
Abstract
Ecology cannot yet fully explain why so many tree species coexist in natural communities such as tropical forests. A major difficulty is linking individual-level processes to community dynamics. We propose a combination of tree spatial data, spatial statistics and dynamical theory to reveal the relationship between spatial patterns and population-level interaction coefficients and their consequences for multispecies dynamics and coexistence. Here we show that the emerging population-level interaction coefficients have, for a broad range of circumstances, a simpler structure than their individual-level counterparts, which allows for an analytical treatment of equilibrium and stability conditions. Mechanisms such as animal seed dispersal, which result in clustering of recruits that is decoupled from parent locations, lead to a rare-species advantage and coexistence of otherwise neutral competitors. Linking spatial statistics with theories of community dynamics offers new avenues for explaining species coexistence and calls for rethinking community ecology through a spatial lens.
Similar content being viewed by others


Main
Understanding the mechanisms that maintain high species diversity in plant communities such as tropical forests has long challenged ecologists1 and has stimulated major efforts in field and theoretical ecology2,3,4,5. However, despite a multitude of coexistence mechanisms that have been proposed6 and recent advances in coexistence theories7,8,9,10,11,12,13,14,15,16,17,18, this fundamental question has not been fully resolved8,9,14. For example, theoretical models indicate that stable coexistence is difficult to reach in large communities11,13. We argue that consideration of spatial patterns of plant individuals, such as intraspecific clustering and interspecific segregation, may allow for a better understanding of mechanisms of coexistence in species-rich communities17.
Although many studies suggest that spatial patterns and neighbourhood effects may play an important role in diversity maintenance17,18,19,20,21, the integration of spatial patterns into coexistence theories of species-rich communities is difficult. A major difficulty is linking spatial processes at the individual level to community dynamics. One reason for this is a scale mismatch. The analytical models that form the basis of most coexistence theories7,8,11,12,13,14,15,16,22 have state variables that operate at the macroscale (that is, the population or community-level abundances), use parameters that describe average ‘mesoscale’ properties of the individuals (such as population-level interaction coefficients and demographic rates) and often rely on ‘mean-field’ approximations18,23 where spatial patterns are neglected. However, spatial patterns and population-level interaction coefficients emerge at the mesoscale from the microscale behaviour of individuals and their interactions with other individuals and the environment. Therefore, studying the impact of spatial patterns on species coexistence requires multiscale approaches such as spatial moment equations18,23,24 that incorporate pattern-forming processes operating at the level of individuals and translate these into population and community dynamics.
We propose here such a multiscale approach. To this end, we first derive population-level interaction coefficients αfi from individual-level interaction coefficients βfi and neighbourhood crowding indices19,21 that are commonly used to describe interactions among tree individuals at the microscale, and then incorporate the emerging coefficients αfi into analytical macroscale models. Our approach is based on separation of timescales (adiabatic approximation25), given that mesoscale spatial patterns usually build up quickly and approach a quasi-steady state whereas the macroscale state variables (for example, abundances) change slowly23. Therefore, we do not need to describe the dynamics of the quick mesoscale patterns explicitly (as, for example, is done in approaches based on moment equations18,23,24) but concentrate instead on spatial patterns that transport the critical information from the microscale into macroscale models. This approach requires information on mesoscale spatial patterns that can be obtained from fully mapped forest plots such as those of the Forest Global Earth Observatory (ForestGEO) network4.
More specifically, we (1) derive species-level interaction coefficients from individual-level interactions using empirical information on spatial patterns in nine ForestGEO megaplots4, (2) integrate the resulting species-level interaction coefficients into analytical macroscale multispecies models and (3) study their consequences for multispecies dynamics and coexistence.
Results and discussion
Species-level interaction coefficients
We first derive species-level interaction coefficients from individual-level neighbourhood crowding indices19,21,26 that quantify how the performance of a focal individual depends on interactions with its neighbours. To this end, we describe the survival rate of a focal individual k of species f in dependence on the local number of neighbours as
where sf is a density-independent background survival rate of species f; the crowding indices nkff, nkfi and nkfh are the number of conspecifics, neighbours of species i and heterospecific neighbours within distance R of a focal individual k, respectively; the subscript ‘h’ indicates all heterospecifics together (that is, nkfh = ∑i≠f nkfi) and the crowding index nkfβ weights each heterospecific neighbour by its relative competition strength βfi/βff (equation (1a)), with βfi being the individual-level interaction coefficients between species f and i (Fig. 1a–c). The corresponding population-level survival rate is given by
where Ni(t) is the abundance of species i at time step t and αfi is the population-level interaction coefficient between species f and i. To estimate survf we average the survival rates skf (equation (1a)) of all individuals k of species f:
where px and py are the distributions of the crowding indices x = nkff and y = nkfβ for individuals of species f, respectively.

a, The conspecific crowding index nkff is the number of conspecific neighbours (filled red circles) within distance R (black circle) of the focal individual k (filled red square). b, The heterospecific crowding index nkfh is the number of heterospecific neighbours (filled grey circles) within distance R of the focal individual k. c, The heterospecific interaction crowding index nkfβ additionally weights heterospecifics by their relative competitive effect βfi/βff, symbolized by the arrows. Different colours indicate different species. d, Distribution of the number nkff of conspecific neighbours with diameter at breast height (dbh) ≥ 10 cm of the species Castanopsis cuspidata of the 25 ha Fushan plot. e, Corresponding distribution of heterospecific neighbours nkfh. f, Corresponding distribution of the crowding index nkfβ. In d–f, blue lines show gamma distributions with the same means and variance-to-mean ratios as the observed distributions, and the vertical black line indicates the mean value. See Supplementary Data Table1 for additional examples.
To determine the distributions px and py, we analysed forest inventory data from nine 20–50 ha forest dynamics plots (Supplementary Table 1) in the ForestGEO network4. We used phylogenetic similarity between tree species as a surrogate for the relative competition strength βfi/βff because it is available for the species in the nine plots (Methods). This is an established approach in species-rich communities19,26,27 to approximate niche differences in the absence of other data.
The number of con- and heterospecific neighbours and the heterospecific interaction index nkfβ vary widely among conspecifics and can be described by gamma distributions (Fig. 1 and Extended Data Figs. 1 and 2). Detailed analysis of the empirical crowding indices reveals additional relationships that are relevant for our subsequent analysis. First, we find that the crowding indices nkff and nkfβ are not, or are only weakly, correlated for a given species f (Extended Data Fig. 3a). Second, we find for trees of a given species f high correlations between the two crowding indices nkfh and nkfβ (Extended Data Fig. 3b) with a common factor Bf (that is, nkfβ ≈ Bfnkfh). This result suggests operation of diffuse neighbourhood competition, in which the competition strength of heterospecifics is on average a factor Bf lower than that of conspecifics.
The integral of equation (2) can be solved analytically for independent gamma distributions px and py and yields
where \(\bar n_{ff}\) and \(\bar n_{f\beta }\) are the average values of the crowding indices nkff and nkfβ, respectively, and γff and γfβ contain the variance-to-mean ratios of the gamma distributions px and py, respectively, but in our case have values close to one (Methods).
The last step in deriving pairwise population-level interaction coefficients is to relate the averages of the different crowding indices to the macroscale population abundances Nf(t). We accomplish this by taking advantage of connections between crowding indices and the summary functions of spatial point process theory21. The mean of the crowding index nkff (that is, the mean number of further conspecific neighbours within distance R) is proportional to Ripley’s K, a well-known quantity in point process theory28,29:
where Kff(R) is the univariate K function for species f and A is the area of the observation window. The K function describes the spatial pattern of conspecifics within a neighbourhood distance R, indicating clustering if Kff(R) > πR2, a random pattern if Kff(R) = πR2 and regularity if Kff(R) < πR2. In the following, we use the normalized K function \(k_{ff}\left( R \right) = K_{ff}\left( R \right)/\uppi R^2\) to quantify the spatial neighbourhood patterns, and therefore \(\bar n_{ff} = k_{ff}\left( R \right)\frac{{\uppi R^2}}{A}N_f(t)\).
Analogously, the mean number of heterospecific neighbours is given by
where the bivariate normalized K function kfh(R) indicates segregation to heterospecifics (subscript ‘h’) within distance R if kfh(R) < 1. Independent placement occurs if kfh(R) = 1, and attraction if kfh(R) > 1.
Motivated by the finding nkfß ≈ Bf nkfh (Extended Data Fig. 3b) we rewrite the mean crowding index \(\bar n_{f\beta }\) as
where the point process summary function Bf indicates how much the competition strength of one heterospecific neighbour differs on average from that of one conspecific neighbour. The values of Bf depend mainly on the individual-level interaction coefficients βfi but also on the spatial pattern of the different species and their relative abundances (equation (12)).
Inserting the expressions for \(\bar n_{ff}\) and \(\bar n_{f\beta }\) into equation (3) and comparing with equation (1b) leads to our first main result, the analytical expressions of the population-level interaction coefficients:
with scaling constant c = πR2/A. Notably, equation (6b) indicates that the emerging population-level interaction coefficients αfi are the same for all heterospecifics (that is, αfi = αfh for i ≠ f). Thus, even if the individual-level interactions coefficients βfi differ among species pairs, the emerging population-level interaction coefficients αfi have a substantially simpler structure. This phenomenon is an example of simplicity emerging from complex species interactions30 and is likely to occur only in species-rich communities9,12,31.
The population-level interaction coefficients αfi depend on several factors that can influence the macroscale balance between intra- and interspecific competition: (1) intraspecific clustering kff and interspecific segregation kfh (Fig. 2a,b), (2) the relative competition strength Bf of one heterospecific neighbour (Fig. 2c) and (3) the shape of the response of survival to crowding (γff and γfβ, which contain the variance-to-mean ratios of the distribution of the crowding indices). Note that absence of spatial patterns (that is, kff = 1 and kfh = 1) and a linear approximation of equation (3) lead to γff = γfβ = 1 and direct proportionality αfi = cβfi of the individual- and population-level interaction coefficients, as assumed by Lotka–Volterra models.

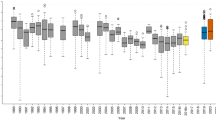
a–c, Distribution of the values of the different measures of spatial patterns, taken over the focal species of the different forest plots. Boxplots show the 10th, 25th, 50th, 75th and 90th percentiles; outliers are indicated by filled black points. Intraspecific clustering is indicated by kff > 1 and interspecific segregation by kfh < 1, and the less a heterospecific neighbour competes on average relative to a conspecific neighbour, the more Bf decreases. The neighbourhood radius used was R = 10 m. For the analysis, we used all individuals with dbh ≥ 10 cm and included focal species with more than 50 individuals. For forest plot names, see Supplementary Data Table 1.
The information on spatial patterns extracted from the inventory data of our nine forests allows us to estimate the relative population-level interaction coefficients αfi/αff for all pairs of species i and f (Fig. 3 and Extended Data Fig. 4). For example, at BCI, the values of αfi/αff differ substantially from the corresponding individual-level coefficients βfi/βff (Fig. 3a,c), and for 83% of all species pairs, we find αfi/αff < βfi/βff. Thus, the mesoscale spatial patterns can reduce, at the population level, the strength of heterospecific interactions relative to conspecific interactions by ‘diluting’ encounters with heterospecific neighbours relative to conspecific neighbours. Spatial patterns therefore have a strong potential to alter the outcome of deterministic individual-level interactions.

a, Relationship between the relative population-level interaction coefficients αfi/αff and the corresponding relative individual-level interaction coefficients βfi/βff, (equation (6)) for the 75 focal species of the BCI plot. The βfi/βff were based on phylogenetic dissimilarity. b, Distribution of the values of αfi/αff, taken over the 289 focal species of the different forest plot. Boxplots show the 10th, 25th, 50th, 75th and 90th percentiles; outliers are indicated by filled black points. For full, separate distributions for tropical, subtropical and temperate forests, see Extended Data Fig. 4. c, Example for the distribution of the relative individual- and population-level interaction coefficients for the BCI plot. The neighbourhood radius used was R = 10 m. For the analysis, we used all individuals with dbh ≥ 10 cm and included focal species with more than 50 individuals. For forest plot names, see Supplementary Data Table 1.
Conditions for coexistence in the multiscale model
To study the consequences of the emerging spatial patterns for community dynamics and coexistence we insert the population-level interaction coefficients αfi (equation (6)) into a simple macroscale model
In this model we assume that survival is governed by neighbourhood competition with αfi = αfh, and the number of recruits of species f during a time step Δt is given by rfNf(t), where rf is the per capita reproduction rate of species f.
The carrying capacity of species f (that is, the equilibrium of equation (7) with Ni(t) = 0 for all i ≠ f) is given by \(K_f = - \ln \left( {\frac{{1 - r_f}}{{s_f}}} \right) {\alpha _{ff}}^{-1}\). Note that our theory also applies, after redefinition of the carrying capacity, to alternative macroscale models (Supplementary Table 3). From equation (7) we find \(K_f = N_f^{\ast} + \frac{{\alpha _{f{\mathrm{h}}}}}{{\alpha _{ff}}}\mathop {\sum }\limits_{i \ne f} N_i^{\ast} = N_f^{\ast} \left( {1 - \frac{{\alpha _{f{\mathrm{h}}}}}{{\alpha _{ff}}}} \right) + \frac{{\alpha _{f{\mathrm{h}}}}}{{\alpha _{ff}}}J^{\ast}\), where \(N_f^{\ast}\) is the abundance of species f in equilibrium and J* the equilibrium community size (that is, \(J^{\ast} = \sum _i N_i^{\ast}\); see also equation (14)). This leads, under the assumption that the population-level interaction coefficients αfh are constant (Supplementary text), to a single equilibrium of the macroscale model for species f
that is positive if denominator and numerator are both positive or both negative. However, the invasion criterion (equation (18)) is only fulfilled if both are positive. In this case, equation (8) suggests two different ways a species can go extinct. First, the denominator indicates that a species with strong clustering kff will show a small equilibrium abundance since in this case αff ≫ αfh (equation (6)). Large values of kff can be expected for species of low abundance under dispersal limitation, where recruitment happens close to conspecific adults.
Second, the numerator of equation (8) indicates a positive abundance of species f if αffKf > αfhJ* and αfh/αff < 1. Therefore, we introduce a new feasibility index
that indicates a positive abundance if µf < 1 given that heterospecific interactions at the population level are weaker than conspecific interactions (that is, αfh/αff < 1). The invasion criterion7,8 that tests whether a species with low abundance can invade the equilibrium community of all other species turned out to be basically the same as the feasibility condition (equation (9)) if the invading species does not show strong clustering (Methods and equation (18)). Note that we did not assume Allee effects8.
Further analysis that considers the dependency of J* on the values of Kf and αfh/αff shows that the values of µf must be similar for all species f to fulfil the condition µf < 1, and that µf can show larger interspecific variability if the species richness S is smaller and/or if the mean of \(\frac{{\alpha _{f{\mathrm{h}}}}}{{\alpha _{ff}}} \left( {1 - \frac{{\alpha _{f{\mathrm{h}}}}}{{\alpha _{ff}}}} \right)^{-1}\) is smaller (equations (14) and (15)). The feasibility index µf therefore governs species assembly by determining the subset of species of a larger species pool that can persist13, but any addition of a new species changes µf and may lead to reassembly of the community.
Using the observed abundances in the forest plots (and assuming equilibrium) allows us to test our theory. We can estimate from the observed abundances the carrying capacities Kf and therefore also the indices µf for all focal species of our nine plots (Fig. 4). For 282 of our 289 focal species, we found µf < 1 and αfh/αff < 1, which means that the two conditions for stable coexistence are indeed satisfied for nearly all species. However, this is not a given, as shown by the seven species from BCI with µf > 1 and αfh/αff > 1. Thus, our theory is compatible with the observed coexistence of most species at our nine forest plots if the assumption of approximately constant population-level interaction coefficients holds.

a, The distribution of the index µf (equation (9)) for the 289 analysed tree species. The vertical dashed line indicates the median of the distribution. b, Distribution of µf, taken over the 289 analysed species of the different forest plot. Boxplots show the 10th, 25th, 50th, 75th and 90th percentiles; outliers are represented by black points. c, Relationship between the feasibility index µf and the ratio αfh/αff of heterospecific to conspecific population-level interaction coefficients. Values of µf < 1 indicate a positive abundance. The red lines show the dependence of µf on αfh/αff expected for communities without interspecific variability in µf (equation (10a)) with 18 focal species (CBS plot, lower line) and 75 focal species (BCI plot, upper line). The neighbourhood radius used was R = 10 m. For the analysis, we used all individuals with dbh ≥ 10 cm and included tree species with more than 50 individuals. For plot names, see Supplementary Data Table 1.
In addition, we get information on the typical values of µf and αfh/αff that allows for insight into the stability of the communities. In agreement with the predictions of our theory, we find that µf tends to be smaller if αfh/αff is smaller (Fig. 4c). Furthermore, the values of µf were, for most species, larger than the expectation of µf for the corresponding communities without interspecific variability in µf (equation (10a)) but with the same number of species and the same mean values of αfh/αff (Fig. 4c), but all of the values were relatively close to the critical value of 1 (the median of all 289 species was 0.938; Fig. 4a).
Consequences of spatial patterns for coexistence
Our theory predicts that coexistence requires, in the limit of high species richness, that species approach functional identity with respect to the feasibility index µf (Methods). This resembles neutral theory2,32, but our theory allows for trade-offs among demographic parameters and emerging spatial patterns to reach this equivalence (equation (9)). To study the consequences of spatial patterns for coexistence, we analysed a symmetric33 version of our model where all species have the same parameters and follow the same stochastic rules and where all individuals compete identically (leading to Bf = 1). Thus, we eliminate any potential coexistence mechanism other than that resulting from spatial patterns.
If the mesoscale patterns kff and kfh converge to a stochastic equilibrium, we find that the feasibility and invasion criteria are always fulfilled if αfh/αff < 1 since
Equations (10a) and (10b) follow from equations (16) and (18), respectively, if αfh/αff is the same for all species f. Thus, the spatial patterns that emerge at the mesoscale from the individual-level interactions can stabilize if αfh/αff < 1. The underlying mechanism is a positive fitness–density covariance34 (Methods).
To reveal the conditions that can lead to coexistence in a spatially explicit context, we use a spatially explicit and individual-based35 implementation of the symmetric version of the multiscale model (equation (7) and Methods). Models of this type are able to produce realistic spatial patterns consistent with mapped species distributions of large forest plots17,35. While our analytical approach in equation (7) only allows us to make simplified assumptions about the spatial component of the recruitment process, the simulation model allows us to explore the role of the spatial component of recruitment in more detail.
Indeed, the way recruits were placed was critical for coexistence. Randomly placed recruits produced unstable dynamics (Extended Data Fig. 5a) characterized by regularity (mean of kff = 0.92) and segregation (mean of kfh = 0.92), both caused by competition18, and the instability was caused by con- and heterospecifics competing equally at the population level (that is, αfh/αff ≈ 1) (Extended Data Fig. 5d,g). When we followed the common approach of placing recruits with a kernel around conspecific adults17,18,35,36,37,38,39 to mimic dispersal limitation, we again found unstable dynamics (Extended Data Fig. 5b), despite intraspecific clustering and interspecific segregation (that is, αfh/αff < 1; Extended Data Fig. 5n). The reason for the instability was high clustering of rare species24,35 (Extended Data Fig. 6) that completely negated the potentially positive effects of αfh/αff < 1.
In contrast, community dynamics can be stabilized if recruits are placed in small clusters but independent of the location of conspecific adults (Extended Data Fig. 5c). With this mechanism we mimic canopy gaps40, animal seed dispersal41 or other mechanisms that can generate clustering independent of parent locations, as found at BCI42. Decoupling clustering from the parent locations does not lead to the negative relationship between clustering and abundance, and all measures of spatial patterns converged quickly into quasi-equilibrium (Extended Data Fig. 5f,i,o).
The simulation data reveal the spatial coexistence mechanism underlying the positive fitness–density covariance34 (Extended Data Figs. 7 and 8). We find that the emerging spatial patterns lead to a situation where individuals of a common species are more likely to be near more neighbours and tend therefore to experience stronger competition (Extended Data Fig. 7). While the number of heterospecific neighbours remains approximately constant, the number of conspecific neighbours decreases with decreasing abundance if clustering does not change with abundance (equation (4a)). However, if clustering increases with decreasing abundance, the rare-species advantage is weakened and the dynamics become unstable24.
The data of several ForestGEO forest plots were compatible with a positive fitness–density covariance (Extended Data Fig. 8f–i) as they show that, when a species becomes rare, areas of higher conspecific crowding tend to have fewer total competitors. Comparison of the results of the stable versus unstable simulation showed that even relatively weak tendencies in this relationship are sufficient to stabilize the dynamics (Extended Data Figs. 8a,b). However, this was not the case for three temperate forest plots where the power-law clustering–abundance relationship showed exponents of b < −0.5 (that is, species tended to have high clustering at low abundances), but the other plots showed b > −0.5 (Extended Data Fig. 8n–p).
The apparent contradiction with previous theoretical studies18,24,35,37 where intraspecific clustering and interspecific segregation could not stabilize community dynamics thus arises as a consequence of the assumption of placing recruits close to their parents. This finding has important consequences for ecological theory because it shows, in contrast to the prevalent view36,43,44, that spatial patterns alone can lead to coexistence of multiple species. This is even more important since the specific spatial patterns required for this coexistence mechanism also exist in real forests.
Conclusions
Understanding the mechanisms that maintain high species diversity in communities such as tropical forests is at the core of ecological theory, but these mechanisms are not yet fully resolved. Here, we argue that spatial patterns may play an important role in species coexistence of high diversity plant communities17. To test this hypothesis, we introduced a multiscale framework that reveals how pattern-forming processes operating at the level of individuals translate into mesoscale spatial patterns and how those patterns influence macroscale community dynamics.
We showed that the population-level interaction coefficients αfi can have, for a broad range of common circumstances, a simpler structure than the underlying individual-level interaction coefficients βfi. This simplicity, which emerged from spatially explicit species interactions30, allowed for an analytical treatment of equilibrium, feasibility and invasion conditions of the corresponding macroscale models (equations (8–10)). Inserting the emerging αfi coefficients into macroscale community models (for example, equation (7); Supplementary Table 3) should, in principle, allow us to take advantage of macroscale theory9,11,12,13,45. However, our results also indicate that the population-level interaction coefficients may not be temporally constant as commonly assumed but depend on spatial patterns that may change with abundance. This is especially likely if recruitment is mainly located close to the parents.
It is also possible to expand our framework to take into account more detailed neighbourhood crowding indices that consider not only the number of neighboured trees of a given species but also their distance and size19,21,26. This requires redefinition of the quantities kff and kfh that describe intraspecific clustering and interspecific segregation, respectively, but does not change the overall structure of our equations. A special strength of our approach is that the population-level interaction coefficients contain measures of spatial neighbourhood patterns that can be directly estimated from fully mapped forest plots4. Together with additional information, this may allow for estimating network structures as well as stability of the whole community.
Our analysis revealed that communities of competing species can show a stable mode where the mesoscale patterns converge quickly into quasi-equilibrium and an unstable mode where negative relationships between species clustering and abundance emerge (Extended Data Figs. 5 and 6). The two modes are governed by the way species clustering is generated: the well-known unstable mode is related to clustering of recruits around their parents17,18,35,36,37,38,39 whereas the stable mode is related to clustering in locations that are independent from the parent locations, due, for example, to animal seed dispersal41 or canopy gaps40. This result calls for a closer examination of the spatial relationship between the recruits and adults. Indeed, independent placement of recruits from conspecific large trees may not be unusual. For example, Getzin et al.42 found in detailed analyses of the BCI forest that recruits were for most species spatially independent of large conspecific trees. For the stable mode we could identify conditions for coexistence, and forthcoming work may extend to quantifying the ability of additional mechanisms such as niche differences7,8, habitat associations46, spatial and temporal relative nonlinearity7,8 and storage effects7,8 to alleviate the destabilizing increase of clustering if species become rare.
This study explicitly incorporates spatial patterns in theoretical models of plant communities and combines analytical theory with spatial simulations and field data analysis. Our finding that species with similar attributes may show stable coexistence has profound implications for ecological theory. Furthermore, the multiscale framework we propose here opens exciting new avenues to explain species coexistence through a spatial lens.
Methods
Study areas
Nine large forest dynamics plots of areas between 20 and 50 ha were used in the present study (Supplementary Table 1). The forest plots are part of the ForestGEO network4 and are situated in Asia and the Americas at locations ranging in latitude from 9.15° N to 45.55° N. Tree species richness among the plots ranges from 36 to 468. All free-standing individuals with diameter at breast height (dbh) ≥1 cm were mapped, size measured and identified. We focused our analysis here on individuals with dbh ≥ 10 cm (resulting in a sample size of 131,582 individuals) and focal species with more than 50 individuals (resulting in 289 species). The 10 cm size threshold excludes most of the saplings and enables comparisons with previous spatial analyses20,35,47,48. Shrub species were also excluded.
Some of our analyses require estimation of the ratio βfi/βff that describes the relative individual-level competitive effect18 of individuals of species i on an individual of the focal species f. We used for this purpose phylogenetic distances49 based on molecular data, given in Myr, that assume that functional traits are phylogenetically conserved19,26,27. In this case, close relatives are predicted to compete more strongly or to share more pests than distant relatives26. To obtain consistent measures among forest plots, phylogenetic similarities were scaled between 0 and 1, with conspecifics set to 1, and a similarity of 0 was assumed for a phylogenetic distance of 1,200 Myr, which was somewhat larger than the maximal observed distance (1,059 Myr). This was necessary to avoid discounting crowding effects from the most distantly related neighbours26.
Observed spatial patterns at species-rich forests
Figure 1 and Supplementary Data Table 1 show the intraspecific variation in our three crowding indices nkff, nkfh and nkfβ that can be approximated by gamma distributions. To assess how well the gamma distribution described the observed distribution, we used an error index defined as the sum of the absolute differences of the two cumulative distributions divided by the number of bins (spanning the two distributions). The maximal value of the error index is one, and a smaller value indicates a better fit.
Equations (6, 8 and 9) relate the measures of the emerging spatial patterns (that is, kff, kfh and Bf) to macroscale properties and conditions for species coexistence. Even though our multiscale model (equation (7)) is simplified, it allows for a direct comparison with the emerging patterns in our nine fully stem-mapped forest plots. We estimate the key quantities of equations (8) and (9) directly from the forest plot data (Fig. 4), with the exception of the carrying capacities Kf, which were indirectly estimated from the observed species abundances (assuming approximate equilibrium; equation (8) and Supplementary Data Table 1). This allowed us to estimate the feasibility index µf (equation (9)). Because statistical analyses with individual-based neighbourhood models19,26 based on neighbourhood crowding indices have shown that the performance of trees depends on their neighbours for R between 10 and 15 m, we estimate all measures of spatial neighbourhood patterns with a neighbourhood radius of R = 10 m. Analyses with R = 15 or R = 20 gave similar results.
The spatial multispecies model and equilibrium
We use a general macroscale model to describe the dynamics of a community of S species:
where rf is the mean number of recruits per adult of species f within time step Δt, sf is a density-independent background survival rate of species f and the αfi are the population-level interaction coefficients, yielding αff = c γff kff βff and αfi = c γfβ kfh βff Bf (equation (6)). The βfi are the assumed individual-level interaction coefficients between individuals of species i and f; kff = Kff(R) / π R2 and kfh = Kfh(R) / π R2 measure intraspecific clustering and interspecific segregation, respectively, with Kff(R) being the univariate K function for species f and Kfh(R) the bivariate K function describing the pattern of all heterospecifics ‘h’ around individuals of species f. A is the area of the observation window.
Following equation (5), Bf can be estimated as
and is the weighted average of the relative individual-level interaction coefficients βfi/βff between species i and the focal species f, weighted by the mean number of individuals of species i in the neighbourhoods of the individuals of the focal species (that is, c kfi Ni(t)). For competitive interactions, Bf ranges between zero and one; Bf = 1 indicates that heterospecific and conspecific neighbours compete equally, and smaller values of Bf indicate reduced competition with heterospecific neighbours. The denominator can be rewritten in terms of segregation kfh to all heterospecifics and the total number of heterospecifics ∑i≠f Ni(t).
The analytical expression of the equilibrium (equation (8)) relies on the assumption that the values of Bf are approximately constant in time. This assumption may not apply in our model during the initial burn-in phase of the simulations if the βfi/βff show large intraspecific variability (Supplementary Text and Figs. 1–5). The underlying mechanism is the central niche effect introduced by Stump45 where a species has reduced average fitness if it has high niche overlap with competitors.
Finally, the factors γff = ln(1 + bff βff) (bff βff)−1 and γfβ = ln(1+ bfβ βff) (bfβ βff)−1 describe the influence of the variance-to-mean ratios bff and bfβ of the gamma distribution of the crowding indices nkff and nkfβ, respectively. For high survival rates during one time step (for example, >85%), the values of γff and γfβ are close to one; in this case the exponential function in equation (1a) can be approximated by its linear expansion and γff = γfβ = 1.
In equilibrium we have (Nf(t + Δt) ‒ Nf(t))/Δt = 0, which leads, with equation (7), to:
with \(K_f = - {\mathrm{ln}}\left( {\frac{{1 - r_f}}{{s_f}}} \right) \left( \alpha _{ff} \right)^{-1}\) and the total number of individuals being \(J^{\ast} = \sum _iN_i^{\ast}\). Rewriting equation (13) yields \(\frac{K_f}{J^{\ast}} = \left( \frac{N_f^{\ast}}{J^{\ast}} \right) \left(1- \frac{\alpha_{f{\mathrm{h}}}}{\alpha_{ff}}\right) + \frac{\alpha_{f{\mathrm{h}}}}{\alpha_{ff}}\). For αfh/αff < 1 we therefore find Kf < J*, which indicates that a multispecies forest would host more individuals than a monoculture. To estimate J* we sum equation (13) over all species i and find \(J^{\ast} = \mathop {\sum }\limits_i \frac{{K_i}}{{1 - \alpha _{i{\mathrm{h}}}/\alpha _{ii}}} - J^{\ast} \mathop {\sum }\limits_i \frac{{\alpha _{i{\mathrm{h}}}/\alpha _{ii}}}{{1 - \alpha _{i{\mathrm{h}}}/\alpha _{ii}}}\). Therefore, we obtain
with \(m_K = \frac{1}{S}\mathop {\sum }\limits_i^{\,} \frac{{K_i}}{{1 - \alpha _{i{\mathrm{h}}}/\alpha _{ii}}}\) and \(m_\alpha = \frac{1}{S}\mathop {\sum }\limits_i^{\,} \frac{{\alpha _{i{\mathrm{h}}}/\alpha _{ii}}}{{1 - \alpha _{i{\mathrm{h}}}/\alpha _{ii}}}\) being averages over the S species of the community.
All species have positive abundances at equilibrium if the two conditions µf = αfhJ*/αffKf < 1 and αfh/αff < 1 are met (see equation (9)). We now show that the chance that these conditions are satisfied for all species is larger if the values of µf show little intraspecific variability. To understand this, we assume that the µf can be approximated by their mean \(\bar \mu\). In this case \(J^{\ast} /\bar \mu\) is also approximately constant and we can replace Ki in equation (14) by \((J^{\ast} /\bar \mu ) (\alpha _{i{\mathrm{h}}}/\alpha _{ii})^{-1}\) and obtain
where S is the number of species in the community, and therefore
Thus, in the case of a perfect interspecific balance in µf we always have a feasible equilibrium if αfh/αfh < 1, and species can go extinct only if the intraspecific variability in µf becomes too large. The smaller the mean value of µf, the more variability in µf is allowed. Equation (16) shows that \(\bar \mu\) is smaller if the number S of species in the community is smaller and/or if the mean value of mα is smaller.
Equation (16) also suggests that communities with more species need to show stronger species equivalence in µf because the term S mα(1 + S mα)−1 approaches a value of one for a large number of species S. This finding mirrors the results of analyses of Lotka–Volterra models with random interaction matrices11 that showed that the larger the number of species S, the more difficult it becomes to generate a feasible community.
Invasion criterion
Using the population-level interaction coefficients (equation (6)) in the macroscale model, we now derive conditions for coexistence based on the invasion criterion7,8 for a species m. The growth rate of an invading species m with low density M(t) into the equilibrium community of all other S – 1 species Ni(t) should be positive; thus, with equation (7), we have
Considering that \(J_m^{\ast} = \mathop {\sum}\nolimits_{i = 1}^{S - 1} {N_i^{\ast}}\) and \(\alpha_{mm} M(t) \ll \alpha_{f{\mathrm{h}}} J_m^{\ast}\) (that is, the invading species m is at low abundance and does not show strong clustering) we find \(- \ln \left( \frac{1-r_m}{s_m} \right) > \alpha_{m{\mathrm{h}}} J_m^ \ast\), and by dividing by αmm we obtain the invasion condition
which is basically identical to the condition for feasibility (equation (9)), but here the community size \(J_m^ \ast\) of the reduced community appears instead of the equilibrium community size J* of all species, including species m. Thus, a new species m is more likely to invade if it has a high value of the carrying capacity Km and if it more strongly reduces heterospecific interactions relative to conspecific interaction (that is, αmh/αmm is smaller). However, if the species is too efficient (that is, has too large a capacity Km and/or too low an αmh/αmm) it may increase the value of J* too much (equation (14)), thereby causing the extinction of the weakest species with the highest values of µf (that is, a too-low value of Km and a too-high value of αfh/αff). Equation (18) also suggest that an equilibrium with µf > 1 and αmh/αmm > 1 will be unstable.
Fitness–density covariance
To place our new spatial coexistence mechanism in the context of existing coexistence theory, we apply scale transition theory34 to our model version where spatial effects are the only potential coexistence mechanism (that is, all species have the same parameters and all individuals compete equally; βfi/βff = 1, Bf = 1).
Following equation (1a), the expected fitness of an individual k of a focal species f (that is, its expected contribution to the population after some defined interval of time Δt) in the macroscale model (equation (7)) is
where Wk = nkff + ∑i≠fnkfi is the fitness factor of individual k, f(Wk) = exp(−βff Wk) is the fitness function and nkff and ∑i≠f nkfi are the number of conspecific and heterospecific neighbours, respectively, of individual k within distance R. The spatial average of the fitness factor over the entire plot is
where c = πR2 / A, and J(t) = ∑iNi(t) is the total number of individuals in the plot. Given that J(t) converges very quickly into equilibrium J* (Extended Data Fig. 5 and Supplementary Figs. 1 and 2), we find for the spatial average fitness \(\bar \lambda _f = 1\).
The average individual fitness \(\tilde \lambda _f(t)\) of a focal species f is the average of λk,f over all individuals k of species f and can be estimated for the macroscale model (equations (6 and 7)) as \(\tilde \lambda _f\left( t \right) = N_f\left( {t + {\Delta}t} \right)/N_f\left( t \right)\). A key ingredient of scale transition theory34 is that the fitness–density covariance is given by \({\mathrm{cov}} = \tilde \lambda _f\left( t \right) - \bar \lambda _f\). With equation (3) and γff ≈ γfβ ≈ 1 and \(\bar n_{f\beta } = \bar n_{f{\mathrm{h}}}\) we find
where the mean of the crowding indices is given by \(\bar n_{ff}(N_f) = ck_{ff}(N_f)N_f\) and \(\bar n_{f{\mathrm{h}}}(N_f) = ck_{f{\mathrm{h}}}(J^{\ast} - N_f)\) (equation (4)). Therefore, if clustering kff and segregation kfh are independent from abundance Nf, more abundant species have more neighbours, since
Thus, a positive fitness–density covariance in our model means that individuals of a common species are more likely to be near more trees in total.
Extended Data Fig. 7 shows the quantities \(\bar n_{ff} + \bar n_{f{\mathrm{h}}}\), \(\bar n_{ff}\), \(\bar n_{f{\mathrm{h}}}\) and \(\tilde \lambda _f - \bar \lambda _f\) plotted over abundance Nt for data generated by our spatially explicit simulation model for the scenarios of stable and unstable dynamics (Extended Data Fig. 5b,c). Indeed, the stable simulations show a positive fitness–density covariance, however, there is no such trend for the dynamics of the unstable community (Extended Data Fig. 7g,h).
Spatial patterns will act as positive fitness–density covariance if, when a species becomes rare, areas of high conspecific crowding have fewer competitors. We tested this for the data generated by our simulation model and for the nine forest plots (Extended Data Fig. 8). We could estimate for each focal species f the covariance between the number of conspecific neighbours (that is, nkff) and the total number of neighbours (that is, nkff + nkfh) and demand that the covariance should be mostly positive and larger for more abundant species. However, since the quantity nkff appears in this test on both sides, a positive covariance can be expected. To compensate for this artefact, we instead used the covariance between the local dominance of conspecifics in the neighbourhood of individuals k (that is, dkff = nkff (nkff + nkfh)−1) and total number of neighbours (that is, nkff + nkfh) (Extended Data Fig. 8).
Spatially explicit simulation model
The model is a spatially explicit and stochastic implementation of the spatial multispecies model (equation (7)), similar to that of May et al.35,37 and Detto and Muller-Landau17, and simulates the dynamics of a community of S tree species in a given plot of a homogeneous environment (for example, 50 ha) in 5 yr time steps adapted to the ForestGEO census interval (Extended Data Fig. 5 and Supplementary Figs. 1 and 2). Only reproductive (adult) trees are considered, but size differences between them are not considered. During a given time step the model first simulates stochastic recruitment of reproductive trees and placement of recruits, and second, stochastic survival of adults that depends on the neighbourhood crowding indices for conspecifics (nkff) and heterospecifics (nkfβ) (but excluding recruits). In the next time step, the recruits count as reproductive adults and are subject to mortality. No immigration from a metacommunity is considered. To avoid edge effects, torus geometry is assumed.
The survival probability of an adult k of species f is given by \(s_f \exp \left(-\beta_{ff} \left( n_{kff}+n_{kf\beta}\right)\right)\) (equation (1a)). The two neighbourhood indices nkff and nkfβ describe the competitive neighbourhood of the focal individual k and sum up all conspecific and heterospecific neighbours, respectively, within distance R, but weight them with the relative individual-level interaction coefficients βfi/βff (refs. 19,21,26).
Each individual produces on average rf recruits, and their locations are determined by a type of Thomas process28 to obtain clustering. To this end, the spatial position of the recruits is determined by two independent mechanisms. First, a proportion 1 – pd of recruits is placed stochastically around randomly selected conspecific adults by using a two-dimensional kernel function (here a Gaussian with variance σ2). This is the most common way to generate species clustering in spatially explicit models17,18,35,36,37,38,39. Specifically, we first randomly select one parent for each of these recruits among the conspecific adults and then determine the position of the recruit by sampling from the kernel. Second, the remaining proportion pd of recruits is distributed in the same way around randomly placed cluster centres that are located independently of conspecific adults. This mode mimics spatial clustering of recruits independent of the parent locations42 in a simple way, such as contagious seed dispersal by animals50 or forest gaps that may imprint clumped distributions of recruits of pioneer species40. For each species we assume a density λfc of randomly distributed cluster centres, which have, at each time step, a probability pfp of changing location. For each of these recruits, we first randomly select one cluster centre among the cluster centres of the corresponding species and then determine the position of the recruit by sampling from the kernel. For the simulation shown in Extended Data Fig. 5a, the recruits were located at random positions within the plot.
Parameterization of the simulation model
Extended Data Fig. 5 shows simulations of the individual-based model conducted in a 200 ha area containing approximately 83,000 trees with, initially, 80 species. There was no immigration. The model parameters were the same for all species, and all species followed exactly the same model rules. We selected βfi = βff to obtain no differences in con- and heterospecific interactions and sf = 1 (no background mortality), and we adjusted the parameters βff = 0.0075 and rf = 0.1 to yield tree densities (415 ha−1) and an overall 5 yr mortality rate (10%) similar to those of trees with dbh ≥ 10 cm in the BCI plot51.
The Gaussian kernel used to place recruits around conspecific adults or around random cluster centres had a parameter σ = 10 m. There were 40 random cluster centres in total for each species that had a probability of pfp = 0.3 of changing location within one census interval. The only difference between the simulation shown in Extended Data Fig. 5b and the one shown in Extended Data Fig. 5c is that in the former, we used a proportion pd = 0.05 of recruits to be placed around randomly distributed cluster centres (that is, 95% of the recruits were placed close to their parents), but in the latter, we selected pd = 0.95 (that is, 95% of the recruits were placed around randomly distributed cluster centres). In our simulations, on average, one of these cluster centres received four recruits per time step, which were scattered within a radius of approximately 30 m, and received approximately 13 recruits during its lifetime (at each time step it had a probability of 0.3 of changing location). In contrast, in Extended Data Fig. 5a recruits were placed at random locations within the plot.
Reporting Summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Data availability
The data that support the findings in this manuscript (and the raw data for Figs. 2–4 and Extended Data Figs. 2–4 and 8) can be found in Supplementary Data Table 1. To generate this data, we used the raw census data of the ForestGEO network that can only be shared on request because most PIs have not made them publicly available. For data requests see https://forestgeo.si.edu/sites-all.
Code availability
The source code of the simulation model is provided in the Supplementary Information.
References
Hutchinson, G. E. The paradox of plankton. Am. Nat. 95, 137–147 (1961).
Hubbell, S. P. The Unified Neutral Theory of Biodiversity and Biogeography (Princeton Univ. Press, 2001).
Usinowicz, J. et al. Temporal coexistence mechanisms contribute to the latitudinal gradient in forest diversity. Nature 550, 105–108 (2017).
Anderson-Teixeira, K. J. et al. CTFS-ForestGEO: a worldwide network monitoring forests in an era of global change. Glob. Change Biol. 21, 528–549 (2015).
Comita, L. S. et al. Testing predictions of the Janzen–Connell hypothesis: a meta-analysis of experimental evidence for distance and density-dependent seed and seedling survival. J. Ecol. 102, 845–856 (2014).
Wright, J. S. Plant diversity in tropical forests: a review of mechanisms of species coexistence. Oecologia 130, 1–14 (2002).
Chesson, P. Mechanisms of maintenance of species diversity. Annu. Rev. Ecol. Syst. 31, 343–366 (2000).
Barabás, G., D’Andrea, R. & Stump, S. M. Chesson’s coexistence theory. Ecol. Monogr. 88, 277–230 (2018).
Levine, J. M., Bascompte, J., Adler, P. B. & Allesina, S. Beyond pairwise mechanisms of species coexistence in complex communities. Nature 546, 56–64 (2017).
HilleRisLambers, J., Adler, P. B., Harpole, W. S., Levine, J. M. & Mayfield, M. M. Rethinking community assembly through the lens of coexistence theory. Annu. Rev. Ecol. Syst. 43, 227–248 (2012).
Stone, L. The feasibility and stability of large complex biological networks: a random matrix approach. Sci. Rep. 8, 8246 (2018).
Saavedra, S. et al. A structural approach for understanding multispecies coexistence. Ecol. Monogr. 87, 470–486 (2017).
Serván, C. A., Capitán, J. A., Grilli, J., Morrison, K. E. & Allesina, S. Coexistence of many species in random ecosystems. Nat. Ecol. Evol. 2, 1237–1242 (2018).
Kraft, N. J. B., Godoy, O. & Levine, J. M. Plant functional traits and the multidimensional nature of species coexistence. Proc. Natl Acad. Sci. USA 112, 797–802 (2015).
Allesina, S. & Tang, S. Stability criteria for complex ecosystems. Nature 483, 205–208 (2012).
Barbier, M., Arnoldi, J.-F., Bunin, G. & Loreau, M. Generic assembly patterns in complex ecological communities. Proc. Natl Acad. Sci. USA 115, 2156–2161 (2018).
Detto, M. & Muller-Landau, H. C. Stabilization of species coexistence in spatial models through the aggregation–segregation effect generated by local dispersal and nonspecific local interactions. Theor. Pop. Biol. 112, 97–108 (2016).
Bolker, B. & Pacala, S. W. Spatial moment equations for plant competition: understanding spatial strategies and the advantage of short dispersal. Am. Nat. 153, 575–602 (1999).
Uriarte, M. et al. Trait similarity, shared ancestry and the structure of neighbourhood interactions in a subtropical wet forest: implications for community assembly. Ecol. Lett. 13, 1503–1514 (2010).
Wang, X. et al. Stochastic dilution effects weaken deterministic effects of niche-based processes on the spatial distribution of large trees in species rich forests. Ecology 97, 347–360 (2016).
Wiegand, T. et al. Spatially explicit metrics of species diversity, functional diversity, and phylogenetic diversity: insights into plant community assembly processes. Annu. Rev. Ecol. Syst. 48, 329–351 (2017).
Godoy, O. & Levine, J. M. Phenology effects on invasion success: insights from coupling field experiments to coexistence theory. Ecology 75, 726–736 (2014).
Dieckmann, U. & Law, R. in The Geometry of Ecogical Interactions: Simplifying Spatial Complexity (eds. Dieckmann, U. et al.) Ch. 21 (Cambridge Univ. Press, 2000).
Klausmeier, C.A. & Tilman, D. in Competition and Coexistence (eds. Sommer, U. & Worm, B.) Ch. 3 (Springer, 2002).
Fahse, L., Wissel, C. & Grimm, V. Reconciling classical and individual-based approaches in theoretical population ecology: a protocol for extracting population parameters from individual-based models. Am. Nat. 152, 838–852 (1998).
Fortunel, C., Valencia, R., Wright, S. J., Garwood, N. C. & Kraft, N. J. B. Functional trait differences influence neighbourhood interactions in a hyperdiverse Amazonian forest. Ecol. Lett. 19, 1062–1070 (2016).
Cadotte, M. W., Davies, T. J. & Peres-Neto, P. R. Why phylogenies do not always predict ecological differences. Ecol. Monogr. 87, 535–551 (2017).
Wiegand, T. & Moloney, K. A. A Handbook of Spatial Point Pattern Analysis in Ecology (CRC Press, 2014).
Illian, J., Penttinen, A., Stoyan, H. & Stoyan, D. Statistical Analysis and Modelling of Spatial Point Patterns (Wiley, 2008).
Wang, S. Simplicity from complex interactions. Nat. Ecol. Evol. 2, 1201–1202 (2018).
Wilson, W. G. et al. Biodiversity and species interactions: extending Lotka–Volterra community theory. Ecol. Lett. 6, 944–952 (2003).
Hubbell, S. P. Neutral theory and the evolution of functional equivalence. Ecology 87, 1387–1398 (2006).
Rosindell, J., Hubbell, S. P. & Etienne, R. S. The unified neutral theory of biodiversity and biogeography at age ten. Trends Ecol. Evol. 26, 340–348 (2011).
Chesson, P. Scale transition theory: its aims, motivations and predictions. Ecol. Complex. 10, 52–68 (2012).
May, F., Wiegand, T., Lehmann, S. & Huth, A. Do abundance distributions and species aggregation correctly predict macroecological biodiversity patterns in tropical forests? Glob. Ecol. Biogeogr. 25, 575–585 (2016).
Murrell, D. When does local spatial structure hinder competitive coexistence and reverse competitive hierarchies? Ecology 91, 1605–1616 (2010).
May, F., Wiegand, T., Huth, A. & Chase, J. M. Scale-dependent effects of conspecific negative density dependence and immigration on biodiversity maintenance. Oikos 129, 1072–1083 (2020).
Rosindell, J. & Cornell, S. J. Species–area relationships from a spatially explicit neutral model in an infinite landscape. Ecol. Lett. 10, 586–595 (2007).
Chave, J. & Leigh, G. L. A spatially explicit neutral model of betadiversity in tropical forests. Theor. Pop. Biol. 62, 153–168 (2002).
Hubbell, S. P. et al. Light-gap disturbances, recruitment limitation, and tree diversity in a neotropical forest. Science 283, 554–557 (1999).
Chanthorn, W., Getzin, S., Wiegand, T., Brockelman, W. Y. & Nathalang, A. Spatial patterns of local species richness reveal importance of frugivores for tropical forest diversity. J. Ecol. 106, 925–935 (2018).
Getzin, S., Wiegand, T. & Hubbell, S. P. Stochastically driven adult-recruit associations of tree species on Barro Colorado Island. Proc. R. Soc. B 281, 20140922 (2014).
Chesson, P. & Neuhauser, C. Intraspecific aggregation and species coexistence. Trends Ecol. Evol. 17, 210–211 (2002).
Ruokolainen, L. & Hanski, I. Stable coexistence of ecologically identical species: conspecific aggregation via reproductive interference. J. Anim. Ecol. 85, 638–647 (2016).
Stump, S. Multispecies coexistence without diffuse competition; or, why phylogenetic signal and trait clustering weaken coexistence. Am. Nat. 190, 213–228 (2017).
Harms, K. E., Condit, R., Hubbell, S. P. & Foster, R. B. Habitat associations of trees and shrubs in a 50-ha neotropical forest plot. J. Ecol. 89, 947–959 (2001).
Wiegand, T. et al. Testing the independent species’ arrangement assertion made by theories of stochastic geometry of biodiversity. Proc. R. Soc. B 279, 3312–3320 (2012).
Wiegand, T., Gunatilleke, C. V. S., Gunatilleke, I. A. U. N. & Huth, A. How individual species structure diversity in tropical forests. Proc. Natl Acad. Sci. USA 104, 19029–19033 (2007).
Erickson, D. L. et al. Comparative evolutionary diversity and phylogenetic structure across multiple forest dynamics plots: a mega-phylogeny approach. Front. Genet. 5, 358 (2014).
Howe, H. F. Scatter- and clump-dispersal and seedling demography: hypothesis and implications. Oecologia 79, 417–426 (1989).
Wiegand, T., May, F., Kazmierczak, M. & Huth, A. What drives the spatial distribution and dynamics of local species richness in tropical forests. Proc. R. Soc. B 284, 20171503 (2017).
Acknowledgements
X.W. was supported by the Strategic Priority Research Program of the Chinese Academy of Sciences (Grant XDB31030000), the National Natural Science Foundation of China (Grant 31961133027), the Key Research Program of Frontier Sciences, Chinese Academy of Sciences (Grant ZDBS-LY-DQC019) and the K.C. Wong Education Foundation. T.W. and A.H. were supported by the ERC advanced grant 233066. M.C. and X. M were supported by the National Natural Science Foundation (32061123003 and 31770478). L.L. was supported by the Joint Fund of the National Natural Science Foundation of China-Yunnan Province (U1902203). The FS plot project was supported by the Taiwan Forestry Bureau, the Taiwan Forestry Research Institute and the Ministry of Science and Technology. The BCI censuses have been made possible through support of the US National Science Foundation (awards 8206992, 8906869, 9405933, 9909947, 0948585 to S.P. Hubbell), the John D. and Catherine D. McArthur Foundation and the Smithsonian Tropical Research Institute. We also thank the hundreds of people who contributed to the collection and management of the data from the plots. This work builds on discussion of the working group sNiche (Expanding neo-Chessonian coexistence theory towards a stochastic theory for species-rich communities) supported by sDiv, the Synthesis Centre of iDiv (DFG FZT 118). We thank S. Lehmann, D. Alonso and S. Harpole for discussion, and especially S. Stump for valuable feedback on earlier drafts.
Author information
Authors and Affiliations
Contributions
T.W. and X.W. conceived and designed the project. T.W. implemented the simulation model, conducted the simulations, analysed the results and prepared figures and tables. T.W. and A.H. led the writing of the manuscript. X.W. assembled and analysed the plot data and conducted the spatial analyses. K.J.A.-T., N.B., M.C, X.C., S.J.D, Z.H., R.H., W.J.K., J. Lian, J. Li, L.L., Y.L., K.M., W.M., X.M., S.-H.S., I.-F.S., A.W., X.W. and W.Y. contributed to the acquisition of the data used in the paper and in revising the manuscript. All authors have given final approval to publish this manuscript and agree to be accountable for the aspects of the work that they conducted.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Peer review information Nature Ecology & Evolution thanks Simon Stump and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data
Extended Data Fig. 1 Examples for intraspecific variability in the crowding indices.
a, b, c, Malus baccata, Baihua plot. d, e, f, Alseis blackiana, BCI plot. g, h, i, Tilia amurensis, CBS plot. j, k, l, Machilus chinensis, DHS plot. m, n, o, Toxicodendron succedaneum, GTS plot. p, q, r, Fraxinus americana WAB plot. s, t, u, Diospyros hasseltii XSBN Plot. v, w, x, Quercus prinus, SCBI plot. Left: number of conspecific neighbours (nkff), middle: number of heterospecific neighbours (nkfh), and right: heterospecifics neighbours weighted by their relative competitive effect βfi/βff (nkfβ). We used a 10 m plant neighbourhood19,26 and phylogenetic similarity as surrogate for pairwise interaction strength19,26. Solid blue lines show gamma distributions with the same mean and variance-to-mean as the observed distributions, and the vertical red lines indicates the mean values. The 95% percentiles for the error indices quantifying the departures from a Gamma distribution for all 289 focal species were 0.051, 0.027, and 0.022 for nkff, nkfh, nkfβ, respectively, indicating a reasonable fit.
Extended Data Fig. 2 Characteristics of the neighbourhood crowding indices.
Distribution of the mean and the variance-to-mean ratio of the crowding indices for the different species at each forest plot with boxplots indicating 10th, 25th, 50th, 75th, 90th percentiles and outliers. a. The mean \(\bar n_{ff}\) of the conspecific neighbourhood crowding index nkff over species. b. The mean \(\bar n_{fh}\) of the heterospecific neighbourhood crowding index nkfh over species. c. The mean \(\bar n_{f\beta }\) of the interaction neighbourhood crowding index nkfβ over species. d. The variance-to-mean ratio bkf of the conspecific neighbourhood crowding index nkff over species. e. The variance-to-mean ratio bkh of the heterospecific neighbourhood crowding index nkfh over species. f. The variance-to-mean ratio bkβ of the interaction neighbourhood crowding index nkfβ over species. The neighbourhood radius was R = 10 m. We used for the analysis all individuals with dbh ≥ 10 cm and included focal species with more than 50 individuals. For plot names see Supplementary Table 1.
Extended Data Fig. 3 Correlation between different crowding indices.
We estimated for all individuals of a species f the correlation between their crowding indices nkff and nkfβ (a) and nkfh and nkfβ (b). The crowding index nkff counts the conspecific neighbours of individual k within distance R = 10 m, nkfh counts the corresponding number of heterospecific neighbours, and nkfβ weights each heterospecific neighbour by its relative competition strength βfi/βff. The boxplots show the distribution of the Pearson correlation coefficients for each focal species, separately for the nine forest plots, indicating 10th, 25th, 50th, 75th, 90th percentiles and outliers. We used for the analysis all individuals with dbh ≥ 10 cm and included focal species with more than 50 individuals. For plot names see Supplementary Table 1.
Extended Data Fig. 4 The distribution of the relative population-level interaction coefficients.
a, The distribution of the relative population level interaction coefficients αfi/αff for the focal species of the tropical forests, resulting from equation 6. b, same as a, but for subtropical forests. c, same as a, but for temperate forests. Other conventions as in Fig. 3.
Extended Data Fig. 5 Spatial patterns can stabilize community dynamics of symmetric species.
Individual-based simulations of a symmetric model with initially 80 identical species, simulated on an area of 200 ha without immigration for 5000 time steps (25,000 years). Different colours correspond to different species. left, Recruits were randomly distributed, the dynamics is unstable with 2 extinctions. middle, Recruit were mostly scattered around conspecific adults, the dynamics is unstable with 7 extinctions. right, recruits were mostly scattered around random cluster centre, the dynamics is stable without extinctions. a –c, Species abundances with the bold black line indicating the expected mean abundance J*/80. d–f, Intraspecific pattern kff. g–i, Interspecific pattern kfh of heterospecifics with respect to the foal species f. j–l, the mean relative interaction strength Bf of a heterospecific neighbour of an individual of species f. m–o, Stabilization, being the population-level heterospecific interaction strength relative to the corresponding conspecific interaction strength (that is, αfh/αff). Note the different scale of the y-axes. Spatial patterns were measured at a 10 m neighbourhood.
Extended Data Fig. 6 The relationship between clustering and abundance.
Shown are detailed results of the simulation of Extended Data Fig. 5b for two species that went extinct. a, Dynamics of the relationship between abundance Nf(t) and clustering kff for species 1. b, same for species 3. The solid line indicates the power law kff = 10,000/Nf(t).
Extended Data Fig. 7 Mechanism underlying the fitness-density covariance in our simulation model.
Quantities involved in the estimation of the fitness–density covariance (equation 21) for model simulations of the stable scenario (left) and the unstable scenario (right). The data were taken from time step 5000 of the simulations shown in Extended Data Fig. 5c (stable dynamics) and of Extended Data Fig. 5b (unstable dynamics). Panels show the mean number \(\bar n_{ff} + \bar n_{fh}\) of all neighbours (a, b), of conspecific neighbours \(\bar n_{ff}\) (c, d), of heterospecific neighbours \(\bar n_{fh}\) (e, f), and the resulting fitness-density covariance \(\tilde \lambda _f - \bar \lambda _f\) (g, h), of all species plotted over their abundance. The red lines show the expected relationship based on equations (21) and (22). We fitted power law relationships kff(Nf) = a Nfb to the data. For stable dynamics we find kff(Nf) = 8.2, kfh(Nf) = 0.905 and for unstable dynamics kff(Nf) = 3723/Nff0.883 and kfh (Nf) = 0.890.
Extended Data Fig. 8 Rare species advantage and abundance −clustering relationships in model simulations and ForestGEO plots.
The covariance between the local dominance dkff of species f (that is, dkff = nkff/(nkff + nkfh)) and the total number of neighbours (that is, nkff + nkfh). A positive relationship of the covariance with abundance indicates that, when a species becomes rare, areas of higher conspecific crowding have fewer competitors. Shown are results of model simulations (a, b) and the nine ForestGEO forest plots (c–k). The p-value is for the null hypothesis that the slope of the linear regression (red lines) is not positive. (l–v) The corresponding relationships between clustering kff and abundance Nf. The value of b is the slope of the power law kff(Nf) = a Nfb (red line). We used for the analysis focal species f with more than 50 individual. For plot names see Supplementary Table 1, and for raw data and details of the linear regressions see Supplementary Data Table 1.
Supplementary information
Supplementary Information
Supplementary Figs. 1–5, Tables 1–3 and text.
Supplementary Data Table 1
The table contains the different summary functions characterizing the spatial patterns of the 289 focal species and raw data for Figs. 2–4 and Extended Data Figs. 2–4 and 8.
Supplementary Software
Source code of the simulation model written in Delphi (Pascal) that contains the procedures to repeat the results shown in Extended Data Figs. 5–7 and Supplementary Figs. 1–5 and to estimate the summary functions of spatial patterns. Rename the file to ‘NeutralModel.pas’ and use it as main unit. There is no graphical output.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wiegand, T., Wang, X., Anderson-Teixeira, K.J. et al. Consequences of spatial patterns for coexistence in species-rich plant communities. Nat Ecol Evol 5, 965–973 (2021). https://doi.org/10.1038/s41559-021-01440-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41559-021-01440-0
This article is cited by
-
A density functional theory for ecology across scales
Nature Communications (2023)
-
Transitions and its indicators in mutualistic meta-networks: effects of network topology, size of metacommunities and species dispersal
Evolutionary Ecology (2023)
-
Spatial point-pattern analysis as a powerful tool in identifying pattern-process relationships in plant ecology: an updated review
Ecological Processes (2021)
