
Abstract
Prepare-and-measure (P&M) quantum networks are the basic building blocks of quantum communication and cryptography. These networks crucially rely on non-orthogonal quantum encodings to distribute quantum correlations, thus enabling superior communication rates and information-theoretic security. Here, we present a computational toolbox that can efficiently characterise the set of input–output probability distributions for any discrete-variable P&M quantum network, assuming only the inner-product information of the quantum encodings. Our toolbox is thus highly versatile and can be used to analyse a wide range of quantum network protocols, including those that employ infinite-dimensional quantum code states. To demonstrate the feasibility and efficacy of our toolbox, we use it to solve open problems in multipartite quantum distributed computing and quantum cryptography. Taken together, these findings suggest that our method may have implications for quantum network information theory and the development of new quantum technologies.
Similar content being viewed by others
Introduction
Quantum correlations1,2,3 (namely, entanglement, nonlocality, steering correlations, etc) are essential resources in quantum information processing. In short, they are the reason why we see such unique advantages in quantum communication, cryptography, computing, and imaging. The general observation is that the stronger these correlations are, the more powerful quantum information becomes. This is especially the case for quantum communication4 and quantum cryptography,5 where stronger entanglement means higher quantum fidelity and stronger information security. For this reason, the characterisation of quantum correlations is an integral step in many quantum information protocols and a central research topic in quantum information science.
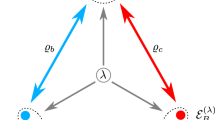
In this work, we are interested in characterising the quantum correlations of prepare-and-measure (P&M) networks, which are the basic building blocks of quantum communication and quantum cryptography. The central goal of a P&M quantum network is to send some classical message z over a quantum network to a group of receivers (see Fig. 1). This message could be anything, e.g., a secret key, elements of a database, or a signed certificate—it depends on the function of the protocol. Quantum encoding is done by preparing a quantum signal in one of the n predefined pure states, \(\{ |\psi _z\rangle \} _{z = 1}^n\) (determined by the input z), and decoding is accomplished by making a measurement (sampled from a finite set of decoding settings) on the output quantum signal. For a generic P&M quantum network with k spatially separated receivers, we write p(a1a2…ak|x1x2…xk, z) to denote the probability of obtaining outcomes a1a2…ak given decoding functions x1x2…xk and message z. We use p to denote the entire list of input–output probability distributions.

Scenario and assumptions. The behaviour of a two-receiver prepare-and-measure (P&M) quantum network is generally described by p = [p(ab|xy, z)], which expresses the probability of z transiting to outcomes a, b given measurement inputs x, y. In the quantum setting, the set of conditional probabilities are given by \(p(ab|xy,z) = \langle \phi _z|E_x^aE_y^b|\phi _z\rangle\), with the constraint that 〈ϕz|ϕz′〉 = λzz′ is fixed. Our consideration hence assumes three conditions: (1) the set of code states are pure states, (2) the Gram matrix of these states is known, and (3) the receivers are independent of each other (they do not share any quantum resources, although classical randomness is allowed)
Our broad goal is to reveal the fundamental limits of P&M quantum networks without restrictions on the network and local decoding strategies. In particular, we are interested in identifying the set of quantum-realisable correlations p (henceforth called the quantum set) using only the knowledge of the quantum encoding scheme {|ψz〉}z. In fact, as we shall show later, it is enough to use the inner-product information of the encoding scheme (instead of the complete specification) to achieve tight characterisation of the quantum network. This type of approach is particularly useful for analysing the performance of quantum communication and quantum cryptography. For instance, one can use the quantum set to derive lower bounds on the quantum network’s error probabilities.6,7,8 These bounds essentially tell us what the encoding scheme could achieve in practice, be it for quantum cryptography, communication, or distributed computing purposes, as we shall demonstrate later.
Also, from the perspective of quantum information theory, this approach draws a direct connection between the distinguishability of quantum states and quantum correlations. More concretely, we first note that if the quantum encoding {|ψz〉}z is completely orthogonal, i.e., 〈ψz|ψz′〉= δzz′, then p is generally unconstrained. That is, such encodings are classical states and hence can be arbitrarily copied—as such, there are no physical principles that could constrain the input–output probability distribution (except for the usual normalisation requirements). The interesting part comes when the encoding {|ψz〉}z is non-orthogonal. In this case, there are two unique consequences. First, it is generally impossible for every receiver to learn the same information about z. This is due to the fact that one cannot clone non-orthogonal states,9 and consequently, there is a global trade-off between the amount of accessible information that each receiver can receive.10,11 Second, no receiver can completely learn z even if he or she has received {|ψz〉}z with perfect fidelity. This is because non-orthogonal states are fundamentally indistinguishable: there is no measurement that can discriminate them with perfect reliability.12 Consequently, probability assignments like p(a = z|x) = 1 are forbidden. Taken together, these imply that, contrary to orthogonal (classical) encodings, correlations emanating from quantum encodings have non-trivial constraints (e.g., see quantum broadcasting13,14).
Results
To solve the above characterisation problem, we propose a general computational method that is able to approximate (from the outside) the quantum set of any P&M quantum network. The approximation is based on a hierarchy of semidefinite relaxations, which is a generalisation and novel application of earlier research in quantum nonlocality.2,15,16,17,18,19,20 More specifically, we extend and generalise the hierarchy of semidefinite relaxations proposed in refs 19,20 to the case whereby the quantum state shared between the receivers is not fixed. A key feature of our method is that it is semi-device independent (SDI).21,22,23,24,25,26,27 That is, the analysis provided is independent of how the network and measurements are implemented. The method only requires that the quantum encoding {|ψz〉}z is characterised in terms of its Gram matrix, i.e., 〈ψz|ψz′〉 = λzz′, which in practice can be easily obtained by taking the inner products of the quantum code states (i.e., using their specifications).
The main advantage with this approach is that the dimension of the encoding system is no longer necessary in the analysis—using the inner-product information is enough to tightly characterise the quantum set. Indeed, the inner-product information is sufficient as it tells us how non-orthogonal the encoded states are and whether they are classical or not. As such, our approach is more practical than the standard SDI approach, which assumes the dimension of the quantum encoding system.21,22,23,24 Notice that physical dimension is generally difficult to fix in practice as actual systems have multiple degrees of freedom. We remark that alternative SDI approaches based on bounded energy constraints26 and the transmission of non-orthogonal binary states27 have also been proposed. These have similar advantages as our approach, but present analyses using these approaches are so far limited to binary code states. It remains to be seen if these can be readily generalised to multiple code states, schemes that are often used in quantum technologies. In the following, we show that our method can be used to efficiently analyse any practical quantum communication protocol,28 including those that use multiple infinite-dimensional code states.
To keep our presentation concise, we restrict the discussion to two-receiver P&M quantum networks (see Fig. 1); extension to larger networks is straightforward. Consider a P&M quantum task, where random code states are sent across a network to two independent receivers, called Alice and Bob, for measurement. For simplicity, we divide the task into two phases: a distribution phase and a measurement phase. In the first phase, a classical random source z is encoded into a quantum system |ψz〉 and distributed to Alice and Bob via an untrusted quantum network. For this type of transmission, it is useful to work in the purification picture, where state transformations are given by unitary evolutions.29 That is, by working in a higher-dimensional Hilbert space, we may see the transmission as an isometric evolution that takes |ψz〉 to some pure output state |ϕz〉, which is now shared between the receivers and the network environment (the purification system). The key advantage of this picture is that while the dimension and possibly other properties of |ψz〉 may change after the transmission, the inner-product information of {|φz〉}z remains the same: 〈ϕz|ϕz′〉 = 〈ψz|ψz′〉. Importantly, this means that our initial knowledge about 〈ψz|ψz′〉 = λzz′ is preserved in the transformed states.
In the measurement phase, Alice and Bob perform independent and random measurements on |ϕz〉 to gain information about z. Since there are only two receivers here, we revert back to the usual convention and denote Alice’s and Bob’s measurements by x and y and their corresponding measurement outcomes by a and b, respectively. Then, using the quantum Born rule, we have that the probability of observing outcomes a, b given measurements x, y and |ϕz〉 is
where \(\{ E_x^a\}\) and \(\{ E_y^b\}\) are projective measurements satisfying the following properties: (i) for any x, \(E_x^aE_x^{a^\prime } = 0\) for \(a\not = a^\prime\), (ii) \(\mathop {\sum}\nolimits_a E_x^a = {\Bbb I}\), (iii) \((E_x^a)^2 = E_x^a = (E_x^a)^\dagger\), and (iv) \([E_x^a,E_y^b] = 0\). We note that there is no loss of generality in assuming projective measurements here. Indeed, we can always lift any measurement to a projective one by working in a higher-dimensional Hilbert space; in our case this is possible since the dimension of the network is not fixed. The last property reflects the fact that Alice’s and Bob’s measurements are separable and hence the application of one has no effect on the outcome of the other.
Our characterisation problem is thus the following: Given an n × n Hermitian positive-semidefinite matrix λ, what is the corresponding quantum set p? We denote this set by \({\cal Q}(\lambda )\). In principle, solving this problem would require optimising over all possible quantum states and measurements in Eq. (1) subject to the constraints 〈ϕz|ϕz′〉 = λzz′. However, this task is computationally intractable: the dimension of the network is not fixed and thus could be infinite. To overcome this obstacle, we take inspiration from the characterisation techniques16,17,18,19,20 developed in Bell nonlocality research,2,15 which is a special case of our problem. Recall that in a Bell experiment, local random measurements are made on a fixed source |ϕ〉 instead of a varying source |ϕz〉. Notably, it was shown in refs 19,20 that the set of quantum probabilities derived from Bell experiments can be approximated via a hierarchy of membership tests. There, the basic idea is to bound the quantum set using a sequence of weaker (but tractable) characterisation tasks, which nevertheless still represent very well the original problem.
In this work, we show that a similar characterisation technique can also be devised for the general problem. More specifically, we give a general procedure for deriving (tractable) necessary conditions for any discrete-variable P&M quantum network. To start with, consider a quantum probability distribution \(p(ab|xy,z) = \langle \phi _z|E_x^aE_y^b|\phi _z\rangle\), where 〈ϕz|ϕz′〉 = λzz′, and with \(\{ E_x^a,E_y^b\} _{a,x,b,y}\) satisfying properties (i)–(iv). Let \({\cal S} = \{ S_1, \ldots ,S_m\}\) be a finite set of m operators, where each element is a linear combination of products of \(\{ E_x^a,E_y^b\} _{a,x,b,y}\). Then define G to be the nm × nm block matrix
where \(G_{(i,j)}^{zz^\prime } = \langle \phi _z|S_i^\dagger S_j|\phi _{z^\prime }\rangle\) for all z, z′ ∈ [n], i, j ∈ [m]. Here we denote by \(\{ |e_z\rangle \} _{z = 1}^n\) the standard orthonormal basis of \({\Bbb C}^n\) and by \(G_{(i,j)}^{zz{\prime}}\) the ij-entry of the matrix Gzz′. By construction, the matrix G is Hermitian and positive-semidefinite (PSD).30 Furthermore, properties (i)–(iv) of the measurement operators and the inner-product constraints 〈ϕz|ϕz′〉 = λzz′ translate to linear conditions on the entries of G. To see this, we note that if the set \({\cal S}\) contains operators \(\{ E_x^a\} _{a,x}\) and \(\{ E_y^b\} _{b,y}\), then it can be easily verified that G satisfies
Therefore, for any discretely modulated P&M quantum network, it is always possible to define a PSD matrix that captures the original quantum model (1) in terms of constraints that are linear in its entries. Importantly, the existence of such a matrix provides us with a powerful means to check if a given p is of quantum origin. More specifically, we can use semidefinite programming (SDP) techniques31 to verify if p is in the set of compatible PSD matrices: if p is not a member, we conclude that it is not quantum realisable. However, successful membership does not necessarily mean p is of quantum origin. This is due to the fact that our characterisation method is a semidefinite relaxation32 of the original problem and hence can only provide an outer-approximation of \({\cal Q}(\lambda )\).
However, by introducing additional linear constraints via a hierarchical procedure, it is possible to gain a tighter characterisation of \({\cal Q}(\lambda )\). In particular, we could use the hierarchy proposed in refs 19,20 to build a series of increasingly stringent membership tests, where the associated Gram matrix G grows bigger in each step and more constraints are generated. More precisely, we define a sequence of hierarchical sets \({\cal S}_1 = \{ E_x^a,E_y^b\}\), \({\cal S}_2 = {\cal S}_1 \cup \{ E_x^aE_{x^\prime }^{a^\prime }\} \cup \{ E_y^bE_{y^\prime }^{b^\prime }\} \cup \{ E_x^aE_y^b\} ,\) where \({\cal S}_k\) is defined inductively as the set of all operator sequences constructed from \(E_x^a,E_y^b\) satisfying \({\cal S}_k \subseteq {\cal S}_{k + 1}\). This corresponds to a sequence of Gram matrices, G1, G2,… with increasing size and constraints. Since the Gram matrix Gk of a particular kth step is at least as informative as a smaller sized Gram matrix Gk′, we conclude that the approximated set \({\cal Q}(\lambda )_k\) is a subset of \({\cal Q}(\lambda )_{k^\prime }\). Therefore, moving up the hierarchy gives a tighter approximation of the quantum set: \({\cal Q}(\lambda ) \subseteq {\cal Q}(\lambda )_k \subseteq {\cal Q}(\lambda )_{k - 1} \ldots\). In the online supplementary material, we prove that this hierarchy is in fact sufficient: it converges to the quantum set, \(lim_{k \to \infty }{\cal Q}(\lambda )_k = {\cal Q}(\lambda )\). Nevertheless, in the applications below, we see that low-level approximations are already enough to achieve very tight bounds.
Applications
Our method can be applied to any quantum communication task that employs the P&M scheme. To illustrate this point, we provide two examples of application: (1) distributed quantum random access coding (QRAC)33,34 and (2) quantum key distribution (QKD).35,36
In the first, we consider a distributed computing task where two random bits z0z1 are encoded into a quantum state \(\left| {\psi _{z_0z_1}} \right\rangle\) and sent to Alice and Bob for selective decoding. For the decoding part, Alice and Bob are each given a random position bit and their goal is to guess the input bit that is associated with the position bit. For example, if Alice receives x = 1, she has to guess the value of z1 via measurement on her share of \(\left| {\psi _{z_0z_1}} \right\rangle\). This task can be seen as a type of distributed quantum database, where network users can choose to learn any entry of the database; this includes the case whereby multiple users can choose to learn the same entry. To this end, we quantify the network’s ability to distribute information by Alice’s and Bob’s guessing probabilities, which we denote by p(a = zx) and p(b = zy), respectively.
At this point, it is useful to recall that if \(\left| {\psi _{z_0z_1}} \right\rangle\) is a two-level quantum system (i.e., a qubit), then the best encoding strategy (in the case of the standard two-party QRAC) is to use the so-called conjugate coding scheme:37 |ψ00〉 = | + 〉, |ψ10〉 = | + i〉, |ψ01〉 = |−i〉, and |ψ11〉 = |−i〉, where |±〉 and |±i〉 are the eigenstates of the Pauli operators \({\Bbb X}\) and \({\Bbb Y}\), respectively. This gives a guessing probability of \(\left( {1 + 1/\sqrt 2 } \right)/2 \approx 0.853\),33,34 which is optimal for qubit code states. Interestingly, using our method, we find that similar bounds can be established using only the Gram matrix information of the code states. In particular, we consider a set of code states {|ψ00〉,|ψ11〉,|ψ10〉,|ψ01〉}, whose Gram matrix is fixed to that of {|+〉,|−〉,|+i〉,|−i〉}, and ask what is Alice’s optimal guessing probability given Bob’s guessing probability is fixed. Our method predicts the following quantum boundary: (2p(a = zx) − 1)2 + (2p(b = zy) − 1)2 ≤ 1/2, which is drawn in Fig. 2. The SDP for this optimisation is given in the supplementary material.

Distributed two-receiver quantum random access coding (QRAC). The boundary is generated using the first level of the semidefinite programming (SDP) hierarchy. In principle, the boundary is not necessarily tight, for \({\cal Q}(\lambda )_1\) may contain correlations that are not of quantum origin. However, in our case we show that the derived boundary is tight: it is saturated by the optimal asymmetric qubit cloning machine. Suppose the quantum code states are given by the conjugate coding scheme: |ψ00〉 = |+〉|0〉,|ψ10〉 = |+i〉|0〉,|ψ01〉 = |−i〉|0〉, and |ψ11〉 = |−〉|0〉. The quantum network is assumed to be an asymmetric cloning channel Uf: |0〉|0〉 → |0〉|0〉 and \(|1\rangle |0\rangle \to \sqrt {1 - f} |1\rangle |0\rangle + \sqrt f |0\rangle |1\rangle\), where f ∈ [0, 1]. For the decoding, we assume that Alice and Bob perform the optimal QRAC qubit measurements: \(E_x^a = ({\Bbb I} + ( - 1)^a({\Bbb X} + ( - 1)^{x + 1}{\Bbb Y})/\sqrt 2 )/2\), \(E_y^b = ({\Bbb I} + ( - 1)^b({\Bbb X} + ( - 1)^{y + 1}{\Bbb Y})/\sqrt 2 )/2\). Using these and setting the left subsystem as Alice’s and the right subsystem as Bob’s, we have that \(p(a = z_x) = 1/2 + \sqrt {(1 - f)/2} /2\) and \(p(b = z_y) = 1/2 + \sqrt {f/2} /2\). These give (2p(a = zx) − 1)2 + (2p(b = zy) − 1)2 = 1/2, which is the quantum boundary predicted by the \({\cal Q}(\lambda )_1\) set
Three remarks are in order here. First, we see that the boundary (obtained from \({\cal Q}(\lambda )_1\)) gives the same upper bound as ref. 33 when one of the receivers is restricted to random guessing. This can be seen as the case in which one party receives \(\left| {\psi _{z_0z_1}} \right\rangle\) with perfect fidelity and the other party receives a dummy state. Second, the boundary specifies a non-trivial trade-off function between Alice’s and Bob’s guessing probabilities, which is independent of their measurement strategies. This implies that the bound is absolute and cannot be improved upon with better measurement strategies, even if Alice and Bob are allowed to use shared randomness. Third, although our method can only provide an outer-approximation of the quantum set, it turns out that the first level of the hierarchy is already tight. More specifically, there is a concrete example, which saturates the boundary predicted by \({\cal Q}(\lambda )_1\); see Fig. 2 for more details. This example is given by the optimal asymmetric qubit cloning machine,38 which optimally splits the qubit information between multiple parties (according to some predefined ratio); this is indeed a natural choice as the goal of the network is to preserve as much quantum information as possible for each party while splitting it.
In the second application, we prove the security of coherent-state QKD. Here, one of the receivers (Alice) is the eavesdropper (renamed to Eve) and her goal is to eavesdrop on the quantum channel connecting the transmitter and the other receiver (Bob). For concreteness, we first consider a phase encoded coherent-state QKD protocol,39 which uses the encoding scheme \(\left| {\psi _{z_0z_1}} \right\rangle :\left| {\psi _{00}} \right\rangle = \left| {\sqrt \mu } \right\rangle ,|\psi _{10}\rangle = \left| { - \sqrt \mu } \right\rangle,|\psi _{01}\rangle = \left| { i \sqrt \mu } \right\rangle\), and \(\left| {\psi _{11}} \right\rangle = \left| { - i\sqrt \mu } \right\rangle\), where μ is the mean photon number of the coherent state. To maximise the sifting efficiency of the protocol, we use \(\left\{ {\left| {\sqrt \mu } \right\rangle ,\left| { - \sqrt \mu } \right\rangle } \right\}\) for key generation and \(\left\{ {\left| {i\sqrt \mu } \right\rangle ,\left| { - i\sqrt \mu } \right\rangle } \right\}\) for testing the security of the channel. Correspondingly on Bob’s side, we have that he uses measurement y = 0 for key recovery and measurement y = 1 for estimating the channel noise; we write ε0 and ε1 to denote the error probabilities observed in the key basis and the test basis, respectively. In this case, the sifting rate of the protocol tends to 1 (in the limit of infinite keys) when the probability of choosing the key basis goes to 1.35
In the supplementary information, we show that the expected secret key rate (per signal sent) is
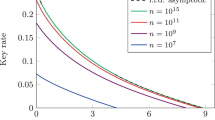
where εph is the so-called phase error rate of the key basis,41 pdet is the probability of detection, and h2(⋅) is the binary entropy function. The quantity of interest here is εph, which is maximised assuming fixed system parameters (e.g., μ, ε0, and ε1). Crucially, εph is a linear function of the matrix G, which allows us to use SDP technique. (For the explicit expression of εph, we refer the interested reader to the supplementary information). Then, we use the second level of the hierarchy \({\cal S}_2\) and maximise εph over the set of compatible probabilities in \({\cal Q}(\lambda )_2\). The outcome of the numerical optimisation is shown in Fig. 3 along with the simulation parameters. To benchmark our results against the best-known security analysis for the protocol, we also plot the security bound of ref. 40 using the same constraints. From the figure, it is evident that our secret key rates are always higher than the ones given by ref. 40. Importantly, this shows that our method significantly improves the security and feasibility of practical QKD, despite making only a few assumptions about the implementation. For completeness, we note that refs 43,44 have also recently proposed a new security proof technique based on SDP (but using a completely different approach). In the case of the current protocol, their simulation outcomes are similar to ours, however, their method additionally requires that Bob’s measurements are fully characterised and an optical squashing model exists for the measurements.45

Phase encoded coherent-state quantum key distribution (QKD). We compare our secret key rate against the one given in ref. 40. For the key rate simulation, we assume a detector dark count rate of pdc = 10−7 and an intrinsic optical error rate of 2%. For a given channel loss 1 − η, the probability of detecting a signal is pdet = 1 − (1 − pdc)2 exp(−2ημ) and the error probability is ε = (pdc + (1 − exp(−2μη))0.02)/pdet. Using these, we maximise the expected secret key rate (2). More precisely, we perform two optimisations. First, for a given μ we maximise the phase error rate over \({\cal Q}(\lambda )_2\) subject to the above constraints. This gives us a lower bound on the achievable secret key rate. Then, we optimise the secret key rate over μ. This gives us an estimate of the optimal secret key rate. Comparing with the secret key rate of ref. 40 (red line), we see that our method predicts a higher secret key rate (blue line) for any loss point. For further comparison, we also plotted the collective beam-splitting attack bound with zero error42 (the top curve: black dashed line), which serves as an upper bound on the achievable secret key rate; note that this bound is not tight and it assumes zero errors
To demonstrate the ability of our method to handle non-standard QKD protocols, we consider the security of a modified coherent-one-way (COW) QKD protocol,46,47 which is based on the transmission of time encoded coherent states {|0〉|α〉,|α〉|0〉,|α〉|α〉} with \(\alpha = \sqrt \mu\). Here, the first two sequences of coherent states carry the secret bit (i.e., ‘0’ →|0〉|α〉 and ‘1’ →|α〉|0〉) and the last sequence is a test state used to estimate Eve’s information about the secret bit. For Bob’s measurements, we use the active switching measurement scheme proposed in ref. 48 instead of the original passive switching scheme.46 In this setup, Bob employs an optical switch to send the incoming states either into the data line or the monitoring line: the former measures the arrival time of the incoming states, whereas the latter measures the coherence (the interference visibility) between two adjacent states. The advantage of this scheme is that it yields higher detection probabilities than the passive scheme. Another major modification is that only the coherence of the test sequence |α〉|α〉 is measured. More specifically, the variant protocol does not measure the coherence between adjacent encodings (e.g., in cases like |0〉|α〉;|α〉|0〉 or |α〉|α〉;|α〉|0〉) like in the original protocol. This modification is largely motivated by earlier research, which showed that knowing the coherence information between adjacent encodings does not significantly improve the security of the protocol.48 Importantly, in discarding these events, we have two benefits. First, the security analysis is greatly simplified, i.e., we only need to analyse a single encoding instead of a sequence of encodings, which can be unwieldy. Second, this opens up the possibility to explore scenarios whereby the mean photon number of the test sequence |α〉|α〉 is optimised. More concretely, we can now adjust the mean photon number of the test sequence to maximise the secret key rate. In the following, we will use |β〉|β〉 to represent the optimised test sequence.
Using the same approach as before (i.e., Eq. (2)), we compute the secret key rate of the variant protocol using a realistic error model that assumes an imperfect intensity modulator (on the transmitter side) and an imbalanced beam-splitter on the receiver side; see the description of Fig. 4 for more details. We first simulate the expected secret key rates of the protocol using the original COW QKD test sequence |β = α〉|β = α〉 with errors (red curve) and without errors (yellow curve). Both of these curves show that secret keys can only be distributed in the low loss regime (i.e., <4 dB loss; or equivalently 20 km of optical fibre length). Comparing with the collective beam-splitting attack curve42 (black dashed curve), we observe that the original COW QKD encoding may be suboptimal. To investigate this possibility, we use the flexibility of our method and further optimise |β〉|β〉 over a discrete set of ratios β/α to search for the best test sequence for a given loss point. We find that the improvement is highly significant. In the case with zero errors, the optimal ratio is β = α/2 and the tolerable loss is extended to >35 dB, which spells a ≥30 dB improvement over the original COW QKD encoding. The secret key rates (green curve) are also significantly higher and are close to the collective beam-splitting attack bound (in the low loss regime). In the case with errors, we also see similar improvements. More concretely, the optimised variant protocol is now able to distribute secret keys up to about 21 dB loss with errors, which translates to a fibre distance of about 110 km. In conclusion, our findings strongly indicate that it is much more secure to vary the mean photon number of the test sequence.

Time encoded coherent-state quantum key distribution (QKD). For this simulation, we consider an error model that is based on imperfect intensity modulation and imperfect mixing of coherent states. On the transmitter’s side, we assume that the intensity modulator used to perform the on-off keying has finite extinction ratio, i.e., states are prepared as \(\left| {\sqrt {1 - \delta } \alpha } \right\rangle\) and \(\left| {\sqrt \delta \alpha } \right\rangle\) instead of |α〉 and \(\left| 0 \right\rangle\). Here, we use δ = 0.01. On the receiver side, we assume that the beam-splitter in the measurement scheme of ref. 48 has a ratio of 51/49 instead of the ideal 50/50. Using these component models and assuming that each detector has a dark count rate of pdc = 10−7, we run the optimisation as per the previous QKD application and obtain four sets of data points using the original coherent-one-way (COW) QKD encoding and a new encoding strategy where the test sequence is optimised. For each of these, we compute the secret key rates with and without errors
Discussion
Taken together, our findings thus provide a powerful method to analyse the quantum set of any discretely modulated P&M quantum network, independently of how the network and decoding measurements are implemented. From the perspective of quantum information theory, the toolbox can help to reveal the fundamental limits of quantum communication and to analyse the performance of any quantum coding scheme. On the application side, the toolbox can be used to analyse the performance of quantum network protocols and the security of quantum cryptography, as evidenced by the three examples given above. Concerning the latter, it would be interesting to investigate how the toolbox could be utilised to solve other open problems in quantum cryptography, e.g., the security of round-robin differential phase-shift QKD49 or continuous variable QKD protocols with discrete modulations.50 Another interesting direction would be to extend the method to multiple transmitters like in the case of measurement-device-independent quantum cryptography.51,52,53,54,55,56 For instance, it would be interesting to see how our method can be used to analyse the security of phase-matching QKD,56 which can break the fundamental distance limit of QKD using coherent states.
Data availability
The data sets generated during the current study are available from the corresponding author upon request.
References
Horodecki, R., Horodecki, P., Horodecki, M. & Horodecki, K. Quantum entanglement. Rev. Mod. Phys. 81, 865–942 (2009).
Bell, J. S. On the Einstein-Podolsky-Rosen paradox. Physics 1, 195–200 (1964).
Wiseman, H. M., Jones, S. J. & Doherty, A. C. Steering, entanglement, nonlocality, and the Einstein-Podolsky-Rosen Paradox. Phys. Rev. Lett. 98, 140402 (2007).
Gisin, N. & Thew, R. Quantum communication. Nat. Photonics 1, 165–171 (2007).
Gisin, N., Ribordy, G., Tittel, W. & Zbinden, H. Quantum cryptography. Rev. Mod. Phys. 74, 145–195 (2002).
Yard, J., Hayden, P. & Devetak, I. Quantum broadcast channels. IEEE Trans. Inf. Theory 57, 7147–7162 (2011).
Hirche, C. & Morgan, C. An improved rate region for the classical-quantum broadcast channel. 2015 IEEE Int. Symposium Inform Theory (ISIT) https://doi.org/10.1109/ISIT.2015.7282963 (2015).
Savov, I. & Wilde, M. M. Classical codes for quantum broadcast channels. IEEE Trans. Inf. Theory 61, 7017–7028 (2015).
Wootters, W. K. & Zurek, W. H. A single quantum cannot be cloned. Nature 299, 802–803 (1982).
Fuchs, C. A. & Peres, A. Quantum-state disturbance versus information gain: uncertainty relations for quantum information. Phys. Rev. A 53, 2038 (1996).
Horodecki, M., Horodecki, R., Sen (De), A. & Sen, U. Common origin of no-cloning and no-deleting principles - conservation of information. Found. Phys. 35, 2041–2049 (2005).
Holevo, A. S. Statistical decision theory for quantum systems. J. Multivar. Anal. 3, 337–394 (1973).
Barnum, H., Caves, C. M., Fuchs, C. A., Jozsa, R. & Schumacher, B. Noncommuting mixed states cannot be broadcast. Phys. Rev. Lett. 76, 2818–2821 (1996).
Barnum, H., Barrett, J., Leifer, M. & Wilce, A. Generalized no-broadcasting theorem. Phys. Rev. Lett. 99, 240501 (2007).
Brunner, N., Cavalcanti, D., Pironio, S., Scarani, V. & Wehner, S. Bell nonlocality. Rev. Mod. Phys. 86, 419–478 (2014).
Tsirel’son, B. S. Quantum analogues of the Bell inequalities. The case of two spatially separated domains. J. Sov. Math. 36, 557–570 (1987).
Landau, L. J. Empirical two-point correlation functions. Found. Phys. 18, 449–460 (1988).
Wehner, S. Tsirelson bounds for generalized Clauser-Horne-Shimony-Holt inequalities. Phys. Rev. A 73, 022110 (2006).
Navascués, M., Pironio, S. & Acín, A. Bounding the set of quantum correlations. Phys. Rev. Lett. 98, 010401 (2007).
Navascués, M., Pironio, S. & Acín, A. A convergent hierarchy of semidefinite programs characterizing the set of quantum correlations. New J. Phys. 10, 073013 (2008).
Pawłowski, M. & Brunner, N. Semi-device-independent security of one-way quantum key distribution. Phys. Rev. A 84, 010300(R) (2011).
Bowles, J., Quintino, M. T. & Brunner, N. Certifying the dimension of classical and quantum systems in a prepare-and-measure scenario with independent devices. Phys. Rev. Lett. 112, 140407 (2014).
Lunghi, T. et al. Self-testing quantum random number generator. Phys. Rev. Lett. 114, 150501 (2015).
Woodhead, E. & Pironio, S. Secrecy in prepare-and-measure Clauser-Horne-Shimony-Holt tests with a qubit bound. Phys. Rev. Lett. 115, 150501 (2015).
Berta, M., Fawzi, O. & Scholz, V. B. Quantum bilinear optimization. SIAM J. Optim. 26, 1529–1564 (2016).
Himbeeck, T. V., Woodhead, E., Cerf, N. J., García-Patrón, R. & Pironio, S. Semi-device-independent framework based on natural physical assumptions. Quantum 1, 33 (2017).
Brask, J. B. et al. Megahertz-rate semi-device-independent quantum random number generators based on unambiguous state discrimination. Phys. Rev. Appl. 7, 054018 (2017).
Arrazola, J. M. & Lütkenhaus, N. Quantum communication with coherent states and linear optics. Phys. Rev. A 90, 042335 (2014).
Wilde, M. M. Quantum Information Theory. (Cambridge Univ. Press, New York, 2013).
Horn, R. A. & Johnson, C. R. Matrix Analysis: Characterizations and Properties CH.7. (Cambridge Univ. Press, Cambridge, 2013).
Vandenberghe, L. & Boyd, S. Semidefinite programming. SIAM Rev. 38, 49–95 (1996).
Burgdorf, S., Klep, I. & Povh, J. Optimisation of Polynomials in Non-Commutative Variables. (Springer, Switzerland, 2016).
Ambainis, A., Nayak, A., Ta-Shma, A. & Vazirani, U. Dense quantum coding and a lower bound for 1-way quantum automata. Proceedings of the thirty-first annual ACM symposium on Theory of computing–STOC 99 (Atlanta, Georgia, USA, 1999).
Nayak, A. Optimal lower bounds for quantum automata and random access codes. 40th Annual Symposium on Foundations of Computer Science (Cat. No.99CB37039) 369 (1999).
Scarani, V. et al. The security of practical quantum key distribution. Rev. Mod. Phys. 81, 1301–1350 (2009).
Lo, H. K., Curty, M. & Tamaki, K. Secure quantum key distribution. Nat. Photonics 8, 595–604 (2014).
Wiesner, S. Conjugate coding. ACM SIGACT News 15, 78–88 (1983).
Cerf, N. J. Asymmetric quantum cloning in any dimension. J. Mod. Opt. 47, 187 (2000).
Huttner, B., Imoto, N., Gisin, N. & Mor, T. Quantum cryptography with coherent states. Phys. Rev. A 51, 1863–1869 (1995).
Lo, H. K. & Preskill, J. Security of quantum key distribution using weak coherent states with nonrandom phases. Quant. Inf. Comput. 8, 431–458 (2007).
Shor, P. W. & Preskill, J. Simple proof of security of the BB84 quantum key distribution protocol. Phys. Rev. Lett. 85, 441–444 (2000).
Branciard, C., Gisin, N., Lütkenhaus, N. & Scarani, V. Zero-error attacks and detection statistics in the coherent one-way protocol for quantum cryptography. Quant. Inf. Comput. 7, 639–664 (2007).
Winick, A., Lütkenhaus, N. & Coles, P. J. Reliable numerical key rates for quantum key distribution. Quantum 2, 77 (2018).
Coles, P. J., Metodiev, E. M. & Lütkenhaus, N. Numerical approach for unstructured quantum key distribution. Nat. Commun. 7, 11712 (2016).
Beaudry, N. J., Moroder, T. & Lütkenhaus, N. Squashing models for optical measurements in quantum communication. Phys. Rev. Lett. 101, 093601 (2008).
Stucki, D., Brunner, N., Gisin, N., Scarani, V. & Zbinden, H. Fast and simple one-way quantum key distribution. Appl. Phys. Lett. 87, 194108 (2005).
Korzh, B. et al. Provably secure and practical quantum key distribution over 307 km of optical fibre. Nat. Photonics 9, 163–168 (2015).
Moroder, T. et al. Security of distributed-phase-reference quantum key distribution. Phys. Rev. Lett. 109, 260501 (2012).
Sasaki, T., Yamamoto, Y. & Koashi, M. Practical quantum key distribution protocol without monitoring signal disturbance. Nature 509, 475–478 (2014).
Leverrier, A. & Grangier, P. Unconditional security proof of long-distance continuous-variable quantum key distribution with discrete modulation. Phys. Rev. Lett. 102, 180504 (2009).
Braunstein, S. & Pirandola, S. Side-channel-free quantum key distribution. Phys. Rev. Lett. 108, 130502 (2012).
Lo, H. K., Curty, M. & Qi, B. Measurement-device-independent quantum key distribution. Phys. Rev. Lett. 108, 130503 (2012).
Tamaki, K., Lo, H. K., Fung, F. & Qi, B. Phase encoding schemes for measurement-device-independent quantum key distribution with basis-dependent flaw. Phys. Rev. A. 85, 042307 (2012).
Ma, X. & Razavi, M. Alternative schemes for measurement-device-independent quantum key distribution. Phys. Rev. A. 86, 062319 (2012).
Lucamarini, M., Yuan, Z. L., Dynes, J. F. & Shields, A. J. Overcoming the rate-distance limit of quantum key distribution without quantum repeaters. Nature 557, 400–403 (2018).
Ma, X., Zheng, P. & Zhou, H. Phase-matching quantum key distribution. Phys. Rev. X. 8, 031043 (2018).
Acknowledgements
We acknowledge support from the National University of Singapore, the Centre for Quantum Technologies, the National Research Foundation, and the Asian Office of Aerospace Research and Development.
Author information
Authors and Affiliations
Contributions
C.C.W.L. conceived the main idea of the method with inputs from all authors and supervised the project. Y.W., I.W.P, and E.L. performed the optimisation and simulations. C.C.W.L., A.V., and Y.W provided the technical derivations needed to prove the main results. The paper was written by all authors.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wang, Y., Primaatmaja, I.W., Lavie, E. et al. Characterising the correlations of prepare-and-measure quantum networks. npj Quantum Inf 5, 17 (2019). https://doi.org/10.1038/s41534-019-0133-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41534-019-0133-3
This article is cited by
-
Provably-secure quantum randomness expansion with uncharacterised homodyne detection
Nature Communications (2023)
-
Computing secure key rates for quantum cryptography with untrusted devices
npj Quantum Information (2021)
-
Numerical finite-key analysis of quantum key distribution
npj Quantum Information (2020)
-
Quantum key distribution with flawed and leaky sources
npj Quantum Information (2019)
