
Abstract
The number of spatiotemporal data sets has increased rapidly in the last years, which demands robust and fast methods to extract information from this kind of data. Here, we propose a network-based model, called Chronnet, for spatiotemporal data analysis. The network construction process consists of dividing a geometric space into grid cells represented by nodes connected chronologically. Strong links in the network represent consecutive recurrent events between cells. The chronnet construction process is fast, making the model suitable to process large data sets. Using artificial and real data sets, we show how chronnets can capture data properties beyond simple statistics, like frequent patterns, spatial changes, outliers, and spatiotemporal clusters. Therefore, we conclude that chronnets represent a robust tool for the analysis of spatiotemporal data sets.
Similar content being viewed by others


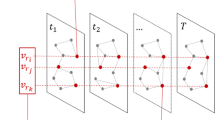
Introduction
Large amounts of spatiotemporal data are collected every day from several domains, including georeferenced climate variables, epidemic outbreaks, crime events, social media, traffic, and transportation dynamics, among many others. Analyzing and mining such kind of data is of great importance for advancing the state-of-the-art in many scientific problems and real applications. Nevertheless, data with spatial and temporal characteristics have different properties in comparison to relational sources studied in classical data mining literature1: they present temporal and/or spatial dependencies, in which instances are not independent or identically distributed. It means that samples can be structurally related in some spatial regions or specific temporal moments. Also, they are non-static, i.e., the instances can change their class attribute depending on time and location. Thus, traditional data mining methods are not the ideal tools for spatiotemporal data, which can result in poor performance and misleading interpretation1,2.
Spatiotemporal data mining (STDM) is an emerging field that proposes novel methods for analyzing event-based data, trajectories, time-series, spatial maps, and raster data1. Some of the main STDM tasks are clustering, anomaly detection, frequent pattern mining, relationship mining, change detection, and predictive learning. STDM brought new challenges and opportunities in several application domains. In this context, some works have employed networks as a way of representing and analyzing spatiotemporal information3,4,5,6. The interest is justified by the benefits that the network representation provides, like the ability to describe sub-manifold in dimensional space and to capture dynamic and topological structures—hierarchical structures (communities) and global or local patterns, independent of the data distribution6,7. The network-based representation of spatiotemporal data also allows the discovery of different patterns like local-range spatial dependencies and long-distant correlations4,5,8.
Functional or correlation networks9 have been widely applied to map spatiotemporal data into networks. Such a method connects nodes, i.e., time-series from spatial grid-cells, according to their correlation. Functional networks have been employed in a diversity of areas like: in earth sciences4,5,8,10,11, bioinformatics12, finance13, among others. One drawback of this kind of networks appears when short-length time series are considered, making the statistical significance of correlations questionable and may result in spurious links in the network. Additionally, in the case of event-based data, it is common to have a higher proportion of—no events—or values equal to zero throughout time, which clearly affect the correlation results. Alternative methods have been proposed to construct networks6,7,14, like the visibility property in time series14. However, this method produces single and static representations of the time-series, discarding the spatial location.
Another way to construct networks considers the chronological order in the spatiotemporal events to define the links. It was applied to study seismic events by constructing a network from a geographic region divided into small cubic cells15,16. It also was used to analyze wildfire events in the Amazon basin by constructing the network following the co-occurrence of events in a grid division of the area3. The authors presented two approaches—a single-layer network and temporal network—for data analysis. Although the previous works have identified valuable information in a couple of domains, the proposed methods and results are restricted to the specific problem and were not generalized to a variety of domains with spatiotemporal events.
Here, we provide a general method for representing spatiotemporal events with networks, as a structure for dealing with data mining problems, like clustering, predictive learning, pattern mining, anomaly detection, change detection, and relationship mining. The idea is to divide the geometric space into grid cells that are represented by nodes. Links are established between the nodes in chronological order, i.e., nodes are connected if successive events occur in the respective cells. Therefore, the links represent events in a chronological occurrence, which we call, for the sake of simplicity, as chronnet. In this way, we generalize the previously reported mechanism of connections3,15,16 transforming the spatiotemporal data set into a network, as explored in other domains like text-mining17,18 and social media19,20.
In such a way, recurrent consecutive events are represented by strong (high weighted) links. The constructed network presents non-trivial characteristics obeying the original spatiotemporal events distribution, such as scale-free and small-world for power-law event distribution. The chronnets allow the detection of a new type of spatiotemporal community and permit the identification of influential nodes and outliers. More importantly, the method is computationally efficient—with linear complexity, can be easily parallelized and distributed, and can be adapted according to the domain, e.g., different number of sequence connections, grid division, and time windows in the case of temporal analyses.
The network construction method has been tested and analyzed using artificial and real data. We propose a simple data set generator to explain how the topology of the chronnet captures different spatial and temporal characteristics. Specifically, we use the proposed data set generator to experimentally describe how chronnet measures can be used to extract information from spatiotemporal data. We also applied our model to a real data set composed of global fire events as a case study. The results show that our model is able to describe the frequency of fire events, regions with outlier activity, and the fire seasonal activity using a single chronnet and complex network measures.
Results
Artificial data sets and dynamical systems
In this section, we construct data sets to generate static chronnets, i.e., the whole data set is used to construct a single chronnet. We employ this single network to characterize the whole historical activity using network theory. We provide interpretations for the network measures in the context of chronnets and show how these measures can be used to extract information from spatiotemporal data.
Figure 1 presents three spatiotemporal data sets constructed using our data generator. Each data set was constructed considering a different probability distribution (P): uniform, power-law, and exponential. For each of them, we also present the undirected chronnets constructed for and their degree distributions. The uniform probability distribution generates a Gaussian degree distribution, the power-law distribution creates a scale-free21 chronnet, and the exponential probability distribution generates a chronnet with exponential degree distribution. Scale-free networks are characterized by the presence of many low degree nodes and just a few high degree nodes (hubs). Exponential degree distributions have a fast decay, which makes the hubs less numerous than what was expected in a scale-free network. The presence of hubs reveals interesting features that can be explored. In summary, the degree distribution of a chronnet captures the probability distribution of event generation.

a uniform, d power-law, and g exponential. For simplicity purposes, we plot part of the data set. For each distribution, we illustrate the respective networks (b, e, and h) and degree distributions (c, f, and i).
Figure 2 illustrates an artificial data set generated with a probability distribution P following a power-law. In this case, the maximum probability p ∈ P and the total time of generation T are higher than the previous case (Fig. 1d). When P or/and T are high enough, the resulting data set have a large number of events and the resulting chronnet tends to be highly connected (〈k〉 ≈ n − 1). In these situations, the node strength provides more information than the node degree. In Fig. 2b, we show that the strength distribution can capture the power-law probability P. From the strength distribution it is possible to observe that chronnets have weak nodes. In Fig 2c, we show the influence of the weak links pruning on the topology of the chronnet considering the same artificial data set from Fig. 2. As previously described, the resulting chronnet for this data set is densely connected, which does not bring much information. However, it is possible to reveal the original probability distribution P by pruning weak links from the network (τ = 9). The pruned chronnet has a degree distribution that follows a power-law (γ = 2.01), similar to the probability distribution (P) used to construct the data set.

a An example of a data set with a power-law distribution of event generation that creates a highly connected network. In these cases, the strength distribution of the resulting chronnets b provides a better description of the network. Another possibility is to consider a pruning threshold (τ) to remove weak links and to analyze the degree distribution. c Shows the degree distributions for τ = 1, 2, 5, and 9 represented by different colors and marks. The blue lines (b and c) represent the power-law fitting. In both cases (b and c), it is possible to observe the original power-law distribution from the original data set (a).
The pruning process has a strong influence on the network. The edge density (D) presents a fast decay event with small values of τ. For example, in Fig. 2 when τ = 9, only 6% of the original links remain. This fast decay reflects the strength distribution that shows that the great majority of nodes have low strength. It means that even a very low threshold will remove many links. Therefore, the pruning threshold τ cannot be high otherwise it will remove too many links and might make the network disconnected. When the pruning threshold is low, it is possible to remove weak links but still preserve part of the strongest links and the nodes in the largest component. These results show, for a specific data set, how the pruning affects the chronnet and how it can be used to reveal interesting topological features. Other data sets may respond differently to the pruning process, which means that the pruning should be analyzed in particular.
Important nodes in chronnets can be detected by applying network centrality measures22. In Fig. 3, we present four data sets with some specific temporal characteristics. The first data set was constructed using the power-law probability distribution illustrated in Fig. 1d. The resulting chronnet (Fig. 3e) shows that the cells with higher event generation probability (p) tend to generate a high number of connections. These hubs can be captured by the degree centrality. The second data set (Fig. 3b) was constructed by generating Gaussian distributions in two fixed positions (x and y) alternated in time, forming spatiotemporal clusters. The resulting chronnet (Fig. 3f) is composed of two communities. By definition, communities have high intra-community links but low inter-communities connections. This feature makes the betweenness higher in links and nodes that connect communities. Therefore, the betweenness centrality can be used to detect nodes connecting communities. The third and fourth data sets (Fig. 3c, d) were constructed by sampling two coordinates of the Lorenz and Rössler systems, respectively, in chaotic regimes. The resulting chronnet for the Lorenz equations (Fig. 3g) has a topology that reproduces the characteristic two-loop form of the trajectory connected by a single node. This node has the shortest average distance between the other ones, which indicates that the represented cell has the shortest temporal distance to all the other ones when considering all the combinations of cells. This central node has the highest closeness centrality. The chronnet for the Rössler system (Fig. 3h) also reproduces in the topology some characteristics of the trajectory. Most part of the time, it oscillates in the x-dimension leading to stronger links between the nodes that represent these cells. Nodes with stronger links have higher closeness centrality when the weights are considered23, a measure that can be used to find these nodes.

The upper three figures a–d illustrate data sets used to construct the chronnets, respectively illustrated below them e–h. Only parts of the data set are shown for illustrative reasons. a Data set constructed considering the power-law probability illustrated in Fig. 1d and T = 105. b Data set constructed by generating 40 Gaussians (σ = 100) that alternate in two different locations (T = 106). c Data set constructed by sampling (T = 200 and Δt = 0.01) the x and y coordinates of one realization of the Lorenz system35 with parameters σ = 10, β = 8/3, and ρ = 28, resulting in a chaotic trajectory. d Data set constructed by sampling (T = 1000 and Δt = 0.02) the x and z coordinates of one realization of the Rössler system35 with parameters a = 0.2, b = 0.2, and c = 5.7, also resulting in a chaotic trajectory. The chronnets were constructed considering grid sizes e and f Gr10×10, g Gr15×15, and h Gr30×30. Weak links were pruned from all the chronnets except for the Rössler system h considering e and f τ = 1 and g τ = 15. The node size and colors represent the respective centrality measure in the legend below each network.
In Fig. 4, we illustrate the community detection process. First, we generate a spatiotemporal data set composed of four different periods. Different event probability distributions (P) were arbitrarily chosen in such a way that creates four temporal clusters (Fig. 4b) but also generates outlier events with a smaller probability. We constructed the chronnet and applied the Fast greedy algorithm24 to find hierarchical community structures (Fig. 4c). The best partition (best modularity) for the chronnet is formed by four clusters (Fig. 4d) which exactly correspond to those ones whose events occur in the same four periods in T during the data set construction. By choosing the number of communities (dendrogram), it is possible to use chronnets to cluster spatiotemporal data set in distinct spatial regions. For example, the same chronnet can be divided into two communities by cut the dendrogram into two clusters. This partition splits the time T into two intervals that correspond to the first and the last two periods.

a We propose an artificial data set constructed by changing the event probability distribution P in four intervals with total time T = 12,000. Each of the four small grids illustrates the probabilities and the generated events in those intervals. A few outlier events were generated, represented by points outside the region with higher probability. b The resulting data set is composed by merging the events generated during the four periods, represented by colors. c Dendrogram obtained by the Fast greedy algorithm24. Different colors represent the four communities achieved with the best modularity division. d The resulting chronnet is presented in a grid layout that corresponds to the same position in the data set grid. e Spatiotemporal clustering using ST-DBSCAN25 where “×” denotes events that were incorrectly clustered.
We applied our spatiotemporal data clustering method to the artificial data set presented in Fig. 4 and compared to the clustering result for the ST-DBSCAN, a well-known clustering algorithm for spatiotemporal data25. For the ST-DBSCAN, we tested all the combinations for the three parameters: eps = {0, 10, 20, …, 3000}, eps2 = {0, 10, 20, …, 3000}, and minpts = {0, 5, 10, …, 200}. Our results show that the proposed method can correctly cluster all the points while ST-DBSCAN achieves a maximum adjusted rand index of 0.94. As illustrated in Fig. 4e, the ST-DBSCAN algorithm mainly fails to cluster the outlier events. This result shows that the proposed can successfully find temporal clusters.
Spatial changes can also be detected using the community structure in chronnet. As described in the “Methods” section, change points are defined as changes in the communities where the events occur in time. In Fig. 5 we illustrate this process using an artificial data set composed by groups of points forming spatiotemporal Gaussians that alternate in time. The resulting chronnet (Fig. 5b) is composed of three communities that represent the three spatial regions where the events occur. For every event in the data set, we construct a time series (Fig. 5c) with the node community where each event is located. Step changes in this time series represent spatial changes in the data set.

a Artificial data set composed by groups of points sampled from Gaussian distributions in three spatial locations (point color) alternating in time. b The resulting chronnet is composed of three communities (node colors) obtained by the Fast greedy community detection24. c A time series with the node community where each event from the data set.
Real case application using global fire detections data
Here, we apply chronnets to analyze a real spatiotemporal data set composed by fire detections. Similar to the previous analysis with the artificial data sets, we use a single chronnet and network measures to describe the historical fire activity (2003–2018). To remove some weak links, we considered a small pruning threshold τ = 2 which keeps 32% of the original links.
In Fig. 6, we present the degree and strength distributions for the resulting chronnet. High degree nodes account for cells whose fire activity occurs consecutively to other cells while the strength captures the number of events. The strength does not capture here the total number of events since links were pruned. In general, regions with high degrees tend to have high strengths. Both measures show the regions with higher fire activity, e.g., Brazil, large parts of Africa, China, and North Australia. This pattern was observed in previous studies26,27.

a Degree and b strength distributions. A small pruning threshold τ = 2 was considered. The red circles (a) mark the 2% of higher degree nodes. The inner plots show the probability distributions. Red and blue lines illustrate the fit of power-law and log-normal distribution, respectively39.
The degree distribution follows a power-law (γ = 4.28) after a low-degree saturation. Power-law degree distributions are characterized by the presence of many low degree nodes and a few high degree nodes (hubs). The degree exponents γ > 3 show that the distributions decay fast to make the hubs less numerous than what was expected in scale-free networks21. Therefore, we cannot affirm that the network is scale-free, but the presence of hubs reveals interesting features that can be explored. In the fire activity data set, hubs represent cells with periods of fire activity much longer than the other ones. In some cases, these uncommonly long activities are accounted for false wildfire detections like in regions with hot bare soils28. In other cases, hubs represent volcanoes or gas flares from oil and gas exploration. The outlier cells found by our method correspond to the cells with the highest number of fire detections marked as outliers in the original data set. This result is expected and shows the accuracy of the method.
The strength distribution can be partially fitted as a log-normal (μ = 7.21 and σ = 1.79) and a power-law (γ = 4.20) tail. The distribution shows that there is a high number of nodes with low strength (s ≤ 102), which mainly represent cells in medium and high latitudes (e.g. Patagonia region and the Nordics) with very low fire activity. After this low-strength saturation, the number of nodes decreases as a log-normal distribution until a transition point (s ≥ 5.1 × 104), where the number of nodes decays faster as the fitted log-normal distribution, which is better represented as a power-law. This interval comprises the regions with medium (103 ≤ s ≤ 104) like the Russia and USA, and high strength nodes (s > 104), which correspond to high fire activity regions occurring mainly in the tropics, like Brazil, Central America, north Australia, Indochinese Peninsula, and large parts of Sub-Saharan Africa. This later is where the highest strength nodes appear (power-law tail), corresponding to the region in the southern Democratic Republic of the Congo and Northern Angola, as well as Southern Sudan and the Central African Republic, already described in previous works26,27.
As demonstrated, simple chronnet measures like the degree and strength can be used to describe the distribution of the events in the data set. Other network measures can be used to describe different aspects of the data set. The average path length L = 3.21, indicates that the average time steps to occur consecutive events between any pair of cells is on average small. The transitivity C = 0.34 shows that there is a clustering structure in the network, which is an expected result since close regions tend to have similar climate and land use. Since L is small but C is not, the resulting chronnet presents the small-world feature21,29,30. The presence of hubs is highly responsible for decreasing the average path length. It means that, for any pair of nodes on the globe, the average number of edges, i.e., consecutive events, to co-occur wildfires is low.
Another capability of chronnets is to represent groups of cells whose activity occurs in the same period as communities. Figure 7 illustrates community structures for the wildfire data set. Most of the communities are formed by nodes that represent relatively near geographical regions. The spatial distribution of the communities can be explained by the similarity of climate and land use in near regions that tends to have fire seasons in the same period27. However, some communities are formed by distant regions. For example, the southwest-most community in South America (light green) is the same one in the small region in South Western Australia. It is important to note that we have presented the results for just one network partition (38 communities). Other algorithms, as the fast greedy algorithm24, returns a hierarchy of communities that can be used to divide the area of study in an arbitrary number of regions. In the fire data set, this hierarchy can be used to study the fire seasons in different geographical scales.

Only 20% of strongest links were considered and 1% of the largest degree nodes were removed (outliers). Communities were achieved using the label propagation method40. Colors represent the 38 communities.
Discussion
In this paper, we present a network-based representation model for spatiotemporal data analyses called chronnets, whose main goal is to capture recurrent consecutive events in a data set. In this way, we transform spatiotemporal events into a network with a construction method that is fast (linear time complexity) and thus can be applied to large data sets. The model permits the use of different tools from network science and graph mining to extract information from spatiotemporal data sets. It can be used not just to describe, but also to compare data sets.
Our results show that the method can extract simple statistics as well as intricate and hidden information. Local network measures, as the degree and strength, can describe the event activities in each cell and can be used to detect cells with outlier activities, while centrality measures can be applied to detect important nodes. Global network measures describe the data set as a whole and can reveal features that cannot be detected by simply looking to single cells. For example, high transitivity indicates a high tendency of consecutive events to form triangles and cluster together. In these cases, community detection algorithms can be used to find communities, which represent groups of cells whose activity occurs in the same period of time. We also show how to apply our model to some STDM tasks, like frequent patterns detection, spatial changes identification, clustering, and outlier detection.
The aforementioned capabilities of the model were experimentally demonstrated using toy data sets generated by a simple probabilistic process here proposed. The model was also applied to real data set of global active fire detections, in which we described the frequency of fire events, outlier fire detections, and the seasonal activity, using a single chronnet. Some interesting aspects were found on the real data set. The average path length, which indicates that the average time steps to occur consecutive events between any pair of cells, is on average small. The chronnet presents a clustering structure with larger transitivity values, which is an expected result since close regions tend to have similar climate and land use. Then, the chronnet has the small-world property. The larger presence of hubs is responsible for decreasing the average path length. This result indicates that for any pair of nodes on the globe, the average number of edges, i.e., consecutive events, to co-occur wildfires is low. Therefore, we conclude that chronnets are a robust and fast model for spatiotemporal data analysis.
This work is extendable in many directions. The construction method can be improved by introducing controlling parameters to capture not just consecutive events but different lags. It will permit the detection of temporal patterns in other time scales. More variables can also be considered by applying the same grid division process used to transform the spatial coordinates into nodes. Another future work is the chronnets analysis from a temporal network perspective. Different methods of graph mining can also be used with chronnets to propose new pattern recognition techniques. The temporal patterns captured by chronnets can be used to propose new machine-learning tools or forecasting methods. In the particular application problem, new analyses focusing on some specific regions with high fire intensity27, such as the Amazon forest, South America, or Africa, can be developed. Furthermore, other spatiotemporal data sets may also be analyzed with chronnets.
Methods
Chronnet construction
Our method aims to transform a spatiotemporal data set into a network whose links represent events in a chronological approach, simply named chronnet. Let us consider a spatiotemporal data set X composed of time-ordered sequence of events X = {e1, e2, …, eT}, where an event ea = (la, ta) is represented by its location la = (xa, ya) and time ta ∈ {t1, t2… ≤ tT}. Note that an event may also provide more measurements as additional information about the occurrence. The method for constructing the chronnet G(V, E) from the data set consists of three steps. In the first step, the studied geometric area is divided into grid cells and each grid-cell is represented by a node vi ∈ V. The second step consists of defining a time length for the network construction. The time length Δt divides the spatiotemporal data set into time windows. If Δt = T, the whole data set will be used to generate the single network. If Δt < T, then each time window will be used to create a layer (snapshot) of the temporal network. The final step comprises the network connections.
Formally, a directed link (vi, vj) is established from node vi to node vj if two consecutive events ea and ea+h, within a time window of a predetermined size h ≥ 1, co-occur therein the cells i and j, respectively. A threshold parameter \({d}_{\max }\) may be considered to limit the maximum distance between links. In this case, vi and vj are connected iff the distance between two consecutive events ea and ea+h is smaller than \({d}_{\max }\), i.e., \(\exists \,({v}_{i},{v}_{j})\ \iff \ d({e}_{a},{e}_{a+h})\le {d}_{\max }\). The threshold parameter \({d}_{\max }\) can be used to avoid that events occurring in far regions be connected.
The process slides over the entire data set from the first to the last event. The link weight wij between two nodes vi and vj is the sum of consecutive events between them. Note that i = j represents self-loops used to count consecutive events that occur in the same cell. The main idea behind this construction process is to map recurrent consecutive events into strong (high weighted) links. The steps to construct a chronnet with a sliding window h = 1 is illustrated in Fig. 8.

a Given a time-ordered spatiotemporal data set, the first step consists of dividing the area of study into grid cells. b Shows a spatial representation of the data set using links between cells to indicate the temporal order they occur, in a sliding window of h = 1. c In a chronnet, nodes represent grid cells and links stand for co-occurred events between cells. Link weights indicate the number of consecutive events observed between cells.
In the following, we summarize the chronnet construction process. The first step consists of the grid division where the spatiotemporal data is separated into grid cells. Each cell is represented by a node in a chronnet. The second step corresponds to the definition of time window length. The whole period from the data set can be used to construct a single static network or the data set can be divided into time windows used to create layers (or snapshots) of a temporal network. Finally, the node connections are established by adding directed links between two nodes if two events co-occur within a sliding window of size h in the cells represented by them. Self-loops are used to denote consecutive events in the same cell.
Some comments on this construction method are remarked. First, it contains one parameter, the sliding window h, and one domain decision, the grid division which is a scale of coarse-graining. Since there is no priori rule to determine the grid size, it is a decision related to the application domain. Increasing the resolution impacts in the final network size and sparsity. On the other hand, lowing the resolution helps to remove redundancies in the observations, but may also result in a loss of spatial information. The same happens with the parameter h. The larger h, the more events are temporal aggregated and the denser the network. Both sliding window and grid size are primary decisions independent of performing temporal or single-network analysis.
Chronnets are by definition directed weighted graphs. In this paper, for simplicity purposes and without loss of generality, we opt for focusing on analyzing undirected weighted chronnets constructed by consecutive events (h = 1) without distance restriction (\({d}_{\max }=\infty\)). In an undirected chronnet, link weights represent the total number of events that co-occurred between two cells independently of which node appears first in time, i.e., the sum of in-link and out-link weights. In the rest of this paper, we use the term “chronnet” to refer to an undirected weighted network.
We consider in this paper, for simplicity reason, that the data set does not have parallel (same timestamp) events. However, this is not a limitation in the model. Parallel events can be treated by establishing links between all the combinations of different nodes with events in consecutive time stamps. Considering a time window h = 1 and two sets of nodes \({\{{v}_{1},{v}_{2},\ldots ,{v}_{r}\}}^{t}\) and \({\{{v}_{1},{v}_{2},\ldots ,{v}_{s}\}}^{t+1}\) whose cells have parallel events in time t and t + 1, respectively, a link is established between all the combinations of different nodes between both sets. We also consider only the spatial (x and y) locations and time of the events in the construction method but we emphasize that our proposed approach is not limited to these three variables. Our approach can be extended to more variables by applying the same grid division process to other variables.
Weak links in chronnets represent sporadic consecutive events between two cells that might not represent temporal patterns. These links may appear as a result of different factors. One common reason is the inaccurate or wrong records generated by distinct problems in the data gathering process31, leading to spurious links in the chronnet. To minimize these problems, we consider an optional pruning step that consists of removing links whose weights are equal or lower than a threshold τ. Pruning weak links will remove some of these wrong records from the analyses and can be used as an outlier removal step. This process can also be used to transform weighted chronnets into unweighted ones. In this case, only those links whose weights are higher than τ remain in the network.
An advantage of the construction process is its low time complexity. The time complexity for finding the cells whose events occur (grid division) is linear concerning the number of events if a squared grid is considered. Assuming no parallel events and that the events were recorded in chronological order (sorted) in the data set, the time complexity for constructing the chronnet is also linear to the total number of events T. If the data set is unsorted, the time complexity is bounded by the time complexity of the sorting algorithm. Even in the unsorted case, the time complexity is low, considering the fast sorting algorithms available. This process can be easily parallelized by breaking the sorted data set into smaller data sets, constructing smaller chronnets, and merging them. The parallelization can considerably speed up the construction process. Therefore, our method can is suitable to model large-scale spatiotemporal data sets.
Chronnet characterization
The degree ki of a node vi in a chronnet represents the number of other cells whose events occur consecutively in time with respect to vi. Higher degree nodes (hubs) represent cells with relatively longer periods of activity occurring simultaneously with many other cells. The activity period in a hub cell should be sufficiently higher than the others to allow the connection to several other cells.
The strength \({s}_{i}=\mathop{\sum }\nolimits_{j}^{n}{w}_{ij}\) is the sum of the weights of the node vi and represents the frequency that the events happened after or before any neighbor. A high node strength indicates a recurrent link between this node and at least one of its neighbors. High strength accounts for a higher number of events.
The degree distribution is the fraction of nodes with the same degree k, which could be seen as the probability P(k) of randomly selecting a node with degree k21. Recalling that in chronnets an edge represents consecutive events between two cells, the degree distribution represents how spatially distributed are the events over time. The more uniform is the degree distribution, the more spatially homogeneous occurred the events. When the chronnet exhibits heavy-tailed degree distribution, e.g. following a power law in the form P(k) ~ k−γ, then, most of the cells have a low degree, i.e., they present few events that co-occurred with other nodes. On the other hand, few cells have very high degrees (hubs), which means, the nodes present a larger number of spatiotemporal events that co-occurred with many other nodes of the grid. The strength distribution interpretation is analogous to degree distribution. In this case, the frequency of consecutive events (link weights) between nodes is also taken into account.
A path length in chronnets represents the number of consecutive events in a route between two nodes, i.e., how many consecutive historical events separate two cells. The simplest case is the one-path distance between nodes vi and vj, meaning that both nodes were consecutively activated after a while. A two-path distance means that it was necessary an intermediate or third node vk to occur a consecutive cascade of events between vi and vj, and so on for larger distances paths. Therefore, the shortest path distance, ℓi,j, is the minimum sequence of historical cascade activation that separates two nodes.
The average shortest path (〈ℓ〉) corresponds to the expected shortest path distance to occur an event activation between any pair of nodes. Then, the diameter (\(\max ({\ell }_{i,j})\)) is the longest shortest path distances to historical co-occur a cascade of events between the nodes on the chronnet.
Centrality measures quantify how influential or central nodes are, which can be defined in many ways22. It is important to mention that many centrality measures do not take into account the link weights. These measures are unappropriated for chronnets since they consider that strong (recurrent events) and weak links have the same influence. Therefore, two approaches can be considered: to use centrality measures for weighed graphs23 or to prune low weight links and then apply centrality measures for unweighted networks22.
One of the most straightforward definitions, the degree centrality, assumes that the most relevant nodes are those with the highest degrees. Considering a node vi and its degree ki, the degree centrality is \({C}_{i}^{\,{\mathrm{{deg}}}}={k}_{i}\). As discussed previously, high degree nodes in chronnets represent cells whose events occur consecutively to other many other cells. Another common measure is the betweenness centrality that quantifies how many times a node is traversed when considering the shortest paths between all node combinations in the network, defined as \({C}_{i}^{\,{\mathrm{{betw}}}}={\sum }_{jk}{n}_{i}^{jk}/{g}^{jk}\), where \({n}_{i}^{jk}\) is the number of shortest paths between nodes vj and vk that passes through vi and gjk is the total number of shortest paths between vj and vk. The betweenness centrality can detect nodes connecting communities (densely connected nodes with few connections between groups). The closeness centrality, defined as the inverse of the sum of distances dij between all combination of node vi and vj, i.e., \({C}_{i}^{\,{\mathrm{{clo}}}}=1/\mathop{\sum }\nolimits_{j = 1}^{n}{\ell }_{ij}\). In chronnets, the closeness centrality can be used to find those nodes whose consecutive events occur with less time steps to all the other ones. Some centrality measures were also extended to weighted graphs23. The closeness centrality, for example, takes the weights into account when calculating the ℓij between nodes.
Transitivity accounts for the proportion of cycles of order three on the network, which is a common property found in real-world networks21. In chronnets, a triangle means a recurrent or reinforcement pattern of cycle activation between three nodes. If the events occur at random positions, we have a very low transitivity coefficient in the chronnet. In the case of weighted and directed networks, it can represent strong causal or reinforcement behavior, e.g., a modus operandi, or seasonal fire progression3.
A common pattern in spatiotemporal data sets is the cluster structure1,32. In networks, the analogous structure is called communities, which are groups of densely connected nodes that have few connections between groups (also called partitions)33. The nodes in chronnet that correspond to an active region (multiple events) tend to be connected forming a community. If the region of activity changes to another region, another community emerges. Thus, communities in chronnets represent groups of cells (regions) whose events appear consecutively in an interval.
Spatiotemporal data mining
The chronnet construction method itself is a form of detecting frequent patterns. The method concentrates on a pattern: consecutive events between different locations. This pattern is represented by strong links that indicate repeating consecutive events between different regions. Since we consider different regions, it can also be used for spatiotemporal relationship mining. Strong relationships in terms of consecutive events can be studied by pruning low-weight links or focusing on the strongest links in the chronnet.
In chronnet, cells with long periods of activity are mapped to high degree nodes, and cells with a high number of events are mapped to high strength nodes. These nodes represent cells whose activity is much higher than the other ones and can, therefore, be treated as outliers. The degree and/or strength can be used to detect these outlier nodes that may be removed from the network when convenient.
In data sets with spatiotemporal clusters, the events in a cluster tend to generate strong links between the nodes representing the geometric region where the events occur, resulting in community structures in chronnets. Different community detection methods have been proposed to find a single partition or a hierarchical clustering structure, commonly represented as a dendrogram24,33. Hierarchical community structures are particularly interesting since they permit to define an arbitrary number of communities. Other advantages are the low time complexity and the reduced or absent number of algorithm parameters, making them suitable for large data sets.
After detecting communities, they can be used to find spatiotemporal clusters in the data set. Given a data set X = {e1, e2, …, eT} composed by T events, the clustering for each event is defined as the community where the node that represents this event is inserted. This process results in a temporal sequence of communities C = {c1, c2, …, cT} defining the spatiotemporal clustering for events. Hierarchical community detection algorithms can be used to divide the nodes into an arbitrary number of communities, making possible the spatial division into a distinct number of regions. An advantage of community detection algorithm over traditional clustering algorithms comes from their partition strategy that normally considers macro, mesoscale, and microcharacteristics from the network33,34. This strategy tends to find clusters of different forms and sizes, which might provide better clustering results.
Outliers can be treated by applying a correction function f(C, δ) to each element ct ∈ C where \(\delta \in 2{\mathbb{N}}+1\) is an odd natural number defining a time window size. This function assigns to every element ct the same value in the time window centered in ct iff all the values in the window are the same, i.e., if the number of unique elements in {ct−δ, …, ct−1, ct+1, …, ct+δ} is one.
The community structure can also be used to find temporal changes in spatiotemporal data sets composed by spatial clusters. Temporal changes can be detected by tracking alterations in the communities where the events occur in time. Following the same approach described for the clustering, we consider a data set X = {e1, e2, …, eT} composed of T events and the respective time series of communities C = {c1, c2, …, cT} that represent the node community where each event occurs. The time intervals in the time series C where the events persist in a specific community correspond to a particular region with a considerable high number of events. When the community changes, it represents a time point where the events start to appear in another region, indicating spatial changes. Therefore, a time index t ∈ {2, 3…, T} in the data set X is considered a change point if ct ≠ ct−1.
Experimental settings
To analyze and test our method, we use three kinds of data: an artificial data set generator, dynamical systems, and a real-world data application. The artificial data sets were constructed with specific characteristics to show the potential of the method and the real data set is a case study where we show different known phenomena via the proposed model. The three approaches are described in the following.
We propose a simple spatiotemporal data set generator composed by an square grid Grx×y with x columns and y rows. The probability matrix Px×y, which has the same size of the grid Gr, defines the likelihood Pij of a cell Grij generates an event in a time t ∈ [1, 2, ⋯ , T], where \(T\in {\mathbb{N}}\) is an arbitrary time length. Different data sets can be generated by modifying the three parameters: grid size Grx×y, the probability matrix P, and the time length T. Figure 9 exemplifies the data generation process.

An example of a data set constructed considering a grid Gr10×10, an exponential probability distribution (cells' colors), and a time length T = 20. Each grid represents all the generated events (black dots) until that time.
We also used data extracted from the Lorenz and Rössler equations using well-known combinations of parameters that generate chaotic trajectories in both equations35. The data set was constructed by sampling the values in the trajectories considering a fixed time step.
We use a global fire detection data set constructed with data from the moderate resolution imaging spectroradiometer (MODIS) that runs on-board NASA’s Terra and Aqua satellites36. Specifically, we used the Global Fire Location Product (MCD14ML) Collection 6 from 2003 to 201837. This data set is composed of global active fire detection with geographic location, date, confidence, type, and additional information for each fire detected by MODIS sensors. We consider only those fire records with confidence higher than 75%. We opt for dividing the globe with a hexagonal grid due to its advantages over a traditional rectangular longitude–latitude one38. Hexagonal grids generate cells with a more uniform coverage area and avoid distortions. In our experiments, we used 21,872 hexagonal grid cells of approximated 23,322 km2 each to cover the whole globe. Since many cells cover regions without fire, e.g. the oceans or poles, we discard them resulting in 5467 cells with at least one fire detection in the historical period. The “type” column in the data set defines if the fire detection is a vegetation fire or an outlier generated by active volcanos, offshores, or other static land sources. In our experiments, we used all the types to test whether our method can detect these outlier activities.
Data availability
The artificial datasets generated and analyzed during the current study can be replicated using our source code that is free for download and use. The MODIS data that support the findings of this study are available at http://modis-fire.umd.edu/files/MODIS_C6_Fire_User_Guide_B.pdf.
Code availability
Our source code was implemented in R and is free for download at https://github.com/lnferreira/chronnets with the identifier https://doi.org/10.5281/zenodo.3906599. It includes routines to generate artificial data sets and chronnets, as well as other analysis functions.
References
Atluri, G., Karpatne, A. & Kumar, V. Spatio-temporal data mining: a survey of problems and methods. ACM Comput. Surv. 51, 83:1–83:41 (2018).
Jiang, Z., Shekhar, S., Zhou, X., Knight, J. K. & Corcoran, J. Focal-test-based spatial decision tree learning. IEEE Trans. Knowl. Data Eng. 27, 1547–1559 (2015).
Vega-Oliveros, D. A. et al. From spatio-temporal data to chronological networks: an application to wildfire analysis. In 34th ACM/SIGAPP Symposium on Applied Computing, SAC ’19, Limassol, 675–682 (ACM, New York, 2019).
Boers, N. et al. Complex networks reveal global pattern of extreme-rainfall teleconnections. Nature 566, 373 (2019).
Falasca, F., Bracco, A., Nenes, A. & Fountalis, I. Dimensionality reduction and network inference for climate data using δ-maps: application to the cesm large ensemble sea surface temperature. J. Adv. Model. Earth Syst. 11, 1479–1515 (2019).
Zou, Y., Donner, R. V., Marwan, N., Donges, J. F. & Kurths, J. Complex network approaches to nonlinear time series analysis. Phys. Rep. 787, 1–97 (2019).
Berton, L., de Andrade Lopes, A. & Vega-Oliveros, D. A. A comparison of graph construction methods for semi-supervised learning. In 2018 International Joint Conference on Neural Networks (IJCNN), IJCNN’18, 1–8 (IEEE, 2018).
Zhou, D., Gozolchiani, A., Ashkenazy, Y. & Havlin, S. Teleconnection paths via climate network direct link detection. Phys. Rev. Lett. 115, 268501 (2015).
Donner, R. V., Wiedermann, M. & Donges, J. F. Complex Network Techniques for Climatological Data Analysis, 159–183 (Cambridge University Press, 2017).
Fan, J., Meng, J., Ashkenazy, Y., Havlin, S. & Schellnhuber, H. J. Network analysis reveals strongly localized impacts of El Niño. Proc. Natl Acad. Sci. USA 114, 7543–7548 (2017).
Meng, J., Fan, J., Ashkenazy, Y., Bunde, A. & Havlin, S. Forecasting the magnitude and onset of El Niño based on climate network. N. J. Phys. 20, 043036 (2018).
Farkas, I., Jeong, H., Vicsek, T., Barabási, A.-L. & Oltvai, Z. The topology of the transcription regulatory network in the yeast, Saccharomyces cerevisiae. Physica A 318, 601–612 (2003).
Bialonski, S., Wendler, M. & Lehnertz, K. Unraveling spurious properties of interaction networks with tailored random networks. PLoS ONE 6, e22826 (2011).
Lacasa, L., Luque, B., Ballesteros, F., Luque, J. & Nuño, J. C. From time series to complex networks: the visibility graph. Proc. Natl Acad. Sci. USA 105, 4972–5 (2008).
Abe, S. & Suzuki, N. Scale-free network of earthquakes. Europhys. Lett. 65, 581–586 (2004).
Ferreira, D., Ribeiro, J., Papa, A. & Menezes, R. Towards evidence of long-range correlations in shallow seismic activities. EPL 121, 58003 (2018).
Ohsawa, Y., Benson, N. E. & Yachida, M. Keygraph: automatic indexing by co-occurrence graph based on building construction metaphor. In Proceedings IEEE International Forum on Research and Technology Advances in Digital Libraries-ADL'98, 12–18 (IEEE, 1998).
Vega-Oliveros, D. A., Gomes, P. S., Milios, E. E. & Berton, L. A multi-centrality index for graph-based keyword extraction. Inf. Process. Manag. 56, 102063 (2019).
Ozgur, A. & Bingol, H. Social network of co-occurrence in news articles. Computer and Information Sciences - ISCIS 2004, (eds Aykanat, C. et al.) Kemer, 688–695 (Springer, Heidelberg, 2004).
Wang, R., Liu, W. & Gao, S. Hashtags and information virality in networked social movement: examining hashtag co-occurrence patterns. Online Inf. Rev. 40, 850–866 (2016).
Barabási, A. & Pósfai, M. Network Science (Cambridge University Press, 2016).
Newman, M. Networks: An Introduction. (Oxford University Press, Inc., New York, NY, 2010).
Opsahl, T., Agneessens, F. & Skvoretz, J. Node centrality in weighted networks: generalizing degree and shortest paths. Soc. Netw. 32, 245–251 (2010).
Clauset, A., Newman, M. E. J. & Moore, C. Finding community structure in very large networks. Phys. Rev. E 70, 066111 (2004).
Birant, D. & Kut, A. St-dbscan: an algorithm for clustering spatial–temporal data. Data Knowl. Eng. 60, 208–221 (2007).
Andela, N. et al. The global fire atlas of individual fire size, duration, speed and direction. Earth Syst. Sci. Data 11, 529–552 (2019).
Ferreira, L. N., Vega-Oliveros, D. A., Zhao, L., Cardoso, M. F. & Macau, E. E. Global fire season severity analysis and forecasting. Computers Geosci. 134, 104339 (2020).
Oom, D. & Pereira, J. M. Exploratory spatial data analysis of global MODIS active fire data. Int. J. Appl. Earth Obs. Geoinf. 21, 326–340 (2012).
Watts, D. J. & Strogatz, S. H. Collective dynamics of ’small-world’ networks. Nature 393, 440–442 (1998).
Amaral, L. A. N., Scala, A., Barthélémy, M. & Stanley, H. E. Classes of small-world networks. Proc. Natl Acad. Sci. 97, 11149–11152 (2000).
Han, J., Pei, J. & Kamber, M. Data Mining: Concepts and Techniques (Elsevier, 2011).
Kisilevich, S., Mansmann, F., Nanni, M. & Rinzivillo, S. Spatio-temporal clustering, 855–874 (Springer US, Boston, MA, 2010).
Fortunato, S. Community detection in graphs. Phys. Rep. 486, 75–174 (2010).
Ferreira, L. N. & Zhao, L. Time series clustering via community detection in networks. Inf. Sci. 326, 227–242 (2016).
Strogatz, S. Nonlinear Dynamics and Chaos: With Applications to Physics, Biology, Chemistry, and Engineering (CRC Press, 2018).
Justice, C. et al. An overview of modis land data processing and product status. Remote Sens. Environ. 83, 3–15 (2002).
Giglio, L., Schroeder, W. & Justice, C. O. The collection 6 modis active fire detection algorithm and fire products. Remote Sens. Environ. 178, 31–41 (2016).
Barnes, R. dggridR: Discrete Global Grids for R. https://CRAN.R-project.org/package=dggridR (2017).
Clauset, A., Shalizi, C. & Newman, M. Power-law distributions in empirical data. SIAM Rev. 51, 661–703 (2009).
Raghavan, U. N., Albert, R. & Kumara, S. Near linear time algorithm to detect community structures in large-scale networks. Phys. Rev. E 76, 036106 (2007).
Acknowledgements
This research is supported by the Fundação de Amparo à Pesquisa do Estado de São Paulo (FAPESP) under Grant No. 2015/50122-0 and the German Research Council (DFG-GRTK) Grant No. 1740/2. L.N.F. acknowledges FAPESP Grant No. 2019/00157-3 and 2017/05831-9. D.A.V.-O. acknowledges FAPESP Grants 2016/23698-1, 2018/24260-5, and 2019/26283-5. M.G.Q. acknowledges FAPESP Grant 2016/16291-2 and CNPq Grant 313426/2018-0. L.Z. acknowledges the Pro-Rectory of Research (PRP) of University of Sao Paulo Grant 2018.1.1702.59.8 and CNPq Grant 303199/2019-9. M.F.C. acknowledges CNPq Grant 314016/2009-0. This research was developed using computational resources from the Center for Mathematical Sciences Applied to Industry (CeMEAI) funded by FAPESP (grant 2013/07375-0).
Author information
Authors and Affiliations
Contributions
L.N.F, D.A.V.O., M.C., M.F.C., and M.G.Q. developed the chronnet model. L.N.F. proposed the data set generator, conceived, and conducted the experiments. L.N.F. and D.A.V.O. analyzed the results and wrote the paper. L.Z. and E.E.N.M. contributed with ideas to improve the work. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Peer review information Nature Communications thanks Juergen Kurths and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ferreira, L.N., Vega-Oliveros, D.A., Cotacallapa, M. et al. Spatiotemporal data analysis with chronological networks. Nat Commun 11, 4036 (2020). https://doi.org/10.1038/s41467-020-17634-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-020-17634-2
This article is cited by
-
The small-world network of global protests
Scientific Reports (2021)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
