
Abstract
Current flood risk mapping, relying on historical observations, fails to account for increasing threat under climate change. Incorporating recent developments in inundation modelling, here we show a 26.4% (24.1–29.1%) increase in US flood risk by 2050 due to climate change alone under RCP4.5. Our national depiction of comprehensive and high-resolution flood risk estimates in the United States indicates current average annual losses of US$32.1 billion (US$30.5–33.8 billion) in 2020’s climate, which are borne disproportionately by poorer communities with a proportionally larger White population. The future increase in risk will disproportionately impact Black communities, while remaining concentrated on the Atlantic and Gulf coasts. Furthermore, projected population change (SSP2) could cause flood risk increases that outweigh the impact of climate change fourfold. These results make clear the need for adaptation to flood and emergent climate risks in the United States, with mitigation required to prevent the acceleration of these risks.
Similar content being viewed by others

Main
The present means by which flood risk is managed globally is predicated on the assumption that history is a good predictor of the future. Be it enforcing regulations within flood zones defined using historical water-level records, modelling the cost–benefit ratio of mitigatory actions on the basis of historical flood probabilities, or not considering future risk when permitting new development, ubiquitous flood risk management tools fail to recognize that the nature of floods is changing.
Simple physical reasoning, complex physical modelling and the recent observational record all suggest that a warming climate is intensifying the hydrological cycle, making extreme precipitation—and thus potentially inland flooding—more severe1,2,3,4. Equally, these sources agree that rising temperatures, leading to oceanic thermal expansion and ice mass loss, induce a rise in global sea levels5,6. The resultant coastal flooding may be further exacerbated by the low atmospheric pressure and high winds of storms, which themselves may intensify in the future7.
Flood hazard models simulate the physical characteristics of the inundation response to such flood drivers to identify potential flood risks. Typical models used for regulatory or commercial applications use historical observations (such as rainfall, river flows or coastal water levels) as their driving input. Not only does the characterization of these historical models as ‘present-day’ gradually become more indefensible over time, they are also instantly outdated if they fail to account for any of the ~1 °C temperature rise already experienced during the industrial era, particularly in recent decades8. Flood risk management requires long-term planning. It may be unwise to permit presently low-risk developments in areas where climatic changes in the coming decades may further heighten the flood risk. Investors and mortgage lenders also need to understand an asset’s flood risk through the life of a loan or investment, possibly decades into the future. There is thus a latent need for flood risk assessments in common practice to account for existing and projected climatic non-stationarities.
Academic efforts to model flooding under climate change are in their infancy and so are rarely used for commercial or regulatory applications. Existing models can be broadly characterized as: (1) having spatial resolutions too crude to estimate property-level flood risk9,10; (2) unrealistically modelling inundation with simplified volume spreading and storage algorithms11,12,13; (3) lacking crucial local flood adaptation information14,15; (4) directly employing precipitation inputs from general circulation models, which are too coarse to represent extreme rainfall or resolve tropical cyclones16,17; (5) focusing on single flood drivers in isolation (for example, riverine10, sea level rise13 or storm surge7); and (6) having relatively limited evidence to support an understanding of the fidelity of their model output18,19,20.
Local-scale studies commonly ameliorate the above concerns relating to modelling accuracy. Flood mapping carried out by the US Federal Emergency Management Agency (FEMA) is often based on high-precision terrain data, fully surveyed river channels, local gauge information and a full appraisal of local protection measures. While this represents the current gold-standard approach for understanding flood hazard locally, the resources and labour required to replicate these methods at a continental scale are formidable. Consequently, since the start of a national flood mapping programme in 1967, only one-third of US rivers have been modelled by FEMA, and only one-quarter of these models have been updated in the past five years21. Furthermore, FEMA models are not mandated to account for climate change, and they simulate a limited number of flood frequencies, prohibiting a calculation of annualized flood losses. Thus, although policy requirements in the US Water Resources Council’s Principles and Guidelines of 1983 have illustrated the need to consider the future condition in flood risk management for the past four decades22, the state of the practice has not provided a consistent application of this on a national scale.
The limitations of existing flood models in the United States have recently been addressed, fusing the accuracy of local studies with the spatial continuity of large-scale models23. The hydrodynamic flood model, with 3 m spatial resolution, accounts for all major flood drivers and is built with a well-documented flood protection database. The present and future impact of sea level rise, tropical cyclones and changing weather patterns are all explicitly represented. Crucially, the model is benchmarked against high-quality local flood maps, flood claims information and observations of real flood events23,24. These validation exercises have determined the skill of the US-wide flood model to be approaching that of local studies and historical observations (80–90% flood extent similarity), while providing a consistent and comprehensive picture of flood hazard spatially. Here we extend this prior analysis of US flood hazard to quantify present and future US flood risk—the financial and human implications of the physical phenomenon—with wider scope, scale and fidelity than existing research.
This work seeks to deepen the understanding of US flood risk in the following ways: (1) estimate the national average annual flood loss and its geographic spread, (2) robustly quantify the uncertainty in these estimates, (3) project changes in risk due to climate and demographic change, and (4) uncover the social justice implications of who bears present and future risk. Risk assessment requires a quantification of the hazard (local flood intensities and frequencies), the exposure (the locations and characteristics of buildings, people and businesses) and vulnerability (the extent to which hazard intensity impacts exposed entities). For the latter two constituents of risk, we employ detailed information from the US government. We use the National Structure Inventory (NSI), a database of building locations and characteristics for residential and non-residential structures, for the representation of exposure. Residential depth–damage functions25 and non-residential functions from the US Army Corps of Engineers (USACE) are used to describe the vulnerability of these buildings to flooding. Combining these three components (hazard, exposure and vulnerability) yields a step change in the understanding of US flood risk by providing a national-scale flood risk assessment using property-level residential and non-residential asset data alongside spatially complete hazard maps of multiple frequencies. Uncertainty in hazard, exposure and vulnerability is considered—unprecedented for a model of this scale and resolution—to produce an ensemble of US average annual flood losses (see Methods for further details). Estimates of these annualized flood losses are compared with those recorded historically, and while we do not expect to replicate these precisely owing to uncertainties in those observations and their questionable relevance to present conditions (in terms of both hazard frequency and exposure availability), we use the comparison to demonstrate that the risk model provides sensible quantifications at the US scale (Supplementary Section 2). As such, this paper provides (1) a methodological framework for comprehensive, high-resolution and forward-facing flood risk estimation, with an innovative approach to characterizing large-scale uncertainties, and (2) empirical insights into US flood risk and its heterogeneity across time, space and demography.
This analysis reveals that annualized US flood losses are currently US$32.1 billion on average (US$30.5–33.8 billion; all specified ranges have a 95% confidence interval) and are projected to rise to US$40.6 billion (US$37.8–42.7 billion) by 2050 under the RCP4.5 scenario. This is a 26.4% (24.1–29.1%) increase across a typical 30-year mortgage term commencing today, a near-term impact that is essentially locked in climatically—that is, these projections hold even if dramatic decarbonization is undertaken immediately.
Figure 1a(i) shows the median distribution of average annual loss (AAL) by US county. Intuitive hotspots are found in highly populated counties along both coasts, as well as across the Northeast and through Appalachia. Controlling for exposure (that is, the total value of what could be damaged) in Fig. 1b(i), hotspots emerge in coastal Louisiana, Appalachia, the inland Northeast, and rural counties of the Pacific Northwest and Northern California. While many of these counties do not have high absolute annual losses, they are proportionally high-risk with median AALs greater than 0.25% of exposure (with losses expressed as a proportion of the total value). Climatic changes alone cause dramatic increases in risk along the East Coast in counties that are already high-risk (Fig. 1c(i),d(i)). The intensification of hurricanes on the East Coast is particularly evident in risk changes, principally a result of greenhouse gas emissions weakening vertical wind shear in the North Atlantic and permitting hurricanes to intensify more than usual26. The impacts of these projected changes in hurricane behaviour on coastal surges are most keenly felt in Virginia, the Carolinas and the west coast of Florida, while the contribution of sea level rise to future coastal floods dominates the remaining stretches of the Atlantic and Gulf coasts23. Intensifying rainfall, both hurricane and non-hurricane, is also expected to drive up risk in inland counties of Florida and the Northeast. Climate risk hotspots are further found in some already-risky western counties in California, Oregon and Washington. Conspicuous by their absence are risk hotspots along the Mississippi–Missouri, perhaps due to lower asset values and the dominant land use being agricultural. Furthermore, climate change impacts on large river systems are highly uncertain, while clearer positive signals emerge for short-duration rainfall and sea level rise.

a, Absolute AAL in 2020. b, Relative AAL in 2020. c, Relative AAL increase by 2050. d, Absolute AAL increase by 2050. In each panel, (i) represents the median county-level statistic, while (ii) and (iii) illustrate the bounds of the 95% confidence interval.
These spatial patterns seem robust to model uncertainty, as demonstrated by the 95% confidence interval maps in Fig. 1 (subparts (ii) and (iii) in all panels). While the uncertainty may seem large in Fig. 1a,b, it is important to note that these maps illustrate within-county model uncertainty, ignoring between-county uncertainty correlations. At more granular scales, where proximal locations may have correlated uncertainty under the assumptions in this analysis (Methods), the 95% confidence interval may be quite large. At larger spatial scales, uncertainties are less likely to be correlated, meaning that location-level extremes cancel each other out and confidence increases. Hence, subparts (ii) and (iii) in all panels of Fig. 1 should be viewed with caution, since these maps do not represent plausible national-level losses (that is, every county experiencing its 97.5th AAL quantile) but illustrate county-level uncertainty only. We explore the sensitivity of our results to uncertainty correlation assumptions in Supplementary Section 1.
The FEMA Special Flood Hazard Area (SFHA), determined by the nationwide patchwork of local-scale FEMA flood models, is the de facto flood risk zone in the United States27. A number of regulations apply to development within the SFHA, as well as the mandatory purchase of flood insurance for those with a federally backed mortgage. Though it was not designed to be a risk communication product, it has become synonymous with that in the public view. Properties located outside the SFHA are commonly misconceived to be risk free, when in reality there may simply not be an up-to-date local flood map, they may be at risk of unmapped pluvial (or, indeed, fluvial) floods or they may be outside of the 100-year flood zone where lower-frequency floods can still occur. Additionally, for those located in the 100-year floodplain (at least a 1% chance of inundation each year), their recurrence of flooding can be anywhere from every other year to once every hundred years on average, and these varying probabilities have dramatically different outcomes in the evaluation of risk. The frequency of floods outside the SFHA and its discontinuous spatial coverage have been well documented elsewhere21,28,29, but here we demonstrate that 41.0% (38.8–42.6%) of the nation’s flood risk is located within the SFHA. Properties in the SFHA are currently subject to AALs of US$13.2 billion (US$12.1–14.1 billion), while AALs outside this area total US$19.1 billion (US$17.9–20.1 billion). Proportional risk is much higher in the SFHA, with an AAL equal to 0.465% (0.425–0.500%) of exposure, 14.7 (14.3–14.9) times the relative risk of non-SFHA properties (0.032% (0.030–0.033%)). This is illustrative of the large number of low-risk or no-risk buildings outside the SFHA, yet it remains that the majority of US flood risk is unmapped by FEMA. Climate-induced risk changes in the SFHA are expected to be more intense than elsewhere. Within-SFHA AALs are projected to rise by 33.8% (30.2–37.4%) to US$17.6 billion (US$15.8–18.9 billion) by 2050, while the outside-SFHA increase is projected to be 21.2% (19.2–24.0%) to US$23.1 billion (US$21.8–24.5 billion).
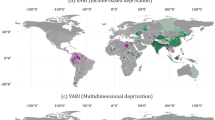
Flood risk is not borne equally by all. We use census-tract-level data from the 2019 American Community Survey (ACS) to assess the demographic characteristics (focusing on race and poverty) of flood risk across the United States. Normalizing for exposure (to understand risk as a fraction of the total that could be damaged), we consistently see that present-day flood risk is concentrated in both the most White and the most impoverished communities across the nation (Fig. 2a). When grouped into ordinal quintiles (bins containing 20% of US census tracts), the data indicate a persistent increase in relative AAL with increasing poverty rate and the proportion of the population that is White. The flood risk in the top 20% proportionally White and impoverished census tracts (>90% White, >22% in poverty) is roughly ten times higher than the risk in tracts that fall into the least White and the least impoverished quintiles (<30% White, <5% in poverty) (Fig. 3a,b). The relative risk of the opposite group—census tracts with the smallest White population proportions and lowest poverty rates—is markedly lower, concentrated in urban clusters on both coasts of the United States.

a, AAL as a proportion of exposure summarized for census tract quintile bins of White population proportion, further broken down by quintile of population proportion in poverty. b, AAL increase from 2020 to 2050 for census tract quintile bins of Black population proportion. The error bars and grey shading represent the 95% confidence intervals.

a, Median relative flood risk of census tracts that fall into the top 20% White population proportion and top 20% poverty rate. b, Median relative flood risk of census tracts that fall into the bottom 20% White population proportion and bottom 20% poverty rate. c, Median relative flood risk increase to 2050 of census tracts in the top 20% Black population proportion. d, Median relative flood risk increase to 2050 of census tracts in the bottom 20% Black population proportion. In each panel, (i)–(iv) highlight selected areas.
Meanwhile, expected changes in flood risk up to 2050 show a largely different trend in demography compared with who bears present-day risk. The sensitivity of flood risk to climate change is concentrated in communities with higher Black population proportions across the United States (Fig. 2b). The top 20% proportionally Black census tracts (>20% Black) are expected to see flood risk increase at double the rate of the bottom 20% (<1% Black) of Black census tracts. Areas with high Black population proportions are clearly concentrated across the Deep South (Fig. 3c), in the very locations where climate change is expected to intensify flood risk (Fig. 2c). Urban and rural areas alike from Texas through Florida to Virginia contain predominantly Black communities projected to see at least a 20% increase in flood risk over the next 30 years. In contrast, most census tracts with the lowest Black population proportions see very little increase in climate-induced flood risk (Fig. 3d). Present and future trends in the flood risk of other demographic groups are less clear and consistent and are shown in Supplementary Figs. 3–11.
Climate will not be the only thing changing over the next 30 years. The US population is expected to continue to grow, and so, accordingly, is development. We use gridded maps of population from the US Environmental Protection Agency (EPA) to calculate the current population exposed to floods, and the EPA’s gridded projections of 2050 populations under the SSP2 scenario to analyse the relative contributions of climate change and population growth to future US flood risk (Fig. 4a). The average annual exposure (AAE) of the current US population to flooding is 3.63 million (1.18%). Climate change is projected to increase the AAE of present populations to 4.31 million (1.41%), an increase of 18.6%. Meanwhile, population growth alone in a static climate (that is, no future changes in flood hazard) would result in a 72.6% increase to an AAE of 6.27 million by 2050. This corresponds to 1.60% of 2050’s projected population, indicating that future development is projected to disproportionately intensify in hazardous areas (given that the present-day proportion is 1.18%). Without policies to direct new development into safer areas, the contribution of population growth to future US flood risk exceeds that of climatic changes. Population growth alone accounts for 74.7% of the increase in AAE to 2050, while climate change represents 19.1% of the change. The remaining 6.2% (yellow in Fig. 4a) of 2050’s projected AAE represents the intersection of both climate change and population growth. Conceptually, this is due to floods intensifying in places where populations are also increasing—and so the compound intensification of both hazard and exposure is required to capture the increased total risk. The AAE of the US population to floods in 2050 is projected to be 7.16 million (1.83%), a 97.3% increase from the present day.

a, Nationwide AAE of the present and future broken down into its constituent drivers. CC, climate change; PG, population growth. b, Absolute AAE in 2020. c, Relative AAE in 2020. d, AAE increase from 2020 to 2050 from climate change alone. e, AAE increase from 2020 to 2050 from population growth alone. f, AAE increase from 2020 to 2050 from only the compound effects of climate change and population growth. g, AAE increase from 2020 to 2050.
Concentrations of population AAE generally fall within populous US states (Fig. 4b). Populations of 547,000, 345,000, 247,000 and 247,000 in Florida, California, New York and Texas, respectively, are expected to be impacted by flooding every year, on average, under current conditions. Proportionally, West Virginia, Vermont, Florida, and Louisiana have the highest AAEs: they can expect over 2% of their populations to be impacted by flooding every year currently (Fig. 4c). AAE increases due to climate change are generally found across the East Coast, with existing Texas and Florida residents seeing a roughly 50% increase in flood exposure by 2050 (Fig. 4d). Interestingly, AAE increases due to population growth occur in many places where increases due to climate change are minimal (Fig. 4e). The intensification of development on existing floodplains is relatively severe in the currently sparsely populated central Prairie States and the Deep South. The consequence is a more widespread increase in flood risk to 2050 than Fig. 1 suggests: states with little climate risk may still see large increases in flood risk unless future development patterns are managed appropriately (Fig. 4g). Areas where the compound effect of climate change and population growth is substantial are scattered across the nation. Over 10% of the risk increase to 2050 is compound in West Virginia, Louisiana, Idaho and Mississippi (Fig. 4f).
With future development patterns projected to be four times more impactful than climate change in elevating national flood losses, the importance of improved flood risk management in the United States is clear. More aggressive local land use controls restricting new developments in the highest-risk areas, coupled with stronger building codes, could help lower the growth in flood losses that is currently projected to accompany expanding populations. Such regulations imposed on future development will need to be accompanied by investments in both relocation and retrofits for existing construction in areas where flood risk is high and/or growing. The federal government has several programmes that currently fund such efforts, although not at levels that will be required to fully adapt to increasing risk30. Furthermore, several of these programmes have been criticized for privileging more affluent and White communities31,32. Equity-centred reform in light of climate change is needed for US disaster policy—a call given greater emphasis by the demographic make-up of present and future bearers of US flood risk shown here.
When considering flood hazard projections derived from only the central 50% of climate model ensemble members (that is, ignoring outlier simulations), the variability between models representing the present day is over double the magnitude of the change signal to 205023. In simpler terms, increased flooding due to climate change is within the error of present-day climate models. Our analysis here further quantifies flood risk model uncertainty. While this is necessarily somewhat crude, owing to computation and knowledge constraints, we demonstrate that national-level trends and conclusions are robust to conservative estimates of model uncertainty. However, at more granular spatial scales, there are effectively fewer distal uncorrelated locations to cancel out local errors. The total dependence method illustrates the scale of location-level uncertainties (since all location errors are completely correlated) (Extended Data Fig. 1). These results demonstrate that it is difficult to quantify present or future flood risk for individual locations with confidence, while aggregate conclusions are probably robust to these uncertainties.
Furthermore, these projections assume that no further adaptation to present and future flood risks takes place. Existing protection measures maintain their integrity up to their original design standard, but no further defences are projected to account for increasing flood hazard or the proliferation of flood-exposed developments. While it is fair to assume that some level of adaptation will be put in place to protect new development, the ability to understand future risk as development takes place is essential to reducing risk in future environmental conditions.
The threats that floods presently pose—both direct and indirect, tangible and intangible—are evidence enough that there is a dearth of flood resilience in the United States, regardless of what the future holds in terms of climate and demographic change. Layered on top of this already critical problem is the large increase in risk that we project a warming world to portend. These impacts are so near-term that climate mitigation (that is, decarbonization) is futile, meaning we can only adapt to this increasing risk in areas currently developed. We thus have to adapt to both the now and the future. Mitigation will largely determine how much worse flood hazard will get in the latter half of this century. The lack of quality publicly available flood risk information has meant that risky developments have proliferated across the United States; planning and investment decisions by the public, governments and corporations rarely consider flood risk adequately33. The current state of the science means that there is no longer an excuse for this to continue. It is critical that information on changing risks be made widely available and transparent to fully inform housing and mortgage markets to guide capital away from the riskiest areas. The findings of this paper provide important insights for communities and the federal government in designing future flood risk management interventions and in allocating federal dollars more effectively. Models such as these can and should inform zoning regulations to prevent anticipated future developments from leading largely inevitable hazard changes to unnecessarily inflate risk. Adaptation policies can be targeted towards locations with disproportionate risk, or where risk is expected to increase, using these data.
Methods
Hazard model
The physical flood data used to calculate risk in this paper were published in Bates et al.23, itself an evolution of the first spatially continuous US flood model presented by Wing et al.20 and the global-scale modelling methods of Sampson et al.34. In this section, the main methods and model validation studies are outlined. For more information, the reader is referred to Bates et al.23.
The flood inundation model, at its core, solves the local inertial formulation of the shallow water equations in two dimensions (based on LISFLOOD-FP)35,36 over a regularly spaced 1″ (~20–30 m in the United States) grid. This formulation has been shown to produce answers indistinguishable from the full solution of the shallow water equations for typical flood inundation problems (that is, subcritical flows), given typical input data errors35,37. Crucially, it provides these answers much faster than full solutions or other common simplifications of the shallow water equations (for example, the diffusive wave)38, owing to its linear scaling of stable time step with grid size35. Alongside vectorization and parallelization of code39, accurate computational hydraulics can thus be deployed at high resolutions over large spatial domains with practicable runtimes. The set of return period hazard maps at 1″ resolution used in this analysis took about two months on a ~2,000-core compute cluster.
The 1″ grid is populated with elevation values principally obtained from the US Geological Survey (USGS) National Elevation Dataset. This dataset consists of a plurality of high-accuracy LiDAR data, covering 39% of the contiguous US land area and two-thirds of its population. The National Elevation Dataset is further infilled by subnational LiDAR terrain data where available. To take full advantage of 1/9″ (~2–3 m in the United States) resolution data where it is available—rather than the degraded 1″ variant on which the hydraulic model was run—a downscaling algorithm is implemented. Simulating hydraulics explicitly at 1/9″ resolution would require an intractable >1,000 times greater compute time. Instead, Bates et al. downscale the simulated 1″ water surface elevations onto a 1/9″ grid of ground surface elevations, thus improving property-level model predictions40.
River channels are represented in one dimension, decoupled from the two-dimensional grid to enable river channels of any size (including <1″ width) to be modelled36. A flow accumulation grid was forged using the composite elevation data alongside the USGS National Hydrography Dataset, ensuring correct alignment of one-dimensional channels with their two-dimensional valleys. River bathymetry (particularly bed elevation) is mostly unobserved over large spatial domains, but since channels convey the bulk of flood flows, the approximation of their bathymetric properties is essential. Channels are thus parameterized under the assumption that they can convey a certain return period discharge (generally the two-year flow, rising to five-year in arid regions), with their bed elevations thus estimated using an inverted gradually varied flow solver (which solves for water height rather than discharge)41.
Return period discharges for channel bed estimation, and for the extreme flows to simulate flooding, are computed using a regional flood frequency analysis (RFFA) based on the methods of Smith et al.42 and further extended in Bates et al.23. This involved pooling almost 7,000 USGS river gauges into proximal and hydrologically similar groups to compute an index flow for every cell on the flow accumulation grid (with an upstream area >50 km2). Since flow records are generally too short to understand extreme flow behaviour, the RFFA substitutes time for space by again pooling hydrologically similar river gauges to derive growth curves. These curves define the proportional change in a given index flow to get a given return period flow. Bates et al. report a 6% and 29% error for 10-year and 100-year flows, respectively, probably within observational error for gauge-based extremes43. In coupling channel conveyance to the RFFA, errors in flow estimation are implicitly dampened to some extent. If the RFFA overestimates flows at a given location, the channel will be larger to account for this, and vice versa.
Pluvial modelling is executed to simulate the flashier flood response on smaller headwater streams (<50 km2 drainage area) and due to surface water flooding directly through a rain-on-grid approach. The boundary conditions take the form of intensity–duration–frequency estimations from National Oceanographic and Atmospheric Administration (NOAA) Atlas 14. The maximum flood depth from 1 h, 6 h and 12 h pluvial simulations form the hazard map for each return period. River channels are explicitly represented in the pluvial simulations, allowing channels to convey water and drain floodplains during simulated extreme precipitation events.
To account for climate change, both up to 2020 and to 2050, we adopt a change factor approach. A large synthetic catalogue of hurricane events based on the methods of Emanuel et al.44 and Feldmann et al.45 was simulated using seven downscaled general circulation model scenarios to yield 55,000 years of synthetic hurricanes for each time horizon. We then extracted 55,000 annual maximum daily rainfall accumulations. We used 21 general circulation model ensemble members from National Aeronautics and Space Administration Earth Exchange Global Daily Downscaled Projections (NEX-GDDP) to create an equivalent 55,000 years of rainfall annual maxima via sampling from fitted generalized extreme value distributions. For each synthetic year, the maximum hurricane or NEX-GDDP annual maximum was retained. Rainfall changes with respect to a historical baseline simulation period (1980–2000) were computed for the 2020 and 2050 climate states, on the basis of RCP4.5. These changes directly perturb the historical pluvial intensity–duration–frequency curves outlined above.
For the fluvial model, these rainfall time series were routed through calibrated Hydrologiska Byråns Vattenbalansavdelning (HBV) hydrological models for ~700 US river catchments to generate 55,000 years of synthetic streamflows for historical, 2020 and 2050 climate states. Change factors with respect to the historical run were again computed, and the regionalization procedure outlined above (for the RFFA) iterated change factors for every US river. Changes were then applied directly to each RFFA-derived return period flow.
For coastal modelling, the historical water levels from 68 detrended NOAA tide gauges (with hurricane events stripped out) were extracted and adjusted to 2020 mean sea levels on the basis of Kopp et al.5. Then, 55,000 years of synthetic non-hurricane extreme water levels were generated at each site, and the Global Tide and Surge Reanalysis was used to interpolate between them46. The pressure and wind fields from the above hurricane event sets were used to drive the GeoCLAW coastal flood model to produce 55,000 years of synthetic hurricane extreme water levels47. At coasts, flood inundation occurs due to the joint probabilities that riverine and oceanic flooding co-occur. Using the stochastic model of Quinn et al.48, we link the return periods of univariate hurricane and non-hurricane fluvial and coastal floods to the return period of the synthetic multivariate event. Flood inundation maps at coasts thus represent the compound impact of fluvial and coastal floods at each return period.
Flood defences are represented in a variety of ways, wrought from a painstaking scouring of national and subnational databases of flood adaptations across the United States. Levees from the USACE National Levee Database, as well as other projects identified locally, were incorporated explicitly into the model. The function of dams from the USACE National Inventory of Dams was used to adjust the bankfull return periods of channels. Other grey, green and coastal adaptations were also incorporated. See Bates et al.23 for further details.
Bates et al. carried out a number of model validation exercises for the predicted physical hazard. They compared the model to high-quality FEMA flood maps, where they exist, finding 78% similarity between these local-scale engineering models and the large-scale flood model, rising to 82% in coastal regions. Given typical errors associated with flood modelling at any scale, Bates et al. refer to this degree of similarity as within error. This test of the modelled 100-year flood was repeated for the 100-year flood maps generated by the Iowa Flood Center, finding 87% similarity to these higher-accuracy models. For the 5-year flood—more difficult to model owing to its modest size and thus sensitivity to channel parameterization and microtopography—the similarity between Bates et al. and the Iowa Flood Center was 69%. Wing et al.24 furthered the validation of the Bates et al. model by simulating historical flood events and comparing them to observations. They found roughly 87% similarity between modelled inundation and observations, a mean bias of 0.17 m, and a mean absolute error of 0.96 m compared with observed flood depths. These studies thus demonstrate the fitness for purpose of the Bates et al. hazard model in a national-scale risk calculation framework.
Flood inundation model uncertainty is typically explored via Monte Carlo simulations, where uncertain parameters are systematically varied, the model is run multiple times, and an ensemble of depth predictions are considered. Given that all available compute resource is devoted to deterministic predictions of the highest possible accuracy (the alternative is a severely degraded model ensemble), it is unfeasible to consider uncertainty in a model of this scale and resolution using Monte Carlo analysis. Instead, we use past validation studies to inform a distribution of flood depths at every building location. Past studies have indicated that the hazard model is unbiased (it overpredicts a given benchmark as much as it underpredicts)23,24, so we assume that the simulated flood depth at a given building represents the central estimate. A normal distribution of flood depths with a standard deviation of 1.0 m, based on the results of Wing et al.24, is then assumed for each building. Locations that are modelled as dry are given depth distributions on the basis of their height above the nearest flood water surface. For example, a location that is 0.6 m higher than a proximal water surface has a ~27% chance of experiencing a positive water depth: its normal depth distribution has a standard deviation of 1.0 m, centred on −0.6 m.
Building data
The National Structure Inventory (NSI) defined the exposure in this assessment. The NSI is a database developed by the USACE to support their dam and levee safety programmes, as well as real-time consequence assessments and planning functions for risk mitigation. The NSI is designed to represent every structure in the United States as a point, as accurately placed and attributed as possible. The product is described in more detail in USACE documentation49. This study used the updated NSI v.2, which is restricted by a license; therefore, no results are shown below the census block level. This version of the NSI was developed in 2019 by coordinating many datasets such as the Microsoft building footprints layer, the CoreLogic parcel database, the ESRI business layer, census data and many others to derive a best-of-breed inventory fit for evaluating natural disasters. The inventory is described by occupancy types, which are linked to standard depth–damage relationships to understand their vulnerability to flooding. Valuations are based on a variety of sources and are designed to represent depreciated replacement value.
One of the more influential variables regarding building attribution for flood risk modelling is the elevation of the first occupied floor with respect to the ground surface. This modelling effort leveraged stratified surveys conducted by USACE economists to describe the range of uncertainty in foundation height given foundation type. This project overrode the base NSI foundation height estimate using the distribution of foundation height estimates from the surveyed data, specifying foundation height as triangular distributions. The distributions were sampled randomly during the Monte Carlo analysis.
Population data
The US Environmental Protection Agency (EPA) EnviroAtlas programme produced a 30-m-resolution dasymetric map of contiguous US populations, which we intersected with the multifrequency hazard data. Here we leverage the 1″ model output (prior to downscaling) deterministically to align with the population data, thus yielding a median estimate of average annual flood exposure. The EPA data were generated via reallocating 2010 US census block populations to 30 m cells on the basis of maps of land cover and slope. The projections of future populations are drawn directly from the EPA Integrated Climate and Land-Use Scenarios projections50. This involves the use of a 90-m-resolution spatial allocation model to assign county-level population change estimates (from a demographic model) to housing units. Fertility, mortality and migration are the key variables of the demographic model, used to project county-level cohorts split by gender, ethnicity, and age. Datasets on population, housing units, non-residential land use, groundwater availability, and transport infrastructure form inputs to the spatial allocation model, which requires parameters such as household size, land-use demand, and travel times to downscale county-level populations to the 90 m grid. Given the use of the RCP4.5 climate scenario, we employ the complementary SSP2 projection of demographic change. This represents a medium-growth scenario, following US Census Bureau projections of the contiguous US growing to almost 400 million people by 2050. Models of socio-economic change are commonly laden with assumptions—for instance, the continuation of historical trends in migration patterns, land-use change, and demand for transport and amenities. The data used thus represent a single plausible population projection, out of many possibilities, based on historically derived model parameters. As such, these projections of change are highly uncertain, not least since they are predicated on the continuation of historical development patterns and how growing populations consume and interact with impervious surfaces. However, conclusions drawn with these data are aggregated to the state and national levels, where substantial local uncertainties will, to some extent, cancel each other out. The results demonstrate that plausible patterns of future development are the overwhelming driver of increased flood risk, which, in spite of projection uncertainty, is a conclusion that cannot be ignored. For more information, the reader is referred to the EPA report50.
Vulnerability functions
The vulnerability functions used for this report were sourced from a curated database developed to support a variety of the USACE Hydrologic Engineering Center’s flood risk modelling activities. The residential damage functions are based on those generated by Wing et al.25. They use damage observations from over two million flood claims from the National Flood Insurance Program (NFIP) to derive probabilistic depth–damage functions for residential buildings, with modifiers including occupancy type, number of storeys and presence of a basement. Since the NFIP covers only residential property, non-residential functions are selected from the HAZUS database from previous USACE projects, largely on the basis of expert elicitation51. These functions, developed by the Galveston District of the USACE, probabilistically represent damage to a variety of non-residential occupancies, including commercial, industrial, agricultural and public buildings.
For this analysis, the damage functions were leveraged probabilistically to account for the variable damage response to certain flood depths. The curves were then input into an open-source consequence engine developed for this project called go-fathom52. The go-fathom project referenced an open-source consequence engine developed by the USACE called go-consequences53, and overrode base behaviours regarding foundation heights and damage functions as described here. Damages were computed for the 5-, 20-, 100-, 250- and 500-year return periods, which were then integrated using trapezoidal Riemann sums to compute an AAL for each location. Two important assumptions were adopted. First, no damages were accrued between the most frequent damage and the annual flood (100% annual exceedance probability) when integrating. If damages did not occur until the 100-year flood, no damages would be assumed until that frequency. The second is that for the space between the 500-year and the ∞-year (0% annual exceedance probability) frequency damage, the value of the 500-year damage was used as the maximum allowable damage (that is, no extrapolation). Both of these assumptions tend to reduce the estimated damages, so our estimates should be conservative. These are both standard assumptions in flood risk estimation but are important to state, as alternatives used in their place tend to dramatically overstate risk.
Ensemble loss calculation
Uncertain hazard, exposure, and vulnerability distributions are sampled to produce an ensemble of flood loss estimates. To span the variable of the greatest contribution to the uncertainty in the output, a simple stratification approach was used for the uncertainty in flood depth. The other parameters were sampled randomly to represent that the parameters are uncorrelated. The process is described as follows: 100 equally spaced flood depth quantile samples at a given location are combined with 100 randomly sampled foundation height estimates, which, in turn, are randomly combined with 100 randomly generated vulnerability curve samples. The sampling quantiles are held constant for each return period of a given sample, yielding 100 estimates of AAL for every building in the United States.
Subsequent aggregations of uncertain location-level flood losses are sensitive to assumptions relating to their correlation in space. We assume that loss uncertainty is locally spatially dependent within USGS HUC10 catchment zones (Supplementary Fig. 2). For example, if the hazard model overpredicts flood depth at a given location, it probably does so for neighbouring locations too. However, this assumption is weakly justified, so we illustrate national flood losses under assumptions of complete nationwide dependence and total location-level independence in the Supplementary Information. Central estimates of US flood risk are insensitive to uncertainty correlation assumptions, while the range of risk estimates is highly sensitive to them.
Both the magnitude and the correlation of flood risk modelling uncertainty warrant further attention. However, this study approaches the ceiling for its representation in a model of such fidelity and spatial scale, given current data and compute constraints.
Census tract data
Demographic data split by census tract were obtained from the 2019 ACS five-year roll-up. The proportion of census tract populations that fell into a specific socio-economic grouping was computed by dividing the counts of each group by the total census tract population. The groups examined were (1) below 100% of the poverty level (B06012_002); (2) not Hispanic or Latino, White alone (B03002_003); (3) not Hispanic or Latino, Black or African American alone (B03002_004); (4) Hispanic or Latino (B03002_012); (5) not Hispanic or Latino, American Indian and Alaska Native alone (B03002_006); and (6) other racial identities that do not fall into the groups mentioned here (2–5), which were combined into an ‘other’ group, calculated from the remaining census tract population yet to be allocated to a group (B01001_001).
ACS data are known to produce inaccurate estimates of socio-economic variables for some census tracts, with estimate quality linked to demography and geography54,55. We mitigated these localized uncertainties in a number of ways. First, five-year estimates were used to favour precision over currency. However, the demographic data used in this analysis are unlikely to deviate substantially across these timescales from one-year or three-year estimates. Second, we focus on the proportional demographic constitution of census tracts, de-emphasizing potentially inaccurate absolute counts. Third, and most important, the granularity of the data was reduced (in line with the recommendations of Folch et al.55) by pooling census tracts into ordinal quintile groups of a given attribute. With conclusions drawn at the scale of five nationwide groups rather than individual census tracts, the impact of local uncertainties is minimized. Overall, the ACS data employed are fit for the purpose to which they were put, in line with US Census Bureau guidelines56.
Data availability
The flood hazard data used in this analysis are available from Bates et al.23, with details on constituent data availability contained therein. The building data used in this analysis are currently restricted from public use. Access details are available at https://www.hec.usace.army.mil/confluence/nsidocs/. The vulnerability functions (and the code for the computation of losses) are available at https://github.com/USACE/go-consequences. EPA EnviroAtlas and Integrated Climate and Land-Use Scenarios population data are available at https://edg.epa.gov/. The R package tidycensus (https://cran.r-project.org/package=tidycensus) was used to obtain data from the ACS.
Code availability
The loss calculations were made on the basis of the go-consequences codebase, available at https://github.com/USACE/go-consequences and published under the MIT license. The variant of the codebase used to execute this analysis is available at https://github.com/HenryGeorgist/go-fathom. A freely available version of the underlying computational hydraulic engine, LISFLOOD-FP v.8.0, is available at https://zenodo.org/record/4073011#.YFCo8Wj7SUl.
References
Trenberth, K. E., Dai, A., Rasmussen, R. M. & Parsons, D. B. The changing character of precipitation. Bull. Am. Meteorol. Soc. 84, 1205–1218 (2003).
Kundzewicz, Z. W. et al. Flood risk and climate change: global and regional perspectives. Hydrol. Sci. J. 59, 1–28 (2014).
Markonis, Y., Papalexiou, S. M., Martinkova, M. & Hanel, M. Assessment of water cycle intensification over land using a multisource global gridded precipitation dataset. J. Geophys. Res. Atmos. 124, 11175–11187 (2019).
Gudmundsson, L. et al. Globally observed trends in mean and extreme river flow attributed to climate change. Science 371, 1159–1162 (2021).
Kopp, R. E. et al. Probabilistic 21st and 22nd century sea-level projections at a global network of tide-gauge sites. Earths Future 2, 383–406 (2014).
Oppenheimer, M. et al. in Special Report on the Ocean and Cryosphere in a Changing Climate (eds Pörtner, H.-O. et al.) Ch. 4 (IPCC, 2019).
Marsooli, R., Lin, N., Emanuel, K. & Feng, K. Climate change exacerbates hurricane flood hazards along US Atlantic and Gulf coasts in spatially varying patterns. Nat. Commun. 10, 3785 (2019).
IPCC Special Report on Global Warming of 1.5 °C (eds Masson-Delmotte, V. et al.) (WMO, 2018).
Ward, P. J. et al. Assessing flood risk at the global scale: model setup, results, and sensitivity. Environ. Res. Lett. 8, 044019 (2013).
Alfieri, L. et al. Global projections of river flood risk in a warmer world. Earths Future 5, 171–182 (2017).
Hirabayashi, Y. et al. Global flood risk under climate change. Nat. Clim. Change 3, 816–821 (2013).
Winsemius, H. C. et al. Global drivers of future river flood risk. Nat. Clim. Change 6, 381–385 (2016).
Kulp, S. A. & Strauss, B. H. New elevation data triple estimates of global vulnerability to sea-level rise and coastal flooding. Nat. Commun. 10, 4844 (2019).
Scussolini, P. et al. FLOPROS: an evolving global database of flood protection standards. Nat. Hazards Earth Syst. Sci. 16, 1049–1061 (2016).
Wing, O. E. J. et al. A new automated method for improved flood defense representation in large-scale hydraulic models. Water Resour. Res. 55, 11007–11034 (2019).
Emanuel, K. A. Downscaling CMIP5 climate models shows increased tropical cyclone activity over the 21st century. Proc. Natl Acad. Sci. USA 110, 347–368 (2013).
Kendon, E. J. et al. Heavier summer downpours with climate change revealed by weather forecast resolution model. Nat. Clim. Change 4, 570–576 (2014).
Dottori, F. et al. Development and evaluation of a framework for global flood hazard mapping. Adv. Water Resour. 94, 87–102 (2016).
Ward, P. J. et al. A global framework for future costs and benefits of river-flood protection in urban areas. Nat. Clim. Change 7, 642–646 (2017).
Wing, O. E. J. et al. Validation of a 30 m resolution flood hazard model of the conterminous United States. Water Resour. Res. 53, 7968–7986 (2017).
Flood Mapping for the Nation: A Cost Analysis for Completing and Maintaining the Nation’s NFIP Flood Map Inventory (Association of State Floodplain Managers, 2020).
Economic and Environmental Principles and Guidelines for Water and Related Land Resources Implementation Studies (US Water Resources Council, 1983).
Bates, P. D. et al. Combined modeling of US fluvial, pluvial, and coastal flood hazard under current and future climates. Water Resour. Res. 57, WR028673 (2021).
Wing, O. E. J. et al. Simulated historical flood events at the continental scale: observational validation of a large-scale hydrodynamic model. Nat. Hazards Earth Syst. Sci. 21, 559–575 (2021).
Wing, O. E. J., Pinter, N., Bates, P. D. & Kousky, C. New insights into flood vulnerability revealed from flood insurance big data. Nat. Commun. 11, 1444 (2020).
Ting, M., Kossin, J. P., Camargo, S. J. & Li, C. Past and future hurricane intensity change along the U.S. East Coast. Sci. Rep. 9, 7795 (2019).
Kousky, C. Financing flood losses: a discussion of the National Flood Insurance Program. Risk Manage. Insur. Rev. 21, 11–32 (2018).
Blessing, R. A., Sebastian, A. & Brody, S. D. Flood risk delineation in the United States: how much loss are we capturing? Nat. Hazards Rev. 18, 04017002 (2017).
Wing, O. E. J. et al. Estimates of present and future flood risk in the conterminous United States. Environ. Res. Lett. 13, 034023 (2018).
Kousky, C. & Golnaraghi, M. Flood Risk Management in the United States: Building Flood Resilience in a Changing Climate (Geneva Association, 2020).
National Advisory Council Report to the FEMA Administrator (FEMA, 2020).
Billings, S. B., Gallagher, E. & Ricketts, L. Let the Rich Be Flooded: The Distribution of Financial Aid and Distress after Hurricane Harvey (SSRN, 2019).
Pralle, S. Drawing lines: FEMA and the politics of mapping flood zones. Climatic Change 152, 227–237 (2019).
Sampson, C. C. et al. A high-resolution global flood hazard model. Water Resour. Res. 51, 7358–7381 (2015).
Bates, P. D., Horritt, M. S. & Fewtrell, T. J. A simple inertial formulation of the shallow water equations for efficient two-dimensional flood inundation modeling. J. Hydrol. 236, 54–77 (2010).
Neal, J., Schumann, G. & Bates, P. A subgrid channel model for simulating river hydraulics and floodplain inundation over large and data sparse areas. Water Resour. Res. 48, WR012514 (2012).
de Almeida, G. A. M. & Bates, P. Applicability of the local inertial approximation of the shallow water equations to flood modeling. Water Resour. Res. 49, 4833–4844 (2013).
Hunter, N. M., Horritt, M. S., Bates, P. D., Wilson, M. D. & Werner, M. G. F. An adaptive time step solution for raster-based storage cell modelling of floodplain inundation. Adv. Water Resour. 28, 975–991 (2005).
Neal, J., Dunne, T., Sampson, C., Smith, A. & Bates, P. Optimisation of the two-dimensional hydraulic model LISFLOOD-FP for CPU architecture. Environ. Model. Softw. 107, 148–157 (2018).
Schumann, G., Andreadis, K. & Bates, P. Downscaling coarse grid hydrodynamic model simulations over large domains. J. Hydrol. 508, 289–298 (2014).
Neal, J. et al. Estimating river channel bathymetry in large scale flood inundation models. Water Resour. Res. 57, e2020WR028301 (2021).
Smith, A., Sampson, C. & Bates, P. Regional flood frequency analysis at the global scale. Water Resour. Res. 51, 539–553 (2015).
McMillan, H., Krueger, T. & Freer, J. Benchmarking observational uncertainties for hydrology: rainfall, river discharge and water quality. Hydrol. Process. 26, 4078–4111 (2012).
Emanuel, K., Sundararajan, R. & Williams, J. Hurricanes and global warming: results from downscaling IPCC AR4 simulations. Bull. Am. Meteorol. Soc. 89, 347–368 (2008).
Feldmann, M., Emanuel, K., Zhu, L. & Lohmann, U. Estimation of Atlantic tropical cyclone rainfall frequency in the United States. J. Appl. Meteorol. Climatol. 58, 1853–1866 (2019).
Muis, S., Verlaan, M., Winsemius, H. C., Aerts, J. C. J. H. & Ward, P. J. A global reanalysis of storm surges and extreme sea levels. Nat. Commun. 7, 11969 (2016).
Mandli, K. T. & Dawson, C. N. Adaptive mesh refinement for storm surge. Ocean Model. 75, 36–50 (2014).
Quinn, N. et al. The spatial dependence of flood hazard and risk in the United States. Water Resour. Res. 55, 1890–1911 (2019).
NSI Technical Documentation (US Army Corps of Engineers Hydrologic Engineering Center, 2021); https://www.hec.usace.army.mil/confluence/nsidocs/nsi-technical-documentation-50495938.html
US Environmental Protection Agency Updates to the Demographic and Spatial Allocation Models to Produce Integrated Climate and Land Use Scenarios (ICLUS) Version 2 (National Center for Environmental Assessment, 2016).
Scawthorn, C. et al. HAZUS-MH flood loss estimation methodology. II. Damage and loss assessment. Nat. Hazards Rev. 7, 72–81 (2006).
Lehman, W. go-fathom: a package to leverage go-consequences with fathom data. GitHub https://github.com/HenryGeorgist/go-fathom (2021).
go-consequences: an economic consequences library written in Golang. GitHub https://github.com/usace/go-consequences (US Army Corps of Engineers, 2021).
Bazuin, J. T. & Fraser, J. C. How the ACS gets it wrong: the story of the American Community Survey and a small, inner city neighborhood. Appl. Geogr. 45, 292–302 (2013).
Folch, D. C. et al. Spatial variation in the quality of American Community Survey estimates. Demography 53, 1535–1554 (2016).
US Census Bureau Understanding and Using American Community Survey Data: What All Data Users Need to Know (US Government Publishing Office, 2020).
Acknowledgements
We thank N. B. Kalman of the University of California, Davis, for assisting with the NFIP data analysis. P.D.B. was supported by a Royal Society Wolfson Research Merit Award. The research in this paper was partly supported by UK Natural Environment Research Council grant no. NE/V017756/1 (to J.C.N.).
Author information
Authors and Affiliations
Contributions
O.E.J.W., P.D.B., C.C.S., N.Q., A.M.S. and J.C.N. conceived the project. C.C.S., N.Q. and A.M.S. developed the flood model. W.L. developed and ran the consequences engine. O.E.J.W. performed all analyses. O.E.J.W. wrote the manuscript. O.E.J.W., W.L., P.D.B., C.C.S., N.Q., A.M.S., J.C.N., J.R.P. and C.K. aided in the refinement, interpretation and discussion of the analyses.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review information
Nature Climate Change thanks Marc Bierkens, Sanjib Sharma and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data
Extended Data Fig. 1 The effect of three different uncertainty correlation methods on the distribution of U.S. AALs.
The effect of three different uncertainty correlation methods on the distribution of U.S. AALs: no correlation of uncertainty between locations (black); total correlation of uncertainty between locations within the same HUC10 unit (see Supplementary Fig. 2) and no correlation of uncertainty between HUC10 units (aquamarine); total correlation of uncertainty between all locations nationwide (vermilion). Panel b is the same as panel a but with a smaller x scale. Boxplots of AALs in 2050 lie above those in 2020 for each correlation group. Boxes are bounded by the upper and lower quartiles, with the median at the centre, and minima and maxima at the end of each whisker.
Supplementary information
Supplementary Information
Supplementary Sections 1 and 2, Table 1 and Figs. 1–13.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wing, O.E.J., Lehman, W., Bates, P.D. et al. Inequitable patterns of US flood risk in the Anthropocene. Nat. Clim. Chang. 12, 156–162 (2022). https://doi.org/10.1038/s41558-021-01265-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41558-021-01265-6
This article is cited by
-
High urban flood risk and no shelter access disproportionally impacts vulnerable communities in the USA
Communications Earth & Environment (2024)
-
Linkages between riverine flooding risk and economic damage over the continental United States
Natural Hazards (2024)
-
Quantifying flood risk using InVEST-UFRM model and mitigation strategies: the case of Adama City, Ethiopia
Modeling Earth Systems and Environment (2024)
-
Theoretical Boundaries of Annual Flood Risk for Single-Family Homes Within the 100-Year Floodplain
International Journal of Environmental Research (2024)
-
Health Disparities in the Aftermath of Flood Events: A Review of Physical and Mental Health Outcomes with Methodological Considerations in the USA
Current Environmental Health Reports (2024)
