
Abstract
Identifying the ancestral components of genomes of admixed individuals helps uncovering the genetic basis of diseases and understanding the demographic history of populations. We estimate local ancestry on 313 Chileans and assess the contribution from three continental populations. The distribution of ancestry block-length suggests an average admixing time around 10 generations ago. Sex-chromosome analyses confirm imbalanced contribution of European men and Native-American women. Previously known genes under selection contain SNPs showing large difference in allele frequencies. Furthermore, we show that assessing ancestry is harder at SNPs with higher recombination rates and easier at SNPs with large difference in allele frequencies at the ancestral populations. Two observations, that African ancestry proportions systematically decrease from North to South, and that European ancestry proportions are highest in central regions, show that the genetic structure of Chileans is under the influence of a diffusion process leading to an ancestry gradient related to geography.
Similar content being viewed by others


Introduction
During the last decade vast advances in genotyping and sequencing technologies have led to better understanding of human genetic variation and its relation with natural selection, recombination rates and phenotype–genotype associations1,2,3,4. In particular, genome-wide association studies (GWAS) have shed light into numerous associations between diseases and genotypes5,6.
GWAS has worked well for homogeneous populations like Europeans. Unfortunately, for many populations that have recent ancestry from two or more continents (so-called admixed populations), like Latino and African Americans, this procedure can produce many spurious associations. A case–control design performed on an admixed population can produce spurious association when subjects in the case and control groups differ in allele frequency. This can easily arise from differences in ancestry proportions. It is therefore crucial to correct for ancestry to avoid false associations7,8,9,10,11.
Nevertheless, performing genome-wide association on admixed populations offers many advantages. First, recently admixed populations are likely to have a larger number of genetic variants with functional effects, as has been suggested by studies of natural selection3. Second, causal risk alleles can be searched by performing the usual comparison in allele frequency between cases and controls (correcting for population structure7,8,9,10,11), by performing an analysis of cases-only (admixture mapping12), or by using cases-and-controls to search for unusual deviation in local ancestry. SNP and admixture association signals contain information that can complement each other13, and more powerful statistical tests that combine the two signals can be applied8,14.
The Latino-admixed populations offer particular challenges for performing GWAS, for example, it is difficult to choose accurate ancestral populations for Latinos15,16, Native-American panels are still sparse and genetically heterogeneous and also existing methods for multi-way local-ancestry inferences (three or more ancestral populations), which are necessary for Latino populations, show biases in their miscalled segments17.
In this paper, we aim to increase our knowledge of the genetic patterns of the Chileans. The genetic composition of the Chileans is shaped by the interplay of ancient populations and recent demographic shifts. Chile is located along the south west coast of the Pacific ocean in South America, bordering on the east with one of the highest chain of mountains in the world, the Andes. Arguably, this isolation may have resulted in particular genomic traits, from the ancient ancestral populations, that are advantageous for genetic mapping. In contrast, the Chileans are admixed. The discovery and conquest of Chile by the Spaniards began in the mid-sixteenth century, starting a Caucasian-Native-American miscegenation during the last 16 generations18. In addition, during the seventeenth century, a minor African component was brought in. After the Spanish conquest, new migrations mainly from Europe occurred during nineteenth and twentieth centuries, which contributed to the development of modern Chileans.
The study of the genetic structure of the admixed Chileans can shed light on the genetic basis of diseases through more powerful tests, as mentioned above. In addition, genetic studies of minority populations are needed to develop truly global medical genomics19. However, to accurately perform association studies in this population, it is necessary to infer local ancestry, and therefore it is essential to assess local ancestry estimations performance in empirical data20. Local ancestry inference (LAI) consists on the assignment of a label of ancestral origin to each position of the genome. It has a wide range of applications from pharmacogenomics to human demographic history and natural selection3,21,22, and numerous computational approaches have been developed17,23,24,25,26,27. In general, LAI methods receive as input unphased genetic data from an admixed individual, and output the ancestral origin of each chromosomal segment based on a model and a reference panel of ancestral populations.
In this work, we characterize the patterns of genetic variation on the Chileans using genotype data on ~685,944 SNPs from 313 individuals across the whole-continental country, with the purpose of providing essential information to future medical genetic association studies. We identify SNPs with highly differentiating allele frequencies and estimate an average time since admixture that is around 10 generations ago. On the basis of LAI, we show that assessing ancestry is in general more difficult at SNPs with higher recombination rates and easier at SNPs that have a large difference in allele frequency at the ancestral populations. Also, African ancestry proportions systematically decrease from North to South and European ancestry proportions are highest in central regions.
We assess the sensitivity of local ancestry estimation methods on sample size of the ancestral populations, showing that the methods are robust. We also show that the errors in ancestry estimation can be large when the density of the SNPs in the panels is small. We further evaluate the consistency between two state-of-the-art codes used for LAI, showing sufficient consistency on global and local ancestry estimation.
Results
Analysis of population structure
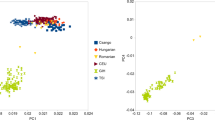
We perform an analysis of spatial ancestry28, results are shown in Fig. 1. Figure 1a shows that the spatial analysis clearly separates the three ancestral population and, as expected, the admixed Chileans are scattered between the European and the Native-Americans. We restrict our spatial analysis to the Chileans with each of its ancestral populations. Figure 1b shows the Chilean-admixed population clearly separated from the African populations. Within Africans, the Yoruba in Ibadan, Nigeria (YRI) and the Luhya in Webuye, Kenya (LWK) are close together, but the African Ancestry from Southwest United States (ASW) is spread along a line and is the closest to the Chileans. Figure 1c shows that the Europeans are separated into two groups, Britain (GBR) and North Europe (CEU) together and Spaniards and Italians together, closer to the Chileans. Figure 1d shows the Chileans together with the Native-Americans. Figure 1b–d shows the Chileans with their global proportion of African, European and Native-American ancestry, respectively, estimated by the LAI method. We observe consistency between the ancestral proportion estimates given by the LAI methods and the spatial ancestry analysis as individuals with higher/lower proportion in ancestry are closer/farther to the ancestral populations.

(a) All populations, (b) Chilean and African populations, (c) Chilean and European populations and (d) Chilean and Native-American populations. Chileans appear in black with its global African, European and Native-American ancestry proportions in (b), (c) and (d), respectively, as estimated by local ancestry methods.
Ancestry informative SNPs
Spatial analysis detects hundreds of SNPs with large frequency difference at Native-American (NAT), European (EUR) and Chilean (CHL) panels (see Supplementary Table 1 for a list of the top 100 loci). Some of these SNPs are located near or within genes known to have undergone recent positive selection or related to phenotypes. Examples of such informative genes are EDAR and SLC45A2 (see Fig. 2). Further analysis should be performed to identify whether any of these genes have undergone recent positive selection.

Marked positions correspond to SNPs from genes discussed in the text.
Estimating ancestry proportions with LAI methods
We obtain local ancestry proportion estimates for each individual in the Chilean sample, at each of the 685,944 specific loci along the 22 pairs of autosomal chromosomes included in this study. We use haplotypes reference panels of sizes of 176, 410 and 458 individuals for the NAT, EUR and AFR ancestral population, respectively.
Individuals’ ancestry
By summing up the local ancestry contribution inferred by LAMP-LD/RFMix, we obtain estimates of global ancestry proportions for each Chilean individual. Results from LAMP-LD are shown in Fig. 3. Each vertical bar represents an individual with the proportion of each ancestry depicted in a different colour. NAT ancestry percentages range from 0.13 to 90.95%, EUR ancestry percentages range from 8.26 to 99.41% and AFR ancestry percentages range from 0.26 to 7.50. According to the analyses performed on Error Evaluation, on average these global ancestry estimators should not deviate in more than (1.06e−04, 5.53e−05, 6.75e−07) at the (NAT, EUR, AFR) proportion, respectively, due to the size of the reference panels considered, and should not deviate in more than (1.5e−05, 1.8e−05, 1.68e−05) at the (NAT, EUR, AFR) proportion, respectively, due to the SNP density considered.

From left to right, Chilean samples are sorted in ascending order of Native-American ancestry proportion.
Population ancestries
To estimate global Native-American, European and African ancestry proportions in the Chileans, we compute weighted averages of LAMP-LD’s global ancestry proportions across the 313 individuals. We find CHL ancestry percentages being 42.38% NAT, 55.16% EUR and 2.44% AFR (using LAMP-LD) and 43.22% NAT, 54.38% EUR and 2.40% AFR (using RFMix), which are consistent with previous studies29.
Population ancestries at demographic zones
We estimate the ancestry proportions at every geographic zone (see Fig. 4) by averaging LAMP-LD’s global ancestry estimates of the individuals from each zone.

(a) The larger pie chart on the left panel corresponds to global ancestry proportion for the Chileans as a whole; (b) the panel in the middle is a map of Chile describing the subdivision into five zones: N (n=16), C1 (n=159), C2 (n=41), S1 (n=73), S2 (n=12) and the political regions associated with each zone; (c) on the right panel, the pie charts correspond to global ancestry estimation on the five zones.
From Fig. 5a,b it can be observed that the central regions C1 and C2 have larger proportion of European ancestries (and smaller proportion of Native-American ancestry), which are statistically significantly different from the proportions at the remaining zones.

The box plots represent the distribution of global ancestry proportions at every zone. The horizontal line inside the box corresponds to the median of this distribution, the bottom and top of the box are the first and third quartiles and data points outside the whiskers can be considered outliers. The sample sizes are 16, 159, 41, 73 and 12 for zones N, C1, C2, S1 and S2. respectively. Figure (a) shows the Native-American ancestry proportions, (b) the European proportions and (c) the African proportions over all the Chilean sample.
Further, the mean African ancestry percentage systematically decreases from North to South (see Fig. 5c), being 3.89% in the northernmost region N, 2.46% in the region C1, 1.97% in region C2, 1.64% in the region S1 and finally 1.32% in the southernmost region S2. The Tukey test for multiple comparisons shows that the means are significantly different between the zone N and C1 and between C1 and C2, but the means at C2, S1 and S2 are statistically equivalent. Arguably, larger sample sizes on these regions are needed to show a statistically significant decrease in African ancestry as we move to the southern regions of Chile.
Gender imbalance
We calculate pairwise FST statistics and test for the null hypothesis that there is no difference between the populations. From pairwise FST estimates in chromosome Y, we confirm a predominant European ancestry, FST=0.07 (P value<10−5) between Chileans and Europeans compared with an FST=0.27 (P value<10−5) between Chileans and Native-Americans. From the analysis on chromosome X, we observed predominant Native-American ancestry FST=0.0013 (P value<10−5) between the Chileans and the Europeans compared with an FST=0 (P value<10−5) between Chileans and Native-Americans.
Estimating time since admixture
We count the number of ancestry blocks at each individual to estimate an average, T, time since admixture. We assume a hybrid-isolation model to estimate the expected number of ancestry switches from a population admixed T generations ago22. A more suitable, but mathematically more involved model, should assume continuous gene flow as well, so we need to interpret our results as an estimate of average admixing time weighted by the relative level of gene-flow per generation. Figure 6 shows the theoretical expected time since admixture for Tε{5, 10, 15, 20} generations ago as a function of genome-wide European ancestry proportion (red dots). Black dots represent the Chilean sample, which is scattered around T=10 generations ago, consistent with previous studies30.

Red dots represent the theoretical expected time (T) since admixture as a function of genome-wide European ancestry proportion. Black dots represent the Chilean sample data.
Comparison between LAMP-LD and RFMix in local ancestry
We evaluate the consistency between local ancestry estimates at each individual by calculating the percentage of coincidences in the local ancestry assignment of both methods (see Supplementary Table 2). Note that 82.35% of the ancestry assignments coincide exactly between the two methods. The largest differences occur at Native-American/European assignments by LAMP-LD/RFMix (8.31%) or inversely, EUR/NAT assignments by LAMP-LD/RFMix (7.33%). We further compare RFMix with and without EM iterations, and obtained a 1% improvement at the number of consistent assignments when the EM iterations were performed.
We evaluate the consistency between global ancestry estimates at each individual between both local-ancestry methods by counting the number of individuals, which differ in its global ancestry percentage in less than 0.1, 0.5, 1, 3, 6% (see Supplementary Table 3). Differences in Native-American ancestry estimates across methods are always<6% (with 88.5% of individuals always <1%), and this holds for differences in European ancestry estimates too (with 87.9% of individuals always <1%). Differences in African ancestry estimates are always<3% (with 90.4% individuals always <0.5%). Therefore, we observe substantial global ancestry consistency between the two methods.
We perform correlation tests to further evaluate whether SNPs with larger inconsistency between the methods correlate with recombination rates, or with SNPs with large frequency differences at the ancestral population. The Pearson correlation test that assesses the association between the number of inconsistencies between the methods and the recombination rate computed at each SNP has a t-statistics=100.86 with df=531,249 and a P value <e−16, which shows that the correlation is statistically significantly different from zero. In this test, we observe positive correlation, meaning that for lower recombination rates we should expect less inconsistencies between the methods, and more inconsistency when the recombination rates are higher. The correlation test that measures the association between the number of inconsistencies between the methods and the square difference of the frequencies at the Native-American and European population computed at each SNP has a t-statistics=−13.91 with df=531,249 and a P value <e−16, which also shows that the correlation is statistically significantly different from zero. In this case, we have negative correlation, meaning that at SNPs with larger frequency differences at the main ancestral populations we should expect a lower number of inconsistencies between the methods.
Comparison of LAMP-LD and ADMIXTURE in global ancestry
We compare global ancestry proportions at each individual between the global ancestry estimates obtained from LAMP-LD and ADMIXTURE31. We run ADMIXTURE with K=2 and K=3, number of ancestral populations, under the unsupervised mode. We obtain a correlation on the NAT ancestry equal to 0.99, for K=2, and 0.96 for K=3. Figure 7 shows the correlation on global ancestry estimates based on these two methods.

Black dots represent the global proportion of NAT ancestry as estimated by ADMIXTURE (y-axis) and LAMP-LD (x-axis) for each individual in the Chilean sample.
LAI’s sensitivity to the size of the reference panels
We measure the global ancestry proportions, using LAMP-LD’s LAI, in the Chilean sample as we increase the size of each of the three reference panels simultaneously from 10 until 176 haplotypes. We estimate the variability on the global proportions estimate for each individual by repeating the procedure 10 times. Supplementary Figure 1 shows how the mean and s.d. of the Chilean global ancestry proportion estimates vary as a function of the size of the reference panels. We select X0=130 haplotypes per reference panels as the minimum starting size for the three ancestry panels.
We start with X0=130 haplotypes per reference panel and increase the number of Native-American reference haplotypes. Native-American ancestry estimates increase from 42.23 to 43.03%, while European dropped from 55.45 to 54.72% and African dropped from 2.32 to 2.25%. Figure 8a shows the distribution of the s.d. of the estimates of Native-American proportion as we increase the ancestral reference panel for this population. This figure shows stable and similar distribution as we increase the size of the Native-American reference panel, at XAm=176 a slightly smaller median s.d. is achieved (mediansd=1.06e−04). We fix XAm=176.

The box plots represent the distribution of the s.d. values over the Chilean sample (n=313).The first row estimates the distribution of s.d. values at different panel sample sizes: (a) Native-American, (b) European and (c) African, respectively. The second row shows the distribution of the sample errors over the Chilean sample at different SNP densities: (d) Native-American, (e) European and (f) African, respectively.
Increasing the size of the EUR reference panel caused an increase in the global estimates of EUR ancestry proportion, at the expense of both AFR and NAT ancestry estimates. We start with haplotype reference panels of size XAm=176 in NAT, 130 in EUR and 130 in AFR. We increase the number of EUR haplotypes in tens until the maximum number of 1822 haplotypes is reached. Estimates of ancestry percentages change from 43.03, 54.72 and 2.25% to 40.75, 57.84 and 1.41% in NAT, EUR, AFR, respectively. A combination of reference panel sizes such as the latter, where two sets are relatively small compared with the third one, might cause an overestimation of ancestry proportions related to the largest reference panel. We set the optimal number of EUR haplotypes to XE=410 for which we find a minimum median s.d. of mediansd=5.53e−05. Figure 8b shows box plots of the distribution of the s.d. of the estimates of European ancestral proportion as we vary the size of this reference panel.
Increasing the size of the AFR reference panel causes an increase in the global estimates of AFR ancestry proportion, mainly at the expense of EUR ancestry estimates. We start with (NAT, EUR, AFR) reference panels of size (XN=176, XE=410, X0=130), and increase the number of haplotypes in the AFR reference panel. Estimates of ancestry percentages change from (41.22, 57.17 and 1.61%) to (41.17, 56.77 and 2.06%) for the total number of haplotypes. The small changes observed in the percentages of ancestry are expected as the Chilean population have small percentages of African ancestry. We set xA=458 at which it is reached a minimum median s.d. of mediansd=6.75e−07. Figure 8c shows box plots of the distribution of the s.d. of the estimates of African ancestral proportion as we vary the size of this reference panel.
SNP density effect on global ancestry estimation
We measure the s.d. on the global ancestry estimators of each individual by sampling randomly 10 times different sets of SNPs of the same sample size from chromosome 1. Figure 8d–f shows box plots of the distributions of the s.d. over the Chilean sample at each sample size and for each ancestral population. Note a rapid decay on the median s.d. as SNP density increases. For the Native-American ancestry, the median s.d. starts at 0.108 for a SNP density of 10 and ends at 1.5e−05 for a SNP density of 10,000. Similarly for the European ancestry, the median s.d. starts at 0.112 for a SNP density of 10 and ends at 1.8e−05 for a SNP density of 10,000. For the African ancestry, the median s.d. starts at 4.69e−02 for a SNP density of 10 and ends at 1.68e−05 for a SNP density of 10,000.
Discussion
In this work, we study the genetic structure of the Chileans through spatial ancestry analysis and by estimating the local ancestry at every individual from the sample. Even though our sample was not selected for this type of study, it is representative of continental Chileans. There are no previous studies showing ancestry correlation to 22q11 microdeletion syndrome (the deletion covers less than 250 SNPs from the panel) or Hantavirus infection. We have individuals from all the regions of the country, and we include a correction for over-sampling southern regions and under-sampling northern regions.
From the spatial ancestry analysis, we confirm that Chileans are admixed with ancestral contribution mainly from Europe and Native America, with a minor African component. Within the Africans, the YRI and the LWK are close together but the ASW is spread along a line and is the closest to the Chileans, arguably because of the historical evidence corroborating a West African origin for the African lineages in the Americas. We also confirm that from the European components, the Chileans are closer to Spaniards and Italians than to British and CEU. This observation is in agreement with Chilean immigration history, as Chile was conquered by the Spaniards during the sixteenth century. From the Native-American components, we observe that the Natives from Peru and Bolivia (Aymara and Quechuas) are clustered together and are closer to the Chileans, as expected, than the North American natives (Mayas and Nahua), which are farther away and more spread. This suggests higher heterogeneity in Native American populations compared with Europeans or Africans, which is in agreement with the observation that obtaining optimal ancestral populations for Latin Americans is more difficult than for other admixed populations17.
Also from the spatial analysis, we identify interesting loci showing highly differentiating allele frequencies. Some of these loci are found within or nearby genes previously reported as candidate genes under selection. For example, EDAR has several SNPs with high SPA-score. Previous studies reported signals of recent positive selection and associate EDAR with hair morphology and sweat glands density in Asians and Native-Americans32,33,34,35,36. SLC45A2 also shows SNPs with high SPA-score. This gene has been associated with skin and hair pigmentation, and several studies found signals of recent positive selection32,33,34,35,36,37. Our spatial analysis reaffirms that SLC45A2 and EDAR hold clues to explain important aspects of the evolutionary history of Native-Americans. A large SPA-score is obtained in an intronic SNP from the LRP1B gene (also previously reported in ref. 28). This gene codifies a low-density lipoprotein receptor38,39 and has been related to body mass index in US and Danish individuals40,41. Other examples of informative genes identified are CIITA, HABP2, COL21A1 and GPC5. CIITA encodes a transactivator of MHC class II42 and has been associated with susceptibility to numerous diseases including lymphoma43. HABP2 codifies a serine protease with a role in coagulation/fibrinolysis-related activities, as well as an inflammatory mediator44. GPC5 is related to inflammatory response and has been identified to be under selection favouring resistance to cholera disease45. COL21A1 codifies the type XXI collagen, a component of extracellular matrix of blood vessel walls46. In addition to these genes, Fig. 2 highlights RHD and ABO genes (Rh and ABO blood group system, respectively). Both exhibit relatively high SPA-scores, which is expected for classic genetic markers widely assessed during last century, and frequently used in the Chilean and Latin American populations47,48,49.
Our study provides the first evaluation genome-wide of local ancestry on the Chileans and provides estimates of s.e. values of individuals’ global ancestry for different SNP densities and sizes of reference panels that can be used to design future GWAS in Latino-admixed population. Our results show that the distribution of errors is in general small as we vary the size of the reference panels. Caution should be taken when one of the ancestry panels is much larger than the other panels. In our case, the European panel is much larger than the African and Native-American panels, so increasing the European panel to its largest size may provoke an over estimation of European ancestry, mainly at the expense of Native-American ancestry. Our analysis also shows that the errors decrease substantially as we increase the SNP density, showing that for a small number of SNPs errors can be unacceptably high.
Good agreement is observed between the two LAI methods regarding individual global ancestry proportions and substantial agreement in local ancestry estimates. Previous studies have shown that loci with increased deviation in LAI show increased Mendelian inconsistency rates in LAI in Latinos20. Our study shows that loci with higher rates of inconsistency between LAMP-LD and RFMix have negative correlation with loci with increased deviation in frequency at the ancestral populations, this is expected, as SNPs with larger deviation in allele frequency at the ancestral population should be more informative for ancestry inference. Also, our study shows that loci with higher rates of inconsistency between the two LAI methods have positive correlation with higher recombination rates. At higher recombination rate loci, the methods should decide whether to switch from the haplotype from which they have been copying, and if a switch is performed, whether they switch to a haplotype from the same ancestral population or to another ancestral population. Therefore, there is more uncertainty on what is the optimal solution and is then natural that the methods have a higher rate of inconsistency at such loci with higher recombination rates.
Our results reflect the demographic history of post-Columbian colonization of Chile. First, our results from sex-chromosome analyses confirm the imbalanced contribution of European men and Native-American women to the Chileans, reported by previous studies of mitochondrial and nuclear DNA markers50,51. Second, the observation that African ancestry proportions systematically decrease from North to South is in agreement with known local history of African slavery brought to the Pacific shore of South America. The northern regions of Chile received an important number of African slaves during the Colonial period52,53. However, this was not the case for the central and southern regions. While a great number of African slaves were brought to Peru to work on plantations and mines, Chile received a low number because of its small economic activity. This explains the decrease in African ancestry proportion from North to South, as a gradient dependent on proximity.
Third, the observation that European/Native-Americans ancestry proportions are the highest/lowest in central regions C1 and C2 reflects the historical concentration of inhabitants in the centre of Chile. Now-a-days, the territories grouped in this study as central regions C1 and C2 concentrate 75% of the total population of Chile. This demographical fact means that central regions received much higher numbers of immigrants than other zones. The causes of this can be traced to several historical factors. During Colonial times, Chile occupied a more reduced territory than today. The North corresponded to a different political government and its boundary area, called Atacama, was usually referred as despoblado or unpopulated. In the South, Mapuches, the only indigenous group that was not subjugated by Spanish conquerors, maintained a military frontier south to the Biobío River (which coincides with the C2/S1 region demarcation used in this study). The entrance and occupation of non-indigenous population to these territories occurred after 1860, when Chile was an independent republic54. In addition to this, the extreme south of Chile (S2 region) was only recently populated. Consequently, most of the northern and southern regions of Chile were populated in recent times. Despite the several waves of European migrants that were moved to colonize extreme northern and southern areas, the central regions consistently kept the majority of this immigration during the last two hundred years.
The correlation between geography and genetic diversity has been widely recognized. Earlier studies show that allele frequencies follow an increasing/decreasing gradient pattern that extend over the entire world55,56. While the regional structure of admixture in the Chilean populations seems homogeneous compared with other countries of Latin America15, the north to south changes in allele frequency for African and from centre to the periphery for European and Native American ancestry show that the spreading of these alleles is dependent on geography. This pattern has been recently observed at lower resolution of markers57.
Overall, the results from global ancestry estimates per zones show that the genetic structure of Chileans is not uniformly distributed along the country. Both observations (African ancestry proportions systematically decrease from North to South, and the highest in central regions C1 and C2) suggest that, at the micro-evolutionary scale, the genetic structure of the Chileans is under the influence of a diffusion process leading to a gradient pattern of variation related to geography. Further analyses including additional data points are needed to corroborate this gradient pattern of variation.
Methods
Sample collection and genotyping
We estimate local ancestry on 313 Chilean admixed samples from two case–control studies, on Hantavirus infection (n=112) and 22q11 microdeletion syndrome (n=201), genotyped on an Affymetrix 6.0 GeneChip Array (Santa Clara, CA). Table 2 shows the distribution of the samples across the 15 political regions in Chile. Local Ethics Committees at each participating institution approved the study and informed consent was obtained from all participants, their parents or legal guardians. Local ancestry estimation requires reference panels from the ancestral populations, which for latinos correspond to Native-American, European and African populations. Our reference panels consist of 88 Native-Americans, 911 European and 229 Africans (Table 1 shows details on the populations). We filter SNPs for minor allele frequency (>0.01), Hardy–Weinberg Equilibrium (P value>10−5), call rates (>95%), missingness on SNPs and samples (10%) and discard A/T and C/G SNPs. We further filter out SNPs from the HLA region to avoid bias in the estimation of local ancestry58. A total of 685,944 SNPs remain. Phase data are obtained using BEAGLE59 on the CHL, NAT and SPN populations. To provide further demographic insights we grouped the Chilean sample into five zones from North to South (N,C1,C2,S1,S2) as shown in Fig. 4.
Analysis of population structure
A cluster analysis is performed using the SPA software28 to identify the spatial structure in two dimensions of the Chilean sample with its ancestral populations. The unsupervised SPA analyses performed under default parameters estimate the allele frequency at every SNP as a function of geographical position. SNPs with large differences in allele frequency at the populations studied are more informative to distinguish individuals with different ancestries and are among candidate loci under selection.
To determine gender imbalance in ancestry, we calculate Slatkin’s FST values between Native-Americans, European and Chileans, using chromosome X on female samples and chromosome Y on male samples.
Local ancestry inference
We infer local ancestry at the Chilean sample using LAMP-LD17 and RFMix27 softwares. Results from RFMix are obtained without the EM iteration option. We evaluate the sensitivity of these softwares on the size of the reference panels, and the density of SNPs, and we evaluate the consistency between the two methods. We compute global ancestry proportions at each ancestral population for every individual from the Chilean sample by calculating the proportion of bases assigned to each ancestral population. From the ancestral proportions at each individual we estimate the ancestral proportions at the admixed Chileans. From Table 2 we can note that the regions in the north are in general under-sampled and the regions in the south are in general over-sampled. Therefore, to obtain unbiased estimators of the population global ancestry proportions for Chileans and at the five demographic zones (Fig. 4), we calculate weighted averages over all the individuals in the sample. We determine a single weight for every region as the ratio between the population and sample fractions for that region, and every individual from the same region shares the same weight. For example, for ‘Arica y Parinacota’ the weight is calculated as w=1.1/0.6=1.83 while the weight for region ‘Metropolitana’ is w=40.3/39.6=1.02. If pi,NAT, pi,EUR and pi,AFR correspond to the Native-American, European and African ancestry proportion, respectively, estimated at individual i from the sample, then

correspond to the Native-American, European and African ancestry proportion estimators for the Chileans.
Consistency assessment of local-ancestry inference methods
To evaluate how consistent the local ancestry estimates are at every locus in each individual between both methods, LAMP-LD and RFMix, we count the number of loci in which both methods differ and look at specific patterns from loci with inconsistent assignments. Specifically, we perform correlation tests to assess whether SNPs in which both methods differ are also more common among SNPs showing larger differences in allele frequency at the ancestral populations or are within regions with recombination hotspots. We obtain the recombination rates from the European HapMap panel ( www.hapmap.org). The main reasons for using the EUR recombination map instead of a Latino map are the following: (i) even though recombination maps have been estimated from some Latino population, the European is the only one that has an accurate pedigree-based map; (ii) at a coarse scale the Latino recombination map correlates well with the EUR map (r2=0.95); (iii) Chileans have on average greater ancestry from Europe than that from Native America.
Effect of the size of reference panels on global ancestry
To estimate the variability on the individuals’ global ancestry proportion estimators due to the size of the reference panels and to propose a minimal optimal size for each reference panel, we implement the following procedure. We fixed the tuning parameters for LAMP-LD and RFMIx and varied the number of haplotypes at each reference panel. For LAMP-LD we fixed the number of states (S=15) and the length of the window (L=75), and for RFMix we fix the number of generations since the first admixture event occurred (G=8).
We start with 10 haplotypes for each reference panel and increase this number by 10 until we obtain a minimum number that stabilizes the estimates of the population global ancestry proportion in the Chilean samples. We denote this number by X0. Starting from X0 haplotypes at each reference panel, we then increase the sample size solely at the Native-American panel until a stability criterion is achieved (we called this number XAm). Then, starting from XAm haplotypes in the NAT population and X0 haplotypes in the EUR and AFR populations we increase the size of the EUR panel until the same stability criterion is achieved (we called this number XE). Last, we start with XAm haplotypes in the NAT population, XE haplotypes in the EUR population and X0 haplotypes in the AFR population and increase the number of haplotypes in the AFR panel until the same stability criterion is achieved (we called this number XAf). To avoid possible biases due to sample selection, and to be able to estimate the variability as a function of reference panel sizes, we repeat the procedure 10 times. The stability criterion that we consider was either the minimum median s.d. (in the cases of the NAT and AFR populations) or, for the EUR population, we use a criterion based on the median estimates of s.d. for every sample size. We identify a ‘kink’ in the plot such that  is large for every m (see Fig. 8).
is large for every m (see Fig. 8).
LAI method’s sensitivity to the density of SNP panels
To determine a minimum number of SNPs with which we can obtain estimates of global ancestry proportions with low variability, we evaluate the performance of LAMP-LD as we vary the density of markers on chromosome 1.
We fix the reference panel to (176, 410, 458) haplotypes at the (NAT, EUR, AFR) population, respectively, and vary the number of SNPs selected randomly (Nsnapsε{70, 80, 90, 100, 200,…, 1,000,…,10,000}). As we start with a small number of SNPs (that is, 70), we fix window length to L=10. To avoid bias due to sample selection, we repeat this procedure 10 times to obtain for every admixed individual an average and s.d. of global ancestry proportions at each SNP-density-size.
Additional information
Accession codes. Genetic polymorphism data have been deposited in NCBI dbSNP database under accession code 1062069.
How to cite this article: Eyheramendy, S. et al. Genetic structure characterization of Chileans reflects historical immigration patterns. Nat. Commun. 6:6472 doi: 10.1038/ncomms7472 (2015).
References
Frazer, K. A. et al. A second generation human haplotype map of over 3.1 million snps. Nature 449, 851–861 (2007) .
Abecasis, G. R. et al. An integrated map of genetic variation from 1,092 human genomes. Nature 491, 56–65 (2012) .
Grossman, S. R. et al. A composite of multiple signals distinguishes causal variants in regions of positive selection. Science 327, 883–886 (2010) .
Wegmann, D. et al. Recombination rates in admixed individuals identified by ancestry-based inference. Nat. Genet. 43, 847–853 (2011) .
Consortium, W. T. C. C. Genome-wide association study of 14,000 cases of seven common diseases and 3,000 shared controls. Nature 447, 661–678 (2007) .
Welter, D. et al. The NHGRI GWAS Catalog, a curated resource of SNP-trait associations. Nucleic Acids Res. 42, D1001–D1006 (2014) .
Price, A. L., Zaitlen, N. A., Reich, D. & Patterson, N. New approaches to population stratification in genome-wide association studies. Nat. Rev. Genet. 11, 459–463 (2010) .
Pasaniuc, B. et al. Enhanced statistical tests for GWAS in admixed populations: assessment using African Americans from CARe and a Breast Cancer Consortium. PLoS Genet. 7, e1001371 (2011) .
Wang, X. et al. Adjustment for local ancestry in genetic association analysis of admixed populations. Bioinformatics 27, 670–677 (2011) .
Liu, J., Lewinger, J. P., Gilliland, F. D., Gauderman, W. J. & Conti, D. V. Confounding and heterogeneity in genetic association studies with admixed populations. Am. J. Epidemiol. 177, 351–360 (2013) .
Qin, H. et al. Interrogating local population structure for fine mapping in genome-wide association studies. Bioinformatics 26, 2961–2968 (2010) .
Winkler, C. A., Nelson, G. W. & Smith, M. W. Admixture mapping comes of age. Annu. Rev. Genomics Hum. Genet. 11, 65–89 (2010) .
Tang, H., Siegmund, D. O., Johnson, N. A., Romieu, I. & London, S. J. Joint testing of genotype and ancestry association in admixed families. Genet. Epidemiol. 34, 783–791 (2010) .
Shriner, D., Adeyemo, A. & Rotimi, C. N. Joint ancestry and association testing in admixed individuals. PLoS Comput. Biol. 7, e1002325 (2011) .
Bryc, K. et al. Colloquium paper: genome-wide patterns of population structure and admixture among Hispanic/Latino populations. Proc. Natl Acad. Sci. USA 107 (Suppl 2), 8954–8961 (2010) .
Tian, C. et al. A genomewide single-nucleotide-polymorphism panel for Mexican American admixture mapping. Am. J. Hum. Genet. 80, 1014–1023 (2007) .
Baran, Y. et al. Fast and accurate inference of local ancestry in Latino populations. Bioinformatics 28, 1359–1367 (2012) .
Valenzuela, C. Y. Human sociogenetics. Biol. Res. 44, 393–404 (2011) .
Bustamante, C. D., Burchard, E. G. & De la Vega, F. M. Genomics for the world. Nature 475, 163–165 (2011) .
Pasaniuc, B. et al. Analysis of Latino populations from GALA and MEC studies reveals genomic loci with biased local ancestry estimation. Bioinformatics 29, 1407–1415 (2013) .
Jarvis, J. P. et al. Patterns of ancestry, signatures of natural selection, and genetic association with stature in Western African pygmies. PLoS Genet. 8, e1002641 (2012) .
Johnson, N. A. et al. Ancestral components of admixed genomes in a Mexican cohort. PLoS Genet. 7, e1002410 (2011) .
Sundquist, A., Fratkin, E., Do, C. B. & Batzoglou, S. Effect of genetic divergence in identifying ancestral origin using HAPAA. Genome Res. 18, 676–682 (2008) .
Price, A. L. et al. Sensitive detection of chromosomal segments of distinct ancestry in admixed populations. PLoS Genet. 5, e1000519 (2009) .
Pasaniuc, B., Sankararaman, S., Kimmel, G. & Halperin, E. Inference of locus-specific ancestry in closely related populations. Bioinformatics 25, i213–i221 (2009) .
Churchhouse, C. & Marchini, J. Multiway admixture deconvolution using phased or unphased ancestral panels. Genet. Epidemiol. 37, 1–12 (2013) .
Maples, B. K., Gravel, S., Kenny, E. E. & Bustamante, C. D. RFMix: a discriminative modeling approach for rapid and robust local-ancestry inference. Am. J. Hum. Genet. 93, 278–288 (2013) .
Yang, W. Y., Novembre, J., Eskin, E. & Halperin, E. A model-based approach for analysis of spatial structure in genetic data. Nat. Genet. 44, 725–731 (2012) .
Fuentes, M. et al. Geografia genica de Chile. Distribucion regional de los aportes geneticos europeos, americanos y africanos]. Rev. Med. Chil. 142, 281–289 (2014) .
Galanter, J. M. et al. Development of a panel of genome-wide ancestry informative markers to study admixture throughout the Americas. PLoS Genet. 8, e1002554 (2012) .
Alexander, D. H., Novembre, J. & Lange, K. Fast model-based estimation of ancestry in unrelated individuals. Genome Res. 19, 1655–1664 (2009) .
Sabeti, P. C. et al. Genome-wide detection and characterization of positive selection in human populations. Nature 449, 913–918 (2007) .
Fujimoto, A. et al. A scan for genetic determinants of human hair morphology: EDAR is associated with Asian hair thickness. Hum. Mol. Genet. 17, 835–843 (2008) .
Bryk, J. et al. Positive selection in East Asians for an EDAR allele that enhances NF-kappaB activation. PLoS ONE 3, e2209 (2008) .
Kamberov, Y. G. et al. Modeling recent human evolution in mice by expression of a selected EDAR variant. Cell 152, 691–702 (2013) .
Grossman, S. R. et al. Identifying recent adaptations in large-scale genomic data. Cell 152, 703–713 (2013) .
Wilde, S. et al. Direct evidence for positive selection of skin, hair, and eye pigmentation in Europeans during the last 5,000 y. Proc. Natl Acad. Sci. USA 111, 4832–4837 (2014) .
Liu, C. X., Musco, S., Lisitsina, N. M., Yaklichkin, S. Y. & Lisitsyn, N. A. Genomic organization of a new candidate tumor suppressor gene, LRP1B. Genomics 69, 271–274 (2000) .
Liu, C. X., Li, Y., Obermoeller-McCormick, L. M., Schwartz, A. L. & Bu, G. The putative tumor suppressor LRP1B, a novel member of the low density lipoprotein (LDL) receptor fam-ily, exhibits both overlapping and distinct properties with the LDL receptor-related protein. J. Biol. Chem. 276, 28889–28896 (2001) .
Cornelis, M. C. et al. Obesity susceptibility loci and uncontrolled eating, emotional eating and cognitive restraint behaviors in men and women. Obesity 22, E135–E141 (2014) .
Burgdorf, K. S. et al. Association studies of novel obesity-related gene variants with quantitative metabolic phenotypes in a population-based sample of 6,039 Danish individuals. Diabetologia 55, 105–113 (2012) .
Steimle, V., Siegrist, C. A., Mottet, A., Lisowska-Grospierre, B. & Mach, B. Regulation of MHC class II expression by interferon-gamma mediated by the transactivator gene CIITA. Science 265, 106–109 (1994) .
Steidl, C. et al. MHC class II transactivator CIITA is a recurrent gene fusion partner in lym-phoid cancers. Nature 471, 377–381 (2011) .
Etscheid, M., Kress, J., Seitz, R. & Dodt, J. The hyaluronic acid-binding protease: a novel vascular and inflammatory mediator? Int. Immunopharmacol. 8, 166–170 (2008) .
Karlsson, E. K. et al. Natural selection in a bangladeshi population from the cholera-endemic ganges river delta. Sci. Transl. Med. 5, 192ra86 (2013) .
Chou, M. Y. & Li, H. C. Genomic organization and characterization of the human type XXI collagen (COL21A1) gene. Genomics 79, 395–401 (2002) .
Cavalli-Sforza, L. L. & Feldman, M. W. The application of molecular genetic approaches to the study of human evolution. Nat. Genet. 33 (Suppl), 266–275 (2003) .
Acuna, M., Llop, E. & Rothhammer, F. [Genetic composition of Chilean population: rural communities of Elqui, Limari and Choapa valleys]. Rev. Med. Chil. 128, 593–600 (2000) .
Sans, M. Admixture studies in Latin America: from the 20th to the 21st century. Hum. Biol. 72, 155–177 (2000) .
Rocco, P. et al. [Genetic composition of the Chilean population. Analysis of mitochondrial DNA polymorphism]. Rev. Med. Chil. 130, 125–131 (2002) .
Cifuentes, L., Morales, R., Sepúlveda, D., Jorquera, H. & Acuna, M. DYS19 and DYS199 loci in a Chilean population of mixed ancestry. Am. J. Phys. Anthropol. 125, 85–89 (2004) .
Mellafe, R. La introduccion de la esclavitud negra en Chile Editorial Universitaria (1984) .
Diaz, A., Galdames, L. & Ruz, R. Y llegaron con cadenas. La poblacion afrodescendientes en la historia de Arica y Tarapaca Universidad de Tarapaca (2013) .
Bengoa, J. Hstoria del pueblo Mapuche Lom Ediciones (2000) .
Serre, D. & Paabo, S. Evidence for gradients of human genetic diversity within and among continents. Genome Res. 14, 1679–1685 (2004) .
Handley, L. J., Manica, A., Goudet, J. & Balloux, F. Going the distance: human population genetics in a clinal world. Trends Genet. 23, 432–439 (2007) .
Ruiz-Linares, A. et al. Admixture in latin america: geographic structure, phenotypic diversity and self-perception of ancestry based on 7,342 individuals. PLoS Genet. 10, e1004572 (2014) .
Oleksyk, T. K., Smith, M. W. & O’Brien, S. J. Genome-wide scans for footprints of natural selection. Philos. Trans. R. Soc. Lond., B, Biol. Sci. 365, 185–205 (2010) .
Browning, S. R. & Browning, B. L. Rapid and accurate haplotype phasing and missing-data inference for whole-genome association studies by use of localized haplotype clustering. Am. J. Hum. Genet. 81, 1084–1097 (2007) .
Bigham, A. W. et al. Identifying positive selection candidate loci for high-altitude adaptation in Andean populations. Hum. Genomics 4, 79–90 (2009) .
Bigham, A. et al. Identifying signatures of natural selection in Tibetan and Andean populations using dense genome scan data. PLoS Genet. 6, doi:10.1371/journal.pgen.1001116 (2010) .
Acknowledgements
S.E. would like to thank Mark Shriver for sharing the Native American panel with us. G.M.R. and C.V. would like to thank Ms K Espinoza and Mr JC Rivera for technical assistance with the arrays. C.V. would like to thank members of the Hantavirus Study Group in Chile for their help in patient enrolment. S.E. acknowledges support from Fondecyt grant 1120813, C.V. is funded by Fondecyt grant 11110397, G.M.R. is funded by Fondecyt grants 1100131 and 1130392, and F.I.M. is funded by Conicyt/Fondap 15110006.
Author information
Authors and Affiliations
Contributions
S.E. conceived the project, S.E. and F.M. analysed the data, S.E. drafted the manuscript. F.I.M., G.M.R. and C.V. collaborated in manuscript writing, G.M.R. and C.V. designed the GWAS studies, obtained funding, enrolled participants and collected information on their geographic origins, performed/supervised array experiments. All authors reviewed and accepted the final version.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Supplementary information
Supplementary Information
Supplementary Figure 1 and Supplementary Tables 1-3 (PDF 174 kb)
Rights and permissions
This work is licensed under a Creative Commons Attribution 4.0 International License. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in the credit line; if the material is not included under the Creative Commons license, users will need to obtain permission from the license holder to reproduce the material. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/
About this article

Cite this article
Eyheramendy, S., Martinez, F., Manevy, F. et al. Genetic structure characterization of Chileans reflects historical immigration patterns. Nat Commun 6, 6472 (2015). https://doi.org/10.1038/ncomms7472
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/ncomms7472
This article is cited by
-
Universal healthcare coverage for first episode of schizophrenia-spectrum disorders in Chile: analysis of the administrative database
European Archives of Psychiatry and Clinical Neuroscience (2022)
-
Ultraviolet erythemal radiation in Central Chile: direct and indirect implication for public health
Air Quality, Atmosphere & Health (2021)
-
Correlation between female sex, IL28B genotype, and the clinical severity of bronchiolitis in pediatric patients
Pediatric Research (2020)
-
Development of a small panel of SNPs to infer ancestry in Chileans that distinguishes Aymara and Mapuche components
Biological Research (2020)
-
Chilean Registry for Neuroendocrine Tumors: A Latin American Perspective
Hormones and Cancer (2019)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
