
Abstract
Early intervention in psychosis is crucial to improving patient response to treatment and the functional deficits that critically affect their long-term quality of life. Stratification tools are needed to personalize functional deficit prevention strategies at an early stage. In the present study, we applied topological tools to analyze symptoms of early psychosis patients, and detected a clear stratification of the cohort into three groups. One of the groups had a significantly better psychosocial outcome than the others after a 3-year clinical follow-up. This group was characterized by a metabolic profile indicative of an activated antioxidant response, while that of the groups with poorer outcome was indicative of oxidative stress. We replicated in a second cohort the finding that the three distinct clinical profiles at baseline were associated with distinct outcomes at follow-up, thus validating the predictive value of this new stratification. This approach could assist in personalizing treatment strategies.
Similar content being viewed by others


Introduction
Early intervention in psychosis is key to improving long-term outcome [1,2,3,4,5,6], which is strongly influenced by quality of life and social functioning trajectories in the early treatment phase [7, 8]. Clinical and biological markers quantifying disease course or treatment response should therefore be developed to guide treatment decision at early stages of the disease [9,10,11,12]. Since patient heterogeneity hampers marker identification, stratification tools allowing personalized functional-disability preventive strategies are needed.
Topological Data Analysis (TDA) is a powerful approach to analyzing the shape of biological datasets, identifying biotypes in a data-driven way. The TDA algorithm Mapper produces graphical output that allows insight into the robustness of the proposed stratification [13]. Mapper has shown promise for outcome assessment in neurological trauma [14] and for detecting significant subgroups of breast cancers. Applied to fragile X-syndrome [15], structural brain images, Mapper identified distinct subgroups with consistent cognition, adaptive functioning, and autism severity scores.
In this study, we used TDA to stratify a cohort of early psychosis patients based on Positive and Negative Syndrome Scale (PANSS) scores. Although clustering algorithms were used previously to study symptom patterns [16], this is the first such application of TDA. TDA stratified the early psychosis cohort into three groups with coherent clinical profiles. We then sought a biosignature of the groups, representing distinct underlying pathophysiological pathways. To test the hypothesis of redox dysregulation/oxidative stress as one pathophysiological hub [17,18,19,20], we studied redox markers such as blood levels of glutathione (GSH), GSH peroxidase and reductase activities (GPx, GR), thioredoxin (Trx), and GSH-related metabolites. In addition, we explored an unbiased selection of 28 amino acids of which metabolism is notably altered both at schizophrenia onset and in later stages [21,22,23,24,25].
To validate the clinical relevance of our stratification, we compared outcomes after 3 years between groups, focusing on functional level for three reasons. First, functional recovery, the main determinant of the social and economic burdens of schizophrenia [7], may fail despite symptom remission. Second, functional level in the early illness phase is relatively stable over 20 years [7] and the strongest predictor of later functional level [26]. The 3-year follow-up in our study is thus likely to predict longer-term outcomes. Finally, functional impairment, reported in all forms of psychosis [7], is an important indicator for individuals at risk for psychosis [27]. Better knowledge of its determinants is therefore useful at various stages of the illness.
Materials/subjects and methods
Participants
All subjects provided a fully informed written consent; all procedures were in accordance with the ethical standards of the Helsinki Declaration (1983) and approved by the local ethical committee. EPP were recruited from the Treatment and early Intervention in Psychosis Program (TIPP2, see Supplementary). Cohort 1 comprises 101 patients from the TIPP program (biomarkers project, globally representative of the entire cohort [28]) and cohort 2 comprises 93 TIPP patients (not included in the biomarker study).
Clinical evaluations
Psychopathological assessments were conducted by trained psychologists. We used the PANSS and the Wallwork five-factor model to assess symptom severity and to categorize the different symptom domains [29].
Outcomes at discharge were evaluated at 36 months or within the last year of treatment: (i) ‘Working’: Modified Vocational Status Index [30]; (ii) ‘Living independently’: Modified Location Code Index [30]; (iii) symptomatic remission: Andreasen criteria [31]; (iv) Social and Occupational Functioning Assessment Scale (composite global score; SOFAS) [32]; (v) Global Assessment of Functioning (global composite score; GAF) [32].
TDA stratification of cohort 1 with Mapper algorithm
We used the Mapper algorithm [33] (www.ayasdi.com) to visualize and study the 30 PANSS items at baseline, using (i) distance: normalized Pearson correlation distance; (ii) filter function: coefficients in the coordinate system given by the first two principal components; (iii) resolution: 60, (iv) gain: 7. Our choice of resolution and gain is not crucial for the identification of the Mapper-based partition [A, B, C], as these groups are easily recognizable whenever the Mapper graph does not have trivial connectivity structure (Supplementary Fig. 1, Supplementary Methods).
Assessment of metabolic markers
Amino acids were quantified in plasma [34], and GSH and GPx, GR, and Trx activity levels in blood cell pellets after hemolysis [35,36,37] (Supplementary Methods). Two metabolites are considered strongly correlated in a group of patients if the Pearson correlation between the associated vectors is significantly different from zero (p value < 0.05). Biological correlations among the 28 measured metabolites in cohort 1 were determined in groups A, B, or C as detailed in the Supplementary.
Validation of the stratification in cohort 2
An independent cohort of 93 individuals, called cohort 2, was used for validation. We computed the centroid of the symptom vectors of each group in cohort 1, i.e., the average value, within the group, of each coordinate in the 30-dimensional space of PANSS scores. We then computed the Euclidean distance between the symptom vector of each patient in cohort 2 and the centroids of the groups from cohort 1, assigning the patient to the group with the closest centroid. This assignment determined a partition of cohort 2 into subgroups, called the replicated groups.
Prediction of good vs. poor functional outcome
We used logistic regression to predict good vs. poor functional outcome (GAF > 65 vs. GAF ≤ 65), based on either the PANSS items or group membership in [A, B, C] or [0, 1, 2]. We trained on cohort 1, validated on cohort 2, and evaluated the accuracy, precision, and recall of the regression, as implemented in the sklearn library. See the Supplementary and Supplementary Table 1 for more details.
Group comparisons for clinical and metabolic data
We used the Kolmogorov–Smirnov test, as implemented in the python function ‘scipy.stats.ks_2samp’ from the scipy library, to identify which PANSS items are group-specific. For each PANSS item, we compared the distribution of its scores in one group with the distribution in the remaining two groups by the Kolmogorov–Smirnov test and applied Bonferroni correction for multiple comparisons. Items were considered as group-specific if the corrected p value < 0.05.
We computed Pearson correlation coefficients to create correlation matrices of metabolite levels in patients within groups A, B, or C, using the function corrcoef(), in the numpy python library. All other statistics were performed with R, using the Chi-Square test for independence to compare distributions and Student’s t test or analysis of variance to compare continuous variables between two or three groups, respectively. If not otherwise specified, groups were considered different when p < 0.05.
k-means clustering
We performed k-means clustering via sklearn.cluster.KMeans implemented in the python library sklearn. We chose k = 3, to be able to compare with the three TDA-based groups.
Results
Stratification of cohort 1 by TDA based on symptom levels at baseline
Cohort 1 was composed of 101 patients treated in an early intervention program (TIPP2). Patients were primarily males, with a mean age of 25.1 years and a mean illness duration of 1.9 years at baseline (Table 1). Most patients were prescribed antipsychotics (95%).
We used the Mapper algorithm to visualize the data quantifying the severity of symptoms. We associated to each patient a vector of 30 entries recording the PANSS items’ scores. The Mapper algorithm was then used to cluster the vectors, forming the nodes of a graph. A vector can belong to more than one node; if two nodes share at least one vector, they are connected by an edge. By construction, vectors representing patients with similar symptom values at baseline belong to the same node or to a set of tightly connected nodes of the Mapper graph (Fig. 1a).

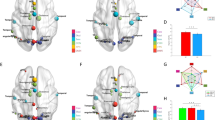
a Mapper graph based on the symptoms of early psychosis patients. Each node represents a group of patients. Each edge represents at least one common patient between the two connected nodes. Nodes are colored according to mean PANSS positive score. The dashed line represents the separation between groups B and C. The dashed circle highlights the two isolated nodes (n = 4 patients in total) who were not assigned to any group. b The Mapper graphs are colored according to the scores for the subscales of the Wallwork five-factor model. c Box plots illustrating the levels of symptoms at recruitment in groups A (white), B (gray), and C (blue) for the subscales of the Wallwork five-factor model. *p < 0.05 d Demographic characteristics of groups A, B, and C. Data are presented as mean (standard error).
From the shape of the Mapper graph generated from the PANSS items, we identified three groups of patients: group A (n = 21), group B (n = 30), and group C (n = 43; Fig. 1a), with similar mean age, age at illness onset, and proportion of males/females (Fig. 1d). A small number of patients were not classified (n = 7, Supplementary Table 2). At recruitment, positive and excited symptoms were highest for group B (Fig. 1b, c); patients in group B had more elevated scores for many items of the positive and general PANSS than the rest of the cohort (e.g., P1, P3, G9; Supplementary Table 3). Negative and depressed symptoms were lowest in group A; low scores for negative and depressed symptoms characterized group A (e.g., N1, N2, G6). Higher scores on negative symptoms (e.g., N1, N2) distinguished group C from the rest of the cohort. Disorganized symptoms were high in group B, intermediate in group C, and low in group A.
We further explored blood metabolites, since the identification of biomarkers correlated with outcome might lead to the identification of target metabolic pathways.
Biomarkers characterizing the clinical groups at baseline
Two groups of compounds were quantified at baseline: (1) redox-related metabolites and enzyme blood levels (GSH, GPx, GR, and Trx activities [34, 36]), and (2) 28 free amino acids and derivatives (Supplementary Table 4).
GPx activity was lower in group A (23.3 ± 1.9 µmol/min/gHb) than in B and C, respectively (25.5 ± 1.9, p = 0.047 and 28.1 ± 1.6 µmol/min/gHb, p = 0.008; Fig. 2), while that of GR and Trx was similar in the three groups. Group A tended to have increased levels of the antioxidant GSH than group B (p = 0.062). Group A displayed higher 2-aminobutyrate levels (21.4 ± 2.1 µM) than B and C, respectively (17.9 ± 1.2 µM, p = 0.046 and 16.8 ± 1.0 µM, p = 0.009; Fig. 2). To further explore whether metabolic pathways related to these proteinogenic amino acids were differentially regulated in the three groups, we studied the correlations between metabolites that correspond to known biological pathways. In group A, the metabolism of nitric oxide and of methionine was affected (urea cycle and arginine, proline metabolism, Fig. 3 and Supplementary Fig. 2). Strikingly, many amino acids were correlated to glutamate levels in group C, possibly reflecting amino acid degradation, as the first step involves transamination to form glutamate [38].

Boxplot illustrating the blood levels of three antioxidant enzymes (Glutathione peroxidase (GPx), Glutathione reductase (GR), Thioredoxin), of glutathione (GSH), and a modulator of GSH metabolism, 2-aminobutyrate. *p < 0.05 using a linear model adjusted for age and sex.

→ or ↔: uni- or bi-directional metabolic reaction. Colored edges connect pairs of metabolites that are strongly correlated among patients (p < 0.05) in group A (red), group B (green), group C (blue), group A and group C (orange), group B and group C (light blue), and in the three groups (black). Note that the pattern of correlated amino acids differed between groups, and stronger correlations among a larger group of amino acids were detected in group A than in groups B and C (Supplementary Fig. 2). When we consider only the correlations that correspond to known biological pathways. (https://www.vmh.life/), the regulation of various systems appeared to be differentially impaired in the three groups.
hyp hydroxy-proline, cit citrulline, orn ornithine.
Predictive value of the grouping for the outcome at discharge
Clinical follow-up assessments included symptom levels, diagnosis, symptomatic remission [31], global and social functioning (GAF; SOFAS), and whether the patient was working or living independently at the end of 3 years of treatment [30].
At follow-up, most symptoms had reached similarly low levels in all three groups (Fig. 4c); the exceptions were the negative symptoms, which remained higher in group C (12.6 ± 1.2) than in group A (7.4 ± 1.0; p = 0.005). Patients from group B were more frequently diagnosed with schizophrenia (Fig. 4a) and those from group A with schizophreniform disorder or brief psychosis episode. Patients from group A had better social functioning (SOFAS) than groups B and C, and better global functioning (GAF) than group C. (Fig. 4b). Varying the position of the boundary between groups B and C did not affect the profiles specific to each group at inclusion, and mostly preserved the differences of outcome (Supplementary Fig. 3).

a Table summarizing the retained diagnosis. The Chi-Square test for independence indicates a difference among the groups in the proportion of diagnosis. Brief Psychotic Ep.: brief psychotic episode. b Bar graph illustrating the percentages of patients from groups A, B, and C who are working, living independently, or in symptomatic remission, and the score for the SOFAS (Social and Functional Assessment scale) and GAF (Global Assessment of Functioning) scales. *p < 0.05. c Temporal evolutions of symptoms in cohort 1. Scores for the subscales of the Wallwork five-factor model in groups A (light gray), B (dark gray), and C (blue).Lines: Mean value, Shaded color: 95% confidence interval.
We used machine learning with logistic regression to quantify the predictive power of this new stratification for good or poor psychosocial functioning at outcome (i.e., GAF > 65 or ≤65). Logistic regression was performed on either PANSS scores at baseline or membership in groups A, B, and C (Supplementary Table 1). The accuracy of logistic regression using the PANSS items was poor (precision: 0.20; recall: 0.05), but was 0.74 when using group membership instead (precision: 0.68; recall: 0.46; Supplementary Fig. 4c).
In summary, TDA of PANSS symptoms at baseline identified three clinically distinct groups of early psychosis patients with predictive value for functional outcome at 3 years.
Validation study in cohort 2
A replication cohort of 93 TIPP patients was constituted (cohort 2), matched for age at illness onset, illness duration, and age at baseline; its proportion of females was higher (Table 1).
Patients from the cohort 2 were assigned to replication groups based on the distance of their symptom vectors to the centroids of groups A, B, and C (Supplementary Fig. 5). For instance, a patient whose symptom vector was closer to the average symptoms in group A than to that of the other groups was assigned to replication-group A (rep-A). For the three replication groups from cohort 2, the number of patients, mean age, age at illness onset, and proportion of males/females were similar to those of cohort 1 (Fig. 5a). The baseline symptoms characterizing each group were reproduced in cohort 2 at the factor level (Fig. 5b) and at the item level (Supplementary Table 3).

a Table summarizing the demographic characteristics of the predicted groups in the validation cohort 2. Data are presented as mean (standard error). b Bar graph representing the levels of symptoms at recruitment in predicted groups A (white), B (gray), and C (blue) using Wallwork five-factors model. *p < 0.05.
Outcome in the validation study
The outcomes of patients in rep-A were better than those of rep-B for all the criteria assessed (Fig. 6b). Mean functioning scores (GAF, SOFAS) were different among the three groups: lowest in rep-B and highest in rep-A.

a Table summarizing the retained diagnoses of patients in the validation cohort. The Chi-Square test for independence indicates a difference between groups in the proportion of diagnosis. Brief Ep.: brief psychotic episode. b Bar graph illustrating the percentage of patients in the validation cohort from predicted groups A, B, and C who are working, living independently, or in symptomatic remission, and the score for the SOFAS and GAF scales. *p < 0.05. c Precision-recall curve of Logistic Regression, with regularization strength 1, when using PANSS items (red), TDA-based group membership (blue), k-means clustering (purple), or k-means clustering on PCA (green). The dashed line represents the proportion of patients with good outcome in cohort 2, i.e., the precision of the model that always predicts good outcome.
The group rep-A had the best outcome after 3 years of clinical follow-up, while rep-B had the worst outcome, as in cohort 1 (see Fig. 4b for comparison). There were two significant differences from cohort 1: (i) the retained diagnoses were similar among the predicted groups (Fig. 6a); (ii) the group rep-C had a better outcome than group C, displaying an intermediate profile, between rep-A and rep-B.
We trained logistic regression to predict good vs. poor functional outcome on cohort 1 and tested it on cohort 2. Using TDA-based groups as features, rather than PANSS items, we obtained better accuracy, precision, and recall scores (Supplementary Fig. 4a). The area under the precision-recall curve for PANSS items was 0.46, compared with 0.61 for the TDA-based groups (Fig. 6c). Overall, we validated with cohort 2 the clinical and demographic profiles of cohort 1. Logistic regression confirmed the robust predictive value of group A for long-term functional outcomes.
Comparing topological clustering to a standard clustering method
To assess the originality of our clustering and confirm that we identify a robust structure in the data, we compared the TDA-based stratification of cohort 1 into groups A, B, and C, to the partition [0, 1, 2] or [0PCA, 1PCA, 2PCA] obtained by clustering the same data with the k-means algorithm (K = 3) or by clustering the two first principal component scores of the data with k-means (K = 3).
The k-means clusters [0, 1, 2] partly overlapped with the TDA-based groups (Supplementary Fig. 6). However, the predictive power of the partition [0, 1, 2] was lower than that of the TDA groups [A, B, C], according to all the metrics considered to evaluate the performance of logistic regression (Fig. 6c and Supplementary Fig. 4). The k-means clustering on PCA produces intermediate results between the k-means and the TDA-based groups. The clusters [0PCA, 1PCA, 2PCA] partly overlapped with the TDA-based groups (Supplementary Fig. 7). The predictive power of the partition [0PCA, 1PCA, 2PCA] was good when using cohort 1 as training set and cohort 2 as test set, but lower than that of the TDA groups [A, B, C] for the fivefold cross validation scheme (Fig. 6c and Supplementary Fig. 4).
Discussion
Applying TDA to stratify a cohort of early psychosis patients (n = 101) according to their symptom levels, we identified three clinical profiles displaying distinct biological characteristics and different long-term functional outcome. Group A was characterized by an overall low level of symptoms and favorable functional outcome, while group B (with high positive and negative symptoms), and group C (with high negative symptoms) had poorer functional outcome. In a validation cohort (n = 93), we confirmed that predicted group membership is associated with distinct clinical profiles at baseline and at follow-up. TDA grouping also predicted good vs poor functional outcome with higher accuracy than the PANSS items or groups obtained by k-means clustering, confirming the clinical relevance of the TDA grouping.
Regarding redox markers, group A displayed a distinct metabolic profile, with the lowest GPx activity compared with groups B and C. As high blood GPx activities are associated with low brain GSH levels [37], this result suggests that better outcome within group A may be related to better redox regulation and poorer outcome in B and C to high oxidative status and/or an important redox dysregulation [18, 36]. Interestingly, the exploratory profiling of amino acids highlighted that 2-aminobutyrate levels were higher in group A than in B and C. 2-Aminobutyrate, proposed as marker for GSH dynamics [39,40,41], is a byproduct of cysteine, the limiting precursor of GSH, which modulates GSH homeostasis. These observations suggest a correlation between better regulation of antioxidant defense and better outcome (Supplementary Fig. 8). The correlations between urea cycle metabolites differed between group A versus B and C, suggesting a difference in reactions distributed between the mitochondrial matrix and the cytosol. The previously reported urea cycle dysregulation, as well as decreased arginine levels and nitric oxide imbalance in schizophrenia, may thus be more prominent in subgroups B and C [22, 24, 42].
Interpretation of the metabolic profile is hindered by our selection, which was oriented toward the assessment of redox balance. Inflammatory markers, lipid metabolism, NMDA receptor reactivity, and dopamine functions should also be examined, as should the potential effect of medication, since antipsychotics may alter amino acid metabolism [21]. Moreover, replication is needed to strengthen these conclusions, as blood was not available in our validation cohort.
The robustness of the TDA-identified groups was established by several tests: (i) the groups remained cohesive for different parameters and different implementations of the Mapper algorithm (Supplementary Fig. 1); (ii) profiles at inclusion and outcomes were stable when changing slightly the boundary between groups; (iii) most results were similar in both cohorts of early psychosis patients; and (iv) the k-means clustering stratification was similar to the TDA stratification, although k-means clusters overall had a lower predictive value for outcome. Compared with other stratification methods, an important advantage of Mapper is the graph structure visualization: connectivity variations when modifying the resolution and gain parameter were important for developing intuition about the relation between groups and their composition at different scales. Other group-assignment strategies that take into account the Mapper structure may improve group identification.
The finding that group A had better outcome was data driven and is therefore a robust finding. The low levels of symptoms in this group may indicate a good early response to treatment, associated with better functioning [11, 43, 44], and improved long-term outcome [45, 46]. The fact that patients with poor functional outcome split into two groups is also of importance, as different therapeutic strategies might be required, based on the clinical and metabolic profiles. Though group B was characterized by high positive symptoms at baseline, it did not include more treatment-resistant patients than those of group C, which present low positive symptoms at baseline (Supplementary Table 5). Furthermore, the observation that all three groups displayed similarly low levels of positive symptoms at the end of the clinical follow-up suggests that patients in group B are slow/poor responders to treatment and may need intensive case management or specific antipsychotic drug [8, 47]. Group B has neither patients with bipolar disorder nor with schizophreniform disorder and its less favorable outcome is in line with previous papers showing that schizophrenia has poorer outcome than affective psychoses or schizophreniform disorder [48, 49].
Negative symptoms are known to be associated with poor outcomes [50] and difficult to treat. Patients from groups B and C displayed high levels of negative symptoms at baseline, though these symptoms remain high only in group C. This may be linked to a different illness profile and neurobiological basis between groups B and C, which is actually in line with our results showing that they have distinct metabolic profiles. Group C may consist of patients with persistent trait-related negative symptoms, known indicators of poor psychosocial outcome [51,52,53]. The GPx activity was particularly high in group C, suggesting that they may benefit from antioxidant add-on therapy [35] such N-acetyl-cysteine, which improves negative symptoms [54, 55]. Despite the limitations of the tools used to assess negative symptoms our results suggest that on their basis it is possible to identify distinct subgroups of patents with distinct needs.
In summary, unsupervised data-driven topological analysis of symptoms produced meaningful stratification of early psychosis patients and detected patients at risk of poor functional and social outcomes. Although this study requires replication in patient populations recruited at different sites, this approach, combined with mechanism-based metabolic profiling, should pave the way for personalized functional-disability preventive strategies at early stages of the disease.
References
Hegelstad WTV, Larsen TK, Auestad B, Evensen J, Haahr U, Joa I, et al. Long-term follow-up of the TIPS early detection in psychosis study: effects on 10-year outcome. Am J Psychiatry. 2012;169:374–80.
Baumann PS, Crespi S, Marion-Veyron R, Solida A, Thonney J, Favrod J, et al. Treatment and early intervention in psychosis program (TIPP-Lausanne): implementation of an early intervention programme for psychosis in Switzerland. Early Inter Psychiatry. 2013;7:322–8.
Hastrup LH, Kronborg C, Bertelsen M, Jeppesen P, Jorgensen P, Petersen L, et al. Cost-effectiveness of early intervention in first-episode psychosis: economic evaluation of a randomised controlled trial (the OPUS study). Br J Psychiatry. 2013;202:35–41.
McGorry P, Johanessen JO, Lewis S, Birchwood M, Malla A, Nordentoft M, et al. Early intervention in psychosis: keeping faith with evidence-based health care: a commentary on: ‘Early intervention in psychotic disorders: faith before facts?’ by Bosanac et al. (). Psychol Med. 2010;40:399–404.
McGorry PD. Early intervention in psychosis: obvious, effective, overdue. J Nerv Ment Dis. 2015;203:310–8.
Nordentoft M. Specialised assertive intervention in early psychosis. Lancet Psychiatry. 2015;2:2–3.
Velthorst E, Fett A-KJ, Reichenberg A, Perlman G, van Os J, Bromet EJ, et al. The 20-year longitudinal trajectories of social functioning in individuals with psychotic disorders. Am J Psychiatry. 2017;174:1075–85.
Koutsouleris N, Kahn RS, Chekroud AM, Leucht S, Falkai P, Wobrock T, et al. Multisite prediction of 4-week and 52-week treatment outcomes in patients with first-episode psychosis: a machine learning approach. Lancet Psychiatry. 2016;3:935–46.
Conus P, Cotton S, Schimmelmann BG, McGorry PD, Lambert M. Rates and predictors of 18-months remission in an epidemiological cohort of 661 patients with first-episode psychosis. Soc Psychiatry Psychiatr Epidemiol. 2017;52:1089–99.
Cotton SM, Lambert M, Schimmelmann BG, Filia K, Rayner V, Hides L, et al. Predictors of functional status at service entry and discharge among young people with first episode psychosis. Soc Psychiatry Psychiatr Epidemiol. 2017;52:575–85.
Conus P, Cotton SM, Francey SM, O’Donoghue B, Schimmelmann BG, McGorry PD, et al. Predictors of favourable outcome in young people with a first episode psychosis without antipsychotic medication. Schizophrenia Res. 2017;185:130–6.
Bergh S, Hjorthøj C, Sørensen HJ, Fagerlund B, Austin S, Secher RG, et al. Predictors and longitudinal course of cognitive functioning in schizophrenia spectrum disorders, 10 years after baseline: the OPUS study. Schizophrenia Res. 2016;175:57–63.
Rizvi AH, Camara PG, Kandror EK, Roberts TJ, Schieren I, Maniatis T, et al. Single-cell topological RNA-seq analysis reveals insights into cellular differentiation and development. Nat Biotechnol. 2017;35:551.
Nielson JL, Paquette J, Liu AW, Guandique CF, Tovar CA, Inoue T, et al. Topological data analysis for discovery in preclinical spinal cord injury and traumatic brain injury. Nat Commun. 2015;6:8581.
Bruno JL, Romano D, Mazaika P, Lightbody AA, Hazlett HC, Piven J, et al. Longitudinal identification of clinically distinct neurophenotypes in young children with fragile X syndrome. Proc Natl Acad Sci. 2017;114:10767–72.
Martinuzzi E, Barbosa S, Daoudlarian D, Bel Haj Ali W, Gilet C, Fillatre L, et al. Stratification and prediction of remission in first-episode psychosis patients: the OPTiMiSE cohort study. Transl Psychiatry. 2019;9:20.
Steullet P, Cabungcal JH, Monin A, Dwir D, O’Donnell P, Cuenod M, et al. Redox dysregulation, neuroinflammation, and NMDA receptor hypofunction: a “central hub” in schizophrenia pathophysiology? Schizophrenia Res. 2016;176:41–51.
Hardingham GE, Do KQ. Linking early-life NMDAR hypofunction and oxidative stress in schizophrenia pathogenesis. Nat Rev Neurosci. 2016;17:128–34.
Steullet P, Cabungcal JH, Coyle J, Didriksen M, Gill K, Grace AA, et al. Oxidative stress-driven parvalbumin interneuron impairment as a common mechanism in models of schizophrenia. Mol Psychiatry. 2017;22:936–43.
Yao JK, Keshavan MS. Antioxidants, redox signaling, and pathophysiology in schizophrenia: an integrative view. Antioxid Redox Signal. 2011;15:2011–35.
Cao B, Jin M, Brietzke E, McIntyre RS, Wang D, Rosenblat JD, et al. Serum metabolic profiling using small molecular water-soluble metabolites in individuals with schizophrenia: a longitudinal study using a pre–post-treatment design. Psychiatry Clin Neurosci. 2019;73:100–8.
Cao B, Wang D, Brietzke E, McIntyre RS, Pan Z, Cha D, et al. Characterizing amino-acid biosignatures amongst individuals with schizophrenia: a case–control study. Amino Acids. 2018;50:1013–23.
Oresic M, Tang J, Seppanen-Laakso T, Mattila I, Saarni SE, Saarni SI, et al. Metabolome in schizophrenia and other psychotic disorders: a general population-based study. Genome Med. 2011;3:19.
He Y, Yu Z, Giegling I, Xie L, Hartmann AM, Prehn C, et al. Schizophrenia shows a unique metabolomics signature in plasma. Transl Psychiatry. 2012;2:e149.
Yang J, Chen T, Sun L, Zhao Z, Qi X, Zhou K, et al. Potential metabolite markers of schizophrenia. Mol Psychiatry. 2011;18:67.
Alvarez-Jimenez M, Gleeson JF, Henry LP, Harrigan SM, Harris MG, Amminger GP, et al. Prediction of a single psychotic episode: a 7.5-year, prospective study in first-episode psychosis. Schizophrenia Res. 2011;125:236–46.
Lin A, Wood SJ, Yung AR. Measuring psychosocial outcome is good. Curr Opin Psychiatry. 2013;26:138–43.
Golay P, Baumann PS, Jenni R, Do KQ, Conus P. Patients participating to neurobiological research in early psychosis: a selected subgroup? Schizophrenia Res. 2018;201:249–53.
Wallwork RS, Fortgang R, Hashimoto R, Weinberger DR, Dickinson D. Searching for a consensus five-factor model of the Positive and Negative Syndrome Scale for schizophrenia. Schizophrenia Res. 2012;137:246–50.
Tohen M, Hennen J, Zarate CM Jr., Baldessarini RJ, Strakowski SM, Stoll AL, et al. Two-year syndromal and functional recovery in 219 cases of first-episode major affective disorder with psychotic features. Am J Psychiatry. 2000;157:220–8.
Andreasen NC, Carpenter WT Jr., Kane JM, Lasser RA, Marder SR, Weinberger DR. Remission in schizophrenia: proposed criteria and rationale for consensus. Am J Psychiatry. 2005;162:441–9.
American Psychiatric Association. Diagnostic and statistical manual of mental disorders: DSM-IV. Washington (DC): American Psychiatric Association; 1994.
Singh G, Memoli F, Carlsson G. Topological Methods for the Analysis of High Dimensional Data Sets and 3D Object Recognition. Eurographics Association. 2007;91–100. https://doi.org/10.2312/SPBG/SPBG07/091-100.
Gysin R, Kraftsik R, Boulat O, Bovet P, Conus P, Comte-Krieger E, et al. Genetic dysregulation of glutathione synthesis predicts alteration of plasma thiol redox status in schizophrenia. Antioxid Redox Signal. 2011;15:2003–10.
Conus P, Seidman LJ, Fournier M, Xin L, Cleusix M, Baumann PS, et al. N-acetylcysteine in a double-blind randomized placebo-controlled trial: toward biomarker-guided treatment in early psychosis. Schizophr Bull. 2018;44:317–27.
Alameda L, Fournier M, Khadimallah I, Griffa A, Cleusix M, Jenni R, et al. Redox dysregulation as a link between childhood trauma and psychopathological and neurocognitive profile in patients with early psychosis. Proc Natl Acad Sci. 2018;115:12495–500.
Xin L, Mekle R, Fournier M, Baumann PS, Ferrari C, Alameda L, et al. Genetic polymorphism associated prefrontal glutathione and its coupling with brain glutamate and peripheral redox status in early psychosis. Schizophr Bull. 2016;42:1185–96.
Berg JM, Tymoczko JL, Stryer L. Biochemistry. 5th ed. New York: W H Freeman; 2002. Section 23.3.
Irino Y, Toh R, Nagao M, Mori T, Honjo T, Shinohara M, et al. 2-Aminobutyric acid modulates glutathione homeostasis in the myocardium. Sci Rep. 2016;6:36749.
Soga T, Baran R, Suematsu M, Ueno Y, Ikeda S, Sakurakawa T, et al. Differential metabolomics reveals ophthalmic acid as an oxidative stress biomarker indicating hepatic glutathione consumption. J Biol Chem. 2006;281:16768–76.
Ghosh S, Forney LA, Wanders D, Stone KP, Gettys TW. An integrative analysis of tissue-specific transcriptomic and metabolomic responses to short-term dietary methionine restriction in mice. PLoS ONE. 2017;12:e0177513.
Bonnot O, Klünemann HH, Sedel F, Tordjman S, Cohen D, Walterfang M. Diagnostic and treatment implications of psychosis secondary to treatable metabolic disorders in adults: a systematic review. Orphanet J Rare Dis. 2014;9:65.
Chen EYH, Tang JYM, Hui CLM, Chiu CPY, Lam MML, Law CW, et al. Three-year outcome of phase-specific early intervention for first-episode psychosis: a cohort study in Hong Kong. Early Intervention Psychiatry. 2011;5:315–23.
Golay P, Alameda L, Baumann P, Elowe J, Progin P, Polari A, et al. Duration of untreated psychosis: Impact of the definition of treatment onset on its predictive value over three years of treatment. J Psychiatr Res. 2016;77:15–21.
Niendam TA, Sardo A, Savill M, Patel P, Xing G, Loewy RL, et al. The rise of early psychosis care in California: an overview of community and university-based services. Psychiatr. Serv. 2019;70:480–7.
Rasmussen SA, Rosebush PI, Mazurek MF. Does early antipsychotic response predict long-term treatment outcome? Hum Psychopharmacol Clin Exp. 2017;32:e2633.
Alameda L, Golay P, Baumann P, Morandi S, Ferrari C, Conus P, et al. Assertive outreach for “difficult to engage” patients: a useful tool for a subgroup of patients in specialized early psychosis intervention programs. Psychiatry Res. 2016;239:212–9.
Conus P, Cotton S, Schimmelmann BG, McGorry PD, Lambert M. The First-Episode Psychosis Outcome Study: premorbid and baseline characteristics of an epidemiological cohort of 661 first-episode psychosis patients. Early Intervention Psychiatry. 2007;1:191–200.
Chang WC, Lau ESK, Chiu SS, Hui CLM, Chan SKW, Lee EHM, et al. Three-year clinical and functional outcome comparison between first-episode mania with psychotic features and first-episode schizophrenia. J Affect Disord. 2016;200:1–5.
Foussias G, Agid O, Fervaha G, Remington G. Negative symptoms of schizophrenia: clinical features, relevance to real world functioning and specificity versus other CNS disorders. Eur Neuropsychopharmacol. 2014;24:693–709.
Albert N, Bertelsen M, Thorup A, Petersen L, Jeppesen P, Le Quack P, et al. Predictors of recovery from psychosis: analyses of clinical and social factors associated with recovery among patients with first-episode psychosis after 5years. Schizophrenia Res. 2011;125:257–66.
Cacciotti-Saija C, Langdon R, Ward PB, Hickie IB, Guastella AJ. Clinical symptoms predict concurrent social and global functioning in an early psychosis sample. Early Intervention Psychiatry. 2018;12:177–84.
Üçok A, Serbest S, Kandemir PE. Remission after first-episode schizophrenia: results of a long-term follow-up. Psychiatry Res. 2011;189:33–7.
Berk M, Copolov D, Dean O, Lu K, Jeavons S, Schapkaitz I, et al. N-acetyl cysteine as a glutathione precursor for schizophrenia-a double-blind, randomized, placebo-controlled trial. Biol Psychiatry. 2008;64:361–8.
Farokhnia M, Azarkolah A, Adinehfar F, Khodaie-Ardakani MR, Hosseini SM, Yekehtaz H, et al. N-acetylcysteine as an adjunct to risperidone for treatment of negative symptoms in patients with chronic schizophrenia: a randomized, double-blind, placebo-controlled study. Clin Neuropharmacol. 2013;36:185–92.
Acknowledgements
We are grateful to Gloria Reuteler, Adeline Cottier, and Hélène Moser for expert technical assistance and to all collaborators of the Section ‘E. Minkowski’ for their precious help in recruiting patients. We would like to thank all patients for their enduring participation. This work was supported by the Swiss National Science Foundation (320030_122419 to PC and KQD), National Center of Competence in Research (NCCR) “SYNAPSY—The Synaptic Bases of Mental Diseases” financed by the Swiss National Science Foundation (n° 51AU40_185897). We are grateful for support from the Damm-Etienne and the Alamaya Foundations. PSB was financially supported by Leenaards Foundation. We acknowledge access to Ayasdi Core Software platform (Ayasdi, Menlo Park, California). MS was partially supported by the Wallenberg AI, Autonomous Systems and Software Program (WASP) funded by the Knut and Alice Wallenberg Foundation.
Author information
Authors and Affiliations
Contributions
MF, MS, PC, KQD, and KH conceived, planned, and designed the study. MCx, RJ, CF, and PSB recruited patients and collected clinical data. MF, MCd, and KQD designed, performed, and analyzed biochemical data. MF, MS, MMG, and PG performed the statistical analyses. MF, MS, PC, KQD, and KH interpreted the results. MF, MS, MCd, PC, KQD, and KH wrote the paper with contributions from all authors.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Fournier, M., Scolamiero, M., Gholam-Rezaee, M.M. et al. Topology predicts long-term functional outcome in early psychosis. Mol Psychiatry 26, 5335–5346 (2021). https://doi.org/10.1038/s41380-020-0826-1
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41380-020-0826-1
