
Abstract
Plastic deformation of micron-scale crystalline solids exhibits stress-strain curves with significant sample-to-sample variations. It is a pertinent question if this variability is purely random or to some extent predictable. Here we show, by employing machine learning techniques such as regression neural networks and support vector machines that deformation predictability evolves with strain and crystal size. Using data from discrete dislocations dynamics simulations, the machine learning models are trained to infer the mapping from features of the pre-existing dislocation configuration to the stress-strain curves. The predictability vs strain relation is non-monotonic and exhibits a system size effect: larger systems are more predictable. Stochastic deformation avalanches give rise to fundamental limits of deformation predictability for intermediate strains. However, the large-strain deformation dynamics of the samples can be predicted surprisingly well.
Similar content being viewed by others

Introduction
Predicting the behavior of complex, non-linear systems is one of the main challenges of science. Yet, achieving such goals has remained elusive: attempts to forecast phenomena such as earthquakes have so far yielded controversial results at best1. Reasonably accurate prediction of, for instance, the failure time of a solid sample subject to external loads2 or the time of a volcanic eruption3 has been achieved mostly using information available only relatively close in time to the event one is trying to predict. What makes such predictions difficult is that the mapping from various features describing the state of the system to its subsequent behavior tends to be very complicated. This is so due to the non-linear nature of the collective dynamics underlying the time-evolution of the system, as well as the high dimensionality of the feature set characterizing the system’s state. This implies that traditional forecasting methods are typically not able to cope with the ensuing complexity.
Recently, the use of artificial intelligence in general and machine learning (ML) in particular have found novel applications in diverse fields and problems including, for instance, image recognition4, medical diagnosis5, and statistical arbitrage in finance6. A specific variant of machine learning models, artificial neural networks (ANNs), has proven to be particularly useful in discovering meaningful structure in data. Given sufficient amounts of training data, such models, or regression neural networks, are capable of learning complex, non-linear mappings from a high-dimensional feature vector to a desired output. This property makes these models useful to solve novel kinds of problems also in fields such as physics and materials science7,8,9,10,11,12,13, and related activities have very recently gained significant momentum14.
It is experimentally well-established that micron-scale crystals deform plastically via a sequence of broadly distributed strain bursts, directly visible as steps in the staircase-like stress-strain curve15,16,17,18,19. The apparently stochastic nature of the deformation bursts—typically characterized by power-law-like size distributions—results in significant sample-to-sample variability of the stress-strain response. On the other hand, the dynamics of dislocations—the topological defects of the crystal lattice the motion of which mediates the plastic deformation process—should be largely deterministic: in the first approximation, their motion obeys a deterministic mobility law relating the Peach–Koehler force to the instantaneous dislocation velocity20. Thus, the details of the deformation process of a given sample are in principle encoded in the features of the initial state, i.e., the pre-existing dislocation network within the crystal. Given a complete characterization of the initial dislocation configuration, the dynamics can be solved from the deterministic equations of motion of the dislocations. The key issues then become to what extent more coarse-grained descriptors of the initial states are sufficient to predict the subsequent bursty deformation dynamics, and what is the role of the apparently stochastic strain bursts on deformation predictability.
Here, we study deformation predictability by applying ML methods able to learn the mapping from features of the pre-existing dislocation microstructure to the ensuing stress-strain curves, using 2D discrete dislocation dynamics (DDD) simulations as a test system. In short, our results show that using a number of physically motivated features to describe the initial states gives rise to robust predictability of the deformation process, the degree of which depends on both the strain level and the system size. We analyze the reasons behind these dependencies, and find that they originate on one hand from the properties of the largely stochastic deformation bursts, and on the other from the predictive power of various descriptors of the initial state evolving with the system size. We also discuss how our results open the door to experimental work on deformation predictability and optimization of mechanical properties of materials.
Results
Machine learning plastic deformation
To study deformation predictability in a simple dislocation system, we start by generating an extensive database of stress-strain curves and the corresponding initial dislocation configurations from 2D DDD simulations (Methods); such a simple model is known to be able to capture the statistics of the strain bursts and hence the fluctuating character of the stress-strain curve21. We then train a regression neural network, as well as a support vector machine (Supplementary Note 1 and Supplementary Fig. 1), to infer the mapping from features characterizing the initial dislocation microstructure to the ensuing stress-strain curve. We then study the predictive ability of the model as a function of strain ε and the system size. For each realization of the simulation, a randomly generated configuration of N dislocations with a zero net Burgers vector (a topological charge of the dislocations) is let to relax in zero external stress, after which the external stress is increased quasistatically (Methods). During this ramp-up of the applied stress, the stress-strain curve characterizing the deformation process is recorded, see Fig. 1 for examples; in what follows, this is labeled as the basic scenario. To address the role of the preparation of the initial state on deformation predictability, we also perform a set of simulations where the initial states have been obtained by first deforming the basic samples up to a pre-determined strain of εID = 0.2 (also intermediate pre-strain values were studied), followed by another relaxation in zero stress; these are referred to as ID (initial deformation) systems. The training, validation and test data sets then consist of a number of features characterizing the initial states with (ID) or without (basic) pre-deformation, as well as of the unique stress-strain curve for each sample. We have tested a large number of physically motivated features. The most important ones in terms of predictive power turn out to be statistical measures of the internal stress field and especially densities of geometrically necessary dislocations (GND)22 (Methods).

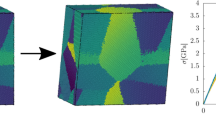
Machine learning plastic deformation. Using features of the initial dislocation configuration (a) (with red and blue symbols corresponding to positive and negative Burgers vectors, respectively), such as the density of geometrically necessary dislocations (depicted in (b), with red and blue corresponding to positive and negative values of ρGND, respectively) or the internal stress field (in (c), orange corresponding to positive and purple to negative σsf), and considering as initial states relaxed random configurations (basic, with the dislocation pair correlation function in (d)), as well as pre-deformed dislocation configurations (ID, (e)), we train a neural network (a schematic is shown in (f)) to infer the relation between features of the initial dislocation configurations and the ensuing stress-strain curves. Examples of the true (solid lines) and predicted (dashed lines) curves for a few basic samples, along with the average (thick black line) and standard deviation (shaded region) of the true stress-strain curves are shown in (g). All the figures are from systems with 400 initial dislocations
Deformation predictability
Once trained, we proceed to analyze the predictive ability of the regression neural network as a function of strain ε, using the standard methodology of evaluating the trained network on a test data set23 (see also Supplementary Note 1). The performance of the neural network may be quantified by considering the score S, defined as \(S = 1 - \left[ {\mathop {\sum}\nolimits_{{i}} (d_{{i}} - y_{{i}})^2} \right]/\left[ {\mathop {\sum}\nolimits_i (d_{{i}} - \langle d_{{i}}\rangle )^2} \right]\), where di and yi are the desired output (i.e., the stress at certain strain) and network output corresponding to the ith test system, respectively; S = 1 would correspond to a perfect fit, and the smaller the S-value the worse the fit. Notice that using the average stress-strain curve as a benchmark prediction would correspond to S = 0. Figure 2a, b show S as a function of ε considering the basic and ID scenarios, with the stress σID needed to reach a fixed pre-deformation strain as an additional feature in the latter case. The data shown in Fig. 2 reveals three main observations: first, we notice that the predictive ability S of the ANN is generally larger for the ID samples. For instance, considering the largest system size N = 400, S(ε = 0.1) increases from 0.44 in the case of the basic systems to 0.69 for ID systems. The second key result to notice is that S exhibits a clear non-monotonic dependence on ε, such that it initially decreases up to a characteristic strain ε* in the range between 0.02–0.03. Surprisingly, for larger ε, S starts to increase again. As the final observation, the large-strain predictability displays a non-trivial size effect. In the basic scenario, the effect is monotonic and the score of the largest system is far better than the corresponding score of the smallest system. The largest ID systems have the largest S, but for smaller N the size dependency becomes non-monotonic. Considering a support vector machine instead of ANN leads to almost identical S(ε) curves, verifying the general nature of our results (Supplementary Fig. 2).

Predictability of the stress-strain curves: large systems are more predictable for larger strains. Score S of the ANN prediction as a function of strain ε for basic (no pre-strain, (a)) and ID (with a pre-strain of 0.2, (b)) systems of different sizes. The insets show example scatter plots of the predicted vs simulated stress values for N = 400 systems at ε = 0.1
Pre-deformation improves deformation predictability
Starting from the difference between the predictability of the basic and ID systems, we attribute this observation to the fact that pre-deformation leads to formation of dislocation structures, resulting in more clear-cut features and hence better predictability. Predictability of ID systems is better especially for large strains (ε > ε*), with the increase of S with ε for ε > ε* significantly more pronounced than in the basic case. The difference in the initial structures is evident in the average pair correlation function \(d(x,y) = \left\langle {\mathop {\sum}\nolimits_{{i}} \rho _{{i}}(x,y)/\rho _0} \right\rangle - 1\), where ρ0 is the average dislocation density and ρi(x, y) is the dislocation density at position (x, y) relative to dislocation i (Fig. 1d, e). d(x, y) shows stronger correlation characteristic to these systems in the ID case: dislocation walls and dipoles are more noticeable24.
Figure 3 emphasizes this in the case of the largest system considered (N = 400), by illustrating how the dislocation pair correlations decay along the dislocation walls (y-direction) for systems with different amounts of pre-strain. The correlation function d(0, y) of all dislocations is shown in Fig. 3a, while the correlation function of positive dislocations d++(0, y) is displayed in Fig. 3b. The general observation is that the larger the pre-strain, the stronger the correlations, and correspondingly, the more correlated systems become more predictable towards the end of the simulation. We quantify this by power-law fits of the form of d(0, y) = αy−β. For the correlation function d(0, y) of all dislocations, we find a pre-strain dependent power-law exponent β, see Fig. 3a. The inset of Fig. 3a shows that the average prediction score in the strain range ε ∈ [0.15,0.2] decreases with increasing β (i.e., faster decay of the correlation function). The corresponding correlation functions of positive dislocations, d++(0, y), exhibit a power-law decay with an exponent β close to 1.5, in agreement with previous results25,26 (see Fig. 3b). In this case the amplitude α of the power-law fit d++(0, y) = αy−β increases with the imposed pre-strain, and can be used as an alternative way to quantify correlations. The inset of Fig. 3b shows that large-strain predictability improves with increasing α, and hence with the correlations. We also note that the exponent β of the correlation function d(0, y) of all dislocations appears to approach the value 1.5 from above as the amount of pre-strain is increased, possibly due to the wall-like structures within the system being increasingly composed of dislocations of the same sign. Interestingly, the observed effect of the pre-strain on predictability is monotonic only in the large strain regime (Supplementary Figs. 3 and 4). This arises due to two competing phenomena, namely the dislocation structures introduced by the initial deformation and the non-monotonic strain dependence discussed below.

Dislocation correlations and predictability. a Average pair correlation functions d(0, y) of initial dislocation configurations along the y-direction for N = 400 obtained with varying amount of pre-strain (See Fig. 1d,e for the full d(x, y) in basic and ID systems, respectively). With larger pre-strain the correlations, i.e., dislocation walls, become larger. The colored solid lines show fits of the form of d(0, y) = αy−β and the black solid line illustrates ∝y−1.5 for reference25,26. The inset shows that smaller β implies better predictability with large strains as the average score in the range ε ∈ [0.15, 0.2] (for full curves see Supplementary Fig. 3) decreases with growing β. b The correlation functions d++(0, y) of positive dislocations with similar power-law fits. Now β is close to 1.5 so the pre-factor α versus the average score is plotted in the inset
Predictability and avalanche activity
We then proceed to analyze the reason behind the surprising non-monotonic strain dependence of deformation predictability. It is well-known that the deformation process of small-scale crystalline samples consists of a sequence of strain bursts with a power-law-like size distribution15,16,17,21. It is often argued that systems with such scale-free dynamics operate in the proximity of a critical point of a non-equilibrium phase transition27, or within an extended critical region spanned by a range of control parameter values21. If deformation bursts are indeed critical avalanches in analogy to those in, say, Barkhausen noise28, the occurrence of a deformation burst of a given size at a specific stress should be intrinsically hard to predict: in the absence of complete characterization of the system, they may be described as uncorrelated random variables with a probability distribution.
The deterioration of deformation predictability observed in Fig. 2 seems to be due to the onset of large deformation bursts, which are not easily predictable using the coarse-grained description of the system considered here; this is also seen in Fig. 1g where the predicted stress-strain curves reproduce the typical shapes but not the individual strain bursts of the real curves. Sometimes the predicted curves in Fig. 1g even have short segments where the stress decreases with strain, but this just reflects the fact that the ML algorithm has not learned the stress-strain curves perfectly (stress is never a decreasing function of strain in the simulated curves due to the loading protocol employed). Figure 4 shows the probability distribution function (PDF) of εaval, the starting strain of a deformation burst, along with the score curves now plotted with a logarithmic strain axis. In both scenarios, basic in Fig. 4a and ID in Fig. 4b, the large decrease of the score until ε* coincides with the onset of avalanche activity and the score minima are aligned with the distribution maxima (which is seen also when comparing the scores and εaval PDFs of systems with different amounts of pre-strain, see Supplementary Fig. 4). This is related also to the recently investigated concept of first pop-in or discrete plastic event29, as well as to the deformation avalanches in the microplastic regime recently proposed to be governed by weakest link arguments30.

Stochastic strain bursts lead to deterioration of deformation predictability. Top: Probability density of the starting strain of the avalanches, εaval, in a basic and b ID systems. Bottom: The same ANN score S as in Fig. 2 (with a showing data for the basic and b for the ID systems) with a logarithmic strain axis, revealing also an additional local minimum of S(ε) for small ε
S plotted on a logarithmic strain scale reveals that there is an additional local minimum in the predictability around ε = ε** ≈ 3 ⋅ 10−4. This minimum is not as dramatic as the one at ε* and it originates most likely from the nature of the used feature set: With ε < ε** the systems are still almost identical to the relaxed initial states where the interaction between dislocations is insignificant and the stress response is trivial. Around ε ≈ ε**, the dislocations start to feel the presence of the other dislocations, but due to the coarse scale of used features, the stress response here is hard to predict. When ε > ε**, dislocation displacement becomes significant, and the coarse-grained features start to contain relevant information. Hence the predictability improves up to the onset of burst activity.
Size effect in deformation predictability
Finally we address the system size effect seen in the S(ε) curves of Fig. 2, i.e., larger systems are more predictable for ε > ε*. Plastic deformation of micron-scale samples is in general dependent on the sample size, and well-known size effects such as smaller systems being stronger have been reported17,31 (this is evident also in our simulations, see Supplementary Fig. 5; notice that in our simulations this size effect arises with periodic boundaries, while in micropillar compression experiments the presence of open boundaries is important). Figure 5a illustrates the PDF of avalanche sizes s with starting strains in a bin relatively close to the start of the simulation with the basic systems (for distributions of all avalanche sizes, see Supplementary Fig. 6). As the simulation advances along the stress-strain curve, the bursts become larger with the distribution cut-offs shifting towards larger burst sizes21, and the smaller systems tend to always exhibit larger bursts (similar in ID systems, Supplementary Figs. 7 and 8). Thus, S of larger systems is less affected by the strain bursts as they tend to be smaller.

Size effect of predictability. a The probability density of the strain avalanche sizes s in the basic system for bursts starting in a strain bin close to the start of the simulation. b r2 of linear fits between chosen feature parameters (Methods) and the stress σext(ε = 0.1) as a function of the system size (inset shows an example of such a fit). Further information of the r2 of single parameter fits for stresses at different strains is presented in Supplementary Fig. 9
Parameter significance
Figure 5b shows r2 values of linear fits between σext(ε = 0.1) and various input parameters of the ANN as a straightforward measure of parameter significance in systems with different sizes, and partly explains the non-monotonic size effect of the ID scores. In the basic scenario, the size effect implying that larger systems are more predictable is mostly due to the increasing information in the parameter fy1 describing the GND density imbalance in the y-direction. Meanwhile in the ID scenario, there are parameters related to the internal stress field that are notably significant in addition to fy1, but the significance of the stress field descriptors decreases in larger systems. Additionally, the r2 values show that, by itself, fy1 is the most informative descriptor. This arises from the fact that it is conserved: it describes the dislocation imbalance in the y-direction, and as the dislocations move along their glide planes in the x-direction, fy1 is constant throughout the simulation. The significance of fy1 is even more emphasized with larger strains as other descriptors lose their relevance (see Supplementary Fig. 9). One should note that while the r2 values reveal interesting information about the significance of the various descriptors employed in isolation, ANN and SVM predictions discussed above are non-linear mappings from all the descriptors of the initial states to the stress at a given strain.
Discussion
To summarize our findings, we observed predictability in the highly fluctuating stress response of a model of a plastically deforming crystal. Since one classical definition of yield strength is the stress corresponding to a given strain threshold, our results can be directly interpreted as predictions of the sample yield strength corresponding to different strain thresholds, with the score parameter S quantifying how well the prediction works for different strains thresholds, pre-strains, and systems sizes. The predictability is significantly better than what one would obtain by using the average stress-strain curve as the prediction (as S > 0 for all ε), and exhibits two local minima as a function of the strain; the first and minor one originating from the coarse nature of the used feature set and the second and more dominant one due to the onset of significant avalanche activity. The predictability recovers after the deformation bursts become less frequent and the score of the predictions is surprisingly good towards the end of the simulations. Larger systems are found to be more predictable. This is due to larger strain avalanches present in the smaller systems causing larger aberration to the stress response, as well as due to the fact that the dislocation configurations in larger systems contain more information useful for deformation predictability.
Our study could be generalized to 3D DDD simulations32, as well as to models containing quenched disorder interacting with the dislocations27. In 3D dislocation systems with multi-slip conditions, predictability might be affected by the fact that in that case fy1 should not remain constant during straining, unlike in the present case of a 2D model with a single-slip geometry. On the other hand, in 3D under multi-slip conditions forest dislocations on inactive slip systems might provide features which do not evolve much during straining and should thus be useful for prediction. Incorporating quenched disorder to the models—e.g., to mimic precipitate particles33—would increase the dimensionality of the relevant feature vector: statistical characteristics of the resulting pinning landscape in a given sample should contain additional information useful for deformation predictability. The pinning points also alter the avalanche statistics as the system starts to exhibit a depinning transition27.
It would be interesting to test our ideas experimentally considering 3D imaging data obtained by various X-ray measurement techniques34,35,36,37,38,39,40, or optical microscopy of colloidal crystal experiments41, to construct features of the initial dislocation microstructure, and then try to predict the consequent sample strength for instance at ε = 0.1% which is one of the typical definitions for yield strain. Another avenue of future research might be given by application of ML based optimization algorithms (such as Bayesian optimization42) to design material microstructures giving rise to samples with desired mechanical properties, such as a large yield stress, or small deformation fluctuations. Our results thus provide novel insight into deformation predictability of materials, and should find applications in fields such as materials design and optimization.
Methods
DDD simulations
To generate the data sets, we consider a 2D DDD model similar to the one in Refs. 21,27, describing a set of parallel, straight edge dislocations with equal number of positive and negative Burgers vectors of magnitude b. The dislocations move in a square box of size L with periodic boundaries and interact via the dislocation-generated shear stress fields20, σd(r) = σd(x, y) = Dbx(x2 − y2)/(x2 + y2)2, where D = μ/2π(1 − ν), with μ and ν the shear modulus and Poisson ratio, respectively. The overdamped equations of motion describing the glide motion of dislocations along the x-direction are \(1/(\chi b)v_{i} = s_{i}b\left[ {\sigma _{\mathrm{ext}} + \mathop {\sum}\nolimits_{{i} \ne {j}} s_{j}\sigma _{d}({\mathbf{r}}_{j} - {\mathbf{r}}_{i})} \right]\), where χ is the dislocation mobility, si and sj are the signs of the Burgers vectors of dislocations i and j, respectively, and σext is the external stress. We measure lengths in units of b, time in units of 1/χbD and stresses in units of D. To mimic dislocation annihilation, two dislocations with opposite Burgers vectors are removed from the system if their distance is less than 2b. We consider different initial numbers N of dislocations ranging from 50 to 400 distributed randomly within the simulation box, adjusting L so that the dislocation density ρ = N/L2 is kept constant. The initial states of the basic scenario are obtained by relaxing these random configurations with σext = 0. Then, we increase σext quasistatically from zero: σext is increased at a slow rate whenever the strain rate is below a small threshold, and is kept constant during the strain bursts (see also Supplementary Fig. 10 and Supplementary Table 1 for more details on the strain bursts.). The ID initial states are obtained by relaxing systems quasistatically pre-deformed up to a strain εID = 0.2 with σext = 0, after which another quasistatic stress ramp is performed.
Descriptors for machine learning
The relaxed initial states are characterized by different descriptors. (i) Statistical features of the stress field σsf generated by the dislocations, and its absolute value: Average, median, variance, skewness, and kurtosis. To avoid problems due to diverging stress values if dislocations appear near grid points where the stress field is computed, the limit |σsf| ≤ 2.0 is imposed (other threshold values yield similar results). Notice that without such a limit, sampling the stress field using a grid of points would sometimes result in arbitrarily large values which would completely dominate the statistical properties (average, etc.) of the stress distribution, an artifact of using linear elasticity. (ii) Density of geometrically necessary dislocations, ρGND = ρ+ − ρ−, where ρ+ and ρ− are the densities of dislocations with positive and negative Burgers vectors, respectively, in slices of width b parallel and perpendicular to the glide planes. Due to the periodic boundaries, we use their Fourier coefficients as features (cross terms did not improve the predictions); thus, coefficients fxi and fyi were included, where x and y refer to the direction of the slicing and i to the ith coefficient). (iii) We identified dislocation walls by observing that dislocations with glide planes separated by less than ~10b and positions along glide planes separated by less than ~3b tend to move collectively, and calculated the number and maximum and average heights of such structures. Finally, the number of dislocations after the relaxation, and also the stress σID at the end of the pre-shear for ID systems are used as features. All the descriptors considered are collected to Supplementary Table 2. The feature set is then used to train a neural network and a support vector machine to predict σext as a function of ε, considering data sets of 5000 (10,000 for N = 50) samples. Technical details of the model implementation can be found in Supplementary Note 1. For a thorough introduction to the ML methods we refer to ref. 23.
Data availability
The data that support the findings of this study are available from the corresponding authors on reasonable request.
References
Kagan, Y. Y. & Jackson, D. D. Probabilistic forecasting of earthquakes. Geophys. J. Int. 143, 438–453 (2000).
Koivisto, J., Ovaska, M., Miksic, A., Laurson, L. & Alava, M. J. Predicting sample lifetimes in creep fracture of heterogeneous materials. Phys. Rev. E 94, 023002 (2016).
Voight, B. A method for prediction of volcanic eruptions. Nature 332, 125–130 (1988).
Brunelli, R. Template Matching Techniques in Computer Vision: Theory and Practice. (John Wiley & Sons, New Jersey, 2009).
Kourou, K., Exarchos, T. P., Exarchos, K. P., Karamouzis, M. V. & Fotiadis, D. I. Machine learning applications in cancer prognosis and prediction. Comput. Struct. Biotechnol. J. 13, 8–17 (2015).
Krauss, C., Do, X. A. & Huck, N. Deep neural networks, gradient-boosted trees, random forests: Statistical arbitrage on the S & P 500. Eur. J. Oper. Res. 259, 689–702 (2017).
Rupp, M., Tkatchenko, A., Müller, K.-R. & von Lilienfeld, O. A. Fast and accurate modeling of molecular atomization energies with machine learning. Phys. Rev. Lett. 108, 058301 (2012).
Cubuk, E. D. et al. Identifying structural flow defects in disordered solids using machine-learning methods. Phys. Rev. Lett. 114, 108001 (2015).
Carrasquilla, J. & Melko, R. G. Machine learning phases of matter. Nat. Phys. 13, 431–434 (2017).
Nieuwenburg, E. P. L., Liu, Y.-H. & Huber, S. D. Learning phase transitions by confusion. Nat. Phys. 13, 435–440 (2017).
Papanikolaou, S., Tzimas, M., Song, H., Reid, A. C. E. & Langer, S. A. Learning crystal plasticity using digital image correlation: Examples from discrete dislocation dynamics. Preprint at https://arxiv.org/abs/1709.08225 (2017).
Papanikolaou, S. Learning local, quenched disorder in plasticity and other crackling noise phenomena. npj Comput. Mater. 4, 27 (2018).
Wiewel, S., Becher, M. & Thuerey, N. Latent-space Physics: Towards Learning the Temporal Evolution of Fluid Flow. Preprint at https://arxiv.org/abs/1802.10123 (2018).
Zdeborová, L. Machine learning: New tool in the box. Nat. Phys. 13, 420–421 (2017).
Zaiser, M. Scale invariance in plastic flow of crystalline solids. Adv. Phys. 54, 185–245 (2006).
Dimiduk, D. M., Woodward, C., LeSar, R. & Uchic, M. D. Scale-free intermittent flow in crystal plasticity. Science 312, 1188–1190 (2006).
Uchic, M. D., Shade, P. A. & Dimiduk, D. M. Plasticity of micrometer-scale single crystals in compression. Annu. Rev. Mater. Res. 39, 361 (2009).
Alava, M. J., Laurson, L. & Zapperi, S. Crackling noise in plasticity. Eur. Phys. J. Spec. Top. 223, 2353 (2014).
Papanikolaou, S., Cui, Y. & Ghoniem, N. Avalanches and plastic flow in crystal plasticity: an overview. Model. Simul. Mater. Sci. Eng. 26, 013001 (2017).
Hirth, J. P. & Lothe, J. Theory of dislocations. (John Wiley & Sons, New Jersey, 1982).
Ispánovity, P. D. et al. Avalanches in 2D dislocation systems: plastic yielding is not depinning. Phys. Rev. Lett. 112, 235501 (2014).
Ispánovity, P. D., Papanikolaou, S. & Groma, I. The emergence and role of dipolar dislocation patterns in discrete and continuum formulations. Preprint at https://arxiv.org/abs/1708.03710 (2017).
Bishop, C. M. Pattern Recognition and Machine Learning. (Springer, Berlin, Germany, 2006).
Zaiser, M., Miguel, M. C. & Groma, I. Statistical dynamics of dislocation systems: the influence of dislocation-dislocation correlations. Phys. Rev. B 64, 224102 (2001).
Groma, I., Györgyi, G. & Kocsis, B. Debye screening of dislocations. Phys. Rev. Lett. 96, 165503 (2006).
Zaiser, M. The energetics and interactions of random dislocation walls. Philos. Mag. Lett. 93, 387–394 (2013).
Ovaska, M., Laurson, L. & Alava, M. J. Quenched pinning and collective dislocation dynamics. Sci. Rep. 5, 10580 (2015).
Durin, G. & Zapperi, S. in The Science of Hysteresis (eds Bertotti, G. & Mayergoyz, I.) 181–267 (Academic, Amsterdam, 2006).
Derlet, P. M. & Maass, R. The stress statistics of the first pop-in or discrete plastic event in crystal plasticity. J. Appl. Phys. 120, 225101 (2016).
Ispánovity, P. D., Tüzes, D., Szabo, P., Zaiser, M. & Groma, I. Role of weakest links and system-size scaling in multiscale modeling of stochastic plasticity. Phys. Rev. B 95, 054108 (2017).
Greer, J. R. & De Hosson, J. T. M. Plasticity in small-sized metallic systems: Intrinsic versus extrinsic size effect. Prog. Mater. Sci. 56, 654–724 (2011).
Lehtinen, A., Costantini, G., Alava, M. J., Zapperi, S. & Laurson, L. Glassy features of crystal plasticity. Phys. Rev. B 94, 064101 (2016).
Lehtinen, A., Granberg, F., Laurson, L., Nordlund, K. & Alava, M. J. Multiscale modeling of dislocation-precipitate interactions in Fe: from molecular dynamics to discrete dislocations. Phys. Rev. E 93, 013309 (2016).
Ludwig, W. et al. Three-dimensional imaging of crystal defects by ‘topo-tomography’. J. Appl. Cryst. 34, 602–607 (2001).
Levine, L. E. et al. X-ray microbeam measurements of individual dislocation cell elastic strains in deformed single-crystal copper. Nat. Mater. 5, 619 (2006).
Kalácska, S., Groma, I., Borbély, A. & Ispánovity, P. D. Comparison of the dislocation density obtained by HR-EBSD and X-ray profile analysis. Appl. Phys. Lett. 110, 091912 (2017).
Groma, I., Ungár, T. & Wilkens, M. Asymmetric Xray line broadening of plastically deformed crystals. I. Theory. J. Appl. Crystallogr. 21, 47–54 (1988).
Groma, I. & Monnet, G. Analysis of asymmetric broadening of X-ray diffraction peak profiles caused by randomly distributed polarized dislocation dipoles and dislocation walls. J. Appl. Crystallogr. 35, 589–593 (2002).
Schafler, E. et al. A second-order phase-transformation of the dislocation structure during plastic deformation determined by in situ synchrotron X-ray diffraction. Acta Mater. 53, 315–322 (2005).
Groma, I., Tüzes, D. & Ispánovity, P. D. Asymmetric X-ray line broadening caused by dislocation polarization induced by external load. Scr. Mater. 68, 755–758 (2013).
Pertsinidis, A. & Ling, X. S. Video microscopy and micromechanics studies of one- and two-dimensional colloidal crystals. New J. Phys. 7, 33 (2005).
Mockus, J. Bayesian approach to global optimization: theory and applications. (Kluwer Academic, Dordrecht, Netherlands, 1989).
Acknowledgements
This work has been supported by the Academy of Finland through an Academy Research Fellowship (LL, project no. 268302). We acknowledge the computational resources provided by the Aalto University School of Science Science-IT project, as well as those provided by CSC (Finland).
Author information
Authors and Affiliations
Contributions
L.L. and M.J.A. designed the study. H.S. performed the numerical simulations and implemented the machine learning algorithms, and contributed significantly to the final form of the study. L.L. wrote the first version of the manuscript. All authors contributed to improve the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Journal peer review information: Nature Communications thanks the anonymous reviewers for their contribution to the peer review of this work.
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Salmenjoki, H., Alava, M.J. & Laurson, L. Machine learning plastic deformation of crystals. Nat Commun 9, 5307 (2018). https://doi.org/10.1038/s41467-018-07737-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-018-07737-2
This article is cited by
-
Neural Networks for Constitutive Modeling: From Universal Function Approximators to Advanced Models and the Integration of Physics
Archives of Computational Methods in Engineering (2024)
-
Machine learning dislocation density correlations and solute effects in Mg-based alloys
Scientific Reports (2023)
-
A machine learning microstructurally predictive framework for the failure of hydrided zirconium alloys
npj Materials Degradation (2023)
-
Predictive machine learning approaches for the microstructural behavior of multiphase zirconium alloys
Scientific Reports (2023)
-
Predicting elastic and plastic properties of small iron polycrystals by machine learning
Scientific Reports (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
