
Abstract
Human height is a representative phenotype to elucidate genetic architecture. However, the majority of large studies have been performed in European population. To investigate the rare and low-frequency variants associated with height, we construct a reference panel (N = 3,541) for genotype imputation by integrating the whole-genome sequence data from 1,037 Japanese with that of the 1000 Genomes Project, and perform a genome-wide association study in 191,787 Japanese. We report 573 height-associated variants, including 22 rare and 42 low-frequency variants. These 64 variants explain 1.7% of the phenotypic variance. Furthermore, a gene-based analysis identifies two genes with multiple height-increasing rare and low-frequency nonsynonymous variants (SLC27A3 and CYP26B1; PSKAT-O < 2.5 × 10−6). Our analysis shows a general tendency of the effect sizes of rare variants towards increasing height, which is contrary to findings among Europeans, suggesting that height-associated rare variants are under different selection pressure in Japanese and European populations.
Similar content being viewed by others

Introduction
Human height is a highly heritable trait under polygenic inheritance1. Over the past decade, genome-wide association studies (GWAS) have identified more than 3500 variants associated with human height2,3,4,5,6,7,8. Furthermore, recent studies using high-density genotype imputation based on the whole-genome sequencing data4,5,6 and commercial genotyping array focused on coding variants7 and uncovered dozens of rare and low-frequency variants with greater impacts on human height. Meanwhile, investigations in non-European populations have been performed with relatively smaller sample sizes3. Therefore, there were limited variants reportedly associated with height in non-European population, such as East Asians. Considering that diverse populations harbor ancestral-specific rare variants9, searching for such genetic variations in East Asian population with large samples would expand our knowledge on genetic components associated with complex traits.
Here we report a large-scale association study (N > 190,000) of human height in a Japanese population using a newly constructed reference panel for genotype imputation, including deep whole-genome sequence (WGS) data of 1037 Japanese10. Our primary aim of this study is to identify rare (minor allele frequency (MAF) <1%) and low-frequency (1% ≤ MAF < 5%) variants associated with height in the Japanese population. To characterize the roles of the identified variants, we further evaluate the gene-level associations and pleiotropic effects of the identified genes and variants, and investigate the natural selection on height-associated rare variants. Through the study, we identify 573 variants associated with height in the Japanese population. Of these, 22 are rare and 42 are low-frequency variants. We also reveal two height-associated genes that have not been reported. Moreover, our analysis of selection on height-associated variants suggests different selection pressure between Japanese and European populations.
Results
Reference panel for genotype imputation
The study design is illustrated in Supplementary Fig. 1. To achieve a better imputation accuracy for rare and low-frequency variants, we constructed a reference panel (N = 3541) composed of deep WGS data obtained from 1037 Japanese individuals10 (BBJ1K; Supplementary Note 1) and the 1000 Genomes Project9 (1KG; phase3v5, N = 2504). We compared the imputation accuracy with that of other reference panels and found that the integrated panel exhibited the best imputation accuracy, especially for rare and low-frequency variants (Fig. 1 and Supplementary Fig. 2).

Plot of imputation qualities by different reference panels. The accuracy of imputation was evaluated for four different reference panels at “masked” HumanExome SNPs. BBJ1K + 1KGp3v5 panel (red) showed the best performance at every allele frequency bins. Even the BBJ1K panel showed much better accuracy than the 1KGp3v5 ALL panel regardless of the difference in sample size, indicating the contribution of deep haplotype information of the specific population to imputation accuracy. Median r2 values are shown on the y-axis
Genome-wide association study
After the application of stringent quality control (QC) and whole-genome imputation to the new reference panel, we conducted a GWAS in 159,195 participants of the Biobank Japan (BBJ) project11,12 using 27,896,057 imputed variants (Supplementary Fig. 3a and Supplementary Table 1). As expected, we observed high genomic inflation (λGC = 1.20 for all variants and 1.69 for variants with MAF ≥1%; Supplementary Fig. 3b). Since we used a linear mixed model13 to test association, we interpreted this inflation as being due to polygenic effects. We quantified the bias resulting from population stratification and cryptic relatedness using linkage disquilibrium (LD) score regression14. The mean χ2 value was 2.63, intercept was 1.21 ± 0.02 (mean ± standard error [s.e.]) and ratio was 0.13. This proportion was comparable with those in our previous GWASs for quantitative traits in the BBJ15,16.
We defined genetic loci by considering the positional relationships of the variants reached genome-wide significance (PGWAS <5.0 × 10−8; Supplementary Fig. 4a). If the significantly associated variants at two different loci were more than 1 Mb apart from each other, we regarded these loci as independent. As a result, we observed 363 independent loci, including nine novel loci with genome-wide significance (Supplementary Data 1, 2 and Supplementary Table 2).
Next, to investigate independently associated signals underlying the identified 363 loci, we performed several rounds of conditional analyses by repeating the association analysis using BOLT-LMM until the association of the top variants fell below the significance threshold. This analysis revealed an additional 246 independently associated variants satisfying the genome-wide significance within 130 loci (Supplementary Data 2, 3 and Supplementary Fig. 5). In total, 609 lead variants reached a genome-wide significant level in the GWAS. We identified a high number of independently associated signals near ACAN (Nsignal = 7), ADAMTS17 (Nsignal = 11), and IGFBP5-IHH-RESP18 (Nsignal = 10), which were also observed in a study conducted in a European population2. When we examined the frequencies of the identified variants in the 1KG (Supplementary Data 4 and Supplementary Fig. 6), 40 were found to be monomorphic in all non-East Asian populations, suggesting that these variants are East Asian specific.
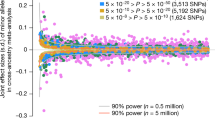
We evaluated 609 identified variants in 32,692 independent individuals as a replication study (Supplementary Note 2, Supplementary Table 1, and Supplementary Data 5). Among these variants, 415 (68.1%) were nominally associated (Prep < 0.05) in the same direction of effects, and 598 variants (98.2%) showed directional consistency (P for sign test = 9.38 × 10−161), suggesting that the majority of the identified variants were not false positives. We also observed a strong correlation of the effect sizes between the GWAS and replication (Pearson’s r = 0.88, P = 3.47 × 10−194, Supplementary Fig. 7). After a fixed-effect meta-analysis, 573 variants (95.5%) remained genome-wide significant (Supplementary Data 5) and we determined that these were significantly associated throughout the present study. Of these variants, 124 (21.6%) were replicated with Bonferroni-corrected level of associations (α = 8.21 × 10−5 [=0.05/609]) and 289 (50.4%) were replicated with nominal significance (8.21 × 10−5 < Prep < 0.05). We did not observe Bonferroni-corrected level of heterogeneity of effect sizes between GWAS and the replication study (Phet > 8.21 × 10−5). Among the 573 variants, 22 were rare and 42 were low-frequency variants. The effect sizes of the rare and low-frequency variants showed stronger effects than those of common variants (Fig. 2). The rare and low-frequency variants that remained genome-wide significant after the meta-analysis (N = 64) together explained 1.7% of the phenotypic variance in the replication set (Tables 1 and 2), which was comparable to findings in the European population (1.7% by 83 variants)7.

Scatter plot of MAF and effect size. We plotted the allele frequency (x-axis) and effect size (y-axis) of the minor alleles of the 609 variants that reached genome-wide significance in the discovery GWAS. Variants that remained genome-wide significant after the meta-analysis are indicated in blue. The orange line denotes 80% power to achieve genome-wide significance. To convert the standardized effect size to a centimeter scale, we regarded 1 standard error as 5.63 cm, which was calculated in the population-based cohorts (replication set)
We searched for 83 coding variants with low MAFs identified in the largest GWAS conducted to date (GIANT consortium7) and identified 30 variants evaluated in our GWAS (25 were rare or low-frequency variants in the Japanese population). Among them variants, eight were nominally associated (PGWAS <0.05; Supplementary Table 3). We also looked up other height-associated variants in the European population4,5,6 (Supplementary Table 4). Notably, we replicated the association of rs143840904 in the KCNQ1 region (PGWAS = 6.4 × 10−19, MAF = 1.6%; Supplementary Fig. 8) that was originally reported by Sardinians4. In that previous study, either rs143840904 or rs150199504 was implicated in height based on considering the LD pattern and their allele frequencies in the South Asian population. However, rs150199504 is monomorphic in the BBJ1K and EAS samples of 1KG9, and we therefore suspected that rs143840904 was the causal variant of this locus. We also looked up at the associations of variants reported by the meta-analysis of GIANT consortium and UK Biobank (UKB)8. By considering that the reported lead variants were selected by GCTA-COJO17, we considered 2481 out of 3290 variants showing genome-wide significant associations in the non-conditioned analysis. Of these variants, 1417 variants were evaluated in our GWAS (Supplementary Data 6), and 772 variants were nominally associated (PGWAS < 0.05) with the consistent direction of effects. These 772 variants represented a significant positive correlation in the effect sizes between our GWAS and the meta-analysis of GIANT and UKB (Pearson’s r = 0.82, P = 7.00 × 10−189), suggesting that these are shared height-associated variants across populations.
Functional annotations and pleiotropic effects
We annotated the variants that were in LD (r2 > 0.8) with the 573 identified variants and found 117 nonsynonymous variants in 98 genes (Supplementary Data 7). Of these genes, 13 have been reported as genes responsible for height-related anomalies in humans (Supplementary Table 5). Among the nonsynonymous variants, 113 were missense variants, 1 was a non-frameshift deletion, and 3 were putative loss-of-function variants, including a low-frequency stop-gain variant (SCIN R56X) that is extremely rare in other populations. SCIN has been reported to mediate osteoclastogenesis and is involved in developmental dysplasia of the hip18.
To characterize rare and low-frequency variants associated with height, we investigated the pleiotropic effects of the identified rare and low-frequency variants across 17 traits by conducting association analysis in the individuals analyzed in GWAS using clinical information obtained from the BBJ (Supplementary Table 6). This analysis revealed three significant pleiotropic associations of two variants (α = 4.60 × 10−5 (=0.05/(17 × 64)); Supplementary Fig. 9). One was a very rare missense variant in JAK2 (p.E890K; MAF = 0.08%), which is the causative gene of polycythemia vera (MIM: 263300) and thrombocythemia-3 (MIM: 614521) and is activated by the binding of a growth hormone to a growth hormone receptor. Its height-decreasing allele was associated with lower levels of both red blood cells (P for linear regression = 7.90 × 10−8, β = −0.39, s.e. = 0.07) and hemoglobin (P for linear regression = 9.80 × 10−6, β = −0.32, s.e. = 0.07). The other was a rare missense variant in IHH (p.G408R; MAF = 0.30%), which is the known causative gene of acrocapitofemoral dysplasia (MIM: 607778) and brachydactyly type A1 (MIM: 112500). The p.G408R height-decreasing allele also decreased white blood cell levels (P for linear regression = 1.02 × 10−6, β = −0.07, s.e. = 0.01).
Gene-based analysis
To pinpoint the genes influencing height, we evaluated gene-level associations with SKAT-O19 in samples analyzed through GWAS and identified 52 genes that were significantly associated with height (PSKAT-O < 2.5 × 10−6; Fig. 3a and Supplementary Data 8). Although most of the observed gene-level associations seemed to represent the single best-associated nonsynonymous variants in each gene, we found stronger associations by grouping other nonsynonymous variants in the two genes SLC27A3 (PSKAT-O = 6.94 × 10−38) and CYP26B1 (PSKAT-O = 1.33 × 10−45) (Table 3 and Fig. 3b), indicating multiple associated low-frequency variants (Fig. 3c, d). All of the minor alleles of the variants showing a nominal association (PGWAS < 0.05) exerted height-increasing effects in both genes (Supplementary Data 9, 10). The replication sets confirmed the associations (Table 3). To further investigate whether the identified gene-level associations of two genes resulted from the associations of multiple associated variants, we performed a conditional analysis. We observed significant gene-level associations remained after conditioned on the best-associated single nonsynonymous variant (PSKAT-O = 3.38 × 10−25, and 2.41 × 10−21 for SLC27A3 and CYP26B1, respectively; Supplementary Table 7). The missense variant in CYP26B1 (p.L264S) was found to show a subgenome-wide significant association in an African population in the recent analysis by the GIANT consortium (P = 1.13 × 10−7)7. We confirmed that this variant showed an association in both our GWAS (PGWAS = 2.5 × 10−7, MAF = 9.2%) and the replication set (Prep = 4.8 × 10−3, MAF = 9.4%) (Supplementary Data 10). Although we did not include CYP26B1 p.L264S in the gene-based analysis, due to its higher MAF, this observation also supported the conclusion that multiple nonsynonymous variants of CYP26B1 are associated with human height.

Summary of gene-based analysis. a Manhattan plot of the gene-based test. The yellow line represents significance threshold (P < 2.5 × 10−6). b Comparison of single-variant test P values and those of the gene-based test. Two genes (SLC27A3 and CYP26B1) showed much stronger associations in the gene-based test. c, d Positions and associations of nonsynonymous variants in SLC27A3 and CYP26B1. The colors of the plots denote the impact of the variants. The symbols (circle, diamond, and square) indicate the function of variants. The coding regions are colored according to their structural domains based on Pfam
Disruption of CYP26B1 gene has been reported to cause fusion or overgrowth of cartilaginous structures in mice and zebrafish and leads to craniosynostosis and multiple skeletal anomalies in humans20; however, the impact of SLC27A3 on human phenotypes has not been well characterized. Therefore, we evaluated their pleiotropic effects on 17 human traits and found that SLC27A3 showed significant associations with lipid-related traits (PSKAT-O = 4.30 × 10−4 and 8.20 × 10−5, for total cholesterol and triglyceride, respectively), and CYP26B1 influenced the body-mass index (PSKAT-O = 2.03 × 10−4) (Supplementary Fig. 10). Considering that SLC27A3 is the fatty acid transporter (FATP) gene, it is likely that further functional investigation of SLC27A3 will reveal the biological link of FATP genes with the regulation of height.
Pathway analysis
To gain further biological insight, we performed a gene set enrichment analysis using PASCAL21 with reconstituted gene sets, which was implemented in DEPICT22. We observed significant enrichment in 221 gene sets (false discovery rate (FDR) q < 0.05; Supplementary Data 11). Of these 221 significant gene sets, 37 gene sets were not reported in the previous study of GIANT consortium7. Since these gene sets were correlated with each other, we clustered the identified gene sets into 16 categories using the affinity propagation (AP) clustering method23 and determined the exemplars in each category. Although gene sets represented by regulatory region DNA binding (GO: 00010607) have not been previously reported, the other 15 categories contained one or more gene sets previously reported by the GIANT consortium7, and the overall observations should support the notion that the biological mechanisms regulating human height are shared across different populations.
Variance explained by the analyzed variants
Next, we estimated the phenotypic variance explained by the variants analyzed in the replication sets (N = 25,419) using the MAF-stratified genomic-relatedness-based restricted maximum likelihood (GREML-MS) method24 with GCTA25, which enabled us to evaluate the explained variance of the sets of variants stratified by MAF. When we investigated all imputed autosomal variants, it was estimated that 52.4 ± 4.5% of the total phenotypic variance could be explained. Variants with a MAF <10% explained 20.3 ± 4.6% of the variance. We further split the low-frequency range at a MAF of 5% and found that variants with a MAF <5% explained the largest proportion of the phenotypic variance in human height (14.1 ± 4.7%; Supplementary Fig. 11). Considering that the identified rare and low-frequency variants explained only 1.7% of the phenotypic variance in our samples, further investigations of rare and low-frequency variants are warranted to elucidate the genetic architecture of human height.
Analysis of natural selection
Recent studies have indicated that the variants associated with human height are under natural selection4,24,26; however, such evidence has been limited to the European population. By examining the relationships between allele frequencies and effect sizes through GWAS, we investigated the effect of selection on height-associated variants in the Japanese population (Fig. 4). We observed that the rarer variants tend to have height raising effects (Spearman’s ρ = −0.63, P < 1.0 × 10−6), implicating negative selection on height-increasing alleles. This relationship showed a clear contrast to findings in Europeans (in whom rarer variants entirely showed height-decreasing tendency after grouped by their MAF)24. The independent replication set confirmed this finding (Spearman’s ρ = −0.69, P < 1.0 × 10−6, Supplementary Fig. 12). This dissimilarity implies differences in selection pressure on height-associated variants in the Japanese and European populations.

Relationship between the minor allele effect for height and MAF in the GWAS. A scatter plot of the mean minor allele effect according to each MAF bin (N = 100) is shown. The mean effects of the minor alleles were clearly greater in rarer variants
Finally, we assessed the possible artifacts in the analysis of relationship between minor allelic effects (MAEs) and MAFs. First, we considered the bias resulting from genotype imputation. We evaluated this tendency using the directly genotyped variants, and observed the consistent relationship between MAEs and MAFs (Supplementary Fig. 13; Spearman’s ρ = −0.39, P = 7.38 × 10−6), suggesting that the observed height-increasing tendency in rarer variants did not result from the bias emerged from imputation. We also considered the impact of convergence in the BOLT-LMM on this analysis. We therefore restricted the variants with standard errors of estimates ≤0.2 and 0.5, and re-evaluated the relationship between MAFs and MAEs. We observed similar relationship (Supplementary Fig. 14; Spearman’s ρ = 0.61 and 0.69 for variants with SE < 0.2 and 0.5, respectively). Based on these results, we interpreted that the impact of convergence on our result is minimal. Next, in order to assess the possible contribution of population stratification, we selected the samples belonging to the Japanese main cluster and performed GWAS (Supplementary Fig. 15a; N = 148,937). When we evaluated the correlation between MAFs and MAEs, we still observed significant correlation (Supplementary Fig. 15b; Spearman’s ρ = −0.35, P = 3.35 × 10−4).
Discussion
Through a large-scale genome-wide analysis in a single non-European population, we identified 64 rare and low-frequency variants and two genes associated with human height. The discovery of the rare and low-frequency height-associated variants was led by the integrated reference panel for genotype imputation, which was constructed with population-specific whole-genome sequencing data10. Considering that dozens of the identified genetic variants appeared to be specific to East Asians, investigations of rare and low-frequency variants in non-European populations will contribute to expand the catalog of genes and genetic variations associated with complex traits. Our findings should encourage further investigations of diverse populations in complex trait genetics.
Our results suggested similarities of genetic architecture of human height between Europeans and East Asians. First, we showed the correlation of effect sizes of height-associated variants between East Asians and Europeans, implying that a certain proportion of height-associated variants are shared across populations. Second, the pathway analysis implicated that the large proportion of the identified gene sets were shared between ours and those found in Europeans. This observation supports the shared biological mechanisms and genetic contributions on human height. Third, the estimated heritability stratified by MAF was comparable between ours and the previous study of Europeans. These observations will help to deepen our knowledge on genetic architecture of human height. On the other hand, we showed some advantages of investigating non-European population, such as identification of dozens of the East Asian-specific height-associated variants, the likely causal variant at KCNQ1 region, and two novel gene-level associations, which were not reported in the previous study. Moreover, by utilizing the phenotypic resources of the Biobank in Japanese population, we evaluated the pleiotropy of the identified rare and low-frequency variants and genes, and found three pleiotropic effects of two rare variants and three gene-level pleiotropic associations in two newly identified genes with multiple rare and low-frequency height-associated variants. These findings contribute to characterize the rare and low-frequency variants associated with height in the Japanese population.
We investigated the negative selection on height-associated variants, and found the relationship that rarer variants showed height-increasing tendency. We note that this tendency appeared for the grouped variants with mean MAF of at most 0.1%. Among the lead variants significantly associated in the present study, only one variant (rs202237966) was MAF <0.1%, suggesting that investigation of the negative selection using significantly associated variants requires much larger sample size. Considering that investigation of rare variants in a Japanese population suggested difference in negative selection on human height, further multi-ethnic comparisons of rare genetic components may expand our knowledge on the selection pressures underlying complex traits. On the other hand, the correlation in the Japanese main cluster was weakened, suggesting the possible bias from population stratification. Future study using novel statistical method, which is not influenced by population stratification, will be needed to confirm our finding.
In conclusion, we performed a large-scale genetic association study in the Japanese population, and identified 573 variants including 22 rare and 42 low-frequency variants associated with height in the Japanese population. Our results provide insights into the similarities and differences underlying genetic architecture of human height, and underscore the utility of investigating diverse populations to deepen our understanding of the genetic architecture of human complex traits.
Methods
Subjects
Clinical information, including height, and the genome-wide variant data of the samples included in the GWAS were obtained from the BBJ project11,12, which enrolled 200,000 participants. We set the eligibility criteria for the GWAS samples as follows: (1) age ≥ 18, (2) available height information, and (3) height within three times the interquartile range of the upper/lower quartile. We calculated Z-scores from the residuals of linear regression against height using age, age2, and sex, and excluded individuals who fell outside ±4 standard deviations. We used genotyping array results to further exclude samples with lower call rates (<98%), closely related individuals using PLINK27 (PI_HAT > 0.175). We determined outliers from the Japanese cluster by visual inspection based on the principal component analysis (PCA) using GCTA software25 (ver1.25) with the samples of HapMap project28 (Supplementary Fig. 16). Finally, 159,095 individuals were included in the GWAS. There was no overlap between samples included in the GWAS and BBJ1K.
The samples used in the replication study were collected from four Japanese population-based studies (Iwate Tohoku Megabank Organization (IMM), Japan Multi-Institutional Collaborative Cohort Study (JMICC), Japan Public Health Center-based Prospective Study (JPHC), and Tohoku University Tohoku Medical Megabank Organization (ToMMo)). We applied the same inclusion and exclusion criteria to the clinical information of the participants. To increase statistical power, we excluded overlapping samples (estimated by PI_HAT) and PCA outliers from the East Asian population and finally included 32,692 individuals in the replication study.
In all participating studies, informed consent was obtained from all participants by following the protocols approved by the corresponding institutional ethical committees before enrollment. The clinical characteristics of each cohort are provided in the Supplementary Table 1. This study was approved by the ethics committee of RIKEN and the Institute of Medical Science, the University of Tokyo.
Imputation reference panel construction
To achieve better imputation accuracy, we constructed a reference panel using WGS data obtained from the BBJ10. Briefly, we sequenced 1037 samples using 2 × 160-bp paired-end reads on the HiSeq2500 platform, aimed at a 30× depth, and processed these data according to the standardized best-practice method proposed by GATK (ver.3.2-2). For QC, we additionally set exclusion filters for genotypes as follows: (1) DP <5, (2) GQ <20, or (3) DP >60 and GQ <95. We set these genotypes as missing and excluded variants with call rates <90% before variant quality score recalibration (VQSR). After performing VQSR implemented by GATK, variants located in low-complexity regions (LCR), as defined by mdust software (“hs37d5-LCRs.20140224.bed,” downloaded from ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/release/20130502/supporting/low_complexity_regions/hs37d5-LCRs.20140224.bed.gz), were excluded. Finally, we used BEAGLE to impute missing genotypes.
To combine the 1KG phase3v5 (n = 2504) and BBJ1K data using IMPUTE229,30, we excluded variants located at multi-allelic sites and estimated haplotypes using SHAPEIT. After combining the two datasets, we excluded singletons and variants at multi-allelic sites from the reference panel using bcftools (ver. 1.3.1) and vcftools (ver. 0.1.14). Since the current version of IMPUTE2 is not applicable to haploid chromosomes, we used BEAGLE to impute WGS data for X chromosomes in males and excluded singletons and variants located at multi-allelic sites before merging with a female dataset.
To evaluate the imputation accuracy of different reference panels, we performed whole-chromosome 1 imputation in GWAS samples after excluding variants that were included on the Illumina HumanExome BeadChip. For the imputation reference panels, we used the genotype data from the following samples: (1) 1KG phase1v3 EAS samples, (2) 1KG phase3v5 ALL samples, (3) BBJ1K samples, and (4) the combined 1KG phase3v5 ALL and BBJ1K samples. We carried out pre-phasing and imputation using Eagle (v2)31 and minimac332, respectively. The accuracy of the imputation was evaluated by Pearson’s r2 between the GWAS array genotypes and the imputed allelic dosages.
Genotyping and imputation
Samples included in the GWAS were genotyped using either of the following genotyping arrays: (1) the Illumina HumanOmniExpressExome BeadChip or (2) a combination of the Illumina HumanOmniExpress and HumanExome BeadChips. For QC of genotypes, we excluded variants meeting any of the following criteria: (1) call rate <99%, (2) P value for Hardy–Weinberg equilibrium <1.0 × 10−6, and (3) number of heterozygotes <5. After we proceeded through these QC steps using all genotyped samples in the BBJ set, 939 samples from BBJ1K were included. We further compared the genotypes of the overlapping variants between the GWAS array and WGS and excluded variants with a concordance rate <99.5% or a non-reference discordance rate ≥0.5%. In the GWAS, we used Eagle31 for haplotype phasing without an external reference panel and Minimac332 for imputation, respectively. For the purpose of QC, we used variants with an Rsq ≥0.3 in the association analysis.
In the replication set, all participants were genotyped with the Illumina HumanOmniExpressExome BeadChip. We excluded variants meeting any of the following criteria: (1) call rate <98%, (2) P value for Hardy–Weinberg equilibrium <1.0 × 10−6, and (3) a minor allele count of <5. Thereafter, we compared the allele frequency between the genotyped samples and BBJ1K and excluded variants showing a >5% difference in allele frequency. Pre-phasing was carried out using SHAPEITv233. We imputed variants with Minimac3 using the same reference panel as in the GWAS. We considered variants with an Rsq ≥0.3 in the association analysis.
Pre-phasing and imputation of the X chromosome were performed using the same software applied for autosomes. In each dataset, we phased the haplotypes for males and females together and then imputed them separately in each sex.
Phenotype and association analysis
For the single-variant association analysis, we obtained the residuals from a linear regression model of height adjusted for age, age2, and sex. The residuals were then converted into Z-scores. Association analysis of autosomes was performed using BOLT-LMM (ver.2.2), which implements linear mixed model analysis under the Gaussian mixture model13. Since this approach is not applicable to the X chromosome, we recalculated the residuals of the linear regression analysis by adding the top 10 principal components (PCs) of the genotypes as covariates and converted them into Z-scores. Association analysis of the X chromosome was carried out with mach2qtl32 in the GWAS and with EPACTS (ver. 3.2.6) in the replication study. Since we did not remove related samples from the replication set, we additionally excluded samples based on a PI_HAT >0.175 and included 30,303 samples in the X-chromosomal analysis.
In the conditional analysis performed in the GWAS, we used BOLT-LMM for autosomes and mac2qtl for the X chromosome. We set the same significance threshold employed for the GWAS (α = 5.0 × 10−8) in the conditional analysis and repeated the analysis until the association of the top variants fell below the significance threshold. To replicate the associations of variants identified through conditional analysis, we used the same set of conditioned variants employed in the GWAS as covariates in the replication set.
We integrated the results of the GWAS and the replication set using the inverse-variance method and estimated heterogeneity with Cochran’s Q test. The variants that satisfied genome-wide significance (P < 5.0 × 10−8) after the meta-analysis were considered to be significantly associated throughout the study.
For the evaluation of gene-level associations, we conducted a group-wise association analysis of coding regions in autosomal genes. For phenotype preparation, we obtained the residuals of the linear regression of height with age, age2, sex, and the top 10 PCs as covariates and standardized them as Z-scores. We annotated the variants as described below and extracted nonsynonymous variants, including missense and nonsense variants, non-frameshift insertions and deletions, and frameshift variants with a MAF <5% and imputation quality of Rsq ≥0.3. A group-wise association test was performed using the imputed allelic dosage employing SKAT-O19 implemented in EPACTS. As in the X-chromosome analysis, we excluded closely related samples from the replication set. We set a conservative significance threshold for the gene-level association analysis using Bonferroni correction based on the assumption that 20,000 genes could be evaluated (α = 0.05/20,000 genes). To evaluate whether the identified gene-level associations resulted from multiple nonsynonymous variants, we performed conditional analyses by adjusting for the best-associated variant of each gene included in the group-wise association analysis.
LD score regression
To assess bias resulted from population stratification and cryptic relatedness, we conducted a single variate LD score regression14 analysis using LDSC v.1.0.0. We used the LD score file for East Asian population provided with the software.
Annotation
We annotated variants using ANNOVAR34 (version: 2017-07-17). PLINK27 was employed to estimate LD with the lead variant of each identified locus in the BBJ1K samples. Protein domain information for SLC27A3 and CYP26B1 from Pfam35 was obtained via the Ensembl genome browser.
Pleiotropy
To investigate the pleiotropic effects of the 64 identified variants with a MAF <5%, we evaluated the associations of 17 different phenotypes using the clinical information of the samples analyzed in the GWAS. We targeted the nine quantitative traits among hematological, kidney-related and liver-related traits and two diseases by considering the results of our genetic correlation analysis across 89 complex traits16. We additionally selected four lipid-related traits, hemoglobin A1c, and type 2 diabetes because height-associated rare and low-frequency variants showed significant associations with these traits in a previous study7. For quantitative traits, we used standardized phenotypes (detailed in Supplementary Table 6) and performed linear regression analysis. For the case–control analysis, we applied a logistic regression analysis adjusted for age, sex, and the top 10 PCs as covariates.
We also tested the pleiotropy of the identified genes (SLC27A3 and CYP26B1) for the same 17 traits. Gene-level associations were estimated with SKAT-O19 using EPACTS (ver. 3.2.6), with the same settings applied for height. We set the significance threshold using Bonferroni correction at α = 0.05/17/64 for single-variant analysis and α = 0.05/17/2 for the gene-based test.
Pathway analysis
We conducted a gene set enrichment analysis using PASCAL software21. To fit into the Japanese LD structure, we used a custom reference panel generated from the BBJ1K set. We used 14,462 gene sets reconstituted with DEPICT software22 (Z-score >3; software downloaded from https://data.broadinstitute.org/mpg/depict/depict_download/reconstituted_genesets/).
The default settings were employed for the analysis. After determining significant gene sets by evaluating the FDR using the Benjamini–Hochberg method (threshold: FDR <0.05) for the P value estimated via the χ2 pathway scoring method, we applied an AP clustering method23 to merge the identified gene sets into functionally relevant categories and defined exemplars in each category. We used the Z-scores for all genes to perform this clustering.
GREML analysis
We employed Japanese population-based cohorts (replication set) to estimate the variance explained by the imputed variants. Following a previous report24, we used hard call genotypes (xdose) estimated based on the imputed allelic dosage (xg), without excluding variants with a lower imputation quality. Here, we converted xg = 0 for xdose < 0.5; xg = 2 for xdose > 1.5; and xg = 1 for 0.5 ≤ xdose ≤ 1.5; and we excluded variants with a minor allele count <3 and a P for Hardy–Weinberg <1.0 × 10−6. To estimate the variance explained by the variants contained in our reference panel, the GREML-MS24 approach was applied using GCTA software25 (ver. 1.25). We first generated a genetic relationship matrix (GRM) using all of the variants and estimated genetic relatedness and restricted samples with relatedness <0.05 using the “–grm-cutof’” option. As a result, 25,419 samples were included in the analysis. Trait values were re-standardized in these samples. Subsequently, we generated seven GRMs stratified by MAF as follows: (1) MAF <5%, (2) 5% ≤ MAF < 10%, (3) MAF <10%, (4) 10% ≤ MAF < 20%, (5) 20% ≤ MAF < 30%, (6) 30% ≤ MAF < 40%, and (7) 40% ≤ MAF. We estimated phenotypic variance according to each MAF strata using the “–reml” option with the top 10 PCs to control population stratification.
Mean allelic effect stratified by MAF
We evaluated the relationship between the MAF and the minor allele effect in our samples by utilizing the variants analyzed in the GWAS (Rsq ≥0.3). After excluding the variants that did not converge, we divided the autosomal variants into 100 bins according to their MAF. The number of the variants in each bin was determined as follows. First, we divided the number of all the analyzed variants by 100. The number of variants assigned in bins 1–99 was the integer quotient of the number of all the variants +1, and the remained variants were grouped into the bin 100. Then, we estimated Spearman’s rank correlation coefficient (ρ) between the MAF and the minor allele effect in each bin. The statistical significance of a correlation coefficient value was determined via one million resamplings. In each resampling procedure, we randomly selected the same number of variants and estimated the empirical distribution of ρ values, as proposed previously24. For the purpose of replication, we analyzed samples in the replication set in the same way.
URLs
For BBJ, see https://biobankjp.org/english/index.html; for IMM, see http://iwate-megabank.org/en/; for JMICC, see http://www.jmicc.com/en/; for JPHC, see http://epi.ncc.go.jp/en/jphc/index.html; for ToMMo, see http://www.megabank.tohoku.ac.jp/english/; for PLINK, see https://www.cog-genomics.org/plink2; for BOLT-LMM, see https://data.broadinstitute.org/alkesgroup/BOLT-LMM/downloads/; for MACH, see http://csg.sph.umich.edu//abecasis/MaCH/; for ANNOVAR, see http://annovar.openbioinformatics.org/en/latest/; for SHAPEIT, see https://mathgen.stats.ox.ac.uk/genetics_software/shapeit/shapeit.html; for Eagle, see https://data.broadinstitute.org/alkesgroup/Eagle/; for R, see https://www.r-project.org/; for GIANT consortium, see https://www.broadinstitute.org/collaboration/giant/index.php/GIANT_consortium; for Locuszoom, see http://locuszoom.sph.umich.edu/locuszoom/; for 1000 genome project, see http://www.1000genomes.org/; for GCTA, see http://cnsgenomics.com/software/gcta/; for PASCAL, see https://www2.unil.ch/cbg/index.php?title = Pascal; for EPACTS, see https://genome.sph.umich.edu/wiki/EPACTS; for IMPUTE2, see https://mathgen.stats.ox.ac.uk/impute/impute_v2.html; for GATK, see https://software.broadinstitute.org/gatk/; for Beagle, see https://faculty.washington.edu/browning/beagle/beagle.html
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Data availability
The summary statistics for the GWAS are available from the National Bioscience Database Center (NBDC) Human Database (https://humandbs.biosciencedbc.jp/en/) with the dataset ID (hum0014 [https://humandbs.biosciencedbc.jp/en/hum0014-v15]) and from JENGER (http://jenger.riken.jp/en/). The genotype data employed in the GWAS are available from the Japanese Genotype-phenotype Archive (JGA; http://trace.ddbj.nig.ac.jp/jga/index_e.html) with accession codes JGAS00000000114 for the study and JGAD00000000123 for the genotype data. The constructed reference panel for genotype imputation is also accessible through JGA upon request (accession code: JGAD00000000220). Height information can be provided by the BBJ project upon a request (please see, https://biobankjp.org/english/index.html).
Change history
09 March 2020
An amendment to this paper has been published and can be accessed via a link at the top of the paper.
References
Visscher, P. M., Brown, M. A., McCarthy, M. I. & Yang, J. Five years of GWAS discovery. Am. J. Hum. Genet. 90, 7–24 (2012).
Wood, A. R. et al. Defining the role of common variation in the genomic and biological architecture of adult human height. Nat. Genet. 46, 1173–1186 (2014).
He, M. et al. Meta-analysis of genome-wide association studies of adult height in East Asians identifies 17 novel loci. Hum. Mol. Genet. 24, 1791–1800 (2015).
Zoledziewska, M. et al. Height-reducing variants and selection for short stature in Sardinia. Nat. Genet. 47, 1352–1356 (2015).
Benonisdottir, S. et al. Epigenetic and genetic components of height regulation. Nat. Commun. 7, 13490 (2016).
Tachmazidou, I. et al. Whole-genome sequencing coupled to imputation discovers genetic signals for anthropometric traits. Am. J. Hum. Genet. 100, 865–884 (2017).
Marouli, E. et al. Rare and low-frequency coding variants alter human adult height. Nature 542, 186–190 (2017).
Yengo, L. et al. Meta-analysis of genome-wide association studies for height and body mass index in ∼700000 individuals of European ancestry. Hum. Mol. Genet. 27, 3641–3649 (2018).
1000 Genomes Project Consortium. A global reference for human genetic variation. Nature 526, 68–74 (2015).
Okada, Y. et al. Deep whole-genome sequencing reveals recent selection signatures linked to demography and disease risk of Japanese. Nat. Commun. 9, 1631 (2018).
Nagai, A. et al. Overview of the BioBank Japan Project: study design and profile. J. Epidemiol. 27, 2–8 (2017).
Hirata, M. et al. Cross-sectional analysis of BioBank Japan clinical data: a large cohort of 200,000 patients with 47 common diseases. J. Epidemiol. 27, 9–21 (2017).
Loh, P.-R. et al. Efficient Bayesian mixed-model analysis increases association power in large cohorts. Nat. Genet. 47, 284–290 (2015).
Bulik-Sullivan, B. K. et al. LD score regression distinguishes confounding from polygenicity in genome-wide association studies. Nat. Genet. 47, 291–295 (2015).
Akiyama, M. et al. Genome-wide association study identifies 112 new loci for body mass index in the Japanese population. Nat. Genet. 49, 1458–1467 (2017).
Kanai, M. et al. Genetic analysis of quantitative traits in the Japanese population links cell types to complex human diseases. Nat. Genet. 50, 390–400 (2018).
Yang, J. et al. Conditional and joint multiple-SNP analysis of GWAS summary statistics identifies additional variants influencing complex traits. Nat. Genet. 44, 369–375 (2012).
Wang, C. L. et al. Cyclic compressive stress-induced scinderin regulates progress of developmental dysplasia of the hip. Biochem. Biophys. Res. Commun. 485, 400–408 (2017).
Lee, S. et al. Optimal unified approach for rare-variant association testing with application to small-sample case–control whole-exome sequencing studies. Am. J. Hum. Genet. 91, 224–237 (2012).
Laue, K. et al. Craniosynostosis and multiple skeletal anomalies in humans and zebrafish result from a defect in the localized degradation of retinoic acid. Am. J. Hum. Genet. 89, 595–606 (2011).
Lamparter, D., Marbach, D., Rueedi, R., Kutalik, Z. & Bergmann, S. Fast and rigorous computation of gene and pathway scores from SNP-based summary statistics. PLoS Comput. Biol. 12, e1004714 (2016).
Pers, T. H. et al. Biological interpretation of genome-wide association studies using predicted gene functions. Nat. Commun. 6, 5890 (2015).
Frey, B. J. & Dueck, D. Clustering by passing messages between data points. Science 315, 972–976 (2007).
Yang, J. et al. Genetic variance estimation with imputed variants finds negligible missing heritability for human height and body mass index. Nat. Genet. 47, 1114–1120 (2015).
Yang, J., Lee, S. H., Goddard, M. E. & Visscher, P. M. GCTA: a tool for genome-wide complex trait analysis. Am. J. Hum. Genet. 88, 76–82 (2011).
Turchin, M. C. et al. Evidence of widespread selection on standing variation in Europe at height-associated SNPs. Nat. Genet. 44, 1015–1019 (2012).
Purcell, S. et al. PLINK: a tool set for whole-genome association and population-based linkage analyses. Am. J. Hum. Genet. 81, 559–575 (2007).
The International HapMap Consortium. A haplotype map of the human genome. Nature 437, 1299–1320 (2005).
Howie, B. N., Donnelly, P. & Marchini, J. A flexible and accurate genotype imputation method for the next generation of genome-wide association studies. PLoS Genet. 5, e1000529 (2009).
Huang, J. et al. Improved imputation of low-frequency and rare variants using the UK10K haplotype reference panel. Nat. Commun. 6, 8111 (2015).
Loh, P.-R., Palamara, P. F. & Price, A. L. Fast and accurate long-range phasing in a UK Biobank cohort. Nat. Genet. 48, 811–816 (2016).
Li, Y., Willer, C. J., Ding, J., Scheet, P. & Abecasis, G. R. MaCH: using sequence and genotype data to estimate haplotypes and unobserved genotypes. Genet. Epidemiol. 34, 816–834 (2010).
Delaneau, O., Marchini, J. & Zagury, J.-F. A linear complexity phasing method for thousands of genomes. Nat. Methods 9, 179–181 (2012).
Wang, K., Li, M. & Hakonarson, H. ANNOVAR: functional annotation of genetic variants from high-throughput sequencing data. Nucleic Acids Res. 38, e164 (2010).
Finn, R. D. et al. The Pfam protein families database: towards a more sustainable future. Nucleic Acids Res. 44, D279–D285 (2016).
Acknowledgements
We are grateful to the staff of the IMM, the JMICC, the JPHC, ToMMo, and the BBJ for collecting samples and clinical information. We would like to acknowledge the staff of the RIKEN Center for Integrative Medical Sciences for genotyping and data management. This study was funded by the BBJ project and the Tohoku Medical Megabank project, supported by the Ministry of Education, Culture, Sports, Sciences, and Technology of the Japanese government and the Japan Agency for Medical Research and Development (Grant numbers: JP17km0305002, 18km0605001, JP18km0105001, JP18km0105002, JP18km0105003, and JP18km0105004). The JPHC Study has been supported by the National Cancer Center Research and Development Fund since 2011 and by a Grant-in-Aid for Cancer Research from the Ministry of Health, Labor, and Welfare of Japan from 1989 to 2010. The JMICC study was supported by Grants-in-Aid for Scientific Research for Priority Areas of Cancer (No. 17015018) and Innovative Areas (No. 221S0001) and a JSPS KAKENHI Grant (No. 16H06277) from the Japanese Ministry of Education, Science, Sports, Culture, and Technology.
Author information
Authors and Affiliations
Contributions
M.A., Y.K., and M.Kubo conceived the study. K.M., M.Hirata, Y.Murakami, and M.Kubo collected and managed the BBJ sample. T.Y., M.I., N.S., and S.T. collected and managed the JPHC sample and information. A.H., N.M., and M.Y. collected and managed the ToMMo sample and information. K.T., M.S., and A.S. collected and managed the IMM sample and information. S.Suzuki, D.M., M.N., and K.W. collected and managed the JMICC sample and information. Y.Momozawa and M.Kubo performed genotyping and whole-genome sequencing. M.A., K.I., S.Sakaue, M.Kanai, and Y.K. performed statistical analysis. Y.K., S.I., A.T., Y.O., and M.Kubo supervised the study. M.A., M.Horikoshi, Y.K., and M.Kubo wrote the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Peer review information Nature Communications thanks Nicola Pirastu and the, other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Akiyama, M., Ishigaki, K., Sakaue, S. et al. Characterizing rare and low-frequency height-associated variants in the Japanese population. Nat Commun 10, 4393 (2019). https://doi.org/10.1038/s41467-019-12276-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-019-12276-5
This article is cited by
-
Diallel panel reveals a significant impact of low-frequency genetic variants on gene expression variation in yeast
Molecular Systems Biology (2024)
-
The association between DNA methylation and human height and a prospective model of DNA methylation-based height prediction
Human Genetics (2024)
-
Proteo-genomics of soluble TREM2 in cerebrospinal fluid provides novel insights and identifies novel modulators for Alzheimer’s disease
Molecular Neurodegeneration (2024)
-
Genetic drivers of heterogeneity in type 2 diabetes pathophysiology
Nature (2024)
-
Improved genetic prediction of the risk of knee osteoarthritis using the risk factor-based polygenic score
Arthritis Research & Therapy (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
