
Abstract
Non-model bacteria like Pseudomonas putida, Lactococcus lactis and other species have unique and versatile metabolisms, offering unique opportunities for Synthetic Biology (SynBio). However, key genome editing and recombineering tools require optimization and large-scale multiplexing to unlock the full SynBio potential of these bacteria. In addition, the limited availability of a set of characterized, species-specific biological parts hampers the construction of reliable genetic circuitry. Mining of currently available, diverse bacteriophages could complete the SynBio toolbox, as they constitute an unexplored treasure trove for fully adapted metabolic modulators and orthogonally-functioning parts, driven by the longstanding co-evolution between phage and host.
Similar content being viewed by others

Introduction
For decades, Escherichia coli, Bacillus subtilis, Saccharomyces cerevisiae and, to a lesser extent, Mycoplasma, have been the key reference models for synthetic biology (SynBio) and the go-to biological chassis for the implementation of genetic circuits. However, advances in metabolic and genome engineering enabled the exploration of non-traditional bacterial species as chassis, including Pseudomonas putida and Lactococcus lactis, for applications that extend far beyond the traditional biotechnology and food industry1.
In spite of the progress, these industrially relevant organisms remain underutilized, due to the relatively limited toolboxes available for the construction of synthetic genetic circuits. The general practice of utilizing genome-editing enzymes and expression systems from the extensive E. coli toolbox in other hosts often leads to unreliable results, pointing to the general problem of portability in SynBio. To fully unlock the potential of non-model bacteria for SynBio, a set of standardized and reliable biological parts is urgently required, tailored to the specific requirements needed to establish genetic circuits in these organisms.
These parts could be mined from bacterial viruses (bacteriophages), as phage-based parts and enzymes are, by definition, fully adapted to the non-model host due to the longstanding co-evolution between phage and bacteria. Indeed, the study of phage–host interactions and phage biology has been a vast source of inspiration for SynBio tools, including CRISPR-Cas9-based technologies, recombineering and numerous DNA-editing enzymes2, but has mainly focused on mining coliphages. In this Perspective, we discuss the potential of bacteriophages to address the lack of reliable, portable tools to bridge critical knowledge and application gaps, towards fully unlocking the potential of non-traditional bacteria for SynBio applications.
Rising stars in the field of synthetic biology
Several bacterial species have caught the attention of the SynBio community as potential biological chassis. This Perspective will focus on industrially relevant members of the Pseudomonas, Klebsiella, Bacillus, Lactococcus, and Mycobacterium genera, for which a significant number of phage genomes are available (Table 1). Moreover, these species cover different bacterial lifestyles and a wide range of SynBio applications. For instance, the Gram-negative root-colonizer P. putida is endowed with a highly versatile metabolism, a significant tolerance for endogenous and exogenous stresses and the capability to produce toxic, value-added compounds, including cis,cis-muconic acid, cinnamate, and p-coumarate3,4. Besides its natural capacity for bioremediation, P. putida is able to grow on structurally diverse carbon sources allowing engineered processing of abundant waste streams, such as lignocellulosic biomass and molasses4.
Apart from P. putida, other Gram-negative species are on their way to become valuable biological chassis. For example, the human pathogen Klebsiella pneumoniae has been recognized as an outstanding glycerol fermenter for value-added, reduced compounds (e.g. diols) and research towards a safe, non-pathogenic K. pneumoniae chassis is currently ongoing5. However, not only Gram-negative bacteria are popular hosts for SynBio. Gram-positive organisms, such as B. subtilis and L. lactis, are excellent producers and in vivo delivery vehicles for therapeutic products, including oral vaccines6. This is due to their lack of immunogenic lipopolysaccharides and their ‘Generally Regarded As Safe’ (GRAS) status conferred by the FDA6. In addition, B. subtilis shows good growth and robustness in industrial fermentations and possesses a superior capacity of protein secretion in comparison to other hosts, whereas L. lactis has become indispensable in the dairy industry as a fermenter and producer of flavouring and texturizing compounds6,7. Furthermore, other lesser-known Gram-positive bacteria show interesting features for SynBio applications. For example, Mycobacterium smegmatis, which is the non-pathogenic model organism for tuberculosis research, meets all the requirements to become a valuable production host for sterols8 and mycobacterial proteins9, which often form inclusion bodies when expressed in E. coli.
P. putida, B. subtilis, and L. lactis have all been successfully submitted to chassis optimization by removing energy-draining components and other unessential or destabilizing genome loci. This has resulted in the generation of several superior strains in terms of genetic stability and physiology for heterologous gene expression10,11,12. Additionally, industrially relevant co-utilization of carbon sources and improved metabolic activity under oxygen-limited conditions have been achieved through metabolic engineering efforts4,6,7,13. These engineering efforts will enable broader applications of these already industrially important strains. For more information on these organisms and their applications in SynBio, we refer the reader to recent reviews4,5,6,7,8,9.
Missing devices in the engineering toolbox of non-model bacteria
Tools for large-scale genome engineering are still in their infancy
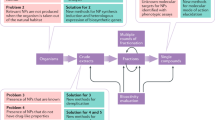
In the past two decades, the genome engineering scene has been revolutionized by ground-breaking advances in DNA-sequencing and RNA-sequencing, CRISPR-Cas9-based genome editing and innovative recombineering techniques. Metabolic and genome engineering of non-model organisms has come a long way and reliable tools for creating genetic deletions, insertions, and replacements are available4,6,7,14. However, large-scale reprogramming of cells is still a tedious and time-consuming undertaking, due to cycles of plasmid construction, multiple cloning steps, and inefficient plasmid curing. These problems were largely overcome in E. coli and related Enterobacterial species like K. pneumoniae, with the development of DNA recombineering and their derived, large-scale technologies including MAGE, DIvERGE, and TRMR (Box 1)15. While these technologies have been perfected for large-scale genome engineering of reference hosts, the upscaling of genome engineering for non-traditional microbes is trailing behind and often accompanied with unsatisfactory efficiencies. This can be explained by inadequate efficiencies of transformation methods and (counter)selection markers for non-model hosts. Moreover, the streamlined genomes of reference organisms and some key strains of P. putida, B. subtilis, and L. lactis allow for easy and efficient manipulation10,11,12, whereas the manipulation of alternative hosts and wild strains is hampered by native endonucleases and other interfering genomic loci. Furthermore, the specific physiology of non-enteric hosts prevents the direct transfer of E. coli-optimized technologies, thus requiring (often tedious and time-consuming) species-specific optimization. As an example, different strategies to boost recombination efficiencies of MAGE in non-model hosts are depicted in Fig. 1. Even with large efforts to implement and improve recombineering-based strategies in non-model hosts, these technologies are still in their infancy and further optimization is vital to allow these valuable bacterial strains to reach their full potential in the SynBio field.

1. Oligonucleotide design should be optimized to maximally avoid the host’s mismatch repair (MMR) system and to allow optimal functioning of the used ssDNA recombinase. 2. It has been shown that poor ssDNA uptake hampers the efficiency and multiplexing of recombineering-based techniques like MAGE and DIvERGE in P. putida21, L. lactis22, and M. smegmatis23. Optimization of transformation methods is therefore essential. 3. The main focus to boost recombination frequencies of MAGE has been put on the recombinase itself, as the state-of-the-art Red-β protein for recombineering in Enterobacteria shows varying functionality in other hosts153. Superior ssDNA recombinases have been identified from prophages for P. putida89, K. pneumoniae89, B. subtilis154, L. lactis22, and M. smegmatis153, but the recombination frequencies remain well below those reported for E. coli, which in turn limits large-scale, multiplexed engineering efforts. Moreover, the use of alternative recombinases requires time-consuming optimization of recombinase expression levels and oligonucleotide design21,89,153,154. 4. CRISPR-Cas-based counter-selection of wild-type sequences has boosted the recombineering efficiency in P. putida155, L. lactis156, and M. smegmatis157. However, the drawbacks of this approach are a the toxicity of the Cas-induced double-strand breaks158, b the necessity of a PAM sequence near the site of mutation, and c the limited number of different loci that can be simultaneously edited in this setup. 5 and 6. Inhibition of the native MMR system has been shown to increase homologous recombination frequencies in multiple non-traditional hosts21,22,159,160. Despite its success in E. coli, (transient) inhibition of the MMR system to improve recombineering has not been widely implemented, probably due to the fact that mechanistic details of MMR are still largely unknown. 7. Mutant selection is an experiment-specific step for both model and non-model hosts. The RNA icon was adapted from ‘waves Icon #459771’ by Dmitry Kovalev, from the nounproject.com.
Perfecting basic tools: learning how to walk before running
The principal requirement for efficient genome engineering of any host is a high-performance DNA transformation method, which is currently available for several non-model species, including P. putida16, L. lactis17, and B. subtilis18. In contrast, transformation of K. pneumoniae and M. smegmatis is much more difficult, as these two strains are endowed with an outer polysaccharide capsule and a thick waxy layer of mycolic acid in the cell wall, respectively19,20. This results in significantly reduced transformation efficiencies, in the range of only 104–105 transformants/µg DNA19,20. Since poor transformation performances will sabotage the efficacy of almost all genome-editing technologies, further optimization of transformation methods is absolutely essential. Moreover, most transformation methods have been optimized for effective uptake of plasmid DNA, whereas novel ssDNA and dsDNA recombineering techniques require efficient introduction of linear DNA. For instance, it has been shown that poor ssDNA uptake hampers the efficiency and multiplexing of recombineering-based techniques like MAGE and DIvERGE in P. putida21, L. lactis22, and M. smegmatis23 (Box 1). A valid alternative for bacterial electroporation is transduction, in which phage particles take up DNA from a donor cell and deliver it to a recipient via phage infection. Transduction has been shown to be a superior method to achieve DNA transfer in some species and wild strains, including Mycobacterium, for which it can mediate an almost 100% transduction efficiency14. However, despite this excellent efficiency, transduction is more time-consuming compared to electroporation as it requires the generation of transducing phages14.
Besides efficient transformation methods, markers for selection and counter-selection are indispensable in genome engineering. Antibiotic-based markers are the state-of-the-art for transformant selection and are readily available for almost all bacterial hosts. This contrasts the lack of high-performance counter-selection markers for some non-model hosts, including P. putida and M. smegmatis. For instance, the well-known levansucrase-encoding sacB gene from B. subtilis efficiently inhibits cell growth in E. coli and related species like K. pneumoniae in the presence of sucrose24. However, its use in other hosts sometimes requires very high sucrose concentrations (>10% w/v), thus exerting high osmotic stress and inducing spontaneous mutations in sacB25,26. To overcome this problem, novel counter-selection markers have been developed for several hosts inspired by the URA3 and upp selection systems from yeast and B. subtilis, respectively. Although these markers show improved performance over sacB in P. putida, their utilization is strictly dependent on deletion mutants, thus limiting their application range25,27. To circumvent this issue, a plasmid curing system for P. putida based on inducible I-SceI-based plasmid restriction and conditional plasmid replication has been developed and has demonstrated to be widely applicable, shortening downtime in genome engineering28. This system, however, is more complex than traditional counter-selection markers.
Urgent need for standards, norms, and regulations in synthetic biology
Apart from advances in genome and metabolic engineering techniques, the positive impact of standardization on the SynBio field should not be underestimated, as it boosts interoperability, reproducibility of results, and reduces redundant work29. Although the level of standardization within SynBio is still far below those of the hard sciences, large efforts led by the National Institute of Standards and Technology, the iGEM foundation and several other organizations are putting us on the right track for the future by the creation of biological part databases, software for circuit design and standards for data representation and communication29. However, standardized biological parts and constructs, transparent data sharing and standard operating procedures (SOPs) are largely missing for non-model species. This makes the construction of reliable genetic circuits in non-traditional microbes a process of mere trail-and-error.
The design of genetic circuitry generally starts with the selection of a suitable backbone for the construct. The development of the standard European vector architecture (SEVA) for Pseudomonas and other Gram-negative species constituted a pivotal point for the uniformity of vectors and standardization of biotechnological research30. The SEVA 3.0 database offers a wide array of replicative and integrative ‘SEVA plasmids’ following a uniform design and nomenclature, some of them endowed with expression systems that are commonly used by the Pseudomonas community31. Besides the SEVA repository, several databases are available with biological parts for both Gram-negative and Gram-positive organisms29, but unfortunately, dedicated parts and repositories for Gram-positive organisms remain scarce. In recent years, progress in this field has been made by developments including the iGEM Registry Probiotic Collection32 and the Bacillus BioBrick Box 2.033. Since their launching, hundreds of SEVA- and Bacillus BioBrick vectors have been requested and the original articles have received thousands of views, indicating the success and the need for dedicated databases for non-model hosts31,33.
The vast majority of parts have been developed for E. coli and are barely validated nor characterized in other hosts. Moreover, even for this reference strain species, standardization of parts is still an illusion, as no clear consensus exists on characterization protocols for parts, let alone on standard units for the quantification of transcriptional and translational activity29. Therefore, biological parts cannot be reliably compared and as a consequence, researchers still tend to construct genetic circuits with parts they are familiar with rather than those possessing the optimal features to reach their goal. The absence of standard units and SOPs has not gone unnoticed and several attempts have been made to implement these in the world of SynBio for processes like fluorescent-activated cell sorting, GFP quantification, and measurements of gene expression levels29. Unfortunately, they have not (yet) been generally adopted by the SynBio community.
In contrast to parts standardization, methods for standard assembly of bacterial genetic constructs are much more established. The development of the restriction enzyme-based BioBrick and BglBrick standards has laid the foundation for more sophisticated assembly methods based on the Type IIs restriction enzymes29, including Golden Gate assembly34, GoldenBraid 3.035, and protected oligo-nucleotide duplex-assisted cloning (PODAC)36. GoldenBraid and PODAC enable the generation of complex combinatorial libraries using position-specific 5′ and 3′ sequences of 4–8 nucleotides. The inherent downsides of these two techniques are the need for sequence modification to remove unwanted restriction sites and the creation of scars in between bricks, which, if reoccurring, could become hotspots for undesired recombination events29. Scarless and sequence-independent alternatives have been developed, including DATEL37 and Twin-Primer Assembly38, but they lack the possibility to quickly generate full or semi-random combinatorial libraries in multi-brick constructs, which is the principal strength of the aforementioned techniques. In summary, the first steps towards standardization have been taken in the field of SynBio with non-traditional hosts. To further unlock the SynBio potential of non-model microbes, there is an urgent need for a reliable, standardized, and well-characterized set of biological parts to build complex genetic circuitry.
Constructing novel genetic circuits: the sum is more than its parts
As our knowledge on metabolic engineering continues to increase, we have learned that balanced expression levels and feedback mechanisms often result in higher yields and healthier cell populations39. To reach these desired expression levels, predictable, robust, and tuneable genetic constructs are a must and can only be built from well-characterized, reliable, and context-independent biological parts as demonstrated by Nielsen et al. 40. Furthermore, more complex circuits require a set of analogous high-performance parts to avoid part reuse and unwanted recombination events between them. The available set of biological parts for non-model hosts is steadily expanding, but there is still a lack of much needed well-characterized, reliable, and orthogonal parts. A graphical summary of this section is provided in Fig. 2.

CRISPRi: CRISPR interference; RBS: ribosomal binding site; BCD: bicistronic design; sRNA: small RNA; asRNA: antisense RNA; STAR: small transcription activating RNA; The RNA, lightbulb, thermometer, and pH-meter icons were adapted from ‘waves Icon #459771’, ‘Light Icon #3393001’, ‘Thermometer Icon #342400’, and ‘ph meter Icon #3215400’ by Dmitry Kovalev, Vichanon Chaimsuk, Sarah Tan, and Vectors Point, respectively, from the nounproject.com.
Promoters as core devices to tune gene expression
The choice for a specific promoter for both model and non-model hosts is very application-dependent, but in general, desired promoter features are predictability, tunability, independence, orthogonality, and composability41. Constitutive promoters are the simplest subset of promoters and are the preferred choice for industrial-scale setups, due to their high reliability and a generally low context-dependency42. A set of (synthetic) constitutive promoters is available for several non-model bacteria with extensive fold ranges, including P. putida43, B. subtilis44, L. lactis45, K. pneumoniae46, and M. smegmatis47.
Inducible promoters offer the user an extra level of control in terms of modulating and inducing gene expression at defined timepoints. Although many expression systems optimized for E. coli have been successfully transferred to other hosts, their characterization and optimization is generally limited (with a few exceptions). Due to the high context-dependent response of most expression systems, predicting protein production levels is almost impossible. Tedious optimization cycles of genetic circuit constructions are therefore required. Additionally, selecting an expression system with the optimal features for one’s goal is difficult, since each of them suffers from specific drawbacks and a centralized reporting system for expression system performance is lacking. As an example, Table 2 indicates the advantages and drawbacks of the most common expression systems used in P. putida. Other relevant inducible systems for P. putida are summarized in Supplementary Table 1 with their respective advantages and disadvantages. For other non-model hosts, the reader is referred to complementary reviews9,44,48.
In contrast to the relatively large set of activators, the number of (characterized) repressors for P. putida is low and limits the construction of complex genetic feedback mechanisms for SynBio applications (Table 2 and Supplementary Table 1). In some applications, the lack of a suitable repressor can be substituted by CRISPR interference (CRISPRi) technology39. This technology enables the simultaneous, tunable, and transient repression of multiple genes by expression of gene-specific sgRNAs and a single nuclease-deficient Cas9 (dCas9) and has been successfully applied in P. putida49, M. smegmatis50, K. pneumoniae51, B. subtilis51, and L. lactis52 with up to 98% repression. Although this technique offers great potential, one must note that its efficiency and efficacy remains dependent on (1) the presence of a PAM sequence within or near the promoter region for efficient transcriptional repression, (2) the strengths and weaknesses of the expression system used for dCas9 expression, (3) the burden imposed by accumulation of a large heterologous protein (dCas9), and (4) polar effects such as the repression of downstream operons.
Despite the many advantages of chemical inducers as stated above, they are often costly, toxic, and do not allow easily switching off induction. Alternative induction methods based on light, pH, temperature, and quorum sensing overcome these issues and are steadily gaining popularity in the SynBio field (Supplementary Table 1). Moreover, several of these systems are available and optimized for non-model hosts, though the number stays well below those for E. coli. Examples include the optogenetic CcaSR system53,54, the thermosensitive cI857-PL system55,56, multiple quorum sensing-based expression systems57,58, and pH-regulated systems59.
Ribosomal-binding sites: highly important, often overlooked
The past few years, the potential of ribosomal-binding sites (RBS) to tune expression levels has received increased attention, leading to the development of high-end RBS calculation tools60 and RBS libraries for some non-model hosts, including P. putida21 and B. subtilis44. However, the performance of these RBS libraries is highly sequence-dependent, due to the formation of mRNA secondary structures at the 5′ end of the transcript, which potentially inhibit translation or cause instability of the mRNA60,61. To overcome this problem, a library of RBS elements with a bicistronic design (BCD) was created for E. coli62. The bicistronic layout consists of two Shine–Dalgarno (SD) sites: the first SD initiates translation of a leader peptide, which in his turn holds the second SD site in its coding sequence and allows translation of the downstream gene of interest (Fig. 2 (2)). Translation of the standard leader peptide will thus disrupt secondary mRNA structures of the second SD and/or gene of interest and allows more reliable, sequence-independent translation levels than traditional RBS libraries62. To our knowledge, this library has not been validated in one of the aforementioned hosts, but its BCD2 element has been deployed successfully in several genetic constructs for P. putida and the BCD concept has been tested with promising results in B. subtilis28,43,44,63.
Reliable transcriptional termination for qualitative genetic circuits
Proper insulation and termination of (synthetic) transcriptional units is key in genetic circuit design, as it avoids transcriptional read-through from the unit itself and interference from neighbouring promoters40. A set of potent terminators, and more specifically bidirectional terminators (Fig. 2 (3)), is therefore an essential part of the SynBio toolbox, leading to the development of characterized (synthetic) terminators and terminator prediction tools for B. subtilis and E. coli64,65. In contrast to initiation elements for which host-dependent performance has long been recognized, the set of optimized terminators for the Gram-negative and Gram-positive models E. coli and B. subtilis are often unduly considered to be generally functional in other hosts without validation. This results in poorly insulated circuits with all the undesired consequences thereof. For example, recent work demonstrated that the well-known rrnB-T1 terminator from E. coli does not fully repress gene expression in P. putida, despite its implementation in all SEVA vectors31,66. Furthermore, several E. coli-based algorithms were used to mine putative rho-independent terminators from environmental DNA for Pseudomonas species. All predicted terminators functioned in E. coli, but only a few showed strong termination in Pseudomonas, thus indicating that these tools can only be used to some extent for other hosts. Specific terminator prediction tools for non-model hosts do exist, such as GeSTer which is able to identify the typical U-trail lacking terminators of Mycobacterium, but they remain scarce67.
RNA-based and protein-based regulation are further to be explored
Besides the classical biological parts described above, RNA-based regulatory parts allow an additional level of regulation in genetic circuits and enable the construction of elegant logic gates68. These RNA-based regulatory parts include riboswitches, RNA thermometers, translation riboregulators, ribozymes, antisense RNAs, and small transcription activating RNAs (STARs) with several functions (Box 2) (Fig. 2 (4)). Their fast response times and minimal cell burden compared to protein-based systems have allowed RNA-based regulatory parts to become a valuable part of the E. coli SynBio toolbox68, but to date, their use in non-model hosts is still rare.
Riboswitches and RNA thermometers are often used in SynBio to tune expression levels in response to their cognate ligand69. For E. coli, genome-wide riboswitch identification, extensive characterization, optimization, and standardization of 5′ sequences have resulted in riboswitches with reliable functioning39,68. In contrast, these parts are not yet exploited as regulatory SynBio tools for non-model hosts. Moreover, the first riboswitches and RNA thermometers have only recently been characterized in vivo in non-traditional bacteria70,71,72,73, except for B. subtilis for which riboswitch research is more mature69. The trans-acting counterparts of riboswitches are called translation riboregulators or antisense RNAs and can be used for multiplexed genome-wide knock-down of gene expression39, but their utilization as biological parts in non-traditional hosts is still limited. This might change in the near future as a synthetic sRNA toolbox for P. putida has recently been developed74.
Another set of undervalued RNA-based parts are ribozymes, whose SynBio applications include the creation of variant logic gates and detecting systems and who have demonstrated their worth as insulators of RNA parts68. Only a few rare examples report the use of ribozymes as tools in non-models hosts, where they have shown their utility as a glucosamine-6-phosphate responsive switch, RNA insulators and as a tool for gene inactivation in B. subtilis, P. putida, and L. lactis, respectively75,76,77. Lastly, regulation of synthetic circuits by tuning protein degradation constitutes a third regulatory level next to transcriptional and translational regulation78, but remains underutilized in non-model hosts. However, in contrast to RNA-based regulation, several examples are already available of controlled and/or inducible proteolysis via protein tags and orthogonal proteolysis machinery44,66,78,79,80,81.
To conclude, biological parts for RNA-based and protein-based regulation are highly underexploited for non-model hosts. Characterization and development of these parts (within a standardized framework) will expand the SynBio toolboxes of non-model bacteria with tools for gene expression manipulation at multiple levels.
Phages are unexplored troves for synthetic biology tools and parts
From the inception of molecular biology, bacteriophages have proven to be indispensable tools to conduct biomolecular research2. Indeed, the billion-year-long ongoing evolutionary arms-race between bacteria and phages has resulted in the emergence of phage enzymes which modify the bacterial genome and the metabolism at different levels. These phage elements reshape the bacterial cell into a highly efficient phage-particle factory in a matter of minutes82. Currently, mostly the exploitation of coliphages has resulted in the development of SynBio tools including phage display, Gateway cloning, recombineering and the famous pET-expression system for recombinant protein production2. The diversification towards phages infecting other species could potentially expand and revolutionize their respective SynBio toolboxes for genome, metabolic, and even cell engineering. More specifically, the number of identified phages infecting Pseudomonas, Klebsiella, Bacillus, Lactococcus, and Mycobacterium genera is steadily rising (Table 1), as such, these phage genomes can be readily explored for novel parts and tools.
Efficient genome engineering using host-specific phage enzymes
Phage genomes encode many toxins to halt cellular growth, which have been successfully applied as treatments against bacterial infections including the engineered endolysin-based “Artilysins”83. Besides their obvious applications as antimicrobials, phage toxins can also be used in SynBio as (inducible) counter-selection markers for non-traditional hosts (Fig. 3 (1)). Notably, several of these toxic proteins are host-specific, such as gp8 and gp18 from Pseudomonas phage LUZ7, a potentially interesting feature for manipulation of expression vectors84. For instance, an expression vector which constitutively expresses a host-specific toxin, can be replicated easily in E. coli. After substituting the toxin for a gene of interest, the non-traditional expression host can be directly transformed with the recombinant vector, while the toxin counterselects against transformants carrying the unmodified vector85. The toxin thus allows to skip intermediate cloning steps to E. coli saving valuable time and effort. Apart from toxins, some phages encode antitoxins or toxin–antitoxin modules to bypass host-encoded abortive infection mechanisms86. These toxin–antitoxin pairs could be used to create plasmid-addiction systems or stabilize genomic inserts in situations where the use of antibiotics is undesirable or impossible, such as large bioreactors or human health applications (Fig. 3 (2)). The most well-known example of a phage-based addiction system is the phd-doc toxin–antitoxin module of temperate coliphage P187, but toxin–antitoxin modules have also been identified in prophages in other bacteria, including txpA/ratA, bsrG/sr4, and yonT/as-yonT in B. subtilis prophage elements88.

Phage proteins show high potential for use in genome engineering (left), manipulation of transcription and translation processes (middle) and cellular engineering (right). Besides phage proteins, phage genomes are a large source of orthogonally functioning biological parts for synthetic genetic circuitry (middle). The RNA, DNA, and bacteriophage icons were adapted from ‘waves Icon #459771’, ‘DNA Icon #3383522’, and ‘bacteriophage Icon #467715’ by Dmitry Kovalev, Muhammad Tajudin, and Dong Ik Seo, respectively, from the nounproject.com.
The discovery of integrases and recombinases from temperate phages have revolutionized the SynBio field and resulted in a myriad of genome engineering tools2. At first, these enzymes were primarily used for genomic integration of synthetic circuitry or to rearrange DNA segments (Fig. 3 (3 and 4)). Soon after, their application range was expanded to include combinatorial and reversible DNA assembly methods, various logic gates, analogue-to-digital converters, memory devices, and multiplexed DNA editing via recombineering (Fig. 3 (4 and 5))2. To date, the use of these versatile enzymes in non-model hosts has mostly remained limited to genomic integration tools and recombineering. The characterization of existing and novel integrases and recombinases from prophages will optimize the currently available recombinase-based tools for these bacteria89. Additionally, they will enable the implementation of more advanced applications, including the construction of complex logic gates and memory devices, thus allowing non-model hosts to reach their full potential as valuable biological chassis for SynBio applications.
Autographiviridae are a goldmine for orthogonal transcription
A specific family of phages, the Autographiviridae, encode their own transcriptional machinery for viral replication90. The archetype of this class is the well-known T7 phage, which has a small, single-subunit RNA polymerase (RNAP) and strong T7 promoters, RBSs and terminators, which have made their mark on the SynBio field2. Apart from the broad-use, fully orthogonal pET expression system for E. coli, several other T7-based applications emerged, such as AND-gates based on fragmented T7 RNAPs and a resource allocator2,91. So far, the use of the pET system in other hosts has been restricted by severe cytotoxicity of the T7 RNAP92. We argue that T7-like phages, like gh-1 and KPO1K2 infecting P. putida and K. pneumoniae, respectively93,94, should be explored as a source of similar orthogonal RNAPs and biological parts specifically tailored to their Gram-negative bacterial host, with reduced toxicity (Fig. 3 (6 and 7)). Beyond this family, the N4-like bacteriophages encode multiple phage RNAPs and corresponding RNAP-specific promoters, allowing a gradual shift from early to middle and late gene expression95. The timed aspect of this transcriptional scheme shows high potential for sequential gene expression in synthetic constructs.
In contrast to the Autographiviridae, other phage families are completely dependent on the host transcription machinery and use different strategies to regulate transcriptional expression. For one, Pseudomonas phage 14-1 and Bacillus phage SPO1 encode sigma factor-like proteins gp12 and gp28, respectively, to alter the RNAP’s promoter specificity towards phage-specific promoters96,97. These proteins, in combination with their native phage promoters, could be used to favour transcription of heterologous genes and at the same time avoid cellular stress due to overexpression by balancing the total transcriptional load, which is a common concern with the pET system (Fig. 3 (8))91. Secondly, temperate phages rely on transcriptional repressors for their lysogenic switch, which can be exploited for SynBio purposes like the cI and Cro repressors from coliphage λ (Fig. 3 (9))98. Besides repressors, also transcriptional activators have been identified in phage genomes, including ORF2 of Lactococcus phage phi3199. Thirdly, apart from transcriptional initiation, other steps in the protein production process are also prone to viral interference, which could inspire novel SynBio tools or interesting approaches to increase bioproduct yields. For example, phage mRNA translation is influenced by secondary mRNA structures, self-splicing introns, frameshifting and the remarkable translational bypassing phenomenon100, which could lead to novel translation regulatory tools. Programmed translational frameshifting is the process where a repeat of nucleotides allows the ribosome to slip and continue translation in a different reading frame, as observed in many dsDNA phages including Lactococcus phage Q54101. These viral frameshifting events could inspire synthetic programmed frameshift to generate signal splitters in genetic circuitry: e.g. the expression of one coding sequence results in two enzymes with different functioning102. The translational bypassing phenomenon has so far only been observed in coliphage T4, where the mRNA of gp60 contains a stretch of 50 non-coding nucleotides, but is still translated into a single polypeptide. Instead of dissociating from the gp60 mRNA when reaching the non-coding gap, the ribosome “glides” over this non-coding region and continues translation at the second coding region103. Further research on this phenomenon may indicate if engineered translational bypassing can be used in controlled expression of designer proteins103. Furthermore, RNA turnover is altered during phage infection by stabilizing viral mRNA via asRNA-masking of RNase E degradation sites or inhibition of the RNA degradosome, e.g. by Dip of Pseudomonas phage phiKZ104,105. These could potentially become interesting approaches to elevate mRNA abundance of a desired transcript and increase protein yield (Fig. 3 (10))106. Lastly, Pseudomonas phages EL and OBP and Bacillus phage AR9 promote protein folding with efficient phage chaperonins which do not require any additional co-factors107,108,109. These chaperonins can be co-expressed in industrial bioreactors to elevate soluble and functional levels of recombinant protein, a proven method for E. coli-based recombinant protein production using more complex bacterial chaperonins (Fig. 3 (11))110.
Beyond traditional engineering: phage-based cellular regulation
During phage infection, phages do not only alter transcription and translation-related processes as described above. They remodel the entire cell metabolism, core processes, and cell physiology to create an optimal environment for phage replication82. To do so, they have acquired high-end cell modulators, optimized to their host’s specific cell physiology. These modulators constitute a goldmine of revolutionary, strain-optimized tools to expand the SynBio toolbox, as we illustrate here using selected examples. First, when entering the cell, the phage protects itself from several host defence mechanisms by using anti-CRISPR proteins (Acr) or by integrating non-canonical nucleotides into their genome to avoid host restriction enzymes111,112. Since the discovery of Acr proteins in Pseudomonas phages, many other Acr proteins have been identified and used in a range of SynBio applications, including regulation of CRISPR-Cas-based tools at multiple stages, reduction of CRISPR-Cas toxicity and the development of Acr-based CRISPRi and selection markers (Fig. 3 (12))112. In contrast, the DNA manipulation enzymes still need to find their way to the in vivo SynBio field, but could for example be used to protect DNA sequences from nucleases in restriction-based DNA assembly methods. Apart from the host defence mechanisms, phages also raise their own defence systems against superinfection by rivalling phages, showing interesting features for SynBio applications. For instance, phage proteins, such as Tip from Pseudomonas phage D3112, have been identified which inhibit type IV pili-formation, a common adsorption site among phages, thus establishing superinfection exclusion113. These inhibitors could allow us to transiently inhibit twitching motility and manipulate biofilm formation to optimize microbial cell-factories in a more flexible manner, an approach already proven successful for Pseudomonas aeruginosa fuel cells (Fig. 3 (13))114.
After successful cell entry, the phage hijacks the cell’s metabolism to favour viral replication. Examples of altered metabolic pathways include the phosphate and nitrogen metabolism, photosynthesis, the pentose phosphate pathway, and nucleic acid synthesis82. For example, Pseudomonas phage phiKZ promotes the de novo synthesis of pyrimidine nucleotides by reprogramming the pyrimidine pathway with seven predicted modulators115. These metabolic modulators could aid to overcome bottlenecks in metabolic engineering or could indicate key targets of metabolic pathways (Fig. 3 (14)). Furthermore, bacteriophages secure their energy supply for phage-particle production by shutting down non-essential energy-draining processes such as host transcription, DNA replication, and cell division116,117. In a similar fashion, these inhibitory proteins could be used to uncouple cellular growth from protein production to maximize substrate-to-product conversion and product yield in bioreactors, as demonstrated successfully in E. coli118. In conclusion, phage genomes are an underexploited treasure trove of metabolic modulators and cellular engineering tools, which could allow us to efficiently manipulate cells on multiple levels and revolutionize the SynBio toolbox.
Concluding remarks and outlook
In recent years, several alternative bacterial hosts for SynBio applications have emerged alongside E. coli, the reference Gram-negative bacterium for such purposes. With further optimization, these hosts could be developed into an established set of biological chassis with an ideal option for every possible SynBio application. To reach this goal, perfecting current genome engineering technologies, creating biological standards and optimizing and expanding the set of biological parts, tailored to each host, are absolutely essential. Bacteriophages are not only a vast source of potential host-specific biological parts and genome engineering tools, their genomes also encode many metabolic modulators and other interesting enzymes for directed cell manipulation, which can extend and revolutionize the SynBio toolbox2,82. These phage genomes are becoming increasingly available and can be readily exploited for Pseudomonas, Klebsiella, Bacillus, Lactococcus and Mycobacterium genera (Table 1). In contrast, for other industrially relevant species (including the ultrafast-growing and upcoming host Vibrio natriegens119), the number of identified phages is still extremely low, thus limiting the SynBio potential of phages for these species for the time being.
To date, protein expression levels are mostly manipulated on the transcriptional level. However, recent research has revealed the importance of the amino acid composition of N-terminal and C-terminal protein regions, post-translational modifications (PTMs) and cellular spatial organization on protein expression, stability, and enzymatic activity120,121,122,123,124. These novel approaches to tune expression levels could soon constitute a new generation of established SynBio tools for reference bacteria. Interestingly, phages employ these strategies naturally to regulate expression levels and manipulate the cell, and could be exploited in phage-based SynBio tools for multilevel cellular engineering in the future. In contrast to regulation of transcription and translation, PTMs allow a very quick adaptation of protein function, localization, or stability to a changing environment124. In spite of this major advantage, the manipulation of PTMs for SynBio purposes remains limited due to the difficulty to alter specific PTMs in vivo. The use of phage kinases and acetylases could facilitate PTM engineering in the future, as such enzymes have been discovered to specifically manipulate host proteins of metabolic pathways and host defence mechanisms (Fig. 3 (14))125,126.
Some phages build their own cytoskeleton to centrally position their genome in the host to optimize phage-particle production127. To our knowledge, physical positioning of DNA as an optimization strategy for recombinant protein production is unknown territory so far, but could significantly increase protein yields in the future (Fig. 3 (15)). Furthermore, it has been proposed that jumbo phages encapsulate their genome in a nucleus-like proteinaceous shell upon cell entry to evade CRISPR-Cas128. Similar strategies including synthetic physical encapsulation or co-localization of enzymes via scaffold molecules have already proven effective to protect molecules from degradation by host enzymes and, moreover, to increase metabolic flux and reduce cross-talk122,123. By further studying phage encapsulation and shell proteins, this could lead to improved synthetic encapsulation and co-localization of enzymes (Fig. 3 (16)).
On a critical note, one potential limitation of phage-based parts and tools is that they are mostly species-specific, thus limiting portability to other species. However, recent examples indicate that some phage recombinases may display broad host specificity89. Rather than solving the portability issue within SynBio, we call for caution when using E. coli-optimized tools blindly in other hosts and promote the development of host-specific toolboxes instead. Furthermore, while several examples of potential novel tools have been proposed and discussed here, it should be obvious that we have only just scratched the surface of the potential bacteriophages hold for SynBio. Indeed, the majority of world’s bacteriophages remains unidentified and up to 40–90% of viral sequences cannot be aligned129. The functional potential to be found in this ‘viral dark matter’ is boundless and one can only imagine the great innovations that remain to be discovered.
References
Calero, P. & Nikel, P. I. Chasing bacterial chassis for metabolic engineering: a perspective review from classical to non-traditional microorganisms. Microb. Biotechnol. 12, 98–124 (2019).
Lemire, S., Yehl, K. M. & Lu, T. K. Phage-based applications in synthetic biology. Annu. Rev. Virol. 5, 453–476 (2018).
Nadeem, S. M. et al. Potential, limitations and future prospects of Pseudomonas spp. for sustainable agriculture and environment: a review. Soil Environ. 35, 106–145 (2016).
Nikel, P. I. & de Lorenzo, V. Pseudomonas putida as a functional chassis for industrial biocatalysis: from native biochemistry to trans-metabolism. Metab. Eng. 50, 142–155 (2018).
Kumar, V. & Park, S. Potential and limitations of Klebsiella pneumoniae as a microbial cell factory utilizing glycerol as the carbon source. Biotechnol. Adv. 36, 150–167 (2018).
van Tilburg, A. Y., Cao, H., van der Meulen, S. B., Solopova, A. & Kuipers, O. P. Metabolic engineering and synthetic biology employing Lactococcus lactis and Bacillus subtilis cell factories. Curr. Opin. Biotechnol. 59, 1–7 (2019).
Liu, Y., Liu, L., Li, J., Du, G. & Chen, J. Synthetic biology toolbox and chassis development in Bacillus subtilis. Trends Biotechnol. 37, 548–562 (2019).
Galán, B. et al. Mycobacterium smegmatis is a suitable cell factory for the production of steroidic synthons. Microb. Biotechnol. 10, 138–150 (2017).
Bashiri, G. & Baker, E. N. Production of recombinant proteins in Mycobacterium smegmatis for structural and functional studies. Protein Sci. 24, 1–10 (2015).
Martínez-García, E., Nikel, P. I., Aparicio, T. & de Lorenzo, V. Pseudomonas 2.0: genetic upgrading of P. putida KT2440 as an enhanced host for heterologous gene expression. Microb. Cell Fact. 13, 1–15 (2014).
Reuß, D. R. et al. Large-scale reduction of the Bacillus subtilis genome: Consequences for the transcriptional network, resource allocation, and metabolism. Genome Res. 27, 289–299 (2017).
Zhu, D. et al. Enhanced heterologous protein productivity by genome reduction in Lactococcus lactis NZ9000. Microb. Cell Fact. 16, 1–13 (2017).
Nikel, P. I. & de Lorenzo, V. Engineering an anaerobic metabolic regime in Pseudomonas putida KT2440 for the anoxic biodegradation of 1,3-dichloroprop-1-ene. Metab. Eng. 15, 98–112 (2013).
Borgers, K., Vandewalle, K., Festjens, N. & Callewaert, N. A guide to Mycobacterium mutagenesis. FEBS J. 286, 3757–3774 (2019).
Simon, A. J., D’Oelsnitz, S. & Ellington, A. D. Synthetic evolution. Nat. Biotechnol. 37, 730–743 (2019).
Choi, K. H., Kumar, A. & Schweizer, H. P. A 10-min method for preparation of highly electrocompetent Pseudomonas aeruginosa cells: application for DNA fragment transfer between chromosomes and plasmid transformation. J. Microbiol. Methods 64, 391–397 (2006).
Papagianni, M., Avramidis, N. & Filioussis, G. High efficiency electrotransformation of Lactococcus lactis spp. lactis cells pretreated with lithium acetate and dithiothreitol. BMC Biotechnol. 7, 1–6 (2007).
Zhang, X. Z. & Zhang, Y. H. P. Simple, fast and high-efficiency transformation system for directed evolution of cellulase in Bacillus subtilis. Microb. Biotechnol. 4, 98–105 (2011).
Fournet-Fayard, S., Joly, B. & Forestier, C. Transformation of wild type Klebsiella pneumoniae with plasmid DNA by electroporation. J. Microbiol. Methods 24, 49–54 (1995).
Datey, A., Subburaj, J., Gopalan, J. & Chakravortty, D. Mechanism of transformation in mycobacteria using a novel shockwave assisted technique driven by in-situ generated oxyhydrogen. Sci. Rep. 7, 1–11 (2017).
Aparicio, T., Nyerges, A., Martínez-García, E. & de Lorenzo, V. High-efficiency multi-site genomic editing of Pseudomonas putida through thermoinducible ssDNA recombineering. iScience 23, 100946 (2020). This research article is the first to report efficient multiplexed genome engineering in Pseudomonas putida, by combining several host-specific optimization strategies for multiplexed recombineering.
Van Pijkeren, J. P. & Britton, R. A. High efficiency recombineering in lactic acid bacteria. Nucleic Acids Res. 40, 1–13 (2012).
Murphy, K. C. et al. ORBIT: a new paradigm for genetic engineering of mycobacterial chromosomes. MBio 9, 1–20 (2018).
Gay, P. et al. Positive selection procedure for entrapment of insertion sequence elements in Gram-negative bacteria. J. Bacteriol. 164, 918–921 (1985).
Galvão, T. C. & de Lorenzo, V. Adaptation of the yeast URA3 selection system to Gram-negative bacteria and generation of a ΔbetCDE Pseudomonas putida strain. Appl. Environ. Microbiol. 71, 883–892 (2005).
Pelicic, V., Reyrat, J. M. & Gicquel, B. Expression of the Bacillus subtilis sacB gene confers sucrose sensitivity on Mycobacteria. J. Bacteriol. 178, 1197–1199 (1996).
Graf, N. & Altenbuchner, J. Development of a method for markerless gene deletion in Pseudomonas putida. Appl. Environ. Microbiol. 77, 5549–5552 (2011).
Volke, D. C., Friis, L., Wirth, N. T., Turlin, J. & Nikel, P. I. Synthetic control of plasmid replication enables target- and self-curing of vectors and expedites genome engineering of Pseudomonas putida. Metab. Eng. Commun. 10, e00126 (2020).
Decoene, T. et al. Standardization in synthetic biology: an engineering discipline coming of age. Crit. Rev. Biotechnol. 38, 647–656 (2018).
Silva-Rocha, R. et al. The Standard European Vector Architecture (SEVA): a coherent platform for the analysis and deployment of complex prokaryotic phenotypes. Nucleic Acids Res. 41, 666–675 (2013). The development of the modular SEVA vectors constitutes a major step in the standardization of SynBio research in Gram-negative hosts.
Martínez-García, E. et al. SEVA 3.0: an update of the Standard European Vector Architecture for enabling portability of genetic constructs among diverse bacterial hosts. Nucleic Acids Res. 48, D1164–D1170 (2020).
Pedrolli, D. B. et al. Engineering microbial living therapeutics: the synthetic biology toolbox. Trends in biotechnology 37, 100–115 (2019).
Popp, P. F., Dotzler, M., Radeck, J., Bartels, J. & Mascher, T. The Bacillus BioBrick Box 2.0: expanding the genetic toolbox for the standardized work with Bacillus subtilis. Sci. Rep. 7, 1–13 (2017).
Engler, C., Kandzia, R. & Marillonnet, S. A one pot, one step, precision cloning method with high throughput capability. PLoS ONE 3, e3647 (2008).
Vazquez-Vilar, M. et al. GB3.0: a platform for plant bio-design that connects functional DNA elements with associated biological data. Nucleic Acids Res. 45, 2196–2209 (2017).
Van Hove, B., Guidi, C., De Wannemaeker, L., Maertens, J. & De Mey, M. Recursive DNA assembly using protected oligonucleotide duplex assisted cloning (PODAC). ACS Synth. Biol. 6, 943–949 (2017).
Jin, P., Ding, W., Du, G., Chen, J. & Kang, Z. DATEL: A Scarless and sequence-independent DNA assembly method using thermostable exonucleases and ligase. ACS Synth. Biol. 5, 1028–1032 (2016).
Liang, J., Liu, Z., Low, X. Z., Ang, E. L. & Zhao, H. Twin-primer non-enzymatic DNA assembly: an efficient and accurate multi-part DNA assembly method. Nucleic Acids Res. 45, e94 (2017).
Kent, R. & Dixon, N. Contemporary tools for regulating gene expression in bacteria. Trends Biotechnol. 38, 316–333 (2020).
Nielsen, A. A. K. et al. Genetic circuit design automation. Science 352, aac7341 (2016).
Lucks, J. B., Qi, L., Whitaker, W. R. & Arkin, A. P. Toward scalable parts families for predictable design of biological circuits. Curr. Opin. Microbiol. 11, 567–573 (2008).
Gilman, J. & Love, J. Synthetic promoter design for new microbial chassis. Biochem. Soc. Trans. 44, 731–737 (2016).
Zobel, S. et al. Tn7-based device for calibrated heterologous gene expression in Pseudomonas putida. ACS Synth. Biol. 4, 1341–1351 (2015).
Guiziou, S. et al. A part toolbox to tune genetic expression in Bacillus subtilis. Nucleic Acids Res. 44, 7495–7508 (2016).
Zhu, D. et al. Isolation of strong constitutive promoters from Lactococcus lactis subsp. lactis N8. FEMS Microbiol. Lett. 362, 1–6 (2015).
Jiang, X. et al. Vector promoters used in Klebsiella pneumoniae. Biotechnol. Appl. Biochem. 63, 734–739 (2016).
Spratt, J. M., Britton, W. J. & Triccas, J. A. Identification of strong promoter elements of Mycobacterium smegmatis and their utility for foreign gene expression in mycobacteria. FEMS Microbiol. Lett. 224, 139–142 (2003).
Kok, J. et al. The evolution of gene regulation research in Lactococcus lactis. FEMS Microbiol. Rev. 41, S220–S243 (2017).
Batianis, C. et al. An expanded CRISPRi toolbox for tunable control of gene expression in Pseudomonas putida. Microb. Biotechnol. 13, 368–385 (2020).
Rock, J. M. et al. Programmable transcriptional repression in mycobacteria using an orthogonal CRISPR interference platform. Nat. Microbiol. 2, 1–9 (2017).
Peters, J. M. et al. Enabling genetic analysis of diverse bacteria with Mobile-CRISPRi. Nat. Microbiol. 4, 244–250 (2019).
Berlec, A., Škrlec, K., Kocjan, J., Olenic, M. & Štrukelj, B. Single plasmid systems for inducible dual protein expression and for CRISPR-Cas9/CRISPRi gene regulation in lactic acid bacterium Lactococcus lactis. Sci. Rep. 8, 1–11 (2018).
Hueso-Gil, A., Nyerges, Á., Pál, C., Calles, B. & de Lorenzo, V. Multiple-site diversification of regulatory sequences enables interspecies operability of genetic devices. ACS Synth. Biol. 9, 104–114 (2020).
Castillo-Hair, S. M., Baerman, E. A., Fujita, M., Igoshin, O. A. & Tabor, J. J. Optogenetic control of Bacillus subtilis gene expression. Nat. Commun. 10, 1–11 (2019).
Aparicio, T., de Lorenzo, V. & Martínez-García, E. Improved thermotolerance of genome-reduced Pseudomonas putida EM42 enables effective functioning of the PL/cI857 system. Biotechnol. J. 14, 1–8 (2019).
Serrano-Heras, G., Salas, M. & Bravo, A. A new plasmid vector for regulated gene expression in Bacillus subtilis. Plasmid 54, 278–282 (2005).
Meyers, A., Furtmann, C., Gesing, K., Tozakidis, I. E. P. & Jose, J. Cell density-dependent auto-inducible promoters for expression of recombinant proteins in Pseudomonas putida. Microb. Biotechnol. 12, 1003–1013 (2019).
Guan, C. et al. Construction and development of an auto-regulatory gene expression system in Bacillus subtilis. Microb. Cell Fact. 14, 1–15 (2015).
Jørgensen, C. M., Vrang, A. & Madsen, S. M. Recombinant protein expression in Lactococcus lactis using the P170 expression system. FEMS Microbiol. Lett. 351, 170–178 (2014).
Salis, H. M., Mirsky, E. A. & Voigt, C. A. Automated design of synthetic ribosome binding sites to control protein expression. Nat. Biotechnol. 27, 946–950 (2009). This research article highlights the importance of synthetic ribosomal binding site design to create genetic circuitry with reliable and predictable expression levels.
Espah Borujeni, A. et al. Precise quantification of translation inhibition by mRNA structures that overlap with the ribosomal footprint in N-terminal coding sequences. Nucleic Acids Res. 45, 5437–5448 (2017).
Mutalik, V. K. et al. Precise and reliable gene expression via standard transcription and translation initiation elements. Nat. Methods 10, 354–360 (2013).
Wirth, N. T., Kozaeva, E. & Nikel, P. I. Accelerated genome engineering of Pseudomonas putida by I-SceI―mediated recombination and CRISPR-Cas9 counterselection. Microb. Biotechnol. 13, 233–249 (2019).
Engstrom, M. D. & Pfleger, B. F. Transcription control engineering and applications in synthetic biology. Synth. Syst. Biotechnol. 2, 176–191 (2017).
de Hoon, M. J. L., Makita, Y., Nakai, K. & Miyano, S. Prediction of transcriptional terminators in Bacillus subtilis and related species. PLoS Comput. Biol. 1, e25 (2005).
Amarelle, V., Sanches-Medeiros, A., Silva-Rocha, R. & Guazzaroni, M. E. Expanding the toolbox of broad host-range transcriptional terminators for Proteobacteria through metagenomics. ACS Synth. Biol. 8, 647–654 (2019).
Mitra, A., Angamuthu, K. & Nagaraja, V. Genome-wide analysis of the intrinsic terminators of transcription across the genus Mycobacterium. Tuberculosis 88, 566–575 (2008).
Kushwaha, M., Rostain, W., Prakash, S., Duncan, J. N. & Jaramillo, A. Using RNA as molecular code for programming cellular function. ACS Synth. Biol. 5, 795–809 (2016).
Hallberg, Z. F., Su, Y., Kitto, R. Z. & Hammond, M. C. Engineering and in vivo applications of riboswitches. Annu. Rev. Biochem. 86, 515–539 (2017).
Noll, P. et al. Evaluating temperature-induced regulation of a ROSE-like RNA-thermometer for heterologous rhamnolipid production in Pseudomonas putida KT2440. AMB Express 9, 154 (2019).
Hernandez-Valdes, J. A., van Gestel, J. & Kuipers, O. P. A riboswitch gives rise to multi-generational phenotypic heterogeneity in an auxotrophic bacterium. Nat. Commun. 11, 1–13 (2020).
Van Vlack, E. R. & Seeliger, J. C. Using riboswitches to regulate gene expression and define gene function in mycobacteria. Methods Enzymol. 550, 251–265 (2015).
Palou-Mir, J., Musiari, A., Sigel, R. K. O. & Barceló-Oliver, M. Characterization of the full-length btuB riboswitch from Klebsiella pneumoniae. J. Inorg. Biochem. 160, 106–113 (2016).
Apura, P. et al. Tailor-made sRNAs: a plasmid tool to control the expression of target mRNAs in Pseudomonas putida. Plasmid 109, 102503 (2020).
Otto, M. et al. Targeting 16S rDNA for stable recombinant gene expression in Pseudomonas. ACS Synth. Biol. 8, 1901–1912 (2019).
Niu, T. et al. Engineering a glucosamine-6-phosphate responsive glmS ribozyme switch enables dynamic control of metabolic flux in Bacillus subtilis for overproduction of N-acetylglucosamine. ACS Synth. Biol. 7, 2423–2435 (2018).
Fiola, K., Perreault, J. P. & Cousineau, B. Gene targeting in the Gram-positive bacterium Lactococcus lactis, using various delta ribozymes. Appl. Environ. Microbiol. 72, 869–879 (2006).
Cameron, D. E. & Collins, J. J. Tunable protein degradation in bacteria. Nat. Biotechnol. 32, 1276–1281 (2014).
Volke, D. C., Turlin, J., Mol, V. & Nikel, P. I. Physical decoupling of XylS/Pm regulatory elements and conditional proteolysis enable precise control of gene expression in Pseudomonas putida. Microb. Biotechnol. 13, 222–232 (2019).
Kim, J. H. et al. Protein inactivation in mycobacteria by controlled proteolysis and its application to deplete the beta subunit of RNA polymerase. Nucleic Acids Res. 39, 2210–2220 (2011).
Durante-Rodríguez, G., De Lorenzo, V. & Nikel, P. I. A post-translational metabolic switch enables complete decoupling of bacterial growth from biopolymer production in engineered Escherichia coli. ACS Synth. Biol. 7, 2686–2697 (2018).
De Smet, J., Hendrix, H., Blasdel, B. G., Danis-Wlodarczyk, K. & Lavigne, R. Pseudomonas predators: understanding and exploiting phage-host interactions. Nat. Rev. Microbiol. 15, 517–530 (2017). This review provides a comprehensive overview on the state-of-the-art concerning phage-encoded proteins impacting the bacterial metabolism.
Briers, Y. et al. Engineered endolysin-based “Artilysins” to combat multidrug-resistant Gram-negative pathogens. MBio 5, e01379–14 (2014). Enzyme-based antibacterials have huge potential as complements to antibiotic use. This research paper provides a novel concept in tackling Gram-negative pathogens using designer enzymes.
Wagemans, J. et al. Functional elucidation of antibacterial phage ORFans targeting Pseudomonas aeruginosa. Cell. Microbiol. 16, 1822–1835 (2014).
Bernard, P., Gabant, P., Bahassi, E. M. & Couturier, M. Positive-selection vectors using the F plasmid ccdB killer gene. Gene 148, 71–74 (1994).
Otsuka, Y. & Yonesaki, T. Dmd of bacteriophage T4 functions as an antitoxin against Escherichia coli LsoA and RnlA toxins. Mol. Microbiol. 83, 669–681 (2012).
Lehnherr, H., Maguin, E., Jafri, S. & Yarmolinsky, M. B. Plasmid addiction genes of bacteriophage P1: doc, which causes cell death on curing of prophage, and phd, which prevents host death when prophage is retained. J. Mol. Biol. 233, 414–428 (1993).
Durand, S., Jahn, N., Condon, C. & Brantl, S. Type I toxin–antitoxin systems in Bacillus subtilis. RNA Biol. 9, 1491–1497 (2012).
Wannier, T. M. et al. Improved bacterial recombineering by parallelized protein discovery. Proc. Natl Acad. Sci. USA 117, 202001588 (2020).
Adriaenssens, E. M. et al. Taxonomy of prokaryotic viruses: 2018–2019 update from the ICTV Bacterial and Archaeal Viruses Subcommittee. Arch. Virol. 165, 1253–1260 (2020).
Segall‐Shapiro, T. H., Meyer, A. J., Ellington, A. D., Sontag, E. D. & Voigt, C. A. A ‘resource allocator’ for transcription based on a highly fragmented T7 RNA polymerase. Mol. Syst. Biol. 10, 742 (2014).
Liang, X., Li, C., Wang, W. & Li, Q. Integrating T7 RNA polymerase and its cognate transcriptional units for a host-independent and stable expression system in single plasmid. ACS Synth. Biol. 7, 1424–1435 (2018).
Kovalyova, I. V. & Kropinski, A. M. The complete genomic sequence of lytic bacteriophage gh-1 infecting Pseudomonas putida—evidence for close relationship to the T7 group. Virology 311, 305–315 (2003).
Verma, V., Harjai, K. & Chhibber, S. Characterization of a T7-Like lytic bacteriophage of Klebsiella pneumoniae b5055: a potential therapeutic agent. Curr. Microbiol. 59, 274–281 (2009).
Lenneman, B. R. & Rothman-Denes, L. B. Structural and biochemical investigation of bacteriophage N4-encoded RNA polymerases. Biomolecules 5, 647–667 (2015).
Van Den Bossche, A. et al. Systematic identification of hypothetical bacteriophage proteins targeting key protein complexes of Pseudomonas aeruginosa. J. Proteome Res. 13, 4446–4456 (2014). Concept research paper that identifies phage-encoded modulators of key bacterial protein complexes.
Fox, T. D., Losick, R. & Pero, J. Regulatory gene 28 of bacteriophage SPO1 codes for a phage-induced subunit of RNA polymerase. J. Mol. Biol. 101, 427–433 (1976).
Kotula, J. W. et al. Programmable bacteria detect and record an environmental signal in the mammalian gut. Proc. Natl Acad. Sci. USA 111, 4838–4843 (2014).
Walker, S. A. & Klaenhammer, T. R. Molecular characterization of a phage-inducible middle promoter and its transcriptional activator from the lactococcal bacteriophage Φ31. J. Bacteriol. 180, 921–931 (1998).
Kutter, E., Raya, R. & Carlson, K. Phage-related RNA: structures and unexpected functions. In Bacteriophages: Biology and Applications (eds. Kutter, E. & Sulakvelidze, A.) Ch. 7.6, 197–200 (CRC Press, 2004).
Fortier, L. C., Bransi, A. & Moineau, S. Genome sequence and global gene expression of Q54, a new phage species linking the 936 and c2 phage species of Lactococcus lactis. J. Bacteriol. 188, 6101–6114 (2006).
Dinman, J. D. Translational recoding signals: expanding the synthetic biology toolbox. J. Biol. Chem. 294, 7537–7545 (2019).
Samatova, E., Konevega, A. L., Wills, N. M., Atkins, J. F. & Rodnina, M. V. High-efficiency translational bypassing of non-coding nucleotides specified by mRNA structure and nascent peptide. Nat. Commun. 5, 4459 (2014).
Stazic, D., Lindell, D. & Steglich, C. Antisense RNA protects mRNA from RNase E degradation by RNA–RNA duplex formation during phage infection. Nucleic Acids Res. 39, 4890–4899 (2011).
Van den Bossche, A. et al. Structural elucidation of a novel mechanism for the bacteriophage-based inhibition of the RNA degradosome. Elife 5, 1–20 (2016).
Neves, D., Vos, S., Blank, L. M. & Ebert, B. E. Pseudomonas mRNA 2.0: boosting gene expression through enhanced mRNA stability and translational efficiency. Front. Bioeng. Biotechnol. 7, 1–11 (2020).
Kurochkina, L. P. et al. Expression and functional characterization of the first bacteriophage-encoded chaperonin. J. Virol. 86, 10103–10111 (2012).
Semenyuk, P. I., Orlov, V. N., Sokolova, O. S. & Kurochkina, L. P. New GroEL-like chaperonin of bacteriophage OBP Pseudomonas fluorescens suppresses thermal protein aggregation in an ATP-dependent manner. Biochem. J. 473, 2383–2393 (2016).
Semenyuk, P. I., Moiseenko, A. V., Sokolova, O. S., Muronetz, V. I. & Kurochkina, L. P. Structural and functional diversity of novel and known bacteriophage-encoded chaperonins. Int. J. Biol. Macromol. 157, 544–552 (2020).
Yan, X., Hu, S., Guan, Y. X. & Yao, S. J. Coexpression of chaperonin GroEL/GroES markedly enhanced soluble and functional expression of recombinant human interferon-gamma in Escherichia coli. Appl. Microbiol. Biotechnol. 93, 1065–1074 (2012).
Weigele, P. & Raleigh, E. A. Biosynthesis and function of modified bases in bacteria and their viruses. Chem. Rev. 116, 12655–12687 (2016).
Marino, N. D., Pinilla-Redondo, R., Csörgő, B. & Bondy-Denomy, J. Anti-CRISPR protein applications: natural brakes for CRISPR-Cas technologies. Nat. Methods 17, 471–479 (2020). This concept manuscript highlights a new layer of phage-based regulation of the CRISPR-Cas system.
Chung, I. Y., Jang, H. J., Bae, H. W. & Cho, Y. H. A phage protein that inhibits the bacterial ATPase required for type IV pilus assembly. Proc. Natl Acad. Sci. USA 111, 11503–11508 (2014).
Shreeram, D. D. et al. Effect of impaired twitching motility and biofilm dispersion on performance of Pseudomonas aeruginosa-powered microbial fuel cells. J. Ind. Microbiol. Biotechnol. 45, 103–109 (2018).
De Smet, J. et al. High coverage metabolomics analysis reveals phage-specific alterations to Pseudomonas aeruginosa physiology during infection. ISME J. 10, 1823–1835 (2016). This comparative metabolomics research paper highlights the diverse impact phages have on the bacterial metabolites.
Conter, A., Bouché, J. P. & Dassain, M. Identification of a new inhibitor of essential division gene ftsZ as the kil gene of defective prophage Rac. J. Bacteriol. 178, 5100–5104 (1996).
Yano, S. T. & Rothman-Denes, L. B. A phage-encoded inhibitor of Escherichia coli DNA replication targets the DNA polymerase clamp loader. Mol. Microbiol. 79, 1325–1338 (2011).
Stargardt, P., Feuchtenhofer, L., Cserjan-Puschmann, M., Striedner, G. & Mairhofer, J. Bacteriophage inspired growth-decoupled recombinant protein production in Escherichia coli. ACS Synth. Biol. 9, 1336–1348 (2020).
Hoff, J. et al. Vibrio natriegens: an ultrafast-growing marine bacterium as emerging synthetic biology chassis. Environ. Microbiol. (2020). Online ahead of print.
Verma, M. et al. A short translational ramp determines the efficiency of protein synthesis. Nat. Commun. 10, 1–15 (2019).
Weber, M. et al. Impact of C-terminal amino acid composition on protein expression in bacteria. Mol. Syst. Biol. 16, 1–19 (2020).
Young, E. J. et al. Engineering the bacterial microcompartment domain for molecular scaffolding applications. Front. Microbiol. 8, 1–9 (2017).
Hagen, A., Sutter, M., Sloan, N. & Kerfeld, C. A. Programmed loading and rapid purification of engineered bacterial microcompartment shells. Nat. Commun. 9, 1–10 (2018).
Macek, B. et al. Protein post-translational modifications in bacteria. Nat. Rev. Microbiol. 17, 651–664 (2019).
Dong, L. et al. An anti-CRISPR protein disables type V Cas12a by acetylation. Nat. Struct. Mol. Biol. 26, 308–314 (2019).
Gone, S. & Nicholson, A. W. Bacteriophage T7 protein kinase: site of inhibitory autophosphorylation, and use of dephosphorylated enzyme for efficient modification of protein in vitro. Protein Expr. Purif. 85, 218–223 (2012).
Kraemer, J. A. et al. A phage tubulin assembles dynamic filaments by an atypical mechanism to center viral DNA within the host cell. Cell 149, 1488–1499 (2012).
Malone, L. M. et al. A jumbo phage that forms a nucleus-like structure evades CRISPR–Cas DNA targeting but is vulnerable to type III RNA-based immunity. Nat. Microbiol. 5, 48–55 (2020).
Krishnamurthy, S. R. & Wang, D. Origins and challenges of viral dark matter. Virus Res. 239, 136–142 (2017).
Borrero-de Acuña, J. M., Hidalgo-Dumont, C., Pacheco, N., Cabrera, A. & Poblete-Castro, I. A novel programmable lysozyme-based lysis system in Pseudomonas putida for biopolymer production. Sci. Rep. 7, 1–11 (2017).
Dammeyer, T. et al. Efficient production of soluble recombinant single chain Fv fragments by a Pseudomonas putida strain KT2440 cell factory. Microb. Cell Fact. 10, 1–8 (2011).
Calero, P., Jensen, S. I. & Nielsen, A. T. Broad-host-range ProUSER vectors enable fast characterization of inducible promoters and optimization of p-coumaric acid production in Pseudomonas putida KT2440. ACS Synth. Biol. 5, 741–753 (2016).
Silva-Rocha, R., de Jong, H., Tamames, J. & de Lorenzo, V. The logic layout of the TOL network of Pseudomonas putida pWW0 plasmid stems from a metabolic amplifier motif (MAM) that optimizes biodegradation of m-xylene. BMC Syst. Biol. 5, 1–16 (2011).
Silva-Rocha, R. & de Lorenzo, V. The TOL network of Pseudomonas putida mt-2 processes multiple environmental inputs into a narrow response space. Environ. Microbiol. 15, 271–286 (2013).
Gawin, A., Valla, S. & Brautaset, T. The XylS/Pm regulator/promoter system and its use in fundamental studies of bacterial gene expression, recombinant protein production and metabolic engineering. Microb. Biotechnol. 10, 702–718 (2017).
Goñi-Moreno, Á., Benedetti, I., Kim, J. & de Lorenzo, V. Deconvolution of gene expression noise into spatial dynamics of transcription factor–promoter interplay. ACS Synth. Biol. 6, 1359–1369 (2017).
Martínez-García, E. & de Lorenzo, V. Engineering multiple genomic deletions in Gram-negative bacteria: analysis of the multi-resistant antibiotic profile of Pseudomonas putida KT2440. Environ. Microbiol. 13, 2702–2716 (2011). This research article describes a highly-efficient protocol to generate genomic deletions in Gram-negative bacteria. The protocol is based on obligatory recombination upon DNA cleavage by the I-SceI restriction enzyme.
Luo, X. et al. Pseudomonas putida KT2440 markerless gene deletion using a combination of λ Red recombineering and Cre/loxP site-specific recombination. FEMS Microbiol. Lett. 363, 1–7 (2016).
Martínez, V., García, P., García, J. L. & Prieto, M. A. Controlled autolysis facilitates the polyhydroxyalkanoate recovery in Pseudomonas putida KT2440. Microb. Biotechnol. 4, 533–547 (2011).
Jeske, M. & Altenbuchner, J. The Escherichia coli rhamnose promoter rhaPBAD is in Pseudomonas putida KT2440 independent of Crp-cAMP activation. Appl. Microbiol. Biotechnol. 85, 1923–1933 (2010).
Kim, S. K. et al. CRISPR interference-mediated gene regulation in Pseudomonas putida KT2440. Microb. Biotechnol. 13, 210–221 (2019).
Galvão, T. C. & de Lorenzo, V. Transcriptional regulators à la carte: engineering new effector specificities in bacterial regulatory proteins. Curr. Opin. Biotechnol. 17, 34–42 (2006).
Cook, T. B. et al. Genetic tools for reliable gene expression and recombineering in Pseudomonas putida. J. Ind. Microbiol. Biotechnol. 45, 517–527 (2018).
Verhoef, S., Ballerstedt, H., Volkers, R. J. M., De Winde, J. H. & Ruijssenaars, H. J. Comparative transcriptomics and proteomics of p-hydroxybenzoate producing Pseudomonas putida S12: novel responses and implications for strain improvement. Appl. Microbiol. Biotechnol. 87, 679–690 (2010).
Elmore, J. R., Furches, A., Wolff, G. N., Gorday, K. & Guss, A. M. Development of a high efficiency integration system and promoter library for rapid modification of Pseudomonas putida KT2440. Metab. Eng. Commun. 5, 1–8 (2017).
Lieder, S., Nikel, P. I., de Lorenzo, V. & Takors, R. Genome reduction boosts heterologous gene expression in Pseudomonas putida. Microb. Cell Fact. 14, 1–14 (2015).
Nikel, P. I. & de Lorenzo, V. Robustness of Pseudomonas putida KT2440 as a host for ethanol biosynthesis. New Biotechnol. 31, 562–571 (2014).
Martínez, I., Mohamed, M. E. S., Rozas, D., García, J. L. & Díaz, E. Engineering synthetic bacterial consortia for enhanced desulfurization and revalorization of oil sulfur compounds. Metab. Eng. 35, 46–54 (2016).
Benedetti, I., de Lorenzo, V. & Nikel, P. I. Genetic programming of catalytic Pseudomonas putida biofilms for boosting biodegradation of haloalkanes. Metab. Eng. 33, 109–118 (2016).
Chai, Y. et al. Heterologous expression and genetic engineering of the tubulysin biosynthetic gene cluster using red/ET recombineering and inactivation mutagenesis. Chem. Biol. 19, 361–371 (2012).
Hoffmann, J. & Altenbuchner, J. Functional characterization of the mannitol promoter of Pseudomonas fluorescens DSM 50106 and its application for a mannitol-inducible expression system for Pseudomonas putida KT2440. PLoS ONE 10, 1–22 (2015).
Ruegg, T. L. et al. Jungle Express is a versatile repressor system for tight transcriptional control. Nat. Commun. 9, 1–13 (2018).
Van Kessel, J. C. & Hatfull, G. F. Efficient point mutagenesis in mycobacteria using single-stranded DNA recombineering: characterization of antimycobacterial drug targets. Mol. Microbiol. 67, 1094–1107 (2008).
Sun, Z. et al. A high-efficiency recombineering system with PCR-based ssDNA in Bacillus subtilis mediated by the native phage recombinase GP35. Appl. Microbiol. Biotechnol. 99, 5151–5162 (2015).
Aparicio, T., de Lorenzo, V. & Martínez-García, E. CRISPR/Cas9-based counterselection boosts recombineering efficiency in Pseudomonas putida. Biotechnol. J. 13, 1–10 (2018).
Guo, T., Xin, Y., Zhang, Y., Gu, X. & Kong, J. A rapid and versatile tool for genomic engineering in Lactococcus lactis. Microb. Cell Fact. 18, 1–12 (2019).
Yan, M., Yan, H., Ren, G., Zhao, J. & Guo, X. CRISPR-Cas12a-assisted recombineering in bacteria. Appl. Environ. Microbiol. 83, 1–13 (2017).
Tycko, J. et al. Mitigation of off-target toxicity in CRISPR-Cas9 screens for essential non-coding elements. Nat. Commun. 10, 1–14 (2019).
Castañeda-Garciá, A. et al. A non-canonical mismatch repair pathway in prokaryotes. Nat. Commun. 8, 1–10 (2017).
Liu, D. et al. Development and characterization of a CRISPR/Cas9n-based multiplex genome editing system for Bacillus subtilis. Biotechnol. Biofuels 12, 1–17 (2019).
Wang, H. H. et al. Programming cells by multiplex genome engineering and accelerated evolution. Nature 460, 894–898 (2009).
Ronda, C., Pedersen, L. E., Sommer, M. O. A. & Nielsen, A. T. CRMAGE: CRISPR Optimized MAGE Recombineering. Sci. Rep. 6, 1–11 (2016).
Mansell, T. J., Warner, J. R. & Gill, R. T. Trackable multiplex recombineering for gene-trait mapping in E. coli. In Systems Metabolic Engineering. Methods in Molecular Biology (Methods and Protocols), vol. 985 (ed. Alper, H.) 223–247 (Humana Press, 2013).
Nyerges, Á. et al. Directed evolution of multiple genomic loci allows the prediction of antibiotic resistance. Proc. Natl Acad. Sci. USA 115, E5726–E5735 (2018).
Acknowledgements
This paper was supported by funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (Grant agreement No. 819800) awarded to R.L. P.I.N. acknowledges financial support by The Novo Nordisk Foundation (grants NNF10CC1016517 and NNF18OC0034818), the European Union’s Horizon 2020 research and innovation programme (Grant agreement No. 814418, SinFonia), and the Danish Council for Independent Research (SWEET, DFF-Research Project 8021-00039B).
Author information
Authors and Affiliations
Contributions
All three authors contributed to the overall structure and design of the manuscript. Principal writing was performed by E.-M.L., with corrections and modifications by P.I.N. and R.L.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Peer review information Nature Communications thanks the anonymous reviewer(s) for their contribution to the peer review of this work.
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Lammens, EM., Nikel, P.I. & Lavigne, R. Exploring the synthetic biology potential of bacteriophages for engineering non-model bacteria. Nat Commun 11, 5294 (2020). https://doi.org/10.1038/s41467-020-19124-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-020-19124-x
This article is cited by
-
Characterization of selected phages for biocontrol of food-spoilage pseudomonads
International Microbiology (2024)
-
Bacteriophage genome engineering for phage therapy to combat bacterial antimicrobial resistance as an alternative to antibiotics
Molecular Biology Reports (2023)
-
Characterization of antibiotic resistomes by reprogrammed bacteriophage-enabled functional metagenomics in clinical strains
Nature Microbiology (2023)
-
Controlling gene expression with deep generative design of regulatory DNA
Nature Communications (2022)
-
Smarter cures to combat COVID-19 and future pathogens: a review
Environmental Chemistry Letters (2021)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
