
Abstract
A skullcap found in the Salkhit Valley in northeast Mongolia is, to our knowledge, the only Pleistocene hominin fossil found in the country. It was initially described as an individual with possible archaic affinities, but its ancestry has been debated since the discovery. Here, we determine the age of the Salkhit skull by compound-specific radiocarbon dating of hydroxyproline to 34,950–33,900 Cal. BP (at 95% probability), placing the Salkhit individual in the Early Upper Paleolithic period. We reconstruct the complete mitochondrial genome (mtDNA) of the specimen. It falls within a group of modern human mtDNAs (haplogroup N) that is widespread in Eurasia today. The results now place the specimen into its proper chronometric and biological context and allow us to begin integrating it with other evidence for the human occupation of this region during the Paleolithic, as well as wider Pleistocene sequences across Eurasia.
Similar content being viewed by others
Introduction
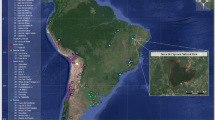
Mongolia has been a focus of attention for researchers interested in human origins for more than a century and substantial advances in the understanding of the Mongolian Paleolithic have been made in the last few decades1. The discovery of Paleolithic remains is, however, still mainly limited to restricted areas in the centre part of the country (Fig. 1, Supplementary Table 1). In addition to surface surveys, recent excavations revealed aspects of the Paleolithic occupation of the region, enabling archaeologists to begin integrating the Mongolian Paleolithic with other Pleistocene sequences across Eurasia. In congruence with the neighbouring regions of southern Siberia and the Siberian Altai, the Upper Paleolithic in Mongolia has been divided into three phases: Early, Middle and Late Upper Paleolithic. In contrast with the Lower and Middle Paleolithic, which are characterized by few sites, the start of the Upper Paleolithic is relatively well defined by the presumably persistence of earlier Mousterian or Levallois industries and the appearance of blade production in Northern Mongolia, mirroring the southern Siberian record2. The Early Upper Paleolithic (EUP) is usually subdivided into two phases. The first, spanning from 40,000 BP to 35,000 BP, includes the site of Rashaan Khad, which is about 150 km SW from Salkhit (dated at 39,100 ± 1000 BP (OxA-34324))3. The second, represented by assemblages from the Khangai Mountains and the Gobi Altai district, covers the period between 33,000 BP and 26,000 BP1,4,5. The Mousterian or Levallois elements disappear with the Middle Upper Paleolithic (MUP) in Mongolia. MUP sites have been identified only in the Orkhon River valley and are younger than ca. 25,000 BP1. Finally, the later phase of the Mongolian Upper Paleolithic (LUP) is characterized by microliths and lasts until the end of the Pleistocene1,2,3.

Map showing Upper Paleolithic sites in Mongolia. 1—Tolbor sites, 2—Dörölj, 3—Orkhon sites, 4—Chickhen sites, 5—Tsagaan Agui, 6—Rashaan Khad and 7—Salkhit. Chronometric data for these sites is listed in Supplementary Table 1. Blocks on scale bars represent 100 km
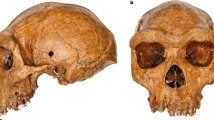
The skullcap analysed in this study was discovered in 2006 during mining operations in the Salkhit Valley of the Norovlin county in the Khentii province, eastern Mongolia (48°16′17.9″ N and 112°21′37.9″ E). It is, so far, the only Pleistocene human fossil found in the country. Subsequent investigations around the find-spot did not yield additional fossil remains. The skullcap has a mostly complete frontal as well as two partially complete parietal and nasal bones. Ages suggested for the specimen range from the Early Middle Pleistocene to the terminal Late Pleistocene. The presence of archaic features has led to a potential affiliation to an uncharacterized archaic hominin species. The specimen was thus initially referred to as Mongolanthropus6. The comparison of the dimensions of the skullcap with reference skullcaps by multidimensional scaling analysis showed similarities with Neanderthals, Homo erectus and Asian archaic Homo sapiens7. Based on the published photographs, Kaifu and Fujita8 suggested that the Salkhit specimen belongs to a terminal Pleistocene modern human. Additional comparisons with Middle and Late Pleistocene hominin fossils from northeast Asia (Zhoukoudian Locality 1, Dali, and Zhoukoudian Upper Cave) concluded that the peculiar features of the Salkhit skull are more likely to be regionally predominant modern human features than diagnostic features of an archaic species9,10.
Because of the dearth of hominin fossils recovered in Mongolia, the Salkhit skull represents a unique opportunity to investigate the types of humans that occupied the region during the Pleistocene. Here, we present the results of both chronometric and genetic analyses of the Salkhit specimen. This fossil dates to approximately 34–35 thousand years ago and its mitochondrial genome is of Eurasian modern human type.
Results and Discussion
Fossil specimen
Since its discovery in 2006, the Salkhit fossil (Reference number: 2006-4) has been kept at the Institute of History and Archaeology (formerly, Institute of Archaeology), Mongolian Academy of Sciences, in Ulaanbaatar. The specimen was sampled for radiocarbon and genetic analyses in four locations (B, C, D and E, Fig. 2) in the internal part of the skull at the posterior tip next to an area that had been sampled prior to this study (A, Fig. 2). In total, ~1 g of bone was sampled.

The Salkhit skullcap. In norma frontalis (1), in norma basilaris showing the first sampling for dating A (2) and the areas of sampling B, C, D and E (3) for genetic analyses and compound-specific radiocarbon dating. Blocks on scale bars represent 1 cm
AMS dating
The Salkhit skull (Sample A, Fig. 2) was previously dated to 22,105 ± 45 BP by the Beta Analytic Inc. radiocarbon laboratory (Miami, Florida, USA), but this result has never been formally reported11. Unfortunately, no information is available about the sample preparation methods that had been applied. Another fraction of the same sample A was also dated at the Oxford Radiocarbon Accelerator Unit (ORAU) in 2010. It was pre-treated following the routine procedure comprising decalcification, base wash, reacidification, gelatinisation and ultrafiltration steps (Coded ‘AF’ in the ORAU), as described by Brock et al.12. It produced a date of 23,630 ± 160 BP (Table 1). The C:N atomic ratio of carbon to nitrogen for the extracted collagen was 3.5. Even though this value falls within a range of C:N values [2.9–3.5] that passes the quality control criteria of most radiocarbon facilities, the value is relatively high and could indicate that some of the contamination was not entirely removed from the sample. We therefore decided to re-date the skullcap using a compound-specific approach13. The higher efficiency of this method in removing contaminants from heavily contaminated samples and its ability to provide accurate 14C measurements has been demonstrated in several recent cases involving Paleolithic sites in France14, Croatia15, Russia16,17,18,19,20,21, and the Americas22,23.
A new bone sample was obtained and after extraction, the collagen was hydrolyzed and the amino acid hydroxyproline was isolated using preparative High Performance Liquid Chromatography (Prep-HPLC). The hydroxyproline was combusted, graphitised, and measured by AMS, producing a date of 30,430 ± 300 BP (OxA-X-2717-25). The C:N atomic ratio measured was 5.0, corresponding to the expected theoretical value for hydroxyproline (C5H9NO3) and indicating the absence of contamination in the sample after the Prep-HPLC treatment. The date were calibrated using OxCal 4.324 and the INTCAL13 calibration curve25, yielding an age range of 34,950–33,900 Cal BP (at 95% probability) (Table 1, Fig. 3). This is significantly older than the two dates obtained previously. Such differences have been observed before in cases where bones were heavily contaminated with conservation agents, indicating that the standard chemical pretreatment12 is sometimes not efficient enough to remove all high molecular-weight contamination that is present in a sample and sometimes even cross-linked to the collagen. The contamination was confirmed by additional chemical investigations using Pyrolysis Gas Chromatography coupled with Mass Spectrometry (Py-GC/MS). They revealed the presence of a silicone-based contaminant in the Salkhit bone probably used to make the endocast (Fig. 4)7. The hydrolysis of the collagen and isolation of the amino acid hydroxyproline obviated this problem.


Py-GC/MS characterization. Blue profile—Pyrogram obtained on 450 µg of the Salkhit bone; Black profile—Pyrogram obtained on 220 µg of an uncontaminated bone (Latton, UK) used as a standard at the ORAU. The main compounds identified in both profiles are pyrolytic products of collagen51,52. The profile of the Salkhit sample also shows the presence of 3 compounds with siloxane structure (red arrows) that are reported as pyrolysis products of silicone53 leading to assess the residual presence of such material within the bone matrix
DNA extraction and mtDNA enrichment
DNA was extracted from 30.9, 27.0 and 33.1 mg of powder removed from the sampling spots B, C and D, respectively (Fig. 2)26. Aliquots of the extracts were converted to single-stranded libraries27 and enriched for human mtDNA fragments using a present-day human mtDNA probe set28. The enriched library molecules were sequenced from both ends. Overlapping paired-end reads were merged to reconstruct full-length molecules sequences, which were then mapped to the revised Cambridge reference sequence of the human mitochondrial genome (rCRS, GenBank acc. no. NC_0120920). After discarding sequences shorter than 35 base pairs (bp) and fusing sequences with identical start and end coordinates, 264,884 unique mtDNA fragments remained (Table 2).
To assess whether or not molecules of ancient origin were present, we estimated the frequencies of cytosine (C) to thymine (T) mismatches along the sequences relative to the reference sequence. Such mismatches result from deamination of C residues in ancient DNA, particularly towards the ends of molecules29. The C to T mismatch frequencies ranged from 34.9% to 41.6% at the first (5’) position and from 20.6% to 25.7% at the last (3’) position of the sequences, respectively (Table 2) (Supplementary Fig. 1), with the library yielding the largest number of mitochondrial sequences exhibiting the lowest terminal C to T mismatch frequencies. The differences among the libraries suggest that, in addition to endogenous ancient DNA molecules, contaminating present-day human mtDNA molecules were extracted and incorporated in the libraries. This is further supported by the observation that DNA fragments that carry C to T mismatches at one end have higher frequencies of C to T mismatch at the other end than when all DNA fragments are considered (Table 2) (Supplementary Table 2)30. We conclude that the DNA libraries contain authentic ancient molecules carrying terminal C to T mismatches as well as present-day contaminating DNA molecules.
Contamination and Salkhit mtDNA consensus sequence
To reduce the impact of cytosine deamination on the reconstruction of the mitochondrial genome, we masked T bases at the first and last three positions of each mtDNA fragment before aligning them to the rCRS reference human mitochondrial genome. The estimation of present-day human contamination in each library relied on two positions (pos. 10,364 and pos. 14,578 in the rCRS reference genome) where the Salkhit mtDNA genome sequence differs from a worldwide panel of 311 present-day human mtDNA genomes. The proportions of sequences covering both positions and not matching the Salkhit-specific state are 19.6%, 35.2% and 42.6% for the libraries made out the extracts B, C and D, respectively (Table 2).
Because of the high level of contamination of the specimen, we called the Salkhit mtDNA consensus using only the 38,024 mtDNA fragments carrying C to T mismatches to the human reference mtDNA in one of their three first or three last positions recovered from the three DNA libraries. This significantly lowers the amount of modern human contaminating sequences and reduces any potential bias for contaminating molecules resulting from the use of modern human capture baits and reference sequence for mapping. The consensus was called for 16,567 positions, out of 16,569, where at least 80% of the fragments supported the same base (Supplementary Fig. 2) with an average coverage of 123 DNA fragments per nucleotide position. One of the two missing positions was in a C-homopolymer stretch (pos. 295–320), which after visual inspection was manually corrected, while the other (pos. 16,093) is covered by 117 fragments from which 88 carry a C while 29 carry a T (Supplementary Fig. 2). This observation might reflect heteroplasmy and was left uncalled.
For the alignments of deaminated fragments only, we estimated the level of contamination to 4.1%, 1.6% and 3.7% for libraries made from extracts B, C and D, respectively (Table 2). Given the coverage of the genome, this level of contamination is not expected to affect the accuracy of the consensus sequence.
MtDNA phylogeny and dating
The Salkhit mtDNA lineage was assigned to the modern human macro-haplogroup N using HaploGrep231 (based on mtDNA tree Build 1732). Haplogroup N and M are the two basal mtDNA haplogroups shared among all present-day non-Africans. While the mosaic of archaic-like and modern human-like morphological traits have made the assignment of the fossil to Pleistocene hominin groups difficult, we thus show that the mtDNA of the Salkhit individual is of modern human origin. However, the sequence does not carry any substitutions characteristic of known sub-haplogroups inside the haplogroup N. A maximum parsimony analysis (subtree Fig. 5) assigns the Salkhit mtDNA to an uncharacterized lineage which branches off the root of haplogroup N. It is therefore unlikely that the Salkhit mitochondrial lineage is directly ancestral to any present-day human mtDNA. Among ancient modern humans, only the mtDNA of the ~40,000-year-old Romanian Oase 1 individual33 falls outside the known sub-lineages of N or M, suggesting the existence of more mtDNA diversity among early modern humans in Eurasia than among later and present-day Eurasian populations.

Maximum parsimony phylogeny relating the Salkhit mtDNA to ancient and present-day human mtDNAs. a Subtree of the N haplogroup (Hg) phylogeny structure extracted from a global tree including all the mtDNAs diversity found in ancient and present-day anatomically modern human (Supplementary Fig. 3). The tree was obtained in MEGA6 (30, 31) and is #1 out of 3 most parsimonious trees putting in a phylogenetic network 58 ancient and 55 present-day modern human mtDNA including the Salkhit sequence. The mtDNA sequence of a Neanderthal from Altai is used as outgroup. The percentage of replicate trees in which the associated taxa clustered together in the bootstrap test (1000 replicates) are shown next to the branches. b Diagnostic positions of the N haplogroup and positions of the substitutions accumulated in the Salkhit mtDNA since its divergence from the common ancestor of the N haplogroup, indicated along the branch, are obtained using mtPhyl (https://sites.google.com/site/mtphyl/home)
The maximum parsimony tree (Fig. 5) suggests that the Salkhit mtDNA accumulated 10 substitutions since its divergence from its closest relatives in the N haplogroup. Using a mtDNA mutation rate of 2.67 × 10−8 substitution per site per year34, we estimate that the Salkhit mtDNA diverged from the root of the N haplogroup 19,000 to 28,000 years (95% HPD) before the Salkhit individual lived. Considering the reported divergence time of the N haplogroup between 70 and 50 ka ago35,36,37, this estimate is compatible with the calibrated radiocarbon date.
We also estimated the age of the Salkhit specimen mtDNA using a Bayesian method implemented in BEAST38 and 58 mtDNA sequences from archaeologically dated specimens as calibration points (Supplementary Table 3). Applying a strict clock and the mutation rate above we obtain a date between 12,910 and 39,410 years BP (95% HPD) with a median of 26,600 years BP, supported by a Bayesian inference of phylogeny tree (Supplementary Fig. 4). This date is consistent with the calibrated radiocarbon date as well as with the molecular date inferred from the number of private substitutions accumulated in the Salkhit mtDNA since its divergence from the root of the N haplogroup.
Conclusions
The morphological traits of the Salkhit skullcap have fueled the debate about the origins of the prehistoric humans of the region, where it is, to our knowledge, the only Pleistocene human fossil discovered. The complete mtDNA sequence reconstructed from the Salkhit skull falls within the variation of modern human mtDNAs, showing that the maternal lineage of the specimen is of modern human ancestry. The compound-specific radiocarbon date shows that the previous dates of 22 and 23 ka BP were too young. This is due to the presence of a silicon-based contaminant that could not be removed with other pretreatments. It is now clear that the Salkhit individual belongs within the EUP in Mongolia. Based on this new chronological evidence and its location, we hypothesize that the Salkhit individual, although found without any archaeological context, may have been familiar with the Levallois-like technology and blade production industry of the EUP found in Northern Mongolia and in Southern Siberia.
Methods
Radiocarbon dating
Two different methods were used to prepare the samples for AMS dating. First, samples were pre-treated following the routine procedure at the Oxford Radiocarbon Accelerator Unit (ORAU) comprising a decalcification, base wash, reacidification, gelatinisation and ultrafiltration (Coded ‘AF’ in the ORAU)12. The second sample taken from the skullcap was dated using the single amino acid radiocarbon dating method optimized at the ORAU13. This method involves separation of the underivatised amino acids from hydrolyzed bone collagen samples using preparative High Performance Liquid Chromatography (Prep-HPLC). The amino acid hydroxyproline is isolated by Prep-HPLC, combusted, graphitized and AMS dated. This pretreatment approach (Coded ‘HYP’ in the ORAU) is the most efficient technique to remove contaminants including, but not limited to, conservation materials (unless collagen-based glue has been applied). The %C, %N and atomic C/N ratio were measured using an automated carbon and nitrogen elemental analyzer (Carlo Erba EA1108) coupled with a continuous-flow isotope monitoring mass spectrometer (Europa Geo 20/20).
DNA sampling, extraction and mtDNA sequence determination
After the removal of approximately 1 mm of surface material using a sterile dentistry drill, which was performed to reduce present-day human DNA contamination, the sampling for DNA analyses was carried out in areas B, C and D (Fig. 2). DNA was extracted from 30.9 mg, 33.1 mg and 27 mg, respectively, using a silica-based protocol optimized for the recovery of short molecules from ancient material26. An extraction blank was also carried through each step of DNA extraction. Ten microliters of each extract (of a total of 50 µL) were converted into a single-stranded DNA library as described elsewhere27 using an automated liquid handling platform39. One positive and one negative control were included during library preparation40. No uracil-DNA glycosylase treatment was performed. After amplification with a pair of primers carrying unique index sequences41 and quantification using a NanoDrop ND-1000 (NanoDrop Technologies) photospectrometer, 1 µg of each sample library and the blank library were enriched for mtDNA using present-day human mtDNA probes (in 1-bp tiling density) as described28,34. Before sequencing, libraries were amplified in a one-cycle-PCR using Herculase II Fusion DNA polymerase (Agilent)42 with primers IS5 and IS643 to remove heteroduplices.
The libraries were pooled and sequenced on a MiSeq (Illumina Inc.) using a paired-end configuration of 76 + 7 cycles for each insert and index read41. Base calling was performed using Bustard (Illumina), and sequences that did not exactly match one of the expected index combinations were discarded. Adapter sequences were trimmed and overlapping paired-end reads merged using leeHom44 before mapping the sequences to the revised Cambridge Reference mitochondrial genome (rCRS, NC_0120920) using the Burrows-Wheeler Aligner (BWA)45 with parameters « -n 0.01 –o 2 –l 16500 »46. Mapped sequences with identical alignment start and end coordinates were collapsed using bam-rmdup (https://bitbucket.org/ustenzel/biohazard). Only overlap-merged sequences of at least 35 base pairs in length were retained for subsequent analyses.
After masking terminal C to T substitutions, a perl script was used to call the consensus mtDNA sequence (based on the «mpileup» command of SAMtools47) requiring a minimum coverage of 5 and a consensus support of at least 80% at each position.
Phylogenetic analyses
The Salkhit mtDNA haplogroup was assigned using Haplogrep31 and mtPhyl5 (https://sites.google.com/site/mtphyl/home) based on the Phylotree database (mtDNA tree Build 17)32. The number of mutations that occurred in the Salkhit mtDNA since its divergence from the root of haplogroup N was inferred by maximum parsimony analysis using mtPhyl.
A multiple sequence alignment of the Salkhit mtDNA sequence to 115 complete mtDNAs of modern humans18,34,36 and one Neandertal mtDNA48 was generated using MAFFT49. We then estimated the molecular age of the Salkhit mtDNA based on its branch length in a Bayesian statistical framework38 as implemented in BEAST250 using the dataset above. We used tip dates of zero for present-day mtDNA sequences and individual fossil dates intervals as priors for the ancient mtDNA sequences (Supplementary Table 3). As determined by jModelTest2, we performed the analyses using a GTR +I+G model for nucleotide substitution with a gamma distributed rates among sites. A strict clock and an uncorrelated lognormal-distributed relaxed clock, both under a constant size population and a Bayesian skyline coalescent tree prior, were tested. To estimate the posterior distribution of each model, we performed two runs of the Markov Chain Monte Carlo (MCMC) algorithm implemented in the Beast software. Each MCMC run was performed with 50,000,000 iterations and sampled every 10,000 generations. After discarding 10% of the sampled iterations as burn-in, the output was analyzed with Tracer v1.5.0 (http://tree.bio.ed.ac.uk/software/tracer/). The effective sample sizes estimate supported the strict clock model over the relaxed clock model, while neither the constant size nor the Bayesian skyline coalescent models were rejected. The age of the Salkhit mtDNA was therefore estimated based on a strict clock model and a Bayesian skyline coalescent model.
Pyrolysis gas chromatography coupled with mass spectrometry
The analyses were performed on an EGA/PY-3030D Micro Furnace Pyrolyzer (Frontier Lab, Japan) connected to a 6890 gas chromatograph equipped with a split/splitless injector. An HP 5MS column (30 m × 0.25 mm, film thickness 0.25 µm, Agilent Technologies, USA) coupled with a deactivated silica pre-column (2 m × 0.32 mm, Agilent Technologies, USA) was used for the chromatographic separation. The program of the oven temperature used for the chromatographic separation was 40 °C isothermal for 6 min followed by a linear ramp at 20 °C/min up to 310 °C. Analyses were performed under a constant flow of helium at 1 mL/min, with a split ratio 1:20. The gas chromatograph was coupled with a 5973 Mass Selective Detector (Agilent Technologies, USA). The MS transfer line temperature was 300 °C. The mass spectrometer was operated in EI positive mode (70 eV, scanning m/z 50-600). The MS ion source was kept at 230 °C and the MS quadrupole at 150 °C.
The two samples, 450 µg of bone powder from the Salkhit skull and 250 µg of an uncontaminated mammoth bone sample from Latton (UK), used as a background standard at the ORAU, were successively placed in a stainless-steel cup and inserted in the micro-furnace where they were pyrolysed at 600 °C for 20 sec.
Reporting summary
Further information on experimental design is available in the Nature Research Reporting Summary linked to this article.
Data availability
The complete mitochondrial DNA sequence of the Salkhit individual is deposited in the European Nucleotide Archive (http://www.ebi.ac.uk/ena) under the accession number PRJEB29760. Other data that support the findings of this study are available from the corresponding authors on reasonable request. A reporting summary for this Article is available as a Supplementary Information file.
References
Gladyshev, S. A., Olsen, J. W., Tabarev, A. V. & Jull, A. J. T. The Upper Paleolithic of Mongolia: Recent finds and new perspectives. Quat. Int. 281, 36–46 (2012).
Zwyns, N., Gladyshev, S., Tabarev, A. & Gunchinsuren, B. in Encyclopedia of Global Archaeology (ed Claire Smith) 5025-5032 (Springer New York, 2014).
Yi, S. Rashaan Khad—An Early Blade Industry in Eastern Mongolia. J. Korean Palaeolithic Soc. 28, 105–129 (2013).
Gladyshev, S. A., Olsen, J. W., Tabarev, A. V. & Kuzmin, Y. V. Chronology and periodization of Upper Paleolithic sites in Mongolia. Archaeol., Ethnol. Anthropol. Eurasia 38, 33–40 (2010).
Derevianko, A. P., Markin, S. V., Gladyshev, S. A. & Olsen, J. W. The Early Upper Paleolithic of the Gobi Altai Region in Mongolia Based on Materials from the Chikhen-2 Site. Archaeol., Ethnol. Anthropol. Eurasia 43, 17–41 (2015).
Tseveendorj, D., Batbold, N. & Amgalantugs, T. Mongolanthropus was discovered in Mongolia. Stud. Archaeol. - Inst. Archaeol. Acad. Sci. Mong. 3, 5–20 (2007).
Coppens, Y., Tseveendorj, D., Demeter, F., Turbat, T. & Giscard, P.-H. Discovery of an archaic Homo sapiens skullcap in Northeast Mongolia. Comptes Rendus Palevol 7, 51–60 (2008).
Kaifu, Y. & Fujita, M. Fossil record of early modern humans in East Asia. Quat. Int. 248, 2–11 (2012).
Lee, S.-H. Homo erectus in Salkhit, Mongolia? HOMO - J. Comp. Human. Biol. 66, 287–298 (2015).
Tseveendorj, D., Gunchinsuren, B., Gelegdorj, E., Yi, S. & Lee, S.-H. Patterns of human evolution in northeast Asia with a particular focus on Salkhit. Quat. Int. 400, 175–179 (2016).
Huet, S. Cro-Magnon ne crâne plus. Liberation, 36-37 (2010).
Brock, F., Higham, T., Ditchfield, P. & Bronk Ramsey, C. Current pretreatment methods for AMS radiocarbon dating at the Oxford Radiocarbon Accelerator Unit (ORAU). Radiocarbon 52, 103–112 (2010).
Devièse, T., Comeskey, D., McCullagh, J., Bronk Ramsey, C. & Higham, T. New protocol for compound specific radiocarbon analysis of archaeological bones. Rapid Commun. Mass Spectrom. 32, 373–379 (2018).
Bourrillon, R. et al. A new Aurignacian engraving from Abri Blanchard, France: Implications for understanding Aurignacian graphic expression in Western and Central Europe. Quat. Int. 491, 46–64 (2018).
Devièse, T. et al. Direct dating of Neanderthal remains from the site of Vindija Cave and implications for the Middle to Upper Paleolithic transition. Proc. Natl Acad. Sci. USA 114, 10606–10611 (2017).
Nalawade-Chavan, S., McCullagh, J. S. O. & Hedges, R. New hydroxyproline radiocarbon dates from Sungir, Russia, confirm early Mid Upper Palaeolithic burials in Eurasia. PLoS One 9, e76896 (2014).
Marom, A., McCullagh, J. S. O., Higham, T. F. G., Sinitsyn, A. A. & Hedges, R. E. M. Single amino acid radiocarbon dating of Upper Paleolithic modern humans. Proc. Natl Acad. Sci. USA 109, 6878–6881 (2012).
Sikora, M. et al. Ancient genomes show social and reproductive behavior of early Upper Paleolithic foragers. Science 358, 659–662 (2017).
Reynolds, N., Dinnis, R., Bessudnov, A., Devièse, T. & Higham, T. The Kostënki 18 child burial and the cultural and funerary landscape of Mid Upper Palaeolithic European Russia. Antiquity 91, 1435–1450 (2017).
Kosintsev, P. et al. Evolution and extinction of the giant rhinoceros Elasmotherium sibiricum sheds light on late Quaternary megafaunal extinctions. Nat. Ecol. Evol. 3, 31–38 (2019).
Dinnis, R. et al. New data for the Early Upper Paleolithic of Kostenki (Russia). J. Hum. Evol. 127, 21–40 (2019).
Becerra-Valdivia, L. et al. Reassessing the chronology of the archaeological site of Anzick. Proc. Natl Acad. Sci. USA 115, 7000–7003 (2018).
Devièse, T. et al. Increasing accuracy for the radiocarbon dating of sites occupied by the first Americans. Quat. Sci. Rev. 198, 171–180 (2018).
Bronk Ramsey, C. Bayesian analysis of radiocarbon dates. Radiocarbon 51, 337–360 (2009).
Reimer, P. J. et al. IntCal13 and Marine13 radiocarbon age calibration curves 0–50,000 years cal BP. Radiocarbon 55, 1869–1887 (2013).
Dabney, J. et al. Complete mitochondrial genome sequence of a Middle Pleistocene cave bear reconstructed from ultrashort DNA fragments. Proc. Natl Acad. Sci. USA 110, 15758–15763 (2013).
Gansauge, M.-T. et al. Single-stranded DNA library preparation from highly degraded DNA using T4 DNA ligase. Nucleic Acids Res. 45, e79–e79 (2017).
Maricic, T., Whitten, M. & Pääbo, S. Multiplexed DNA sequence capture of mitochondrial genomes using PCR products. PLoS One 5, e14004 (2010).
Briggs, A. W. et al. Patterns of damage in genomic DNA sequences from a Neandertal. Proc. Natl Acad. Sci. USA 104, 14616–14621 (2007).
Meyer, M. et al. A mitochondrial genome sequence of a hominin from Sima de los Huesos. Nature 505, 403 (2013).
Weissensteiner, H. et al. HaploGrep 2: mitochondrial haplogroup classification in the era of high-throughput sequencing. Nucleic Acids Res. 44, W58–W63 (2016).
van Oven, M. PhyloTree Build 17: Growing the human mitochondrial DNA tree. Forensic Sci. Int.: Genet. Suppl. Ser. 5, e392–e394 (2015).
Fu, Q. et al. An early modern human from Romania with a recent Neanderthal ancestor. Nature 524, 216–219 (2015).
Fu, Q. et al. A revised timescale for human evolution based on ancient mitochondrial genomes. Curr. Biol. 23, 553–559 (2013).
Behar, D. M. et al. A “Copernican” reassessment of the human mitochondrial DNA tree from its root. Am. J. Hum. Genet. 90, 675–684 (2012).
Posth, C. et al. Pleistocene mitochondrial genomes suggest a single major dispersal of non-Africans and a Late Glacial Population turnover in Europe. Curr. Biol. 26, 827–833 (2016).
Soares, P. et al. Correcting for purifying selection: an improved human mitochondrial molecular clock. Am. J. Hum. Genet. 84, 740–759 (2009).
Shapiro, B. et al. A Bayesian Phylogenetic Method to Estimate Unknown Sequence Ages. Mol. Biol. Evol. 28, 879–887 (2011).
Slon, V. et al. Neandertal and Denisovan DNA from Pleistocene sediments. Science, https://doi.org/10.1126/science.aam9695 (2017).
Gansauge, M.-T. & Meyer, M. Single-stranded DNA library preparation for the sequencing of ancient or damaged DNA. Nat. Protoc. 8, 737–748 (2013).
Kircher, M., Sawyer, S. & Meyer, M. Double indexing overcomes inaccuracies in multiplex sequencing on the Illumina platform. Nucleic Acids Res. 40, e3–e3 (2012).
Dabney, J. & Meyer, M. Length and GC-biases during sequencing library amplification: a comparison of various polymerase-buffer systems with ancient and modern DNA sequencing libraries. Biotechniques 52, 87–94 (2012).
Meyer, M. & Kircher, M. Illumina sequencing library preparation for highly multiplexed target capture and sequencing. Cold Spring Harb. Protoc. 2010, pdb.prot5448 (2010).
Renaud, G., Stenzel, U. & Kelso, J. leeHom: adaptor trimming and merging for Illumina sequencing reads. Nucleic Acids Res. 42, e141–e141 (2014).
Li, H. & Durbin, R. Fast and accurate short read alignment with Burrows–Wheeler transform. Bioinformatics 25, 1754–1760 (2009).
Meyer, M. et al. A high coverage genome sequence from an archaic Denisovan individual. Sci. (New Y., N. Y.) 338, 222–226 (2012).
Li, H. et al. The sequence alignment/map format and SAMtools. Bioinformatics 25, 2078–2079 (2009).
Prufer, K. et al. The complete genome sequence of a Neanderthal from the Altai Mountains. Nature 505, 43–49 (2014).
Katoh, K. & Standley, D. M. MAFFT multiple sequence alignment software version 7: improvements in performance and usability. Mol. Biol. Evol. 30, 772–780 (2013).
Bouckaert, R. et al. BEAST 2: a software platform for bayesian evolutionary analysis. PLoS. Comput. Biol. 10, e1003537 (2014).
Adamiano, A., Fabbri, D., Falini, G. & Giovanna Belcastro, M. A complementary approach using analytical pyrolysis to evaluate collagen degradation and mineral fossilisation in archaeological bones: The case study of Vicenne-Campochiaro necropolis (Italy). J. Anal. Appl. Pyrolysis 100, 173–180 (2013).
Orsini, S., Parlanti, F. & Bonaduce, I. Analytical pyrolysis of proteins in samples from artistic and archaeological objects. J. Anal. Appl. Pyrolysis 124, 643–657 (2017).
Moldoveanu, S. C. in Techniques and Instrumentation in Analytical Chemistry Vol. 25, 657–668 (Elsevier, Amsterdam, The Netherlands, 2005).
Stuiver, M. & Polach, H. A. Discussion: Reporting of C-14 data. Radiocarbon 19, 355–363 (1977).
Coplen Tyler, B. in Pure and Applied Chemistry Vol. 66, 273–276 (IUPAC (INTERNATIONAL UNION OF PURE AND APPLIED CHEMISTRY), Great Britain, 1994).
Acknowledgements
Funding was provided by the Max Planck Society and the European Research Council under the European Union’s Seventh Framework Programme (FP7/2007-2013); ERC grant 324139 PalaeoChron awarded to Professor Tom Higham and ERC grant 694707-100 100 Archaic Genomes awarded to Professor Svante Pääbo. We thank the staff of the Oxford Radiocarbon Accelerator Unit at the University of Oxford for support in the lab, Cosimo Posth at the Max Planck Institute for the Science of Human History (Jena), Martin Sikora and Ashot Margaryan at the Centre for GeoGenetics, University of Copenhagen and Mateja Hajdinjak, Alexandre Huebner, Stéphane Peyrégne, Viviane Slon and Mark Stoneking at the Max Planck Institute for Evolutionary Anthropology, Leipzig for helpful discussions.
Author information
Authors and Affiliations
Contributions
T.D., D.M., D.C., S.N. and B.N. performed the laboratory work. T.D., D.C. and T.H. generated and analyzed the radiocarbon data. D.M., M.M. and S.P. generated and analyzed the genetic data. T.D. and E.R. performed the pyrolysis work and analyzed the data. S.Y. carried out morphological analyses of the fossil. S.Y., D.T., B.G. and J.L. analyzed all archaeological data. T.D and D.M. wrote the manuscript with input from all authors.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Devièse, T., Massilani, D., Yi, S. et al. Compound-specific radiocarbon dating and mitochondrial DNA analysis of the Pleistocene hominin from Salkhit Mongolia. Nat Commun 10, 274 (2019). https://doi.org/10.1038/s41467-018-08018-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-018-08018-8
This article is cited by
-
Luminescence rock surface exposure and burial dating: a review of an innovative new method and its applications in archaeology
Archaeological and Anthropological Sciences (2024)
-
Initial Upper Palaeolithic material culture by 45,000 years ago at Shiyu in northern China
Nature Ecology & Evolution (2024)
-
Denisovans, Neanderthals, and Early Modern Humans: A Review of the Pleistocene Hominin Fossils from the Altai Mountains (Southern Siberia)
Journal of Archaeological Research (2022)
-
The earliest Denisovans and their cultural adaptation
Nature Ecology & Evolution (2021)
-
Radiocarbon dating
Nature Reviews Methods Primers (2021)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
