
Abstract
The epidemiology of infectious causes of meningitis in sub-Saharan Africa is not well understood, and a common cause of meningitis in this region, Mycobacterium tuberculosis (TB), is notoriously hard to diagnose. Here we show that integrating cerebrospinal fluid (CSF) metagenomic next-generation sequencing (mNGS) with a host gene expression-based machine learning classifier (MLC) enhances diagnostic accuracy for TB meningitis (TBM) and its mimics. 368 HIV-infected Ugandan adults with subacute meningitis were prospectively enrolled. Total RNA and DNA CSF mNGS libraries were sequenced to identify meningitis pathogens. In parallel, a CSF host transcriptomic MLC to distinguish between TBM and other infections was trained and then evaluated in a blinded fashion on an independent dataset. mNGS identifies an array of infectious TBM mimics (and co-infections), including emerging, treatable, and vaccine-preventable pathogens including Wesselsbron virus, Toxoplasma gondii, Streptococcus pneumoniae, Nocardia brasiliensis, measles virus and cytomegalovirus. By leveraging the specificity of mNGS and the sensitivity of an MLC created from CSF host transcriptomes, the combined assay has high sensitivity (88.9%) and specificity (86.7%) for the detection of TBM and its many mimics. Furthermore, we achieve comparable combined assay performance at sequencing depths more amenable to performing diagnostic mNGS in low resource settings.
Similar content being viewed by others


Introduction
Mycobacterium tuberculosis (TB) affects 10 million (8.9–11 million) people worldwide and carries devastating consequences, including ~1.2 million deaths in 2019 alone. With significant public health resources required for the COVID-19 pandemic, the global TB burden will likely only increase in the coming years1,2. Meningitis is the most severe complication of TB, carrying a 50–60% mortality rate in persons living with HIV3. The diagnosis of TB meningitis (TBM) is notoriously difficult yet essential, as early and appropriate treatment is critical to prevent significant morbidity and mortality4. Due to the paucibacillary nature of TB infection in the central nervous system (CNS), culture and nucleic acid detection (e.g., TB PCR) are insensitive diagnostic tools4,5,6,7 compared to the TBM Uniform Case Definition (UCD), which was created to standardize research studies8. However, the clinical, radiological, and laboratory criteria that comprise the UCD lack specificity9. Thus, there is a double-edged problem of patients with delayed or missed diagnoses of TBM due to the inadequate sensitivity of available diagnostic tests as well as patients inappropriately diagnosed and empirically treated for TBM based on nonspecific clinical, laboratory, and radiologic criteria who have other infectious (and non-infectious) causes of meningitis10,11,12.
Metagenomic next-generation sequencing (mNGS) is a validated diagnostic assay for neuroinfectious diseases that can test for a wide variety of infections by amplifying all the genetic material (host and pathogen) from a cerebrospinal fluid (CSF) sample13. We and others have published case reports and case series demonstrating that CSF mNGS can diagnose TBM (and other infections that can clinically mimic TBM). These studies suggest that mNGS is specific but only moderately sensitive for detecting the small amounts of TB nucleic acid in the CSF of patients with TBM10,11,14,15,16. Here, we investigated the clinical utility of CSF mNGS in a large population of prospectively enrolled Ugandan adults living with HIV and suspected TBM. We sought to enhance test performance by leveraging the human gene expression component of the CSF mNGS data to develop a complementary machine learning classifier (MLC) that categorizes patients as having TBM or not. While host-based MLCs derived from blood and respiratory fluids are increasingly available to distinguish between infectious and non-infectious diseases (including TB)17,18,19,20,21, the picogram quantities of RNA in a typical CSF sample have thus far stymied the development of analogous host-based classifiers for patients with neuroinflammatory disease.
Results
Cohort demographics
From 2018–2019, 368 patients consented for the study. The median age was 35 years [IQR 29–41 years] with 42.7% female. Among the patients for whom the CD4 cell count was measured (n = 95), the median was 41 cells/mm3 [IQR 13–80 cells/mm3]. At the time of admission, 181 patients (49.1%) were documented as being on antiretroviral therapy (ART), with 41/181 (22.6%) of these patients known to have commenced ART in the prior month. Median duration of headache prior to admission was 14 days [IQR 7–21 days]. Median Glasgow Coma Scale (GCS) at presentation was 14 [IQR 14–15], 185/362 (51.1% of those with known GCS) had GCS < 15. Mortality at discharge or last contact was 25.9% (94/362) (Table 1).
CSF was collected for mNGS from 368 patients. Of note, a second CSF sample was available for 14 patients, and results are represented as pathogens detected per patient, not per sample. Basic CSF studies (i.e., cell counts, chemistry) are listed in Table 1. One hundred eighty (48.9%) were diagnosed with cryptococcal meningitis (CM) based on: a positive serum cryptococcal antigen (CrAg) as well as a positive CSF CrAg and/or positive fungal culture (Not-TBM group). 2.9% (11/368) of patients were diagnosed with bacterial meningitis (Not-TBM group). 10/366 (2.7%) were diagnosed as viral meningitis (Not-TBM group).
Sixty-three patients (17.1%) were classified as probable or definite TBM, of which 61.9% (39/63) had definite TBM and 38% (24/63) were classified as probable TBM. Definite TBM was diagnosed by Xpert MTB/RIF Ultra in 97.4% (38/39) of cases. 66.6% (12/18) of cases were TB culture positive (11/18 cases were positive for TB by both Xpert MTB/RIF Ultra and culture). 16.3% (60/368) of cases were classified as possible TBM. 11.9% (44/368) were categorized as indeterminate. Nine cases had missing data for their TBM UCD score, 6 of these cases had cryptococcal antigenemia, and 3 cases had a final hospital diagnosis listed as unknown. These patients were classified as indeterminate.
Training and test cohorts
Two hundred forty patients were included in the training cohort, ~2/3 of the cohort. Within this cohort, 70 samples had either definite TBM or some other neurological disease (OND) (see Methods) and were used for the training of the MLC. The learning curves generated show that further addition of samples would have diminishing improvements to performance of the classifier (Supplementary Fig. 1). One hundred thirty patients were included in the test cohort. Apart from two cases, cases were exclusive to either the training or test cohorts. In one case, the CSF was used in both the training and test cohorts, and in the other case, CSF collections from 2 separate days from a single case were split between the training and test cohorts. In the training cohort, the percentage of cases with definite TBM was 12.6% (n = 30) whereas in the test cohort, it was 6.3% (n = 8) (Supplementary Table 1).
Training cohort mNGS results
Median sequencing depth for the RNA-Seq libraries after removal of External RNA Control Consortium (ERCC) sequences (both through bioinformatic filtering and depletion of abundant sequences by hybridization (DASH))22,23 was 5,668,087 paired-end reads (IQR 2,804,906–13,858,372). The median RNA input mass was 4.37 pg (0.8–1326.4 pg). The median sequencing depth for the DNA-Seq libraries was 27,341,015 (IQR 19,161,771–32,158,040). Transcripts aligning to an average of 3212 protein-coding genes (113–5335) were detected. We did not observe a strong correlation between the total number of protein-coding genes for which transcripts were detected in each sample and RNA mass, cell count, and library preparation method (i.e., with or without ERCC DASH) (Supplementary Fig. 2A).
TBM detection by mNGS
We evaluated all definite TBM cases that were mNGS positive for TB. The median number of sequences aligning to the TB genome was 24 in the DNA-seq libraries (2–552 sequences) (median 1.4 reads per million reads (rpM) sequenced, 0.1–25.2 rPM), and 3683 in the RNA-seq libraries (1–116,083 sequences) (median 155.7 rPM, 0.1–9050 rpM). No TB reads were detected in the 8 “no template” water controls. Given the very low abundance of TB reads in definite TBM CSF and the lack of any TB sequences detected in the “no template” water controls, detection of TB by mNGS was defined as 1 or more sequences, with the entire sequence aligning (with no alignment to any other mycobacterial species) to the TB genome with ≥98% nucleotide sequence identity.
Training cohort machine learning classifier
Seventy microbiologically proven samples (TBM: n = 32 and OND: n = 38) infections, identified in the training cohort, were used for the training of the MLC. Samples were sequenced across two batches (TBM: batch 1 (n = 12), batch 2 (n = 20); OND: batch 1 (n = 19), batch 2 (n = 19)) to mitigate batch effects. Sixteen thousand six hundred seventeen different iterations of the classifier were run to determine the optimal parameters: all combinations of five ML methods (with parameters) with/without feature selection, addition of the co-variate matrix variables before/after feature selection, class weights (TBM, OND) and prior count for logCPM. We wanted to identify a small set of features to distinguish the TBM versus OND, and hence chose L1 regularization. The first round of iterations (n = 16,050) of the classifier was bootstrapped 100 times. A second round of iterations (n = 567) to fine tune the classifier was run 1000 times. A cutoff of ≥50% was used for the diagnosis of TBM.
Two support vector machine (SVM) classifiers, with L1 regularization (regularization parameter C = 0.1), independent of the co-variate matrix, with highest sensitivities were chosen: MLC1 and MLC2. MLC1 had a prior count = 75, and top 50 features, and MLC2 had a prior count = 75, top 40 features and class weight for TBM = 2. This class weight of 2 further increased the sensitivity of TBM detection in our training cohort.
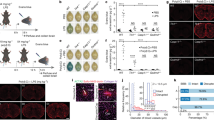
MLC1 had an area under the receiver operator characteristics curve (AUC) = 0.94, sensitivity = 0.84 and specificity = 0.95 on the training cohort. Of the 10 resequenced samples, MLC1 classified 4/5 TBM and 5/5 OND correctly. A total of 15 genes were used to classify TBM and 111 genes to classify OND (bootstrap = 1000) (Supplementary Data 1). For the TBM group, four genes were used predominantly (>500/1000 bootstrap) for classification: FTL (528/1000), NFKBIA (674/1000), SOD2 (999/1000), and GBP5 (1000/1000). For the OND group, three genes were used predominantly for classification: EEF1A1 (532/1000), TMSB4X (544/1000), and ACTB (717/1000). We created two additional classifiers (SVM, C = 0.1, prior count = 75) based on these top genes to classify TBM vs. OND: a four-gene (FTL, NFKBIA, SOD2, and GBP5) and seven-gene (FTL, NFKBIA, SOD2, GBP5, EEF1A1, TMSB4X, and ACTB) classifier. In the main manuscript we only discuss results from MLC1. Performance of the MLC2, four-gene and seven-gene classifiers are described in the Supplementary Information (Supplementary Note 1).
Test cohort mNGS and MLC detection of TBM
Median sequencing depth for RNA-seq after removal of ERCCs (both through bioinformatic filtering and DASH) was 2,576,270 (IQR 1,274,462–13,761,173). The median sequencing depth for DNA-seq was 21,698,038 (IQR 9,842,494–29,087,373) The median RNA mass was 7.03 pg (2.7–4750 pg).
There were nine cases of definite TBM and 13 probable TBM cases in the test cohort. mNGS detected TB in six of the definite TBM cases, for a sensitivity of 6/9 (66.6%). In the probable TBM group, mNGS detected one case of TB, one case of Toxoplasma gondii, one case of C. neoformans, one case of T. gondii and varicella zoster virus (VZV) co-infection, and one case of T. gondii and C. neoformans co-infection. The case with T. gondii and C. neoformans co-infection was a repeat CSF sample present in the training cohort which the authors were blinded to.
The MLC correctly called seven out of nine cases of definite TBM as TBM for a sensitivity of 77.7%. The MLC called three cases as TBM in the probable TBM group. One of these cases had TB detected by mNGS (Fig. 1), and the other two cases had no pathogen identified. We compared the MLC failures and successes and saw no statistically significant differences regarding their RNA mass, CSF cell counts or the number of protein-coding genes with non-zero counts (Supplementary Fig. 2B).

A Workflow for creation of the machine learning classifier using 70 microbiologically proven samples, through PCR or conventional testing, identified in the training cohort. B Most predictive 4 genes of a 15 gene classifier to classify TBM vs OND. C Left: ROC curve for the combined mNGS and MLC assay. Blue dotted line is the MLC assay alone, and the green solid line is the combined assay. If the MLC categorized a case as TBM, but mNGS detected a non-TB pathogen, then mNGS overruled the MLC result, thus increasing specificity of the overall assay. Right: In silico prediction of shallow depth (i.e., 100,000 reads for the RNA-seq library and 500,000 reads for the DNA-seq library) sequencing results. Pink dotted line is the MLC assay alone, red solid line is combined assay with mNGS. Current cost prediction for shallow depth sequencing in $75 per patient. CPM counts per million, GBP5 guanylate binding protein 5, FTL ferritin light chain, NFKBIA NF-kappa-B inhibitor alpha, SOD2 superoxide dismutase 2, TBM tuberculous meningitis, OND other neurological disease, MLC machine learning classifier, mNGS metagenomic next-generation sequencing, AUC area under the receiver operator curve. Source data are provided as a Source Data file.
mNGS results for entire cohort
Sequences aligning to M. tuberculosis were detected by RNA-seq, DNA-seq or both in 37 cases throughout the cohort (Supplementary Table 2). TB was detected by mNGS in 74.4% (29/39) of definite TBM cases. TB was detected by mNGS in 12.5% (3/24) of cases classified as probable TBM (i.e., negative CSF TB PCR and TB culture). Thus, overall sensitivity for detecting TB by mNGS in cases defined as definite or probable TBM was 50.8% (32/63). Sensitivity increased to 54.2% (32/59) when excluding cases from the probable TBM group in which mNGS detected alternate infections. TB was detected in 3.8% (4/104) of cases classified as possible TBM or indeterminate. TB was identified as a co-infection in one patient with CM (Not-TBM group) for whom TB culture and Xpert Ultra had not been performed. Regarding alternate infections, one definite TBM case had a T. gondii co-infection detected by mNGS. As stated, mNGS detected four cases with non-TB infections in the probable TBM group, including three cases previously mentioned in the test cohort results section (C. neoformans in one case, T. gondii in one case and a T. gondii and VZV co-infection in another), and one case of a T. gondii and C. neoformans co-infection in the training cohort.
Viral infections
Nineteen neuroinvasive viruses (other than HIV-1) were detected by mNGS across the entire cohort (Table 2). As described above, VZV was detected as a co-infection with T. gondii in a case classified as probable TBM. Ten viruses were detected in the possible TBM and indeterminate groups (herpes simplex virus type 1 (HSV-1) n = 1, HSV-2 n = 1, VZV n = 3, cytomegalovirus (CMV) n = 2, human parvovirus B19 n = 1, rubella virus n = 1, Wesselsbron virus n = 1). Wesselsbron virus, a neuroinvasive flavivirus endemic to sub-Saharan Africa24,25, was identified along with TB (see Supplementary Information for clinical history). mNGS yielded 5739.5 rPM with 96.1% coverage across the Wesselsbron virus genome (Fig. 2D and Supplementary methods for phylogenetic tree).

A Detection of TB for entire cohort. Blue circle represents definite TBM (i.e., detected by GeneXpert Ultra and/or culture). Pink circle represents probable TBM cases based on clinical consensus but GeneXpert Ultra and/or culture negative. Green circle is TBM detected by mNGS. Five additional cases of TBM were detected in possible TB, indeterminate and Not-TBM groups. B Breakdown of pathogens found in possible TBM and indeterminate groups. C Top two graphs are log10(rPM) for normalized DNA-seq and RNA-seq reads to Streptococcus pneumoniae and Neisseria meningitidis detected in every sample sequenced. Red dots indicate samples with greater than 1 log fold abundance greater than the mean cohort abundance in both the DNA-seq and RNA-seq datasets relative to the remaining cohort. Red dots circled in black indicate samples that were diagnosed as bacterial meningitis during hospital admission in Uganda. Bottom two graphs demonstrate a similar method performed for Epstein-Barr virus and cytomegalovirus as both these viruses can be seen in low abundance in neuroinflammatory conditions. Red dots indicate samples with Epstein-Barr virus or cytomegalovirus with rPM 2 log fold higher than the mean cohort abundance in DNA-seq. D Phylogenetic tree for Wesselsbron virus detected in 1 patient in the possible TBM group. Phylogenetic tree was built with a multiple sequence alignment using the assembled genome and reference genomes obtained from National Center for Biotechnology Information. The best-fitting evolutionary model was picked by ModelTest-NGv0.1.5, and a phylogenetic tree was built using RAxML-ng v0.6.0. Scale bar indicates length associated with 4.0 nucleotide substitutions. TBM tuberculous meningitis, TB Mycobacterium tuberculosis, mNGS metagenomic next-generation sequencing, RNA-seq ribonucleic acid sequencing, DNA-seq deoxyribonucleic acid sequencing, rPM reads per million. Source data are provided as a Source Data file.
Nine additional viruses were detected in the Not-TBM group: HSV-2 n = 1, VZV n = 2, CMV n = 1, human parvovirus B19 n = 1, measles virus n = 1, John Cunningham (JC) virus n = 1, and Epstein-Barr virus (EBV) n = 2 were detected as co-infections in patients with CM (Fig. 2C). In addition, viral reads to likely nonpathogenic viruses were detected (Supplementary Data 2).
Bacterial infections
We identified nine cases of bacterial meningitis, including four cases of Streptococcus pneumoniae (Fig. 2C). All four of the cases were categorized as acute bacterial meningitis by hospital discharge diagnosis (Not-TBM group) (Table 2). One case of Nocardia brasiliensis was detected by CSF mNGS in a patient classified as possible TBM. Four cases of Neisseria meningitidis were detected. Two of these cases had a clinical diagnosis of bacterial meningitis (Not-TBM group). One case was in the possible / indeterminate group, and the other case was a co-infection in a patient with CM (Not-TBM group). mNGS also detected C. neoformans in this case (9.21 rPM).
Parasitic infections
Fifteen cases of T. gondii were identified. One case was identified as a co-infection in a patient with definite TBM, three cases were identified in patients classified as probable TBM, one case which also had C. neoformans identified on mNGS (CSF CrAg negative), and another with a co-infection with VZV (as described above). Six cases of T. gondii were identified in patients classified as possible TBM, and four were identified as co-infections in patients with CM (Table 2).
A combined microbial and host-based MLC assay for diagnosing TBM and its mimics in a Ugandan HIV-positive cohort
The host MLC alone classified cases in the blinded test set as TBM vs OND with a sensitivity of 77.8% (CI: 40–97.2%) (7/9) sensitive and 76% (CI: 64.8–85.1%) (57/75) specific with an AUC of 0.74 (p = 0.02). The combined mNGS and host MLC displayed 88.9% (CI:51.8–99.7%) (8/9) sensitivity, 86.7% (CI:76.8–93.4%) (65/75) specificity, with an AUC of 0.87 (p = 0.0003). Concordance was 50% (11/22) against the UCD of definite and probable TBM and 61% (11/18) when cases of non-TB pathogens detected in the probable group were excluded. The combined assay detected three cases of TB in the probable TBM group and eight additional TBM cases initially classified as possible TBM. Improvement in specificity of the combined assay from the standalone host MLC classifier was due to eight cases that were classified as TBM by the MLC but were found to have other pathogens detected on mNGS, which overruled the MLC classification. These were three cases of N. meningitidis, three cases of C. neoformans, one case of VZV, and one case of EBV. One case of definite TBM had lumbar punctures (LPs) performed on days 1 and 3 post-initiation of TBM treatment. Day 1 CSF was used as part of the MLC training cohort, and TB was detected by mNGS. Day 3 CSF was used in the test cohort to which the authors were blinded. mNGS failed to detect TB in the day 3 CSF; however, the MLC still classified this sample as TBM. We considered this a failure of TB detection by mNGS when analyzing the test cohort data.
In silico evaluation of mNGS and host gene expression MLC with shallow depth sequencing for low resource settings
Shallow depth sequencing of the test set had no impact on MLC sensitivity or specificity: MLC1 correctly identified 7/9 definite TBM cases (100% concordance with deep sequencing MLC results) as TBM, and 59/75 OND cases as OND at all subsampled depths down to 100,000 reads. The final AUC, sensitivity, and specificity for the MLC1 were calculated once the optimal threshold was determined for the mNGS assay.
mNGS subsampling
mNGS results from the original samples were used as a baseline for comparison at various subsampling depths. DNA-seq libraries in which TB was detected for the entire cohort at the original sequencing depth (n = 25) had TB detected with 56% sensitivity (14/25) at 2,000,000 reads and 32% sensitivity at 500,000 reads (8/25). RNA-seq libraries in which TB was detected for the entire cohort at the original sequencing depth (n = 9) had TB detected with 100% sensitivity (9/9) at a subsampling depth of 2,000,000 reads and 88.9% sensitivity (8/9) at 100,000 reads (Supplementary Table 3).
For non-TB pathogens, 15 DNA and 6 RNA samples consisting of viral, bacterial, and parasitic infections were analyzed, including one sample with a co-infection. For DNA-seq, at a subsample depth of 500,000 reads, mNGS detected 100% of the pathogens that were detected at the original sequencing depth. At the lowest subsample depth of 100,000 reads, 13/15 (86.67%) of pathogens were detected. When subsampling RNA-seq libraries at a depth of 2,000,000 or 100,000 reads, 6/6 (100%) of pathogens detected at the original sequencing depths were detected (Supplementary Table 3).
Based on these results, the optimal sequencing depth for the detection of non-TBM pathogens was considered 100,000 paired-end reads for RNA-seq and 500,000 pair end reads for DNA-seq. While TB detection by mNGS at shallow sequencing depths was insensitive, the MLC classifier still maintained similar sensitivity to classify TBM at 100,000 paired-end reads. We therefore reran all microbiologically proven samples from the final test cohort (n = 84) at 100,000 reads for RNA-seq and 500,000 reads for DNA-seq for through the MLC and the open source, cloud-based metagenomics pipeline (Chan Zuckerberg ID or CZID)26 pipeline to assess AUC, sensitivity and specificity of our in silico low depth sequencing model. The MLC had an AUC of 0.76 (p = 0.01) with a sensitivity of 77.8 (CI:40–97.2%) and a specificity of 78.7 (CI:67.8–87.3%). The combined MLC and mNGS assay had an AUC of 0.88 (p = 0.0002) with a sensitivity of 88.9% (CI:51.8–99.7%) and a specificity of 88% (CI:78.4–94.4%) (Fig. 1C).
Cost analysis
At a depth of 100,000 reads for the RNA library and 500,000 reads for the DNA library, one sample would require 600,000 total paired-end reads. An Illumina iSeq generates 8,000,000 paired-end reads per flow cell. Thus, at 600,000 reads per sample, it would be possible to evaluate 13 samples/run. The current cost of the iSeq cartridge at the time of writing was $USD495, or $38 per sample. With our current library preparation protocol, the total cost of reagents would be $28.25/sample at a 0.5× reaction volume with the NEBNext® Ultra™ II kits: NEBNext Ultra II RNA library kit (NEB Cat No. E7770) $15.75/sample, NEBNext® Ultra™ II FS DNA Library Prep Kit (E7805L) $12.50/sample. SPRIselect 450 mL reagent kit (B23319) $5/sample, and QIAseq FastSelect—rRNA HMR Kit (334386) at 1:100 dilution $4.60/sample. The overall cost/sample would be $75.85, excluding the upfront costs of the Illumina iSeq and ongoing service contracts.
Discussion
Characterizing the epidemiology of infectious and non-infectious etiologies of meningitis and encephalitis is inherently challenging and only compounded by the limited diagnostic capacity in sub-Saharan Africa27,28,29. Because of the high prevalence of advanced HIV-1 and TB infections in Uganda, C. neoformans and TB are the most commonly diagnosed causes of meningitis. Yet, the etiology of many other cases of meningitis and/or encephalitis is never known30. Here, we utilized unbiased CSF mNGS to obtain a more comprehensive profile of neurologic infections (and co-infections) in Ugandan adults with subacute meningitis living with HIV. We identified many treatable and vaccine-preventable infections. In addition, we describe the first use of human transcriptomic data generated by a CSF mNGS assay to combine direct detection of pathogens with a host-based MLC that identifies patients with or without TBM.
The diagnosis of TBM remains difficult due to the paucibacillary nature of the disease. While mNGS can detect TB in CSF, mNGS still has limited sensitivity, akin to TB PCR14,15,16. Here, mNGS demonstrated 74.4% concordance against microbiologically confirmed cases of TBM (i.e., definite TBM) and 54.2% concordance against the UCD of definite and probable TBM after removing probable TBM cases in whom mNGS identified an alternate infection. We detected an additional five cases of TBM missed by conventional testing in the possible TBM and indeterminate groups and a sixth case in a patient diagnosed with CM (Not-TBM group), who did not undergo conventional testing for TBM.
mNGS identified 43 additional neurological infections that were either sole or co-infections, including neuroinvasive viruses like Wesselsbron virus, a flavivirus endemic to the region that mainly infects livestock24 but with several reports of human infections, including neuroinvasive disease25,31. This virus was present in a patient co-infected with TB (Supplementary Information). We also identified 14 cases of treatable viruses (HSV-1, HSV-2, VZV, CMV, and EBV) and 2 vaccine-preventable viruses (measles virus and rubella virus). Measles can present with varying CNS manifestations, including measles inclusion body encephalitis occurring in HIV-infected patients32. Two cases of human parvovirus B19 were detected. Neurological manifestations of human parvovirus B19 have been previously described in both immunocompetent and immunocompromised patients33. In addition to viral infections, we found 15 cases of CNS toxoplasmosis and 1 case of CNS Nocardia, highly morbid but treatable conditions if diagnosed early34,35.
Despite the relatively pauci-cellular content of many CSF samples in this cohort of immunocompromised patients, we recovered a rich human gene expression dataset, detecting transcripts to an average of more than 3000 genes/sample. Leveraging these data, we built a sensitive MLC to distinguish TBM from ONDs that can mimic TBM. Five of six definite TBM cases in the test cohort were classified correctly, improving upon the direct detection of TB in 3/6 cases by mNGS. Our MLC primarily uses four genes to classify TBM: GBP5, SOD2, NFKBIA, and FTL. GBP5, which promotes NLRP3 inflammasome responses to pathogenic bacteria36,37, and is part of a 3 gene signature (GBP5, DUSP3, and KLF2) that distinguishes active pulmonary TB from other infections38,39. Additional studies using GBP5 have also distinguished TB from non-TB pneumonia with >90% sensitivity and specificity40,41. The three other primary genes (SOD2, NFKBIA, and FTL) used in our MLC have not been described in other TB host gene expression signatures. Interestingly, SOD2-mediated acidification of phagosomes has been shown to promote survival of TB in their host and serves as a marker for oxidative stress42,43,44. Ferritin has been recognized as an important factor in host immunity against TB, and ferritin heavy chain in particular has been shown to protect against TB in murine studies45. NFKBIA is a member of the NF-kappa-B (NF-κB) inhibitor family. NF-κB signaling dynamics, triggered via tumor necrosis factor-α binding to receptors on macrophages, has been shown to play a key role for survival of TB46. Particularly, Bai et al., reported that NF-κB inhibition, decreased survival of TB in macrophages47.
Overall, the MLC was optimized for high sensitivity, but there was a trade-off with specificity. The MLC performed poorly classifying OND cases that had infections which were not present in the training cohort. For instance, three of four cases of N. meningitidis were classified as TBM. Fortunately, coupling case classification by the host MLC with direct detection of pathogens by mNGS enhanced the overall specificity of the assay. In other words, direct detection of a pathogen by mNGS overruled the MLC if a pathogen other than TB was detected. Training the MLC on a larger cohort of patients with a wider range of ONDs will further improve accuracy.
Implementing these technologies in low resource settings is critical to improve prospective diagnoses and the institution of appropriate therapies. The utility of our diagnostic tool is not only its ability to detect TB, but also co-infections and infectious TB mimics with enhanced sensitivity for TB enabled by the host MLC analysis whose data are generated as part of the mNGS assay. Our in silico analyses suggest that only an average of 600,000 paired-end reads are required to achieve results that we and others have traditionally achieved with millions or tens of millions of reads/sample10,14,48. In addition to an estimated per sample cost of $75, the cost-effectiveness of this assay will likely be enhanced in low resource settings lacking numerous pathogen-specific PCR assays and other diagnostic modalities commonly at the disposal of clinicians in high resource settings. Thus, mNGS, may serve as a “leapfrog” technology in this context.
This study has several additional limitations. It remains to be determined how well the genes that comprise the MLC translate to immunocompetent individuals though we are heartened that the key genes in our classifier have significant overlap with host transcriptomic studies in pulmonary TB, including non-HIV-positive patient populations39. In addition, host responses may vary between patients with different genetic backgrounds and based on the virulence of the infecting TB strain. Although almost all LPs were performed prior to initiation of therapy, we did not have data about prehospital antibiotic treatment, which may have impacted CSF pathogen load and host gene expression profiles. As illustrated in the case vignettes (Supplementary Information), we made every attempt to clinically correlate candidate pathogens detected by mNGS (in addition to confirmatory laboratory testing). However, the lack of widely available advanced neuroimaging and other testing modalities limited clinical adjudication to some degree. This is reflected in the fact that we detected high levels of HIV in the CSF of many patients, some of whom likely had HIV-associated dementia. However, we were not able to confidently classify them as such. Additionally, while we had a large cohort of patients, the number of cases of definite TBM in the training and test cohorts was small which limited the precision of the point estimates for the sensitivity, specificity, and AUC of the combined assay.
Currently mNGS is an expensive technology; however, research is underway to make this tool more accessible, especially for low resource settings where the burden of infectious diseases is high and the availability of many pathogen-specific assays is low48,49,50. Here, we demonstrated that mNGS identified many previously undiagnosed but treatable neurologic infections, even in patients already diagnosed with one cause of infectious meningitis. In addition, we developed a first-of-its-kind combined diagnostic assay utilizing mNGS and analysis of the CSF host transcriptome to diagnose TBM vs other non-TB meningitis etiologies. The accuracy of this method will only increase with the incorporation of larger patient numbers and holds the promise of more sensitively and rapidly detecting TBM along with TBM co-infections and TBM mimics, many of which are treatable or vaccine-preventable illnesses. Lastly, the ability to generate useful host transcriptomic data from pauci-cellular CSF augurs well for developing future MLCs that distinguish between other clinically overlapping neuroinflammatory syndromes like viral and autoimmune encephalitis.
Methods
Study cohort
All research was conducted complies with all ethical regulations. Patients were prospectively recruited as part of the “Improving Diagnostics and Neurocognitive Outcomes in HIV/AIDS-related Meningitis” study (NCT01802385), a prospective cohort study underway in Uganda. Although some patients studied here later enrolled into other unrelated clinical trials, the analyses in this study of baseline CSF specimens are not related to the outcomes of any therapeutic intervention. Research was approved by University of Minnesota (IRB Study ID STUDY00006856), Infectious Diseases Institute at Makerere University and the Mulago Hospital Research and Ethics Committee (IRB Study ID MHREC1246), and University of California San Francisco (IRB 13–12236). All HIV-positive patients presenting with signs and symptoms concerning for meningitis (presentation with some combination of headache, fever, nuchal rigidity, neurologic deficit, or altered mental status) to Kiruddu Regional Referral Hospital, Kampala, Uganda from March 2018 to March 2020 were screened for study inclusion. LP was performed during days 1–3 of admission utilizing a standardized diagnostic algorithm. All patients had extensive demographic, clinical, biochemical, and microbial data collected. However, CD4 + T cell counts and HIV viral loads were not available for the majority of patients. Clinical data included presenting signs and symptoms, prior TB history and prophylaxis, response to antimicrobial and adjunctive treatments, and hospital discharge status. Baseline CSF cell count, protein, glucose, microscopy, gram stain, bacterial cultures, CrAg, and fungal culture were obtained for all participants. If the CrAg was positive, the patient was treated for CM, and no further microbiological diagnostic testing was performed. If the CSF CrAg was negative, CSF Gene Xpert MTB/RIF Ultra and TB culture were performed to evaluate for TBM8. If TB was detected by either of these tests, the patient was considered to have definite TBM. The BioFire® FilmArray® Meningitis/Encephalitis (ME) Panel was performed on a subset (n = 52) of CSF samples, regardless of presumed diagnosis based on the clinician’s discretion. For all enrollees, ~1 mL of CSF was collected in Zymo DNA/RNA Shield collection tubes (Zymo Research; Irving, CA) and subsequently frozen at −70 °C within 8 h of collection and shipped in batches to the University of California San Francisco (UCSF) for mNGS on dry ice (Fig. 3).

Four major components of the study: recruitment, library preparation, analysis, and creation of the combined assay. HIV human immunodeficiency virus, CSF cerebrospinal fluid, NGS next-generation sequencing, mNGS metagenomic next-generation sequencing, USA United States of America, RNA ribonucleic acid, DNA deoxyribonucleic acid, MLC machine learning classifier, TB Mycobacterium tuberculosis, OND other neurological disorders, UCD uniform case definition.
Final clinical diagnoses and case classifications were adjudicated based on investigations performed in Uganda and per the consensus TBM UCD8 (Supplementary Table 4), respectively. Cases were categorized into definite TBM (microbiologically proven), probable TBM (score > 10 points), possible TBM (score 6–9 points), indeterminate (score < 6 points and without a microbiologically confirmed alternate infection), and Not-TBM (microbiologically confirmed alternate infection). Alternate diseases in the Not-TBM category included CM, bacterial meningitis, and viral meningitis (Table 1).
Cerebrospinal fluid mNGS
Total nucleic acid was extracted from 90 uL of CSF using the Zymo Quick-DNA/RNA MagBead (Zymo Cat. No. R2130) via the Agilent Bravo or the Integra Viaflo 96, in batches of 40–96 samples and eluted into 50 uL of sterile water. The nucleic acid was then divided with half undergoing DNAse treatment to isolate RNA and the remainder being used for DNA sequencing (DNA-Seq). Total nucleic acid was also extracted from no-template water controls. ERCC RNAs were spiked into the RNA fractions at 25 pg to later back-calculate RNA mass and use as positive internal controls23.
RNA sequencing (RNA-Seq) libraries were prepared using the New England Biolabs’ NEBNext Ultra II RNA library preparation kit (NEB Cat No. E7770) as per the protocol. Library preparation was performed in bulk using the Echo Labcyte 525 and Agilent Bravo or Integra Viaflo 96 liquid handling robots51. DNA libraries were prepared using the New England Biolabs’ NEBNext® Ultra™ II FS DNA Library Prep Kit (E7805L) as per the protocol using the Echo Labcyte 525 and Agilent Bravo liquid handling robots. Host ribosomal RNA depletion was performed using the Qiagen QIAseq FastSelect RNA removal kit (Qiagen Cat No. 333180) at 1:100 dilution. The RNA-Seq libraries for 205 samples from both training and test cohorts underwent ERCC depletion using DASH. DASH is a CRISPR-Cas9 technology the removes abundant sequences from mNGS libraries. CRISPR-Cas-9 guide RNAs (gRNAs) were created to target ERCC sequences. DASH treatment is performed after ligation of adapters and unique barcoding of the RNA-seq library. gRNAs targe ERCC sequences. These regions in the library are cleaved, leaving only the fragments with intact adapters on both ends to be further amplified and sequenced22. Shallow sequencing was performed on an Illumina iSeq to calculate pooling volumes. Then pooled libraries were size selected using Ampure beads and sequenced on an Illumina Novaseq 6000 using 146 base pair paired-end sequencing.
Metagenomic analysis
A open source, cloud-based metagenomics pipeline CZID was used for mNGS analysis26. Raw sequencing files are uploaded to CZID (czid.org), which performs several processing steps prior to analysis of non-host data. The first step in the pipeline is an alignment to the human genome to remove host sequences. Remaining sequences after this initial human alignment step were deposited in the National Center for Biotechnology Information (NCBI) Sequence Read Archive (SRA) with the primary accession codes PRJNA773920 (https://www.ncbi.nlm.nih.gov/bioproject/PRJNA773920). As a result, these data files contain non-host sequences not only from pathogens but also from environmental contaminants from skin and the laboratory, including bacteria, fungi, nonpathogenic viruses, and even vertebrates. Subsequent steps in the CZID pipeline (i.e., removal of low-quality reads, duplicate reads. low complexity reads, and additional human sequence filtering) further reduce contaminating and uninformative sequences from the nonhuman dataset. The remaining sequences undergo an assembly-based alignment using an indexed version of the NCBI’s GenBank database to identify the source of nonhuman sequences in the datasets. Additional computational steps detailed below that are specific to different types of pathogens were used to discriminate between likely environmental contaminants and candidate pathogens.
Given its paucibacillary nature, the abundance of TB DNA in CSF, as measured by rpM, can fall below the reporting thresholds in clinical mNGS assays14. We therefore identified the optimal reporting threshold for TB using the training cohort and used this threshold on the test cohort. Regarding common causes of bacterial meningitis, sequences aligning to Streptococcus pneumoniae, Haemophilus influenzae, and Neisseria meningitidis can be found in low abundance in CSF mNGS datasets secondary to environmental, specimen handling, and/or water contamination. Reads aligning to these pathogens were normalized using compression ratios obtained from the CZID pipeline. The relative abundance for these organisms was calculated in log10(rpM) by RNA-Seq (x-axis) versus DNA-Seq (y-axis) (Fig. 2C). When these bacteria were detected with both RNA and DNA abundance greater than 1 log relative to the mean abundance of the entire cohort, they were considered likely pathogens rather than environmental contaminants. A positive detection of a fungus or parasite required an rpM ratio of ≥10, where the rpM ratio = rpM CSF sample/rpM no-template control (NTC), or rpM ratio = rpM CSF sample if rpM NTC = 052. Candidate viral pathogens had to have known neuroinvasive potential and at least one sequence and its mate pair both aligning specifically to the virus’ genome. Given that EBV and CMV can be incidentally detected by pathogen-specific PCR and/or CSF mNGS without clear disease association, only clear outlier cases defined as log10 (rPM) two-fold greater than the mean abundance of the entire cohort were presumed pathogenic within the context of patients with advanced HIV infection. Neuroinvasive viruses, bacteria, fungi, and parasites identified by mNGS were orthogonally validated with pathogen-specific PCR, clinical microbiological tests performed in Uganda (e.g., CrAg and fungal culture) or repeat mNGS on an independent CSF aliquot.
Development of a host gene expression MLC to discriminate between TBM (without co-infection) and non-TB etiologies
We created a training cohort to identify the optimal reporting threshold for TB and to build the MLC classifier. The cohort included patients with definite TBM and other neurological diseases (ONDs). Patients from the OND group were selected from the probable TBM, possible TBM / indeterminate and Not-TBM groups, including cases with viral, bacterial, or fungal pathogens, along with cases with only low abundance HIV, EBV, and/or CMV. This was done to prevent biasing the training set to a particular OND and to provide a more accurate representation of the overall patient population.
The workflow for the training of the MLC is presented in Fig. 3A. Human gene counts were generated with Spliced Transcripts Alignment to a Reference (STAR) (v2.5.3a) from the CZID analysis pipeline26 using human genome assembly build 38 v23. Transcript counts for human protein-coding genes (n = 19,590) from the samples comprising the training set were used as an input for building the MLC. Samples were normalized using the trimmed mean of M-values using calcNormFactors and logCPM functions from the edgeR R package that were adapted in python v3.6.2153. Additionally, age, sex, GCS, and CSF white cell counts were included as a priori suspected co-variates. As the number of genes used as input (19,590) was larger than the number of samples used to train the classifier, we used feature selection (Univariate Feature Selection, scikit-learn v.0.21.3) to reduce the dimensionality of the input vector and identify the smallest set of genes most predictive of TBM and OND. Finally, five different ML methods (logistic regression, random forest, SVM, elastic net, and XGBoost) were evaluated to determine the best performing classifier. We chose to evaluate these MLC methods because they are “interpretable”. In other words, the genes used for classification are known so it is possible to extract decision rules. Final parameters for the MLC were chosen using cross-validation (80/20 split) to avoid overfitting. The classifier with the highest sensitivity (followed by AUC, and specificity) was chosen as the final classifier.
Testing of a combined mNGS and host gene expression MLC
A test cohort of patients with TBM and ONDs was created to assess the sensitivity and specificity of the host gene expression MLC alone and the combined mNGS and host-based gene expression MLC assay for diagnosing patients with or without TBM. UCSF investigators were blinded to any sample or case details. The final combined assay used both the mNGS (both DNA-seq and RNA-seq) and host MLC resulting in a single test for the detection of TBM versus OND. If the MLC classified a case differently than the pathogens detected by the mNGS assay (meeting preset mNGS thresholds), then the mNGS results would overrule the MLC due to the presumption that direct detection of a pathogen was more specific than categorization of disease based on a host response signature. Patients with TBM for whom there was evidence of a CNS co-infection found on mNGS (other than HIV) were not used in the final test set. The reference standard was a microbiological composite of conventional CSF testing (e.g., CSF CrAg, fungal culture, Gram stain, bacterial culture, Gene Xpert MTB/RIF Ultra, TB culture) and orthogonally confirmed mNGS-identified pathogens (other than TB).
In silico evaluation of mNGS and a host gene expression MLC with shallow depth sequencing for low resource settings
To assess whether similar results were achievable at shallow depth sequencing to better enable mNGS diagnostics in lower resource settings, we subsampled our test dataset at various sequencing depths (i.e., 100,000 to 2 million reads) and analyzed the impact on the sensitivity and specificity of the assay for pathogen identification and the accuracy of the host gene expression MLC. First, all samples were aligned to the ERCC transcripts using STAR (v2.5.3a) to filter out any remaining ERCC sequences that were not removed through DASH. Next, files were each subsampled in triplicate using seqtk (v1.2-r94) at the following sequencing depths: 100,000, 150,000, 200,000, 500,000, 1,000,000, and 2,000,000 reads. Subsampled files were then aligned to the human genome using STAR to obtain transcript counts, which were then run through MLC1 classifier. Subsampled files were also uploaded to the CZID pipeline for mNGS analysis.
Statistics
Final diagnostic accuracy of the combined assay (AUC, sensitivity, and specificity) was based on comparing the results against a composite of clinical diagnostic testing results and orthogonally confirmed mNGS-identified pathogens. The p-value for the AUC was calculated in GraphPad Prism, using a two-tailed test for hypotheses and assuming that the null hypothesis value for the AUC was 0.5. Baseline clinical characteristics and demographic data were compared between cohorts via Mann-Whitney U for continuous variables and chi-square test for categorical variables.
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Data availability
Non-host sequence data that support the findings of this study have been deposited in NCBI Sequence Read Archive with the primary accession codes PRJNA773920. All host gene counts for samples have been deposited at https://github.com/UCSF-Wilson-Lab/TBM_classifier and Zenodo54. Source data are provided with this paper.
Code availability
All code used in the generation of the machine learning classifier, and all gene counts used in the development of the machine learning classifier have been deposited at https://github.com/UCSF-Wilson-Lab/TBM_classifier and Zenodo54.
References
WHO. Global tuberculosis report. (WHO, 2017).
Hogan, A. B. et al. Potential impact of the COVID-19 pandemic on HIV, tuberculosis, and malaria in low-income and middle-income countries: a modelling study. Lancet Glob. Health 8, e1132–e1141 (2020).
Woldeamanuel, Y. W. & Girma, B. A 43-year systematic review and meta-analysis: case-fatality and risk of death among adults with tuberculous meningitis in Africa. J. Neurol. 261, 851–865 (2014).
Bahr, N. C. & Boulware, D. R. Methods of rapid diagnosis for the etiology of meningitis in adults. Biomark. Med. 8, 1085–1103 (2014).
Byrd, T. F. & Davis, L. E. Multidrug-resistant tuberculous meningitis. Curr. Neurol. Neurosci. Rep. 7, 470–475 (2007).
World Health Organization. WHO meeting report of a technical expert consultation: non-inferiority analysis of Xpert MTB/RIF Ultra (World Health Organization, 2017).
Bahr, N. C. et al. Diagnostic accuracy of Xpert MTB/RIF Ultra for tuberculous meningitis in HIV-infected adults: a prospective cohort study. Lancet Infect. Dis. 18, 68–75 (2018).
Marais, S. et al. Tuberculous meningitis: a uniform case definition for use in clinical research. Lancet Infect. Dis. 10, 803–812 (2010).
Kim, M. C., Park, K. H., Lee, S. A. & Kim, S. H. Validation of the uniform case definition criteria for differentiating tuberculous meningitis, viral meningitis, and bacterial meningitis in adults. Infect. Chemother. 51, 188–190 (2019).
Wilson, M. R. et al. Chronic meningitis investigated via metagenomic next-generation sequencing. JAMA Neurol. 75, 947–955 (2018).
Beck, E. S. et al. Clinicopathology conference: 41-year-old woman with chronic relapsing meningitis. Ann. Neurol. 85, 161–169 (2019).
Wilkinson, R. J. et al. Tuberculous meningitis. Nat. Rev. Neurol. 13, 581–598 (2017).
Ramachandran, P. S. & Wilson, M. R. Metagenomics for neurological infections—expanding our imagination. Nat. Rev. Neurol. 16, 547–556 (2020).
Wilson, M. R. et al. Clinical metagenomic sequencing for diagnosis of meningitis and encephalitis. N. Engl. J. Med. 380, 2327–2340 (2019).
Yu, G. et al. Comparison of the efficacy of metagenomic next-generation sequencing and Xpert MTB/RIF in the diagnosis of tuberculous meningitis. J. Microbiol. Methods 180, 106124 (2021).
Yu, G., Zhao, W., Shen, Y., Zhu, P. & Zheng, H. Metagenomic next generation sequencing for the diagnosis of tuberculosis meningitis: A systematic review and meta-analysis. PLoS ONE 15, e0243161 (2020).
Langelier, C. et al. Integrating host response and unbiased microbe detection for lower respiratory tract infection diagnosis in critically ill adults. Proc. Natl Acad. Sci. USA 115, E12353–E12362 (2018).
Heinonen, S. et al. Rhinovirus detection in symptomatic and asymptomatic children: value of host transcriptome analysis. Am. J. Respir. Crit. Care Med. 193, 772–782 (2016).
Tsalik, E. L. et al. Host gene expression classifiers diagnose acute respiratory illness etiology. Sci. Transl. Med. 8, 322ra311 (2016).
Suarez, N. M. et al. Superiority of transcriptional profiling over procalcitonin for distinguishing bacterial from viral lower respiratory tract infections in hospitalized adults. J. Infect. Dis. 212, 213–222 (2015).
Rajan, J. V. et al. A novel, 5-transcript, whole-blood gene-expression signature for tuberculosis screening among people living with human immunodeficiency virus. Clin. Infect. Dis. 69, 77–83 (2019).
Gu, W. et al. Depletion of Abundant Sequences by Hybridization (DASH): using Cas9 to remove unwanted high-abundance species in sequencing libraries and molecular counting applications. Genome Biol. 17, 41 (2016).
Zinter, M. S., Mayday, M. Y., Ryckman, K. K., Jelliffe-Pawlowski, L. L. & DeRisi, J. L. Towards precision quantification of contamination in metagenomic sequencing experiments. Microbiome 7, 62 (2019).
Oymans, J., van Keulen, L., Wichgers Schreur, P. J. & Kortekaas, J. Early pathogenesis of Wesselsbron disease in pregnant ewes. Pathogens https://doi.org/10.3390/pathogens9050373 (2020).
Weyer, J. et al. Human cases of Wesselsbron disease, South Africa 2010-2011. Vector Borne Zoonotic Dis. 13, 330–336 (2013).
Kalantar, K. L. et al. IDseq-An open source cloud-based pipeline and analysis service for metagenomic pathogen detection and monitoring. Gigascience https://doi.org/10.1093/gigascience/giaa111 (2020).
Hasbun, R. et al. Epidemiology of meningitis and encephalitis in the United States, 2011-2014. Clin. Infect. Dis. 65, 359–363 (2017).
Granerod, J. et al. Causes of encephalitis and differences in their clinical presentations in England: a multicentre, population-based prospective study. Lancet Infect. Dis. 10, 835–844 (2010).
George, B. P., Schneider, E. B. & Venkatesan, A. Encephalitis hospitalization rates and inpatient mortality in the United States, 2000-2010. PLoS ONE 9, e104169 (2014).
Rajasingham, R. et al. Epidemiology of meningitis in an HIV-infected Ugandan cohort. Am. J. Trop. Med. Hyg. 92, 274–279 (2015).
Smithburn, K. C., Kokernot, R. H., Weinbren, M. P. & De Meillon, B. Studies on arthropod-borne viruses of Tongaland. IX. Isolation of Wesselsbron virus from a naturally infected human being and from Aedes (Banksinella) circumluteolus Theo. S Afr. J. Med. Sci. 22, 113–120 (1957).
Wilson, M. R., Ludlow, M. L. & Duprex, W. P. Human paramyxoviruses and infections of the central nervous system. In: Neuroviral Infections. (eds. Singh, S. et al.) (New York: Taylor and Francis Group, 2013).
Barah, F., Whiteside, S., Batista, S. & Morris, J. Neurological aspects of human parvovirus B19 infection: a systematic review. Rev. Med. Virol. 24, 154–168 (2014).
Elsheikha, H. M., Marra, C. M. & Zhu, X. Q. Epidemiology, pathophysiology, diagnosis, and management of cerebral toxoplasmosis. Clin. Microbiol. Rev. https://doi.org/10.1128/CMR.00115-19 (2021).
Anagnostou, T. et al. Nocardiosis of the central nervous system: experience from a general hospital and review of 84 cases from the literature. Medicine 93, 19–32 (2014).
Shenoy, A. R. et al. GBP5 promotes NLRP3 inflammasome assembly and immunity in mammals. Science 336, 481–485 (2012).
Caffrey, D. R. & Fitzgerald, K. A. Immunology. Select inflammasome assembly. Science 336, 420–421 (2012).
Warsinske, H. C. et al. Assessment of validity of a blood-based 3-gene signature score for progression and diagnosis of tuberculosis, disease severity, and treatment response. JAMA Netw. Open 1, e183779 (2018).
Sweeney, T. E., Braviak, L., Tato, C. M. & Khatri, P. Genome-wide expression for diagnosis of pulmonary tuberculosis: a multicohort analysis. Lancet Respir. Med. 4, 213–224 (2016).
Laux da Costa, L. et al. A real-time PCR signature to discriminate between tuberculosis and other pulmonary diseases. Tuberculosis (Edinb.) 95, 421–425 (2015).
Gjoen, J. E. et al. Novel transcriptional signatures for sputum-independent diagnostics of tuberculosis in children. Sci. Rep. 7, 5839 (2017).
Drane, P., Bravard, A., Bouvard, V. & May, E. Reciprocal down-regulation of p53 and SOD2 gene expression-implication in p53 mediated apoptosis. Oncogene 20, 430–439 (2001).
Mitterhuemer, S. et al. Escherichia coli infection induces distinct local and systemic transcriptome responses in the mammary gland. BMC Genomics 11, 138 (2010).
Pias, E. K. et al. Differential effects of superoxide dismutase isoform expression on hydroperoxide-induced apoptosis in PC-12 cells. J. Biol. Chem. 278, 13294–13301 (2003).
Reddy, V. P. et al. Ferritin H deficiency in myeloid compartments dysregulates host energy metabolism and increases susceptibility to Mycobacterium tuberculosis infection. Front. Immunol. 9, 860 (2018).
Fallahi-Sichani, M., Kirschner, D. E. & Linderman, J. J. NF-kappaB signaling dynamics play a key role in infection control in tuberculosis. Front. Physiol. 3, 170 (2012).
Bai, X. et al. Inhibition of nuclear factor-kappa B activation decreases survival of Mycobacterium tuberculosis in human macrophages. PLoS ONE 8, e61925 (2013).
Gu, W. et al. Rapid pathogen detection by metagenomic next-generation sequencing of infected body fluids. Nat. Med. 27, 115–124 (2021).
Saha, S. et al. Unbiased metagenomic sequencing for pediatric meningitis in Bangladesh reveals neuroinvasive chikungunya virus outbreak and other unrealized pathogens. mBio https://doi.org/10.1128/mBio.02877-19 (2019).
Hong, N. T. T. et al. Performance of metagenomic next-generation sequencing for the diagnosis of viral meningoencephalitis in a resource-limited setting. Open Forum Infect. Dis. 7, ofaa046 (2020).
Mayday, M. Y., Khan, L. M., Chow, E. D., Zinter, M. S. & DeRisi, J. L. Miniaturization and optimization of 384-well compatible RNA sequencing library preparation. PLoS ONE 14, e0206194 (2019).
Miller, S. et al. Laboratory validation of a clinical metagenomic sequencing assay for pathogen detection in cerebrospinal fluid. Genome Res. 29, 831–842 (2019).
Robinson, M. D., McCarthy, D. J. & Smyth, G. K. edgeR: a Bioconductor package for differential expression analysis of digital gene expression data. Bioinformatics 26, 139–140 (2010).
Ramachandran, P. S. et al. Integrating central nervous system metagenomics and host response for diagnosis of tuberculosis meningitis and its mimics. Zenodo https://doi.org/10.5281/zenodo.6207665 (2022).
Acknowledgements
This research was made possible through support from the National Institute of Allergy and Infectious Diseases grant R01AI145437 (M.R.W., D.R.B., P.S.R., A.R., D.B.M., C.L., and A.W.), National Institute of Neurologic Disorders and Stroke grants K08NS096117 (M.R.W.) and K23NS110470 (N.C.B.), American Academy of Neurology Clinical Research Training Scholarship P0534134 (P.S.R.), Weill Institute for Neurosciences Pilot Award for Junior Investigators in the Neurosciences (P.S.R.), The Australian Government Research Training Program Scholarship (P.S.R.), the Fogarty International Center R01NS086312 and D43TW009345 (C.P.S.), Chan Zuckerberg Biohub (C.L., E.D.C., V.A., and J.L.D.), UCSF School of Medicine (C.M.Q. and E.B.T.), the Westridge Foundation (M.R.W.), and Wellcome (210772/Z/18/Z, F.V.C.). We thank the patients and their families for participation in this study.
Author information
Authors and Affiliations
Contributions
P.S.R., A.W., V.A., A.L., P.S., G.C., S.C., and E.D.C. performed metagenomic sequencing. A.W. and C.F. assisted with orthogonal confirmation. P.S.R. and M.R.W. analyzed metagenomic data. A.W. helped prepare samples for sequencing. F.V.C., C.M.Q., M.K.R., A.S.B., E.K., K.T.K., L.T., J.K., K.S., M.O., N.C.B., A.M., C.P.S., D.R.B., K.C.Z., and D.B.M. identified patients, performed clinical phenotyping, and provided patient samples. A.R. performed the machine learning analyses and evaluation of the final machine learning classifier. P.S.R., R.N., A.R., and E.B.T. performed the shallow sequencing computational analyses. P.S.R. and A.R. generated the figures. C.L. and J.L.D. provided expert guidance on metagenomics and host transcriptomic analyses. P.S.R., A.R., D.R.B., D.M., and M.R.W. conceived of and wrote the manuscript. All authors discussed the results and contributed critical reviews to the manuscript.
Corresponding author
Ethics declarations
Competing interests
M.R.W. receives unrelated research grant funding from Roche/Genentech and received speaking honoraria from Genentech, Takeda, and Novartis. The remaining authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Leo Lahti and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Source data
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ramachandran, P.S., Ramesh, A., Creswell, F.V. et al. Integrating central nervous system metagenomics and host response for diagnosis of tuberculosis meningitis and its mimics. Nat Commun 13, 1675 (2022). https://doi.org/10.1038/s41467-022-29353-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-022-29353-x
This article is cited by
-
Integrating host transcriptomic signatures for distinguishing autoimmune encephalitis in cerebrospinal fluid by metagenomic sequencing
Cell & Bioscience (2023)
-
Current Insights into Diagnosing and Treating Neurotuberculosis in Adults
CNS Drugs (2023)
-
Advancing Diagnosis and Treatment in People Living with HIV and Tuberculosis Meningitis
Current HIV/AIDS Reports (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
