
Abstract
We investigate the problem of synthesizing T-depth optimal quantum circuits for exactly implementable unitaries over the Clifford+T gate set. We construct a subset, \({{\mathbb{V}}}_{n}\), of T-depth 1 unitaries. T-depth-optimal decomposition of unitary U is \({e}^{i\phi }\left({\prod }_{i}{V}_{i}\right)C\), \({V}_{i}\in {{\mathbb{V}}}_{n}\), C is Clifford and \(| {{\mathbb{V}}}_{n}| \,\le \,n\cdot {2}^{5.6n}\). We use nested meet-in-the-middle technique to synthesize provably depth-optimal and T-depth-optimal circuits. For the latter, we achieve space and time complexity \(O({({4}^{{n}^{2}})}^{\lceil d/c\rceil })\) and \(O({({4}^{{n}^{2}})}^{(c-1)\lceil d/c\rceil })\) respectively (d is the minimum T-depth, c ≥ 2 a constant). The previous best algorithm had complexity \(O({({3}^{n}\cdot {2}^{k{n}^{2}})}^{\lceil \frac{d}{2}\rceil }\cdot {2}^{k{n}^{2}})\)(k > 2.5 a constant). We design a more efficient algorithm with space and time complexity poly(n, 25.6n, d) (or \({{{\rm{poly}}}}({n}^{\log n},{2}^{5.6n},d)\) with weaker assumptions). The claimed efficiency, optimality depends on conjectures.
Similar content being viewed by others

Introduction
The notion of a quantum computer was introduced by Feynman1 as a solution to the limitations of conventional or classical computers. In numerous fields algorithms designed for quantum computers outperform their classical counterparts. Some examples include integer factorization2,3, searching an unstructured solution space4. One of the most widely used methods for describing and implementing quantum algorithms is quantum circuits, which consist of a series of elementary operations dictated by the implementing technologies.
Circuit synthesis and optimization is a significant part of any computer compilation process whose primary goal is to translate from a human-readable input (programming language) into instructions that can be executed directly on hardware. In quantum circuit synthesis, the aim is to decompose an arbitrary unitary operation into a sequence of gates from a universal set, which usually consists of Clifford group gates and at least one more non-Clifford gate5. The non-Clifford gates are more expensive to implement fault-tolerantly than Clifford gates. A popular universal fault-tolerant gate set is the Clifford+T, in which the cost of fault-tolerant implementation of the T gate6,7,8 exceeds the cost of the Clifford group gates by as much as a factor of a hundred or more in most error correction schemes. Fault-tolerant designs and quantum error correction are essential in order to deal with errors due to noise in quantum information, faulty quantum gates, faulty quantum state preparation, and faulty measurements. In particular, for long computations, where the number of operations in the computation vastly exceeds the number of operations one could hope to execute before errors make negligible the likelihood of obtaining a useful answer, fault-tolerant quantum error correction is the only known way to reliably implement the computation. With recent advances in quantum information processing technologies9,10,11,12 and fault-tolerant thresholds7,13,14, as scalable quantum computation is becoming more and more viable we need efficient automated design tools targeting fault-tolerant quantum computers. And minimization of the number of T gates in quantum circuits remains an important and widely studied goal. It has been argued15,16,17,18,19 that it is also important to reduce the maximum number of T gates in any circuit path. While the former metric is referred to as the T-count, the latter is called the T-depth of the circuit.
An n-qubit quantum circuit consisting of Clifford+T gates implements a 2n × 2n unitary. In the context of reducing resources (such as T gates) necessary to implement a unitary U, two types of problems have been investigated—(a) synthesis and (b) re-synthesis. The input to an algorithm for a quantum circuit synthesis problem is a 2n × 2n unitary matrix and the goal is to output a circuit implementing it20,21. When we impose additional constraints like minimizing certain resources such as T-count or T-depth16, we often call this as (resource)-optimal synthesis problem. From here on, we focus on the T-depth as the resource being minimized. To be more precise, there can be more than one (equivalent) circuits implementing U. A T-depth-optimal synthesis algorithm is required to output a circuit with the minimum T-depth. We call this a T-depth-optimal circuit. With a slight abuse of terminology, we use the terms ’synthesis algorithm’ and 'T-depth optimal synthesis algorithm’ interchangeably, which should be clear from the context. It must be observed that with the addition of this tighter constraint on the output (i.e. that it be T-depth optimal), there is a probability that the complexity of the problems change. For example, it was known that a quantum circuit can be synthesized in poly(2n) time, where 2n is the input size20,22. The work in ref. 23 was the first to propose a poly(2n) time algorithm for synthesizing T-count-optimal circuits.
With an input size O(2n), we cannot hope to get an optimal synthesis algorithm with a complexity of less than that. This makes these algorithms practically intractable after a certain value of n. Hence re-synthesis algorithms have been developed, where some more information is provided as input, usually a circuit implementing U17,24 and the task is to reduce (not minimize) the T-depth in the input circuit. In the literature, nearly every re-synthesis algorithm (usually with complexity poly(n)) does not account for the complexity of generating the initial input circuit from U. This step itself has complexity O(2n). A full study comparing these two kinds of algorithms and the quality of their results is beyond the scope of this work.
Despite their higher complexity compared to re-synthesis algorithms, the importance of studying optimal synthesis algorithms cannot be undermined. They can be used to assess the quality of a re-synthesis algorithm, for example, how close are their output to an optimal one. They can be used to generate the input circuit of a re-synthesis algorithm. A large circuit can be fragmented and the unitary of each part can be synthesized optimally, giving an overall reduction in resources. From a theoretical viewpoint, they shed light on the complexity of problems that are usually harder than their relaxed re-synthesis counterpart. As an illustration of the significance of developing resource-optimal synthesis algorithms, we observe the following. In our paper, we have been able to generate T-depth-optimal circuits for standard unitaries like Toffoli, Fredkin, Peres, and Quantum OR, which were not generated by the re-synthesis methods used in ref. 16. Though this has a T-depth-optimal synthesis algorithm, it could not synthesize beyond 2-qubit unitaries with T-depth 2. For larger unitaries like the mentioned 3-qubit ones, it used peep-hole optimization, a popular re-synthesis method. Except for Toffoli, they obtained T-depth 4, even for unitaries that are Clifford equivalent to Toffoli. The approach in this paper has significantly lower complexity than the synthesis method in ref. 16 and is able to synthesize T-depth 3 circuits.
The Solovay–Kitaev algorithm20,25 guarantees that given a unitary U, we can generate a circuit with a universal gate set like Clifford + T, such that the unitary \(U^{\prime}\) implemented by the circuit is at most a certain distance from U (the distance being induced by some appropriate norm). In fact, it has been proved that we can get a Clifford + T circuit that exactly implements U, i.e. \(U^{\prime} =U\) (up to some global phase) if and only if the entries of U are in ring \({\mathbb{Z}}\left[i,\frac{1}{\sqrt{2}}\right]\)21. We denote this group of unitaries by \({{{{\mathcal{J}}}}}_{n}\). For example, the Toffoli and Fredkin gates belong to \({{{{\mathcal{J}}}}}_{3}\). Thus quantum synthesis algorithms can be further subdivided into two categories: (a) exact synthesis algorithms, that output a circuit implementing \(U^{\prime} =U\) (e.g. refs. 23,26) and (b) approximate synthesis algorithms, that output a circuit implementing \(U^{\prime}\) such that \(U^{\prime}\) is close to U (e.g. ref. 27).
In this paper we focus on the group \({{{{\mathcal{J}}}}}_{n}\) of unitaries that can be exactly synthesized and consider the following synthesis problem.
MIN T-DEPTH
Given \(U\in {{{{\mathcal{J}}}}}_{n}\) synthesize a T-depth optimal circuit for it. In the decision version of this problem we are given \(U\in {{{{\mathcal{J}}}}}_{n}\) and \(m\in {\mathbb{N}}\), and the goal is to decide if the minimum T-depth of U is at most m.
We consider the complexity of our exact synthesis algorithms as a function of m and N = 2n. We treat arithmetic operations on the entries of U at unit cost, and we do not account for the bit complexity associated with specifying or manipulating them.
We first show (in the section “Methods”) that the nested meet-in-the-middle (MITM) technique developed in ref. 23 can be applied to the problem of synthesizing provably depth-optimal circuits. This gives us a depth-optimal-synthesis algorithm with time complexity \(O({|{{{{\mathcal{V}}}}}_{n,{{{\mathcal{G}}}}}|}^{(c-1)\lceil \frac{d^{\prime} }{c}\rceil })\) and space complexity \(O(| {{{{\mathcal{V}}}}}_{n,{{{\mathcal{G}}}}}{| }^{\lceil \frac{d^{\prime} }{c}\rceil })\), where \({{{{\mathcal{V}}}}}_{n,{{{\mathcal{G}}}}}\) is the set of depth-1 n-qubit unitaries over the gate set \({{{\mathcal{G}}}}\), \(d^{\prime}\) is the min-depth of input unitary, and c ≥ 2 is the extent of nesting. This gives us a space–time trade-off for MITM-related techniques applied to this problem.
Next, we apply this technique to synthesize T-depth optimal circuits. We work with channel representation of unitaries. We define a special subset, \({{\mathbb{V}}}_{n}\), of T-depth-1 unitaries, which can generate a T-depth-optimal decomposition of any exactly implementable unitary (up to some Clifford). We prove \(| {{\mathbb{V}}}_{n}| \in O(n\cdot {2}^{5.6n})\). Then we give an algorithm that returns provably T-depth-optimal circuits and has time and space complexity \(O({({4}^{{n}^{2}})}^{(c-1)\lceil \frac{d}{c}\rceil })\) and \(O({({4}^{{n}^{2}})}^{\lceil \frac{d}{c}\rceil })\), respectively, where d is the min-T-depth of input unitary. This is much less than the complexity of the algorithm in ref. 16. It had a complexity \(O({\left({3}^{n}\left|{{{{\mathcal{C}}}}}_{n}\right|\right)}^{\lceil \frac{d}{2}\rceil }\cdot | {{{{\mathcal{C}}}}}_{n}| )\), where \({{{{\mathcal{C}}}}}_{n}\) is the set of n-qubit Clifford operators. \(| {{{{\mathcal{C}}}}}_{n}| \in O({2}^{k{n}^{2}})\)28,29,30, for some constant k > 2.5. In ref. 16 the authors iteratively used \({{{{\mathcal{C}}}}}_{n}\), as indicated by the stated complexity. It took more than 4 days to generate \({{{{\mathcal{C}}}}}_{3}\)16. In fact, in ref. 16 the largest circuit optimally synthesized had 2 qubits and had T-depth 2. We use much smaller sets, which has cardinality \(O({4}^{{n}^{2}})\) and can be derived from \({{\mathbb{V}}}_{n}\). We can generate \({{\mathbb{V}}}_{3}\) in a few seconds (Table 1). This gives a (rough) indication of the computational advantage one can have if algorithms are designed with such smaller sets, and thus the motivation to come up with alternate representations.
To improve the efficiency further, we develop another algorithm, MIN-T-DEPTH, whose complexity depends on some conjectures that have been motivated by the polynomial complexity algorithm in ref. 23 for synthesizing T-count optimal circuits. At this point, our conjectures do not seem to be derived from the ones in ref. 23. If our assumptions are true, then this algorithm returns T-depth-optimal circuits with space and time complexity poly(n, 25.6n, d). Under a weaker assumption, this complexity is \({{{\rm{poly}}}}({n}^{\log n},d,{2}^{5.6n})\).
Apart from T-depth-optimal circuit synthesis algorithms for exactly implementable unitaries, the generating set \({{\mathbb{V}}}_{n}\), has found other applications like optimal synthesis algorithms for approximately implementable unitaries31.
The technique of meet-in-the-middle (MITM) and its variant (nested MITM) was used for the exact synthesis of provably T-count optimal circuits in refs. 23,26 as well as provably depth optimal circuits in ref. 16. This MITM technique has also been used with deterministic walks in ref. 32 to construct a parallel framework for the synthesis of T-count optimal circuits. The time as well as space complexity of the algorithms in refs. 26,32 is \(O\left({\left({2}^{n}\right)}^{m}\right)\) where m is the T-count of the 2n × 2n input unitary. (The T-count of a unitary is the minimum number of T gates required to implement it.) The time and space complexity of the algorithm in ref. 16 is \(O({({3}^{n}\cdot {2}^{k{n}^{2}})}^{\lceil \frac{d}{2}\rceil }\cdot {2}^{k{n}^{2}})\), where k is a constant and d is the min-T-depth. The first T-count-optimal synthesis algorithm which reduces the complexity to poly(2n, m), assuming some conjectures, was given in ref. 23.
Results and discussion
Preliminaries
We write [K] = {1, 2, …, K}. We assume that a set has distinct elements. We denote the n × n identity matrix by \({{\mathbb{I}}}_{n}\) or \({\mathbb{I}}\) if the dimension is clear from the context. The size of an n-qubit unitary is denoted by N = 2n. We call the number of non-zero entries in a matrix as its Hamming weight.
The single qubit Pauli matrices are as follows:
Parenthesized subscripts are used to indicate qubits on which an operator acts. For example, \({{{{\rm{X}}}}}_{(1)}={{{\rm{X}}}}\otimes {{\mathbb{I}}}^{\otimes (n-1)}\) implies that Pauli X matrix acts on the first qubit and the remaining qubits are unchanged.
The n-qubit Pauli operators are: \({{{{\mathcal{P}}}}}_{n}=\{{Q}_{1}\otimes {Q}_{2}\otimes \ldots \otimes {Q}_{n}:{Q}_{i}\in \{{\mathbb{I}},{{{\rm{X}}}},{{{\rm{Y}}}},{{{\rm{Z}}}}\}\}.\)
The single-qubit Clifford group \({{{{\mathcal{C}}}}}_{1}\) is generated by the Hadamard and phase gates: \({{{{\mathcal{C}}}}}_{1}=\left\langle {{{\rm{H}}}},{{{\rm{S}}}}\right\rangle\)where
When n > 1 the n-qubit Clifford group \({{{{\mathcal{C}}}}}_{n}\) is generated by these two gates (acting on any of the n qubits) along with the two-qubit \({{{\rm{CNOT}}}}=\left|0\right\rangle \left\langle 0\right|\otimes {\mathbb{I}}+\left|1\right\rangle \left\langle 1\right|\otimes {{{\rm{X}}}}\) gate (acting on any pair of qubits). Cliffords map Paulis to Paulis, up to a possible phase of −1, i.e. for any \(P\in {{{{\mathcal{P}}}}}_{n}\) and any \(C\in {{{{\mathcal{C}}}}}_{n}\) we have \(CP{C}^{{\dagger} }={(-1)}^{b}P^{\prime}\) for some b ∈ {0, 1} and \(P^{\prime} \in {{{{\mathcal{P}}}}}_{n}\). In fact, given two Paulis (neither equal to the identity), it is always possible to efficiently find a Clifford which maps one to the other.
Fact 2.1 (Gosset et al.26) For any P, P′ ∈ Pn\{I} there exists a Clifford C ∈ Cn such that CPC† = P′. A circuit for C over the gate set {H, S, CNOT} can be computed efficiently (as a function of n).
The group \({{{{\mathcal{J}}}}}_{n}\) is generated by the n-qubit Clifford group along with the T gate. Thus
It can be easily verified that \({{{{\mathcal{J}}}}}_{n}\) is a group, since the H and CNOT gates are their own inverses and T−1 = T7. We denote the group of unitaries exactly synthesized over the Clifford + T gate set by \({{{{\mathcal{J}}}}}_{n}\). Some elements of this group cannot be exactly synthesized over this gate set without ancilla qubits21.
Channel representations
An n-qubit unitary U can be completely determined by considering its action on a Pauli \({P}_{s}\in {{{{\mathcal{P}}}}}_{n}\) : UPsU†. Since \({{{{\mathcal{P}}}}}_{n}\) is a basis for the space of all Hermitian N × N matrices we can write
This defines a N2 × N2 matrix \(\widehat{U}\) with rows and columns indexed by Paulis \({P}_{r},{P}_{s}\in {{{{\mathcal{P}}}}}_{n}\). We refer to \(\widehat{U}\) as the channel representation of U26.
By Hermitian conjugation each entry of the matrix \(\widehat{U}\) is real. The channel representation respects matrix multiplication, i.e. \(\widehat{UV}=\widehat{U}\widehat{V}\). Setting V = U† and using the fact that \(\widehat{{U}^{{\dagger} }}={\left(\widehat{U}\right)}^{{\dagger} }\), we see that the channel representation \(\widehat{U}\) is unitary. If \(U\in {{{{\mathcal{J}}}}}_{n}\), implying its entries are in the ring \({\mathbb{Z}}\left[i,\frac{1}{\sqrt{2}}\right]\)21, then from Eq. (1) the entries of \(\widehat{U}\) are in the same ring. Since \(\widehat{U}\) is real, its entries are from the subring
The channel representation identifies unitaries that differ by a global phase. We write the following for the groups in which global phases are modded out.
Each \(Q\in \widehat{{{{{\mathcal{C}}}}}_{n}}\) is a unitary matrix with one nonzero entry in each row and each column, equal to ± 1. This is because Cliffords map Paulis to Paulis up to a possible phase of −1. The converse also holds: if \(W\in \widehat{{{{{\mathcal{J}}}}}_{n}}\) has this property then \(W\in \widehat{{{{{\mathcal{C}}}}}_{n}}\). Since the definition of T-count is insensitive to the global phase, it is well-defined in the channel representation and so \({{{\mathcal{T}}}}(\widehat{U})\) is defined to be equal to \({{{\mathcal{T}}}}(U)\). If a unitary U requires ancilla to be implemented, then we can consider the unitary that acts on the joint state space of input and ancilla qubits. From here on, with a slight abuse of notation when we write \(U\in {{{{\mathcal{J}}}}}_{n}\) we assume it is the unitary that acts on this joint state space.
Definition 2.1
For any non-zero \(v\in {\mathbb{Z}}\left[\frac{1}{\sqrt{2}}\right]\) the smallest denominator exponent, denoted by sde(v), is the smallest \(k\in {\mathbb{N}}\) for which
We define sde(0) = 0. For a d1 × d2 matrix M with entries over this ring we define
T-depth
The purpose of this section is to derive a generating set consisting of T-depth 1 unitaries, such that we can write a T-depth-optimal decomposition of any exactly implementable unitary (up to global phase) as a product of elements of this set and a trailing Clifford. This set must be efficiently generated and have a finite cardinality. We first give some essential definitions.
Definition 2.2
The depth of a circuit is the length of any critical path through the circuit. Representing a circuit as a directed acyclic graph with nodes corresponding to the circuit’s gates and edges corresponding to gate inputs/outputs, a critical path is a path of maximum length flowing from an input of the circuit to an output.
In other words, suppose the unitary U implemented by a circuit is written as a product U = UmUm−1…U1 such that each Ui can be implemented by a circuit in which all the gates can act in parallel or simultaneously. We say Ui has depth 1 and m is the depth of the circuit. We often refer to each Ui as a stage or (parallel) block. The T-depth of a circuit is the number of stages (or unitaries Ui) where the T/T† gate is the only non-Clifford gate and all the T/T† gates can act in parallel. The min-T-depth or T-depth of a unitary U is the minimum T-depth of a Clifford + T circuit that implements it (up to a global phase). We often simply say T-depth instead of 'T-depth of a unitary’. It should be clear from the context.
Any unitary U, having a circuit with T-depth t can be written as follows:
In the above equation \(\overline{T}\in \{{{{\rm{T}}}},{{{{\rm{T}}}}}^{{\dagger} },{\mathbb{I}}\}\) is used to indicate whether there is T, T† or \({\mathbb{I}}\) gate in that qubit. \({C}_{1},{C}_{2},{C}_{3}\ldots {C}_{t}\in {{{{\mathcal{C}}}}}_{n}\). For simplicity we ignore the global phase. We can also write the above equation as follows:
We call each Vj as a (parallel) block. It is a product of T or T† gates on distinct qubits, conjugated by a Clifford. Thus the following set
can be regarded as a generating set (up to a Clifford) for the decomposition of an exactly implementable unitary. More precisely, any exactly implementable unitary U (ignoring the global phase) can be written as a product of elements from this set and a Clifford. The number of elements from \({{\mathbb{V}}}_{n}\) is equal to the T-depth of this decomposition or circuit. Any decomposition of U with the minimum number of parallel blocks is called a T-depth-optimal decomposition. A circuit implementing U with the minimum T-depth is called a T-depth-optimal circuit.
We can equivalently write each Vj as follows:
Now if \(C\in {{{{\mathcal{C}}}}}_{n}\) then
The R(P) unitaries and somewhat similar unitaries called Pauli gadgets have been studied extensively in previous works like refs. 26,33. We believe that the conclusions derived in this paper will enhance the study of these gadgets or special unitaries, such that we can have more applications (for example, see ref. 31).
Also \({\left(R(P)\right)}^{{\dagger} }=C{{{{\rm{T}}}}}_{(i)}^{{\dagger} }{C}^{{\dagger} }={R}^{{\dagger} }(P)\) (let). Thus we can write Eq. (5) as follows:
The second subscript of Pij gives the index of the block. The ordering of the intermediate T/T† gates does not matter. It merely changes the sequence of \(\widetilde{R}({P}_{ij})\), but we get the same product Vj. Given a set S of qubits there are 3∣S∣ possible ways of placing a \({{{\rm{T}}}}/{{{{\rm{T}}}}}^{{\dagger} }/{\mathbb{I}}\) gate in each qubit. We call each such placement as a configuration of \(\overline{T}\) gates and denote it by \({\overline{T}}_{S}\).
From Eq. (7) we get a simple way of constructing \({{\mathbb{V}}}_{n}^{\prime}\).
-
1.
For each \(C\in {{{{\mathcal{C}}}}}_{n}\) do the following.
-
(a)
For each configuration \({\overline{T}}_{[n]}\) do the following.
-
i.
\(V\leftarrow {\mathbb{I}}\).
-
ii.
For each i ∈ [n] do the following.
If \({\overline{T}}_{(i)}\,\ne \,{\mathbb{I}}\) then determine P = CZ(i)C†. If \(\overline{T}={{{\rm{T}}}}\) then V ← V ⋅ R(P), else if \(\overline{T}={{{{\rm{T}}}}}^{{\dagger} }\) then V ← V ⋅ R†(P).
-
iii.
Include V in \({{\mathbb{V}}}_{n}^{\prime}\) if it does not already exist.
-
i.
-
(a)
The time complexity of this procedure is \(O\left(| {{{{\mathcal{C}}}}}_{n}| \right)\) or \(O({2}^{k{n}^{2}})\), where k is a constant. A bound on \(| {{\mathbb{V}}}_{n}^{\prime}|\) can be obtained by counting all possible distinct n-length strings of \(\widetilde{R}(P)\), where \(\widetilde{R}\in \{R,{R}^{{\dagger} }\}\) and \(P\in \pm {{{{\mathcal{P}}}}}_{n}\). Without loss of generality we can assume that every string or sequence is of length n, by filling in \(R({\mathbb{I}})={R}^{{\dagger} }({\mathbb{I}})={\mathbb{I}}\). Thus it gives \(| {{\mathbb{V}}}_{n}^{\prime}| \,<\, {\left(2\cdot 2\cdot {4}^{n}\right)}^{n}={4}^{n+{n}^{2}}\). From ref. 26 we know that there are at most \({4}^{{n}^{2}}\cdot | {{{{\mathcal{C}}}}}_{n}|\) unitaries (up to global phase) with T-count n. So it is highly plausible that \(| {{\mathbb{V}}}_{n}^{\prime}| \in O({4}^{{n}^{2}})\).
Every n-length string of \(\widetilde{R}(P)\) does not have T-depth 1. We are over-counting a lot here. Our aim is to construct a more compact (smaller) set of T-depth 1 unitaries such that it is possible to write any T-depth 1 unitary as product of unitaries from this set and a Clifford. This is sufficient because it will enable us to write any T-depth-d decomposition (and hence T-depth-optimal decomposition) of a unitary as product of elements from this set and a Clifford (up to global phase). In this way, we can use information from a set of less number of unitaries in order to make more intelligent guesses about a T-depth-optimal decomposition (specially algorithm MIN-T-DEPTH). We would want to prune many Cliffords to be considered at step 1.
Here we make the following observation. There are \({2}^{O({n}^{2})}\) Clifford operators that can map Z(i) to a particular Pauli \(P\in {{{{\mathcal{P}}}}}_{n}\). All of them lead to the same unitary R(P). Similarly, there are many Cliffords such that when ∏iZ(i) (where the Zs are on different qubits) is conjugated it leads to the same sequence of Paulis (ordering does not matter) i.e. it will give the same unitary ∏iR(Pi). So for our purpose, what is more important are the mappings or rather images of mappings, and not the Clifford operators. If CPC† = P, we call it a trivial conjugation, for any \(P\in {{{{\mathcal{P}}}}}_{n},C\in {{{{\mathcal{C}}}}}_{n}\). P, in this case, is trivially conjugated by C.
We now construct a smaller generating set, \({{\mathbb{V}}}_{n}\). We consider each \(\widetilde{R}(P)\) as the starting unit of a string and then determine the remaining n−1 units. A formal constructive definition of \({{\mathbb{V}}}_{n}\) is as follows.
Definition 2.3
We define \({{\mathbb{V}}}_{n}\), a subset of n-qubit unitaries with T-depth 1, that is constructed as follows.
-
1.
Include \(\widetilde{R}({Z}_{(i)})\) (i ∈ [n]) in \({{\mathbb{V}}}_{n}\).
-
2.
For each \(P\in \pm {{{{\mathcal{P}}}}}_{n}\!\!\setminus\!\! \{{\mathbb{I}}\}\), for each q ∈ [n] and for each \(\widetilde{R}\in \{R,{R}^{{\dagger} }\}\) do the following.
-
(a)
For each Clifford C such that P = CZ(q)C†. (If P = Z(q), we will skip this iteration for Z(q). We will discuss later which Cliffords to consider.)
-
i.
For each configuration \({\overline{T}}_{[n]\setminus \{q\}}\) do the following.
-
A.
\(V\leftarrow \widetilde{R}(P)\).
-
B.
For each i ∈ [n]⧹{q} do the following.
If \({\overline{T}}_{(i)}\,\ne \,{\mathbb{I}}\) then determine \(P^{\prime} =C{Z}_{(i)}{C}^{{\dagger} }\). If \(\overline{T}={{{\rm{T}}}}\) then \(V\leftarrow V\cdot R(P^{\prime} )\), else if \(\overline{T}={{{{\rm{T}}}}}^{{\dagger} }\) then \(V\leftarrow V\cdot {R}^{{\dagger} }(P^{\prime} )\).
-
C.
Include V in \({{\mathbb{V}}}_{n}\) if it did not already exist.
-
A.
-
i.
-
(a)
Cliffords to be considered (or not considered) at step 2(a)
We have explained before that for our purpose, combinations of images obtained by conjugating Z(i) (ordering does not matter) is the most important, in order to have distinct unitaries. So we can make some choices of Cliffords to be considered (or rather, not to be considered) at step 2(a). For this, we can make some observations.
-
1.
If \(C\left({\prod }_{i}{\overline{T}}_{(i)}\right){C}^{{\dagger} }={\prod }_{j}\widetilde{R}({Z}_{(j)})\) for any \(C\in {{{{\mathcal{C}}}}}_{n}\) then it is equal to the unitary \(\left({\prod }_{j}{\overline{T}}_{(j)}\right)\), even if the set of indices i and j are not same. Thus we have included each \(\widetilde{R}({Z}_{(j)})\) at step 1. Products of these also give T-depth 1 unitaries. In step 2(a) if P = Z(q) then we skip the iteration. In this loop we always consider those sequences of conjugations where there is at least one non-trivial mapping. So we always start with a non-trivial conjugation.
-
2.
If C = ⊗ iCi for some Cliffords Ci then it is easy to see that we can write \(U=C\left({\prod }_{j}{\overline{T}}_{(j)}\right){C}^{{\dagger} }={\prod }_{i}{C}_{i}\left({\prod }_{{j}_{i}}{\overline{T}}_{({j}_{i})}\right){C}_{i}^{{\dagger} }={\prod }_{i}{U}_{i}\), where each Ui has T-depth 1. So it is sufficient to consider each Ci and not C.
-
3.
Let \(U=C\left(\mathop{\prod }\nolimits_{i = a}^{b}{\overline{T}}_{(i)}\right){C}^{{\dagger} }\) is such that CZ(j)C† = Z(j), where a ≤ j ≤ b. Then we can decompose U = U1U2 where U1 excludes T(j) and U2 = T(j) and each is of T-depth 1. This implies we should be concerned with the images of non-trivial conjugations (more reason to separate the trivial conjugations at step 1).
To determine the Cliffords to be considered we follow the mappings given in ref. 28. Consider i ∈ [n]. First, we fix 2(4n − 1)4n Cliffords in \({{{{\mathcal{C}}}}}_{n}\) that conjugate Z(i) or X(i) non-trivially. We call these coset leaders of Z(i). The elements of \({{{{\mathcal{C}}}}}_{n}\) that conjugate Z(i) and X(i) trivially, form a group isomorphic to \({{{{\mathcal{C}}}}}_{n-1}\) with the number of cosets at most 2(4n − 1)4n. For example, let \(C\in {{{{\mathcal{C}}}}}_{n}\) is a coset leader (of Z(i)) such that CZ(i)C† = P where P ≠ Z(i), then any other Clifford that does the same conjugation (which is not a coset leader of Z(i)) is of the form \(CC^{\prime}\) where \(C^{\prime} {Z}_{(i)}{C}^{\prime\dagger}={Z}_{(i)}\). In step 2(a) (when q = i) we consider all these coset leaders only. Suppose C is a coset leader that conjugates Z(i) to P ≠ Z(i). In the loop 2(a) we considered all possible sequences of R(P) or images obtained by conjugation of Z(j) (j ≠ i) by C. Let \(C^{\prime}\) is non-coset leader of Z(i) and does the trivial conjugation of Z(i). Now among all the Z(j) (j ≠ i) where \(CC^{\prime}\) conjugates non-trivially, it has to be the coset leader of one of them. This follows from the counting argument. So again we take all possible combinations of images obtained by conjugations by \(CC^{\prime}\), when the loop starts with that particular position of T/T†.
Taking product
Now suppose \({U}_{1}={C}_{1}\left({\prod }_{i}{\overline{T}}_{(i)}\right){C}_{1}^{{\dagger} }\in {{\mathbb{V}}}_{n}\) and \({U}_{2}={C}_{2}\left({\prod }_{j}{\overline{T}}_{(j)}\right){C}_{2}^{{\dagger} }\in {{\mathbb{V}}}_{n}\), and there is no qubit such that a T/T†-gate is placed in both the unitaries. Let C1 conjugates Z(j) trivially if j is a qubit in which there is a T/T† gate in U2. Similarly \({C}_{2}{Z}_{(i)}{C}_{2}^{{\dagger} }={Z}_{(i)}\), where there is a T/T† gate on qubit i in U1. If [C1, C2] = 0 then it is easy to check that \(U={U}_{1}{U}_{2}={C}_{1}{C}_{2}\left({\prod }_{k}{\overline{T}}_{(k)}\right){C}_{2}^{{\dagger} }{C}_{1}^{{\dagger} }\) has T-depth 1. If \({C}_{2}{Z}_{(j)}{C}_{2}^{{\dagger} }={P}_{j}\) and \({C}_{1}{P}_{j}{C}_{1}^{{\dagger} }={P}_{j}\) then we do not need the commutation condition. It is straightforward to check that these conditions satisfy the 3 observations made earlier. (While constructing \({{\mathbb{V}}}_{n}\), we can store the information about which unitaries can be multiplied to have a T-depth 1 product.) Thus we can generate T-depth 1 unitaries (without trailing Clifford) by taking product of unitaries from \({{\mathbb{V}}}_{n}\).
Thus, from the above discussion, we can have the following result.
Theorem 2.1
Any \(U\in {{{{\mathcal{J}}}}}_{n}\) with T-depth 1 can be written as follows : \(U={e}^{i\phi }\left(\mathop{\prod }\nolimits_{i = d}^{1}{V}_{i}\right){C}_{0}\), where \({V}_{i}\in {{\mathbb{V}}}_{n}\), \({C}_{0}\in {{{{\mathcal{C}}}}}_{n}\) and d ≥ 1.
Proof
We ignore the global phase and the trailing Clifford. Let \(U=C\left({\prod }_{i\in [n]}{\overline{T}}_{(i)}\right){C}^{{\dagger} }\) (Eq. (3)). Let S ⊆ [n] is the set of qubits such that C conjugates Z(i) trivially, where i ∈ S. Then we can write \(U=\left({\prod }_{i\in S}\widetilde{R}({Z}_{i})\right)C\left({\prod }_{i\in \overline{S}}{\overline{T}}_{(i)}\right){C}^{{\dagger} }=\left({\prod }_{i\in S}\widetilde{R}({Z}_{i})\right)U^{\prime} .\) Each of these \(\widetilde{R}({Z}_{(i)})\) are included in \({{\mathbb{V}}}_{n}\) (step 1). So now let us consider the second term, \(U^{\prime}\), in the product. If C = ⊗ jCj then we can write \(U^{\prime} ={\prod }_{j}{C}_{j}\left({\prod }_{k\in {S}_{j}}{\overline{T}}_{(k)}\right){C}_{j}^{{\dagger} }={\prod }_{j}{U}_{j}^{\prime}\), where \({S}_{j}\subseteq \overline{S}\) is the set of qubits on which Cj acts. If there are no T/T† gates at any qubit of Sj then \({C}_{j}{C}_{j}^{{\dagger} }={\mathbb{I}}\). Else, there exists at least one k ∈ Sj such that Cj conjugates Z(k) non-trivially. In step 2 of the definition of \({{\mathbb{V}}}_{n}\), we have included each such Uj in our set. This proves the theorem.
In ref. 26 it has been shown that \(\{R(P):P\in {{{{\mathcal{P}}}}}_{n}\}\) generates the T-count-optimal decomposition of any exactly implementable unitary, up to a Clifford. The channel representation inherits these decompositions and in this representation, the global phase goes away. Thus we can write the following:
Let
Fact 2.2 \(| {{\mathbb{V}}}_{n}| \,\le \,2n\cdot {3}^{n-1}\cdot {4}^{n}\cdot {4}^{n} \,<\, n\cdot {2}^{5.6n}\) and hence \(| \widehat{{{\mathbb{V}}}_{n}}| \,< n\cdot {2}^{5.6n}\).
Proof
From Definition 2.3, for each starting R(P)/R†(P) there can be n positions for first T/T† gate respectively. In the remaining qubits we can have T, T† or \({\mathbb{I}}\). Thus there are at most 3n−1 ways to place the T/T† gates in remaining (n−1) qubits. Given a starting Clifford and a configuration, the rest of the R(P) unitaries are uniquely determined. We have discussed that we need to consider at most 2 ⋅ 4n ⋅ 4n Cliffords (coset leaders, as discussed before) that can map each Z(i) to any P28,29,30. More precisely, there are at most 2 ⋅ 4n ⋅ 4n choices for the starting Clifford for each of the n positions of the starting T/T† gate, which can lead to distinct strings of R(P) during the construction of \({{\mathbb{V}}}_{n}\). So we get the stated bounds.
In Table 1 we have compared the cardinalities and generation time of \({{\mathbb{V}}}_{n}\) and \({{{{\mathcal{C}}}}}_{n}\). The latter has been used in16 to design a T-depth-optimal-synthesis algorithm. We use the set \({{\mathbb{V}}}_{n}\) for our heuristic algorithm MIN-T-DEPTH. In the next section we use a bigger set with cardinality \(O({4}^{{n}^{2}})\), much less than \(| {{{{\mathcal{C}}}}}_{n}| \in O({2}^{k{n}^{2}})\), where k > 2.5. This set can be derived from \({{\mathbb{V}}}_{n}\), or we can simply use \({{\mathbb{V}}}_{n}^{\prime}\). We will see in the following sections how the cardinalities of these sets make a difference in the running time and space of the various algorithms.
The following fact can be easily proved from Fact 3.2 in ref. 23.
Fact 2.3 Let \(W^{\prime} =\widehat{\widetilde{R}(P)}W\) where W and \(W^{\prime}\) are unitaries, \(\widetilde{R}\in \{R,{R}^{{\dagger} }\}\) and \(P\in \pm {{{{\mathcal{P}}}}}_{n}\). Then \({{{\rm{sde}}}}(W^{\prime} )={{{\rm{sde}}}}(W)\pm 1\) or \({{{\rm{sde}}}}(W^{\prime} )={{{\rm{sde}}}}(W)\).
An \(O\left({N}^{4}\right)\) time algorithm for multiplying two N2 × N2 unitaries \({\widehat{\widetilde{R}(P)}}\) and W (where N = 2n) has been given in ref. 23. This will help in computing \(\widehat{{{\mathbb{V}}}_{n}}\) faster, but it will not make much difference in the asymptotic complexity of any of our algorithms. So these are not essential for the rest of the paper.
Discussion of implementation results
We implemented our heuristic algorithm MIN-T-DEPTH (described in the section “Methods”) in standard C++17 on an Intel(R) Core(TM) i7-7700K CPU at 4.2 GHz, with 8 cores and 16 GB RAM, running Debian Linux 9.13. We used OpenMP34 for parallelization and the Eigen 3 matrix library35 for some of the matrix operations. Our algorithm returns a T-depth-optimal decomposition of an input unitary. We can generate a circuit for each R(P) using Fact 2.1 and the trailing Clifford using the algorithm in ref. 5. We remind the reader that the numerical results of this subsection, together with instructions on how to reproduce them, are available online at https://github.com/vsoftco/t-depth. We have implemented MIN-T-DEPTH and not the optimal nested MITM algorithm because the former has better complexity.
We have synthesized T-depth-optimal circuits for three-qubit benchmark unitaries like Toffoli, Fredkin, Peres, Quantum OR, Negated Toffoli (Table 2). We found the min-T-depth of all these unitaries is 3, which is less than the T-depth of the circuits shown in ref. 16 (except Toffoli). The authors did not perform a T-depth-optimal synthesis of these 3 qubit circuits, since their algorithm required to generate a (pre-processed) set of more than 92,897,280 elements, which took more than 4 days (Table 1). The running time as well as space requirement, being an exponential (in min-T-depth) of this set, it would have been intractable on a PC. The largest T-depth-optimal circuit implemented in ref. 16 had 2-qubits and had T-depth 2. In our case the set generated during pre-processing is \({{\mathbb{V}}}_{n}\). In case of three qubits it has 2282 elements and takes about 2 s to be generated. The average searching time is 27.5 min. Thus our algorithm clearly outperforms the previously best T-depth-optimal synthesis algorithm in ref. 16.
We would like to mention here that for T-depth-optimal synthesis algorithms like16 or ours, the input is a unitary matrix and no other additional information is provided. The T-depth of some unitaries may be related. For example, the authors have been pointed out that T-depth of Fredkin, Peres can be obtained from T-depth of Toffoli because they are Clifford equivalent. There are some concerns here. We do not know of any efficient test for Clifford equivalence given arbitrary exactly implementable unitaries. Second, we are unaware of any set of benchmark unitaries from which we can derive the T-depth of any exactly implementable unitary. In fact, these extra information can serve as litmus tests for the correctness of the output of any algorithm.
We have synthesized T-depth-optimal circuits for 2 and 3-qubit permutation unitaries. We found that all 2-qubit permutations are Cliffords. It took us, on average, 0.726 seconds to synthesize 2-qubit permutations. We considered about 100 random 3-qubit permutation unitaries and (due to time constraints) we synthesized completely (up to Clifford) the unitaries with T-depth at most 5. The permutations with T-depth at most 3 took on average 15 min. The permutations with T-depth at most 5 took on average 4.5 h.
We have also tested our algorithm on random 2 and 3 qubit circuits (Table 3). The input 2 and 3 qubit circuits had T-depth 2-10 and 2-7, respectively. Each line in Table 3 is computed from 10 random circuits. By Max.# nodes we mean the maximum number of unitaries selected at any level. ’avg’ means we average this statistic over all unitaries considered. ’std’ means we find the standard deviation of this statistic. We found out that the circuits output by our algorithm had T-depth at most of the input T-depth. Now the min-T-depth can be at most the input T-depth. We could not verify the optimality of our results, since we do not know of any T-depth-optimal synthesis algorithm that can implement such large circuits. However, this is a good indication that our algorithm MIN-T-DEPTH actually obtains the min-T-depth for most unitaries.
Methods
A faster synthesis algorithm for T-depth
In this section, we describe an exact synthesis algorithm that finds a circuit that is provably T-depth-optimal. We modify the algorithm by Amy et al.16 and employ a nested meet-in-the-middle technique, as has been done by Mosca and Mukhopadhyay23, to optimize the T-count. This gives a more space-efficient algorithm to get optimal depth circuits. Furthermore, we work with channel representations to get T-depth-optimal circuits. This reduces both the time and space complexity compared to the algorithm in ref. 16.
An exact algorithm for depth-optimal circuits
We first describe a general algorithm where we are given a set of gates (and their inverses), \({{{\mathcal{G}}}}\), with which we want to design a depth optimal circuit implementing a unitary U. The set \({{{\mathcal{G}}}}\) is called the instruction set. Let \({{{{\mathcal{V}}}}}_{n,{{{\mathcal{G}}}}}\) be the set of n-qubit unitaries of depth 1 that can be implemented by a circuit designed with the gates in \({{{\mathcal{G}}}}\). We state the following lemma which can be regarded as a generalization of Lemma 1 in ref. 16. This observation allows us to search for circuits of depth d by only generating circuits of depth at most \(\lceil \frac{d}{c}\rceil\) (c ≥ 2).
Lemma 3.1
Let Si ⊂ U(2n) be the set of all unitaries implementable in depth i over the gate set \({{{\mathcal{G}}}}\). Given a unitary U, there exists a circuit over \({{{\mathcal{G}}}}\) of depth (d1 + d2) implementing U if and only if \({S}_{{d}_{1}}^{{\dagger} }U\bigcap {S}_{{d}_{2}}\,\ne \,{{\emptyset}}\).
Proof
We note that \(U\in {S}_{i}^{{\dagger} }=\{{U}^{{\dagger} }| U\in {S}_{i}\}\) if and only if U can be implemented in depth i over \({{{\mathcal{G}}}}\). (Though this was proved in Lemma 1 of ref. 16 we include it briefly here for completion). Let U = U1U2…Ui where \({U}_{1},{U}_{2},\ldots ,{U}_{i}\in {{{{\mathcal{V}}}}}_{n,{{{\mathcal{G}}}}}\) and so \({U}^{{\dagger} }={U}_{i}^{{\dagger} }\ldots {U}_{2}^{{\dagger} }{U}_{1}^{{\dagger} }\). As \({{{\mathcal{G}}}}\) is closed under inversion so \({U}_{1}^{{\dagger} },{U}_{2}^{{\dagger} },\ldots ,{U}_{i}^{{\dagger} }\in {{{{\mathcal{V}}}}}_{n,{{{\mathcal{G}}}}}\), and thus a circuit of depth i over \({{{\mathcal{G}}}}\) implements U†. Since \({\left({S}_{i}^{{\dagger} }\right)}^{{\dagger} }={S}_{i}\) the reverse direction follows.
Suppose U is implementable by a circuit C of depth d1 + d2. We divide C into two circuits of depth d1 and d2, implementing unitaries \({W}_{1}\in {S}_{{d}_{1}}\) and \({W}_{2}\in {S}_{{d}_{2}}\) respectively, where W1W2 = U. So \({W}_{2}={W}_{1}^{{\dagger} }U\in {S}_{{d}_{1}}^{{\dagger} }U\) and hence \({W}_{2}\in {S}_{{d}_{1}}^{{\dagger} }U\bigcap {S}_{{d}_{2}}\).
In the other direction let \({S}_{{d}_{1}}^{{\dagger} }U\bigcap {S}_{{d}_{2}}\,\ne \,{{\emptyset}}\). So there exists some \({W}_{2}\in {S}_{{d}_{1}}^{{\dagger} }U\bigcap {S}_{{d}_{2}}\). Since \({W}_{2}\in {S}_{{d}_{1}}^{{\dagger} }U\) so \({W}_{2}={W}_{1}^{{\dagger} }U\) for some \({W}_{1}\in {S}_{{d}_{1}}^{{\dagger} }\). Now \({W}_{2}\in {S}_{{d}_{2}}\) and W1W2 = U. Thus U is implementable by some circuit of depth d1 + d2.
We now describe our procedure (Nested MITM), whose pseudocode has been given Algorithm 1. The input consists of the unitary U, instruction set \({{{\mathcal{G}}}}\), depth d and c ≥ 2 that indicates the extent of nesting or recursion we want in our meet-in-the-middle approach. If U is of depth at most d then the output consists of a decomposition of U into smaller depth unitaries, else the algorithm indicates that U has depth more than d. At the beginning of the algorithm we generate the set \({{{{\mathcal{V}}}}}_{n,{{{\mathcal{G}}}}}\).
Algorithm 1
Nested MITM

The algorithm consists of \(\lceil \frac{d}{c}\rceil\) iterations and in the ith such iteration we generate circuits of depth i (Si) by extending the circuits of depth i−1 (Si−1) by one more level. Then we use these two sets to search for circuits of depth at most ci. The search is performed iteratively where in the kth (1 ≤ k ≤ c−1) round we generate unitaries of depth at most ki by taking k unitaries W1, W2, …, Wk where Wi ∈ Si or Wi ∈ Si−1. Let W = W1W2…Wk and its depth is \(k^{\prime} \,\le \,ki\). We search for a unitary \(W^{\prime}\) in Si or Si−1 such that \({W}^{{\dagger} }U=W^{\prime}\). By Lemma 3.1 if we find such a unitary it would imply that depth of U is \(k^{\prime} +i\) or \(k^{\prime} +i-1\), respectively. In the other direction if the depth of U is either \(k^{\prime} +i\) or \(k^{\prime} +i-1\) then there should exist such a unitary \(W^{\prime}\) in Si or Si−1, respectively. Thus if the depth of U is at most d then the algorithm terminates in one such iteration and returns a decomposition of U. This proves the correctness of this algorithm.
Time and space complexity
We impose a strict lexicographic ordering on unitaries such that a set Si can be sorted with respect to this ordering in \(O\left(| {S}_{i}| \log | {S}_{i}| \right)\) time and we can search for an element in this set in \(O\left(\log | {S}_{i}| \right)\) time. An example of such an ordering is ordering two unitaries according to the first element in which they differ. Now consider the kth round of the ith iteration (steps 3–17 of Algorithm 1). We build unitaries W of depth at most ki using elements from Si or Si−1. Number of such unitaries is at most ∣Si∣k. Given a W, time taken to search for \(W^{\prime}\) in Si or Si−1 such that \({W}^{{\dagger} }U=W^{\prime}\) is \(O\left(\log | {S}_{i}| \right)\). Since \(| {S}_{j}| \,\le \,| {{{{\mathcal{V}}}}}_{n,{{{\mathcal{G}}}}}{| }^{j}\), so the kth iteration of the for loop within the ith iteration of the while loop, takes time \(O\left(| {{{{\mathcal{V}}}}}_{n,{{{\mathcal{G}}}}}{| }^{(c-1)i}\log | {{{{\mathcal{V}}}}}_{n,{{{\mathcal{G}}}}}| \right)\). Thus the time taken by the algorithm is \(O\left(| {{{{\mathcal{V}}}}}_{n,{{{\mathcal{G}}}}}{| }^{(c-1)\lceil \frac{d}{c}\rceil }\log | {{{{\mathcal{V}}}}}_{n,{{{\mathcal{G}}}}}| \right)\).
In the algorithm we store unitaries of depth at most \(\lceil \frac{d}{c}\rceil\). So the space complexity of the algorithm is \(O\left(| {{{{\mathcal{V}}}}}_{n,{{{\mathcal{G}}}}}{| }^{\lceil \frac{d}{c}\rceil }\right)\). Since \(| {{{{\mathcal{V}}}}}_{n,{{{\mathcal{G}}}}}| \in O\left(| {{{\mathcal{G}}}}{| }^{n}\right)\), so we have an algorithm with space complexity \(O\left(| {{{\mathcal{G}}}}{| }^{n\lceil \frac{d}{c}\rceil }\right)\) and time complexity \(O\left(n| {{{\mathcal{G}}}}{| }^{n(c-1)\lceil \frac{d}{c}\rceil }\log | {{{\mathcal{G}}}}| \right)\).
Reducing both space and time complexity to find T-depth optimal circuits
We now consider the special case where \({{{\mathcal{G}}}}\) is the Clifford+T gate set and the goal is to design a T-depth optimal circuit for a given unitary U. We work with the channel representation of unitaries. We generate the set \({{\mathbb{V}}}_{n}^{^{\prime\prime} }\), which consists of products of unitaries from \({{\mathbb{V}}}_{n}\) and has T-depth 1. We have explained in Section T-depth how to perform such products. We can even use \({{\mathbb{V}}}_{n}^{\prime}\) described in the previous section. In Section T-depth we gave conditions for generating these products. Thus we replace \({{{{\mathcal{V}}}}}_{n,{{{\mathcal{G}}}}}\) with \(\widehat{{{\mathbb{V}}}_{n}^{^{\prime\prime} }}\). It is easy to see that for any T-depth 1 unitary \(\widehat{U}\) there exists \(\widehat{V}\in \widehat{{{\mathbb{V}}}_{n}^{^{\prime\prime} }}\) such that \(\widehat{U}=\widehat{V}\widehat{C}\) for some Clifford \(C\in {{{{\mathcal{C}}}}}_{n}\). This motivates us to use the following definition from ref. 26.
Definition 3.1 (Coset label)
Let \(W\in \widehat{{{{{\mathcal{J}}}}}_{n}}\). Its coset label W(co) is the matrix obtained by the following procedure. (1) Rewrite W so that each nonzero entry has a common denominator, equal to \({\sqrt{2}}^{{{{\rm{sde}}}}(W)}\). (2) For each column of W, look at the first non-zero entry (from top to bottom) which we write as \(v=\frac{a+b\sqrt{2}}{{\sqrt{2}}^{{{{\rm{sde}}}}(W)}}\). If a < 0, or if a = 0 and b < 0, multiply every element of the column by − 1. Otherwise, if a > 0, or a = 0 and b > 0, do nothing and move on to the next column. (3) After performing this step on all columns, permute the columns so that they are ordered lexicographically from left to right.
Since unitaries stored in \(\widehat{{{\mathbb{V}}}_{n}^{^{\prime\prime} }}\) are distinct, we can say that this set stores the coset labels of T-depth 1 unitaries. The following can be shown.
Theorem 3.1 (Proposition in ref. 26)
Let \(W,V\in \widehat{{{{{\mathcal{J}}}}}_{n}}\). Then W(co) = V(co) if and only if W = VC for some \(C\in \widehat{{{{{\mathcal{C}}}}}_{n}}\).
The nested meet-in-the-middle search for T-depth-optimal circuit is performed as described before, except for the following changes. We replace the set \({{{{\mathcal{V}}}}}_{n,{{{\mathcal{G}}}}}\) with the set \(\widehat{{{\mathbb{V}}}_{n}^{^{\prime\prime} }}\) (step 4 of Algorithm 1), for reasons described before. This helps us to generate coset labels of unitaries with increasing T-depth. We work with channel representations \(\widehat{W},\widehat{{W}_{1}},\widehat{{W}_{2}},\ldots\). So at the kth round of the ith iteration, we calculate \(\widehat{W}=\mathop{\prod }\nolimits_{j = 1}^{k}\widehat{{W}_{j}}\) where \(\widehat{{W}_{j}}\in {S}_{i}\) or Si−1. Then we check if \(\exists \widehat{W^{\prime} }\in {S}_{i}\) (or Si−1 respectively) such that \({({\widehat{W}}^{{\dagger} }\widehat{U})}^{(co)}=\widehat{W^{\prime} }\). If such a unitary exists it would imply \(U={e}^{i\phi }WW^{\prime} C\) for some Clifford \(C\in {{{{\mathcal{C}}}}}_{n}\). From Lemma 3.1 we can say that U can be implemented by a circuit with T-depth equal to the sum of the T-depth of the circuit for W and \(W^{\prime}\).
Space and time complexity
From Fact 2.2 we know that \(| \widehat{{{\mathbb{V}}}_{n}}| \,\le \,n\cdot {2}^{5.6n}\) and \({{\mathbb{V}}}_{n}^{^{\prime\prime} }\) is formed by taking the product of unitaries from \({{\mathbb{V}}}_{n}\). The most naive upper bound that we can have is \(| {{\mathbb{V}}}_{n}^{^{\prime\prime} }| \in O({4}^{{n}^{2}})\), which is the bound on \({{\mathbb{V}}}_{n}^{\prime}\) discussed in the section “T-depth”. (We believe that \(| {{\mathbb{V}}}_{n}^{^{\prime\prime} }|\) is much less than \({4}^{{n}^{2}}\).) Thus analyzing in the same way as before we can say that the algorithm has space complexity \(O({({4}^{{n}^{2}})}^{\lceil \frac{d}{c}\rceil })\) and time complexity \(O({({4}^{{n}^{2}})}^{(c-1)\lceil \frac{d}{c}\rceil })\) (c ≥ 2). This is much less than the space and time complexity of the T-depth-optimal algorithm in ref. 16. They use the MITM technique and the space and time complexity is \(O({({3}^{n}| {{{{\mathcal{C}}}}}_{n}| )}^{\lceil \frac{d}{2}\rceil }\cdot | {{{{\mathcal{C}}}}}_{n}| )\). The cardinality of the n-qubit Clifford group, \({{{{\mathcal{C}}}}}_{n}\), is \(O({2}^{k{n}^{2}})\) (k > 2.5)28,29. So the space and time complexity is \(O({({2}^{k{n}^{2}})}^{\lceil \frac{d}{2}\rceil +1}{3}^{n\lceil \frac{d}{2}\rceil })\), where k > 2.5. Clearly, even if the extent of nesting is 2 i.e. c = 2, in which case our procedure becomes a MITM algorithm, we get a significant improvement in both time and space complexity.
A more efficient algorithm to synthesize T-depth optimal circuits
In this section, we describe an algorithm that on input a 2n × 2n unitary U finds a T-depth optimal circuit for it and has space and time complexity poly(n, 25.6n, d) with some conjecture (or \({{{\rm{poly}}}}({n}^{\log n},d,{2}^{5.6n})\) with a weaker conjecture), where d is the min-T-depth of U. We draw inspiration from some observations made in ref. 23, while developing a polynomial time algorithm for synthesizing T-count-optimal circuits. We came up with another way of pruning the search space. The numerical results of this section (Tables 2 and 3) are available online at https://github.com/vsoftco/t-depth.
Algorithm 2
\({{{\mathcal{A}}}}\)

Algorithm 3
MIN T-DEPTH

The input of our algorithm is the channel representation of a 2n × 2n unitary U. From Theorem 2.1 we know there exists a T-depth-optimal decomposition of \(\widehat{U}\) as follows : \(\widehat{U}=\left(\mathop{\prod }\nolimits_{i = d^{\prime\prime} }^{1}\widehat{{V}_{i}}\right)\widehat{{C}_{0}}\), where \({C}_{0}\in {{{{\mathcal{C}}}}}_{n}\), \(\widehat{{V}_{i}}\in {{\mathbb{V}}}_{n}\), d ≤ d″ ≤ dn and d is the T-depth of U. We iteratively try to guess the blocks \(\widehat{{V}_{i}}\) by looking at the change in some ’properties’ of the matrix \({\widehat{{V}_{i}}}^{-1}\widehat{U^{\prime} }\) where \(\widehat{U^{\prime} }=\mathop{\prod }\nolimits_{j = d^{\prime\prime} }^{i+1}{\widehat{{V}_{j}}}^{-1}\widehat{U}\). If we have the correct sequence then we should reach \(\widehat{{C}_{0}}\), a matrix consisting of exactly one +1 or −1 in each row and column. As in ref. 23 we consider two properties of the resultant matrices—their sde and Hamming weight. The intuition is as follows. Consider a unitary \(\widehat{W}\) and we multiply it by \(\widehat{{V}_{1}}\in \widehat{{{\mathbb{V}}}_{n}}\). Let \(\widehat{Y}=\widehat{W{V}_{1}}\), \({{{\Delta }}}_{s}={{{\rm{sde}}}}(\widehat{W})-{{{\rm{sde}}}}(\widehat{Y})\) and \({{{\Delta }}}_{h}={{{\rm{ham}}}}(\widehat{W})-{{{\rm{ham}}}}(\widehat{Y})\), where ham(. ) is the Hamming weight. Now we multiply \(\widehat{Y}\) by \({\widehat{{V}_{i}}}^{-1}\) where \(\widehat{{V}_{i}}\in \widehat{{{\mathbb{V}}}_{n}}\). Let \(\widehat{Z}=\widehat{Y{V}_{i}^{-1}}\), \({{{\Delta }}}_{s}^{i}={{{\rm{sde}}}}(\widehat{Y})-{{{\rm{sde}}}}(\widehat{Z})\) and \({{{\Delta }}}_{h}^{i}={{{\rm{ham}}}}(\widehat{Y})-{{{\rm{ham}}}}(\widehat{Z})\). If Vi = V1 then \({{{\Delta }}}_{s}=-{{{\Delta }}}_{s}^{i}\) and \({{{\Delta }}}_{h}=-{{{\Delta }}}_{h}^{i}\). But if Vi ≠ V1 then with high probability we do not expect to see this kind of change. This helps us to distinguish the Vi’s in at least one T-depth-optimal decomposition.
The pseudocode for algorithm MIN T-DEPTH has been given in Algorithm 3. We iteratively call the sub-procedure \({{{\mathcal{A}}}}(\widehat{U},d^{\prime} )\) with the value \(d^{\prime} \in {\mathbb{Z}}\) increasing in each iteration. We accumulate all decompositions returned by \({{{\mathcal{A}}}}\). Then in MIN T-DEPTH we check if in each such decomposition we can combine consecutive unitaries to form a T-depth 1 unitary (refer to the section “T-depth”). We output a decomposition with the minimum T-depth. Here let us explain the starting value for \(d^{\prime}\). If we know that any circuit requires at least x T gates to implement U, we know that the T-depth of any circuit implementing U will be at least \(\lceil \frac{x}{n}\rceil\). Thus if we know \({{{\mathcal{T}}}}(U)\) i.e. the T-count of U we can start the iterations with \(d^{\prime} =\lceil \frac{{{{\mathcal{T}}}}(U)}{n}\rceil\). If we do not know that, we can consider \({{{\rm{sde}}}}(\widehat{U})\). Due to Fact 2.3 we know \({{{\mathcal{T}}}}(U)\,\ge \,{{{\rm{sde}}}}(\widehat{U})\), so we can also start the iterations with \(d^{\prime} =\lceil \frac{{{{\rm{sde}}}}(\widehat{U})}{n}\rceil\). We can also determine stopping criteria from these information. For example, if we get a decomposition with T-depth \(\lceil \frac{{{{\mathcal{T}}}}(U)}{n}\rceil\), then we can stop immediately. Alternatively, we can generate the set \({{\mathbb{V}}}_{n}^{^{\prime\prime} }\), described for our nested-MITM algorithm and stop as soon as we get a decomposition in \({{{\mathcal{A}}}}\).
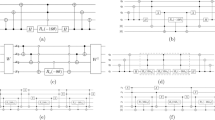
It will be useful if we depict the procedure \({{{\mathcal{A}}}}\) using a tree (Fig. 1), where each node stores a unitary. The root (depth 0) stores \(\widehat{U}\). The edges are labeled by unitaries from \({\widehat{{{\mathbb{V}}}_{n}}}^{-1}\), which is defined as
This is a set of n-qubit unitaries with T-depth 1 (refer to the section “T-depth”). A child node unitary is obtained by multiplying the parent unitary with the unitary of the edge. We refer to these two types of unitaries as ’node-unitary’ and ’edge-unitary’ respectively. The product of the edge unitaries on a path from the root to a non-root node is referred to as the ’path unitary’ with respect to the non-root node. By ’path T-count’ of a non-root node, we refer to the sum of the number of R(P) terms in the edge-unitaries. Each R(P) has one T-gate. At each depth of the tree, we group the nodes into some ’hypernodes’ such that the path T-count of each node within a hypernode is the same. At this point it will be useful to observe \({\widehat{{{\mathbb{V}}}_{n}}}^{-1}={\bigcup }_{1\le j\le n}{\widehat{{{\mathbb{V}}}_{n,j}}}^{-1}\), where \({\widehat{{{\mathbb{V}}}_{n,j}}}^{-1}\) is the set of unitaries with j number of \({\widehat{R(P)}}^{-1}\). In Fig. 1 we have grouped the edges such that the edge-unitaries within one such ’hyperedge’ are from \({\widehat{{{\mathbb{V}}}_{n,j}}}^{-1}\) for some j.

Each node stores a unitary, the root at level 0 storing \(\widehat{U}\). The edges are labeled by unitaries in \({\widehat{{{\mathbb{V}}}_{n}}}^{-1}\). A child node unitary is obtained by multiplying the edge unitary with the parent node unitary. The edges are grouped into hyper-edges, where each hyper-edge is labeled by a unitary in \({\widehat{{{\mathbb{V}}}_{n,j}}}^{-1}\). The nodes are grouped into hyper-nodes, where each hyper-node has a number indicating the number of \({\widehat{R(P)}}^{-1}\) in the path from the root to each node in this hyper-node. Within each hyper-node we select some nodes according to some criteria and the nodes in the next level are built from these selected (black) nodes.
At each depth, within each such hypernode we sub-divide the nodes according to the sde of its unitary and change in Hamming weight of this unitary compared to the parent node-unitary. By change in Hamming weight we mean if it has increased or decreased or remains unchanged, with respect to the Hamming weight of the parent node. Within each hypernode we select the set of nodes with minimum cardinality such that sde of its unitaries can be reduced to 0 within depth \(d^{\prime}\) of the tree. We build the nodes in the next level from the ‘selected’ node-unitaries only. We stop building the tree as soon as we reach a node-unitary with sde 0, indicating we reached a Clifford. If we have not reached any Clifford within depth \(d^{\prime}\) we quit and conclude that minimum T-depth of \(\widehat{U}\) is more than \(d^{\prime}\). A pseudocode of the procedure \({{{\mathcal{A}}}}\) has been given in Algorithm 2. The number of hypernodes in depth i can be at most ni − i + 1, since the path T-count of any unitary can be at most ni and at least i. Also, since the sde can change by at most 1 after multiplying by any \({\widehat{R(P)}}^{-1}\) (Fact 2.3), then after multiplying by any unitary in \({{\mathbb{V}}}_{n,j}^{-1}\) sde of any unitary can change by at most j. So (at step 25 of Algorithm 2) we select the minimum sized set among those sets of unitaries which has the potential to reach the Clifford within the remaining steps.
To analyze the space and time complexity of our algorithm we make the following conjecture.
Conjecture 1
(a) While dividing the nodes according to their sde and change in Hamming weight within any hypernode, the minimum cardinality of any set (such that its sde can be potentially reduced to 0) is bounded by poly(2n). (b) Also, we get at least one T-depth-optimal decomposition.
So our conjecture has two parts. (a) bounds the size of the tree and thus determines the complexity of the algorithm. (b) implies that we can preserve at least one T-depth-optimal decomposition by pruning in this way. So it determines the efficiency. We can make a weaker conjecture with a more relaxed bound.
Conjecture 2
(Weaker version) (b) While dividing the nodes according to their sde and change in Hamming weight within any hypernode, the minimum cardinality of any set (such that its sde can be potentially reduced to 0) is bounded by \({{{\rm{poly}}}}({n}^{\log n},{2}^{n})\). (b) Also, we get at least one T-depth-optimal decomposition.
Comparison with Conjecture 1 in ref. 23
In ref. 23 the authors proposed some conjectures to reduce the complexity of synthesizing T-count-optimal circuits. Our algorithm has been motivated by that work but based on current knowledge it does not appear that Conjectures 1 or 2 can be derived from the conjecture used in ref. 23, with the present knowledge. The main intuition of these conjectures stems from the following observation. Suppose we multiply a unitary \(\widehat{U}^{\prime}\) by \(\widehat{R({P}_{1})}\). We will notice some change in the properties (like sde, Hamming weight) in the product unitary \(\widehat{W}^{\prime} =\widehat{U}^{\prime} \widehat{R({P}_{1})}\) compared to the initial \(\widehat{U}^{\prime}\). Now when we multiply \(\widehat{W}^{\prime}\) by \({\widehat{R({P}_{1})}}^{-1}\) we will see these effects reversed. But if we multiply \(\widehat{W}^{\prime}\) by \({\widehat{R({P}_{i})}}^{-1}\) (where i ≠ 1) then with high probability we will observe some other effects. In ref. 23 the authors used these intuitions to design a T-count-optimal algorithm, where they iteratively tried to guess a sequence of R(P)s in a T-count-optimal decomposition of U, by observing these change in properties. In our present algorithm (see Fig. 1) we consider many paths with different T-counts at each level. Now the T-depth-optimal decompositions will follow some of these paths. When we select the minimum cardinality set in each hypernode (where all unitaries have the same path T-count), we expect that the distinguishing property that we explained before does not get destroyed even if we multiply an (intermediate) unitary by up to n\({\widehat{R(P)}}^{-1}\). We do not see how this observation follows from the conjecture in ref. 23, without some more knowledge about the underlying mathematics. So for T-depth-optimal decompositions, we have made separate conjectures.
Space and time complexity
We consider the time and space complexity of \({{{\mathcal{A}}}}\). From Fact 2.2 we know \(| {\widehat{{{\mathbb{V}}}_{n}}}^{-1}| \,\le \,n\cdot {2}^{5.6n}\). These are the number of unitaries we always store.
In the ith iteration we have up to ni−i + 1 children hypernodes. There are at most n(i−1)−(i−1)+1 parent hypernodes and within each at most poly(2n) parent nodes are selected by Conjecture 1. Each parent node is multiplied by \(| \widehat{{{\mathbb{V}}}_{n}}|\)22n × 22n unitaries. Arguing in similar way space and time complexity of procedure \({{{\mathcal{A}}}}\) is \({{{\rm{poly}}}}\left(d^{\prime} ,n,{2}^{5.6n}\right)\).
Since MIN T-DEPTH consists of at most dn iterations of \({{{\mathcal{A}}}}\), where d is the minimum T-depth of U, so space and time complexity is \({{{\rm{poly}}}}\left(d,n,{2}^{5.6n}\right)\).
If we assume the weaker Conjecture 2 then we get a space and time complexity \({{{\rm{poly}}}}\left(d,{n}^{\log n},{2}^{5.6n}\right)\).
Data availability
Numerical results together with instructions on how to reproduce them, are available online at https://github.com/vsoftco/t-depth.
Code availability
The code is available from the corresponding author on request.
References
Feynman, R. P. Simulating physics with computers. Int. J. Theor. Phys 21, 467–488 (1982).
Shor, P. W. Polynomial-time algorithms for prime factorization and discrete logarithms on a quantum computer. SIAM Rev. 41, 303–332 (1999).
Shor, P. W. Algorithms for quantum computation: discrete logarithms and factoring. In Proc. 35th Annual Symposium on Foundations of Computer Science, 124–134 (IEEE, 1994).
Grover, L. K. A fast quantum mechanical algorithm for database search. In Proc. 28th Annual Symposium on Theory of Computing, 212–219 (ACM, 1996).
Aaronson, S. & Gottesman, D. Improved simulation of stabilizer circuits. Phys. Rev. A 70, 052328 (2004).
Bravyi, S. & Kitaev, A. Universal quantum computation with ideal Clifford gates and noisy ancillas. Phys. Rev. A 71, 022316 (2005).
Fowler, A. G., Stephens, A. M. & Groszkowski, P. High-threshold universal quantum computation on the surface code. Phys. Rev. A 80, 052312 (2009).
Aliferis, P., Gottesman, D. & Preskill, J. Quantum accuracy threshold for concatenated distance-3 codes. Quantum Inf. Comput. 6, 97–165 (2006).
Britton, J. W. et al. Engineered two-dimensional Ising interactions in a trapped-ion quantum simulator with hundreds of spins. Nature 484, 489 (2012).
Brown, K. R. et al. Single-qubit-gate error below 10−4 in a trapped ion. Phys. Rev. A 84, 030303 (2011).
Chow, J. M. et al. Universal quantum gate set approaching fault-tolerant thresholds with superconducting qubits. Phys. Rev. Lett. 109, 060501 (2012).
Rigetti, C. et al. Superconducting qubit in a waveguide cavity with a coherence time approaching 0.1 ms. Phys. Rev. B 86, 100506 (2012).
Bombin, H., Andrist, R. S., Ohzeki, M., Katzgraber, H. G. & Martín-Delgado, M. A. Strong resilience of topological codes to depolarization. Phys. Rev. X 2, 021004 (2012).
Fowler, A. G., Whiteside, A. C. & Hollenberg, L. C. L. Towards practical classical processing for the surface code. Phys. Rev. Lett. 108, 180501 (2012).
Fowler, A. G. Time-optimal quantum computation. Preprint at https://arXiv.org/quant-ph/1210.4626 (2012).
Amy, M., Maslov, D., Mosca, M. & Roetteler, M. A meet-in-the-middle algorithm for fast synthesis of depth-optimal quantum circuits. IEEE Trans. Comput.-Aided Design Integr. Circuits Syst. 32, 818–830 (2013).
Amy, M., Maslov, D. & Mosca, M. Polynomial-time T-depth optimization of Clifford+T circuits via matroid partitioning. IEEE Trans. Comput.-Aided Design Integr. Circuits Syst. 33, 1476–1489 (2014).
Amy, M. et al. Estimating the cost of generic quantum pre-image attacks on SHA-2 and SHA-3. In Int. Conf. on Selected Areas in Cryptography, 317–337 (Springer, 2016).
Di Matteo, O., Gheorghiu, V. & Mosca, M. Fault-tolerant resource estimation of quantum random-access memories. IEEE Trans. Quantum Eng. 1, 1–13 (2020).
Dawson, C. M. & Nielsen, M. A. The Solovay–Kitaev algorithm. Quantum Inf. Comput. 6, 81–95 (2006).
Giles, B. & Selinger, P. Exact synthesis of multiqubit Clifford+T circuits. Phys. Rev. A 87, 032332 (2013).
de Brugière, T. G., Baboulin, M., Valiron, B. & Allouche, C. Quantum circuits synthesis using Householder transformations. Comput. Phys. Commun. 248, 107001 (2020).
Mosca, M. & Mukhopadhyay, P. A polynomial time and space heuristic algorithm for T-count. Quantum Sci. Technol. 7, 015003 (2021).
Häner, T. & Soeken, M. Lowering the T-depth of quantum circuits by reducing the multiplicative depth of logic networks. Preprint at https://arXiv.org/quant-ph/2006.03845 (2020).
Kitaev, A. Y. Quantum computations: algorithms and error correction. Russ. Math. Surv. 52, 1191 (1997).
Gosset, D., Kliuchnikov, V., Mosca, M. & Russo, V. An algorithm for the T-count. Quantum Inf. Comput. 14, 1261–1276 (2014).
Ross, N. J. & Selinger, P. Optimal ancilla-free Clifford+T approximation of Z-rotations. Quantum Inf. Comput. 16, 901–953 (2016).
Ozols, M. Clifford group. Essays at University of Waterloo (Springer, 2008).
Koenig, R. & Smolin, J. A. How to efficiently select an arbitrary Clifford group element. J. Math. Phys. 55, 122202 (2014).
Calderbank, A. R., Rains, E. M., Shor, P. M. & Sloane, N. J. A. Quantum error correction via codes over GF(4). IEEE Trans. Inf. Theory 44, 1369–1387 (1998).
Gheorghiu, V., Mosca, M. & Mukhopadhyay, P. T-count and T-depth of any multi-qubit unitary. Preprint at https://arXiv.org/quant-ph/2110.10292 (2021).
Di Matteo, O. & Mosca, M. Parallelizing quantum circuit synthesis. Quantum Sci. Technol. 1, 015003 (2016).
Cowtan, A., Dilkes, S., Duncan, R., Simmons, W. & Sivarajah, S. Phase gadget synthesis for shallow circuits. In 16th Int. Conf. on Quantum Physics and Logic, 213–228 (Open Publishing Association, 2019).
The OpenMP API Specification for Parallel Programming. https://www.openmp.org/ (2021).
Eigen: A C++ Template Library for Linear Algebra. http://eigen.tuxfamily.org (2021).
Acknowledgements
The authors wish to thank NTT Research for their financial and technical support. This work was supported in part by Canada’s NSERC. IQC and the Perimeter Institute (PI) are supported in part by the Government of Canada and the Province of Ontario (PI). We thank the anonymous reviewers for their comments, that not only helped us improve the write-up significantly, but also led to a tighter bound in Fact 2.2.
Author information
Authors and Affiliations
Contributions
The ideas were given by P.M. The software implementations were done by V.G. All the authors have made substantial contributions to the preparation of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing non-financial interests but the following competing financial interests. M.M. is co-founder of softwareQ Inc. and has filed a provisional patent application for this work. P.M. is a co-inventor of this patent.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Gheorghiu, V., Mosca, M. & Mukhopadhyay, P. A (quasi-)polynomial time heuristic algorithm for synthesizing T-depth optimal circuits. npj Quantum Inf 8, 110 (2022). https://doi.org/10.1038/s41534-022-00624-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41534-022-00624-1
This article is cited by
-
Synthesizing efficient circuits for Hamiltonian simulation
npj Quantum Information (2023)
-
Improving the implementation of quantum blockchain based on hypergraphs
Quantum Information Processing (2023)
-
T-count and T-depth of any multi-qubit unitary
npj Quantum Information (2022)
