
Abstract
Large population-based registry studies have shown that breast cancer prognosis is inherited. Here we analyse single-nucleotide polymorphisms (SNPs) of genes implicated in human immunology and inflammation as candidates for prognostic markers of breast cancer survival involving 1,804 oestrogen receptor (ER)-negative patients treated with chemotherapy (279 events) from 14 European studies in a prior large-scale genotyping experiment, which is part of the Collaborative Oncological Gene-environment Study (COGS) initiative. We carry out replication using Asian COGS samples (n=522, 53 events) and the Prospective Study of Outcomes in Sporadic versus Hereditary breast cancer (POSH) study (n=315, 108 events). Rs4458204_A near CCL20 (2q36.3) is found to be associated with breast cancer-specific death at a genome-wide significant level (n=2,641, 440 events, combined allelic hazard ratio (HR)=1.81 (1.49–2.19); P for trend=1.90 × 10−9). Such survival-associated variants can represent ideal targets for tailored therapeutics, and may also enhance our current prognostic prediction capabilities.
Similar content being viewed by others

Introduction
We have previously shown, through large population-based registry studies, that survival from breast cancer is correlated among relatives, consistent with an inherited cancer prognosis1,2,3,4. A potential explanation for the heritability of survival would be that family members are predisposed to developing a breast cancer tumour of predefined aetiology and predetermined tumour characteristics. This is plausible given the observation that carriers of high- and moderate-risk germline mutations in genes such as BRCA1, BRCA2, CHEK2 and PALB2, are predisposed to specific subtypes of breast cancer5,6,7,8, and that many common variants identified through genome-wide association studies (GWAS) tend to be associated with specific subtypes, with some variants more strongly associated with oestrogen receptor (ER)-negative or triple-negative breast cancer9,10,11, while others more strongly associated with ER-positive breast cancer12,13,14.
It is also possible that the inherited predeterminants of survival lie not in the biology of the tumour but rather the milieu in which the tumour arises. The tumour microenvironment is composed of tumour cells, fibroblasts, endothelial cells and infiltrating immune cells, which may inhibit or promote tumour growth and progression. There is empirical support for the concept that a host immune response might enhance the effects of conventional chemotherapy, conceivably having an influence on breast cancer outcome. For example, the presence of tumour-associated lymphocytes in a breast tumour has been suggested to be an independent predictor of neoadjuvant chemotherapy response15. Other studies have shown the host immune system to be involved in the elimination of tumour cells to control cancer growth16,17.
In this candidate pathway study, we investigate the pre-specified hypothesis that the germline common variants of genes involved in immune response and inflammation can predict the response to breast cancer survival for ER-negative, chemotherapy-treated patients. We identify a single-nucleotide polymorphism (SNP) near the CCL20 gene (2q36.3), which is associated with a difference in the clinical outcome of ER-negative breast cancer treated with chemotherapy independent of known tumour prognostic features.
Results
Individual patient-level genetic and phenotypic data were extracted from European studies in a prior large-scale genotyping experiment conducted in the Breast Cancer Association Consortium (BCAC), part of the Collaborative Oncological Gene-environment Study (COGS) initiative18. For this study, we selected women of European descent inferred from genetic ancestry with invasive breast cancer, who have had no previous diagnosis of the disease. Subjects missing follow-up information on vital status, time to vital status, date of study entry and cause of death data were excluded.
The selection of only ER-negative patients in this study was strongly motivated by prior insight. A Swedish study of the breast cancer prognosis of 834 sister pairs in which both were affected showed that younger sisters with poor older sister survival had worse survival than younger sisters with good older sister survival (number of breast cancer deaths within 5 years from diagnosis in younger sisters, nevent=65, P=0.02 in a multivariate proportional hazard (Cox) analysis)3. When stratified by ER subtypes, the increased risk of death from ER-negative breast cancer for younger sisters with poor older sister survival compared with younger sisters with good older sister survival was found to be almost sevenfold (n=139 sister pairs, nevent=28, hazard ratio (HR)=6.69 (1.36–32.91), P=0.02) in contrast to sister pairs with the ER-positive disease (n=584 sister pairs, nevent=28, HR=1.54 (0.48–4.98), P=0.50) (unpublished data). In addition, in a recent Breast International Group phase III trial, increasing lymphocytic infiltration was found to be associated with excellent prognosis only for patients with node-positive, ER-negative/HER2-negative disease19. Twenty studies with ER-negative cases and at least one event (breast cancer-specific death) were eligible for the combined analysis (Supplementary Table 1). As we were primarily interested in response to chemotherapy, patients missing information on chemotherapy were not considered in our analyses. The 14 studies (n=1,804) included in the combined analysis for the chemotherapy-treated subgroup are summarized in Supplementary Table 2. A total of 279 breast cancer-specific deaths were recorded in a 15-year follow-up.
For the replication phase, four iCOGS Asian studies with ER-negative breast cancer cases treated with chemotherapy and at least one death due to breast cancer in a 15-year follow-up were analysed (n=522, 53 events, Supplementary Table 3). Early-onset breast cancer patients from the independent Prospective Study of Outcomes in Sporadic versus Hereditary breast cancer (POSH) study20,21 were used as a second replication data set. In particular, we performed our replication using ER-negative breast cancer patients treated with chemotherapy in the POSH study’s Stage 1 discovery data set samples (n=315, 108 events) selected to facilitate studies on breast cancer prognosis22. The breast cancer-specific death rate is thus particularly high and there were few cases that drop out due to lack of phenotype information.
All women in participating studies had provided written consent for the research and approval for each study was obtained from their local ethical review board (Supplementary Tables 1 and 3). Collection of blood samples and clinical data from subjects was performed in accordance with local guidelines and regulations.
Genotyping was conducted using a custom Illumina iSelect genotyping array (iCOGS), comprising 211,115 SNPs. Details of quality control of the iCOGS data are described in detail elsewhere18. Briefly, individuals were excluded for any of the following reasons: genotypically not female XX (XY, XXY or XO), overall call rate <95%, low or high heterozygosity (P<1 × 10−6, determined separately for individuals of European and East Asian ancestry), genotypes discordant with those determined in previous genotyping such that the individual appeared to be different, genotypes for the duplicate sample that seemed to be from a different individual and cryptic duplicates. SNPs with call rates of <95%, SNPs that deviated from Hardy–Weinberg equilibrium in controls at P<1 × 10−7 and SNPs for which the genotypes were discrepant in >2% of duplicate samples across all COGS consortia were excluded. The final analyses in the parent COGS study were based on data from 199,961 SNPs.
Key genes related to human immunology and inflammation were identified from two comprehensive and highly curated gene panels (nCounter GX Human Immunology Kit and nCounter GX Human Inflammation Kit, NanoString Technologies, Seattle, WA, USA), which are commercially available (Supplementary Data 1). We identified all SNPs on the iCOGS within a 50-kb window of any gene on the panel. Out of 8,237 unique SNPs extracted from COGS, we further removed SNPs with low minor allele frequency (<0.05) and low call rate (<0.95). After quality-control exclusions, we analysed 7,020 non-overlapping SNPs in 557 unique gene regions (from 597 genes on the original nCounter panels).
In the POSH study, rs4458204 was genotyped on the Illumina 660 W-Quad SNP array. Details can be found in the parent POSH article22. Briefly, genotyping for the samples was conducted in two separate batches in two locations (Mayo Clinic and the Genome Institute of Singapore). To ensure harmonization of the genotype calling, the intensity data were combined and used to generate genotypes based on the algorithm available in the genotyping module of Illumina’s Genome Studio software.
Breast cancer survival, right-truncated at 15 years after diagnosis, was modelled by using multivariate Cox proportional hazard analyses, treating each SNP as an ordinal variable (that is, 0, 1 and 2 copies of minor allele). Analyses were partially adjusted for age at diagnosis (years), study and seven principal components (as recommended by COGS) as covariates. As comparisons of survival are often confounded by differences in the patients, their tumours or the treatments, we further included covariates on tumour characteristics and treatment in a fully adjusted model,which is presented as the main analysis in this study. The fully adjusted model was additionally adjusted for tumour size (≤2, >2 and ≤5, or >5 cm), presence of distant metastasis (M from the Tumour, Nodes and Metastasis (TNM) staging system), lymph node status (negative/positive), histopathological grade (well, moderately or poorly differentiated), surgery (no surgery, breast-saving or mastectomy with or without axillary), hormone therapy (Yes/No) and radiotherapy (no radiation, breast only, breast and lymph nodes or lymph nodes only). Missing values were coded separately as missing. Separate baseline hazard functions were fitted for each study. Between-study heterogeneity was evaluated by using the Q statistic and the I2 metric23. Estimated HRs and confidence limits are presented for heterozygotes and minor allele homozygotes, relative to the major allele homozygotes. Delayed entry (left truncation) was allowed for all models to adjust for the timing of blood draw. The proportional hazards assumption for each SNP was assessed using Schoenfeld’s test statistics24. The Kaplan–Meier estimator for delayed-entry data was computed using the survfit function from the survival package in R. The Nagelkerke pseudo R-squared statistic was used to assess variance explained25.
To adjust for multiple testing without overly penalizing the tests, we determined the number of ‘independent’ SNPs. SNPs were thinned using the ‘—indep-pairwise’ option in PLINK26 such that all SNPs within a window size of 50 SNPs (step size of 10) were required to have r2<0.2. This procedure resulted in a set of 2,184 independent SNPs pruned by linkage disequilibrium. The Bonferroni-adjusted threshold for 2,184 independent tests is 2.29 × 10−5. In addition to standard Bonferroni adjustment, a 10% false discovery rate (FDR) threshold was applied to try to identify more candidate SNPs associated with breast cancer outcome. An FDR-adjusted P-value of 0.10 implies that 10% of significant tests will result in false positives.
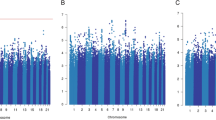
The results for tests of association between 7,020 human immunology and inflammation SNPs and risk of death from ER-negative breast cancer are summarized in Supplementary Data 2 and 3. The deviation of the smaller observed P-values from those expected (λ=1.16) is consistent with multiple weak associations between these SNPs and survival for ER-negative breast cancer patients (Fig. 1). In particular, for a single SNP rs4458204_A located on chromosome 2:228637113 (minor allele frequency=0.12), the χ2 (1df) association test statistic was much higher than for the other SNPs and was close to surpassing the threshold for experiment-wide significance after Bonferroni adjustment (P<2.29 × 10−5) in the partially adjusted analysis stratified by study and adjusted for only population stratification and age (n=2,218, 332 events, per-allele HR=1.54 (1.26–1.90), P for trend=3.62 × 10−5, Supplementary Data 3). However, after further adjusting for appropriate patient tumour and treatment characteristics, the SNP association surpassed the threshold for genome-wide significance (P<5 × 10−8) (per-allele HR=1.83 (1.47–2.27), P for trend=4.68 × 10−8, Table 1 and Fig. 2), a conservative threshold which is likely to be overly stringent27. The lack of an association signal tower could be because the iCOGS was designed to have minimum linkage disequilibrium across SNPs. No SNP within a 100-kb window is correlated to rs4458204 with r2>0.2 (Fig. 3). The association was stronger for a subset of ER-negative patients who had been treated with chemotherapy (n=1,804, 279 events, per-allele HR=1.96 (1.55–2.47), P for trend=1.60 × 10−8). We found no evidence of heterogeneity in the per-allele HR across 14 studies (I2=0%, P for heterogeneity=0.84; forest plot in Fig. 4). Univariate Kaplan–Meier survival curves of breast cancer-specific survival for ER-negative patients treated with chemotherapy by rs4458204 genotypes are presented in Fig. 5 (log-rank P=3.18 × 10−6). The median survival time for the AA genotype at rs4458204 was 11.5 years. SNPs in three other loci corresponding to regions around the transforming growth factor beta receptor II (TGFBR2), interleukin 12B (IL12B) and interferon induced with helicase C domain 1 (IFIH1) genes were found to be associated with breast cancer-specific death with FDR-adjusted P<0.10 (Fig. 2).

QQ plot of the observed −log10 P-values (y axis) versus the ‘expected’ −log10 rank P-values (x axis) for trend tests of association of 7,020 human immunology and inflammation SNPs, with the risk of dying from breast cancer for all ER-negative breast cancer patients (black/below) and ER-negative patients treated with adjuvant chemotherapy (blue/above) (genomic inflation factor, λ=1.16 and 1.14, respectively) in the discovery phase. The grey region indicates bootstrapped 95% confidence intervals. The diagonal red line indicates expected results under null hypothesis. The dotted lines indicate Bonferroni threshold for multiple-testing correction (2,184 independent tests with r2<0.2).

Manhattan plot showing directly genotyped SNPs plotted according to chromosomal location (x axis), with −log10 P-values (y axis) derived from trend tests of association of 7,020 human immunology and inflammation SNPs with the risk of dying from breast cancer for all ER-negative patients (above) and ER-negative patients treated with chemotherapy (below) in the discovery phase. Blue and red lines indicate the Bonferroni threshold for multiple-testing correction for 2,184 (r2<0.2) and genome-wide significance level (5 × 10−8), respectively. SNPs with FDRs of <10% are additionally encircled and denoted in green. Chromosomal positions are based on NCBI build 36.

The closest SNP flanking the left of rs4458204 is >9.5 Mb away. Chromosomal positions are based on NCBI build 36. P-values are derived from trend tests of association. Plotted using ‘snp.plotter’ package in R.

We found no evidence of heterogeneity in the per-allele HR across 14 studies (I2=0%, P for heterogeneity=0.84). P-value for both fixed and random effects meta-analyses on all 14 studies was 3.93 × 10−7, whereas on this reduced data set (studies with <10events excluded for clarity of presentation) it was 1.76 × 10−6, which passes the preset Bonferroni threshold of 2.29 × 10−5 for 2,184 independent tests. The 95% confidence interval for each study is given by a horizontal line, and the point estimate is given by a square whose height is inversely proportional to the s.e. of the estimate. The summary odds ratio is drawn as a diamond with horizontal limits at the confidence limits and width inversely proportional to itss.e.

Analysis were adjusted only for time of blood draw and stratified by genotype. The p-value shown is based on the log-rank test. The number of events/n for each genotype are in parenthesis as follows rs4458204_GG (195/1415, single continuous line), rs4458204_AG (73/357, broken line) and rs4458204_AA (11/32, dotted line). The log rank P-value for this analysis was 3.18 x 10−6.
From our replication study of rs4458204_A using multi-ethnic iCOGS Asian samples (522 ER-negative patients treated with chemotherapy, 53 events; see Supplementary Table 3), the per-allele HR after controlling for tumour characteristics and treatment was 1.97 (0.94–4.17); P for trend=0.07, Table 1). Together with multivariable-adjusted results from a second replication of the SNP using early-onset breast cancer patients POSH study, significant evidence of replication was observed (combined per-allele HR=1.52 (1.07–2.15), P for trend=0.02, Table 1). From a meta-analysis of both discovery and replication stages, the association of the SNP with risk of dying from breast cancer was found to be 1.81 (1.49–2.19; P for trend=1.90 × 10−9) with no observed heterogeneity (I2=1.4%, P for heterogeneity=0.36; Table 1).
The cluster plots for the most significant SNP in our analysis, rs4458204 (CCL20), and three other index SNPs of loci for which the associated test statistic passed FDR<0.1, namely rs1367610 (TGFBR2), rs2569254 (IL12B) and rs13422767 (IFIH1), were examined. All SNPs showed good discrimination of the three genotypes in cluster plots for the BCAC samples that passed quality control in the parent COGS study (Fig. 6).

Cluster plots are shown for rs4458204 (CCL20), rs1367610 (TGFBR2), rs2569254 (IL12B) and rs13422767 (IFIH1) for the BCAC samples that passed quality control in the parent COGS study18. The SNP genotypes have been assigned based on cluster formation in scatter plots of normalized allele intensities X and Y. Each circle represents one individual’s genotype. Blue and red clouds indicate homozygote genotypes for the SNP (AA/aa), green heterozygote (Aa) and black undetermined. Three distinct, tight clusters exhibited by all four representative SNPs indicate good discrimination of the three genotypes.
Discussion
rs4458204 is located ~41.5 kb upstream of the chemokine (C–C motif) ligand 20 (CCL20) gene. Chemokines are important mediators of immune response, and CCL20 has previously been shown to induce migration and proliferation of breast epithelial cells28. CCL20 has also been reported to be strongly chemotactic for lymphocytes and weakly attracts neutrophils29. However, rs4458204 was not found to be a significant (P for trend>0.05) expression trait quantitative locus in any of the tissues (that is, adipose subcutaneous, artery tibial, blood, heart, lung, muscle skeletal, nerve tibial, skin and thyroid) reported on the publicly available Genotype-Tissue Expression Portal30.
It is of note that the association of rs4458204_A with the survival of ER-negative breast cancer patients treated with chemotherapy increased and the strength of the association became stronger after adjustment for tumour characteristics and type of treatment (per-allele HR (95% confidence interval) from 1.64 (1.31–2.05) to 1.96 (1.55–2.47), P for trend from 1.27 × 10−5 to 1.60 × 10−8). This suggests that tumour characteristics and treatment covariates are likely to be confounders and thus it is desirable to include them in the fully adjusted model to obtain a more accurate effect size of the genetic factor. Moreover, it has also been shown that adjustment for prognostic factors will lead to a gain in power for statistical analyses. Genes in other regions indentified by the less stringent FDR threshold (TGFBR2, IL12B and IFIH1) have been implicated to play a role in breast cancer disease progression, suggesting that there are potentially more variants in immune response and inflammation genes that are associated with breast cancer prognosis. Although TGFBR2 is a breast cancer susceptibility locus18, none of the SNPs annotated to this gene was significantly associated with breast cancer risk (P>0.05) in the parent COGS study.
Although several GWAS have aimed to find genetic markers associated with breast cancer survival to date22,31,32,33, few credible variants have been robustly identified. The threefold greater breast cancer mortality for affected sisters is comparable in magnitude to the familial relative risk for breast cancer incidence, for which close to 100 independent susceptibility loci based on common variants (SNPs) have been identified, and these explain only a small proportion of familial aggregation of risk18. The failure to identify a similar number of survival-associated loci influencing survival may reflect the much lower statistical power for survival analyses to date, but may also reflect the substantial heterogeneity in tumour characteristics and treatment. As such, it has been suggested that sufficiently powered studies investigating specific cancer subtypes or treatment subgroups would need to be much larger to discover more regions in the genome associated with breast cancer prognosis33. In agreement, the association between rs4458204 and breast cancer survival for this study was found to be more pronounced (larger HR) for women with ER-negative disease treated with chemotherapy (Table 1). However, as we did not study the association for women with ER-positive disease, the impact of this SNP on survival for those women remains unclear. One of the strengths of our study is that we have based our gene selection on commercially pre-designed panels of genes known to be differentially expressed in immunology and inflammation, which covers a comprehensive and validated list of relevant genes. The use of the iCOGS array in the BCAC consortium allowed us to investigate genetic variation across >500 immune response genes and provided an unprecedented large sample size with detailed clinical information to examine their associations with breast cancer survival. The results were also replicated by the POSH study, which is not part of the COGS consortium. However, SNPs related to immune response and inflammation were not specifically selected to be put on the iCOGS panel to give comprehensive coverage of these genes; only 557 of the 597 genes (~93%) were represented. The proportion of total phenotypic variance (Nagelkerke pseudo R-squared) explained by this SNP alone was also small, at ~1.3%, suggesting that many more variants will need to be discovered for such genetic data to be useful in a clinical setting.
Our findings suggest that host factors affecting the ability to respond to systemic treatment or to mount an effective immunologic response contribute to the heritability of prognosis. Such survival-associated variants can represent ideal targets for tailored therapeutics and may also enhance our current prognostic prediction capabilities.
Additional information
How to cite this article: Li, J. et al. 2q36.3 is associated with prognosis for oestrogen receptor-negative breast cancer patients treated with chemotherapy. Nat. Commun. 5:4051 doi: 10.1038/ncomms5051 (2014).
References
Lindstrom, L. S. et al. Familial concordance in cancer survival: a Swedish population-based study. Lancet Oncol. 8, 1001–1006 (2007).
Hartman, M. et al. Is breast cancer prognosis inherited? Breast Cancer Res. 9, R39 (2007).
Lindström, L. et al. Association of breast cancer survival among sisters is not explained by shared primary tumour characteristics. Submitted (2013).
Verkooijen, H. M. et al. Breast cancer prognosis is inherited independently of patient, tumor and treatment characteristics. Int. J. Cancer 130, 2103–2110 (2012).
Roy, R., Chun, J. & Powell, S. N. BRCA1 and BRCA2: different roles in a common pathway of genome protection. Nat. Rev. Cancer 12, 68–78 (2012).
Honrado, E., Osorio, A., Palacios, J. & Benitez, J. Pathology and gene expression of hereditary breast tumors associated with BRCA1, BRCA2 and CHEK2 gene mutations. Oncogene 25, 5837–5845 (2006).
Heikkinen, T. et al. The breast cancer susceptibility mutation PALB2 1592delT is associated with an aggressive tumor phenotype. Clin. Cancer Res. 15, 3214–3222 (2009).
Teo, Z. L. et al. Tumour morphology predicts PALB2 germline mutation status. Br. J. Cancer 109, 154–163 (2013).
Stevens, K. N. et al. Common breast cancer susceptibility loci are associated with triple-negative breast cancer. Cancer Res. 71, 6240–6249 (2011).
Antoniou, A. C. et al. A locus on 19p13 modifies risk of breast cancer in BRCA1 mutation carriers and is associated with hormone receptor-negative breast cancer in the general population. Nat. Genet. 42, 885–892 (2010).
Haiman, C. A. et al. A common variant at the TERT-CLPTM1L locus is associated with estrogen receptor-negative breast cancer. Nat. Genet. 43, 1210–1214 (2011).
Broeks, A. et al. Low penetrance breast cancer susceptibility loci are associated with specific breast tumor subtypes: findings from the Breast Cancer Association Consortium. Hum. Mol. Genet. 20, 3289–3303 (2011).
Stacey, S. N. et al. Common variants on chromosomes 2q35 and 16q12 confer susceptibility to estrogen receptor-positive breast cancer. Nat. Genet. 39, 865–869 (2007).
Stacey, S. N. et al. Common variants on chromosome 5p12 confer susceptibility to estrogen receptor-positive breast cancer. Nat. Genet. 40, 703–706 (2008).
Denkert, C. et al. Tumor-associated lymphocytes as an independent predictor of response to neoadjuvant chemotherapy in breast cancer. J. Clin. Oncol. 28, 105–113 (2010).
Apetoh, L. et al. The interaction between HMGB1 and TLR4 dictates the outcome of anticancer chemotherapy and radiotherapy. Immunol. Rev. 220, 47–59 (2007).
Zitvogel, L. & Kroemer, G. The immune response against dying tumor cells: avoid disaster, achieve cure. Cell Death Differ. 15, 1–2 (2008).
Michailidou, K. et al. Large-scale genotyping identifies 41 new loci associated with breast cancer risk. Nat. Genet. 45, 353–361 (2013).
Loi, S. et al. Prognostic and predictive value of tumor-infiltrating lymphocytes in a phase III randomized adjuvant breast cancer trial in node-positive breast cancer comparing the addition of docetaxel to doxorubicin with doxorubicin-based chemotherapy: BIG 02-98. J. Clin. Oncol. 31, 860–867 (2013).
Eccles, D. et al. Prospective study of Outcomes in Sporadic versus Hereditary breast cancer (POSH): study protocol. BMC Cancer 7, 160 (2007).
Copson, E. et al. Prospective observational study of breast cancer treatment outcomes for UK women aged 18-40 years at diagnosis: the POSH study. J. Natl Cancer Inst. 105, 978–988 (2013).
Rafiq, S. et al. Identification of inherited genetic variations influencing prognosis in early-onset breast cancer. Cancer Res. 73, 1883–1891 (2013).
Huedo-Medina, T. B., Sanchez-Meca, J., Marin-Martinez, F. & Botella, J. Assessing heterogeneity in meta-analysis: Q statistic or I2 index? Psychol. Methods 11, 193–206 (2006).
Schoenfeld, D. Partial residuals for the proportional hazards regression model. Biometrika 69, 239–241 (1982).
Nagelkerke, N. J. D. A note on a general definition of the coefficient of determination. Biometrika 78, 691–692 (1991).
Purcell, S. et al. PLINK: a tool set for whole-genome association and population-based linkage analyses. Am. J. Hum. Genet. 81, 559–575 (2007).
Milestone in Anhui. Nat. Genet. 43, 613 (2011).
Marsigliante, S., Vetrugno, C. & Muscella, A. CCL20 induces migration and proliferation on breast epithelial cells. J. Cell. Physiol. 228, 1873–1883 (2013).
Hieshima, K. et al. Molecular cloning of a novel human CC chemokine liver and activation-regulated chemokine (LARC) expressed in liver. Chemotactic activity for lymphocytes and gene localization on chromosome 2. J. Biol. Chem. 272, 5846–5853 (1997).
GTEx Consortium. The Genotype-Tissue Expression (GTEx) project. Nat. Genet. 45, 580–585 (2013).
Shu, X. O. et al. Novel genetic markers of breast cancer survival identified by a genome-wide association study. Cancer Res. 72, 1182–1189 (2012).
Kiyotani, K. et al. A genome-wide association study identifies locus at 10q22 associated with clinical outcomes of adjuvant tamoxifen therapy for breast cancer patients in Japanese. Hum. Mol. Genet. 21, 1665–1672 (2012).
Azzato, E. M. et al. A genome-wide association study of prognosis in breast cancer. Cancer Epidemiol. Biomarkers Prev. 19, 1140–1143 (2010).
Acknowledgements
We thank all the individuals who took part in these studies and all the researchers, study staff, clinicians and other health care providers, technicians and administrative staff who have enabled this work to be carried out. This work was financed by the Swedish Research Council (grant number: 521-2011-3187 and 524-2011-6857 to L.L.); Gösta Miltons Donationsfond to L.L., Swedish Cancer Society (grant number: CAN 2010/807 and 5128-B07-01PAF to K.C.) and a UNESCO-L’Oréal International Fellowship to J.L. This study was also supported by the Cancer Risk Prediction Center (CRisP; www.crispcenter.org), a Linneus Centre (Contract ID 70867902) financed by the Swedish Research Council. Funding for the iCOGS infrastructure came from: the European Community’s Seventh Framework Programme under grant agreement number 223175 (HEALTH-F2-2009-223175) (COGS), Cancer Research UK (C1287/A10118, C1287/A 10710, C12292/A11174, C1281/A12014, C5047/A8384, C5047/A15007, C5047/A10692), the National Institutes of Health (CA128978) and Post-Cancer GWAS initiative (1U19 CA148537, 1U19 CA148065 and 1U19 CA148112—the GAME-ON initiative), the Department of Defence (W81XWH-10-1-0341), the Canadian Institutes of Health Research (CIHR) for the CIHR Team in Familial Risks of Breast Cancer, Komen Foundation for the Cure, the Breast Cancer Research Foundation and the Ovarian Cancer Research Fund. The ABCFS and OFBCR work was supported by grant UM1 CA164920 from the National Cancer Institute (USA). The OFBCR work was also supported by the Canadian Institutes of Health Research ‘CIHR Team in Familial Risks of Breast Cancer’ programme. The ABCS was funded by Dutch Cancer Society grant numberNKI2007-3839; M.K.S. was funded by Dutch Cancer Society grant number NKI2009-4363. The work of the BBCC was partly funded by ELAN-Programme of the University Hospital of Erlangen. The BCAC is funded by CR-UK (C1287/A10118 and C1287/A12014). Meetings of the BCAC have been funded by the European Union COST programme (BM0606). E.S. is supported by NIHR Comprehensive Biomedical Research Centre, Guy’s & St Thomas’ NHS Foundation Trust in partnership with King’s College London, United Kingdom. I.T. is supported by the Oxford Biomedical Research Centre. The HEBCS was supported by the Helsinki University Central Hospital Research Fund, Academy of Finland (132473), the Finnish Cancer Society, The Nordic Cancer Union and the Sigrid Juselius Foundation. Financial support for KARBAC was provided through the regional agreement on medical training and clinical research (ALF) between Stockholm County Council and Karolinska Institutet, the Swedish Cancer Society, The Gustav V Jubilee foundatin and Bert von Kantzows foundation. The KBCP was financially supported by the special Government Funding (EVO) of Kuopio University Hospital grants, Cancer Fund of North Savo, the Finnish Cancer Organizations, the Academy of Finland and by the strategic funding of the University of Eastern Finland. kConFab is supported by grants from the National Breast Cancer Foundation, the NHMRC, the Queensland Cancer Fund, the Cancer Councils of New South Wales, Victoria, Tasmania and South Australia, and the Cancer Foundation of Western Australia. The kConFab Clinical Follow-Up Study was funded by the NHMRC, Cancer Australia and the National Breast Cancer Foundation. K.A.P. is a National Breast Cancer Foundation Practitioner Fellow. L.M.B.C. is supported by the ‘Stichting tegen Kanker’ (232-2008 and 196-2010). The MARIE study was supported by the Deutsche Krebshilfe e.V. (70-2892-BR I), the Hamburg Cancer Society, the German Cancer Research Center and the genotype work in part by the Federal Ministry of Education and Research (BMBF) Germany (01KH0402). MCCS cohort recruitment was funded by VicHealth and Cancer Council Victoria. The MCCS was further supported by Australian NHMRC grants 209057, 251553 and 504711, and by infrastructure provided by Cancer Council Victoria. The MEC was supported by NIH grants CA63464, CA54281, CA098758 and CA132839. The NBCS was supported by grants from the Norwegian Research council (155218/V40, 175240/S10 to A.L.B.D., FUGE-NFR 181600/V11 to V.N.K. and a Swizz Bridge Award to A.L.B.D.). The OBCS was supported by research grants from the Finnish Cancer Foundation, the Sigrid Juselius Foundation, the Academy of Finland, the University of Oulu and the Oulu University Hospital. The ORIGO study was supported by the Dutch Cancer Society (RUL 1997-1505) and the Biobanking and Biomolecular Resources Research Infrastructure (BBMRI-NL CP16). pKARMA is a combination of the KARMA and LIBRO-1 studies. KARMA was supported by Märit and Hans Rausings Initiative Against Breast Cancer. KARMA and LIBRO-1 were supported the Cancer Risk Prediction Center (CRisP; www.crispcenter.org), a Linnaeus Centre (Contract ID 70867902) financed by the Swedish Research Council. The RBCS was funded by the Dutch Cancer Society (DDHK 2004-3124, DDHK 2009-4318). SASBAC was supported by funding from the Agency for Science, Technology and Research of Singapore (A*STAR), the US National Institute of Health (NIH) and the Susan G. Komen Breast Cancer Foundation. K.C. was financed by the Swedish Cancer Society (5128-B07-01PAF). SEARCH is funded by a programme grant from Cancer Research UK (C490/A10124) and supported by the UK National Institute for Health Research Biomedical Research Centre at the University of Cambridge. SKKDKFZS is supported by the DKFZ. The TWBCS is supported by the Institute of Biomedical Sciences, Academia Sinica and the National Science Council, Taiwan. MYBRCA is funded by research grants from the Malaysian Ministry of Science, Technology and Innovation (MOSTI), Malaysian Ministry of Higher Education (UM.C/HlR/MOHE/06) and Cancer Research Initiatives Foundation (CARIF). The HERPACC was supported by a Grant-in-Aid for Scientific Research on Priority Areas from the Ministry of Education, Science, Sports, Culture and Technology of Japan, by a Grant-in-Aid for the Third Term Comprehensive 10-Year Strategy for Cancer Control from Ministry Health, Labour and Welfare of Japan, by a research grant from Takeda Science Foundation, by the Health and Labour Sciences Research Grants for Research on Applying Health Technology from Ministry Health, Labour and Welfare of Japan and by the National Cancer Center Research and Development Fund. The SEBCS was supported by the Korea Health 21 R&D Project (AO30001), Ministry of Health and Welfare, Republic of Korea. POSH was supported by Funding Breast Cancer Campaign (NOV210PR62) and Cancer Research UK (C1275/A9896). The content of this manuscript does not necessarily reflect the views or policies of the National Cancer Institute or any of the collaborating centers in the Breast Cancer Family Registry (BCFR), nor does mention of trade names, commercial products, or organizations imply endorsement by the US Government or the BCFR. J.L.H. is a National Health and Medical Research Council (NHMRC) Senior Principal Research Fellow and M.C.S. is a NHMRC Senior Research Fellow. D.F.E. is a Principal Research Fellow of CR-UK.The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Author information
Authors and Affiliations
Contributions
J.Li, K.C., L.L. M.L. and J.N.F. performed the statistical analysis and drafted the manuscript. D.E. conceived and coordinated the synthesis of the iCOGS array and led BCAC. P.H. coordinated COGS. M.K.S., P.D.P.P., K.M., J.D., M.K.B. and Q.W. provided data management support for BCAC. M.K.S., L.J.V.V., S.C. and E.R. coordinated ABCS. M.C.S., C.A., G.S.D. and J.L.H coordinated ABCFS. P.A.F., L.H., A.B.E. and M.W.B. coordinated BBCC. H.N., C.B., T.A.M. and K.A. coordinated HEBCS. A.L. and S.M. coordinated KARBAC. A.M., V.-M.K., J.M.H. and V. Kataja coordinated KBCP. G.C.-T., K-A.P. and S.-A.M. coordinated kConFab. D.L, B.T., A.S. and H.W. coordinated LMBC. J.C.-C., D.F.-J., P.S. and A.R. coordinated MARIE. G.G.G., L.B. and G.S. coordinated MCCS. C.A.H., B.E.H., F.S. and L.L.M. coordinated MEC. V. Kristensen, G.I.G.A., A.-L.B.-D and S.N. coordinated NBCS. R.W., K.P., A.J.-V. and M.G. coordinated OBCS. I.L.A., J.A.K., G.G. and S.T. coordinated OFBCR. P.D., R.T. and C.S. coordinated ORIGO. P.H., K.H., K.C. and J.Li coordinated pKARMA. M.H., M.K., A.H. and A.v.d.O. coordinated RBCS. U.H., D.T., H.U.U. and T.R. coordinated SKKDKFZS. J.Liu, J.N.F., C.C.K. and Y.L. coordinated SASBAC. A.D., M.S., R.L. and J.D. coordinated SEARCH. C.-Y.S., C.-N.H., P.-E.W. and S.-T.C coordinated TWBCS. S.H.T., N.A.M.T., C.H.Y. and G.F.H coordinated MYBRCA. K.M., H. Ito, H. Iwata and K.T. coordinated HERPACC. D.K., J.-Y.C., S.K.P. and K.-Y.Y. coordinated SEBCS. S.R., T.M., J.W.T. and D.M.E. coordinated POSH. All authors provided critical review of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Supplementary information
Supplementary Tables
Supplementary Tables 1-3 (PDF 262 kb)
Supplementary Data 1
List of investigated genes implicated in human immune response and inflammation. (XLSX 128 kb)
Supplementary Data 2
Association between SNPs implicated in human immunology and inflammation and risk of dying from breast cancer for ER-negative patients within 15 years. (XLSX 2590 kb)
Supplementary Data 3
Association between SNPs implicated in human immunology and inflammation and risk of dying from breast cancer for ER-negative patients treated with chemotherapy within 15 years. (XLSX 1353 kb)
Rights and permissions
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. The images or other third party material in this article are included in the article's Creative Commons license, unless indicated otherwise in the credit line; if the material is not included under the Creative Commons license, users will need to obtain permission from the license holder to reproduce the material. To view a copy of this license, visit http://creativecommons.org/licenses/by-nc-sa/4.0/
About this article

Cite this article
Li, J., Lindström, L., Foo, J. et al. 2q36.3 is associated with prognosis for oestrogen receptor-negative breast cancer patients treated with chemotherapy. Nat Commun 5, 4051 (2014). https://doi.org/10.1038/ncomms5051
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/ncomms5051
This article is cited by
-
Association of germline genetic variants with breast cancer-specific survival in patient subgroups defined by clinic-pathological variables related to tumor biology and type of systemic treatment
Breast Cancer Research (2021)
-
Assessment of variation in immunosuppressive pathway genes reveals TGFBR2 to be associated with prognosis of estrogen receptor-negative breast cancer after chemotherapy
Breast Cancer Research (2015)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
