
Abstract
Natural gas vehicles (NGVs) have been promoted in China to mitigate air pollution, yet our measurements and analyses show that NGV growth in China may have significant negative impacts on climate change. We conducted real-world vehicle emission measurements in China and found high methane emissions from heavy-duty NGVs (90% higher than current emission limits). These emissions have been ignored in previous emission estimates, leading to biased results. Applying our observations to life-cycle analyses, we found that switching to NGVs from conventional vehicles in China has led to a net increase in greenhouse gas (GHG) emissions since 2000. With scenario analyses, we also show that the next decade will be critical for China to reverse the trend with the upcoming China VI standard for heavy-duty vehicles. Implementing and enforcing the China VI standard is challenging, and the method demonstrated here can provide critical information regarding the fleet-level CH4 emissions from NGVs.
Similar content being viewed by others

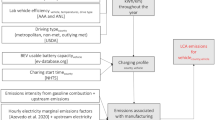
Introduction
From 2000 to 2017, the population of natural gas vehicles (NGVs) in China increased from 6000 to 6.08 million (Fig. 1 and Supplementary Table 1)1. This rapid growth of NGVs in China is primarily driven by environmental considerations and associated economic incentives. Natural gas (NG) is considered to be a clean-burning fuel characterized by relatively low carbon content and low air pollutant emissions2, making it less costly for NGVs to meet increasingly stringent PM2.5 and NOx emission standards in China compared to gasoline and diesel counterparts3,4. Currently, the payback time of the additional cost for purchasing a NGV relative to gasoline and diesel counterparts are two to three years for a taxi driver3, and around one year for a truck driver in China (see Supplementary Fig. 1 for details). China aims to increase the population of NGVs to 10 million by 20205, and more growth is expected beyond 2020 for heavy-duty applications (buses and trucks) where vehicle electrification remains difficult6. In 2017, 6.37 million heavy-duty trucks (all fuel-types combined) accounted for 3.1% of the total vehicles in China and contributed 53 and 60% of the vehicular NOx and particulate matter (PM) emissions7. To improve the situation, the State Council of the People’s Republic of China set the goal to retire heavy-duty vehicles meeting just China III emission standards and specifically mentioned the goal of promoting the use of heavy-duty NGVs for the first time in 20188. In the first half of 2019, 85,000 heavy-duty NG trucks were sold in China accounting for 13% of the total heavy-duty vehicles sold in the same period and were 27% higher than the annual sales of heavy-duty NG trucks in 20189.

Supplementary Table S1 lists the number of NGVs in each category. Source data are provided as a Source Data file.
Although NGVs are cost-effective alternatives to achieve the desired NOx, PM, and CO2 emission reductions4,10,11, their unintended methane (CH4) emissions could compromise their potential climate benefits. CH4 is a potent greenhouse gas (GHG) with a global warming potential (GWP) of 28–34 over a 100-year time horizon (84–86 over a 20-year time horizon)12. Despite having the largest NGV fleet in the world, emission factors (EFs) of NGVs in China have not been carefully quantified, and CH4 emissions from NGVs are not included in the CH4 emission inventory for China13,14,15. Previous studies of NGVs mainly focused on CH4 emissions from the upstream stages in China, such as extraction, processing, and distribution of NG, using life-cycle analysis (LCA). Emissions related to vehicle operation have been ignored in these life-cycle analyses because of the lack of direct measurements in China14,16,17,18. CH4 can be emitted from NGVs as unburnt fuels from tailpipes. CH4 is the hydrocarbon most resistant to catalytic oxidation. Therefore, CH4 removal rates in the exhaust of NGVs are highly variable and strongly depend on the combination of engine and after-treatment technology2. CH4 also has been observed in the blowby gas from spark ignited (SI) engines with an open crankcase system and in the vented gas from High-Pressure Direct Injection (HPDI) engines19. Occasionally, CH4 can be released directly from on-board fuel storage tanks as well due to manual or pressure relief venting19. Clark et al.20 estimated that vehicle emissions account for about 80% and 40–60% of pump-to-wheels (PTW) and well-to-wheels (WTW) CH4 emissions, respectively, based upon observations for NGVs in the US. For WTW GHG emissions from NGVs in China, only Huo et al.16 adopted the CH4 emission factor (EF) of light-duty NGVs developed for the US. Other life-cycle analyses for China have ignored vehicle CH4 emissions from NGVs entirely14,17,21,22.
In fact, CH4 emissions from NGVs in China may be significantly higher than the results from the US and other regions. In China, about 80% of NGVs are retrofitted from conventional vehicles with engines and after-treatment equipment not designed for NG23. In 2018, Hu et al.23 reported the overall CH4 emission factor of NGVs in China (3.0 ± 0.5% of NG consumed, (mean ± standard error)) is about eight times the emission factor for NGVs given by the IPCC (0.4% of NG consumed). Without distinguishing light- and heavy-duty NGVs (Supplementary Fig. 2), they attributed the high CH4 emissions to the retrofitted light-duty NGVs23. However, heavy-duty NG buses and trucks produced in China are equipped with lean-burn (LB) engines and oxidation catalysts (OC)2. The exhaust temperature of LB engines is usually lower than the ideal temperature for OC (450 °C) to effectively remove CH42,24. The mean value of fuel-specific EFs found in previous studies for LB engines with OC is six times higher than that of stoichiometric (SM) engines equipped with a three-way catalyst (TWC, Supplementary Table 2 lists CH4 EFs for different technologies)25. Finally, although CH4 emissions from heavy-duty NGVs are regulated by emission standards in China, the low removal rate at low exhaust temperature may lead to significantly elevated real-world emissions than the certified emission limit. Such discrepancies have been reported widely for NOx emissions from heavy-duty vehicles equipped with selective catalytic reduction (SCR) systems, which are also temperature sensitive10,26. Because measurements of CH4 emissions from NGVs are lacking, however, it is unclear whether such a discrepancy exists for CH4 emissions from NGVs in China and to what extent it impacts their GHG emissions.
During the 2014 CAREBEIJING North China Plain field campaign, we deployed a mobile laboratory to quantify CH4 EFs of NGVs in China. We updated the well-to-wheels GHG emissions for NGVs with the observed EFs and developed a detailed bottom-up CH4 emission inventory of NGVs in China for 2000–2017. Starting July 1st, 2019, heavy-duty NGVs sold in China must be certified for the China VI emission standard for heavy-duty vehicles27. We designed three scenarios to assess the potential impacts of the implementation of the new standard on CH4 emissions from NGVs. Our results show that CH4 emissions from heavy-duty NGVs were high and switching to NGVs from conventional vehicles in China has led to a net increase of 77 Mt CO2eq from 2000–2017. Our scenario analyses demonstrate that strictly implementing the upcoming China VI standard could reduce GHG emissions by 509 Mt CO2eq for 2020–2030.
Results
On-road CH4 emissions from NG taxis and buses
CH4 emissions from exhaust and leakage from NG buses and taxis in Baoding and Shijiazhuang were measured by our mobile laboratory equipped with fast-response sensors. We measured 26 h on-road, covering around 600 km in these two cities in June 2014 (details about instruments and spatial coverage can be found in Supplementary Table 3 and Supplementary Fig. 3). The fast-response sensors (10 Hz) allowed the use of the plume-chasing method to measure on-road emissions from vehicles. Several criteria, including sufficient CO2 and CH4 enhancements, correlations between CH4 and CO2 and videos recorded on the road, were developed to identify plumes from NGVs. Supplementary Movie 1 provides an example of the on-road measurements. A Gaussian puff model was used to investigate the effectiveness of our method to minimize the influence of the exhaust of nearby vehicles, and the results show our method can significantly reduce interferences caused by the emissions from other vehicles28. Using the plume-chasing method, we were able to capture emissions from 73 NG buses and 63 NG taxis during the field campaign. The observed CH4 and CO2 mixing ratios were used to derive CH4:CO2 enhancement and emission ratios. The emission ratios were then converted to fuel-specific CH4 emission factors. Similar methods have been used to estimate vehicular NH3 emissions29,30. More details and discussion about the uncertainty of the method can be found in the “Method” section and Supplementary Discussion. Figure 2 shows the on-road fuel-specific CH4 EFs (presented as % of NG consumed) derived from CH4:CO2 emission ratios measured in China as well as previously reported EFs.

The boxes and whiskers for our observations show 5th, 25th, 50th, 75th, and 95th percentiles of the observed EFs. Black dots and bars show the average values and standard errors of corresponding EFs measured in China. Black dots and bars show the average values and standard deviation (S.D.) of corresponding EFs measured in China. Numbers of independent samples (vehicles) used to derive EFs and the standard errors are listed in the labels. Red dots and bars show the venting-emission and seasonality adjusted values of corresponding EFs for China. Gray dots and bars show the average values and standard errors of corresponding EFs measured in other regions. The star and the associated bar show the estimated EF and its uncertainty for heavy-duty NG trucks equipped with a lean-burn engine and oxidation catalyst (determination of the uncertainty can be found in method section). Xie et al. and Guo et al. measured total hydrocarbon (THC) emissions instead of CH423,52. We converted their results to CH4 emissions assuming 90% of THC is CH4 as suggested by Xie et al. and Hu et al.23,52. The observed EF for heavy-duty vehicles is 85% higher than the current standard (China V). “LB + OC”, “SM + TWC”, “SM + TWC w. CC”, “HPDI”, and “HPDI w. DV” stand for a lean-burn engine with oxidation catalyst, stoichiometric engine with three-way catalyst, stoichiometric engine with a three-way catalyst with crankcase emissions, high-pressure direct injection (HPDI), and HPDI with dynamic venting emissions. Source data are provided as a Source Data file.
Sixty-three NG taxis with clear NGV labels were sampled to represent light-duty NGVs in China, which had an average EF of 1.7 ± 0.5%. The EF is 16 times higher than the values reported for light-duty NGVs in the US and EU (0.10 ± 0.3%), but the EF agrees with the tailpipe CH4 EF measured in the exhaust of NG taxis by Hu et al.23 (1.7 ± 0.8%). The CH4 EF measured from 73 NG buses in China is 2.9 ± 0.5%, which is 90% higher than the CH4 limit of the China V standard for heavy-duty vehicles31. We were able to distinguish buses powered by liquified natural gas (LNG) and compressed natural gas (CNG) by checking the label of the buses. No statistically significant difference was found between the EFs of LNG buses (39 buses, 2.8 ± 0.4 %) and CNG buses (34 buses, 3.1 ± 0.5 %). The NG buses in these two cities were equipped with LB engine and OC, and they were certified for the China VI and China V standards, respectively. We also observed low NH3 emissions from NG buses (Supplementary Fig. 4), consistent with the reported pattern for NGVs with LB engine with OC32,33. The observed EF of NG buses is more consistent with the overall on-road CH4 EF measured by Hu et al.23 (3.0 ± 0.5%) than the observed EF of light-duty NGVs. To validate our method, we conducted additional measurements by following NG buses in Atlantic City, US, in the spring of 2015. The observed EF agrees with previously reported tailpipe CH4 emissions for NG buses in the US as well as the CH4 emissions used in the GREET model18.
Estimation of CH4 emissions from heavy-duty NG trucks
Identifying NG trucks in China was more difficult than NG buses since they were not labeled as clearly as the NG buses. Therefore, we could not derive CH4 EF for heavy-duty NG trucks using our observations. Our survey shows that NG trucks certified for China IV and V from the major manufacturers in China are equipped with similar LB engines and OC but with slightly larger displacements than the engines on NG buses (Supplementary Table 4). This type of engine is rarely used on trucks in other countries, and therefore, no CH4 EF have been reported for NG trucks equipped with LB engines. Previous studies suggested driving conditions of the vehicles may have larger impacts on CH4 emissions rather than the chassis2,19. Comparing CH4 EFs reported for NG buses and trucks equipped with similar SM engines and TWC, we did not find a significant difference for both the tailpipe and the crankcase CH4 emissions (Fig. 2 and Supplementary Table 2)33,34,35,36,37,38. Therefore, the measured CH4 EF of NG buses is used to estimate CH4 emissions from heavy-duty NG trucks. Since NG trucks may operate on the highway more frequently than NG buses, we assigned a larger error to the lower-bound uncertainty of EFs of NG trucks, which equals to the lower-bound uncertainty of the previously reported CH4 EF of LB engines with OC (Fig. 2 and Supplementary Table 2).
Venting-emission and seasonality adjustment
Because low CO2 enhancements and correlations between CH4 and CO2 mixing ratio enhancements are used to remove impacts from other CH4 sources, our method can capture operations related CH4 emissions from tailpipes and crankcases but may miss sporadic venting events directly from the on-board fuel tanks that are not fed to the engine. Clark et al.19 found these emissions are difficult to be characterized by in-field observations because of the large volume of methane vented in single events and their intermittent nature. Using tank pressure and liquid fuel level (%) differences before and after venting, they estimated the fuel-specific emission rate of these venting events is 0.1% of NG consumed in the US (about 8.4% of total pump-to-wheels CH4 emissions for NGVs in the US)19. The same emission rate is adopted in our study to account for the venting emissions. Our observations were made in June with an average ambient temperature of 30 °C, which may underestimate CH4 emissions during cold seasons, especially for the cold-start emissions. Among the studies reviewed, only two studies reported the cold-start CH4 emissions for heavy-duty NGVs at low temperatures. The ratio of cold- and hot-start for CH4 EFs at around 0 °C ranges from 1.08 for vehicles with a fuel-specific EF of 11.2% to 2.69 for vehicles with a fuel-specific EF of 0.2% (Supplementary Table 5)37,39. To account for the potential impact of cold-start emissions at low temperature, we adjusted the observed EFs using a cold-start/hot-start emission ratio of 1.5 and a weighting factor of 14% for cold-start emissions as listed in the testing procedure for the China VI standard (see “Method” section for details). The adjusted EFs are 1.9 [−0.7, +0.9] %, 3.2 [−0.8, +1.0] %, and 3.2 [−1.7, +1.0] % for NG taxies, heavy-duty NG buses, and heavy-duty NG trucks as shown by the red dots and bars in Fig. 2.
Technological pathways for the China VI standard
Figure 2 also shows the EFs for SM engines equipped with TWC and the high-pressure direct injection (HPDI) engines. Both have the potential to meet the CH4 limit of the China VI standard. However, high CH4 emissions from the crankcases of SM engines have been observed as NG could pass through the gaps between the piston rings and the cylinders19. When crankcase CH4 emissions are considered, it will be difficult for SM engines to meet the China VI standard unless a complicated, closed crankcase ventilation system (CCV) is installed2. No crankcase CH4 emission has been reported for the HPDI engines, but HPDI engines require venting of the high-pressure fuel to balance NG and diesel fueling pressures, leading to dynamic venting CH4 emissions19. The dynamic venting CH4 emissions could far outweigh the tailpipe CH4 emissions during urban operation and could be equivalent to tailpipe emissions during highway operation19.
Well-to-wheels GHG emissions of NGVs in China
Previous studies have estimated the WTW GHG emissions for NGVs in China with limited consideration of CH4 emissions from NGVs (see Supplementary Table 6 for studies reviewed)14,16,22. Ou et al.22 investigated multiple pathways of CNG and LNG in China and reported a WTP leakage rate about 0.6% of NG consumed in the Tsinghua Life Cycle Analysis Model. Huo et al. assumed the technologies in China for production and distribution of CNG and LNG are similar to the ones used in other regions and adopted the rates of 1.93% of NG consumed for extraction and production and 0.007% of NG transported per km via pipeline from the GREET model16,18. The difference of WTP GHG emissions between CNG and LNG (1%) is lower than the variation caused by the CH4 leakage from pipeline distribution (standard deviation of 7%) since the transport distance ranges from 200 to 4400 km for different provinces. Therefore, the same WTP GHG emission factor (28 ± 6 CO2eq MJ−1) and the same WTP CH4 leakage rate (1.65 ± 1.05% of NG consumed) are used for both LNG and CNG. The overall WTP leakage rate is about the same as the CH4 EF of light-duty NGVs and is 40% lower than the CH4 EF of heavy-duty NGVs (Fig. 2).
The distance-specific WTW GHG EFs for NGVs are derived in this study by combining previously reported upstream GHG EFs, distance-specific fuel consumption, and adjusted CH4 EFs of NGVs (shown in Fig. 3). The uncertainty of the national level WTW GHG EF for NGVs in China is large because of the variation in NG transport distance via pipeline (from 200 km to 4400 km). For provincial analysis, as demonstrated by Huo et al.16, the uncertainty could be reduced. With the observed CH4 emissions, both light-duty NGVs and NG buses are unlikely to reduce GHG emissions compared to their counterparts. For NG buses, the WTW GHG emissions are likely to be higher than diesel buses even if they satisfy the China VI standard CH4 limit because of their increased fuel consumption (Supplementary Table 7). Switching from diesel trucks to current generation NG trucks equipped with LB engines and OC as the measured NG buses is likely to increase GHG emissions by 160 [−200, +180] g CO2eq km−1. Only the ones operating mostly on the highways in the near-source regions may have lower WTW GHG EF compared to diesel trucks.

Panels a and b show the well-to-wheels GHG emissions for light- and heavy-duty vehicles, respectively, in China. Blue bars show the WTW GHG emissions without CH4 contribution. Green and orange bars are the CO2 equivalents of WTP CH4 emissions and CH4 emissions from NGVs (a GWP of 30 over a time-scale of 100 years is used for CH4 from fossil fuel consumption according to IPCC AR5)12. For cars and buses, NGVs may not bring GHG emission mitigation. NG trucks that meet China VI standard have lower GHG emissions compared to diesel trucks. The black error bars indicate high and low estimates derived using error propagation of uncertainties of multiple input parameters (e.g., life-cycle GHG emissions, CH4 emission factors, and fuel consumptions). Uncertainty estimates (standard deviation, S.D.) of individual parameters are listed in Supplementary Tables 1, 6, 7, and 11. Source data are provided as a Source Data file.
For trucks equipped with SM engines and TWC or HPDI engines, the WTW GHG emissions are similar to diesel trucks. It should be noted that the fuel consumption of trucks equipped with SM engines and TWC is assumed to be the same as trucks with LB engines. Operating at lean conditions is an effective way to improve fuel efficiency compared to a pure stoichiometric operation40. However, the fuel economy of SM engines can be significantly improved by operating the engine with diluted mixtures through exhaust gas recirculation (EGR) systems, which also can significantly reduce NOx emissions35,40. Hajbabaei et al.35 compared the fuel consumption of a SM engine with an EGR system and two LB engines. They found the SM engine with EGR had very similar fuel consumption compared to the LB engines. For the NG trucks to be certified for the China VI standard, SM engines are likely to be used with an EGR system to be competitive in the market in terms of fuel economy and to be in compliance with the China VI NOx emission limit and the China Stage 3 fuel consumption limits41. The same fuel consumption was scaled by 0.95 to approximate the fuel consumption of HPDI engines because Thiruvengadam et al.32 reported the fuel consumption of HPDI engines was 4% lower than that of SM engines with EGR systems.
If the China VI standard is stringently the enforced with the real-world emissions being the same as the CH4 emission limit, switching from diesel trucks to NG trucks will lead to a GHG reduction of 100 ± 150 g CO2eq km−1, and upstream CH4 leakages will become the limiting factor for lowering the WTW GHG emissions from NGVs in China. Although having real-world emissions in line with certified emission limits is challenging, it has been shown to be technically achievable at least for NOx emissions from Euro VI trucks, to which the China VI standard is equivalent26.
CH4 emissions from NGVs in China
NG consumption of the Transport, Storage, and Post sector reported in the China Statistical Yearbook (CSYB) does not have the detailed categorical information for estimating CH4 emissions from NGVs in China42. Therefore, we estimated NG consumption of NG taxis, light-duty NGVs (non-taxi), NG buses, and NG trucks in China as the product of vehicle population (Supplementary Table 1), distance-specific fuel consumption (Supplementary Table 7), and annual mileage traveled (Supplementary Table 8). The four categories are determined based on fuel consumption and emission characteristics and availability of the population data. Figure 4a shows the estimated NG consumption and reported NG consumption in the CSYB42. Personal light-duty NGVs (light-duty NGVs except for NG taxis) should be excluded when comparing the estimated NG consumption and the CSYB reported values since fuel consumed by personal vehicles are not included in the Transport, Storage, and Post sector in the CSYB43. The sum of NG consumption of NG taxis, buses, and trucks is slightly lower than the CSYB reported consumption because NG consumption of cargo ships is included in the CSYB but not included in our estimates. For 2017, our estimate is closer to the reported consumption of CSYB likely due to the NG shortage in China in the winter of 2017. In 2017, NG buses and trucks consumed about 70% of the total NG consumption of NGVs.

Estimated (bars or solid lines) and projected (dashed lines) NG consumption (a), total CH4 emissions from NGVs (b), and changes of WTW GHG emissions of switching to NGVs (c) in China from 2000 to 2030. Gray line in a shows the reported NG consumption for the Transport, Storage, and Post sector reported in the China Statistical Yearbook (CSYB). When comparing the estimated NG consumption and NG consumption from CSYB, light-duty vehicles (without taxis) should be excluded (light blue bar in a). The error bars in a and b and the gray area in c indicate high and low estimates derived using error propagation of uncertainties of multiple input parameters. Uncertainty estimates (standard deviation, S.D.) of individual parameters are listed in Supplementary Table 1, 6, 7, 8, and 11. Source data are provided as a Source Data file.
Total CH4 emissions and changes in WTW GHG emissions are calculated by multiplying the corresponding emission factors (venting-emission and seasonality adjusted) to the NG consumption (see “Method” section for more details). Figure 4b, c shows the estimated and the projected total CH4 emissions from NGVs in China and the changes in WTW GHG emissions of switching to NGVs from gasoline and diesel counterparts for 2000–2030. The annual CH4 emissions from NGVs in China increased from 0.0014 [−0.0004, +0.0004] Mt in 2000 to 0.77 [−0.28, +0.22] Mt in 2017. Switching to NGVs has increased the GHG emissions by 83 Mt CO2eq for 2000–2017. More than 80% of CH4 emissions from NGVs are emitted by NG buses and trucks in 2017 because of their high fuel consumption and high EFs. Therefore, the implementation of the CH4 limit of the China VI standard for heavy-duty vehicles is critical for mitigating future CH4 emissions from NGVs.
Future scenarios
Three scenarios were designed to assess different pathways regarding the implementation of the China VI standard. Table 1 lists the major features of these scenarios. The population estimates are adapted from the projection by Wu et al.6, where aggressive electrification for applicable fleets was considered (see Supplementary Table 9 for projected vehicle population for the three scenarios). The fuel consumption of heavy-duty vehicles (both NGVs and conventional gasoline or diesel vehicles) purchased after 2021 is lowered by 15% assuming that the Stage 3 China Fuel Consumption Standard will be implemented successfully41.
The high-emission scenario represents the pathway that retrofitting light-duty vehicles is allowed. In addition, this scenario assumes that the CH4 limit of China VI standard is loosely enforced, which has been the case for previous standards as demonstrated here. Although LB engines with OC are considered the last generation technology, they could meet the NOx limit of China VI standard if SCR is implemented11. If the CH4 limit of the China VI standard is loosely implemented, LB engines may dominate the heavy-duty vehicle market because of their advantages in terms of upfront cost, since SM engines require precise air–fuel ratio control strategies and an exhaust gas recirculation system40. Under this scenario, annual CH4 emissions from NGVs in China would increase to 3.3 Mt, equivalent to 8% of the estimated total anthropogenic CH4 emissions and 17% of CH4 emissions related to fossil fuel production and consumption in China in 201013. Cumulatively, switching to NGVs from counterparts would increase the WTW GHG emissions by 432 Mt CO2eq from 2020 to 2030 under this scenario (the integrated area under the orange curve in Fig. 4b from 2020 to 2030).
The medium-emission scenario represents the pathway that retrofitting is prohibited, and heavy-duty NGVs sold after 2019 are equipped with SM or HPDI engines. Because of the increased cost, the penetration rate of NGVs is lower than the high-emission scenario. Under this scenario, CH4 emissions from NGVs in China would increase at a slower rate, reaching 1.3 Mt in 2030 and the cumulative changes in the WTW GHG emissions from 2020 to 2030 would increase by 117 Mt CO2eq.
The low-emission scenario assumes that the EF of the heavy-duty NGVs purchased after 2019 is the same as the CH4 limit of China VI standard. The growth of NGVs is assumed to be localized within source regions where NG price is low, and the leakage CH4 emissions related to NG distribution are lower than the medium- and high-emission scenarios. The annual CH4 emissions from NGVs in China would gradually decrease to 0.7 Mt in 2030 and reduce the WTW GHG emissions by 77 Mt CO2eq cumulatively from 2020 to 2030 under this scenario. Comparing the cumulative WTW GHG changes between the high- and the low-emission scenarios, we find that stringently enforcing the China VI standard for heavy-duty vehicles could generate a GHG reduction of 509 Mt CO2eq for 2020– 2030, equivalent to eliminating GHG emissions of 12 million passenger cars with the current GHG emission level.
Discussion
NGVs have been promoted in China as a cost-effective alternative to mitigate air pollution and to reduce GHG emissions from vehicles, especially for heavy-duty applications where vehicle electrification remains difficult. Previous studies suggested that the WTW GHG emissions of NGVs were 6–25% lower than gasoline and diesel counterparts, but tailpipe and crankcase CH4 emissions from NGVs were mostly ignored14,16,17,18. Hu et al.23 sampled on-road CH4 emissions from NGVs in China and reported an overall fuel-specific EF of 3.0% and attributed the high on-road CH4 emissions to leakage from converted light-duty NGVs. However, our sampling results of 63 NG taxis show similar tailpipe CH4 emissions and no significant leakage from light-duty NGVs. Our observations of CH4 emissions from 73 NG buses indicate that heavy-duty NGVs contributed more to the high overall on-road CH4 emissions in China compared to light-duty NGVs. With the current level of CH4 emissions from NGVs, switching to NGVs in China has not brought a reduction of GHG emissions.
With the China VI standard, the heavy-duty transportation sector in China will be “gasified” rapidly because it is less costly for NGVs than diesel and heavy-duty electric vehicles to meet the stringent limits for air pollutant emissions4. The rapid growth of heavy-duty NGVs without stringent enforcement of the China VI standard CH4 limit, however, would increase CH4 emissions as demonstrated by the high-emission scenario. Strictly implementing the China VI standard as in the low-emission scenario will require a closed crankcase ventilation system for SM engines with TWC for heavy-duty NGVs. This pathway would reduce CH4 emissions by around 70% in 2030 compared to the high-emission scenario and generate a significant GHG emission reduction, making it a “win-win” option for air quality and climate. Although this measure could lead to an increased price barrier for purchasing NGVs, innovations in the design of engines and after-treatment devices could lower the barrier. For example, catalysts that can remove CH4 more effectively from LB engines are being pursued44,45,46,47. China’s successful implementation of the China VI standard on such a large scale could inspire climatically beneficial NGV development in other regions facing similar challenges, especially in developing countries where natural gas is already considered as an economical alternative for transportation48,49.
Substantial uncertainties still exist in the estimates and the projections for CH4 and WTW GHG emissions from NGVs in China due to lacking detailed vehicle population and NG consumption data as well as the uncertainties related to CH4 EFs of NGVs. With categorized and regional NGV data, the uncertainties for both the CH4 emissions and the WTW GHG emissions could be significantly reduced. Despite the large sample size from our campaign, the observed EFs for light-duty NGVs and NG buses may be underestimated because of missing cold-start CH4 emissions at low temperature and sporadic venting emissions. In addition, no CH4 EF has been reported for current generation NG trucks that are equipped with LB engine and OC and the CH4 EF could be different under various driving conditions for the NG trucks. Finally, CH4 emissions from NGVs in China in the next decade could vary substantially, depending on the implementation of the China VI standard, as demonstrated in our scenario analyses. Therefore, more observations are needed not only to constrain CH4 emissions from current generation NGVs but also to enforce the CH4 limit of the China VI standard.
As our measurements demonstrate, there is a discrepancy between real-world CH4 emissions and the associated emission limits. For China III, IV, and V, the compliance testing for CH4 emissions from NGVs is conducted with the European Transient Cycle (ETC)31. The ETC has been criticized for not representing real-world driving conditions since it has relatively high average engine loads over the entire test; consequently, exhaust temperatures during the ETC test are relatively high50. Under real-world driving conditions, especially in urban areas, the exhaust temperature from NGVs equipped with LB and OC may be lower than the ideal temperature for CH4 removal leading to elevated CH4 emissions. This discrepancy highlights the challenges in ensuring that the desired CH4 emission levels for NGVs are met in reality and the need for more real-world measurements. For the China VI standard, the compliance testing will be conducted using the World Harmonized Steady-State Cycle (WHSC), which should be more representative of the full range of real-world driving conditions27. In addition, starting in 2021, model compliance testing will include a real-world emission test conducted with a portable emissions measurement system (PEMS) attached to the vehicles27. However, crankcase and venting emissions may not be captured by the PEMS method. Besides, the results of PEMS testing often show considerable variation because of different vehicle and traffic conditions, as can be seen from EFs measured using PEMS from 25 light-duty NGVs by Xie et al. (Fig. 2), limiting its use to estimate overall emissions51,52. Increasing the sample size can reduce the variability but will lead higher costs and difficulties in getting access to the vehicles. Remote sensing or plume-chasing methods, similar to the method used in this study or the method demonstrated by Hu et al.23, can provide critical information regarding the fleet-level CH4 emissions from NGVs in China to researchers in other fields and the stakeholders. Finally, our method could be applied to other regions as well. For example, a majority of taxis, buses, and autorickshaws in 11 (out of 29) Indian states are powered with CNG due to Indian Supreme Court decisions53,54. However, similar to the case in China, CH4 emissions from these vehicles have rarely been quantified despite the large fleet size, and EFs developed for other regions were used to investigate climatic impacts of NGVs in India55. Our method could be implemented at relatively low cost and, combined with fuel consumption estimates, used to quantify CH4 emissions from NGVs in India and total impacts on GHG emissions.
Method
Derivation of CH4:CO2 emission ratio
We used a method similar to Sun et al.30 to calculate the CH4:CO2 emission ratio (in the unit of (ppmv CH4) (ppmv CO2)−1). Observed CH4 and CO2 mixing ratios were first separated into localized vehicle emission signals (local enhancements) from the urban backgrounds by finding their 2nd percentiles within a 3-min window. Since CH4 and CO2 are relatively stable (lifetimes about are 12 and 30–95 years for CH4 and CO2), and we were close to the emission sources, the CH4:CO2 emission ratio at a given time can be approximated by the slope of orthogonal regression of CH4 and CO2 enhancements measured within a time window of ±1 s. The short time window was chosen to capture instantaneous changes of CH4 emissions. Increasing the time window to ±2.5 s only changed the results by less than 2%.
The plume-chasing method assumes that CH4 and CO2 are co-emitted from the same sources of interest and are transported and dispersed in the same way. To make sure this assumption is valid, we only used observations when the mobile laboratory was directly following NGVs. With the videos, we were able to distinguish buses powered by liquified natural gas (LNG) and compressed natural gas (CNG) by checking the label of the buses and our on-road videos. No significant difference was observed between the LNG and CNG buses (see Supplementary Table 2 for values), and, therefore, we did not distinguish LNG and CNG buses in the life-cycle analysis and emission scenario analyses.
An example is provided in Supplementary Movie 1, and the associated observations are also shown in Supplementary Fig. 5. We were typically less than 50 m away from the NGVs. Although we did not measure the distance between the NGVs and our mobile laboratory, we used the ΔCO2 and ΔCH4 thresholds (10 ppmv for ΔCO2 and 0.2 ppmv for ΔCH4) to determine if the mobile laboratory was within the plume of NGVs. To prevent the influence of the emissions from our mobile platform, we excluded observations with a driving speed smaller than 5 km h−1 based on our previous studies29,56. As shown in Supplementary Movie 1, there were still vehicles in other lanes even when our mobile laboratory was directly behind the NGVs. Since most of the vehicles were not powered by NG (only 2.6% of the vehicles were powered by NG on a national scale), emissions from other vehicles would contribute to the observed ΔCO2, which could potentially lower the estimated emission ratios. To reduce such interference, the correlation between ΔCO2 and ΔCH4 was used as a criterion to remove observations potentially influenced by other vehicles. Data with R2 < 0.5 within the ±1 s time window were excluded. The rationale behind this criterion is that high-frequency fluctuations (10 Hz) of CO2 and CH4 concentrations were caused by turbulent movements of the plumes, and these changes should be correlated if CO2 and CH4 plumes are emitted from the same source and go thru the same atmospheric transport and dispersion. In addition, using the slope of orthogonal regression between ΔCH4 and ΔCO2 (instead of the quotient) to estimate enhancement ratio helps to remove the ΔCO2 offsets caused by emissions from other vehicles. To investigate the effectiveness of correlation criterion and orthogonal regression, we used a Gaussian puff model (PUFFER) to simulate on-road CO2 and CH4 concentrations measured by our mobile laboratory (see Supplementary Discussion for more details)28. Our results highlight the importance of capturing high-frequency variations. When high-frequency fluctuation is present, which was usually the case for busy roads when our measurements were influenced by other vehicles, no statistically significant difference between the true and the estimated ΔCH4:ΔCO2 ratios is found, indicating that the combination of R2 filtering and orthogonal regression effective in minimizing the interference.
As shown in Supplementary Movie 1, the emission ratio could vary by a factor of three following single bus. This variability is related to driving mode changes and leads to the skewness of observed EFs shown in Fig. 2. Similar variability has been reported by previous studies using the chassis dynamometer method33,57. This variability was largely reduced by using fleet-wise mean emission ratios. During our field campaign in China, we had three days of observations and we treated observations from each day as an individual fleet sample. The relative standard deviations of the daily averaged EFs for NG buses and taxis are 3 and 12%. The major source of uncertainty in our method is the plume-identification process. Our results are insensitive to the choice of temporal window for background removal and the thresholds for ΔCO2 and R2. However, our results are sensitive to the threshold for ΔCH4. For example, changing the threshold for R2 to 0.25 or 0.75 from 0.5 leads to 2–8% changes in the mean ER, much smaller than the impacts of the CH4 cutoff (see Supplementary Table 10 for details). In addition, R2 filtering is less sensitive as the CH4 threshold increases. With a CH4 threshold of 0.4 ppmv, the daily mean ER changed <2% when increasing R2 threshold from 0.25 to 0.75. Therefore, we estimated our standard errors of ER related to plume identification as the difference of the results without a cutoff for CH4 and the results with a CH4 cutoff of 0.4 ppmv. Finally, we estimated the uncertainty of our observation using sample-size weighted uncertainty propagation combining the plume-identification uncertainty and sample uncertainty (see Supplementary Table 10 for details).
Derivation of the fuel-specific CH4 emission factors
The observed fuel-specific CH4 emission factor (EF) is defined as the ratio of CH4 emission rate and fuel consumption rate. Fuel consumption rate can be estimated by the carbon balance method
where ΔCH4 and ΔCH2 are CH4 and CO2 enhancements in ppmv, \(M_{{\mathrm{CH}}_{\mathrm{4}}}\) and MC are the molar weights of CH4 and carbon, wc = 0.75 is the carbon content of NG, and ER is the emission ratio. Since \(w_{\mathrm{c}}\,M_{{\mathrm{CH}}_4}/M_{\mathrm{C}} = 1\) for CH4 emissions from NGVs, Eq. (1) can be simplified as:
CH4 emissions and CO2 emissions from other studies are converted to fuel-specific emission factor using the same method when they are not provided (Supplementary Table 2). CO was neglected in this study to be consistent with past literature and because CO emissions are often not available. Adding the observed CO concentrations to Eq. (1) would decrease the fuel-specific CH4 emission factors by 2%. The fuel-specific emission factors that include CO emissions can be found in Supplementary Table 2.
Venting-emission and seasonality adjusted fuel-specific CH4 emission factors
The observed EFs are adjusted to account for venting emissions and seasonality as
where cold-start emissions are estimated using a cold-start/hot-start emission ratio of 1.5. The cold-start/hot-start emission ratio is determined as the average cold-start/hot-start emission ratio for an EF near 3% of fuel consumed (Supplementary Table 5). Cold-start and hot-start are averaged with weighting factors of 14% and 86% (adapted from the testing procedure listed in the China VI standard), respectively27. Venting CH4 emissions from the on-board tank are not related to the combustion process and are not co-emitted with CO2 emissions. Therefore, these emissions were not captured by our method and should be compensated. Therefore, 0.1% of NG consumed is added to compensate the venting EF as reported by Clark et al.19. The lower-bound uncertainty remains unchanged as the lower-bound uncertainty of the observed ERs to account for the possibility that ambient temperature and venting events have no impact on CH4 emissions. The upper-bound uncertainty (\({\mathrm{UBEF}}_{{\mathrm{CH}}_{\mathrm{4}}{\mathrm{,adj}}}^{{\mathrm{fuel}}}\)) is estimated as
to account for the possibility of large temperature impact on CH4 emissions as reported by Olofsson et al.37 for a lower EF.
Estimation of WTW GHG emissions
The GHG emissions considered in this study include CO2, CH4, and nitrous oxide (N2O). The CO2 equivalents for CH4 and N2O were calculated with 100-year GWPs of 30 and 268 for fossil fuel combustion, respectively12. Fuel life-cycle analyses have been conducted for gasoline, diesel and NG in the transportation sector in China, and the reported GHG emissions per fuel (MJ) consumed are listed in Supplementary Table 6. Vehicle CH4 emissions from NGVs were largely neglected in previous studies and were included here. Therefore, WTW GHG emissions per km traveled from NGVs can be estimated as
where FC is the fuel consumption (MJ km−1), GEF is the previously reported fuel life-cycle GHG emissions (kg CO2eq MJ−1), \(M_{{\mathrm{CH}}_{\mathrm{4}}}\) and MC are the molar weights of CH4 and CO2, \({\mathrm{EF}}_{{\mathrm{CO}}_{\mathrm{2}}}^{{\mathrm{energy}}} = 55.72\) (kg CO2 MJ−1) is the CO2 emission factor per MJ natural gas consumed recommended by the IPCC58, and \({\mathrm{GWP}}_{{\mathrm{CH}}_{\mathrm{4}}} = 30\) is the 100-year GWP for CH4. Fuel consumption can be found in Supplementary Table 7. The \({\mathrm{EF}}_{{\mathrm{CO}}_{\mathrm{2}}}^{{\mathrm{energy}}}\) includes CO2 oxidized from the escaped fuel carbons (in the form of CO, CH4, and other hydrocarbons)58. Carbon emissions in the form soot is ignored since the reported soot emissions are extremely low for NGVs (<1 × 10−3%)59. In addition, we also assigned 5% uncertainty to \({\mathrm{EF}}_{{\mathrm{CO}}_{\mathrm{2}}}^{{\mathrm{energy}}}\) to account for potential changes in the oxidation rate as well as potential variation in the composition of natural gas (previously reported value ranges from 55.54 to 57.7 kg CO2 MJ−1 for China)14,17.
Compilation of the bottom-up CH4 emission inventory for NGVs in China
The total CH4 emissions from NGVs in China are estimated by multiplying the category-specific ERs to the corresponding CO2 emissions. The CO2 emissions from NGVs are calculated using the estimated NG consumption based on vehicle population and annual mileage traveled in each category. The estimated NG consumption is consistent with the official statistics (Fig. 3a). Four categories are defined: NG taxis, private light-duty NGVs, NG buses, and heavy-duty NG trucks. We estimate CH4 emissions from NG taxis and light-duty NGVs separately because of the significant difference between their annual mileage traveled (Supplementary Table 8). Therefore, CH4 emissions from NGVs can be described as
where i is the vehicle category, y is the age of the vehicles (compulsory retirement age (yr) ranges from 8 to 15, see Supplementary Table 9 for more details), AMTi,y is the annual mileage traveled by vehicles in category i with age y (km, see Supplementary Table 9 for details), FCi is the fuel consumption for category i (MJ km−1, see Supplementary Table 7), \({\mathrm{EF}}_{{\mathrm{CO}}_{\mathrm{2}}}^{{\mathrm{energy}}}\) is the energy-specific CO2 emission factor58, and VPi,y is the vehicle population for category i with age y. Uncertainty of annual emissions are calculated using uncertainty propagation, and relative standard errors for these parameters can be found in Supplementary Table 11.
Calculating GHG emission changes of switching to NGVs
The GHG emission changes of switching to NGVs are calculated similar to total CH4 emissions from NGVs
where WTW GHGNG,I is the WTW GHG emission of NGVs in category i, and WTW GHGCG/CD,I is the WTW GHG emission of conventional gasoline or diesel vehicles in category i.
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Data availability
Time series of raw observations used for emission ratio calculations (10 Hz), time series of ΔCH4:ΔCO2 and ΔNH3:ΔCO2, and their determination coefficients (R2) are included in Supplementary Data 1. The data are also available from DataSpace at Princeton University [https://doi.org/10.34770/t009-7064]. Other data related to emission calculation are listed in the main text or in Supplementary Information. Source data are provided with this paper.
Code availability
The source codes for calculating enhancement ratios and R2 and for Gaussian puff model are provided within Supplementary Data 1. The codes are also archived in https://github.com/dp7-PU/CH4_from_NGV_in_China.
References
NGV Global. NGV Statistics. http://www.ngvglobal.org/ngv-statistics/ (2019).
Thiruvengadam, A., Besch, M., Padmanaban, V., Pradhan, S. & Demirgok, B. Natural gas vehicles in heavy-duty transportation-A review. Energy Policy 122, 253–259 (2018).
Hao, H., Liu, Z., Zhao, F. & Li, W. Natural gas as vehicle fuel in China: a review. Renew. Sustain. Energy Rev. 62, 521–533 (2016).
Moultak, M., Lutsey, N. & Hall, D. Transitioning to Zero-Emission Heavy-duty Freight Vehicles. https://theicct.org/publications/transitioning-zero-emission-heavy-duty-freight-vehicles (2017).
National Development and Reform Commission of the People’s Republic of China. 13th Five-Year Plan for Natural Gas Development. https://www.ndrc.gov.cn/fggz/fzzlgh/gjjzxgh/201706/t20170607_1196794.html (2017).
Wu, Y. et al. On-road vehicle emissions and their control in China: a review and outlook. Sci. Total Environ. 574, 332–349 (2017).
Ministry of Ecology and Environment of the People’s Republic of China. China Vehicle Environmental Management Annual Report. http://www.gov.cn/guoqing/2019-04/09/5380744/files/88ce80585dfd49c3a7d51c007c0a5112.pdf (2018).
State Council of the People’s Republic of China. Three-Year Action Plan to Win the Blue Sky Defense War. www.gov.cn/zhengce/content/2018-07/03/content_5303158.htm (2018).
Xie, G. Record Sales of LNG Heavy-Duty Trucks in the First Half of 2019! 8.5 Million Vehicles Sold! 300% Increase. https://finance.sina.com.cn/chanjing/cyxw/2019-01-02/doc-ihqfskcn3409487.shtml (2019).
Zhang, S. et al. Can Euro V heavy-duty diesel engines, diesel hybrid and alternative fuel technologies mitigate NOX emissions? New evidence from on-road tests of buses in China. Appl. Energy 132, 118–126 (2014).
Guo, J. et al. On-road measurement of regulated pollutants from diesel and CNG buses with urea selective catalytic reduction systems. Atmos. Environ. 99, 1–9 (2014).
Myhre, G. et al. Anthropogenic and natural radiative forcing. Clim. Change 423, 658–740 (2013).
Peng, S. et al. Inventory of anthropogenic methane emissions in mainland China from 1980 to 2010. Atmos. Chem. Phys. 16, 14545–14562 (2016).
Song, H., Ou, X., Yuan, J., Yu, M. & Wang, C. Energy consumption and greenhouse gas emissions of diesel/LNG heavy-duty vehicle fleets in China based on a bottom-up model analysis. Energy 140, 966–978 (2017).
HE, L. et al. CH4 and N2O emission inventory for motor vehicles in China in 2010. Res. Environ. Sci. 27, 28–35 (2014).
Huo, H., Zhang, Q., Liu, F. & He, K. Climate and environmental effects of electric vehicles versus compressed natural gas vehicles in China: a life-cycle analysis at provincial level. Environ. Sci. Technol. 47, 1711–1718 (2013).
Ou, X., Zhang, X. & Chang, S. Alternative fuel buses currently in use in China: life-cycle fossil energy use, GHG emissions and policy recommendations. Energy Policy 38, 406–418 (2010).
Burnham, A., Wang, M. & Wu, Y. Development and applications of GREET 2.7—The Transportation Vehicle-CycleModel. https://doi.org/10.2172/898530~ (2006).
Clark, N. N. et al. Pump-to-wheels methane emissions from the heavy-duty transportation sector. Environ. Sci. Technol. 51, 968–976 (2016).
Clark, N. N. et al. Future methane emissions from the heavy-duty natural gas transportation sector for stasis, high, medium, and low scenarios in 2035. J. Air Waste Manag. Assoc. 67, 1328–1341 (2017).
Yan, X. & Crookes, R. J. Life cycle analysis of energy use and greenhouse gas emissions for road transportation fuels in China. Renew. Sustain. Energy Rev. 13, 2505–2514 (2009).
Ou, X. & Zhang, X. Life-cycle analyses of energy consumption and GHG emissions of natural gas-based alternative vehicle fuels in China. J. Energy 2013, 268263 (2013).
Hu, N. et al. Large methane emissions from natural gas vehicles in Chinese cities. Atmos. Environ. 187, 374–380 (2018).
Petrov, A. W., Ferri, D., Tarik, M., Kröcher, O. & Van Bokhoven, J. A. Deactivation aspects of methane oxidation catalysts based on palladium and ZSM-5. Top. Catal. 60, 123–130 (2017).
Ministry of Transport of the People’s Republic of China. Vehicle “oil to gas” Technical Equipment Needs to be Upgraded (In Chinese). http://www.mot.gov.cn/jiaotongyaowen/201808/t20180816_3058294.html (2018).
Anenberg, S. C. et al. Impacts and mitigation of excess diesel-related NO x emissions in 11 major vehicle markets. Nature 545, 467–471 (2017).
Ministry of Ecological Environment of the People’s Republic of China. Limits and Measurement Methods for Emissions from Diesel Fuelled Heavy-duty Vehicles (China VI). http://www.mee.gov.cn/ywgz/fgbz/bz/bzwb/dqhjbh/dqydywrwpfbz/201807/t20180703_445995.shtml (2018).
Hargreaves, D. & Baker, C. Gaussian puff model of an urban street canyon. J. Wind Eng. Ind. Aerodyn. 69, 927–939 (1997).
Sun, K., Tao, L., Miller, D. J., Khan, M. A. & Zondlo, M. A. On-road ammonia emissions characterized by mobile, open-path measurements. Environ. Sci. Technol. 48, 3943–3950 (2014).
Sun, K. et al. Vehicle emissions as an important urban ammonia source in the United States and China. Environ. Sci. Technol. 51, 2472–2481 (2017).
Ministry of Environmental Protection of the People’s Republic of China. Limits and Measurement Methods for Exhaust Pollutants from Compression Ignition and Gas Fuelled Positive Ignition Engines of Vehicles (III, IV, V). http://www.mee.gov.cn/ywgz/fgbz/bz/bzwb/dqhjbh/dqydywrwpfbz/200701/t20070101_67495.htm (2005).
Thiruvengadam, A. et al. Unregulated greenhouse gas and ammonia emissions from current technology heavy-duty vehicles. J. Air Waste Manag. Assoc. 66, 1045–1060 (2016).
Karavalakis, G. et al. Regulated, greenhouse gas, and particulate emissions from lean-burn and stoichiometric natural gas heavy-duty vehicles on different fuel compositions. Fuel 175, 146–156 (2016).
Yoon, S. et al. Criteria pollutant and greenhouse gas emissions from CNG transit buses equipped with three-way catalysts compared to lean-burn engines and oxidation catalyst technologies. J. Air Waste Manag. Assoc. 63, 926–933 (2013).
Hajbabaei, M., Karavalakis, G., Johnson, K. C., Lee, L. & Durbin, T. D. Impact of natural gas fuel composition on criteria, toxic, and particle emissions from transit buses equipped with lean burn and stoichiometric engines. Energy 62, 425–434 (2013).
Nylund, N.-O. & Koponen, K. Fuel and Technology Alternatives for Buses: Overall Energy Efficiency and Emission Performance. https://cris.vtt.fi/en/publications/fuel-and-technology-alternatives-for-buses-overall-energy-efficie (2012).
Olofsson, M., Erlandsson, L. & Willner, K. Enheanced Emission Performance and Fuel Efficiency for HD Methane Engines (Final Report). https://www.ieabioenergy.com/wp-content/uploads/2014/09/Enhanced-emission-performance-and-fuel-efficiency-of-HD-methane-engines-2014-Final-report.pdf (2014).
Grigoratos, T., Fontaras, G., Martini, G. & Peletto, C. A study of regulated and green house gas emissions from a prototype heavy-duty compressed natural gas engine under transient and real life conditions. Energy 103, 340–355 (2016).
Stettler, M. E., Midgley, W. J., Swanson, J. J., Cebon, D. & Boies, A. M. Greenhouse gas and noxious emissions from dual fuel diesel and natural gas heavy goods vehicles. Environ. Sci. Technol. 50, 2018–2026 (2016).
Einewall, P., Tunestål, P. & Johansson, B. Lean Burn Natural Gas Operation vs. Stoichiometric Operation with EGR and A Three Way Catalyst. Report no. 0148-7191 (SAE Technical Paper, 2005).
General Administration of Quality Supervision. Fuel Consumption Limits for Heavy-Duty Commercial Vehicles. http://www.gb688.cn/bzgk/gb/newGbInfo?hcno=9C036161B1CEAFDA5225B7184A67229B (2018).
National Bureau of Statistics of China. China Statistical Yearbook (National Bureau of Statistics of China, 2002–2018).
Zhao, Y., Nielsen, C. P., McElroy, M. B., Zhang, L. & Zhang, J. CO emissions in China: uncertainties and implications of improved energy efficiency and emission control. Atmos. Environ. 49, 103–113 (2012).
Xi, Y., Ottinger, N. & Liu, Z. G. Effect of Reductive Regeneration Conditions on Reactivity and Stability of A Pd-based Oxidation Catalyst for Lean-Burn Natural Gas Applications. Report no. 0148-7191 (SAE Technical Paper, 2016).
Hu, W. et al. Enhancement of activity and hydrothermal stability of Pd/ZrO2-Al2O3 doped by Mg for methane combustion under lean conditions. Fuel 194, 368–374 (2017).
Kim, J., Kim, E., Han, J. & Han, H. S. Pt/Pd bimetallic catalyst with improved activity and durability for lean-burn CNG engines. SAE Int. J. Fuels Lubr. 6, 651–656 (2013).
Petrov, A. W. et al. Stable complete methane oxidation over palladium based zeolite catalysts. Nat. Commun. 9, 1–8 (2018).
Reynolds, C. C., Grieshop, A. P. & Kandlikar, M. Climate and health relevant emissions from in-use Indian three-wheelers fueled by natural gas and gasoline. Environ. Sci. Technol. 45, 2406–2412 (2011).
Ong, H., Mahlia, T. & Masjuki, H. A review on emissions and mitigation strategies for road transport in Malaysia. Renew. Sustain. Energy Rev. 15, 3516–3522 (2011).
Lowell, D. & Kamakaté, F. Urban Off-Cycle NOX Emissions from Euro IV/V Trucks and Buses (The International Council on Clean Transportation, 2012).
Franco, V. et al. Road vehicle emission factors development: a review. Atmos. Environ. 70, 84–97 (2013).
Xie, S. et al. Real-world emission characteristics of natural gas-gasoline bi-fuel vehicles. Acta Sci. Circumstantiae 31, 2347–2353 (2011).
Cedigaz. India’s Vision to A Gas-based Economy Drivers and Challenges. https://www.cedigaz.org/indias-vision-gas-based-economy-drivers-challenges/ (2017).
Singh, S.P. SC Order on Conversion of Diesel-petrol Taxis to CNG will Boost Volumes for CGD Players, Says India Ratings. https://www.business-standard.com/article/current-affairs/sc-order-on-conversion-of-diesel-petrol-taxis-to-cng-will-boost-volumes-for-cgd-players-says-india-ratings-116050401127_1.html (2016).
Reynolds, C. C. O. & Kandlikar, M. Climate impacts of air quality policy: switching to a natural gas-fueled public transportation system in New Delhi. Environ. Sci. Technol. 42, 5860–5865 (2008).
Tao, L. et al. Low-power, open-path mobile sensing platform for high-resolution measurements of greenhouse gases and air pollutants. Appl. Phys. B 119, 153–164 (2015).
Hesterberg, T. W., Lapin, C. A. & Bunn, W. B. A comparison of emissions from vehicles fueled with diesel or compressed natural gas. Environ. Sci. Technol. 42, 6437–6445 (2008).
Eggleston, S., Buendia, L., Miwa, K., Ngara, T. & Tanabe, K. 2006 IPCC Guidelines for National Greenhouse Gas Inventories Vol. 5 (Institute for Global Environmental Strategies Hayama, Japan, 2006).
Amirante, R., Distaso, E., Tamburrano, P. & Reitz, R. D. Measured and Predicted Soot Particle Emissions from Natural Gas Engines. Report no. 0148-7191 (SAE Technical Paper, 2015).
Acknowledgements
We acknowledge Levi Stanton, Victor Fu, and the CAREBeijing/NCP science team for their support during the field sampling. The research was supported by the Council for International Teaching and Research at Princeton University, the National Geographic Air and Water Conservation Fund (GEFC16-13), NSF Center for Mid-Infrared Technologies for Health and the Environment (MIRTHE, NSF EEC-0540832). Special thanks to LI-COR Biosciences (environmental division) for providing a set of LI-COR sensors for the mobile laboratory.
Author information
Authors and Affiliations
Contributions
D.P. contributed to the design of the work, acquisition of the data, data analysis, and interpretation of data and led the writing. L.T. contributed to the design of the work, acquisition of the data, and interpretation of data. K.S. contributed to the design of the work, acquisition of the data, and interpretation of data. L.M.G. contributed to the acquisition of the data, data analysis, and interpretation of data. D.J.M. the contributed to acquisition of the data and interpretation of data. T.Z. contributed to the design of the work. Y.Q. contributed to the interpretation of data. Y.Z. contributed to the design of the work. D.L.M. contributed to the design of the work and interpretation of data. M.A.Z. contributed to the design of the work, data analysis, interpretation of data, and writing.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Peer review information Nature Communications thanks Oliver Krocher and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Source data
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Da Pan, Tao, L., Sun, K. et al. Methane emissions from natural gas vehicles in China. Nat Commun 11, 4588 (2020). https://doi.org/10.1038/s41467-020-18141-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-020-18141-0
This article is cited by
-
Green Energy Pathways Towards Carbon Neutrality
Environmental and Resource Economics (2024)
-
Hydrophobic Modification of Small-Pore Pd-SSZ-13 Zeolites for Catalytic Methane Combustion
Topics in Catalysis (2024)
-
Future reductions of China’s transport emissions impacted by changing driving behaviour
Nature Sustainability (2023)
-
Impact assessment of crude oil mix, electricity generation mix, and vehicle technology on road freight emission reduction in China
Environmental Science and Pollution Research (2022)
-
Near and long-term perspectives on strategies to decarbonize China’s heavy-duty trucks through 2050
Scientific Reports (2021)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
