
Abstract
Abused drugs can profoundly alter mental states in ways that may motivate drug use. These effects are usually assessed with self-report, an approach that is vulnerable to biases. Analyzing speech during intoxication may present a more direct, objective measure, offering a unique ‘window’ into the mind. Here, we employed computational analyses of speech semantic and topological structure after ±3,4-methylenedioxymethamphetamine (MDMA; ‘ecstasy’) and methamphetamine in 13 ecstasy users. In 4 sessions, participants completed a 10-min speech task after MDMA (0.75 and 1.5 mg/kg), methamphetamine (20 mg), or placebo. Latent Semantic Analyses identified the semantic proximity between speech content and concepts relevant to drug effects. Graph-based analyses identified topological speech characteristics. Group-level drug effects on semantic distances and topology were assessed. Machine-learning analyses (with leave-one-out cross-validation) assessed whether speech characteristics could predict drug condition in the individual subject. Speech after MDMA (1.5 mg/kg) had greater semantic proximity than placebo to the concepts friend, support, intimacy, and rapport. Speech on MDMA (0.75 mg/kg) had greater proximity to empathy than placebo. Conversely, speech on methamphetamine was further from compassion than placebo. Classifiers discriminated between MDMA (1.5 mg/kg) and placebo with 88% accuracy, and MDMA (1.5 mg/kg) and methamphetamine with 84% accuracy. For the two MDMA doses, the classifier performed at chance. These data suggest that automated semantic speech analyses can capture subtle alterations in mental state, accurately discriminating between drugs. The findings also illustrate the potential for automated speech-based approaches to characterize clinically relevant alterations to mental state, including those occurring in psychiatric illness.
Similar content being viewed by others
INTRODUCTION
A fundamental characteristic of abused drugs is that they alter mental states, sometimes profoundly. These consciousness- and mood-altering effects appear to be intimately involved in motivations to use drugs (Sumnall et al, 2006; Fischman and Foltin, 2006), suggesting they are critically important in addiction. Investigating pharmacologically induced mental-state alterations may also provide insights into the neurobiology of consciousness (Coyle et al, 2012).
As long as drugs have been used, people have attempted to communicate drug-related alterations to mental state through artistic and literary approaches (see, eg, Huxley, 1970). From the scientific perspective, drug effects on human mental states have been studied using two main approaches. The first comprises retrospective descriptive reports (Coyle et al, 2012), which may be affected by inaccurate recall. In addition, descriptive reports are nonstandardized, and hence most readily analyzed qualitatively, an analytic approach that can be time intensive (Coyle et al, 2012) and lacks generalizability (Rice and Ezzy, 1999). Most available descriptive reports are also from instances of drug use that were not blinded, leaving them open to expectancy effects (Mitchell et al, 1996). Conversely, such reports have the advantage of being open-ended, allowing exhaustive examination of different mental-state alterations. The second approach to studying drug-induced mental states is via controlled laboratory studies, typically employing standardized self-report measures to assess whether individuals endorse relevant subjective states (eg, ‘euphoric’) repeatedly throughout the drug experience (Carter and Griffiths, 2009; Fischman and Foltin, 2006). Momentary reporting resolves the issue of biased recall, and standardized instruments allow straightforward quantitative analyses. However, the sensitivity of standardized scales is limited by the mood descriptors included. Moreover, both descriptive reports and self-report assessments rely on access to introspective experiences, as well as motivation and capacity to accurately report them, factors that may vary systematically with drug effects.
A potentially more direct alternative is to investigate speech during intoxication. Several studies have examined the effects of drugs on the quantity of speech emitted (see, eg, Foltin and Fischman, 1988; Higgins and Stitzer, 1986, 1988; Stitzer et al, 1984), but these provide little information about mental-state alterations because they did not examine speech content. Here, we investigate the hypothesis that speech content can provide a unique window into thought, allowing more direct assessment of mental-state alterations due to abused drugs and bypassing issues of measurement and motivation affecting other methods.
In early studies, Adler et al (1998, 1999) manually coded the speech of healthy volunteers after administration of ketamine as a pharmacological model for psychosis. They found that the drug produced disordered speech as identified with clinical ratings. Recent advances in computational measurement allow quantitative speech analysis using automated methods. For example, these methods have been used to detect repetitiveness in speech during ketamine intoxication and in schizophrenia (Covington et al, 2007). Automated graph-based analysis of speech structure was used to distinguish speech in manic patients from that in schizophrenia (Mota et al, 2012, 2014) and automated semantic content analysis was used to detect incoherence in speech in schizophrenia (Elvevåg et al, 2007; Tagamets et al, 2013). Moreover, automated algorithms were able to discriminate between psychedelic drugs at above chance levels based on the content of descriptive reports written after the drug experience (Coyle et al, 2012), raising the possibility that speech emitted during intoxication could be characterized, semantically as well as structurally, with similar methods. Assessing drug-related mental-state alterations with automated speech analysis could add to existing methods in several ways. This approach is not constrained by the measurement instrument or participants’ ability to report their subjective state. It would be less time and labor intensive than qualitative analyses of narratives, and less vulnerable to expectancy and biased recall. Assessing drug-related alterations to mental state broadly, this approach could be used to characterize the effects of emerging, relative to known, drugs.
To assess these possibilities, we employed automated analyses of semantic and structural components of free speech after oral administration of two abused drugs relative to placebo: methylenedioxymethamphetamine (MDMA; ‘ecstasy’; 0.75 and 1.5 mg/kg) and methamphetamine (20 mg). These drugs provide a sensitive assessment of automated speech analyses to measure drug effects because they have both commonalities and differences: they are both psychostimulants, but only MDMA appears to produce unique socioemotional subjective effects related to empathy, friendliness, and interpersonal intimacy (Dumont et al, 2009). Thus, we focused semantic analyses on several specific mental states that might differentiate the effects produced by the two drugs. We tested the hypothesis that the drugs would produce unique semantic as well as structural changes to speech, and that these speech characteristics would accurately discriminate the drugs tested.
Structural aspects of speech (eg, syntax) can be readily measured quantitatively, whereas semantics (ie, the meaning of words) is more elusive. The holistic theory of meaning posits that the semantic content of a word is determined by its relationship to other words in a language (Quine, 1951), partially expressed in dictionaries, thesauri, and similar databases. Specifically, semantic similarity between words can be captured by the frequency of cooccurrence of the words in text corpora, as words with similar or overlapping meaning tend to appear frequently together in consistent discourse (Miller and Charles, 1991). We chose here a well-established implementation of this idea, Latent Semantic Analysis (LSA; Deerwester et al, 1990), to measure how speech semantic content is affected by drug intoxication. Similar approaches have been employed to study schizophrenia (Elvevåg et al, 2007; Tagamets et al, 2013).
This study thus extended previous work by using automated approaches to measure both semantic and structural aspects of speech and by applying these methods to the assessment of drug-induced mental-state changes. In addition, we employed multivariate machine-learning methods to assess whether speech characteristics identified could differentiate between drug conditions at the level of the individual.
MATERIALS AND METHODS
Participants
Healthy volunteers (18–38 years old) reporting ecstasy use ⩾ twice were recruited with advertisements. Candidates underwent comprehensive medical and psychiatric screening and were excluded for: psychiatric disorder (DSM-IV current Axis 1 diagnosis); medical illness; body mass index outside 18.5–30 kg/m2; first-degree relative cardiovascular illness; prior adverse ecstasy response; and pregnancy/lactation. All participants provided written informed consent, and were debriefed at completion. Procedures were approved by the University of Chicago Institutional Review Board.
Design and Protocol
The design was within subject, double blind, and randomized, with four 5-h sessions in which participants received MDMA (0.75 mg/kg (MDMA0.75) or 1.5 mg/kg (MDMA1.5)), methamphetamine (20 mg; METH), or placebo (PBO). Before sessions, participants abstained from: food consumption for 2 h; cannabis for 7 days; alcohol or medications for 24 h; and all other illicit drugs for 48 h. Recent drug use was verified with urine (QuickTox Drug Screen Dipcard, Branan Medical Corporation, Irvine, CA), saliva (Oratect III, Branan Medical Corporation), and breathalyzer (Alco-sensor III, Intoximeters, St Louis, MO) tests. Females were tested for pregnancy at each session (Aimstrip, Craig Medical, Vista, CA).
Sessions were conducted in the afternoon in a comfortable laboratory environment. At arrival, baseline cardiovascular and self-report subjective measurements were collected, after which participants ingested a size 00 gelatin capsule containing MDMA hydrochloride (David Nichols, Purdue University) or methamphetamine hydrochloride (Desoxyn, Ovation Pharmaceuticals, Chicago, IL) with lactose or dextrose. Placebo capsules contained filler. Cardiovascular and mood measurements were obtained repeatedly throughout the session, and subjects completed behavioral tasks beginning 65 min after the capsule (see Bedi et al, 2010). At 130 min after the capsule, subjects completed the free speech task (below), providing the data used here. Tasks were scheduled during the expected period of peak drug effects (Cami et al, 2000).
Assessment Measures
During the free speech task, participants spoke to a research assistant for 10 min (average words=784) about a person of importance in their life, and the speech was recorded. The person of importance was selected randomly from a list of four people provided by the participant at the beginning of the study (Wardle et al, 2012). A different person was discussed in each session. Research assistants trained in active listening applied skills such as paraphrasing and reflecting feelings to minimize their impact on speech content. The same assistant interviewed each participant across sessions.
Analytic Approach
A professional transcriber blind to drug condition manually transcribed audio recordings. We preprocessed each transcribed interview using the Natural Language Toolkit (NLTK; Bird et al, 2009). First, we identified individual words in the text, discarding punctuation marks, resulting in a list of words for each text, with repetitions. We then parsed each interview into sentences, and identified the parts of speech (eg, nouns) using the Treebank tagger supplied by NLTK. We then lemmatized each word using the WordNet lemmatizer from NLTK: this corresponds to converting words into the root from which they are inflected. We have previously found that word lemmatizing facilitates robust measurement of abstract concepts and topological features in texts (Diuk et al, 2012; Mota et al, 2012). Preprocessing resulted in a list of lemmatized words, each one in a new line maintaining original order, in lowercase and without punctuation marks or symbols. Each interview thus resulted in a string of N tokens {wi}={w1,w2,…,wN} to be later fed to the semantic and structural analyzers.
The analytic strategy was as follows: (1) transcripts were assessed for semantic proximity to several relevant concepts, chosen to approximate the subjective effects produced by MDMA (Bedi et al, 2009, 2010); we assessed for group-level effects of drug condition on these semantic proximity values; (2) we employed a machine-learning approach to classify drug conditions to determine whether a combination of the semantic proximity values could predict drug condition in the individual subject; and (3) we used a graph-based approach to assess whether the drugs altered structural components of speech.
Semantic proximity to the concepts of interest
As noted above, meaning can be understood as arising from mutual dependencies of words within a language, as partially captured by dictionaries, thesauri, and similar databases (Ferrer i Cancho and Solé, 2001; Quine, 1951; Sigman and Cecchi, 2002). Therefore, any attempt to identify the presence of a particular concept in a text requires considering its distributed semantic sense, as opposed to a simple word count. Several methods have been introduced to obtain a notion of semantic proximity (Fellbaum, 2010; Lund and Burgess, 1996; Patwardhan et al, 2003; Pedersen et al, 2004). One of the more widely used resources is LSA (Deerwester et al, 1990). LSA is a high-dimensional associative model that captures similarity between words by assuming that semantically related words will necessarily cooccur in texts with coherent topics.
LSA generates a linear representation of the semantic content of words based on their cooccurrence with other words in a text corpus. If the corpus is sufficiently large and diverse, the frequency of cooccurrence of words across different documents represents the extent to which the words are semantically related (Landauer and Dumais, 1998). The input to LSA is a word-by-document occurrence matrix X, with each row corresponding to a unique word in the corpus (N total words) and each column corresponding to a document (M total documents). Using singular value decomposition (SVD), the dimensionality of this matrix is reduced to a smaller number of columns, preserving as much as possible the similarity structure between rows. Formally, using SVD, we obtain a decomposition (U, S, V) cropped to k dimensions. By reducing dimensionality, each word is projected into a space where semantic ‘meaning’ is just its corresponding vector. The similarity in meaning between two words (or semantic proximity) can be measured by calculating the cosine between the corresponding vectors. That is, similarity between two words is computed as the dot product  , where the vectors are the SVD representation of the words a and b. As the vectors are normalized, the range of possible values for the similarity measure is (−1, 1).
, where the vectors are the SVD representation of the words a and b. As the vectors are normalized, the range of possible values for the similarity measure is (−1, 1).
For our text corpus, we used TASA, a collection of educational materials compiled by Touchstone Applied Science Associates. TASA includes 37 651 documents and 12 190 931 words, from a vocabulary of 77 998 distinct words. TASA consists of general reading texts believed to be common in the US educational system up to college, including a wide variety of short documents from novels, newspapers, and other sources. We lemmatized the TASA corpus using the WordNet lemmatizer from NLTK. After generating the occurrence matrix for TASA, SVD was executed on the term-frequency matrix obtaining the decomposition. As the LSA method proposes, the SVD matrix may be cropped—reducing dimensionality—while conserving the range of the original matrix. The choice of dimensionality is an important factor for success in measuring semantic distance. Landauer and Dumais (1998) studied the effect of the number of dimensions in LSA and obtained maximum performance by retaining around 300 dimensions, the number we used here. No weights were used for terms in the SVD. LSA analyses employed Text to Matrix Generator software (http://scgroup20.ceid.upatras.gr:8000/tmg/).
The semantic analysis was performed as follows: the proximity to a selection of words related to well-established effects of MDMA {m1,m2,…,mK} was measured for all words in each interview {{d1i},{d2i},…,{dKi}}. The resulting traces were discretized to {0,1} for similarity above a universal threshold of 0.1, resulting in a binary trace {{θ1i},{θ2i},…,{θKi}}. Finally, a mean was computed for each interview  .
.
We selected the words affect, anxiety, compassion, confidence, emotion, empathy, fear, feeling, forgive, friend, happy, intimacy, love, pain, peace, rapport, sad, support, talk, and think to capture a broad range of subjective mood states that have been reported to occur during MDMA intoxication (Dumont and Verkes, 2006). Because psychostimulants increase speech quantity (Wardle et al, 2012), we also computed the total number of words (ie, tokens), or verbosity, in each interview as an additional feature. Group-level drug effects on the mean semantic proximity values for each concept selected were assessed using repeated-measures ANOVA followed by planned comparisons between placebo and active drug conditions, with a significance threshold of 0.05. Effect sizes are presented as partial η2. Analyses were conducted using SPSS 20 (IBM, Armonk, NY).
Although the main analysis used this a priori approach, selecting words hypothesized to be affected by MDMA but not by prototypical psychostimulants, we also conducted a data-driven, ‘black-box’ analysis to demonstrate an alternative approach. The methods and results for the data-driven analysis are in Supplementary Information; see also Supplementary Figure S1.
Prediction of drug condition using pattern classification
Univariate approaches such as that described above carry the possibility of ‘overfitting,’ that is, fitting a model so closely to a specific data set that it cannot generalize to other data. Thus, a classification approach that operates based on overall patterns within the pooled data with stringent cross-validation may be more appropriate. Here, we used an off-the-shelf Support Vector Machine (SVM) classifier. We reduced the problem of binary classification to information provided by the semantic similarity to rapport, love, and support, with the addition of verbosity. We implemented leave-subject-out cross-validation on the data set consisting of N=13 subjects and 4 conditions. More precisely, N discriminative models were computed by learning the parameters on N-1 subjects, and testing on the remaining subject all of the six possible binary classifications. Finally, we implemented a four-way classifier via an off-the-shelf linear discriminant analysis (LDA), using the same leave-subject-out cross-validation scheme, but with rapport, support, intimacy, and friend as semantic similarity measures, plus verbosity. The feature combination in both binary and four-way classifications was obtained by systematic search for the best classification accuracy, among the features with lowest p-values. For the purposes of classification, we applied a standard normalization transformation: each feature was normalized to zero mean for each subject over the four interviews, as a means to control for individual baselines. As mentioned above, we use here a leave-subject-out validation scheme, hence assuming access to the four conditions when testing the predictive model. Analyses were conducted using the classification package in Matlab (MathWorks, Natick, MA).
Graph-based analysis of speech structure
Recently, a graph-based approach for identifying psychosis from speech was introduced (Mota et al, 2012). In brief, a graph can be thought of as a network comprising a series of nodes connected by edges. Applying this approach to speech involves considering individual words to be nodes in this network, whereas edges represent grammatical or semantic relationships linking nodes. In psychosis, the method aims to capture thought disorder in the formal structure of discourse, regardless of the specific meaning of the words. An initial study showed that the differential disorganization of thought in people with schizophrenia and mania can be characterized using topological features of graphs derived from transcribed interviews (Mota et al, 2012).
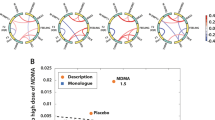
As depicted in Figure 1, we applied this method as follows: the tokens (words) obtained in preprocessing were assigned to nodes in a graph, while a directed edge was assigned from node i to j whenever token i immediately preceded token j in each interview. The resulting graphs were analyzed for topological features including: the number of different tokens/words (Nodes), the number of unique transitions between different nodes (Edges), the number of times the speaker returned to a token/word, going through 0, 1, 2, or 3 other words (loops: L1, L2, L3, L4), the number of edges normalized to number of nodes (mean degree), and the size of largest connected component (a connected component is an ‘island’ such that there is a path that connects any two nodes). To assess group-level differences between drug conditions in these structural speech dimensions, we used repeated-measures ANOVA with planned comparisons between placebo and active drugs.

Participants were asked to speak about someone of importance in their life. Speech graphs were derived such that individual words were assigned to nodes in the graph, while a directed edge was assigned between two nodes (word A and word B) whenever word A immediately preceded word B in an interview. In the example shown, nodes (words) are represented with circles, with edges shown as arrows and sequentially numbered.
RESULTS
A total of 13 participants (4 females) provided consent for speech recording. Mean age was 24.5 (SD=5.4). Of these participants, 11 were Caucasian, 1 was Black, and 1 was of mixed race. Participants reported previous ecstasy use on 12.6 (SD=19.1) occasions; they reportedly smoked marijuana 9.5 (SD=10.8) days/month and drank 7.4 (SD=5.5) alcoholic drinks/week.
Drug Effects on Semantic Proximity to Concepts of Interest
As shown in Figure 2, the drug conditions differed from placebo in semantic proximity to several concepts. Speech after MDMA1.5 had greater proximity to the concepts friend (F(1, 12)=5.7, p=0.03, partial η2=0.32) and support (F(1, 12)=5.3, p=0.04, partial η2=0.31) compared with PBO as well as marginally greater proximity to intimacy (F(1, 12)=4.2, p=0.062, partial η2=0.26) and rapport (F(1, 12)=4.1, p=0.067, partial η2=0.25). Speech after MDMA0.75 had greater proximity to the concept empathy than PBO (F(1, 12)=10.3, p=0.007, partial η2=0.46). Speech on METH had lower proximity to compassion than PBO (F(1, 12)=6.3, p=0.03, partial η2=0.35). There were no significant differences in semantic proximity to the other selected concepts. Speech on METH was higher in verbosity (ie, speech quantity) than speech on PBO (F(1, 12)=5.8, p=0.03, partial η2=0.32).

Effects of MDMA (0.75 and 1.5 mg/kg) and methamphetamine (20 mg) on semantic proximity to selected concepts during free speech. Data are means and SD of semantic proximity values during the transcribed free speech task. PBO, placebo; MDMA0.75, MDMA 0.75 mg/kg; MDMA1.5, MDMA 1.5 mg/kg; METH, methamphetamine 20 mg; *significant differences from placebo (p<0.05); #marginal differences from placebo (p<0.07).
Prediction of Drug Condition Using Pattern Classification
We implemented a SVM classification to assess whether a combination of the proximity values could differentiate drug conditions. Table 1 shows the classification accuracy for the different groupings, with the expected baseline if assignment was random. The highest accuracy classifications were between MDMA1.5 and PBO with 88% accuracy, MDMA1.5 and METH with 84% accuracy, and PBO and METH with 69% accuracy (all over 50% chance). Classification was at chance for the two doses of MDMA, MDMA0.75 and PBO, and MDMA0.75 and METH. Finally, we implemented the four-way LDA classifier, resulting in a classification accuracy of 59% (over 25% chance).
Graph-Based Analyses of the Structure of Speech
Although we did not expect to find evidence of disorganized speech structure after MDMA as was previously observed in psychosis (Mota et al, 2012), we did observe a small but statistically significant difference between METH and PBO in the number of 1-loops (the number of times a speaker returned to a word without going through other words; eg, ‘I…I felt very happy’) normalized by the total edge number. This normalized loop count was lower on METH than PBO (F(1, 12)=6.6, p=0.03, partial η2=0.36), indicating a reduction in returning to a word without going through any other word (Supplementary Figure S2). No other differences in speech structure were observed.
DISCUSSION
Using a novel automated approach, we found that MDMA (0.75 or 1.5 mg/kg) increased the semantic proximity of speech to several concepts relevant to the effects of MDMA, including friend, support, intimacy, rapport, and empathy, all with large effect sizes. Although MDMA altered speech meaning, it did not change its topological structure. Methamphetamine (20 mg) decreased proximity to compassion and increased verbosity. Speech semantic content predicted drug condition at the level of the individual, with the highest accuracy (88%) observed in binary classification between MDMA (1.5 mg/kg) and placebo.
To our knowledge, this is the first study using semantic and topological speech characteristics to study drug-related mental-state alterations. Group-level effects of MDMA on speech content were broadly consistent with purported prosocial effects of the drug (Bedi et al, 2010), supporting the utility of speech analyses to measure mental-state changes caused by drugs. Moreover, most effects were dose dependent, emerging only at the higher MDMA dose. An exception is semantic proximity to empathy, which increased only on the lower dose. An earlier functional Magnetic Resonance Imaging study showed that MDMA (0.75 but not 1.5 mg/kg) enhanced striatal response to positive social stimuli (Bedi et al, 2009). In combination with the present finding, this suggests that dose-related effects of MDMA on social processing should be the focus of future study. Of note, many previous studies on this question used only one MDMA dose (see, eg, Dumont et al, 2009; Hysek et al, 2013).
The neurobiological mechanisms underlying these mental-state alterations, as reflected in speech, are unknown. MDMA produces psychoactive effects primarily via transporter-mediated serotonin release, with euphorigenic effects mediated by interaction with dopamine type 2 receptors (Liechti and Vollenweider, 2001) and a potential role for norepinephrine (Hysek et al, 2011). Data in rodents (Thompson et al, 2007) and humans (Dumont et al, 2009) indicate that oxytocin release is implicated in the prosocial effects of MDMA, potentially through interaction with vasopressin 1A receptors (Ramos et al, 2013). Thus, the effects revealed here may be partially subserved by oxytocinergic mechanisms. Future research could valuably address the psychopharmacological mechanisms of these drug effects on speech.
Importantly, in this study we not only assessed group-level drug effects, but also showed that a multivariate combination of speech characteristics could predict drug condition in the individual subject. This approach, using machine-learning algorithms, also effectively differentiated manic and schizophrenic patients based on speech structure (Mota et al, 2012). Moreover, machine-learning classification discriminated between different types of psychedelic drugs above chance levels based on retrospective drug experience narratives in another study (Coyle et al, 2012). These earlier findings combined with our own support the utility of computational approaches like machine learning to quantitatively characterize complex human behaviors such as speech.
Previous studies show that several drugs alter speech quantity (see, eg, Foltin and Fischman, 1988; Haney et al, 1999; Higgins and Stitzer, 1988; Stitzer et al, 1984). Our finding that methamphetamine increased verbosity is consistent with these findings (see, eg, Wardle et al, 2012). One prior study assessed effects of methamphetamine (20 and 40 mg) and MDMA (100 mg) on speech quantity and manually rated fluency, and found that methamphetamine (20, 40 mg) increased speech quantity whereas methamphetamine (40 mg only) increased fluency. Conversely, MDMA increased duration of filled pauses (eg, ‘um…’), a fluency reduction associated with self-rated concentration problems (Marrone et al, 2010). The present findings are consistent with the increased verbosity after methamphetamine (20 mg). Direct comparison between our findings on speech structure and the earlier results is complicated by methodological differences (eg, we did not quantify pauses, and the prior study did not assess topology). These differences notwithstanding, it is interesting to note that we did not observe disrupted speech structure on MDMA, which is implied by the earlier finding of reduced fluency. However, the graph-based approach we employed can detect altered speech structure related to thought disorder in psychosis (Mota et al, 2012). The lack of such an effect on MDMA therefore suggests that MDMA does not alter the formal structure of speech, although it does affect speech meaning. These findings thus emphasize the need to assess drug effects on speech content to access mental-state changes, rather than measuring only behavioral speech characteristics.
These findings have several potential implications. Given the limitations of existing methods, automated speech analysis could be used as an adjunct to other approaches to better characterize drug-related mental-state alterations. Despite the relatively high computational demands of the analyses, measurement itself is easy to implement. Given the high rates of accuracy discriminating between different drugs, an important potential use could be to characterize new drugs relative to known ones. This appears likely to be increasingly important given the recent proliferation of ‘legal highs’ (Hughes and Winstock, 2012).
As an initial investigation, this study had limitations. The study used two MDMA doses and one methamphetamine dose, and a broader dose-response function would further validate the measure. Second, the number of subjects was small and they were a homogenous group, and the method needs to be tested in a broader sample. Furthermore, we chose the concepts of interest based on the apparently unique effects of MDMA, rather than methamphetamine, which may have contributed to the higher accuracy of classifications including the high MDMA dose. The semantic analysis employed does not require preselection of concepts of interest, and future studies might use a less hypothesis-driven approach. Here, we also illustrate the use of a data-driven, ‘black-box’ analysis in Supplementary Material. Although a priori approaches are more commonly employed in psychiatry and psychopharmacology research, data-driven approaches may yield important insights in the future.
To assess speech structure, we used a graph-based approach previously shown to be sensitive to mental-state alterations in psychosis (Mota et al, 2012). Alternative methods of constructing graphs from speech may have revealed effects of MDMA on speech structure. However, in addition to being sensitive to psychosis (Mota et al, 2012), the method employed detected effects of methamphetamine (see Supplementary Figure S2), supporting its sensitivity. The best method for psychiatric and psychopharmacological applications of automated speech analysis remains an important empirical question for future study. A final limitation relates to inherent limits on the extent to which speech can be understood to comprehensively reflect altered thoughts or mental states. For instance, types of thought such as mental imagery, which may occur frequently during intoxication, are unlikely to be detected via speech analyses. To the extent that thoughts cannot be directly measured, we are also unable to unequivocally state that the changes in speech observed are a direct reflection of altered thoughts or mental states. However, the current data combined with previous work in psychosis (Mota et al, 2012) provide strong support for use of this method to detect altered mental states arising because of drug intoxication or mental illness.
An important question for future research will be the effects of the speech task selected. Here, we employed a task suited to the apparent prosocial effects of MDMA, asking subjects to speak about important people in their life. This task was also selected because of its similarity to psychotherapy, given the recent interest in psychotherapeutic MDMA use (Mithoefer et al, 2011). Conversely, earlier studies asked subjects to describe a dream (Mota et al, 2014; Mota et al, 2012) or a movie (Marrone et al, 2010). Such differences may affect the information that can be drawn from analyses of the speech emitted. The task we employed, which was repeated across sessions (albeit with different individuals as the topic) may have resulted in practice effects, or in variability between sessions that was unrelated to drug effects, because language used to describe a person may vary with the relationship. An alternative approach would be the use of shorter, more constrained language tasks that could be counterbalanced across conditions. Studies addressing the question of which tasks best reveal drug effects on speech will be an important direction for future research. Another relevant factor may be whether the speech is collected during an interaction or a monolog. Although we chose a task likely to tap the prosocial effects of MDMA and endeavored to minimize the interviewer’s impact by blinding them to drug condition and instructing them to use reflective rather than directional interviewing, the effect of using a dialog vs a monolog approach on speech analysis outcomes remains an empirical question. A further focus for future research will be the relationship between automated methods of speech analyses and more traditional, manual approaches to coding.
Although the present study focused on mental-state alterations after drugs, we view these findings as further evidence for the use of automated semantic speech analyses as a unique ‘window’ into the mind in other clinically relevant mental-state changes. Importantly, this approach could potentially assist mental health professionals by providing diagnostic or prognostic information about individual patients. In the earlier study of speech structure, automated analyses accurately discriminated bipolar disorder from schizophrenia (Mota et al, 2012). The present study extends this earlier method with the inclusion of automated content analyses. Other studies support the potential for automated analysis of acoustic features of speech (ie, prosody) to characterize diminished expressivity in psychiatric disorders (Cohen et al, 2012, 2013). A combination of semantic and structural speech characteristics, perhaps including acoustic features (Low et al, 2011; Ooi et al, 2013), when synthesized computationally, could provide fine-grained, previously unavailable data for clinicians on which to base diagnostic, prognostic, and treatment-related decisions.
Such possibilities notwithstanding, these data provide initial evidence for the use of automated semantic speech analysis to characterize alterations to mental state after drugs. MDMA changed the meaning of speech in ways that are consistent with its purported subjective effects. Automated speech analyses could therefore prove a useful addition to existing methods to characterize the wide-ranging, sometimes profound, alterations to consciousness that can be occasioned by drugs of abuse.
FUNDING AND DISCLOSURE
The authors declare no conflict of interest.
References
Adler CM, Goldberg T, Malhotra AK, Pickar D, Breier A (1998). Effects of ketamine on thought disorder, working memory, and semantic memory in healthy volunteers. Biol Psychiatry 43: 811–816.
Adler CM, Malhotra AK, Elman I, Goldberg T, Egan M, Pickar D et al (1999). Comparison of ketamine-induced thought disorder in healthy volunteers and thought disorder in schizophrenia. Am J Psychiatry 156: 1646–1649.
Bedi G, Hyman D, de Wit H (2010). Is ecstasy an ‘empathogen’: effects of MDMA on prosocial feelings and identification of emotional states in others. Biol Psychiatry 68: 1134–1140.
Bedi G, Phan KL, Angstadt M, de Wit H (2009). Effects of MDMA on sociability and neural response to social threat and social reward. Psychopharmacology 207: 73–83.
Bird S, Klein E, Loper E (2009) Natural Language Processing with Python. O'Reilly Media: Sebastopol, CA.
Cami J, Farre M, Mas M, Roset PN, Poudevida S, Mas A et al (2000). Human pharmacology of 3,4-methylenedioxymethamphetamine (“Ecstasy”): psychomotor performance and subjective effects. J Clin Psychopharmacol 20: 455–466.
Carter LP, Griffiths RR (2009). Principles of laboratory assessment of drug abuse liability and implications for clinical development. Drug Alcohol Depend 105: S14–S25.
Cohen AS, Yunjung K, Najolia GM (2013). Psychiatric symptom versus neurocognitive correlates of diminished expressivity in schizophrenia and mood disorders. Schiz Res 146: 249–253.
Cohen AS, Najolia GM, Yunjung K, Dinzeo TJ (2012). On the boundaries of blunt affect/alogia across severe mental illness: implications for Research Domain Criteria. Schiz Res 140: 41–45.
Covington MA, Riedel WJ, Bron C, He C, Morris E, Weinsten S et al (2007). Does ketamine mimic aspects of schizophrenic speech? J Psychopharmacol 21: 338–346.
Coyle J, Presti D, Baggott M (2012). Quantitative analysis of narrative reports of psychedelic drugs. arXiv 1206.0312 [q-bioQM].
Deerwester SC, Dumais ST, Landauer TK, Furnas GW, Harshman RA (1990). Indexing by latent semantic analysis. JASIS 41: 391–407.
Diuk C, Fernandez Slezak D, Raskovsky I, Sigman M, Cecchi GA (2012). A quantitative philology of introspection. Front Integr Neurosci 6: 80.
Dumont GJ, Sweep FC, van der Steen R, Hermsen R, Donders AR, Touw DJ et al (2009). Increased oxytocin concentrations and prosocial feelings in humans after ecstasy (3,4-methylenedioxymethamphetamine) administration. Soc Neurosci 4: 359–366.
Dumont GJH, Verkes RJ (2006). A review of acute effects of 3,4-methylenedioxymethamphetmine in healthy volunteers. J Psychopharmacol 20: 176–187.
Elvevåg B, Foltz PW, Weinberger DR, Goldberg TE (2007). Quantifying incoherence in speech: an automated methodology and novel application to schizophrenia. Schiz Res 93: 304–316.
Fellbaum C (2010). WordNet. In Poli R, Healy M, Kameas A, (eds) Theory and Applications of Ontology: Computer Applications. Springer: Berlin, Germany.
Ferrer i Cancho R, Solé RV (2001). The small world of human language. Proc R Soc Lond B Biol Sci 268: 2261–2265.
Fischman MW, Foltin RW (2006). Utility of subjective-effects measurements in assessing abuse liability of drugs in humans. Br J Addict 86: 1563–1570.
Foltin R, Fischman M (1988). Effects of smoked marijuana on human social behavior in small groups. Pharmacol Biochem Behav 30: 539–541.
Haney M, Ward A, Comer S, Foltin R, Fischman M (1999). Abstinence symptoms following oral THC administration to humans. Psychopharmacology 141: 385–394.
Higgins ST, Stitzer ML (1986). Acute marijuana effects on social conversation. Psychopharmacology 89: 234–238.
Higgins ST, Stitzer ML (1988). Effects of alcohol on speaking in isolated humans. Psychopharmacology 95: 189–194.
Hughes B, Winstock AR (2012). Controlling new drugs under marketing regulations. Addiction 107: 1894–1899.
Huxley A (1970) The Doors of Perception. Perennial Library.
Hysek CM, Schmid Y, Simmler LD, Domes G, Heinrichs M, Eisenegger C et al (2013). MDMA enhances emotional empathy and prosocial behavior. Soc Cogn Affect Neurosci (in press).
Hysek CM, Simmler LD, Ineichen M, Grouzmann E, Hoener MC, Brenneisen R et al (2011). The norepinephrine transporter inhibitor reboxetine reduces stimulant effects of MDMA (“ecstasy”) in humans. Clin Pharmacol Ther 90: 246–255.
Landauer TK, Dumais ST (1998). A solution to Plato’s problem: the latent semantic analysis theory of acquisition, induction, and representation of knowledge. Psychol Rev 104: 211.
Liechti ME, Vollenweider FX (2001). Which neuroreceptors mediate the subjective effects of MDMA in humans? A summary of mechanistic studies. Hum Psychopharmacol 16: 590–598.
Low LS, Maddage NC, Lech M, Sheeber LB, Allen NB (2011). Detection of clinical depression in adolescents’ speech during family interactions. IEEE Trans Biomed Eng 58: 574–586.
Lund K, Burgess C (1996). Producing high-dimensional semantic spaces from lexical co-occurrence. Behav Res Methods Instrum Comput 28: 203–208.
Marrone GF, Pardo J, Krauss R, Hart C (2010). Amphetamine analogs methamphetamine and 3,4-methylenedioxymethamphetamine (MDMA) differentially affect speech. Psychopharmacology 208: 169–177.
Miller GA, Charles WG (1991). Contextual correlates of semantic similarity. Lang Cogn Proc 6: 1–28.
Mitchell SH, Laurent CL, de Wit H (1996). Interaction of expectancy and the pharmacological effects of d-amphetamine: subjective effects and self-administration. Psychopharmacology 125: 371–378.
Mithoefer MC, Wagner MT, Mithoefer AT, Jerome L, Doblin R (2011). The safety and efficacy of {+/-}3,4-methylenedioxymethamphetamine-assisted psychotherapy in subjects with chronic, treatment-resistant posttraumatic stress disorder: the first randomized controlled pilot study. J Psychopharmacol 25: 439–452.
Mota NB, Furtado R, Maia PPC, Capelli M, Ribeiro S (2014). Graph analysis of dream reports is especially informative about psychosis. Sci Rep 4: 3691.
Mota NB, Vasconcelos NA, Lemos N, Pieretti AC, Kinouchi O, Cecchi GA et al (2012). Speech graphs provide a quantitative measure of thought disorder in psychosis. PLoS One 7: e34928.
Ooi KE, Lech M, Allen NB (2013). Multichannel weighted speech classification system for prediction of major depression in adolescents. IEEE Trans Biomed Eng 60: 497–506.
Patwardhan S, Banerjee S, Pedersen T (2003). Using measures of semantic relatedness for word sense disambiguation. Proceedings of the Fourth International Conference on Intelligent Text Processing and Computational Linguistics 2003. Springer: Mexico City, Mexico.
Pedersen T, Patwardhan S, Michelizzi J (2004). WordNet: Similarity: measuring the relatedness of concepts. Proceedings of the Nineteenth National Conference on Artificial Intelligence 2004. Association for Computational Linguistics: San Jose, CA.
Quine WVO (1951). Two dogmas of empiricism. Philos Rev 60: 20–43.
Ramos L, Hicks C, Kevin R, Caminer A, Narlawar R, Kassiou M et al (2013). Acute prosocial effects of oxytocin and vasopressin when given alone or in combination with 3,4-methylenedioxymethamphetamine in rats: involvement of the V1A receptor. Neuropsychopharmacology 38: 2249–2259.
Rice P, Ezzy D (1999) Qualitative Research Methods, A Health Focus. Oxford University Press: Melbourne, Australia.
Sigman M, Cecchi GA (2002). Global organization of the Wordnet lexicon. Proc Natl Acad Sci USA 99: 1742–1747.
Stitzer ML, McCaul ME, Bigelow GE, Liebson IA (1984). Hydromorphone effects on human conversational speech. Psychopharmacology 84: 402–404.
Sumnall HR, Cole JC, Jerome L (2006). The varieties of ecstasy experience: an exploration of the subjective experiences of ecstasy. J Psychopharmacol 20: 670–682.
Tagamets MA, Cortes CR, Greigo JA, Elvevåg B (2013). Neural correlates of the relationship between discourse coherence and sensory monitoring in schizophrenia. Cortex (in press).
Thompson MR, Callaghan PD, Hunt GE, Cornish JL, McGregor IS (2007). A role for oxytocin and 5-HT(1A) receptors in the prosocial effects of 3,4-methylenedioxymethamphetamine (“ecstasy”). Neuroscience 146: 509–514.
Wardle MC, Garner MJ, Munafo MR, de Wit H (2012). Amphetamine as a social drug: effects of d-amphetamine on social processing and behavior. Psychopharmacology 223: 199–210.
Acknowledgements
We thank participants for their involvement and Lisa Jerome for comments on an earlier draft. This research was supported by the National Institute on Drug Abuse (DA029679, DA034877, DA026570, and DA02812).
Author information
Authors and Affiliations
Corresponding author
Additional information
Supplementary Information accompanies the paper on the Neuropsychopharmacology website
PowerPoint slides
Rights and permissions
About this article
Cite this article
Bedi, G., Cecchi, G., Slezak, D. et al. A Window into the Intoxicated Mind? Speech as an Index of Psychoactive Drug Effects. Neuropsychopharmacol 39, 2340–2348 (2014). https://doi.org/10.1038/npp.2014.80
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/npp.2014.80
This article is cited by
-
Analysis of recreational psychedelic substance use experiences classified by substance
Psychopharmacology (2022)
-
Detection of acute 3,4-methylenedioxymethamphetamine (MDMA) effects across protocols using automated natural language processing
Neuropsychopharmacology (2020)
-
Long-term follow-up outcomes of MDMA-assisted psychotherapy for treatment of PTSD: a longitudinal pooled analysis of six phase 2 trials
Psychopharmacology (2020)
-
Computational Approaches to Behavior Analysis in Psychiatry
Neuropsychopharmacology (2018)
-
Considering the context: social factors in responses to drugs in humans
Psychopharmacology (2018)

{kind=link}
{kind=link}