
Abstract
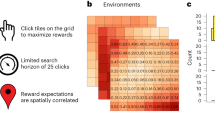
From foraging for food to learning complex games, many aspects of human behaviour can be framed as a search problem with a vast space of possible actions. Under finite search horizons, optimal solutions are generally unobtainable. Yet, how do humans navigate vast problem spaces, which require intelligent exploration of unobserved actions? Using various bandit tasks with up to 121 arms, we study how humans search for rewards under limited search horizons, in which the spatial correlation of rewards (in both generated and natural environments) provides traction for generalization. Across various different probabilistic and heuristic models, we find evidence that Gaussian process function learning—combined with an optimistic upper confidence bound sampling strategy—provides a robust account of how people use generalization to guide search. Our modelling results and parameter estimates are recoverable and can be used to simulate human-like performance, providing insights about human behaviour in complex environments.
This is a preview of subscription content, access via your institution
Access options
Access Nature and 54 other Nature Portfolio journals
Get Nature+, our best-value online-access subscription
$29.99 / 30 days
cancel any time
Subscribe to this journal
Receive 12 digital issues and online access to articles
$119.00 per year
only $9.92 per issue
Buy this article
- Purchase on Springer Link
- Instant access to full article PDF
Prices may be subject to local taxes which are calculated during checkout




Similar content being viewed by others

Data availability
Anonymized participant data and model simulation data are available at https://github.com/charleywu/gridsearch.
Code availability
The code used for all models and analyses is available at https://github.com/charleywu/gridsearch.
Change history
23 October 2020
A Correction to this paper has been published: https://doi.org/10.1038/s41562-020-00958-w
References
Todd, P. M., Hills, T. T. & Robbins, T. W. Cognitive Search: Evolution, Algorithms, and the Brain (MIT Press, Cambridge, 2012).
Kolling, N., Behrens, T. E., Mars, R. B. & Rushworth, M. F. Neural mechanisms of foraging. Science 336, 95–98 (2012).
Bramley, N. R., Dayan, P., Griffiths, T. L. & Lagnado, D. A. Formalizing neurath’s ship: approximate algorithms for online causal learning. Psychol. Rev. 124, 301–338 (2017).
Sutton, R. S. & Barto, A. G. Reinforcement Learning: An Introduction (MIT Press, Cambridge, 1998).
Steyvers, M., Lee, M. D. & Wagenmakers, E.-J. A Bayesian analysis of human decision-making on bandit problems. J. Math. Psychol. 53, 168–179 (2009).
Speekenbrink, M. & Konstantinidis, E. Uncertainty and exploration in a restless bandit problem. Top. Cogn. Sci. 7, 351–367 (2015).
Palminteri, S., Lefebvre, G., Kilford, E. J. & Blakemore, S.-J. Confirmation bias in human reinforcement learning: evidence from counterfactual feedback processing. PLoS Comput. Biol. 13, e1005684 (2017).
Reverdy, P. B., Srivastava, V. & Leonard, N. E. Modeling human decision making in generalized gaussian multiarmed bandits. Proc. IEEE 102, 544–571 (2014).
Lee, S. W., Shimojo, S. & O’Doherty, J. P. Neural computations underlying arbitration between model-based and model-free learning. Neuron 81, 687–699 (2014).
Gershman, S. J. & Daw, N. D. Reinforcement learning and episodic memory in humans and animals: an integrative framework. Annu. Rev. Psychol. 68, 101–128 (2017).
Lake, B. M., Ullman, T. D., Tenenbaum, J. B. & Gershman, S. J.Building machines that learn and think like people. Behav. Brain Sci. 40, e253 (2017).
Wilson, R. C., Geana, A., White, J. M., Ludvig, E. A. & Cohen, J. D. Humans use directed and random exploration to solve the explore–exploit dilemma. J. Exp. Psychol. Gen. 143, 2074–2081 (2014).
Tesauro, G. Practical issues in temporal difference learning. Mach. Learn. 8, 257–277 (1992).
Mnih, V. et al. Human-level control through deep reinforcement learning. Nature 518, 529–533 (2015).
Silver, D. et al. Mastering the game of Go with deep neural networks and tree search. Nature 529, 484–489 (2016).
Huys, Q. J. et al. Interplay of approximate planning strategies. Proc. Natl Acad. Sci. USA 112, 3098–3103 (2015).
Solway, A. & Botvinick, M. M. Evidence integration in model-based tree search. Proc. Natl Acad. Sci. USA 112, 11708–11713 (2015).
Guez, A., Silver, D. & Dayan, P. Scalable and efficient Bayes-adaptive reinforcement learning based on Monte-Carlo tree search. J. Artif. Intell. Res. 48, 841–883 (2013).
Rasmussen, C. E. & Kuss, M. Gaussian processes in reinforcement learning. Adv. Neural Inf. Process. Syst. 16, 751–758 (2004).
Sutton, R. S. Generalization in reinforcement learning: successful examples using sparse coarse coding. Adv. Neural Inf. Process. Syst. 8, 1038–1044 (1996).
Lucas, C. G., Griffiths, T. L., Williams, J. J. & Kalish, M. L. A rational model of function learning. Psychon. Bull. Rev. 22, 1193–1215 (2015).
Schulz, E., Tenenbaum, J. B., Duvenaud, D., Speekenbrink, M. & Gershman, S. J. Compositional inductive biases in function learning. Cogn. Psychol. 99, 44–79 (2017).
Borji, A. & Itti, L. Bayesian optimization explains human active search. Adv. Neural Inf. Process. Syst. 26, 55–63 (2013).
Dayan, P. & Niv, Y. Reinforcement learning: the good, the bad and the ugly. Curr. Opin. Neurobiol. 18, 185–196 (2008).
Srivastava, V., Reverdy, P. & Leonard, N. E. Correlated multiarmed bandit problem: Bayesian algorithms and regret analysis. Preprint at https://arxiv.org/abs/1507.01160 (2015).
Wilke, A. et al. A game of hide and seek: expectations of clumpy resources influence hiding and searching patterns. PLoS ONE 10, e0130976 (2015).
Constantinescu, A. O., O’Reilly, J. X. & Behrens, T. E. Organizing conceptual knowledge in humans with a gridlike code. Science 352, 1464–1468 (2016).
Stojic, H., Analytis, P. P. & Speekenbrink, M. Human behavior in contextual multi-armed bandit problems. In Proc. 37th Annual Meeting of the Cognitive Science Society (eds Noelle, D. C. et al.) 2290–2295 (Cognitive Science Society, 2015).
Schulz, E., Konstantinidis, E. & Speekenbrink, M. Putting bandits into context: how function learning supports decision making. J. Exp. Psychol. Learn. Mem. Cogn. 44, 927–943 (2018).
Wu, C. M., Schulz, E., Garvert, M. M., Meder, B. & Schuck, N. W. Connecting conceptual and spatial search via a model of generalization. In Proc. 40th Annual Meeting of the Cognitive Science Society (eds Rogers, T. T., Rau, M., Zhu, X. & Kalish, C. W.) 1183–1188 (Cognitive Science Society, 2018).
Hills, T. T., Jones, M. N. & Todd, P. M. Optimal foraging in semantic memory. Psychol. Rev. 119, 431–440 (2012).
Abbott, J. T., Austerweil, J. L. & Griffiths, T. L. Random walks on semantic networks can resemble optimal foraging. Psychol. Rev. 122, 558–569 (2015).
Schulz, E., Tenenbaum, J. B., Reshef, D. N., Speekenbrink, M. & Gershman, S. Assessing the perceived predictability of functions. In Proc. 37th Annual Meeting of the Cognitive Science Society (eds Noelle, D. C. et al.) 2116–2121 (Cognitive Science Society, 2015).
Wright, K. agridat: Agricultural Datasets R Package Version 1.13 (2017); https://CRAN.R-project.org/package=agridat
Lindley, D. V. On a measure of the information provided by an experiment. Ann. Math. Stat. 27, 986–1005 (1956).
Nelson, J. D. Finding useful questions: on Bayesian diagnosticity, probability, impact, and information gain. Psychol. Rev. 112, 979–999 (2005).
Crupi, V. & Tentori, K. State of the field: measuring information and confirmation. Stud. Hist. Philos. Sci. A 47, 81–90 (2014).
Rasmussen, C. E. & Williams, C. K. I. Gaussian Processes for Machine Learning (Adaptive Computation and Machine Learning) (MIT Press, Cambridge, 2006).
Schulz, E., Speekenbrink, M. & Krause, A. A tutorial on Gaussian process regression: modelling, exploring, and exploiting functions. J. Math. Psychol. 85, 1–16 (2018).
Auer, P. Using confidence bounds for exploitation–exploration trade-offs. J. Mach. Learn. Res. 3, 397–422 (2002).
Neal, R. M. Bayesian Learning for Neural Networks (Springer, New York, 1996).
Shepard, R. N. Toward a universal law of generalization for psychological science. Science 237, 1317–1323 (1987).
Kaufmann, E., Cappé, O. & Garivier, A. On Bayesian upper confidence bounds for bandit problems. In Proc. 15th International Conference on Artificial Intelligence and Statistics (AISTAT) (eds Lawrence, N. D. & Girolami, M. A.) 592–600 (JMLR, 2012).
Stephan, K. E., Penny, W. D., Daunizeau, J., Moran, R. J. & Friston, K. J. Bayesian model selection for group studies. Neuroimage 46, 1004–1017 (2009).
Myung, I. J., Kim, C. & Pitt, M. A. Toward an explanation of the power law artifact: insights from response surface analysis. Mem. Cognit. 28, 832–840 (2000).
Palminteri, S., Wyart, V. & Koechlin, E. The importance of falsification in computational cognitive modeling. Trends Cogn. Sci. 21, 425–433 (2017).
Daw, N. D., O’Doherty, J. P., Dayan, P., Seymour, B. & Dolan, R. J. Cortical substrates for exploratory decisions in humans. Nature 441, 876–879 (2006).
Metzen, J. H. Minimum regret search for single- and multi-task optimization. Preprint at https://arxiv.org/abs/1602.01064 (2016).
Gotovos, A., Casati, N., Hitz, G. & Krause, A. Active learning for level set estimation. In International Joint Conference on Artificial Intelligence (IJCAI) (ed. Rossi, F.) 1344–1350 (AAAI Press/International Joint Conferences on Artificial Intelligence, 2013).
Cully, A., Clune, J., Tarapore, D. & Mouret, J.-B. Robots that can adapt like animals. Nature 521, 503–507 (2015).
Deisenroth, M. P., Fox, D. & Rasmussen, C. E. Gaussian processes for data-efficient learning in robotics and control. IEEE Trans. Pattern Anal. Mach. Intell. 37, 408–423 (2015).
Sui, Y., Gotovos, A., Burdick, J. & Krause, A. Safe exploration for optimization with Gaussian processes. In International Conference on Machine Learning (eds Bach, F. & Blei, D.) 997–1005 (PMLR, 2015).
Srinivas, N., Krause, A., Kakade, S. & Seeger, M. W. Gaussian process optimization in the bandit setting: no regret and experimental design. In Proc. 27th International Conference on Machine Learning (eds Fürnkranz, J. & Joachims, T.) 1015–1022 (Omnipress, 2010).
Mockus, J. Bayesian Approach to Global Optimization: Theory and Applications Vol. 37 (Springer, Dordrecht, 2012).
Reece, S. & Roberts, S. An introduction to Gaussian processes for the Kalman filter expert. In 13th Conference on Information Fusion (FUSION) 1–9 (IEEE, 2010).
LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. Nature 521, 436–444 (2015).
Schölkopf, B. Artificial intelligence: learning to see and act. Nature 518, 486–487 (2015).
Stachenfeld, K. L., Botvinick, M. M. & Gershman, S. J. The hippocampus as a predictive map. Nat. Neurosci. 20, 1643–1653 (2017).
Rouder, J. N., Speckman, P. L., Sun, D., Morey, R. D. & Iverson, G. Bayesian t-tests for accepting and rejecting the null hypothesis. Psychon. Bull. Rev. 16, 225–237 (2009).
van Doorn, J., Ly, A., Marsman, M. & Wagenmakers, E. J. Bayesian latent-normal inference for the rank sum test, the signed rank test, and Spearman’s ρ. Preprint at https://arxiv.org/abs/1712.06941 (2017).
Acknowledgements
We thank P. Todd, T. Pleskac, N. Bramley, H. Singmann and M. Moussaïd for helpful feedback. This work was supported by the International Max Planck Research School on Adapting Behavior in a Fundamentally Uncertain World (C.M.W.), by the Harvard Data Science Initiative (E.S.), and DFG grants ME 3717/2-2 to B.M. and NE 1713/1-2 to J.D.N. as part of the New Frameworks of Rationality (SPP 1516) priority programme. The funders had no role in study design, data collection and analysis, decision to publish or preparation of the manuscript.
Author information
Authors and Affiliations
Contributions
C.M.W. and E.S. designed the experiments, collected and analysed the data and wrote the paper. M.S., J.D.N. and B.M. designed the experiments and wrote the paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Supplementary Information
Supplementary Methods, Supplementary Figures 1–9, Supplementary Tables 1–3, Supplementary References
Rights and permissions
About this article

Cite this article
Wu, C.M., Schulz, E., Speekenbrink, M. et al. Generalization guides human exploration in vast decision spaces. Nat Hum Behav 2, 915–924 (2018). https://doi.org/10.1038/s41562-018-0467-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41562-018-0467-4
This article is cited by
-
A model of conceptual bootstrapping in human cognition
Nature Human Behaviour (2023)
-
Visuospatial information foraging describes search behavior in learning latent environmental features
Scientific Reports (2023)
-
Developmental changes in exploration resemble stochastic optimization
Nature Human Behaviour (2023)
-
Humans Adopt Different Exploration Strategies Depending on the Environment
Computational Brain & Behavior (2023)
-
Uncertainty quantification and exploration–exploitation trade-off in humans
Journal of Ambient Intelligence and Humanized Computing (2023)
