
Abstract
Background
In modern societies, noise is ubiquitous. It is an annoyance and can have a negative impact on human health as well as on the environment. Despite increasing evidence of its negative impacts, spatial knowledge about noise distribution remains limited. Up to now, noise mapping is frequently inhibited by the necessary resources and therefore limited to selected areas.
Objective
Based on the assumption, that prevalent noise is determined by the arrangement of sources and the surrounding environment in which the sound propagates, we build a geostatistical model representing these parameters. Aiming for a large-scale noise mapping approach, we utilize publicly available data, context-aware feature engineering and a linear land-use regression (LUR) model.
Methods
Compliant to the European Noise Directive 2002/49/EG, we work at a high spatial granularity of 10 × 10-m resolution. As reference, we use the day–evening–night noise level indicator Lden. Therewith, we carry out 2000 virtual field campaigns simulating different sampling schemes and introduce spatial cross-validation concepts to test the transferability to new areas.
Results
The experimental results suggest the necessity for more than 500 samples stratified over the different noise levels to produce a representative model. Eventually, using 21 selected variables, our model was able to explain large proportions of the yearly averaged road noise (Lden) variability (R2 = 0.702) with a mean absolute error of 4.24 dB(A), 3.84 dB(A) for build-up areas, respectively. In applying this best performing model for an area-wide prediction, we spatially close the blank spots in existing noise maps with continuous noise levels for the entire range from 24 to 106 dB(A).
Significance
This data is new, particular for small communities that have not been mapped sufficiently in Europe so far. In conjunction, our findings also supplement conventionally sampled studies using physical microphones and spatially blocked cross-validations.
Similar content being viewed by others

Introduction
Today, noise is ubiquitous—it is prevalent in and around urban areas (see [1]) and even pervades remote protect areas [2]. Multiple studies have shown its influence on annoyance, stress and subsequent cardiovascular diseases, sleep disturbance, and further impairments [3,4,5], as well as impacts on animals [6] and ecosystems in general [7]. Thereby, noise emitted from infrastructures such as roads, airports or from industries is not spatially distributed equally but confined to specific areas. Consequently, noise affects the population to a varying degree depending on their place of residence and spatial behavior. In fact, multiple studies in the domain of environmental justice have found that noise exposure is particularly affecting social groups of lower socioeconomic position [8,9,10,11].
In Europe, noise pollution has received increasing societal and political attention leading among others to the establishment of the European Noise Directive (END) [12]. Noise, however, is highly complex in its spatial and temporal variability so that quantification and mapping is challenging. Actual field measurements need to be comprehensive and therefore are expensive. However, sophisticated engineering methods can be deployed to map simulated noise [13, 14]. Provided with detailed traffic information and subsequently with data describing the environment, these source–path–receiver-based simulations are known to be very accurate. In accordance with the END, this approach is deployed to generate strategic noise maps every 5 years in Europe. Amongst other parameters, these maps include Lden, the yearly averaged noise estimate condensing weighted day, evening, and night periods [15], specific to individual noise emitters (e.g., road traffic) at 4 m above the ground. Notwithstanding its merits though, the END has limitations as well—particular for consecutive exposure studies on regional or even national scale. Road noise, for example, only needs to be mapped in urban agglomerations with more than 100,000 inhabitants ([12] art.3 sec. k) and for rural areas along major roads with more than 3,000,000 vehicles per year ([12] art.3 sec. n). Therefore, predominantly no noise data are available for smaller urban areas and other roads in peripheral areas. In regards to environmental health equity though, the incomplete data bases of rural areas distort direct comparisons of affected populations [16]. Also, where a large city physically grew outside its administrative boundaries [17], areas not mapped Lden > 55 dB(A) correspond to the two separate END sections k) and n) of article 3 and thus have different semantics as well: inside the boundaries, these areas represent Lden < 55 dB(A), whereas in the suburbs, these areas actually were not mapped at all. The epidemiological analysis of exposure to noise therefore often remains spatially partial, or too aggregated.
For such studies, we aim at leveling data inequities and search for a scalable noise mapping approach. In, but particularly outside Europe, epidemiologists extrapolate microphone measurements using kriging (e.g., [18]) and land-use regressions (LURs) [19,20,21,22,23,24,25,26]. Both approaches are relatively inexpensive but comparing them, Xie et al. [19] have found LUR models produce better results. Thereby LUR, initially developed to assess the exposure of air pollution [27], integrate multiple spatial predictors into a statistical model. After preprocessing (i.e., log-transformations, feature selections, etc.), a statistical model is fitted, which conclusively can be used to estimate noise exposure. Building on the fact that Aguilera et al. [21] found high correlations between in situ noise measurements and END compliant noise maps, we utilize the latter Lden to learn a LUR model and transfer the encoded information to surrounding areas. Thereby, likewise referring to virtual microphones, we investigate the implications of different sampling schemes, i.e., sizes and localizations, by repeating the procedure 2000 times. With this, overall 185,000 samples were drawn and tested for quantifying statistical uncertainties. In particular, as spatial autocorrelation is a distinct matter for local acoustical phenomena, we extend the investigations of Liu et al. [26] by introducing two structured cross-validation approaches [28] for LUR. Blocking samples by specific classes related to urban morphology as well as by administrative districts respectively, a comprehensive set of spatially independent cross-validations allows for assessing the transferability of the model to new, unseen areas. Discussing those last two parameters, sampling scheme and cross-validation, contributes to the development of LURs in general and outside Europe as well. For our study though, the conjunction provides comprehensively benchmarked noise predictions in particular. As a result, a detailed noise map presents continuous exposure levels for peripheral areas not included in the END obligation yet.
Material and methods
After introducing the study area first, we start with compiling the model’s independent predictor variables (highlighted blue in Fig. 1). In order to represent road traffic noise emissions and respective soundwave interactions with the environment, four different inputs are considered—road infrastructures, built-up structures (LoD1), and the natural environment in terms of land cover (LCC) and topology (DEM). In a preprocessing step, these data are integrated matching the 10 × 10-m resolution commonly obliged in European noise studies. As noise may travel over large distances, contextual effects are embraced at eight moving window radii ranging from 12.5 to 1600 m. After the most relevant radius per variable is selected, the predictors are embedded into the modeling. Analogous, simulated noise data are sampled (highlighted in green), later also referred to as virtual microphones. Among four investigated sampling schemes, two stratified approaches required urban land-use categories and noise classes as stratum, respectively. The sampled data sets are described statistically (t-test), before being related to the predictor variables (highlighted orange). During various cross-validations, the parameters are assessed. Last but not least, both the data are used for training a final model, which eventually is applied to a larger area.

Black lines illustrate data flow in general, while gray lines denote auxiliary information needed within individual steps only. Dotted elements denote selection processes.
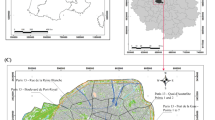
Area of interest
In this study, we exemplify the emission and propagation of traffic noise in and around Koblenz, a German city with 113,844 inhabitants living on 105 km2 [29]. The city of Koblenz represents an excellent case for training the model because of its different types of built structures, the heterogenous natural environment and topography, a diverse road network, and spatially nuanced noise patterns. Id est, its administrative boundaries embrace different structural features from dense built-up morphologies to low-density rural areas, and from flat areas to steep fluvial shaped flanks by the meandering rivers Rhine and Mosel (see Fig. S1).
Further, Koblenz is surrounded by the travel region Rhine valley, defined by the German statistical office (Destatis) and the Federal office for building and regional planning (BBSR). This 924 km2 large geographic entity is situated along the river Rhine, connecting four cities and 56 municipalities with a total population of 773,071 [29]. We chose this area for deploying the final LUR model, as it surrounds the city of Koblenz and shares morphological features with it. That are the suburban structures along the northern river loop (e.g., Vallendar, Bendorf, Neuwied, etc.) in particular, as well as agrestic patterns opening out south. Further, it is interesting to note, that due to major roads most often located parallel to the river and thus outside this touristic appealing region, noise data are rarely available.
Sampling noise simulation data
Due to the expensive nature of noise measurement sampling, the sampling schemes applied in other studies are more often stratified [19,20,21,22, 25, 26, see also Table S1] than random [24]. This is not surprising, as stratified sampling is known to be more cost-effective [30]. According to our knowledge, a systematic sampling approach has not been deployed yet. In both, systematic and random sampling, the sample units are drawn independently from each other with an equal probability such as they can represent the complete data set best (see first two columns of Fig. 2). Particular at smaller sample sizes though, both approaches can lead to relatively large gaps in the sampled area as well. In related literature, sample sizes range from 40 (Girona in [21]), up to 729 (across five cities in [26]). As the importance of locating the samples was stressed from the very beginning of noise-related LURs [15], we simulate its effects in this study with 2000 virtual field campaigns. Thereby, our sampling experiments systematically vary sampling scheme, sample size, and random influences. We considered random, systematic, and two variants of stratified sampling schemes aiming for a comprehensive representation of noise levels. The latter, stratified sampling, is to ensure that the whole population is represented well at reduced collection costs [30]. We reproduce the approach of Chang et al. [25], stratifying based on land-use categories, using the 22 different LU/LC classes defined by the European Urban Atlas [31] as strata. Analogous, as the actual noise data are already prevalent, we also stratified samples based on 5-dB(A) increments (illustrated in column three of Fig. 2). Further, investigating uncertainties due to the sample size, N was increased from 50, 100, 200, 500 to 1000 for each sampling scheme. These Ns are akin to previous studies (see Table S1) and beyond. Regarding stratified sampling though, the scarce outer classes may lead to an actual smaller N eventually sampled (hereafter referred to as Nsampled). To account for bias of random sample generation, we iterate each experiment with 100 different random number seeds. In case of regular sampling, this seed refers to an offset in the sampling grid.

Highlighted dots (purple) represent samples being left out for an individual cross-validation iteration. Colored background illustrates noise levelsused as strata. Dashed red lines depict administrative borders used for blocking the cross-validation.
As reference, we considered EU compliant noise simulations for our virtual campaigns. The local authorities of Koblenz provided us with the simulation results of 2017 (see center Fig. S2). Such maps, fulfilling the END, are produced combining high resolution input data such as traffic information and built-up inventory with ray-tracing propagation models [13, 14]. The engineering’s software output has a spatial resolution of 10 × 10 m, the continuous pixel values depict the simulated road traffic noise Lden. Thereby, the Lden ranges from 12.8 to 88.3 dB(A), with a mean of 51.0 dB(A) and a standard deviation of sd = 11.1. The advantage of using END conform noise maps instead of actual in situ measurements is, that they are source-specific (i.e. road traffic noise) and they provide annually averaged sound pressure levels, which both are the basis for political decision making. Also, the 1.05 million pixels of our study area allow for investigating sampling effects comprehensively, which is important in order to assess the transferability of the model. Due to a heterogeneous infrastructure network as well as different topographic, built-up and natural morphologies, the sound pressure levels, however, are not uniform (see map Fig. S2 or Table S2 for descriptive statistics along all 30 districts, respectively. Table S3 for descriptive statistics with respect to the Urban Atlas), but structured spatially. Two very loud and long-range hearable motorways are allocated in the north-east, affecting large proportions of the adjacent districts. From there, a trunk road runs through the city center in a southerly direction, before finally connecting the eastern parts of the city over the Rhine river. Primary roads are located along the river banks and one (B327) meandering uphill South-southwest. Here it is well depicted, that the scope of noise propagation depends on the surrounding natural environment as well. Zooms b&c in Fig. S2 highlight local effects by highly built-up urban morphology and the topography.
The sampled Lden sound pressure levels are considered virtual microphone measurements. In order to assess the sampling impacts statistically, the representativity of each of the 2000 virtual field campaigns is assess by aggregating their mean and standard deviation first. Then, they were related to the total population using a two-sided t-test assuming the variances to be equal.
Predictor variables
In general, LUR predictors in noise-related studies vary from physical road infrastructures [19,20,21,22,23,24,25,26], traffic information [21, 22, 24,25,26], surrounding buildings [20,21,22,23,24], land-use/-cover patches [19,20,21,22,23,24,25,26], vegetative indices [20, 22, 23, 26], and amongst weather data [25] and topography [26] to any other auxiliary information hypothesized to affect the response variable. Based on this literature and data review (see also Table S1), we inherit the most common features and, aiming for large-scale reproducibility, prioritize publicly-accessible data sources throughout the study. To incorporate contextual effects like the arrangement of streets, built-up density, and fraction of green spaces, moving windows were utilized. The respective aggregation functions (sum, mean, etc.) depend on the variable and their respective geographic rational, which is laid out below. Regarding the radii, preceding studies did not agree on a standardized and commonly accepted rule for defining them. Nevertheless, the applied radii generally range between 50 and 1000 m and also some particular scales were already used more often (highlighted bold in following enumeration). In relation to the logarithmic behavior of noise attenuation, we thus used systematically scaled radii of 12.5, 25, 50, 100, 200, 400, 800, and 1600 m. Then, following the descriptions of Ragettli et al. [22] and Liu et al. [26] the most relevant radius per feature was selected a priori. To do so, a bivariate linear model was fitted for each available variable. The most relevant radius per variable was chosen based on the smallest root mean square error (RMSE). Thus, together with six road proximity features, eventually 21 features were considered.
Road infrastructure
In this study, we focus on traffic noise emitted along roads. In consequence, the road network and the proximity hereto are essential. We take the spatial layout of the streets from OpenStreetMap (OSM) data. Since data on traffic counts were not available, we considered the assorted functional road types Motorway, Trunk, Primary, Secondary, Tertiary and Residential as proxies for traffic volume capacities and speed limits. We tested the suitability of this metadata by investigating the Lden values at the road center. A subsequent ANOVA tests for significantly different noise levels between the six road types. Then, being coded as dummy variables [32], their effects were added to the model for each road type separately. Hereby we distinguish two effect types—proximity and cumulated road length. In both cases, tunnels were excluded throughout the study [21].
At a scale of 10 × 10-m resolution, the proximities to roads were derived, such as the digital numbers of the grid depict to distance to the nearest road in meters. We consider this raster-based approach, as conducted by Harouvi et al. [24], more sensitive than vectored buffer rings [19,20,21,22,23, 25] and therewith justify the additional computational resources needed. Along these gradients, with increasing distance to the source, sound levels are known to decline on a logarithmic basis [33]. Consequently, the feature space was log-transformed.
In addition, for each location, all neighboring roads were considered. This allows cumulating multiple road exposures such as at intersections and multilane roads. To do so, we first rasterize the input features, where the value of each cell represents the subjacent length of a road multiplied by its number of lanes, as it is recommended in the European Good Practice Guide [34]. Where the latter attribute was not available, it defaults to one. Then, the cumulated road length was summarized [19,20,21,22,23, 25, 26] using the systematically scaled moving windows defined above.
Urban morphology
Buildings and their corresponding volume are also essential for sound propagation [35,36,37]. On the one side, their emission facing façade reflects the sound. This is very well exemplified by dense street canyons, which are known to increase noise levels [38]. Vice versa, on the side of the buildings facing away from the road, sound levels are significantly lower. To include urban morphologies, building footprint and height data are added to the model from the nationwide Level-Of-Detail-1 data set by the Federal Agency for Cartography and Geodesy [39].
Then, using the moving windows defined above, the neighborhood was integrated to the list of predictors by averaging the mean built-up height. Similar to the topographic position index (TPI) introduced by Weiss [40], the values were normalized by subtracting the built-up height of the central pixel. Positive values depict superior locations, while negative values represent locations that are lower than their surroundings (valleys). Therefore, these values correspond to the volume available for sound propagation.
Natural environment
Analogous to the built environment, the surrounding topography has an important influence on sound propagation [41]. Therefore, the EU-DEM [42] was rescaled to the 10 × 10-m resolution using bilinear interpolation. The respective TPI was derived at the above-defined moving window radii as well.
In addition, propagating sound waves interact with the ground surface [43]. While plain and solid surfaces such as water bodies and some artificial material have reflecting acoustical properties, other, soft, or porous material have absorbing effects [41, 44]. In the case of vegetative cover, experiments comparing noise propagation in areas covered with trees against such covered with grass have shown that this effect is proportional to biomass [45, 46]. In our study, we represent the earth’s surface by a remote-sensing-derived land-cover classification [47]. Computed from a multi-temporal Sentinel-2 data set using Land-Use/-Cover Area frame Survey reference samples, this publicly available product with an overall accuracy of 93.1% has the same spatial properties as the reference units defined above. It includes seven land-cover classes expected to be important for noise mapping: artificial land, open soil, water areas, and detailed information about vegetative biomass and its seasonality (low perennial, high perennial, low seasonal, and high seasonal vegetation). As a part of the data harmonization process, each land-cover class is treated separately [32]. The moving windows computed the respective land-cover fraction for each given neighborhood radius in percent.
Modeling
To test the potentials and limitations of our various sampling experiments systematically, we have chosen linear least squares regressions. These are most commonly used in this thematic context [19, 21, 23,24,25]. In addition, their computational complexity is manageable. This is relevant for both, repetitive training of our 2000 virtual field campaigns, and prediction. With respect to the 10 × 10-m resolution, it is crucial that the model can be deployed to larger areas of interest. Keeping the focus on sampling artefacts, we selected a simple and consistent model implementation and ruled out variability between the experiments by not considering forwards- (as in [21,22,23, 25]) or backwards-selecting approaches [19, 20, 24, 26].
The model performances are assessed using five complementing variations of cross-validations and three accuracy measures. Cross-validation is a common approach aiming for a statistically independent evaluation, particularly interesting at small sample sizes. Leaving n random samples out, the model is fitted excluding these n samples, and evaluated against them in a subsequent step (c.f. rows in Fig. 2). Herewith an independent measure is available in order to quantify the transferability of the model. Typically (as in [20,21,22, 25, 26] n is one (hereafter revered to as LOOCV) or (as in [19, 24, 26]) a fraction, e.g., 10% random samples (hereafter referred to as leave-group-out LGOCV10%). Similar to Liu et al. [26], in this study, we implemented LOOCV, LGOCV10%, LGOCV25%, and LGOCV50%. However, especially when the data are structured, e.g., by landscape, spatial autocorrelation can jeopardize the central assumption that training and evaluation data are independent, such as no conclusions regarding overfitting can be drawn [28]. For such applications, Roberts et al. [28] recommended blocking (although the division do not need to be rectangular) the cross-validation samples accordingly. That is, a model is trained on one proportion of the city and then tested in a new, unseen area. As the spatial transferability is of particular interest in our study, we consider two approaches: LSOCVAdmin leaves out one of the 30 spatial districts of Koblenz at a time and second, LSOCVUrb.Atl. validates the transferability by blocking samples based on the urban settlement structures. This is achieved by utilizing polygon geometries of 22 different LU/LC classes from the European Urban Atlas data set [31] as blocks.
We evaluate the models’ accuracies by calculating the coefficient of determination (R2), root mean squared error (RMSE) and mean absolute error (MAE). During the cross-validations, the accuracy metrics were summarized into mean and standard deviation. Further, for each sampling experiment we fit an overall model including all samples. Although the accuracy metrics for this model do not indicate its transferability, it is presumed to be the best trained one and should be deployed on new data [28]. The discrepancy between the cross-validated and overall accuracy metrics indicate the internal validity of a model [25]. According to Eeftens et al. [48], a R2 difference of <0.15 resembles a robust model. Eventually, after selecting a final model based on these evaluations, it was deployed to the neighboring communities in the Rhine valley.
Results
Predictor variables
Road infrastructure
In particular, the OSM roads have to be examined in detail for their suitability as eminent proxies. Along their spatial representation, the six individual road types differentiated in OSM indicate different traffic intensities, speed limits, and road surface properties. To ensure that this classification was an appropriate representation of the resulting noise emissions, Lden at a distance of 0 m, id est on the road itself was investigated. Despite some larger standard deviations for tertiary and residential roads, Table 1 reports that all road types have individual noise levels in terms of mean and median. This observation is empirically backed by a corresponding, highly significant (p < 0.001) ANOVA analyses. Although visually some overlaps exist, the subsequent Tuckey test finds significant (p < 0.001) difference between all road types.
Starting with a distance of 0 m, the proximity with respect to residential roads ranged up to 2 km, respectively, 12 km as to motorways (see log10-transformed values in Table 2). As the proximity to roads showed an exponential relationship toward Lden, a log transformation was required [21, 24, 25]. After the preprocessing, the Shapiro–Wilk test certifies a normal distribution for all individual road types (p < 0.001).
Selected variable radii
Further, Table 2 presents the other selected variables, as well. We obtain multiple neighboring contexts for each predictor. Following the procedure of Ragettli et al. [22] and Liu et al. [26], we identified the most appropriate radii by the lowest RMSE in bivariate models. The subscripts depict the selected moving window size for each variable. It turned out that the influence range on the resulting sound field lies between 100 and 1600 m, respectively.
Sample localization
By permuting the four individual sampling schemes at five sample sizes and reproducing with 100 different random number seeds, a total of 2000 independently sampled data sets were produced. As stated before, the utilized noise input values had a mean of 51.0 dB(A) and a standard deviation of 11.1. In comparison thereto, not all sample sets comply. Figure 3a depicts that in general the magnitude of deviations highly depends on random effects, i.e., the seed. Naturally, at larger sample sizes, this effect alleviates. Despite that, the sample schemes show two distinct characteristics: in general, random and systematic sampling both represent the total population well in terms of comparable means and standard deviations. This is empirically backed by high p values (Fig. 3b). Using a systematically gridded sampling scheme, all but two sets (N = 200, seed = 83 and 84) exemplify the mapped noise representatively (p > 0.05). Stratified sampling though, particularly stratifiedLden, returns higher Lden values. The balanced sampling based on urban morphology, stratifiedUrb.Atl., though tends to just slightly overestimate Lden. The two-sided t test attests significant differences (p < 0.05) at larger sample sizes only, replicating a well-known issue of p values [49].

a Depicts mean (Y-axis) and standard deviation (color) of Lden. Dashed lines reference to complete data set. b Shows p value of the consequent Shapiro–Wilk test (Y-axis). Solid line refers to 5% confidence interval.
The integration of these 2000 sample experiments with the aforementioned predictors results in one corresponding LUR model each. To compare them, the three accuracy measures are summarized into mean, standard deviation, as well as the 5% and 95% percentile as a dependency of sample size and sampling scheme in Table S4. Thereby, unaffected by the sampling scheme, two trends were related to the extent: first and congruent to the aforementioned observations, the standard deviation was inversely correlated to sample size. Second, the overall accuracy decreased asymptotically for larger sample sets. This holds true for R2 where values closer to 1 are favored, as well as for RMSE and MAE where small values indicate a good fit. Nevertheless, the R2 of both stratified sampling approaches did so on a higher level, i.e., the R2 of stratifiedLden not falling below 0.78, respectively, 0.74 stratifiedUrb.Atl,, RMSE and MAE certify statifiedLden larger residuals though. These observations were backed by highly significant MANOVAs (p < 0.001 for both, sampling scheme and size) on R2, RMSE, and MAE. The subsequent Tukey tests point out that there was a significant difference between all parameters except increasing the sample size from 500 to 1000 observations (pR² = 0.19, pRMSE = 0.80, pMAE = 0.97).
Cross-validations
Examining the transferability of a model to unseen samples (Fig. 4), the four randomized approaches perform notably different to the two spatially independent LSOCV concepts. Id est, their cross-validated accuracy measures converge antipodal to the overall models. Eventually, at 1000 samples, the difference between the overall R2 (black lines in Fig. 4) and its cross-validated pendant (colored lines in Fig. 4), fell below the level of 0.15 (specified by 25 and 48) for all but the two LSOCVs at both stratified sampling schemes. Coefficients of determination retrieved using LSOCVAdmin. were relatively high at lower sample sizes, but then drastically decreased at sample sizes >200. In contrast to this, the mean R2 of LSOCVUrb.Atl. remained steadily within a range of 0.55 and 0.64, but showed obtrusive values at N = 50 for the stratified sampling scheme based on the same strata. Considering the averaged RMSE and MAE, LGOCV50% stands out in particular. However, no differentiating trends could be observed between spatial and conventional cross-validation approaches.

With respect to R², RMSE and MAE, each point condenses the means of 100 repetitions.
Final model
In our geographical application, we aim to model our complete test area. For this, we select a specific model. In order to minimize random effects, such as discussed above, only the largest sample sizes were considered (N = 1000). Further, aiming for a high accuracy, stratifiedUrb.Atl. was selected. Although the respective R2 tends to be marginally lower compared to stratifiedLden, the significant smaller residuals depicted in the RMSE and MAE outweigh these considerations. At these settings, the overall R2 was 0.702, adjusted R2 0.696, respectively. All accuracy metrics are presented in Table 3.
In particular for subsequent map interpretation and decision making, it is of interest to assess the parameters of the final model. Starting with describing the estimated intercept, the linear regression model assumes a very high Lden of 130.78 dB(A). Subtracting thereof, the regression terms regarding the log-transformed proximity to all but residential roads had negative estimates. As can be seen in Table 4 though, these were insignificant in respect to proximity to secondary and tertiary roads. Where many motorways or tertiary roads were in close vicinity, Lden is lower; in contrast thereto, an accumulation of the other road types comparatively increases noise levels. Contemplating the other variables, not related to traffic noise emissions, a small but highly significant (p < 0.001) estimate of −0.04 for the topographic TPI1600 indicates that increased noise levels can be found in valley locations. Analogous, the negative estimate (β = −0.218) regarding TPI800 for buildings is congruent to the findings of Heutschi [38], but insignificant (p > 0.1). Land cover [47] was a significant parameter for four out of the seven land-cover classes (p < 0.10): for example, low, perennial vegetation reduced Lden by −0.17 dB(A) per percentage fractional cover within a radius of 800 m, respectively, −0.09 dB(A) for high but seasonal vegetation at the same radius. The full model is presented in Table 4.
To comprehend this model further, a subsequent assessment of the residuals though showed that most of the modeled values within the range of 35–75 dB(A) align well to the official road Lden (Fig. S3c). As is visualized by the width of the boxplots, this concerns the majority of pixels. The spatial representation (Fig. S3a) of the residuals depicts two distinct issues. Large positive residuals can be found along certain roads, where in officially higher noise levels occur. Conversely, large negative residuals are found in otherwise quiet canyons. Analogous, a tendency toward smaller negative residuals was found in backyards of residential blocks, indicating that it is potentially quieter here. Putting the residuals into place, we last but not least intersected them with our building model. With respect to these vulnerable areas, the supplementary histogram (Fig. S3b) shows that actually 44% of them have an error ranging between −2.5 and 2.5 dB(A) at most. In summary, we only found an exposure-specific MAE of 3.84 dB(A) here.
The selected final model was then deployed on the urban, peri-urban, and rural regions of Koblenz and surroundings. The map (see Fig. 5) shows that 90.8% of the Rhine valley are below the threshold of 55 dB(A). With respect to exposed populations in particular, the same is true only for 79.2% of the build-up areas. An example of such is visualized for the flat and highly populated city Neuwied (Fig. 5a), bordering in the northwest of Koblenz. Moreover, our results also show that in close vicinity to the Rhine, where primary roads can be found on both river sides, such critical noise levels can be found in peripheral regions as well (Fig. 5b). Vice versa, it is interesting to see at the example of Bacharach (Fig. 5c) that existing noise preventive planning such as bypass roads are highly effective. Id est, this example illustrates very well how built-up structures can block propagating noise. However, some noise is still emitted along the village’s main road itself, particular in the northern part. But, this does not exceed the critical threshold of 55 dB(A) Lden. In summary, the resulting final noise map provides valuable insights about possibly affected populations in suburban and peripheral areas.

Zooms show (a) highly dense suburbs and (b) low populated villages along the river Rheine, as well as (c) an exemplary detail at very low scale. Continuous colorscheme akin to DIN 18005, dotted line depicts 55-dB(A) contour, build-up areas are colored white.
Discussion
In this study, we transferred noise information encoded in official noise maps to statistical models. Thereby, the very details of sampling noise, in this case evaluated using thousands of virtual microphones, and their influence was assessed. In contrast thereto, a small feature set was held constant. Overall, the model proves accurate results for a large-scale area. However, some critical aspects of our approach are to be pointed out: when subsampling END conform noise for training LURs, two issues arise: first, as LURs usually are used to extrapolate in situ noise measurements into larger areas, one may discuss training them with Lden maps. In this study, we substituted in situ noise measurements with Lden maps and could show that generally existing noise map can be predicted beyond its administrative limitations to estimate respective noise exposure levels for surrounding areas at low costs. Second, one needs to be aware that errors and methodical shortcomings of this input source will propagate. EU compliant calculation methods are configured conservatively, such that the predicted noise levels and the consecutive number of people exposed to noise both are overestimated (cf. [34]). In addition, it needs to be noted that Lden quantifies noise exposure dosage but insufficiently predicts health relevant noise annoyance [50]. Therefore, we need to be aware that a finer temporal resolution of noise levels, e.g., 10 min, 1 h, etc., or quantifying significant noise peaks is not included in the analysis, but would be interesting from an epidemiological point of view [51].
In addition, and also relevant for conventionally sampled LUR studies, important methodical aspects could be tested with this approach. Random and systematic sampling schemes both retrieve the most representative samples. However, they both were sensitive to random effects and require larger sampling sizes—probably impracticable for time and cost expensive field campaigns. Stratified sampling on the other hand is sensitive to the precise sampling scheme. Referring to sample size only, we found no significant model improvement for N > 500. Stochastically, 500 samples in our 105 km2 large area refers to a Euclidean distance of 458 m between the virtual microphones. Most probably due to wireless sensor networks [52], such dense sampling strategies appear economically feasible for limited areas. For assessments on national levels or the like, however, this still is not the case and will be difficult to achieve. Thus, END conform that predicted noise maps are an alternative.
Further, on smaller scopes, the spatial distribution of noise can be both, clustered i.e., along line sources as well as disperse. Such spatial autocorrelation is known to challenge statistical modeling and can jeopardize the assumptions of cross-validations [28, 53]. Particularly at larger sample sizes, the cross-validated accuracy measure converges with the overall models’ R2. As this effect was best observed with stratified sampling, where especially very loud samples were limited and therefore in close vicinity, we infer it being caused by spatially neighboring samples. Confirming the experiences made in ecological studies [28], the informative value of conventional leave-n-out cross-validations may be limited in such structured data. Only LSOCV does encounter jeopardizing the credibility of CV in regards of actually assessing overfitting. Nevertheless, the administrative blocking proved holding out circumscribed portions of the predictor space, i.e., very loud motorways in the peripheral, north eastern district of Rübenach. In such cases, the model needs to extrapolate into unknown administrative areas. The same holds true for LSOCVUrb.Atl, where we specifically challenged the model to transfer into unknown settlement structures. In both cases, the accuracy measures retrieved with the cross-validations actually reflect these transfer abilities. To reduce further covariations in the data introduced by proactive landscaping, likewise other spatial blocking concepts, such as rectangular, hexagonal, or radial, may be considered in future.
Aiming for an easy reproducible study design, the model focused on road-related traffic noise. Therefore, the predictor variables scope road infrastructures, urban morphology and the natural environment only. Although this variable set is relatively small, nevertheless it was capable of explaining large proportions of the overall variance. Moreover, similar to the models of Harouvi et al. [24], proximity of the traffic-related features is more significant than the cumulated sum. The negative betas of road proximity for example appear logical, as with increasing distance to an emission source, noise levels decrease. For residential roads though, most frequently found in respective residential areas, the proximity thereto was rather an indicator for quietness. A significant correlation (r = −0.87, p < 0.05) between the proximity estimates (Table 4) and the respective mean per road type (Table 1) proves their model integration plausible. Nevertheless, the mapped residuals and the standard deviations shown in Table 1 reveal local constraints when relying on six different functional road types only. Additional information, if available, such as driving speed, traffic volume, and road surface could help declaring these variations. Further, also the urban morphology could be represented in further detail. This could be achieved by invoking shape and landscape metrics. However, alike variables tend to also correlate, such as the linear model may be biased. This is very well exemplified with the cumulated length of residential roads within a radius of 800 m and the land-cover fraction of artificial land at the same radius (r = 0.795, p < 0.001). Last, when selecting the most relevant contextual features, the rather generous radii of the moving windows were surprising. Particular, a radius of 800 m for the TPI of urban morphology does not correspond to the small-scale acoustical phenomena caused by built-up morphology [38] and might have led to insignificant estimates. We assume that the large proportions of sparsely built-up areas were grasped as a major spurious collinearity instead of a local detail by the overall linear feature selector. We thus apprehend, selecting features based on univariate regression models as suggested by Ragettli et al. [22] and Liu et al. [26] cannot meet the multifactorial relationships observed. Second, with respect to the observed residuals, the linear regression was not capable of coping with acoustical phenomena such as reflections, refractions, and shadowing effects. While this could be encountered by a larger and more complex feature space, more elaborate models capable of grasping higher dimensional interactions need to be considered in the future. First steps in this direction were presented by Liu et al. [26] comparing random forest regressions against generalized additive models. Considering ongoing developments in computer sciences, deep convolutional neural networks hold immense potential. In the combination of the aspect mentioned above, future works shall investigate models more robust in regards to collinearity, such as they are capable of considering multiple contextual scales altogether. The deployment of a linear model here, however, was important to investigate the sampling schemes and their consequential artefacts.
The resulting broad scale noise assessment is novel for most of the small communities in the Rhine valley and fills a previously blind spot spatially. Further, congruent to our continuous base data, the predicted map depicts local variances below of the critical mapping threshold of 55 dB(A) and therefore enables analysis of environmental justice in higher granularity for the suburban parts in the Rhine valley as well. The subsequent residual analyses revealed that the most common noise levels between 35 and 75 dB(A) Lden were estimated concurrent to the conventional END conform map. With respect to exposure sciences, it is important to note that overall the map lacks accuracy for very loud and quite areas, respectively. In addition, the error was found to be lower for built-up areas in particular.
Conclusion
In general, noise is a complex phenomenon, consisting of emission, propagation, and interactions with the environment. Therefore, the—very accurate—engineering noise mapping methods are highly sophisticated (see [14]) but technically inapplicable for large-scale epidemiological studies [21]. In this study we showed, however, that the acoustical phenomena being encoded in such END conform maps can be used to train statistical models, also known as LURs. Subsequent extrapolations can then be applied to estimate noise accurately at comparably low costs.
Yet, utilizing this most valuable data source, we were able to show that sampling design has a major impact on such models. Regarding the models’ predictive power, we conclude that the decreasing overall R2 at larger sample sizes reflects the complexity of acoustical phenomena. In few cases, smaller sample sizes could grasp them, but most probably lead to oversimplifying these physical mechanisms. This effect was most visible observed at N = 50 and LGOCV50%, where only 25 points were used to carry the regression, but dramatically underperformed during the validation. Vice versa, due to spatial autocorrelation, very large sample sizes compromise conventional leave-n-out cross-validation approaches. Following the guide by Roberts et al. [28], we recommend spatially blocked cross-validations. However, as each cross-validation approach tests distinct transfer abilities, we conclude the combined evaluation of multiple CV approaches being most meaningful. Last but not least, as to the unmet discrepancy between END conform noise maps and the reproductions using LUR, we acknowledge further development possibilities related to feature space and model architectures. Eventually, the aim must be to enable large-scale noise pollution assessments of previously excluded areas. Only then, affected populations can be identified and subsequent noise attenuation measures may be taken.
References
European Environment Agency. Environmental noise in Europe—2020, vol. 22. 2020. p. 104.
Buxton RT, McKenna MF, Mennitt D, Fristrup K, Crooks K, Angeloni L, et al. Noise pollution is pervasive in US protected areas. Science. 2017;356:531–3.
Stansfeld SA. Noise pollution: non-auditory effects on health. Br Med Bull. 2003;68:243–57.
van Kempen EE, Kruize H, Boshuizen HC, Ameling CB, Staatsen BA, de Hollander AE. The association between noise exposure and blood pressure and ischemic heart disease: a meta-analysis. Environ Health Perspect. 2002;110:307–17.
van Kempen E, Babisch W. The quantitative relationship between road traffic noise and hypertension: a meta-analysis. J Hypertension. 2012;30:1075–86.
Brumm H, editor. Animal communication and noise, vol. 2, animal signals and communication. Berlin, Heidelberg: Springer; 2013.
Francis CD, Kleist NJ, Ortega CP, Cruz A. Noise pollution alters ecological services: enhanced pollination and disrupted seed dispersal. Proc R Soc B: Biol Sci. 2012;279:2727–35.
Dreger S, Schüle S, Hilz L, Bolte G. Social inequalities in environmental noise exposure: a review of evidence in the WHO European region. IJERPH. 2019;16:1011.
von Szombathely M, Albrecht M, Augustin J, Bechtel B, Dwinger I, Gaffron P, et al. Relation between observed and perceived traffic noise and socio-economic status in urban blocks of different characteristics. Urban Sci. 2018;2:20.
Havard S, Reich BJ, Bean K, Chaix B. Social inequalities in residential exposure to road traffic noise: an environmental justice analysis based on the RECORD Cohort Study. Occup Environ Med. 2011;68:366–74.
European Commission, Environment Directorate-General, University of the West of England B, Science Communication Unit. Links between noise and air pollution and socioeconomic status. 2016. Available from: http://dx.publications.europa.eu/10.2779/200217.
2002/49/EG. Directive relating to the assessment and management of environmental noise. L 189/12. 2002. Available from: https://eur-lex.europa.eu/legal-content/EN/TXT/HTML/?uri=CELEX:32002L0049.
Steele C. A critical review of some traffic noise prediction models. Appl Acoust. 2001;62:271–87.
Garg N, Maji S. A critical review of principal traffic noise models: strategies and implications. Environ Impact Assess Rev. 2014;46:68–81.
ISO 1996-2:1987. Available from: https://www.iso.org/cms/render/live/en/sites/isoorg/contents/data/standard/00/67/6749.html.
Weigand M, Wurm M, Dech S, Taubenböck H. Remote sensing in environmental justice research—a review. ISPRS Int J Geo-Inf. 2019;8:20.
Taubenböck H, Weigand M, Esch T, Staab J, Wurm M, Mast J, et al. A new ranking of the world’s largest cities—do administrative units obscure morphological realities? Remote Sens Environ. 2019;232:111353.
Aumond P, Can A, Mallet V, De Coensel B, Ribeiro C, Botteldooren D, et al. Kriging-based spatial interpolation from measurements for sound level mapping in urban areas. J Acoustical Soc Am. 2018;143:2847–57.
Xie D, Liu Y, Chen J. Mapping urban environmental noise: a land use regression method. Environ Sci Technol. 2011;45:7358–64.
Goudreau S, Plante C, Fournier M, Brand A, Roche Y, Smargiassi A. Estimation of spatial variations in urban noise levels with a land use regression model. EP. 2014;3:48.
Aguilera I, Foraster M, Basagaña X, Corradi E, Deltell A, Morelli X, et al. Application of land use regression modelling to assess the spatial distribution of road traffic noise in three European cities. J Exposure Sci Environ Epidemiol. 2015;25:97–105.
Ragettli MS, Goudreau S, Plante C, Fournier M, Hatzopoulou M, Perron S, et al. Statistical modeling of the spatial variability of environmental noise levels in Montreal, Canada, using noise measurements and land use characteristics. J Expo Sci Environ Epidemiol. 2016;26:597–605.
Sieber C, Ragettli MS, Brink M, Toyib O, Baatjies R, Saucy A, et al. Land use regression modeling of outdoor noise exposure in informal settlements in Western Cape. South Afr Int J Environ Res Public Health. 2017;14:1262.
Harouvi O, Ben-Elia E, Factor R, Hoogh K, de, Kloog I. Noise estimation model development using high-resolution transportation and land use regression. J Expo Sci Environ Epidemiol. 2018;28:559–67.
Chang T-Y, Liang C-H, Wu C-F, Chang L-T. Application of land-use regression models to estimate sound pressure levels and frequency components of road traffic noise in Taichung, Taiwan. Environ Int. 2019;131:104959.
Liu Y, Goudreau S, Oiamo T, Rainham D, Hatzopoulou M, Chen H, et al. Comparison of land use regression and random forests models on estimating noise levels in five Canadian cities. Environ Pollut. 2020;256:113367.
Hoek G, Beelen R, de Hoogh K, Vienneau D, Gulliver J, Fischer P, et al. A review of land-use regression models to assess spatial variation of outdoor air pollution. Atmos Environ. 2008;42:7561–78.
Roberts DR, Bahn V, Ciuti S, Boyce MS, Elith J, Guillera-Arroita G, et al. Cross-validation strategies for data with temporal, spatial, hierarchical, or phylogenetic structure. Ecography. 2017;40:913–29.
Federal Statistical Office Germany. GENESIS-online. Available from: https://www-genesis.destatis.de/genesis/online.
Wang J-F, Stein A, Gao B-B, Ge Y. A review of spatial sampling. Spat Stat. 2012;2:1–14.
European Environment Agency. Urban Atlas 2018—Copernicus Land Monitoring Service. 2020. Available from: https://land.copernicus.eu/local/urban-atlas/urban-atlas-2018.
Suits DB. Use of dummy variables in regression equations. J Am Stat Assoc. 1957;52:548–51.
Ostashev VE, Wilson DK. Acoustics in moving inhomogeneous media. CRC Press; Boca Raton, Florida; 2015.
European Commission Working Group. Assessment of exposure to noise. Good practice guide for strategic noise mapping and the production of associated data on noise exposure. 2007.
Schady A, Heimann D. Einfluss der Siedlungsform auf die Schallimmission an Fassaden—numerische Simulationen. Lärmbekämpfung. 2018;13:204–10.
Guedes ICM, Bertoli SR, Zannin PHT. Influence of urban shapes on environmental noise: a case study in Aracaju—Brazil. Sci Total Environ. 2011;412-3:66–76.
Wang B, Kang J. Effects of urban morphology on the traffic noise distribution through noise mapping: a comparative study between UK and China. Appl Acoust. 2011;72:556–68.
Heutschi K. A simple method to evaluate the increase of traffic noise emission level due to buildings, for a long straight street. Appl Acoust. 1995;44:259–74.
Federal Agency for Cartography and Geodesy (BKG). LoD1-DE. Available from: https://gdz.bkg.bund.de/index.php/default/digitale-geodaten/sonstige-geodaten/3d-gebaudemodelle-lod1-deutschland-lod1-de.html.
Weiss A. Topographic position and landforms analysis. 2001.
Piercy JE, Embleton TFW, Sutherland LC. Review of noise propagation in the atmosphere. J Acoustical Soc Am. 1977;61:1403–18.
European Environment Agency. EU-DEM v1.1—Copernicus Land Monitoring Service. 2016. Available from: https://land.copernicus.eu/imagery-in-situ/eu-dem/eu-dem-v1.1.
Attenborough K. Sound propagation in the atmosphere. In: Rossing TD, editor. Springer handbook of acoustics. New York, NY: Springer; 2007. p. 113–47.
Aylor D. Noise reduction by vegetation and ground. J Acoustical Soc Am. 1972;51:197–205.
Margaritis E, Kang J, Filipan K, Botteldooren D. The influence of vegetation and surrounding traffic noise parameters on the sound environment of urban parks. Appl Geogr. 2018;94:199–212.
Reethof G. Effect of plantings on radiation of highway noise. J Air Pollut Control Assoc. 1973;23:185–9.
Weigand M, Staab J, Wurm M, Taubenböck H. Spatial and semantic effects of LUCAS samples on fully automated land use/land cover classification in high-resolution Sentinel-2 data. Int J Appl Earth Obs Geoinf. 2020;88:102065.
Eeftens M, Beelen R, de Hoogh K, Bellander T, Cesaroni G, Cirach M, et al. Development of land use regression models for PM 2.5, PM 2.5 absorbance, PM 10 and PM coarse in 20 European study areas; results of the ESCAPE Project. Environ Sci Technol. 2012;46:11195–205.
Royall RM. The effect of sample size on the meaning of significance tests. Am Stat. 1986;40:313–5.
Riedel N, Scheiner J, Müller G, Köckler H. Assessing the relationship between objective and subjective indicators of residential exposure to road traffic noise in the context of environmental justice. J Environ Plan Manag. 2014;57:1398–421.
Can A, Aumond P, Michel S, Coensel BD, Ribeiro C. Comparison of noise indicators in an urban context. 2016;10.
Picaut J, Can A, Fortin N, Ardouin J, Lagrange M. Low-cost sensors for urban noise monitoring networks—a literature review. Sensors. 2020;20:2256.
Telford RJ, Birks HJB. The secret assumption of transfer functions: problems with spatial autocorrelation in evaluating model performance. Quat Sci Rev. 2005;24:2173–9.
Acknowledgements
First, we want to thank the authorities of Koblenz for sharing the simulated noise levels. Further, both, the EU-DEM and the Urban Atlas were produced with funding by the European Union (https://land.copernicus.eu). The LoD1 model was provided by the German Federal Agency for Cartography and Geodesy (BKG, 2015). The administrative borders of the Rhine valley were provided by the Netherlands-palatinates Office for Land Surveying and Geoinformation (www.lvmergeo.rlp.de). Last but not least, we acknowledge Matthias Schultheiss for his support to this work.
Funding
This study was mainly funded by the German Federal Environmental Foundation (DBU). Funding for the project “Noise2NAKOAI” (funding code ZT-I-PF-5-42) was granted by the Helmholtz Association. The funding sponsors had no role in the design of the study, the interpretation, the process of writing of the manuscript, or the decision to publish the study. Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Staab, J., Schady, A., Weigand, M. et al. Predicting traffic noise using land-use regression—a scalable approach. J Expo Sci Environ Epidemiol 32, 232–243 (2022). https://doi.org/10.1038/s41370-021-00355-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41370-021-00355-z
Keywords
This article is cited by
-
EcoLight+: a novel multi-modal data fusion for enhanced eco-friendly traffic signal control driven by urban traffic noise prediction
Knowledge and Information Systems (2023)
