
Abstract
Studying immune repertoire in the context of organ transplant provides important information on how adaptive immunity may contribute and modulate graft rejection. Here we characterize the peripheral blood immune repertoire of individuals before and after kidney transplant using B cell receptor sequencing in a longitudinal clinical study. Individuals who develop rejection after transplantation have a more diverse immune repertoire before transplant, suggesting a predisposition for post-transplant rejection risk. Additionally, over 2 years of follow-up, patients who develop rejection demonstrate a specific set of expanded clones that persist after the rejection. While there is an overall reduction of peripheral B cell diversity, likely due to increased general immunosuppression exposure in this cohort, the detection of specific IGHV gene usage across all rejecting patients supports that a common pool of immunogenic antigens may drive post-transplant rejection. Our findings may have clinical implications for the prediction and clinical management of kidney transplant rejection.
Similar content being viewed by others


Introduction
Kidney transplantation is the preferred treatment of end-stage renal disease (ESRD) and chronic kidney disease. Even though there have been significant improvements in technologies and tissue matching based on histocompatibility testing for donor/recipient human leukocyte antigens (HLA)1, predicting graft outcome is still an unsolved problem. Unmeasured tissue mismatching at other minor, non-HLA loci2,3 can also drive alloimmune injury with acute and chronic rejection, resulting in poor long term graft outcomes4. Moreover, around 50% of kidney allografts, with no major HLA mismatches, are still lost within 10 years of transplantation5. We have previously hypothesized that non-HLA loci, may influence the immune response of the recipient against his kidney donor graft6. It is clear that more research needs to be done to better understand and predict the recipients’ risk of rejection to substantially improve long term patient and graft outcomes. Nevertheless, the diversity of the immune response to various immunogenic epitopes is as yet, poorly understood. The role of T cells in organ transplant rejection has been demonstrated7, but there is increasing appreciation of the additional role of B cells and antibodies in triggering this process8. In this regard, B-cell receptor sequencing (BCRSeq) is a promising high-throughput technique9 that allows the sequencing of millions of Immunoglobulin (Ig) regions in parallel to study the immune response. The key feature of B cells is their enormous diversity. Each individual is capable of producing >1013 different antibodies10, which enables them to recognize a vast array of foreign antigens. Human BCRs or Ig consist of two identical heavy chains (IgH) formed by five isotypes: IgM, IgD, IgA, IgE, and IgG and two light chains. The intact antibody contains a variable and a constant domain. Antigen binding occurs in the variable domain, which is generated by recombination of a set of variable (V), diversity (D) and joining (J) gene segments forming the B-cell immune repertoire, and its diversity is mainly concentrated in the complementary determining region 3 (CDR3). During the process of affinity maturation, somatic hypermutation (SHM) occurs in the variable region. A potent adaptive immune response is reliant upon the expansion of B-cell clones and a process termed affinity maturation, during which somatic mutations are introduced into the Ig gene rearrangements and B cells with higher affinity for a given antigen are selected.
The study of the immune repertoire in organ transplant is crucial to understand what triggers and sustains the rejection process and how it may eventually accelerate the path toward graft failure. With the advances of next generation sequencing and robust computational approaches, we can study the VDJ region in fine detail11,12. To date, T-cell immune repertoire analysis in kidney transplant has been carried out in very limited numbers of patients13,14,15, and even though BCRSeq has been applied to other diseases and human immune responses, such as multiple sclerosis16, influenza vaccine17 or immunodeficiency disorders18, there is a lack of studies in transplant rejection. In kidney transplant, BCRSeq has been only carried out in the context of tolerance19, HLA sensitized kidney transplant candidates undergoing desensitization therapy20 and B-cell infiltration comparing clonal expansion in blood and graft21. Another application on BCRSeq in transplant was previously published in a small cohort of 12 heart transplant recipients22.
Recognizing the importance of the humoral arm of immune response in late transplant rejection and chronic allograft failure, we characterize the peripheral blood immune repertoire using BCRSeq in a prospective, longitudinal study. We find that the immune repertoire diversity before transplantation is higher in those individuals who reject the kidney showing also expansion of certain clones and IGHV genes along the 24 months of follow-up. These results may help predict the rejection risk before engraftment, and may have clinical implications in the detection of particular antigens driving rejection.
Results
Study subjects
We performed BCRSeq in 83 peripheral blood samples from 27 unique patients and executed the analytical pipeline shown in Fig.1. Three clinical phenotype groups, defined by blinded central pathology reads of serial allograft biopsies scored by Banff criteria23,24 and the chronic allograft damage index (CADI) score were considered in this study: Non-progressors (NP; n = 10) had low non-incremental CADI score without acute rejection, progressors with no rejection (PNR; n = 10) had incremental CADI score over 2 years without rejection, and progressors with rejection (PR; n = 7) had incremental high CADI scores over 2 years with rejection episodes. Demographics, causes of kidney failure and immunosuppression usage is provided in Table 1. It is important to highlight some characteristics about these patients. The parent study that these patients were enrolled from had an overall low rate (17%) of biopsy confirmed acute rejection (mean{min,max} = 12 {6,24} months rejection time). These patients were all at low immunologic risk for rejection (peak panel reactive antibody sensitization status < 20%), and also had low rates of generation of donor-specific antibody (DSA) and in fact only two of the rejection phenotype patients included in the analysis had DSA. The generation of DSA to HLA, and MICA were measured in all serial sera over the course of the study25. National experience with similar immunosuppressive protocols in similar patient cohorts have confirmed similar good clinical outcomes and low rejection rates26,27,28.

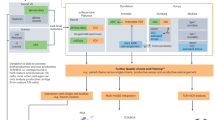
Overall study pipeline. a Schematic representation of antibody structure and the process of VDJ recombination responsible for the diversity produced in the immune repertoire. b B-cell clone defined as cells from a common ancestor and c analytical pipeline of the study: B-cell sequencing for gDNA and cDNA, diversity analysis considering the number of clones (richness) and the frequency of each clone (Shannon entropy), network analysis and clonal and IGHV gene analysis
B-cell immune repertoire sequencing
BCRSeq was done on genomic DNA (gDNA) samples extracted from blood clots on 81 samples from 27 kidney transplant recipients at three time points (0, 6, 24 months). Sequencing obtained a total number of 327,703 reads (mean 4045/sample) after quality control (see methods section). For validation of the results and further evaluation of each isotype, we additionally extracted RNA from matched PBMC that were available for 55 samples, collected at the same time as the blood clot, and performed complementary DNA (cDNA) sequencing at greater depth obtaining 1,773,330 reads for IgD (mean 31,667/sample), 1,708,227 reads for IgM (mean 30,504/sample), 973,444 reads for IgA (mean 17,383/sample), 139,7345 reads for IgG (mean 24,953/sample), and 29,000 reads for IgE (mean 5178/sample) (Supplementary Fig. 1). Libraries for each isotype were amplified separately and then pooled for sequencing; therefore, comparative cross isotype analysis is not feasible.
As shown in Fig. 1b, we defined a clone as a group of cells descended from a common ancestor molecule that have the same IGHV and IGHJ segment, same CDR3 length, and 90% nucleotide identity between CDR3s as previously defined in studies of adaptive B-cell responses18. This definition allows to study diversity, shared or common clones, and clonal expansion in the context of alloimmunity in kidney transplant. The number of unique clones per individual at each time point is shown as a barplot in supplementary material (Supplementary Fig. 1). For stringency of data analysis, we discounted samples with <100 clones (69 samples from gDNA and 55 samples from cDNA were left for further study. IgE isotype was discarded completely due to a very small number of reads). In addition, we filtered out patient 8 in the NP group from subsequent analysis, as we recognized after the run, that he had developed EBV + post transplant lymphoproliferative disease (PTLD) at 2.2 years post kidney transplant, characterized by proliferation of Epstein Barr virus (EBV) infected B cells. We observed an increased number of clones at time 6 in this patient, with lower clonal diversity before kidney transplant and at 24 months after kidney transplant. Since libraries were amplified from an invariant amount of template, a higher fraction of B cells in the blood may have resulted in a larger number of clonotypes represented in the sequenced products. Because of the distinct and unique pathologic process in this patient, this sample was excluded from future analysis.
Pre-transplant B-cell diversity is associated with rejection
As shown in Fig. 1c, we examined the B-cell immune repertoire diversity considering species richness (number of unique clones) and Shannon entropy (equation (1) from methods) across time points and clinical outcomes using a linear regression model considering the number of clones or entropy as a dependent variable and clinical outcome or SHM as an independent factor variable. The repertoire before kidney transplant in PR was significantly more diverse than in the NP (richness: P-value = 0.005, entropy: P-value = 0.01) with the same trend persisting at 6 months after kidney transplant (richness: P-value = 0.02, entropy: P-value = 0.02), and with no distinguishable group differences at 2 years post transplant (Fig. 2a and Supplementary Fig. 2). cDNA sequencing data post transplant showed the same trend in greater repertoire diversity at 6 months after transplant, predominantly for the IgD isotypes (richness: P-value = 0.02, entropy: P-value = 0.03) (Fig. 2b and Supplementary Fig. 2). There was no confounding effect on the data from various demographic and clinical variables, such as recipient age, gender, race, donor source, type of immunosuppression, HLA mismatch, and cause of renal failure. Since the B-cell response of a 1-year-old (the minimum age in the data) and 19-years-old (the maximum age in the data) might be very different, we performed a sensitivity analysis excluding these two patients and the results remained significant (NP vs. PR at time 0: richness: P-value = 0.01, entropy: P-value = 0.03). In another measure of immune repertoire diversity, we evaluated the SHM, defined as the frequency of mutations in each V gene segment, and found a trend for higher number of SHM for PR before transplant, and trend for higher SHM in the IgD isotype in PR at 6 months post transplant (P-value = 0.06).

Violin plots showing the number of clones (richness) across the three clinical outcomes. a Number of clones at time 0, 6, and 24 from gDNA samples. b Number of clones at time 6 for the IgD isotype from cDNA samples. The P-values are obtained from the adjustment of a linear regression model considering the number of clones as a dependent variable and clinical outcome as an independent factor variable (n = 27 samples). Violin plots represent the probability density of the data at each value. The dot marker represents the median value with the interquartile range. Source data is provided as Source Data File
B-cell diversity changes across time by clinical outcome
To find whether the immune repertoire diversity changes across time by the clinical outcome, we modeled the longitudinal data using linear-mixed effect models considering the interaction between clinical outcome and time. We found that NP and PR behaved differently across time after transplant showing an increase in diversity in NP and a decrease in diversity in PR, while for PNR the diversity remained invariable across time. This was observed for gDNA (richness: P-value = 0.007, entropy: P-value = 0.001, Fig. 3a) and all isotypes for cDNA, with the most significant differences in entropy being for IgM and IgD isotypes (IgA: P-value = 0.07, IgD: P-value = 0.02, IgG: P-value = 0.05, IgM: P-value = 0.04, Fig. 3b). The plots for richness with corresponding P-values are shown in Supplementary Fig. 3. As observed in the plots, one individual has an extra sample at time 32 months, which might skew the results, thus a sensitivity analysis was performed excluding this sample from the analysis and observing similar results except for the IgG and IgM isotypes where the significance is lost (gDNA-entropy: P-value = 0.004. cDNA-entropy: IgA: P-value = 0.1, IgD: P-value = 0.05, IgG: P-value = 0.08, IgM: P-value = 0.1).

Longitudinal data plotted with the fitted line for each clinical outcome. a Diversity measured by Shannon entropy represented across time points by the three clinical outcomes (NP, PNR, PR) in gDNA. b Diversity measured by Shannon entropy represented across time points by the three clinical outcomes (NP, PNR, PR) by isotypes in cDNA. The P-values correspond to the interaction term defined by time × clinical outcome adjusting a linear-mixed effect model (n = 27 samples). Each dot represents the entropy per sample along the time with its fitted line and confidence interval. Source data is provided as Source Data File
Diversity measures may be affected by biological and technical sampling. The diversity of a sample can differ markedly from the overall diversity in a repertoire since only a fraction of billions of cells are represented, which is known as missing species problem. Technical sampling may exist because each sample may vary on sequencing depth and some degree of experimental errors. To deal with the missing species problem, we used Recon (reconstruction of estimated clones from observed numbers) tool29, which estimates the overall clone size distribution. Recon outputs accurate and robust estimates of a set of diversity measures, including richness and entropy allowing robust comparisons of diversity between individuals. To deal with the sequencing depth and some degree of experimental errors, we performed a downsampling strategy; a very well used strategy in immune repertoire analysis11,17,30. In the Recon analysis (Supplementary Fig. S4: A–E), both richness and diversity were replicated for the gDNA data. In the cDNA data, time 6 IgD isotype shows the trend but did not reach significance although the longitudinal results for IgA, IgD, and IgG isotypes were replicated. In the downsampling analysis (Supplementary Fig. S4: F–J), everything is replicated but the time 0 for gDNA data. This might be a consequence of the restriction that downsampling strategies implied, especially on the gDNA data where the number of sequences is much lower than for the cDNA data. In gDNA, we restricted the analysis to individuals with at least 1000 clones in order to conserve enough sequences. Downsampling was done to a minimum of 1062 clones in comparison to 62,173 clones in cDNA. Despite this limitation, we observed the trend for time 0, conserve the significance for the longitudinal analysis in gDNA and replicated all the associations in cDNA. In both analyses (recon and downsampling), we replicated the results, despite some limitations highlighted here, showing the validity of the previously reported results.
B-cell networks show differences in clonal expansion
The B-cell repertoire can be naturally represented as a network based on sequence diversity31. In our data, we developed a visual network for each sample (Fig. 4 and Supplementary Figs. 5–7) where each vertex represented a unique BCR, and the number of identical BCRs based on their nucleotide sequences defined the vertex size. An edge exists between vertices when they belong to the same clone, so clusters of B cells can be shown as groups of interconnected vertices forming a clone. To quantify the network, we used the Gini index, which is an unevenness measure that was applied to the vertex and cluster distributions. When applied to vertex size, Gini(V), the overall clonal nature is represented. If Gini(V) is closer to 1, vertices are unequal showing expansion of some of them, and closer to 0 otherwise. When applied to cluster size, Gini(C), clonal dominance is represented. If closer to 1, clusters are unequal and therefore represent dominant clones, if closer to 0, all clusters are of equal size.

B-cell repertoire networks from three individuals representing the three clinical outcomes across time points. Each vertex represents a unique BCR being the vertex size defined by the number of identical BCRs considering the nucleotide sequences. An edge exists between vertices when they belong to the same clone as defined before, so clusters are groups of interconnected vertices forming a clone. Each sample shows the gini index obtained for the vertex size (Gini(V)) and cluster size (Gini(C)). BCR reflects the total B-cell receptors for that specific sample and clones reflect the total number of unique clones. Source Data is provided as Source Data File
In Fig. 4 we show an example of the marked visual and quantitative differences between representative B-cell repertoires from each of the three clinical outcome groups, across the three different time points (pre-transplant, and post transplant 6 and 24 months). In the PR repertoire, there is an abundance of B-cell sequences of forming more and larger clusters of clones in comparison with NP while PNR is located in between. Across time, the PR group shows a decrease in the number of BCR and unique clones in comparison with NP. The detailed B-cell networks of every individual in the study are provided in Supplementary Figs. 5–7. It is interesting to observe the very diverse pattern of the B-cell network in the individual who developed PTLD in the NP group (Supplementary Fig. 5), with no B-cell expansion before transplant, followed by an increase of B cells after 6 months and a clear clonal expansion accompanied with a decrease in diversity at 24 months post transplant.
On further evaluation of the Gini Index measure (Fig. 5), the PR group consistently showed significantly higher measures for both the vertex and the cluster over the NP group, suggesting that the PR group patients had higher clonal expansion at baseline, and further post transplant expansion of a subset of dominant clones (P-value [linear regression] < 0.05, Fig. 5). The PNR group falls between NP and PR as previously shown, although this time is significantly different over the NP group at time 24 (P-value [linear regression] < 0.05). Although the data for Fig. 5 was generated from the gDNA data, the IgM isotype for cDNA showed the same differences (P-value [linear regression] = 0.05) (Supplementary Fig. 8).

Vertex Gini Index plotted against Cluster Gini Index. The scatter plot represents each sample at time 0, 6, and 24. Boxplots shows the Gini(V) and Gini(C) differences at time 24. The P-values are obtained from the adjustment of a linear regression model considering the Gini(V) and Gini(C) as a dependent variable and clinical outcome as an independent factor variable for each time point (n = 27 samples). In the boxplot only time 24 is shown but time 0 and 6 where also significant for NP vs. PR: time 0: P (Gini(V)) = 0.1, P (Gini(C)) = 0.05; time 6 P (Gini(V)) = 0.02, P (Gini(C)) = 0.01; time 24: P (Gini(V)) = 0.003, P (Gini(C)) = 0.01. The band inside the box represents the median value, the box define the interquartile range (IQR) and whiskers define the first and third quartile ± 1.5 × IQR. Source data is provided as Source Data File
Certain clones and IGHV genes are implicated in rejection
Although our primary focus was to characterize the B-cell repertoire by clinical outcome groups, providing a global picture of the immune response pre- and post transplant, our data also enabled us to perform Ig sequence-specific analysis at the clone and the IGHV gene level.
For clonal analysis, we assessed the association of the presence or absence of each particular clone (118,223 total clones) with the clinical outcome (PR, PNR, NR) at each time point. Applying Fisher’s exact test, we found 8, 4, and 21 clones nominally associated with clinical outcomes at each of 0, 6, and 24 months, respectively (Supplementary Table 1). While none passed multiple testing correction, mainly because of a lack of power since we have a limited sample size in an analysis with thousands of parameters (clones), we could observe that the few clones that approached significance (P-value < 0.05) were shared across patients only in PR group and enriched at 24 months post transplant.
We also considered whether there were some clones that persisted over sampling time, more than others, within each clinical outcome (Supplementary Fig. 9). We account for two different measures: (1) number of persisting clones and (2) clonal expansion. We observed that the clones that were persistent in the PR were significantly more expanded (P-value [linear regression] = 0.01, PR vs. NP) and showed a trend of a higher number of persistent clones (P-value [linear regression] = 0.09). We further examined whether these persistent clones were also shared across different individuals within each clinical outcome. From the 263 persistent clones detected, 23 were shared across individuals. Five were shared within the same PNR and six within the PR group and no clones were shared between the NP group. In total, there were 12 shared clones that were common across both groups of patients with progressive chronic transplant injury and fibrosis over time (PR and PNR). The list of clones shared across individuals is provided in supplementary material (Supplementary Table 2).
We next performed IGHV gene analysis, looking at IGHV gene usage per sample, defined as the number of times each IGHV gene has been used, normalized by the number of clones (to avoid sampling bias of certain IGHV genes), filtering out low-expressed genes (IGHV gene usage > 0.05 in at least 10% of the samples), and applying a linear regression model to find those genes that were associated with each clinical outcome, at each time point. From the 27 IGHV genes that passed the low-expression filter, we found significant genes between the PR and NP group (P-value < 0.05) with three genes at time 0, 7 at time 6 and 16 at time 24 (Fig. 6a–c). From these genes, 1 (IGHV3-11) at time 0, 5 genes (IGHV3-7, IGHV3-15, IGHV3-21, IGHV3-23, IGHV4-39) at time 6 and 16 genes (IGHV1-8, IGHV1-18, IGHV1-46, IGHV2-5, IGHV3-7, IGHV3-11, IGHV3-15, IGHV3-23, IGHV3-30, IGHV3-33, IGHV3-48, IGHV3-74, IGHV4-39, IGHV4-59, IGHV4-61, IGHV5-51) at time 24 passed False Discovery Rate (FDR) multiple testing correction. Interestingly, we found that IGHV3-23 was the most significant and abundant gene across all three time points in the NP vs. PR comparison (time 0: P-value = 0.04, time 6: P-value = 0.003, time 24: P-value = 0.02) (Fig. 6d). In addition, we evaluated whether the IGHV3-23 sequences were over represented among the shared sequences from the previous clonal analysis. We found, using an enrichment analysis with Fisher’s exact test, that the IGHV3-23 sequences were significantly over represented in both, the persistent clones shared among individuals (Supplementary Table 2) (P-value < 2.2 × 10−16), and the clones associated with clinical outcome at time 24 (Supplementary Table 1) (P-value < 2.2 × 10−16). We observed that individual 9 in the NR group, who had been found to share some persistent clones with the progressors in the previous analyses, classified with the PR group at all time points. There was no confounding effect on the data from various demographic and clinical variables, such as recipient age, gender, race, donor source, type of immunosuppression, HLA mismatch, and cause of renal failure. In addition, this gene was also found to be significant in both the IgM (P-value [linear regression] = 0.008) and IgD (P-value [linear regression] = 0.05) isotypes based on cDNA at 24 months post transplant, in concordance with the previous results showing consistency with these two isotypes being most enriched in the PR group. Only three other genes were found significant in the cDNA analysis, and all were at 24 months post transplant in IgD and IgM isotypes (IGHV3-15 and IGHV4-61 in IgD and IGHV4-39 in IgM).

Heatmap and boxplot for the IGHV genes usage analysis. Heatmap showing the IGHV genes selected as nominally significant (P-value < 0.05) at time 0 (a), 6 (b), and 24 (c) for NP vs. PR. The red color scale represents the expression of each gene across samples. The bands on the top shows the clinical outcome and the cause of ESRD. Boxplot showing IGHV3-23 expression across time points for NP vs. PR (time 0: P-value = 0.04, time 6: P-value = 0.003, time 24: P-value = 0.02) (d). The band inside the box represents the median value, the box define the interquartile range (IQR) and whiskers define the first and third quartile ± 1.5 × IQR. P-values are obtained from the adjustment of a linear regression model considering the V genes as a dependent variable and clinical outcome as an independent variable. (n = 12 samples). Source data is provided as Source Data File
Discussion
Diversity is an essential characteristic of the immune system, and in healthy humans, is critical against pathogens to deal with diseases. In organ transplant, deliberate therapeutic manipulation is instituted clinically to allow the foreign organ to be actively ignored or accepted by the own patient’s immune system so as to not mount an alloimmune response, leading to rejection. B cells are an important component of this process and have been shown by our group and others, to be pivotal in both antigen presentation32,33 and alloantibody production34,35. In this work, we have used high-throughput B-cell sequencing to better understand the diversity and clonality of B cells in the kidney transplant recipient’s circulation, both before engraftment and after 24 months of follow-up, with longitudinal assessment of the B-cell immune repertoire. Overall, our analysis shows a higher B-cell diversity before engraftment, differences longitudinally with a decrease in diversity accompanied by clonal expansion and an increase in certain IGHV gene usage among those who go on to reject the grafts.
A key unmet clinical need in organ transplant is the lack of noninvasive, sensitive, and accurate prediction of transplant injury and poor outcomes. This task is complicated by the fact that there are diverse factors that influence graft survival36. In this study, we found that stable individuals had a reduced diversity of the B-cell immune repertoire before transplant in comparison with those who rejected the organ. The next step should be to demonstrate the predictive value of B-cell repertoire diversity, providing potential better biomarkers for prediction of rejection before engraftment, and the possibility of being implemented in clinical care and immunosuppression choices before and after kidney transplant. If this feature is the result of any factor contributing to the decrease of diversity in stable individuals, such as environmental or genetic factors, we could not only predict the rejection but also prevent it. Indeed, very recent findings showed that the variation in the immune system is driven by environmental and genetic factors37,38. In our study, we could not find any association with any demographic and other clinical patient characteristics (age, gender, race, immunosuppression, organ source, HLA mismatches, and ESRD). In this regard, we need new analysis to corroborate whether specific factors affect the B-cell repertoire diversity and transplant outcomes.
Another interesting finding in our study shows that the immune repertoire behaves differently across time depending on the clinical outcome group. For those who show post transplant rejection of the organ, the B-cell diversity is initially higher and then decreases over time, whereas the reverse diversity trend is seen in patients who do not develop rejection or chronic graft injury. Even though all individuals received the same immunosuppression load after transplant, some possible explanation for the decreased diversity in the patients who develop rejection, may relate to the fact that these patients receive a temporarily greatly increased load of immunosuppression for the treatment of rejection and then are kept on higher baseline. Though this could explain the reduction in B-cell diversity over time, and explain the difference at 24 months post transplant, this is unlikely to be the cause, as the reduced diversity in the PR group is also seen at 6 months post transplant, at a time when patients have not yet developed rejection, suggesting that other active processes are likely to be involved. The observation of selective clonal expansion with more dominant clones only in patients who develop both rejection and/or progressive chronic kidney transplant injury, suggests a biologically relevant, alloantigen driven selection, persistence and expansion of certain clones over time, which accounts for the overall reduction in temporal diversity. Even though we can hypothesize that the expansion of these clones is likely linked to alloimmnue injury to the graft, direct evidence that the expansion of these clones is alloimmune requires additional in vitro and animal studies.
Acute rejection remains the strongest negative factor for long term graft survival despite the rapid improvements in immunosuppression therapies39,40. This study also finds an association of some IGHV genes usage with rejection, although the causal link should be explored in future studies. The IGHV3-23 is the most interesting gene in the gDNA analysis as it is significantly higher used in patients who develop rejection across all measured time points and it is over represented in the persistent clones shared among individuals and the clones enriched among rejected patients at 24 months post transplant. This gene is also validated at 24 months post transplant in both the IgD and IgM isotypes in the cDNA analysis. IGHV3-23 has been extensively associated with bad prognosis in chronic lymphocytic leukemia41 and it has been shown that the vast majority of IGHV3-23 sequences retained the capacity to mediate superantigen interactions42. B-cell superantigens are produced by viruses and bacteria, known to bind to immunoglobulins outside the conventional antigen binding sites43. Encounters of B cells with a superantigen have been shown to induce proliferation, activation, migration and deletion44. In the transplanted kidney, there is the potential for continuous exposure to virus and bacterial antigens, relating either to an etiology of primary vesicoureteric reflux as the cause of ESRD or secondary urinary reflux after reimplantation of the transplant ureter, or reflux following urinary tract infection, the risk of which are increased with exposure to chronic immunosuppression after transplantation. We adjusted the analyses results for cause of renal failure, among other clinical and demographic factors; the results previously discussed remain significant although we realized that the NP misclassified patient in the analysis (Fig. 6) had a reflux disease. Cheng et al. have also previously found that clones in biopsy tissue of kidney transplant recipients infiltrated by B cells had a predominance of the IGHV3-23 gene among others45. Grover et al.46 demonstrated that the antibodies for this particular gene were not recognizing donor HLA antigens but rather were specific for E. coli and Modena et al.47 showed that the burden of the number of bacteria in urine were much higher in patients with interstitial fibrosis and tubular atrophy than those with grafts that were functioning well. We extend these findings demonstrating that the use of IGHV3-23 gene is significantly higher in multiple rejecting patients in peripheral blood and may implicate particular common antigens in driving rejection. In the future, the expression of IGHV3-23 could be potentially used to monitor the immune response towards the transplanted kidney.
Extending our study using cDNA sequencing, we could replicate the majority of our results in two of the isotypes (IgM and IgD), showing lower diversity pre-transplant in the NP, being the two most significant in the longitudinal analysis with more expansion and dominant clones in the network analysis and also replicating the IGHV3-23 gene. The first antibodies to be produced in a humoral immune response are always IgM and quickly progress to the production of all the different isotypes, IgD, IgA, IgG, and IgE but especial interest requires the IgD isotype48. IgD is co-expressed with IgM and secreted IgD exists and has a function in blood, mucosal secretions and on the surface of innate immune effector cells such as basophils49. Basophils are white cells that fight viruses, bacteria, parasites and fungi and they have been shown to be involved in renal diseases and transplant rejection50. Thus, another evidence that relates the B-cell responses to the rejection process with viruses and bacteria. Future studies are needed to demonstrate that this activation is due to differences in the recipient microbiome with implications in diagnostics and therapeutics.
This study allowed us to identify the relevance of some of these BCR clones, identify the BCR clones of clinical relevance with allograft rejection, and show that there is a likely relevance of these clones with heterologous immunity, given the enrichment of these clones in patients with colonized urinary tracts before transplant and their biological relevance to pathogen responses. A better understanding of the immune repertoire behavior in kidney transplant would not have been possible without the application of BCRSeq in combination with a robust implementation of a computational and statistical pipelines. Nevertheless, there are several limitations of our approach that should be recognized: First, our sample size is highly selected and relatively small in a set of pediatric patients and even though we reached statistical significance in our analysis and validated in two different sources of data, further analysis will be needed to corroborate our results. Secondly, our results are not exempted of the influence that biological and technical sampling may have in our analysis. Diversity measures are dependent of several issues: the fact that only a fraction of billions of cells in a repertoire are represented in a sample, differences in sequencing depth and possible experimental errors. We have extensively controlled for all these issues, first in the laboratory, running the same amount of blood for each sample in the same batch and second, computationally and statistically, applying recon tool to estimate the overall repertoire and performing downsampling to control for sequencing depth and experimental errors. Thirdly, we have performed BCRSeq using two different sources, gDNA and cDNA. Sequencing gDNA facilitates estimation of the clonality of a given Ig sequence since the number of sequence reads will be proportional to the number of gDNA molecules. Sequencing cDNA provides an estimate of the relative expression level of various Ig sequences in the repertoire. It has been shown that for T-cell receptors, the clonotype characterization performed on cDNA is not that good as in gDNA showing that the relative proportion of individual clones differed greatly15 or that the tracking of HIV-specific clones is only successful with gDNA, but not mRNA51. Fourthly, the influence of immunosuppression may be a confounding factor on this type of analysis. In this study all the samples come from a clinical trial where the same immunosuppression load was received by all patients after transplantation. Nevertheless, we controlled by the two types of steroid-based and steroid-free to make sure that this was not an issue, observing no differences in the results. Finally, the cohort we present here is that of pediatric transplants. The majority of the transplanted clinical aspects are similar in children and adults. The immunosuppression and regimens used are similar, creatinine is the major serum biomarker, acute rejection is determined primarily by means of biopsy with the use of the Banff criteria and the rejection mechanisms of the kidney graft are generally similar52, therefore the majority of the research done in adults or children may apply to both. However, other aspects such as non-compliance/non-adherence to immunosuppression, immunological aspects, the primary kidney diseases, leading to kidney failure, often associated with urologic issues, and the immunizations that are required before transplantation may differ, therefore further analysis in an adult population will be necessary to generalize these findings.
Despite these limitations, our data reveal that higher pre-transplant diversity is observed in individuals who go on to reject the organ, suggesting a predisposition of rejection, which may have future implications in predicting risk of rejection before engraftment, immunosuppression choices and clinical care practices. After 24 months of follow-up, an overall reduction in diversity over time accompanied by the persistence and expansion of certain clones and a higher use of several IGHV genes is observed in the rejection group, which may implicate particular common antigens in driving rejection. Special interest is observed for the increased use of IGHV3-23 gene among the rejection patients since it has been previously associated with kidney transplantation and could be a key component to drive the rejection process. This work presents a longitudinal analysis of the B-cell immune repertoire in organ transplant promoting more studies to confirm these findings since they may have clinical implications in predicting, controlling, monitoring and treating kidney rejection.
Methods
Study design
We studied 81 samples for gDNA and 56 matched samples for cDNA longitudinally at time 0, 6, and 24 months from a total number of 27 pediatric recipients who received a primary kidney transplant. The subjects in this study come from a clinical trial (SNSO1 multicenter study) where subjects were randomized (1:1) to a traditional low-dose steroid-based immunosuppression regimen (steroids, standard daclizumab induction until the second month post transplant, and maintenance immunosuppression with tacrolimus (Prograf, Astellas Pharma) and MMF (CellCept, Hoffman-La Roche) or a steroid-free immunosuppression regimen (prolonged daclizumab induction until the sixth month post transplant, tacrolimus and MMF). All subjects were enrolled following IRB approval and had informed consent. In this study, 14 patients received a steroid-avoidance regimen, while 13 received a steroid-based immunosuppressive regimen53 and none of these patients received immunosuppression before transplant as this was one exclusion criteria. Treatment for rejection consisted of three pulses of intravenous corticosteroid (10 mg/kg) and baseline immunosuppression intensification.
All the samples used in the study had an associated serial allograft biopsy, which was read by a central pathologist, using semi-quantitative histological scores. Clinical acute rejection was defined as an acute rejection episode, associated with graft dysfunction, based on a greater than 10% rise in serum creatinine from baseline values, and confirmed through central pathological reading of the biopsies according to the updated Banff classification23,24. Chronic allograft injury was defined using the chronic allograft damage index (CADI) score. The patients were classified in three clinical outcomes defined by CADI score and rejection episodes Non-progressors (NP) had low non-incremental CADI score on three serial biopsies over 2 years, without acute rejection, progressors with no rejection (PNR) had higher CADI score on their serial biopsies over 2 years and incremental across the time points without rejection, and progressors with rejection (PR) had incremental high CADI scores on their serial biopsies over 2 years with rejection episodes. These patients were very carefully selected from a larger cohort of 120 patients, matching for demographic variables, and for all NP, and PNR to have no evidence inflammation on biopsy, or subclinical injury as measured by absent donor-specific antibodies. None had HLA or haplo- identical graft as this was an exclusion criteria for enrollment54. All samples were collected from 12 different US pediatric transplant programs between 2004 and 2006, under IRB approved protocols. The study was also approved by The Human Research Protection Program (HRPP) of the University of California, San Francisco and Stanford University to allow analysis of biobanked samples. All patients/guardians provided informed consent to participate in the research, in full adherence to the Declaration of Helsinki. The clinical and research activities being reported are consistent with the Principles of the Declaration of Istanbul as outlined in the Declaration of Istanbul on Organ Trafficking and Transplant Tourism.
Isolation of gDNA and RNA
Blood samples (4.5 ml) were collected into a 5 ml red top tube and incubated at room temperature for 30 min until the clot was formed. The sample was then centrifuged at 2000 × g for 5 min using a swinging bucket rotor. The upper layer of serum was then transferred to another cryotube and the clot was stored in the same tube at −80 °C until use. Genomic DNA from whole-blood clot was extracted by using Clotspin Baskets and the Gentra PuregeneBlood Kit (Qiagen, Valencia, CA).
For RNA extraction from kidney needle biopsy (Qiagen, Valencia, CA) and stored at −80 °C; total RNA was extracted using a master mix of 790 µl TRIzol and 10 µl glycogen. Tissue samples were homogenized, incubated at 15 to 25 °C for 5 min and 160 µl chloroform was added for phase separation. The mixture was incubated again at 25 °C for 2 min followed by centrifugation at 4 °C and used for RNA extraction using the RNeasy Micro Kit (Qiagen Catalog no.4004). RNA quantity and integrity were determined with the Thermo Scientific NanoDrop ND-2000 UV–Vis Spectrophotometer and Agilent Bioanalyzer, respectively.
B-cell sequencing
Genomic DNA templated PCR reactions were prepared from 100 ng gDNA aliquots to generate six independent barcoded libraries per sample. Multiplexed primers to the IgH J or FR1 or FR2 framework regions per the BIOMED-2 design were used55. Ten-nucleotide ‘barcode sequences’ in the primers were used to indicate the sample identity and replicate library identity for each PCR reaction. PCR was performed with AmpliTaq Gold (Roche) polymerase with the following program: 94 °C for 5 min; 35 cycles of (94 °C for 30 s, 60 °C for 45 s, 72 °C for 90 s); and final extension at 72 °C for 10 min. A second PCR reaction was carried out to ensure that libraries were not amplified to saturation prior to gel purification and sequencing. In all, 0.4 μl of each first PCR product templated the second PCR reaction using external primers specific for the 454 linker sequences; the amplification was carried out with the program: 94 °C for 15 min, 12 cycles of (94 °C for 30 s, 60 °C for 45 s, 72 °C for 90 s), and final extension at 72 °C for 10 min. The error rate of the AmpliTaq Gold should have a minimal effect on the identification of clonally related sequences or estimation of somatic mutation rates in sequences as discussed somewhere else56. cDNA was synthesized from total 300 ng of RNA with priming by random hexamers. Templates were amplified by PCR using Biomed IGHV primers in framework 1 (FR1) and isotype-specific primers located in the first exon of the constant regions. These primers18,57 also encoded approximately half of the Illumina linker sequences needed for cluster generation and sequencing on the MiSeq instrument. Sample identity was encoded by eight-nucleotide multiplex identifier barcodes in each primer. For Illumina cluster recognition, four randomized nucleotides were encoded in the primers immediately after the Illumina linker sequence in the constant region primers. Each antibody isotype for each sample was amplified in a separate PCR reaction, to prevent formation of cross isotype chimeric PCR products. PCR was carried out with AmpliTaq Gold (Roche) following the manufacturer’s instructions, and used a program of: 94 °C for 7 min, 35 cycles of (94 °C for 30 s, 58 °C for 45 s, 72 °C for 120 s), and final extension at 72 °C for 10 min. A second PCR step was used to add the remaining portion of the Illumina linkers to the amplicons and was carried out with the Qiagen Multiplex PCR kit (Qiagen) according to the manufacturer’s instructions, using 0.4 microliters of the first PCR product as template in a 30 microliter reaction. The PCR program for the second PCR step was 94 °C for 15 min, 12 cycles of (94 °C for 30 s, 60 °C for 45 s, 72 °C for 90 s), and final extension at 72 °C for 10 min. The products of each PCR reaction were pooled in estimated equimolar amounts, electrophoresed on agarose gels, and gel extracted with QIAquick kits (Qiagen). High-throughput sequencing of genomic DNA templated libraries was performed on the 454 (Roche) platform using Titanium chemistry. cDNA library sequencing was performed on an Illumina MiSeq instrument using 600-cycle sequencing kits. A full list with the primers used with MiSeq (M154 and M155) and 454 Titanium (T7) are included in Supplementary Data 1.
Sequencing reads were processed as follows: paired-end reads were merged using FLASH58 where after sequences were demultiplexed and trimmed of barcodes and IGHV primer sequences. The V, D, and J regions and V–D (N1), D–J (N2) junctions were identified using the alignment program IgBLAST59. Sequences were filtered to remove non-IGH artifacts, sequences with V gene insertion or deletions, chimeric sequences and nonfunctional sequences. At sample level, we excluded those with <100 clones (defined by same V and J segments, same CDR3 length and 90% nucleotide identity) as a control for bad quality samples. After quality control, for gDNA we had complete longitudinally data for 69 samples at time 0, 6 and 24 with a total number of 327,703 reads (mean 4045 per sample). For cDNA, we had complete data for 55 matched samples, although no time 0 samples were further available. In this case, we had isotype-specific information (1,773,330 reads for IgD (31,667 per sample), 1,708,227 reads for IgM (30,504 per sample), 973,444 reads for IgA (17,383 per sample), 139,7345 reads for IgG (24,953 per sample), and 29,000 reads for IgE (5,178 per sample).
Diversity analysis
Diversity is measured by species richness considering the number of clones per sample. This measure does not consider the frequency of each species, so we also used Shannon entropy (H) to measure diversity providing information about the size distribution of species in the population. H is defined as:
where N is the number of unique clones and pi is the frequency of clone i. H ranges from 0 (sample with only one clone) to \(H{\mathrm{max}} = {\mathrm{log}}_2N\) (sample with a uniform distribution of clones).
Then, we used general linear model to find the association between richness and entropy with the clinical outcome at the different time points. We adjusted this model by all the clinical variables available showed in Table 1 to be sure that any of the characteristics of the patient was a confounding factor.
To model the longitudinal component of the data, we applied linear-mixed effect model considering a conditional growth model as shown in Supplementary Fig. 10. To apply this model, we used lme4 package in R considering the interaction between clinical outcome and time to find association with richness and diversity with time being a random effect.
To deal with the fact that diversity measures may be affected by the missing species problem (only a fraction of billions of cells in a repertoire are represented) and sequencing and experimental errors, we performed two strategies in addition of the full data analysis. First, we used Recon (reconstruction of estimated clones from observed numbers) tool29 to deal with the missing species problem. Recon is a modified maximum likelihood method that outputs the overall diversity of a repertoire from measurements on a sample. Recon outputs accurate and robust estimates of a set of diversity measures, including richness and entropy allowing robust comparisons of diversity between individuals. Second, we performed a downsampling strategy taking a random subset of reads for each sample equal to the smallest sequencing size, followed to the re-calculation of the B-cell clones to adjust by sequencing depth and deal with possible experimental errors. For gDNA, there are samples with very low reads ( < 1000), and to avoid losing many sequences and the reality of the data, we excluded a total of nine samples that had <1000 reads. In the case of cDNA, this was not necessary. We generated ten random subsamples to account for possible stochastic effects and performed the diversity analysis at each time point and the longitudinal data analysis on the mean value of ten independently downsampled diversity estimates.
Network analysis
The network generation algorithm is very similar to the one defined before31. Briefly, each vertex represents a B-cell sequence where the size is defined by all the identical sequences. Edges are calculated using the clone definition (same V and J segments, same CDR3 length and 90% nucleotide identity between CDR3s) and clusters represents each clone in the repertoire. The analysis was done using igraph package in R using the layout_with_graphopt option to generate the plot.
To quantify the network, we calculated the Gini Index for vertex size and cluster size. Gini Index is a measure of unevenness extensively used to measure wealth distribution. It measures the inequality among values of frequency distribution. We used the Gini function from ineq package in R to calculate the Gini coefficient for vertex size and cluster size distribution. A Gini coefficient of zero expresses perfect equality and a Gini coefficient of 1 expressed maximal inequality.
Clonal analysis
To study the specific clones associated with clinical outcome, we built a matrix with all clones that are present in more than one sample (total number = 118,223) by all samples at each time point. We then studied the association with clinical outcome of each particular clone defining one variable per clone as present/no present. Finally, we applied Fisher’s exact test to account for significance in the 2 × 3 table for each clone in each time point. We also studied the persistence clones defined by those clones that are in more than one time point in each individual. Then, to account for differences by clinical outcome, we applied a linear model defining as dependent variable the number of clones (to measure differences in persistence) and the number of counts of each clone (to measure the clonal expansion) and clinical outcome as independent predictor.
IGHV gene usage analysis
To study the IGHV genes, we assessed the IGHV gene usage per sample as the number of times each gene is used normalized by the number of clones to avoid overrepresentation of certain IGHV genes. For statistical analysis, we filtered out those genes with very low expression (IGHV usage/clones < 0.05) in at least 10% of the samples. In total, we analyzed 27 IGHV genes corresponding to 63 samples. Then, we applied a linear model to find those genes that were associated with clinical outcome in each time point and corrected these results by multiple testing using Benjamini and Hochberg FDR < 0.05. We adjusted this model by all the clinical variables available showed in Table 1 to be sure that any of the characteristics of the patient was a confounding factor.
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Data availability
The data supporting this publication has been deposited in the ImmPort repository under the study accession SDY1361(https://www.immport.org/shared/study/SDY1361). All other data are available from the authors upon request. Source data for the graphs and statistical analyses can be found in the Source Data file.
References
Cai, J. & Terasaki, P. I. Post-transplantation antibody monitoring and HLA antibody epitope identification. Curr. Opin. Immunol. 20, 602–606 (2008).
Sigdel, T. K. et al. Non-HLA antibodies to immunogenic epitopes predict the evolution of chronic renal allograft injury. J. Am. Soc. Nephrol. 23, 750–763 (2012).
Li, L. et al. Compartmental localization and clinical relevance of MICA antibodies after renal transplantation. Transplantation 89, 312–319 (2010).
Lamb, K. E., Lodhi, S. & Meier-Kriesche, H. -U. Long-term renal allograft survival in the United States: A critical reappraisal. Am. J. Transplant. 11, 450–462 (2011).
The Scientific Registry of Transplant Recipients. Available at: https://srtr.transplant.hrsa.gov/annual_reports/2012/Default.aspx. (Accessed: 24th May 2018)
Pineda, S. et al. Novel non-histocompatibility antigen mismatched variants improve the ability to predict antibody-mediated rejection risk in kidney transplant. Front. Immunol. 8, 1687 (2017).
Valujskikh, A., Baldwin, W. M. & Fairchild, R. L. Recent progress and new perspectives in studying T cell responses to allografts. Am. J. Transplant. 10, 1117–1125 (2010).
Zarkhin, V., Chalasani, G. & Sarwal, M. M. The yin and yang of B cells in graft rejection and tolerance. Transplant. Rev. 24, 67–78 (2010).
Georgiou, G. et al. The promise and challenge of high-throughput sequencing of the +antibody repertoire. Nat. Biotechnol. 32, 158–168 (2014).
Schroeder, H. W. Similarity and divergence in the development and expression of the mouse and human antibody repertoires. Dev. Comp. Immunol. 30, 119–135 (2006).
Yaari, G. & Kleinstein, S. H. Practical guidelines for B-cell receptor repertoire sequencing analysis. Genome Med. 7, 121 (2015).
Shugay, M. et al. VDJtools: Unifying post-analysis of T cell receptor repertoires. PLOS Comput. Biol. 11, e1004503 (2015).
Alachkar, H. et al. Quantitative characterization of T-cell repertoire and biomarkers in kidney transplant rejection. BMC Nephrol. 17, 181 (2016).
Morris, H. et al. Tracking donor-reactive T cells: Evidence for clonal deletion in tolerant kidney transplant patients. Sci. Transl. Med. 7, 272ra10 (2015).
Dziubianau, M. et al. TCR repertoire analysis by next generation sequencing allows complex differential diagnosis of T cell-related pathology. Am. J. Transplant. 13, 2842–2854 (2013).
Palanichamy, A. et al. Immunoglobulin class-switched B cells form an active immune axis between CNS and periphery in multiple sclerosis. Sci. Transl. Med. 6, 248ra106–248ra106 (2014).
Strauli, N. B. & Hernandez, R. D. Statistical inference of a convergent antibody repertoire response to influenza vaccine. Genome Med. 8, 60 (2016).
Roskin, K. M. et al. IgH sequences in common variable immune deficiency reveal altered B cell development and selection. Sci. Transl. Med. 7, 302ra135 (2015).
Massart, A., Ghisdal, L., Abramowicz, M. & Abramowicz, D. Operational tolerance in kidney transplantation and associated biomarkers. Clin. Exp. Immunol. 189, 138–157 (2017).
Beausang, J. F. et al. B cell repertoires in HLA-sensitized kidney transplant candidates undergoing desensitization therapy. J. Transl. Med. 15, 9 (2017).
Ferdman, J. et al. Expansion and somatic hypermutation of B-cell clones in rejected human kidney grafts. Transplantation 98, 766–772 (2014).
Vollmers, C. et al. Monitoring pharmacologically induced immunosuppression by immune repertoire sequencing to detect acute allograft rejection in heart transplant patients: A Proof-of-Concept Diagnostic Accuracy Study. PLOS Med. 12, e1001890 (2015).
Solez, K. et al. Banff ’05 Meeting Report: Differential diagnosis of chronic allograft injury and elimination of chronic allograft nephropathy (CAN). Am. J. Transplant. 7, 518–526 (2007).
Solez, K. et al. Banff 07 classification of renal allograft pathology: Updates and future directions. Am. J. Transplant. 8, 753–760 (2008).
Chaudhuri, A. et al. The clinical impact of humoral immunity in pediatric renal transplantation. J. Am. Soc. Nephrol. 24, 655–664 (2013).
Rajab, A., Pelletier, R. P., Henry, M. L. & Ferguson, R. M. Excellent clinical outcomes in primary kidney transplant recipients treated with steroid-free maintenance immunosuppression. Clin. Transplant. 20, 537–546 (2006).
Luan, F. L., Steffick, D. E. & Ojo, A. O. Steroid-free maintenance immunosuppression in kidney transplantation: is it time to consider it as a standard therapy? Kidney Int. 76, 825–830 (2009).
Legendre, C. et al. Three-year outcomes in kidney transplant patients randomized to steroid-free immunosuppression or steroid withdrawal, with enteric-coated mycophenolate sodium and cyclosporine: the infinity study. J. Transplant. 2014, 1–8 (2014).
Kaplinsky, J. & Arnaout, R. Robust estimates of overall immune-repertoire diversity from high-throughput measurements on samples. Nat. Commun. 7, 11881 (2016).
Stern, J. N. H. et al. B cells populating the multiple sclerosis brain mature in the draining cervical lymph nodes. Sci. Transl. Med. 6, 248ra107 (2014).
Bashford-Rogers, R. J. M. et al. Network properties derived from deep sequencing of human B-cell receptor repertoires delineate B-cell populations. Genome Res. 23, 1874–1884 (2013).
Sarwal, M. et al. Molecular heterogeneity in acute renal allograft rejection identified by DNA microarray profiling. N. Engl. J. Med. 349, 125–138 (2003).
Zarkhin, V., Lovelace, P. A., Li, L., Hsieh, S. -C. & Sarwal, M. M. Phenotypic Evaluation of b-cell subsets after rituximab for treatment of acute renal allograft rejection in pediatric recipients. Transplantation 91, 1010–1018 (2011).
Clatworthy, M. R. & Targeting, B. Cells and antibody in transplantation. Am. J. Transplant. 11, 1359–1367 (2011).
Dijke, E. I. et al. B cells in transplantation. J. Heart Lung Transplant. 35, 704–710 (2016).
Nankivell, B. J. & Kuypers, D. R. Diagnosis and prevention of chronic kidney allograft loss. Lancet 378, 1428–1437 (2011).
Patin, E. et al. Natural variation in the parameters of innate immune cells is preferentially driven by genetic factors. Nat. Immunol. 19, 302–314 (2018).
Liston, A. & Goris, A. The origins of diversity in human immunity. Nat. Immunol. 19, 209–210 (2018).
Meier-Kriesche, H. -U., Schold, J. D., Srinivas, T. R. & Kaplan, B. Lack of improvement in renal allograft survival despite a marked decrease in acute rejection rates over the most recent era. Am. J. Transplant. 4, 378–383 (2004).
Keith, D. S., Vranic, G. & Nishio-Lucar, A. Graft function and intermediate-term outcomes of kidney transplants improved in the last decade: Analysis of the United States kidney transplant database. Transplant. direct 3, e166 (2017).
Bomben, R. et al. Expression of mutated IGHV3-23 genes in chronic lymphocytic leukemia identifies a disease subset with peculiar clinical and biological features. Clin. Cancer Res. 16, 620–628 (2010).
Levinson, A. I., Kozlowski, L., Zheng, Y. & Wheatley, L. B-cell superantigens: definition and potential impact on the immune response. J. Clin. Immunol. 15, 26S–36S (1995).
Silverman, G. J. & Goodyear, C. S. A model B-Cell superantigen and the immunobiology of B lymphocytes. Clin. Immunol. 102, 117–134 (2002).
Silverman, G. J. & Goodyear, C. S. Confounding B-cell defences: lessons from a staphylococcal superantigen. Nat. Rev. Immunol. 6, 465–475 (2006).
Cheng, J. et al. Ectopic B-cell clusters that infiltrate transplanted human kidneys are clonal. Proc. Natl Acad. Sci. 108, 5560–5565 (2011).
Grover, R. K. et al. The costimulatory immunogen LPS induces the B-Cell clones that infiltrate transplanted human kidneys. Proc. Natl Acad. Sci. USA 109, 6036–6041 (2012).
Modena, B. D. et al. Changes in urinary microbiome populations correlate in kidney transplants with interstitial fibrosis and tubular atrophy documented in early surveillance biopsies. Am. J. Transpl. 17, 712–723 (2017).
Chen, K. & Cerutti, A. New insights into the enigma of immunoglobulin D. Immunol. Rev. 237, 160–179 (2010).
Chen, K. et al. Immunoglobulin D enhances immune surveillance by activating antimicrobial, proinflammatory and B cell-stimulating programs in basophils. Nat. Immunol. 10, 889–898 (2009).
Mack, M. & Rosenkranz, A. R. Basophils and mast cells in renal injury. Kidney Int. 76, 1142–1147 (2009).
Nixon, D. F. et al. Molecular tracking of an human immunodeficiency virus nef specific cytotoxic T-cell clone shows persistence of clone-specific T-cell receptor DNA but not mRNA following early combination antiretroviral therapy. Immunol. Lett. 66, 219–228 (1999).
Dharnidharka, V. R., Fiorina, P. & Harmon, W. E. Kidney transplantation in children. N. Engl. J. Med. 371, 549–558 (2014).
Sarwal, M. M. et al. Complete steroid avoidance is effective and safe in children with renal transplants: A multicenter randomized trial with three-year follow-up. Am. J. Transplant. 12, 2719–2729 (2012).
Li, L. et al. Steroid-free immunosuppression since 1999: 129 pediatric renal transplants with sustained graft and patient benefits. Am. J. Transpl. 9, 1362–1372 (2009).
van Dongen, J. J. M. et al. Design and standardization of PCR primers and protocols for detection of clonal immunoglobulin and T-cell receptor gene recombinations in suspect lymphoproliferations: Report of the BIOMED-2 Concerted Action BMH4-CT98-3936. Leukemia 17, 2257–2317 (2003).
Beaulieu, M., Larson, G. P., Geller, L., Flanagan, S. D. & Krontiris, T. G. PCR candidate region mismatch scanning: adaptation to quantitative, high-throughput genotyping. Nucl. Acids Res. 29, 1114–1124 (2001).
Boyd, S. D. et al. Measurement and clinical monitoring of human lymphocyte clonality by massively parallel VDJ pyrosequencing. Sci. Transl. Med. 1, 12ra23 (2009).
Mag, T. & Salzberg, S. L. FLASH: fast length adjustment of short reads to improve genome assemblies. Bioinformatics 27, 2957–296310 (2011).
Ye, J., Ma, N., Madden, T. L. & Ostell, J. M. IgBLAST: an immunoglobulin variable domain sequence analysis tool. Nucl. Acids Res. 41, W34–W40 (2013).
Acknowledgements
We thank Scott Boyd and Krishna Roskin from the Boyd’s lab for generating the data and contributing in the discussion of the data. We thank Mikel San Vicente, senior software engineer, for his contribution with the coding to define the clones and perform the network visualization. We acknowledge funding support from U01AI113362-01 (M.M.S) and P30AR070155 (M.S.). M.S. is supported by K01P0511836.
Author information
Authors and Affiliations
Contributions
M.M.S., M.S. and S.P. conceived the study design and analysis plan. M.S., M.M.S. and S.P. carried out the bioinformatics/data analysis plan. S.P. performed the data analysis and generated all figures and tables. J.M.L., F.V., T.K.S. and M.M.S. collected and analyzed clinical materials. M.S. and M.M.S. supervised the work.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Journal peer review information: Nature Communications thanks the anonymous reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Source Data
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Pineda, S., Sigdel, T.K., Liberto, J.M. et al. Characterizing pre-transplant and post-transplant kidney rejection risk by B cell immune repertoire sequencing. Nat Commun 10, 1906 (2019). https://doi.org/10.1038/s41467-019-09930-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-019-09930-3
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
