
Abstract
To promote the implementation of genomic medicine, we developed an integrated database, the Medical Genomics Japan Variant Database (MGeND). In its first release, MGeND provides data regarding genomic variations in Japanese individuals, collected by research groups in five disease fields. These variations consist of curated SNV/INDEL variants and susceptibility variants for diseases established by genome-wide association study analysis. Furthermore, we recorded the frequencies of HLA alleles in infectious disease populations.
Similar content being viewed by others
The accumulation of data regarding associations between genotypes and clinical phenotypes is important to accelerate the implementation of genomic medicine in clinical practice. Several databases containing genetic information and their clinical significance have already been released. ClinVar, developed by the National Institutes of Health in the US, provides genomic variant information with supporting evidence and review status1 and is widely utilized for the clinical interpretation of variants. Furthermore, some databases provide variant information regarding specific diseases.
There are two major problems with the utilization of databases for genomic medicine. The first pertains to the differences between populations. The genomic information stored in previously established databases has been primarily obtained from US and European populations. Genes and genotypes associated with the risk of onset of several diseases have been reported to vary between ethnic groups2. The second is the disease fields of the databases. Certain diseases are known to be triggers for other diseases, such as hepatitis and cancer3, and an example in which rare variants contribute to the risk of common diseases has been reported4. Interpretation of variants across diseases is necessary to elucidate variants and diseases with unknown mechanisms. However, there is no database of clinical and genomic information that reflects the characteristics of Asian populations across multiple disease fields, including monogenic and polygenic diseases.
We developed a database, the Medical Genomics Japan Variant Database, “MGeND”, which integrates clinical and genomic information regarding Japanese individuals. The first version of MGeND was released in March 2018, with genomic variations collected from 11 representative Japanese groups in the fields of “cancer”, “rare/intractable disease”, “dementia”, “infectious disease”, and “hearing loss”. The research groups in each disease field recruited patients and performed genomic analysis and interpretation of variants (Supplementary Table 1 presents the list of research groups). In collaboration with these groups, we collected and integrated genomic and clinical information that can be publicly shared on MGeND.
The clinical data to be registered include disease or diagnosis name along with basic patient background information, such as sex and age, excluding information that could identify individuals. Disease names are registered using general condition identifiers, such as Online Mendelian Inheritance in Man5, Human Phenotype Ontology6, and ICD10 (ref. 7). The age of onset and age at which the test was conducted can be submitted based on the disease type, with age divided into 10-year age bins in MGeND.
Because different genomic analyses can be conducted in monogenic and polygenic diseases, varying genomic data can be submitted to MGeND. Therefore, submission data formats have been defined for each genomic data type. In the first release of MGeND, we provided SNV/INDEL variants, susceptibility variants obtained by genome-wide association study (GWAS) analysis, and human leukocyte antigen (HLA) allele frequencies. To submit sequence variants, a valid description of a variant consists of a set of chromosome coordinates, changes, and the assembly version. Each variant position submitted is integrated into the GRCh38/hg38 assembly to be combined with public databases.
Furthermore, we accept sets of susceptibility variants identified using GWAS analysis often performed for some diseases, particularly for polygenic diseases. The statistical criteria of the data to be submitted are based on the judgment of the submitters. We recommend submitting variants with a p-value < 10−4.
Protein molecules encoded by HLA genes play key roles in the immune system, including antigen presentation and self-recognition. Accordingly, it is important to know the HLA types not only for autoimmune and infectious diseases but also for cancer. Therefore, we accept HLA allele frequency data represented in two or three/four fields. Currently, these types of variant data are not included in ClinVar and other databases.
In addition, for all types of variations, we recommend submitting information regarding details such as platform type, gene panels, methods, statistical tests, and imputation methods used for genotyping. In particular, for SNV/INDEL variants, we suggest that research groups submit variants with evidence for clinical significance and curation; MGeND provides publication information (PubMed ID) for each submission if it is available. Table 1 shows the number of variants for each data type in each disease field published in MGeND as of 16 February 2019.
To interpret variants, it is necessary to make comprehensive judgments by searching related information from a huge amount of data stored in public databases. Thus, the web display of MGeND has been designed to support the clinical interpretation of variants for medical research and clinical use.
Users can search variant information in MGeND using free text, such as disease name, gene symbol, or genomic position. The list of variants produced by the keyword search is displayed, with the clinical significance identified by submitters and information regarding public databases that are often used for clinical interpretation (Fig. 1a). Furthermore, investigation of diseases, drugs, and genes associated with the query is possible using the filters in the side bar. The list of all public databases displayed in MGeND is shown in Supplementary Table 2.

a The resulting view from a keyword search. The variants identified by the keyword search are listed with the original information in MGeND (clinical significance, the number of samples, and origin of cells) and with the information from public databases, which is often used for interpretation of variants. b The statistics for each gene or variant are provided. The statistics regarding disease name, sex, and age can be filtered in each disease field by clicking on the disease field name in the upper left graph. Full text of the disease name is shown by placing the cursor over the disease name at the left side of the bar.
After selecting a variant or gene in the list of search results, detailed information can be obtained from the variant or gene pages. Each variant or gene page provides information about the disease fields and disease name for which that variant was reported and age and sex distributions of cases in which the variant was detected (Fig. 1b).
There are some variants common to different diseases, and analyzing these variants can assist in clarifying the underlying disease mechanisms. For example, a variant in the MAP2K1 gene (NC_000015.9:g.66727483G>A) is known to be associated with cardiofaciocutaneous syndrome 1 and cancer. In MGeND, the variant has been submitted by groups researching cancer and rare diseases, and users can confirm the situation on the variant page (details are provided in the Supplementary Material).
Furthermore, we provide specific viewers for some disease fields. For infectious diseases, we implemented a table viewer for the frequencies of HLA alleles in each study, with the frequencies of each allele in the healthy control group obtained from studies performed by the National Center for Global Health and Medicine and the HLA Laboratory8 (Fig. 2a). The APOE gene is known to be associated with the risk of onset of dementia9. Thus, the data submitted by the groups researching dementia can be filtered by type of dementia, sex, family history, and diagnosis source; the frequencies of the genotypes in the selected data are shown as pie graphs on the dementia page (Fig. 2b).

a The table viewer for the frequencies of human leukocyte antigen (HLA) alleles. The columns with blue headers are the HLA allele frequencies in patients and control samples for each study of the infectious disease group. The gray columns display the frequencies in the healthy control groups obtained from HLA Laboratory and National Center for Global Health and Medicine (NCGM) studies. b The graph for the genotype distribution of the APOE gene. The data used to draw these graphs can be filtered by factors such as sex, family history, and age of onset.
MGeND is the first database that provides disease-related genomic information specific to Asian populations and integrates variant information from monogenic and polygenic diseases. We aim to develop pages and contents that can present variant information more usefully; for example, we are developing the viewer for the GWAS dataset with meta-data, such as study design and p-values. We aim to expand and integrate the disease fields and accept submissions from researchers in various fields. The number of variants recorded in the database is expected to increase continuously.
Software availability
MGeND is available from the following URL: https://mgend.med.kyoto-u.ac.jp.
References
Landrum, M. J. et al. ClinVar: public archive of interpretations of clinically relevant variants. Nucleic Acids Res. 44, D862–D868 (2016).
Ma, R. C. W. & Chan, J. C. N. Type 2 diabetes in East Asians: similarities and differences with populations in Europe and the United States. Ann. N. Y. Acad. Sci. 1281, 64–91 (2013).
Ishiguro, S. et al. Impact of viral load of hepatitis C on the incidence of hepatocellular carcinoma: a population-based cohort study (JPHC Study). Cancer Lett. 300, 173–179 (2011).
Tajima, T. et al. Blood lipid-related low-frequency variants in LDLR and PCSK9 are associated with onset age and risk of myocardial infarction in Japanese. Sci. Rep. 8, 1–9 (2018).
Amberger, J. S., Bocchini, C. A., Schiettecatte, F., Scott, A. F. & Hamosh, A. OMIM.org: Online Mendelian Inheritance in Man (OMIM®), an Online catalog of human genes and genetic disorders. Nucleic Acids Res. 43, D789–D798 (2015).
Köhler, S. et al. The human phenotype ontology in 2017. Nucleic Acids Res. 45, D865–D876 (2017).
World Health Organization. ICD-10: international statistical classification of diseases and related health problems: tenth revision, 2nd ed. (2004). https://apps.who.int/iris/handle/10665/42980.
Ikeda, N. et al. Determination of HLA-A, -C, -B, -DRB1 allele and haplotype frequency in Japanese population based on family study. Tissue Antigens 85, 252–259 (2015).
Farrer, L. A. et al. Effects of age, sex, and ethnicity on the association between apolipoprotein E genotype and Alzheimer disease. A meta-analysis. APOE and Alzheimer Disease Meta Analysis Consortium. JAMA 278, 1349–1356 (1997).
Acknowledgements
This work was supported by the Japan Agency for Medical Research and Development (AMED) under grant number JP18kk0205013h0003. We especially acknowledge the members of the research groups for their contributions to provide genomic data and clinical information.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kamada, M., Nakatsui, M., Kojima, R. et al. MGeND: an integrated database for Japanese clinical and genomic information. Hum Genome Var 6, 53 (2019). https://doi.org/10.1038/s41439-019-0084-4
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41439-019-0084-4
This article is cited by
-
National Center Biobank Network
Human Genome Variation (2022)
-
TogoVar: A comprehensive Japanese genetic variation database
Human Genome Variation (2022)
-
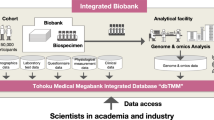
dbTMM: an integrated database of large-scale cohort, genome and clinical data for the Tohoku Medical Megabank Project
Human Genome Variation (2021)
