
Abstract
The problem of establishing a fair bet between spatially separated gambler and casino can only be solved in the classical regime by relying on a trusted third party. By combining Nash-equilibrium theory with quantum game theory, we show that a secure, remote, two-party game can be played using a quantum gambling machine which has no classical counterpart. Specifically, by modifying the Nash-equilibrium point we can construct games with arbitrary amount of bias, including a game that is demonstrably fair to both parties. We also report a proof-of-principle experimental demonstration using linear optics.
Similar content being viewed by others
Introduction
Gambling is a game where people wager of money or something valuable on an event with an uncertain outcome (such as raffle). It has a wide range of applications in every aspects of human society.1,2,3,4,5,6,7 However, despite its long history and wide spread usages, it has a long standing problem yet to be resolved. Suppose a gambler (say Bob) wants to gamble with the casino (say Alice), how does Bob knows that the gambling machine (GM) provided by Alice is not biased towards Alice herself, especially in the case of online gambling or lotteries?
The standard solution to this problem is to introduce a trusted third party to provide an unbiased GM to make sure the gambling is fair to both parties. However, in some cases such third party which is trusted by both parties does not exist. There are several quantum gambling protocols to address this problem since 1999. The first one was put forward by Goldenberg et al.,8 which was experimentally demonstrated in 2008.9 Hwang et al. improved this original scheme using nonorthogonal states.10, 11 However these quantum gambling protocols are impractical all biased to casino, and the fairness remains hard to implement.
Surprisingly, by drawing from the classical12 and quantum game theory,13, 14 we have found a protocol which enables two parties to create an unbiased GM themselves to perform a fair gambling without introducing any third party. The GM, which has two independent parameters, is constructed by Alice and Bob together who can change the values of the two parameters respectively. Furthermore, the GM is elaborately designed in a way that a Nash-equilibrium15 exists—each party has a strategy to choose his/her parameter which can guarantee his/her gain is no less than a certain amount and neither of the two parties can benefit from changing his/her own parameter unilaterally. In this way, Alice and Bob are ‘forced’ to choose the Nash-equilibrium in their own favor so that a stable GM can be established.
Results
The rules of the game
Alice has two quantum boxes, named A and B, which are used to store a particle. The quantum states of the particle stored in the two boxes are denoted |a〉 and |b〉, respectively. Alice prepares the particle in a state and then sends the box B to Bob. Bob wins R coins (R > 0) in one of the following two cases: (1) Bob opens the box B and finds the particle. (2) Bob does not find the particle in box B and asks Alice to send him the box A. Bob then detects the state Alice prepared is different from the committed state |ψ c 〉, where |ψ c 〉 =\(\sqrt {\left( {1 - \gamma } \right)} \left| a \right\rangle + \sqrt \gamma \left| b \right\rangle \). In any other cases, Alice wins one coin.
Alice’s strategy
Alice prepares the particle in the following state
where α is a parameter controlled by Alice (0 ≤ α ≤ 1).
Bob’s strategy
After receiving the box B, Bob splits the box into two parts. One part is still called box B and the other part is a new box called B′. Specifically, the state |b〉 is changed into
where |b′〉 denotes the quantum state of the particle stored in the box B′. The splitting ratio β is a parameter controlled by Bob (0 ≤ β ≤ 1). After the splitting, Bob opens the box B and projects the state to |b〉〈b|. If he finds the particle in the box B, he wins. If he doesn’t, he asks Alice for the box A and combines it with the box B′ to make a verification. If the verification shows the initial state Alice prepared is different from the committed state |ψ c 〉, Bob still wins; otherwise, Alice wins. Here the quantum superposition states and projection measurement are essential to our protocol.
Let us briefly analyze the protocol and both players’ strategies. For Alice, she has a motivation to prepare a state that the particle has a higher chance to stay in box A (choosing a small α), so that Bob has a lower chance to find the particle in box B. However, if α is too small, the discrepancy between the prepared and the committed state would be too big, which will result in a higher chance for Alice to lose in the verification stage—there is a tradeoff for Alice to choose her strategy (parameter α). Similar analysis can apply to Bob’s strategy as well. Bob cannot rely solely on the |b〉 projection stage (choosing a small β) or the verification stage (choosing a big β). He needs to consider both stages and chooses an intermediate β to maximize his chance to win. By now, the analysis is just qualitative, we will give the rigorous proof in the following.
Proof for both honest parties
The most important and fundamental case is that both Alice and Bob obey the rules without any cheating. The other cases for dishonest Alice or Bob could be derived from this and will be addressed in the Discussion section. For both honest parties, we have found that there exists the best strategies for both of them. The average gain of Alice (Bob) G a (G b) will never be less than an amount once she (he) chooses the optimal α (β), and G a + G b = 0 holds the gambling as a zero-sum game.
To prove the above claims and features of the protocol, let us write down the expression for G b first (for it is a zero-sum game, G a = −G b, without loss of generality, we can only calculate Bob’s average gain G b),
where P 1 denotes the probability for Bob to find the particle in box B, P 2 (P 3) denotes the probability of finding the initial state is different (can not be proven different) with committed state, and P 1 + P 2 + P 3 = 1. When Bob receives the box B and splits one part to the box B′, the state becomes
From Eq. (4), it is straightforward to calculate the probability of finding the particle in box B,
The state of the particle will collapse to \(\left| {\psi _0^{\prime}} \right\rangle \) if Bob fails to detect the particle in box B, where
If Alice did prepare the particle in the committed state |ψ c 〉 initially, the state at this stage will be \(\left| {\psi _c^{\prime}} \right\rangle \)
Bob then makes a projection measurement on \(\left| {\psi _c^{\prime}} \right\rangle \) for the verification. The probability of getting positive outcome is given by
By using P 1 + P 2 + P 3 = 1 and substituting Eqs. (5) and (8) into Eq. (3), we can get G b is a function in the form of four parameters: α, β, γ and R:
In order to find the best strategy for Bob, we should first minimize G b for any α and then maximize the result for β. This means that no matter what strategy Alice chooses, Bob can ensure his gain is no less than a value δ. Meanwhile, Alice’s gain should be no more than −δ. So δ can be regarded as the Nash-equibrilium value. Similarly, to find the best strategy for Alice, we should first maximize G b for any β and then minimize the result for α. The calculation yields that there is a Nash-equibrilium at
From Eq. (10), we can know how to choose the parameter of conventional state:
Equations (10), (11), (12), and (13) are the results for general quantum gambling.
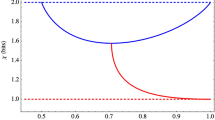
Taking a fair game (δ = 0) for instance, if we set R = 1, then we can get the committed state (\(\gamma = \frac{8}{9}\)), the optimal parameters \(\alpha = \frac{1}{3}\) and \(\beta = \frac{1}{4}\). As shown in Fig. 1a, the function of G b(α,β) is saddle-shaped and the saddle point matches our calculation results. Figure 1b, c is the projection of the G b function to the α − G a plane and β − G b plane, respectively. From (Fig. 1b, c), it is clear that, no matter what strategy Bob (Alice) chooses, Alice’s (Bob’s) gain will always be non-negative if she (he) sets her (his) parameter to be \(\frac{1}{3}\,\left( {\frac{1}{4}} \right)\). Any party changing his/her strategy unilaterally will only decrease his/her own gain. In this way, Nash-equilibrium is achieved and both parties will stick their strategy, thus a stable and fair game is achieved.

Theoretical and experimental results of our protocol under R = 1 and γ = 8/9. a Bob’s average gain in a three dimensional view and contour view. The Nash-equilibrium is the point of G b = 0, β = 1/4 and α = 1/3. The lines in contour view show G b = 0. b Alice’s gain under her parameter α no matter which strategy Bob chooses. Lines and circles with different colors show the theoretical and experimental gain of Alice under different β, respectively. Her best choice is α = 1/3. c Bob’s gain under his parameter β no matter which strategy Alice chooses. Lines and circles with different colors show the theoretical and experimental gain of Bob under different α, respectively. The best strategy is choosing β = 1/4
In practice, there are much more diverse gambling protocols, such as roulette and lottery, where the expectation value of the gains is non-zero. This can be easily achieved by setting appropriate parameters guided by Eq. (10). So we can say that our protocol can be generalized to the full family of quantum gambling.
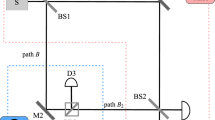
Besides proposing the theory, we also implemented a proof-of-principle experiment (as shown in Fig. 2) to demonstrate our gambling protocol. In our experiment, we simulated a fair GM, where R and γ were set to be 1 and \(\frac{8}{9}\), respectively. Both Alice and Bob chose a series of strategies and the final gains for both parties were measured and recorded. The results are shown in Fig. 1b, c including the error bars. The deviation between experimental results (circle dots) and theoretical predictions (lines) mainly comes from imperfection of components used in the setup and statistic errors of measurement. From the results, we can clearly see that the best gain Alice and Bob can get is 0 when they choose the strategies \(a = \frac{1}{3}\) and \(\beta = \frac{1}{4}\), respectively. For their own good, Alice and Bob would both choose their best strategies and thus a Nash-equilibrium is formed and a fair gamble is achieved.

Experimental demonstration of quantum gambling. Two 1-mm thick β-barium borate crystals (BBO1 and BBO2) located side by side and the BBO2 is rotated 180° around the pump direction, so the photon pairs generated are in polarization state |H〉|V〉 for BBO1 and in |V〉|H〉 for BBO2. HWP indicates the half-wave-plate and PBS is the acronym for polarized beam splitter, which transmits horizontally polarized light and reflects vertically polarized light. HWP1 and PBS1 are used to project the state of idle photon into \(\sqrt {1 - a} \left| H \right\rangle - \sqrt a \left| V \right\rangle \), thus the signal photon will be prepared in the form of Eq. (1). So the parameter α can be controlled with rotating HWP1 by Alice. Two calcite beam displacers (BD1 and BD2) construct a polarization interferometer, which is instinct stable. HWP2 at 45° swaps the polarization and HWP3 realizes the parameter γ for Bob. HWP4 and PBS2 are used to check the state to be committed state or not. The three probabilities P 1, P 2, and P 3 are gotten from the coincident counts of D1&D2, D1&D3, and D1&D4, respectively, where D represents the single-photon detector
In summary, we have invented a protocol which can promise an unbiased GM to each party by using quantum gambling theory and Nash-equilibrium. Furthermore, the choice of parameter values is flexible, and we have found the relationship between these adjustable parameters, which can be used to guide a feasible implementation of full family of quantum gambling, including both biased and unbiased cases. This proof-of-principle experiment therefore provides solid support for the applicability and feasibility of our scheme. In a world full of competitions and cooperations, we believe our protocol of GM without a third party will provide direct applications in the near future, and also shed light on developing new quantum technologies.
Discussion
Let us now consider the scenario of cheating. In our protocol, the GM is provided by the casino Alice, however the claim is made by player Bob, so they both have chance to cheat to maximize their gain.
For dishonest Alice, she could prepare any state rather than |ψ〉. The most general state is
where |Φ a 〉, |Φ b 〉, and \(\left| {{\Phi _{{c_i}}}} \right\rangle \) are the ancillary states and \({\left| {\tilde \alpha } \right|^2} + {\left| {\tilde \beta } \right|^2} + \mathop {\sum}\nolimits_i {{{\left| {{{\tilde \gamma }_i}} \right|}^2}} = 1\). If Alice only applies unitary operation \({\cal U}\) to the ancillary states after Bob asks for the box A, she gets no advantage using ancilla because Bob checks the conventional state which is only associated on the first particle. This can be proven as following. After Bob splits box B, the state changes into
So the probability to find particle in box B is
If Bob does not find |b〉, and Alice applies a unitary operation \({\cal U}\) on the second particle, then the state changes to
where N is the normalized factor with \(N = {\left[ {1 - \left( {1 - \beta } \right){{\left| {\tilde \beta } \right|}^2}} \right]^{ - \frac{1}{2}}}\). However for Bob, he will project |Ψ2〉 on state |ψ c′〉 in Eq. (7) to check whether Alice prepared |ψ c 〉 or not. So the probability to win for Bob at the final step is
where \(\mu = \sqrt {\frac{{1 - \gamma }}{{1 - \gamma + \beta \gamma }}} \tilde \alpha \) and \(\nu = \sqrt {\frac{\gamma }{{1 - \gamma + \beta \gamma }}} \beta \tilde \beta \).
For Alice, she tries to minimize both P′1 and P′2 by using ancillary particle and boxes. However, from Eq. (16), we know P′1 has no relation to the ancilla. From Eq. (18), |〈Φ a |Φ b 〉| = 1 is one condition of minimizing P′2, the other condition is that N 2|μ + ν|2 gets the maximum value. Because Alice can not change γ and β, the way for her to maximize N 2|μ + ν|2 is to set all \({\tilde \gamma _i} = 0\) and the coefficients \(\tilde \alpha \) and \(\tilde \beta \) to be real positive numbers, as \({\left| {\tilde \alpha } \right|^2} + {\left| {\tilde \beta } \right|^2} = 1 - \mathop {\sum}\nolimits_i {{{\left| {{{\tilde \gamma }_i}} \right|}^2}} \). Thus we get that there is no advantage for Alice to prepare a state with ancillary particle and box.
However, when Alice gets the information that Bob does not find the particle in box B, she may do some measurements to box A trying to increase the probability of Bob finding the rest of state to be the committed state. We have given a complete proof to show there is still no advantage for these cheating strategies in the Appendix A of the Supplementary Materials, and here we just show a simple analysis. For Alice, she may modify box A to make the rest of state be committed state when she knows that the particle is not in box B. The most general way to achieve this modification is doing a weak measurement on box A (this equals to splitting |a〉 to \(\sqrt {1 - \theta } \left| a \right\rangle + \sqrt \theta \left| {a'} \right\rangle \), and open box A′). However, this measurement may make the particle collapse to the measured part (box A′), then Bob will catch Alice cheating after he finds none of the detectors clicks. In such case, Alice has to send a new particle in state |a〉 to Bob as not to be caught. Obviously, successfully manipulating box A will increase Alice’s gain but failure then resending a particle in state |a〉 will decrease her gain. This tradeoff therefore leads no advantage for Alice to cheat and guarantees the GM to be fair without any third party.
In this protocol, because the verification result is claimed by Bob, so Bob may lie to Alice to maximize his gain. For dishonest Bob, he can claim that he has detected the particle in box B, even though B is in fact empty. This cheating strategy can be unambiguously detected by Alice by simply verifying the box A. In another cheating strategy, Bob lies about the verification result, claiming that the initial state is different to committed state even though it is not. This cheating can also be exposed by Alice if she prepared the committed state |ψ c 〉. To restrain or even eliminate Bob lying, we can set a parameter R′ to punish Bob lying. In a more elaborated application where many random bits are needed it would be easy to detect the cheating. We may set the G a slightly greater than zero (δ < 0) on the Nash-equilibrium (this can be achieved by choosing proper parameters γ and R), in which case Alice can occasionally prepare state |ψ c 〉 with probability x to detect whether Bob is cheating or not (suppose Bob lies with probability y). We will see the probabilities x and y are restrained by δ and the price of cheating being caught R′ in Appendix B of the Supplementary Materials. Especially x → 0 and y → 0 will be achieved when R′ → ∞, which indicates that Bob has no motivation to lie.
We should mention that our proposal is inspired with the pioneer work of quantum gambling.8 In ref. 8, the critical problem is that the protocol is not realistic. In their protocol, if Alice follows the protocol to prepare the equally distributed state, Bob’s best strategy would be directly opening the box without splitting it, because Bob never wins R under this situation. On the other hand, if Bob follows the protocol to do an optimal splitting, Alice’s best strategy will be definitely not to prepare the equally distributed state (the best strategy for Alice was not discussed in ref. 8). As a result, their protocol is unstable and neither Alice nor Bob will follow it. Furthermore, the fair game is impossible to be achieved—it needs to set parameter R → ∞, and even larger R is hard to be experimentally implemented (a 98% visibility is needed to set R = 27.1 in ref. 9). In our proposal, by introducing the Nash-equilibrium, both the casino and the player will follow their best strategies, and the equilibrium point can be set freely by tuning the parameters. As a result, our method can be used to construct a full family of quantum gambling protocols.
Methods
In our experiment, the pump laser is a mode-locked Ti:sapphire laser (duration of 140 fs, repetition rate of 76 MHz, and central wavelength of 780 nm) with a frequency doubler. A beam-like polarization entangled two-photon source16 is introduced to generate Bell state \(\psi \, = \,\frac{1}{{\sqrt 2 }}\left( {\left| {\it{H}} \right\rangle \left| V \right\rangle - \left| V \right\rangle \left| H \right\rangle } \right)\) with fidelity of 0.97. The coincidence rate is 30,000 s−1 with 100 mW pump power. The two polarization states |V〉 and |H〉 of signal photon are encoded as the two box states |a〉 and |b〉, respectively. Then Alice can prepare the required input state \(\left|\psi \right\rangle = \sqrt {1 - \alpha } \left| V \right\rangle + \sqrt \alpha \left| H \right\rangle \) in signal photon by projecting the idle photon into state \(\sqrt {1 - \alpha } \left| H \right\rangle - \sqrt \alpha \left| V \right\rangle \) with a half wave plate (HWP1) and a polarized beam splitter (PBS1). The calcite beam displacer (BD1) transmits |H〉 state and refracts |V〉 state, and HWP2 at 45° swaps the polarization for the interferometer. Bob uses HWP3 and BD2 to split the box |b〉 to |b〉 and |b′〉, and measures P 1 at the single-photon detector (D2). Then |b′〉 and |a〉 are combined at BD2 for verification. HWP4 and PBS2 are used for the projective measurement, that is, HWP4 rotates the state \(\left| {\psi _c^{\prime}} \right\rangle = \sqrt {\frac{1}{{1 + 8\beta }}} \left| V \right\rangle + \sqrt {\frac{{8\beta }}{{1 + 8\beta }}} \left| H \right\rangle \) to |H〉, and PBS2 guides |H〉 to D4 and |H〉 to D3. So P 2 and P 3 can be measured from D3 and D4, respectively. The gains for Alice and Bob can be calculated by \({G_{\rm{a}}} = \frac{{{C_D}_4}}{{{C_D}_2 + {C_D}_3 + {C_D}_4}}\) and \({G_{\rm{b}}} = \frac{{{C_D}_2 + {C_D}_3}}{{{C_D}_2 + {C_D}_3 + {C_D}_4}}\), respectively, where C Di represents the coincidence count of D1 and Di, i = 2,3,4.
In the experimental setup, Alice’s action should depend on Bob’s first declaration, so there should be a time delay or a quantum register for Alice before sending the box A to Bob. However, for the proof-of-principle experiment, we just simplified this and detected the results simultaneously.
The sensitivity to error of our protocol depends on the reward R. Considering a fair GM, from Eq. (3) we know that if R ≫ 1, the error in P 1 and P 2 will be linearly amplified by factor R; if R ≪ 1, the error in P 3 will be linearly amplified by factor 1/R. So in the practical implementation of GM, although R can be chosen freely, we recommend to set value of R around 1.
References
Myerson, R. B. Game Theory: An Analysis of Conflict (MIT Press, 1991).
Walker, M. B. The psychology of gambling (Pergamon Press, 1992).
Rasmusen, E. Games and Information (Blackwell, 1995).
Turner, P. E. & Chao, L. Prisoner’s dilemma in an RNA virus. Nature 398, 441–443 (1999).
Chen, K.-Y. & Hogg, T. How well do people play a quantum prisonerÕs dilemma? Quant. Inf. Process 5, 43–67 (2006).
Hogg, T., Harsha, P. & Chen, K.-Y. Quantum auctions. Int. J. Quant. Inf. 5, 751–780 (2007).
Guo, H., Zhang, J. H. & Koehler, G. J. A survey of quantum games. Decis. Support Syst. 46, 318–332 (2008).
Goldenberg, L., Vaidman, L. & Wiesner, S. Quantum gambling. Phys. Rev. Lett. 82, 3356 (1999).
Zhang, P. et al. Optical realization of quantum gambling machine. Europhys. Lett. 82, 30002 (2008).
Hwang, W. Y., Ahn, D. & Hwang, S. W. Quantum gambling using two nonorthogonal states. Phys. Rev. A 64, 064302 (2001).
Hwang, W. Y. & Matsumoto, K. Quantum gambling using three nonorthogonal states. Phys. Rev. A 66, 052311 (2002).
Nash, J. F. Essays on game theory (Edward Elgar, 1996).
Meyer, D. A. Quantum strategies. Phys. Rev. Lett. 82, 1052 (1999).
Eisert, J., Wilkens, M. & Lewenstein, M. Quantum games and quantum strategies. Phys. Rev. Lett. 83, 3077 (1999).
Nash, J. F. Equilibrium points in n-person games. Proc. Natl. Acad. Sci. USA 36, 48–49 (1950).
Niu, X.-L. et al. Beamlike high-brightness source of polarization-entangled photon pairs. Opt. Lett. 33, 968 (2008).
Acknowledgements
We thank Dr. Wei-Dong Tang for useful discussion and acknowledge the financial support given by the Fundamental Research Funds for the Central Universities, National Natural Science Foundation of China (Grant Nos. 11374008, 11534008, 11074198, 11534008 and 60778021), EPSRC, ERC, QUANTIP, PHORBITECH, and NSQI. J.L.O.B. acknowledges a Royal Society Wolfson Merit Award and a Royal Academy of Engineering Chair in Emerging Technologies.
Author information
Authors and Affiliations
Contributions
P.Z. and X.Q.Z. proposed the study and wrote the manuscript. P.Z. and B.H.L. performed the experiment. Y.L.W., P.S. and Y.S.Z. analyzed the results. H.G., F.L.L. and J.L.O. supervised the project and edited the manuscript. All authors discussed the results and commented on the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare that they have no competing financial interests.
Electronic supplementary material
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhang, P., Zhou, XQ., Wang, YL. et al. Quantum gambling based on Nash-equilibrium. npj Quantum Inf 3, 24 (2017). https://doi.org/10.1038/s41534-017-0021-7
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41534-017-0021-7
This article is cited by
-
Conditions that enable a player to surely win in sequential quantum games
Quantum Information Processing (2022)
-
Quantum games: a review of the history, current state, and interpretation
Quantum Information Processing (2018)
