation analysis36. The parallel mediation model replicates the findings from the Retrospective study: training group was a statistically significant predictor of performance on post-test N-back (B = 1.34; p < 0.001; 95% CI [1.08, 1.60]), and post-test N-back was in turn a statistically significant predictor of performance on post-test Matrix Reasoning (B = 0.20; p < 0.001; 95% CI [0.08, 0.31]) after controlling for baseline performance on each test. A bootstrap CI for the specific IE through post-test N-back did not include zero (IE = 0.26; s.e. = 0.08; 95% CI [0.10, 0.43]), showing evidence for significant mediation. There was no statistically significant evidence that performance on the Countermanding task mediated the relationship between training group and Matrix Reasoning (IE = 0.04; s.e. = 0.03; 95% CI [−0.004, 0.11]), which is in line with the results obtained in the Retrospective study. These results provide further evidence that transfer to untrained N-back tasks is a vital mediator through which the N-back training intervention affects improved performance on Matrix Reasoning. Moreover, post-test performance on the untrained N-back preceded performance on Matrix Reasoning by one day, hence satisfying the recommendation that the mediator must intervene between the predictor and the outcome37. The same pattern of results was obtained when the two mediators were replaced with composite scores (Fig. 2b). Note that the sample size for this and subsequent analyses is smaller (n = 170) due to outliers removed on WM and IC tasks. Post-test WM Composite 1, which includes the N-back task, significantly mediated transfer to Matrix Reasoning (IE = 0.11; s.e. = 0.05; 95% CI [0.02, 0.22]), whereas we found no evidence of statistically significant mediation via the IC Composite (IE = 0.05; s.e. = 0.04; 95% CI [−0.003, 0.14]), thus replicating and extending the basic parallel model.

a, RCT 3 (n = 189). The mediators are post-test N-back and Countermanding. b, RCT 3—analytical subset (n = 170). The mediators are WM Composite 1 (consisting of N-back, Sequencing, Simple Span and Complex Span) and IC Composite (consisting of Countermanding and UCancellation). c, RCT 3—analytical subset (n = 170). The mediators are WM Composite 2 (consisting of Sequencing, Simple Span and Complex Span) and the IC Composite. In all models, the independent variable is training group (N-back training or active control), and the dependent variable is post-test performance on Matrix Reasoning, with pre-test data for all included measures entered as covariates. The path coefficients are standardized regression coefficients with p values reported in parentheses. Bold text indicates statistical significance. No corrections for multiple comparisons were made.
A question that arises is whether Matrix Reasoning is mediated solely by N-back or whether other WM measures contribute to the mediation as well. A multiple parallel mediation model (Fig. 3a) showed that post-test N-back was the only significant mediator of Matrix Reasoning performance (IE = 0.22; s.e. = 0.09; 95% CI [0.07, 0.41]). The IE via post-test N-back was significantly different from all other IEs (N-back versus Running Span: IE = 0.22; s.e. = 0.09; 95% CI [0.06, 0.41]; N-back versus Sequencing: IE = 0.22; s.e. = 0.09; 95% CI [0.06, 0.41]; N-back versus Simple Span: IE = 0.22; s.e. = 0.09; 95% CI [0.06, 0.41]; N-back versus Complex Span: IE = 0.21; s.e. = 0.09; 95% CI [0.04, 0.40]). Given these results, it is not surprising that WM Composite 2, which does not include N-back or Running Span, did not show a statistically significant mediation of the relationship between training group and transfer to Matrix Reasoning performance (IE = 0.006; s.e. = 0.004; 95% CI [−0.012, 0.015]), and neither did the IC Composite (IE = 0.011; s.e. = 0.007; 95% CI [−0.001, 0.027]) (Fig. 2c).

a, Parallel multiple-mediator model. The mediators are post-test N-back, Running Span, Sequencing, Simple Span and Complex Span tasks. b, Serial mediator model in which the first mediator is post-test N-back and the second is WM Composite 2, consisting of the Sequencing, Simple Span and Complex Span tasks. c, Serial mediator model in which the first mediator is post-test N-back and the second is the IC Composite, consisting of the Countermanding and UCancellation tasks. In all models, the independent variable is training group (N-back training or active control), and the dependent variable is post-test performance on Matrix Reasoning, with pre-test data for all included measures entered as covariates. The path coefficients are standardized regression coefficients with p values reported in parentheses. Bold text indicates statistical significance. No corrections for multiple comparisons were made. RCT 3—analytical subset (n = 170).
In the literature, the untrained N-back task is often seen as very near transfer, while structurally different WM tasks are classified as near transfer and non-WM tasks as far transfer13, implying a serial relationship among these task domains. While unlikely given the above results, a serial mediation model, in which the first mediator was post-test N-back and the second mediator was post-test WM Composite 2, was conducted to test this exploratory hypothesis (Fig. 3b). As expected, the indirect specific effect via the untrained N-back was significant (training group → N-back → Matrix Reasoning: IE = 0.20; s.e. = 0.09; 95% CI [0.04, 0.39]), whereas we found no evidence of a significant IE when the model included WM Composite 2 as a mediator (training group → WM Composite 2 → Matrix Reasoning: IE = 0.01; s.e. = 0.02; 95% CI [−0.03, 0.05]; training group → N-back → WM Composite 2 → Matrix Reasoning: IE = 0.02; s.e. = 0.02; 95% CI [−0.01, 0.06]).
Since overriding dominant or prepotent responses is also required during N-back training (for example, when switching N-levels, the player must inhibit responses related to the previous level), and this may play a role in solving Matrix Reasoning tasks, we replaced the second mediator (WM Composite 2) with the IC Composite (Fig. 3c). The results showed that only the path via N-back significantly mediated transfer to Matrix Reasoning (training group → N-back → Matrix Reasoning: IE = 0.21; s.e. = 0.09; 95% CI [0.05, 0.38]), whereas there was no evidence that the two IEs that included the IC Composite were significant (training group → IC Composite → Matrix Reasoning: IE = 0.04; s.e. = 0.03; 95% CI [−0.01, 0.12]; training group → N-back → IC Composite → Matrix Reasoning: IE = 0.02; s.e. = 0.02; 95% CI [−0.01, 0.05]). Overall, single-mediator models explained the data better than serial models. Note that the serial mediation models were not pre-registered and were added post hoc.
There is no statistically significant evidence that N-back training led to improved performance on other measures of visuospatial reasoning (ETS and DAT tests) relative to the active control group (Table 3). Nevertheless, as planned during pre-registration, we ran a mediation model in which post-test N-back and Countermanding were entered as mediators and the outcome variable was a fluid intelligence composite (Gf), which consisted of Matrix Reasoning, ETS and DAT tests. While training group (N-back training or active control) predicted performance on post-test N-back (B = 1.22; p < 0.001; 95% CI [0.95, 1.49]) and on post-test Countermanding (B = −0.22; p = 0.01; 95% CI [−0.39, −0.05]), we found no evidence that N-back (IE = 0.03; s.e. = 0.05; 95% CI [−0.06, 0.13]) or Countermanding (IE = 0.03; s.e. = 0.02; 95% CI [0.0002, 0.08]) was a statistically significant predictor of performance on the Gf Composite after controlling for baseline performance on these tests. The same pattern of results was obtained when WM Composite 1 and the IC Composite were entered as mediators (Fig. 4a).

a–c, In each model, the independent variable is training group (N-back training or active control), and the dependent is Gf Composite (a), WM Composite 2 (b) or IC Composite (c), with pre-test measures entered as covariates. The path coefficients are standardized regression coefficients with p values reported in parentheses. Bold text indicates statistical significance. No corrections for multiple comparisons were made. RCT 3—analytical subset (n = 170).
Alternative mediation models
Taking a step back, we investigated whether N-back-training-related changes are observed in WM tasks beyond the untrained N-back and what the mechanisms might be that support this process. Specifically, we tested whether performance on the untrained N-back mediates transfer to a WM composite consisting of sequencing and spatial span tasks, called WM Composite 2, while entering post-test Countermanding as a control mediator (Fig. 4b). The results showed that the IE through the untrained N-back was statistically significant (IE = 0.20; s.e. = 0.06; 95% CI [0.07, 0.30]), but there was no evidence of statistically significant mediation via Countermanding (IE = 0.01; s.e. = 0.02; 95% CI [−0.04, 0.05]). In addition, the TE of training group on post-test WM Composite 2 performance was statistically significant (TE = 0.21; s.e. = 0.09; p = 0.03; 95% CI [0.02, 0.39]; ESp.s. = 0.28; R2 = 0.43). These results suggest that the effectiveness of the N-back training intervention to improve WM skills depends on the extent to which an individual shows improvement on untrained N-back tasks. The same results were obtained when the Countermanding mediator was replaced with an IC Composite consisting of the Countermanding and UCancellation tasks (IE via IC = 0.03; s.e. = 0.02; 95% CI [−0.02, 0.08]).
We also ran a mediation model in which the IC Composite was entered as the dependent variable. There was no evidence that the indirect specific effects via the untrained N-back (IE = 0.05; s.e. = 0.05; 95% CI [−0.04, 0.15]) and WM Composite 2 (IE = 0.02; s.e. = 0.02; 95% CI [−0.01, 0.06]) were statistically significant. However, the TE of training group on IC was statistically significant (TE = 0.25; s.e. = 0.08; p = 0.002; 95% CI [0.09 to 0.40]; ESp.s. = 0.29; R2 = 0.69), suggesting that N-back training boosted IC performance relative to control training (Figs. 4c and 5c).

a, WM Composite 1, consisting of the N-back, Sequencing, Simple Span and Complex Span. b, WM Composite 2, consisting of Sequencing, Simple Span and Complex Span. c, IC composite, consisting of Countermanding and UCancellation. d, Gf Composite, consisting of UCMRT, ETS Surface Development, ETS Space Relations and DAT Form Board. The data are presented as mean values ± s.e.m., plotted separately for the N-back training (filled circles; n = 115) and active control (empty circles; n = 55) groups.
Specific training effects and near transfer
The N-back training group in RCT 3 showed similar training performance as in the Retrospective study, particularly with respect to RCT 2 (Extended Data Fig. 2). The mean N-level on the first day of training ranged from 2.00 to 3.94 and on the last from 2.00 to 14.33. Likewise, individual differences were observed in the Near Transfer task, with pre-test accuracy ranging from 0.22 to 0.95 in the active control group and from 0.23 to 0.95 in the N-back training group.
Far transfer effects
At pre-test, Near Transfer performance showed a statistically significant relationship with Countermanding and Matrix Reasoning performance (Supplementary Table 5; see Extended Data Fig. 6a–c for the scatter plots), which is in line with the findings reported for the Retrospective study. Post-test correlation statistics are shown in Supplementary Table 6, and scatter plots are shown in Extended Data Fig. 6d–f. No evidence of baseline differences between the N-back training and active control groups was observed for Matrix Reasoning or any of the other outcome measures (Supplementary Table 3). To confirm the results of the mediation analyses, Bayesian repeated-measures analyses of variance with the within-participants factor time (pre or post) and the between-participants factor group (control or N-back training) were conducted on composite scores (not pre-registered). Inclusion Bayes factors across matched models (BFincl) were used to evaluate evidence of time × group interactions. Statistically significant interactions in favour of the N-back training group were obtained for WM Composite 1 (BFincl > 100), WM Composite 2 (BFincl = 2.46) and the IC Composite (BFincl = 9.59), but there was no evidence of a statistically significant interaction effect for the Gf Composite (BFincl = 0.22) (Fig. 5), which is in line with the results reported above.
Discussion
Previous studies have examined the relationship between training gain and far transfer, typically by comparing subgroups of participants who show low versus high training gain31,38,39; however, this type of responder analysis can be problematic40. Here we demonstrate that there are alternative ways of analysing transfer data that do not involve dichotomization and may reveal concealed associations and mechanisms to explain the effects of training. We obtained inconsistent results for the overall intervention effects on Matrix Reasoning across three RCTs; however, all RCTs, involving a total of 460 participants, showed that the extent of transfer to untrained N-back tasks determines transfer to Matrix Reasoning. This result may explain some of the variability seen in the literature that reports only sporadic transfer to these types of tasks. Transfer to untrained N-back tasks is often not reported; therefore, information is often missing about what participants learned, and the extent of learning on measures of transfer thus remains unknown. For example, in a meta-analysis of WM training studies13, 35 experiments measured fluid intelligence, 28 experiments assessed WM (including tasks that correlate poorly with the N-back24) but only 9 experiments also included untrained N-back tasks. In another meta-analysis of N-back training studies, only 37% of N-back training studies reported using N-back tasks as an outcome measure19; thus, for the majority of studies, information is missing about what participants gained. If we do not know whether the minimal amount of near transfer occurred (for example, to a different stimulus set), then how can we gauge improvements in WM and measures beyond WM such as fluid intelligence or IC tasks?
The Retrospective WM training study using a no-contact control group confirmed our theoretical prediction that if N-back training improves performance on untrained N-back tasks, this will in turn lead to transfer to Matrix Reasoning, as demonstrated by a significant mediation effect and a significant total (intervention) effect. Note that the TE was demonstrated for the whole sample, but when examined separately for each of the two RCTs, it was demonstrated only for RCT 1. These results imply that N-back training does not merely enhance task-specific strategies but may lead to changes in underlying components of WM, such as the capacity of the focus of attention41 or updating42, which in turn can support performance on Matrix Reasoning problems43. Understanding how this occurs is a challenge, which is constrained by the lack of agreement about why WM and measures of fluid intelligence, and in particular, Matrix Reasoning, correlate positively in the first place. One explanation suggests that WM is needed to maintain rules in mind to successfully solve Matrix Reasoning problems44. However, this was not supported in a subsequent study; instead, the ability to manage proactive interference seemed to play a role in both constructs45. Similarly, it has been shown that WM helps keep previously learned rule combinations from interfering when solving problems that require a new rule combination46,47. However, since we found no evidence that IC mediated transfer to Matrix Reasoning, our results do not support interference-type accounts. Recent evidence also challenges these accounts, showing that the relationship between WM capacity and Matrix Reasoning can be explained by individuals’ ability to maintain how they solved previous problems in memory48. Our results are therefore in line with research showing that updating42 and executive attention49 show strong relations with Matrix Reasoning performance. Finally, it has been argued that WM and fluid intelligence are complementary processes that promote complex cognition, wherein the first reflects maintenance and the other disengagement, and both serve a single top-down executive attention50. Extending this to the neural level, it is plausible that transfer occurs if the training and transfer tasks engage overlapping processes and neural circuits26,51.
To verify this finding using a more rigorous design, we pre-registered a double-blind Replication study and included an active control group, which was conducted online due to a ban on in-person research amid the COVID-19 pandemic. Furthermore, we investigated whether the mediation model replicates using composite scores of WM, IC and fluid intelligence as outcome measures. This study provided three key findings. First, we replicated the finding that transfer to Matrix Reasoning depends on the extent to which individuals show near transfer as measured by performance on untrained N-back tasks, even after controlling for participant and/or experimenter expectancies with the use of an active control group and full blinding procedures. Overall, this finding has now been observed in three independent RCTs that included a total of 460 individuals. While a significant total (intervention) effect on Matrix Reasoning was observed for the whole sample in the Retrospective study, this was not observed in the Replication study (RCT 3). Here, it is important to note that the mediated effect and the non-significant intervention effect each provide valuable information about how an intervention achieved (or failed to achieve) its effects; therefore, it is critical to discuss both types of effects. There is evidence to suggest that in certain situations, mediated effects can be statistically significant in the absence of a TE. For example, the power of mediation is probably greater than the power of the test of the TE, because the mediator (the untrained N-back) is more closely related to the outcome measure (Matrix Reasoning) than the intervention is, and it was measured more closely in time with the outcome measure than the intervention52. In addition, it has been shown that the intervention can exert an IE on the outcome measure through a mediator in the absence of an association between these two variables, for example in the case of a crossover interaction53.
It remains to be determined why some individuals show no or very little near transfer. It is possible that the individuals in our sample had low achievement motivation42,43, showed little engagement with the task or applied inefficient strategies during training44, resulting in poor WM training performance and, consequentially, limited near transfer. On the basis of subjective observation of the young-adult college student population that is represented in the sample, we note that they are at times sleep deprived, experience stress and anxiety, and adopt strategies of disengagement as the novelty of tasks wears off. Critically, the pre-registered Replication study was conducted remotely, with participants completing sessions in their home environments during social distancing amid the COVID-19 pandemic. It is now well documented that the pandemic was associated with widespread emotional and mental distress and increased risk for psychiatric illness54,55. Elevated levels of COVID-19-related anxiety have also been associated with poorer WM performance as measured by N-back tasks56. In our population, it was typical for students to have limited personal space and numerous home responsibilities and distractions, which may have increased the proportion of participants that were motivated to complete the study so that they would receive payment, but perhaps were not motivated or able to perform their best on the assigned tasks. This may explain the lack of an intervention effect on Matrix Reasoning in the Replication study (RCT 3). While these effects are clear from observation, we are still working on how to best characterize these factors objectively to more effectively disentangle participants who may ‘tune out’ from those who may be engaged but not learning. For now, the mediation analysis presented here is a first approach to addressing their contributions to the mean effects.
A second finding is that no WM measure other than the N-back task mediated transfer to Matrix Reasoning, even though post-test performance on all WM tasks except for Running Span correlated significantly with Matrix Reasoning performance (Supplementary Table 6). Span-based WM tasks might not share enough variance with Matrix Reasoning to explain individual differences in transfer, or the gain on these tasks might not be meaningful enough to have an observable effect on transfer.
A third finding is that N-back training led to small but significant improvements in a WM composite consisting of sequencing and span-based tasks and to enhanced IC performance relative to control training, as evidenced by statistically significant intervention effects. Untrained N-back performance mediated transfer to the WM composite, but there was no evidence of statistically significant mediation via the IC composite. Transfer to sequencing and/or complex WM tasks has been reported by some57,58,59,60,61,62,63 but not other N-back training studies58,64,65,66,67,68,69,70. Likewise, there is no consensus regarding transfer to IC measures, with some WM training studies reporting training-related benefits59,60,71,72 but others failing to find evidence of transfer51,73. Note that previous research often included Stroop tasks as an IC measure, whereas here we used a composite score based on speed of IC and a timed test of selective attention. Along with using a consistent set of measures across studies19, another solution that could bring some clarity is examining individual differences in training and transfer with mediation and moderation analyses. For example, the results of exploratory serial mediation showed that viewing the untrained N-back as very near transfer, which in turn affects transfer to other WM tasks or to an IC composite, and finally to Matrix Reasoning, does not explain the results. Instead, training-related improvement in IC could be seen as a separate form of (far) transfer, and the processes that underly this change seem to be somewhat independent.
There was no evidence of systematic change in a composite of Gf tasks as a function of WM training, and N-back performance did not seem to mediate transfer to this composite; therefore, we make no claims of transfer to fluid intelligence at the construct level. The Matrix Reasoning task used here (called UCMRT) has been shown to correlate highly with performance on Raven’s Advanced Progressive Matrices74; however, the correlations between UCMRT and the spatial visualization measures used here were much lower, especially for Surface Relations and Form Board (Supplementary Table 5), suggesting that the tasks share few commonalities. While UCMRT requires some spatial visualization, it is thought to tap mainly into abstract reasoning and logical problem solving. It is thus possible that UCMRT captures variance that is shared with the N-back but is different from the spatial visualization tasks used here. Of note, the Replication study showed a significant intervention effect as well as significant mediation to the WM composite, and thus, a relevant contribution of the paper is that near transfer after WM training mediates far transfer, which is not challenged by the fact that the Gf Composite did not show an effect. We consider both the Matrix Reasoning task and the WM composite as far transfer because they consist of tasks that are substantially different from the training task. These results are in line with the finding that training-induced changes in WM capacity in children explain considerable parts of the intervention effect of WM training on far transfer75. Because we did not perform follow-up assessments, we do not know how long any of the transfer effects last; however, there is some evidence to suggest that such effects are long-term76,77.
A limitation of the Replication study (RCT 3) is that due to the COVID-19 pandemic, we were not able to conduct it in the lab; therefore, we were not able to completely match the conditions of the Retrospective study (RCT 1 and RCT 2). The participants completed the study on their own devices at home and were instructed to find a quiet environment for each session; however, it is likely that more distractions occurred compared with a controlled laboratory setting. That said, in the Retrospective study, multiple participants completed assessment and training sessions in the same room; thus, even this environment wasn’t distraction-free. The level of supervision was different across studies given that all training sessions were supervised in the Retrospective study and only the first training session was supervised in the Replication study (or more, if needed). Given that the training curves for RCT 2 and RCT 3 are highly similar, yet both show slightly lower average training performance than that for RCT 1 (Extended Data Fig. 2), it is possible that factors besides the extent of supervision, such as small changes in the game mechanic or adoptive algorithm implemented after RCT 1 had concluded, affected these results. Furthermore, a recent comparison of cognitive assessment and training studies conducted in the lab and remotely via videoconferencing revealed similar compliance and performance rates78. Another limitation is the young age of the sample in all three RCTs. Therefore, the extent to which the current results can be generalized to the many studies examining the effects of cognitive training in populations with diverse cognitive needs remains to be clarified.
Overall, our findings challenge the notion that WM training leads to performance gains only in tasks that are closely related to the training79 and indicate that performance in untrained N-back tasks provides information regarding the effectiveness of an N-back intervention and should therefore be included as an outcome measure in future work. It remains to be seen whether a similar association between untrained tasks and transfer applies to other types of cognitive training paradigms or other types of transfer measures, including those capturing real-world performance. Moreover, these results can inform studies examining neuroplastic changes associated with WM interventions, predicting weaker far transfer effects in individuals who show little to no near transfer, in terms of behaviour and related plastic neural changes. From a practical perspective, a near transfer test administered halfway or early in the WM training intervention could indicate the likelihood of far transfer. If participants struggle in near transfer tasks at this point, and far transfer therefore seems unlikely, pivoting to a different type of intervention or providing additional support in terms of effective strategy use80 could be beneficial to study outcomes (but see ref. 81). This simple yet presently untested step could help maximize the effectiveness of WM training interventions.
In sum, it is not surprising that inter-individual differences in responsiveness to WM training interventions exist82,83—in non-invasive brain stimulation studies84,85 and other intervention studies, such as those focusing on physical exercise or nutrition86,87,88,89, ‘non-responders’ are routinely excluded from data analyses or treated differently. To fully understand the underlying mechanisms of WM training, future research should depart from the traditional approach that attempts to determine whether an effect is present or not, and instead focus on how, for whom and why these effects occur31,90. With the rise of precision medicine91, investigating the efficacy of personalized cognitive training interventions92,93 will become increasingly important and ultimately maximize intervention outcomes.
Methods
Retrospective study (RCT 1 and RCT 2)
Participants
Our sample consisted of 283 participants from the Universities of California, Riverside and Irvine, collected over two academic years: winter–spring 2017 (nRCT1 = 102) and fall 2017–spring 2018 (nRCT2 = 181). The participants were randomly assigned either to N-back training (n = 191) or to no-contact control (n = 92) and completed all sessions in laboratories at the respective universities. They were included in the analysis if they completed all pre- and post-assessments as well as at least eight out of ten training days (N-back training group). Note that unequal sample sizes reflect randomization to multiple training conditions and one no-contact condition. The sample demographics are reported in Supplementary Table 7. The sample was relatively diverse, with 31–40% of participants identifying as Hispanic or Latinx and 42–44% identifying as Asian (Supplementary Table 8). The participants provided informed consent and received US$120 compensation for participation; all procedures were approved by the University of California, Riverside Institutional Review Board for Human Subjects Research.
Procedure
Training and testing were administered on tablet computers via publicly available software that was developed in-house (Recollect the Study94), in combination with Qualtrics Software used to administer surveys and certain assessments (Qualtrics). The same software for testing and training was used in both RCTs. The participants completed pre- and post-tests with a ten-day gap (excluding weekends); in addition, the N-back training groups completed up to ten working days of training. Across both RCTs, a variety of assessment tasks were used, including measures of WM, selective attention, mathematical problem solving, decision making and convergent thinking; however, to maximize power, here we focus only on the results of the three tasks that were used by both RCTs and that did not undergo major changes from one year to the next. Many of the measures not included here were being continuously developed for the use of tablets and were included in the studies for validation purposes. Moreover, our goal was to test the specific hypothesis that a simple mediation model focusing on the N-back and Matrix Reasoning can explain a substantial amount of variance in the data.
Training tasks
N-back training
The participants trained on an N-back task (Recollect the Study94) for ten working days, each day consisting of two 20-minute training sessions separated by a 10- to 20-minute break. The training parameters were varied in that they differed in terms of N-level progression, gamification and reinforcement, but since these are not relevant to the present hypothesis, the data were collapsed across N-back training conditions. To provide context, in gamified N-back training, the participants played a platform game called Recollect the Study (a video can be found here: https://www.youtube.com/watch?v=zhgL8Oe42Yk) in which they were tasked with collecting stimuli that matched those presented N items earlier. The stimuli consisted of simple coloured objects and were paired with unique sounds to support multisensory processing of said objects63. In the non-gamified N-back training (Tapback, https://www.youtube.com/watch?v=GMGiDnJ53RU), a series of coloured circles was presented on a plain background, and the participant tapped on the circles that were the same colour as those presented N items earlier. In all training paradigms, the stimuli were presented for 2,500 ms (interstimulus interval (ISI), 500 ms), of which 30% were targets and another 30% lures (for example, items that occur N − 1 or N + 1 of the target position)94. The session was broken into roughly two-minute training blocks with typically seven to ten blocks per training session. Auditory and visual feedback was presented on every trial, indicating correct or incorrect responses. Task difficulty was adaptively adjusted on the basis of performance either within or between blocks depending on the training condition. The outcome measure used here was average N-level per day (weighted across the number of trials within each block).
Near Transfer N-back
We used an untrained N-back task with two versions, featuring pictures of animals or vehicles. The versions were counterbalanced across individuals and sessions, except for 40% of the participants in RCT 1, who completed the same version twice due to a technical error. Mann–Whitney tests indicated that there were no significant performance differences at post-test as a function of test version (different versus the same) in the no-contact (U = 40, z = −0.54, p = 0.88) and N-back training (U = 624, z = −1.01, p = 0.27) groups. All participants completed a 1-back task, followed by 2- and 3-back tasks. Before each level started, there were ten trials of practice during which performance feedback was provided. In RCT 1, the test phase for each N-level consisted of 20 + N trials with six targets, whereas in RCT 2, each N-level consisted of 30 + N trials with nine targets (30% target and 30% lure rates in both RCTs). Progression to 4-back (and beyond) was allowed if the participant made no more than two errors on the previous level; otherwise, the task stopped at 3-back. Accuracy was calculated for each N-level as hits/(hits + misses + false alarms), allowing for comparison across RCTs. Accuracy at the 1-back level was very high (RCT 1: MeanPre = 0.88, s.d.Pre = 0.18, MeanPost = 0.94, s.d.Post = 0.14; RCT 2: MeanPre = 0.90, s.d.Pre = 0.16, MeanPost = 0.95, s.d.Post = 0.11), and only 7.4% and 4.8% of participants reached N-levels higher than 3 at pre-test, respectively; thus, we used average accuracy across the 2-back and 3-back levels as the dependent variable (at least 40 + N trials per participant).
Matrix Reasoning
Matrix Reasoning problems were used to assess non-verbal problem solving ability95. Different versions of the test were used at pre-test and post-test, counterbalanced across participants. While the number of problems and certain design features differed in the two RCTs, the basic structure of the task remained the same. Namely, each problem consisted of a 3 × 3 matrix with the lower right entry missing, and the participants were asked to select one out of eight answer options that best completed the matrix. Prior to the test phase, the participants were presented with example problems and the opportunity to practise the task, during which feedback was provided. In RCT 1, the participants were required to solve 42 problems with a time limit of 20 minutes95, whereas in RCT 2, the participants solved 23 problems with a time limit of 10 minutes (UCMRT)74. The main outcome measure in both RCTs was the proportion of correctly solved problems; in RCT 1, there was a larger number of easy problems (that is, one- and two-relation problems) than used in RCT 2; hence, accuracy was higher for RCT 1 (Table 2).
Countermanding task
A modified Countermanding task was used to assess IC76,96. A series of pictures appeared on either the left or the right of the screen, and the participants were instructed to quickly and accurately tap one of two buttons presented below. The task involved pressing the button on the same side of the screen in response to pictures of a dog (congruent trials) and the button on the opposite side in response to pictures of a monkey (incongruent trials). There were three blocks of trials, each preceded by a practice session: a block of 12 congruent trials, a block of 12 incongruent trials and a mixed block of 48 trials where congruent and incongruent trials were randomly intermixed. All RCTs showed high accuracy in the mixed block: 97% on average or higher at pre-test and post-test. The main dependent measure was RT for correct responses on incongruent trials of the mixed block (index of IC).
Outliers and exclusions
Six outliers were removed from the sample on the basis of performance on Near Transfer and Matrix Reasoning (|zaccuracy| > 3 at pre- or post-test separately for each RCT). In the N-back training group, six additional participants were removed due to a software error in the training program. The final analytical sample consisted of 271 participants, 181 in the N-back training group (RCT 1: n = 72; RCT 2: n = 109) and 90 in the no-contact control group (RCT 1: n = 22; RCT 2: n = 68).
Data analysis
JASP version 0.14.1 (ref. 97) was used to run Bayesian paired-samples t-tests with default priors to estimate changes in performance as a function of time separately for each training condition and RCT (Tables 2 and 3). A value of BF10 between 1 and 3 is considered to be only anecdotal evidence for the alternative hypothesis, 3–10 is moderate evidence, 10–30 is strong evidence, 30–100 is very strong evidence and >100 is extreme evidence98,99. All variables were z-transformed (on the basis of pre-test scores, separately for each RCT) prior to regression-based analyses to control for RCT effects. Linear regression was used to test the relative contributions of training group (N-back training or control), pre-test Matrix Reasoning scores, pre-test N-back and pre-test Countermanding to post-test performance on Matrix Reasoning. We checked for multicollinearity, heteroscedasticity and independent errors using a Durbin–Watson test100 and found these to be in the appropriate ranges.
To determine whether the relationship between training group and Matrix Reasoning (Far Transfer) was mediated by Near Transfer, we conducted mediation analyses using ordinary least squares regression via PROCESS version 3 (ref. 36) in IBM SPSS Statistics version 27 (ref. 101). Performance on the Countermanding task was entered as a parallel mediator. In the next step, each RCT was evaluated separately using the same parallel two-mediator models. The independent variable was training group (N-back training or control), the mediators were average post-test performance on untrained N-back tasks and average RT on incongruent trials of the Countermanding task, and the dependent variable was post-test performance on Matrix Reasoning. Note that no mediator was modelled as influencing another mediator in the model. To control for pre-existing individual differences in cognitive ability, we entered performance for the three aforementioned tasks as covariates. Since the antecedent variable is an experimental variable in a randomized study, its causal relation to the mediator and the outcome variable can be interpreted unambiguously102,103. Because the post-test data were collected within the same session, causality between the mediator and the outcome variable cannot be established unequivocally; that said, we defend this causal claim on theoretical grounds, which should be sufficient to allow for interpretation of the model36. However, to address this limitation, in the Replication study, Near Transfer performance preceded post-test performance on Matrix Reasoning and other Gf tasks by one day; hence, it represents a plausible causal agent for these outcome measures (see below). Note that in the Results section, s.e. refers to standard error, and ESp.s. refers to partially standardized effect size36.
Replication study (RCT 3)
Participants
A second experiment was conducted at the same universities in spring, summer and fall 2020 to investigate whether the mediation model replicates in a double-blind RCT with two N-back training groups and an active control group. The experiment was pre-registered on AsPredicted (no. 40240) and was conducted online due to the COVID-19 pandemic. The participants were randomly assigned to one of three groups: gamified N-back training, non-gamified N-back training and general knowledge training (control group), with a target sample size of 64 participants per condition as determined by a power analysis for two-mediator models using Monte Carlo simulations in MPLUS version 8.4 (ref. 104). We recruited 258 participants, 201 of which completed all training and assessment sessions (ngamified N-back = 70, nnon-gamifed N-back = 67, ncontrol = 64). The participants provided informed consent and were given US$80 in compensation for participation; all procedures were approved by the University of California, Riverside Institutional Review Board for Human Subjects Research. As can be seen in Supplementary Tables 7 and 8, the sample demographics resemble those reported for the Retrospective study. Unless stated otherwise, the procedures, tasks and training details match those described in the Retrospective study.
Procedure
Since additional tasks were added to be able to examine latent constructs, the experiment consisted of three pre-test and three post-test sessions, with three or four tasks per session to prevent fatigue associated with prolonged testing. Supervision was provided via Zoom for all pre- and post-test sessions, as well as the first training session and any additional sessions as needed, along with technical support via e-mail and phone. Different experimenters supervised pre- and post-test sessions versus training sessions to ensure experimenter blinding; likewise, the participants were not aware that there were multiple training conditions or which one they had been assigned to.
Training tasks
N-back training
The same training task was used as in the Retrospective study, and the participants were encouraged to follow the same training protocol—that is, to complete two 20-minute sessions per day over the course of two weeks. The program was set up to prevent access to more than two sessions in 24 hours. The participants were assigned to gamified or non-gamified N-back training as described in the Retrospective study. Half of the participants in each N-back training group trained on slightly different adaptive algorithms: miniblock-reset (each session starts at 2-back; level up, <3 errors in a 40-trial block; level down, >6 errors in a 40-trial block) and online weighted accuracy (level up, accuracy > 70%; level down, accuracy < 50%), which were collapsed for the purposes of the current analysis.
General knowledge training
Participants in the active control group trained on a task that consists of general knowledge, vocabulary, social science and trivia multiple-choice questions as used previously83,105. They were encouraged to follow the same schedule as the N-back training group (two 20-minute sessions per day). This task was selected for the control intervention because it taps into crystallized intelligence and should not engage fluid intelligence or WM. Previous research has shown that participants find this task engaging and enjoyable31,83.
Transfer measures
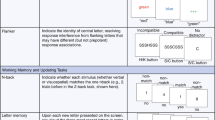
The first and the last assessment sessions, which consisted of surveys and ETS and DAT tests, were administered via Qualtrics (Qualtrics), whereas the rest were implemented within Recollect the Study. All assessment sessions were supervised via videoconferencing by a researcher who was blind to the training condition the participant had been assigned to. Alternate versions51 of the ETS Surface Development Test, the ETS Form Board Test and DAT Space Relations were grouped (As and Bs together) for administration at pre- and post-test, the order of which was counterbalanced across participants. Alternate versions of Near Transfer N-back, Running Span and Matrix Reasoning were administered at pre- and post-test in a counterbalanced order (A–B, B–A).
Near Transfer N-back
The same Near Transfer N-back task was used as in the Retrospective study, except that the vehicle stimulus set was replaced with pictures of fruit. The main dependent variable, average accuracy across the 2-back and 3-back levels at pre-test, was comparable across experiments for the two stimulus sets (Retrospective study—vehicles: MeanPre = 0.57, s.d.Pre = 0.16; Replication study—fruit: MeanPre = 0.60, s.d.Pre = 0.14).
Running Span
Running Span was an updating WM task in which the participants saw an unpredictable number of stimuli and were asked to report the last N items. The same stimuli were used as in Near Transfer N-back (animals and fruit), but with different stimulus sets presented at pre- and post-test across the two tasks. The stimuli were presented for 500 ms with an ISI of 1,500 ms. Before each trial, the participants were told how many items they would need to report. The response screen featured a ‘keyboard’ of pictures of eight stimuli (always shown at the same locations), and the participants were asked to select the last N pictures in the order of appearance. The task started with two practice trials (set sizes 2 and 3), and if at least one trial was incorrect, practice was repeated. Feedback was provided during practice but not during the assessment. The assessment consisted of set sizes 2–4 (in that order) with three trials per set size. Progression to set size 5 (and beyond) was contingent on having at least two out of three trials correct on the previous set size. The main dependent measure was the sum of all correctly recalled items (partial score), whereby each item correctly chosen in the correct serial position was assigned one point106.
Sequencing
In the Sequencing task, the participants were presented with a mixed sequence of letters and numbers that appeared one by one (for example, ‘8, T, 2, D’) and were asked to remember and enter the numbers in numerical order (for example, ‘2, 8’) followed by the letters in alphabetical order (for example, ‘D, T’)63. The stimuli appeared for 1,000 ms with an ISI of 500 ms. After five practice trials, the task started at the lowest set size of two items, and then two trials were presented per set size until both trials on a set size were incorrect. The main dependent variable was the sum of all correctly recalled trials (score).
Simple and Complex spatial span
Simple Span was used to assess spatial WM storage, while Complex Span was used to measure WM storage and processing107. In Simple Span, a sequence of gophers appeared in 12 possible locations, and the participants were tasked with reproducing the sequence by tapping on the locations. The stimuli appeared for 1,500 ms with an ISI of 500 ms. In Complex Span, the same procedure was adopted, except that between each appearance of a gopher, the participant completed a secondary sorting task (dragging an item to the left or right). This secondary task presents interleaved processing demands that are thought to limit the use of mnemonic strategies, such as chunking. In both tasks, the set size (that is, the number of gopher locations in the sequence) ranged from 2 to 10; the test started with the lowest set size and then increased (or decreased) using an adaptive algorithm. The main dependent measure for each task was the sum of all correctly recalled items (partial-credit scoring108).
Countermanding
The same Countermanding task was used as in the Retrospective study.
UCancellation
UCancellation is a timed test of selective attention and concentration that has been validated against the D2 Test of Attention109,110. The participants were presented with a series of rows featuring pictures of dogs or monkeys, some of which had inverted colours and were reflected over the vertical axis or presented upside down. There were two types of targets, an upright dog and an upside-down monkey, and there were three to five of these targets per row. The goal was to select all targets from left to right within a six-second time limit. Each target type was practised separately in two single blocks prior to proceeding to a mixed block. If a participant cleared a row before the six-second time limit, they could press a button to continue to the next row; thus, participants completed bonus rows if a global time limit of three minutes and ten seconds was not exceeded. The main dependent measure was concentration performance (∑Hits − ∑False alarms) in the mixed block.
Matrix Reasoning
The same Matrix Reasoning task, UCMRT, was used as in RCT 2 (ref. 74).
ETS Surface Development Test
Surface Development involves visualizing how a piece of paper could be folded to form an object83,111,112. Two images were presented on a computer screen: an unfolded piece of paper and an object. The participants were then asked to mark which edges went together. One practice problem was followed by six test problems, with a time limit of six minutes. The dependent variable was the proportion of correct responses within the time limit.
ETS Form Board Test
In the Form Board test, a given trial consisted of a set of five two-dimensional shapes that could be combined into a two-dimensional geometrical shape presented above the set83,112,113. The goal was to indicate which of the pieces could be combined to match the geometrical shape given at the top of the page. The participants were given two practice problems and then eight minutes to solve 24 problems. The dependent variable was the proportion of correctly solved items in the given time limit.
DAT Space Relations
In the Space Relations test, the participants were presented with a target pattern and four possible objects and were asked to select the appropriate object into which the pattern could be folded83,112,114. Two practice problems preceded 17 test items, with a five-minute time limit to complete the test. The dependent variable was the number of correctly solved items in the given time limit.
Outliers
Of the 201 participants who completed the study, 6 were removed due to administration error on the ETS and DAT tests. Outliers were removed if a given data point was three or more standard deviations from the mean at pre- or post-test. No outliers were removed for Near Transfer or Matrix Reasoning, and six outliers were removed on the basis of Countermanding speed; hence, the resulting sample size was 189 (128 in the N-back training group and 61 in the active control group) (Table 3). This dataset was subject to initial replication mediation analyses. In the next step, additional outliers were removed for Running Span (n = 8) as well as 11 participants who showed non-compliance on the Sequencing and Spatial Span tasks. This second analytical dataset, which consisted of 170 participants (115 in the N-back training group and 55 in the active control group), was used for the additional mediation analyses that included additional assessments and composite scores.
Composite variables
Pre-test correlations of performance on the test battery revealed significant correlations among all measures (Supplementary Table 5) except for Running Span, which correlated only with Sequencing. Moreover, Running Span showed the lowest test–retest reliability among measures, as indicated by the pre–post correlation observed in the active control group (r = 0.35); it was therefore excluded from subsequent analyses. Principal component analysis with oblimin rotation was used to identify composite scores. The sample size for principal component analysis was adequate (Kaiser-Meyer-Olkin index = 0.79), Bartlett’s test of sphericity was significant (χ2(45) = 387.55, P < 0.001), the diagonals of the anti-image correlation matrix were all over 0.7 and the communalities were all above 0.3, thereby confirming that each measure shared some common variance with other measures. A three-factor solution was obtained, which explained 58.5% of the variance (Supplementary Table 9). The following factors were identified: IC (Countermanding and UCancellation), reasoning ability (UCMRT, ETS Surface Development Test, ETS Form Board Test and DAT Space Relations) and WM (Near Transfer N-back, Sequencing, Simple Span and Complex Span), which is in line with the theoretical structure proposed during pre-registration. Composite variables were created by taking the mean of z-transformed dependent variables that had their primary loadings on each factor. Note that for models in which Near Transfer was used as a separate mediator, the WM composite consisted only of Sequencing and Simple and Complex spatial span tasks. For the IC composite, the values on Countermanding were reversed so that higher value indicates better performance.
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Data availability
The data that support the findings of this study are available from the corresponding author upon request.
Code availability
Recollect the Study is a free app for Apple and Android devices; however, the experimental code is not open source. A collection of useful Unity tools and scripts developed at the UC Riverside Brain Game Center is available at https://github.com/UCRBrainGameCenter/BGC_Tools. Analysis code (SPSS script) is available from the corresponding author upon request.
Change history
31 January 2023
A Correction to this paper has been published: https://doi.org/10.1038/s41562-022-01514-4
References
McNab, F. et al. Changes in cortical dopamine D1 receptor binding associated with cognitive training. Science 323, 800–802 (2009).
Park, D. C. & Bischof, G. N. The aging mind: neuroplasticity in response to cognitive training. Dialogues Clin. Neurosci. 15, 109–119 (2013).
Anguera, J. A. et al. Video game training enhances cognitive control in older adults. Nature 501, 97–101 (2013).
Mishra, J., de Villers-Sidani, E., Merzenich, M. & Gazzaley, A. Adaptive training diminishes distractibility in aging across species. Neuron 84, 1091–1103 (2014).
Salmi, J., Nyberg, L. & Laine, M. Working memory training mostly engages general-purpose large-scale networks for learning. Neurosci. Biobehav. Rev. 93, 108–122 (2018).
Bäckman, L. et al. Increased dopamine release after working-memory updating training: neurochemical correlates of transfer. Sci. Rep. 7, 7160 (2017).
Green, C. S. & Seitz, A. R. The impacts of video games on cognition (and how the government can guide the industry). Policy Insights Behav. Brain Sci. 2, 101–110 (2015).
Deveau, J., Jaeggi, S. M., Zordan, V., Phung, C. & Seitz, A. R. How to build better memory training games. Front. Syst. Neurosci. 8, 243 (2014).
Söderqvist, S. et al. Dopamine, working memory, and training induced plasticity: implications for developmental research. Dev. Psychol. 48, 836–843 (2012).
Mishra, J. & Gazzaley, A. Closed-loop rehabilitation of age-related cognitive disorders. Semin. Neurol. 34, 584–590 (2014).
Au, J. et al. Improving fluid intelligence with training on working memory: a meta-analysis. Psychon. Bull. Rev. 22, 366–377 (2015).
Schwaighofer, M., Fischer, F. & Bühner, M. Does working memory training transfer? A meta-analysis including training conditions as moderators. Educ. Psychol. 50, 138–166 (2015).
Soveri, A., Antfolk, J., Karlsson, L., Salo, B. & Laine, M. Working memory training revisited: a multi-level meta-analysis of n-back training studies. Psychon. Bull. Rev. 24, 1077–1096 (2017).
Weicker, J., Villringer, A. & Thöne-Otto, A. Can impaired working memory functioning be improved by training? A meta-analysis with a special focus on brain injured patients. Neuropsychology 30, 190–212 (2016).
Karbach, J. & Verhaeghen, P. Making working memory work: a meta-analysis of executive-control and working memory training in older adults. Psychol. Sci. 25, 2027–2037 (2014).
Melby-Lervåg, M. & Hulme, C. Is working memory training effective? A meta-analytic review. Dev. Psychol. 49, 270–291 (2013).
Melby-Lervåg, M. & Hulme, C. There is no convincing evidence that working memory training is effective: a reply to Au et al. (2014) and Karbach and Verhaeghen (2014). Psychon. Bull. Rev. 23, 324–330 (2016).
Katz, B., Jones, M. R., Shah, P., Buschkuehl, M. & Jaeggi, S. M. in Cognitive Training: An Overview of Features and Applications (eds Strobach, T. & Karbach, J.) 107–123 (Springer, 2021).
Pergher, V. et al. Divergent research methods limit understanding of working memory training. J. Cogn. Enhanc. https://doi.org/10.1007/s41465-019-00134-7 (2019).
Burgess, G. C., Gray, J. R., Conway, A. R. A. & Braver, T. S. Neural mechanisms of interference control underlie the relationship between fluid intelligence and working memory span. J. Exp. Psychol. Gen. 140, 674–692 (2011).
Gray, J. R., Chabris, C. F. & Braver, T. S. Neural mechanisms of general fluid intelligence. Nat. Neurosci. 6, 316–322 (2003).
Hockey, A. & Geffen, G. The concurrent validity and test–retest reliability of a visuospatial working memory task. Intelligence 32, 591–605 (2004).
Kane, M. J., Conway, A. R. A., Miura, T. K. & Colflesh, G. J. H. Working memory, attention control, and the N-back task: a question of construct validity. J. Exp. Psychol. Learn. Mem. Cogn. 33, 615–622 (2007).
Jaeggi, S. M., Buschkuehl, M., Perrig, W. J. & Meier, B. The concurrent validity of the N-back task as a working memory measure. Memory 18, 394–412 (2010).
Soveri, A., Karlsson, E. P. A., Waris, O., Grönholm-Nyman, P. & Laine, M. Pattern of near transfer effects following working memory training with a dual N-back task. Exp. Psychol. 64, 240–252 (2017).
Buschkuehl, M., Hernandez-Garcia, L., Jaeggi, S. M., Bernard, J. A. & Jonides, J. Neural effects of short-term training on working memory. Cogn. Affect. Behav. Neurosci. 14, 147–160 (2014).
Küper, K. & Karbach, J. Increased training complexity reduces the effectiveness of brief working memory training: evidence from short-term single and dual n-back training interventions. J. Cogn. Psychol. 28, 199–208 (2016).
Barnett, S. M. & Ceci, S. J. When and where do we apply what we learn? A taxonomy for far transfer. Psychol. Bull. 128, 612–637 (2002).
Harty, S., Sella, F. & Cohen Kadosh, R. Mind the brain: the mediating and moderating role of neurophysiology. Trends Cogn. Sci. (Regul. Ed.) 21, 2–5 (2017).
Vuorre, M. & Bolger, N. Within-subject mediation analysis for experimental data in cognitive psychology and neuroscience. Behav. Res. Methods 50, 2125–2143 (2018).
Jaeggi, S. M., Buschkuehl, M., Jonides, J. & Shah, P. Short- and long-term benefits of cognitive training. Proc. Natl Acad. Sci. USA 108, 10081–10086 (2011).
Laine, M., Fellman, D., Waris, O. & Nyman, T. J. The early effects of external and internal strategies on working memory updating training. Sci. Rep. 8, 4045 (2018).
Katz, B., Jaeggi, S. M., Buschkuehl, M., Shah, P. & Jonides, J. The effect of monetary compensation on cognitive training outcomes. Learn. Motiv. 63, 77–90 (2018).
Boot, W. R., Simons, D. J., Stothart, C. & Stutts, C. The pervasive problem with placebos in psychology: why active control groups are not sufficient to rule out placebo effects. Perspect. Psychol. Sci. 8, 445–454 (2013).
Au, J., Gibson, B. C., Bunarjo, K., Buschkuehl, M. & Jaeggi, S. M. Quantifying the difference between active and passive control groups in cognitive interventions using two meta-analytical approaches. J. Cogn. Enhanc. 4, 192–210 (2020).
Hayes, A. F. in Introduction to Mediation, Moderation, and Conditional Process Analysis: A Regression-Based Approach (eds Kenny, D. A. & Little, T. D.) 77–112 (Guilford, 2018).
Tate, C. U. On the overuse and misuse of mediation analysis: it may be a matter of timing. Basic Appl. Soc. Psych. 37, 235–246 (2015).
Zinke, K. et al. Working memory training and transfer in older adults: effects of age, baseline performance, and training gains. Dev. Psychol. 50, 304–315 (2014).
Rudebeck, S. R., Bor, D., Ormond, A., O’Reilly, J. X. & Lee, A. C. H. A potential spatial working memory training task to improve both episodic memory and fluid intelligence. PLoS ONE 7, e50431 (2012).
Tidwell, J. W., Dougherty, M. R., Chrabaszcz, J. R., Thomas, R. P. & Mendoza, J. L. What counts as evidence for working memory training? Problems with correlated gains and dichotomization. Psychon. Bull. Rev. 21, 620–628 (2014).
Chuderski, A. & Necka, E. The contribution of working memory to fluid reasoning: capacity, control, or both? J. Exp. Psychol. Learn. Mem. Cogn. 38, 1689–1710 (2012).
Friedman, N. P. et al. Not all executive functions are related to intelligence. Psychol. Sci. 17, 172–179 (2006).
Halford, G. S., Cowan, N. & Andrews, G. Separating cognitive capacity from knowledge: a new hypothesis. Trends Cogn. Sci. (Regul. Ed.) 11, 236–242 (2007).
Carpenter, P. A., Just, M. A. & Shell, P. What one intelligence test measures: a theoretical account of the processing in the Raven Progressive Matrices Test. Psychol. Rev. 97, 404–431 (1990).
Unsworth, N. & Engle, R. Working memory capacity and fluid abilities: examining the correlation between Operation Span and Raven. Intelligence 33, 67–81 (2005).
Wiley, J., Jarosz, A. F., Cushen, P. J. & Colflesh, G. J. H. New rule use drives the relation between working memory capacity and Raven’s Advanced Progressive Matrices. J. Exp. Psychol. Learn. Mem. Cogn. 37, 256–263 (2011).
Jarosz, A. F. & Wiley, J. Why does working memory capacity predict RAPM performance? A possible role of distraction. Intelligence 40, 427–438 (2012).
Harrison, T. L., Shipstead, Z. & Engle, R. W. Why is working memory capacity related to matrix reasoning tasks? Mem. Cogn. 43, 389–396 (2015).
Engle, R. W. Working memory and executive attention: a revisit. Perspect. Psychol. Sci. 13, 190–193 (2018).
Shipstead, Z., Harrison, T. L. & Engle, R. W. Working memory capacity and fluid intelligence: maintenance and disengagement. Perspect. Psychol. Sci. 11, 771–799 (2016).
Dahlin, E., Neely, A. S., Larsson, A., Bäckman, L. & Nyberg, L. Transfer of learning after updating training mediated by the striatum. Science 320, 1510–1512 (2008).
O’Rourke, H. P. & MacKinnon, D. P. Reasons for testing mediation in the absence of an intervention effect: a research imperative in prevention and intervention research. J. Stud. Alcohol Drugs 79, 171–181 (2018).
Hayes, A. F. Beyond Baron and Kenny: statistical mediation analysis in the new millennium. Commun. Monogr. 76, 408–420 (2009).
Twenge, J. M. & Joiner, T. E. Mental distress among U.S. adults during the COVID-19 pandemic. J. Clin. Psychol. 76, 2170–2182 (2020).
Pfefferbaum, B. & North, C. S. Mental health and the COVID-19 pandemic. N. Engl. J. Med. 383, 510–512 (2020).
Fellman, D., Ritakallio, L., Waris, O., Jylkkä, J. & Laine, M. Beginning of the pandemic: COVID-19-elicited anxiety as a predictor of working memory performance. Front. Psychol. 11, 576466 (2020).
Li, W. et al. Dual n-back working memory training evinces superior transfer effects compared to the method of loci. Sci. Rep. 11, 3072 (2021).
Lilienthal, L., Tamez, E., Shelton, J. T., Myerson, J. & Hale, S. Dual n-back training increases the capacity of the focus of attention. Psychon. Bull. Rev. 20, 135–141 (2013).
Chein, J. M. & Morrison, A. B. Expanding the mind’s workspace: training and transfer effects with a complex working memory span task. Psychon. Bull. Rev. 17, 193–199 (2010).
Borella, E., Carretti, B., Riboldi, F. & De Beni, R. Working memory training in older adults: evidence of transfer and maintenance effects. Psychol. Aging 25, 767–778 (2010).
Schwarb, H., Nail, J. & Schumacher, E. H. Working memory training improves visual short-term memory capacity. Psychol. Res. 80, 128–148 (2016).
Stepankova, H. et al. The malleability of working memory and visuospatial skills: a randomized controlled study in older adults. Dev. Psychol. 50, 1049–1059 (2014).
Pahor, A. et al. Multisensory facilitation of working memory training. J. Cogn. Enhanc. https://doi.org/10.1007/s41465-020-00196-y (2020).
Linares, R., Borella, E., Lechuga, M. T., Carretti, B. & Pelegrina, S. Nearest transfer effects of working memory training: a comparison of two programs focused on working memory updating. PLoS ONE 14, e0211321 (2019).
Blacker, K. J., Negoita, S., Ewen, J. B. & Courtney, S. M. N-back versus complex span working memory training. J. Cogn. Enhanc. 1, 434–454 (2017).
Chooi, W.-T. & Thompson, L. A. Working memory training does not improve intelligence in healthy young adults. Intelligence 40, 531–542 (2012).
Li, S.-C. et al. Working memory plasticity in old age: practice gain, transfer, and maintenance. Psychol. Aging 23, 731–742 (2008).
Thompson, T. W. et al. Failure of working memory training to enhance cognition or intelligence. PLoS ONE 8, e63614 (2013).
Minear, M. et al. A simultaneous examination of two forms of working memory training: evidence for near transfer only. Mem. Cogn. 44, 1014–1037 (2016).
Redick, T. S. et al. No evidence of intelligence improvement after working memory training: a randomized, placebo-controlled study. J. Exp. Psychol. Gen. 142, 359–379 (2013).
Schweizer, S., Hampshire, A. & Dalgleish, T. Extending brain-training to the affective domain: increasing cognitive and affective executive control through emotional working memory training. PLoS ONE 6, e24372 (2011).
Jones, M. R., Katz, B., Buschkuehl, M., Jaeggi, S. M. & Shah, P. Exploring N-back cognitive training for children with ADHD. J. Atten. Disord. https://doi.org/10.1177/1087054718779230 (2018).
Maraver, M. J., Bajo, M. T. & Gomez-Ariza, C. J. Training on working memory and inhibitory control in young adults. Front. Hum. Neurosci. 10, 588 (2016).
Pahor, A., Stavropoulos, T., Jaeggi, S. M. & Seitz, A. R. Validation of a matrix reasoning task for mobile devices. Behav. Res. Methods https://doi.org/10.3758/s13428-018-1152-2 (2018).
Berger, E. M., Fehr, E., Hermes, H., Schunk, D. & Winkel, K. The Impact of Working Memory Training on Children’s Cognitive and Noncognitive Skills IZA Discussion Papers No. 13338 (IZA, 2020).
Ramani, G. B. et al. Racing dragons and remembering aliens: benefits of playing number and working memory games on kindergartners’ numerical knowledge. Dev. Sci. 23, e12908 (2020).
Zhang, Q. et al. The malleability of executive function in early childhood: effects of schooling and targeted training. Dev. Sci. 22, e12748 (2019).
Collins, C. L. et al. Video-based remote administration of cognitive assessments and interventions: a comparison with in-lab administration. J. Cogn. Enhanc. https://doi.org/10.1007/s41465-022-00240-z (2022).
Simons, D. J. et al. Do “brain-training” programs work? Psychol. Sci. Public Interest 17, 103–186 (2016).
Borella, E. et al. Training working memory in older adults: is there an advantage of using strategies? Psychol. Aging 32, 178–191 (2017).
Fellman, D. et al. The role of strategy use in working memory training outcomes. J. Mem. Lang. 110, 104064 (2020).
Katz, B. et al. in Cognitive Training (eds Strobach, T. & Karbach, J.) 157–166 (Springer International, 2016); https://doi.org/10.1007/978-3-319-42662-4_15
Jaeggi, S. M., Buschkuehl, M., Shah, P. & Jonides, J. The role of individual differences in cognitive training and transfer. Mem. Cogn. 42, 464–480 (2014).
López-Alonso, V., Cheeran, B., Río-Rodríguez, D. & Fernández-Del-Olmo, M. Inter-individual variability in response to non-invasive brain stimulation paradigms. Brain Stimul. 7, 372–380 (2014).
Bailey, N. W. et al. Responders to rTMS for depression show increased fronto-midline theta and theta connectivity compared to non-responders. Brain Stimul. 11, 190–203 (2018).
Reid, G. et al. Responders and non-responders to probiotic interventions: how can we improve the odds? Gut Microbes 1, 200–204 (2010).
Salas-Pérez, F. et al. Differentially methylated regions (DMRs) in PON3 gene between responders and non-responders to a weight loss dietary intervention: a new tool for precision management of obesity. Epigenetics https://doi.org/10.1080/15592294.2021.1873629 (2021).
Ostojic, S. M. Short-term GAA loading: responders versus nonresponders analysis. Food Sci. Nutr. 8, 4446–4448 (2020).
Pickering, C. & Kiely, J. Do non-responders to exercise exist—and if so, what should we do about them? Sports Med. 49, 1–7 (2019).
Tullo, D. & Jaeggi, S. M. in The Cambridge Handbook of Working Memory and Language (eds Schwieter, W. & Zen, Z.) 881–908 (Cambridge University Press, 2022).
Schork, N. J. Personalized medicine: time for one-person trials. Nature 520, 609–611 (2015).
Peretz, C. et al. Computer-based, personalized cognitive training versus classical computer games: a randomized double-blind prospective trial of cognitive stimulation. Neuroepidemiology 36, 91–99 (2011).
Shatil, E., Metzer, A., Horvitz, O. & Miller, A. Home-based personalized cognitive training in MS patients: a study of adherence and cognitive performance. NeuroRehabilitation 26, 143–153 (2010).
Sandeep, S., Shelton, C. R., Pahor, A., Jaeggi, S. M. & Seitz, A. R. Application of machine learning models for tracking participant skills in cognitive training. Front. Psychol. 11, 1532 (2020).
Matzen, L. E. et al. Recreating Raven’s: software for systematically generating large numbers of Raven-like matrix problems with normed properties. Behav. Res. Methods 42, 525–541 (2010).
Davidson, M. C., Amso, D., Anderson, L. C. & Diamond, A. Development of cognitive control and executive functions from 4 to 13 years: evidence from manipulations of memory, inhibition, and task switching. Neuropsychologia 44, 2037–2078 (2006).
JASP Team. JASP v.0.9.2 (2019).
Wagenmakers, E.-J. et al. Bayesian inference for psychology. Part II: example applications with JASP. Psychon. Bull. Rev. 25, 58–76 (2018).
Lee, M. D. & Wagenmakers, E.-J. Bayesian Cognitive Modeling: A Practical Course (Cambridge Univ. Press, 2013); https://doi.org/10.1017/CBO9781139087759
Field, A. in Discovering Statistics Using IBM SPSS Statistics (ed. Carmichael, M.) 293–356 (Sage, 2013).
IBM SPSS Statistics for MAC v.27.0 (IBM Corp., 2020).
Holland, P. W. Statistics and causal inference. J. Am. Stat. Assoc. 81, 945–960 (1986).
Shrout, P. E. & Bolger, N. Mediation in experimental and nonexperimental studies: new procedures and recommendations. Psychol. Methods 7, 422–445 (2002).
Muthén, L. K. & Muthén, B. O. Mplus User’s Guide 8th edn (Muthén & Muthén, 1998–2017).
Jaeggi, S. M. et al. Investigating the effects of spacing on working memory training outcome—a randomized controlled multi-site trial in older adults. J. Gerontol. B https://doi.org/10.1093/geronb/gbz090 (2019).
Broadway, J. M. & Engle, R. W. Validating running memory span: measurement of working memory capacity and links with fluid intelligence. Behav. Res. Methods 42, 563–570 (2010).
Cowan, N. What are the differences between long-term, short-term, and working memory? Prog. Brain Res. 169, 323–338 (2008).
Conway, A. R. A. et al. Working memory span tasks: a methodological review and user’s guide. Psychon. Bull. Rev. 12, 769–786 (2005).
Pahor, A. et al. UCancellation: a new mobile measure of selective attention and concentration. Behav. Res. Methods https://doi.org/10.3758/s13428-021-01765-5 (2022).
Brickenkamp, R. & Zillmer, E. Test d2: Concentration-Endurance Test (CJ Hogrefe, 1998).
Ekstrom, R. B. ETS Kit of Factor-Referenced Cognitive Tests (Educational Testing Service, 1976).
Kane, M. J. et al. The generality of working memory capacity: a latent-variable approach to verbal and visuospatial memory span and reasoning. J. Exp. Psychol. Gen. 133, 189–217 (2004).
Ekstrom, R. B., French, J. W., Harmon, H. H. & Derman, D. ETS Kit of Factor-Referenced Cognitive Tests (ETS Educational Testing Service, 1976).
Bennett, G. K., Seashore, H. G. & Wesman, A. G. Differential Aptitude Test: Space Relations (Psychological Corporation, 1972).
Acknowledgements
This work was supported by the National Institute of Mental Health (grant no. 1R01MH111742, A.R.S. and S.M.J.) and by the National Institute on Aging (grant no. 1K02AG054665, S.M.J.). The funders had no role in study design, data collection and analysis, decision to publish or preparation of the manuscript. We thank C. Collins, A. Carrillo, R. Smith-Peirce, R. Mester and A. Moon as well as our many undergraduate research assistants for their help with data collection, and C. Reynolds for statistical advice.
Author information
Authors and Affiliations
Contributions
All authors designed the experiments and monitored the data collection. A.P. analysed the data and wrote the manuscript with input from A.R.S. and S.M.J. Senior authorship is shared by A.R.S. and S.M.J.
Corresponding author
Ethics declarations
Competing interests
S.M.J. has an indirect financial conflict of interest with the MIND Research Institute, whose interests are related to this work. The remaining authors declare no competing interests.
Peer review
Peer review information
Nature Human Behaviour thanks Lars Nyberg and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data
Extended Data Fig. 1 Schematic of single mediator models with post-test Countermanding as the dependent variable.
Path coefficients are standardized regression coefficients with p values reported in brackets. Bold text indicates statistical significance. Covariates (not displayed): pre-test Countermanding and pre-test N-back. a, Retrospective study, whole sample (N = 271). b, Retrospective study, RCT 1 (N = 94). c, Retrospective study, RCT 2 (N = 177).
Extended Data Fig. 2 N-back training progress.
Mean N-level achieved per day (40 minutes of training) for active groups in RCT 1 (N = 72), RCT 2 (N = 109), and RCT 3 (N = 128), weighted by the number of trials. RCT differences may reflect the use of slightly different adaptive algorithms. Shaded areas represent standard error of the mean.
Extended Data Fig. 3 Scatter plots demonstrating relationships between main outcome measures at pre-test in RCT 1 (N = 94) and RCT 2 (N = 177).
Data is collapsed across training conditions and solid lines represent the linear fit of data. a, Near Transfer (untrained N-back) and Matrix Reasoning in RCT 1. b, Near Transfer and Countermanding in RCT 1. c, Matrix Reasoning and Countermanding in RCT 1. d, Near Transfer and Matrix Reasoning in RCT 2. e, Near Transfer and Countermanding in RCT 2. f, Matrix Reasoning and Countermanding in RCT 2.
Extended Data Fig. 4 Scatter plots demonstrating relationships between main outcome measures at post-test in RCT 1.
Solid lines represent the linear fit of data. a, Near Transfer (untrained N-back) and Matrix Reasoning performance for N-back training group (N = 72). b, Near Transfer and Countermanding performance for N-back training group (N = 72). c, Matrix Reasoning and Countermanding performance for N-back training group (N = 72). d, Near Transfer and Matrix Reasoning performance for No-contact control group (N = 22). e, Near Transfer and Countermanding performance for No-contact control group (N = 22). f, Matrix Reasoning and Countermanding performance for No-contact control group (N = 22).
Extended Data Fig. 5 Scatter plots demonstrating relationships between main outcome measures at post-test in RCT 2.
Solid lines represent the linear fit of data. a, Near Transfer (untrained N-back) and Matrix Reasoning performance for N-back training group (N = 109). b, Near Transfer and Countermanding performance for N-back training group (N = 109). c, Matrix Reasoning and Countermanding performance for N-back training group (N = 109). d, Near Transfer and Matrix Reasoning performance for No-contact control group (N = 68). e, Near Transfer and Countermanding performance for No-contact control group (N = 68). f, Matrix Reasoning and Countermanding performance for No-contact control group (N = 68).
Extended Data Fig. 6 Scatter plots demonstrating relationships between main outcome measures at pre-test and post-test in RCT 3 (N = 189).
Circles represent the N-back training group (N = 128) and cross marks represent the Active control group (N = 61). a, Matrix Reasoning and Near Transfer (untrained N-back) performance at pre-test b, Matrix Reasoning and Countermanding performance at pre-test. c, Near Transfer and Countermanding performance at pre-test. d, Matrix Reasoning and Near Transfer performance at post-test e, Matrix Reasoning and Countermanding performance at post-test. f, Near Transfer and Countermanding performance at post-test.
Supplementary information
Supplementary Information
Supplementary Tables 1–9.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Pahor, A., Seitz, A.R. & Jaeggi, S.M. Near transfer to an unrelated N-back task mediates the effect of N-back working memory training on matrix reasoning. Nat Hum Behav 6, 1243–1256 (2022). https://doi.org/10.1038/s41562-022-01384-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41562-022-01384-w
This article is cited by
-
Leveraging the Potential of Large Language Models in Education Through Playful and Game-Based Learning
Educational Psychology Review (2024)
-
N-Back training in middle adulthood: evidence for transfer only to structurally similar task
Current Psychology (2024)
-
Age-Independent Transfer After Successful Associative Mnemonic Training
Journal of Cognitive Enhancement (2023)
