
Abstract
Haplotype phasing of genetic variants is important for clinical interpretation of the genome, population genetic analysis and functional genomic analysis of allelic activity. Here we present phASER, an accurate approach for phasing variants that are overlapped by sequencing reads, including those from RNA sequencing (RNA-seq), which often span multiple exons due to splicing. Using diverse RNA-seq data we demonstrate that this provides more accurate phasing of rare variants compared with population-based phasing and allows phasing of variants in the same gene up to hundreds of kilobases away that cannot be obtained from DNA sequencing (DNA-seq) reads. We show that in the context of medical genetic studies this improves the resolution of compound heterozygotes. Additionally, phASER provides measures of haplotypic expression that increase power and accuracy in studies of allelic expression. In summary, phasing using RNA-seq and phASER is accurate and improves studies where rare variant haplotypes or allelic expression is needed.
Similar content being viewed by others


Introduction
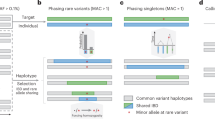
The phasing of rare and de novo variants is crucial for identifying putative causal variants in medical genetics, for example by distinguishing compound heterozygotes from two variants on the same allele. Existing methods to phase variants include phasing by transmission1, only available in familial studies, population based phasing2,3, which is ineffective for rare and de novo variants, phasing by sequencing long genomic fragments4,5, which requires specialized and costly technology, and phasing using expression data by inferring haplotype through allelic imbalance6, which only applies to loci with well-detected allelic expression7. An alternative approach termed ‘read backed phasing’ uses readily available short read DNA-seq8,9,10; however it is limited by the relatively short distances which can be spanned by the reads. Our approach, called phasing and allele specific expression from RNA-seq (phASER), extends the idea of read backed phasing to RNA-seq reads, which due to splicing enables phasing of variants over long genomic distances. Data from both DNA-seq and RNA-seq libraries can be integrated by phASER to produce high confidence phasing of proximal variants, primarily within the same gene, and when available population phasing can also be leveraged to produce full chromosome-length haplotypes (Fig. 1a).

(a) phASER produces accurate variant phasing through the use of combined DNA and RNA read backed phasing integrated with population phasing. Due to splicing, RNA-seq reads often span exons and UTRs, allowing read backed phasing over long ranges, while high coverage exome and whole genome sequencing can phase close proximity variants. For each group of read connected variants a local haplotype is produced by testing all possible phase configurations, and selecting the configuration with the most support (Supplementary Fig. 1). Local haplotype blocks can be phased relative to one another when population data is available by anchoring the phase to common variants, where the population phase is likely correct. (b) Concordance of read backed phasing across sequencing assays and population phasing with phasing by transmission using the Illumina NA12878 Platinum Genome as a function of variant minor allele frequency. Concordance is defined per variant as the percentage of variant—variant phase events that are correct as compared with the known transmission phase. (c) Percentage of phased variants that can be phased at greater than or equal to increasing genomic distances using WES, WGS, paired-end 75 and 250 RNA-seq data in two tissues (whole blood and LCLs) of four GTEx individuals. Solid lines represent the means, and dotted lines the standard error. (d,e) Contribution of read backed phasing at rare coding (MAF≤1%) variants (d) and all rare variants (e) across sequencing assays and GTEx RNA-seq tissue types for four individuals. Values shown are the mean percentage of rare variants within an individual that can be assigned a genome wide phase using phase anchoring. Error bars show the standard error. The fold increase in the number of rare variants that can be phased using DNA-seq with the addition of combined RNA-seq libraries is indicated.
In this work we thoroughly benchmark phASER, showing that our method for haplotype assembly is accurate by comparison to other commonly used read backed phasing methods using gold standard datasets. We show that through enhanced quality control measures RNA-seq can be used to accurately phase variants over much larger distances than DNA-seq, and that the addition of RNA-seq significantly increases the number of rare variants that can be phased. To demonstrate this we apply phASER to genetic studies and show that the inclusion of RNA-seq improves the resolution of compound heterozygotes, and propose an example workflow for the incorporation of expression and phase information in medical genetic studies. Finally, we show that haplotypic expression generated by phASER improves allelic expression studies by increasing power and accuracy.
Results
Haplotype assembly and phasing accuracy
Assembling haplotypes from observations of alleles on the same read is a necessary step of read backed phasing, and has been accomplished using various approaches8,9,10. Our approach in phASER employs a two step method, first defining edges between the alleles of each pair of variants observed on the same sequencing fragments, and second, determining the most likely phase within a set of connected variants given the edges defined in the first step (Supplementary Fig. 1). During the first step the phase with the most supporting reads is chosen, and a binomial test is performed to determine if the number of reads supporting alternative phases is greater than would be expected from sequencing noise, allowing for filtering of low confidence phasing (Supplementary Figs. 1a, 2a). For the second step, phASER counts the number of edges that support each possible haplotype configuration (2n variants), and selects the configuration with the most support. To prevent an exponential increase in haplotype search space while maintaining accuracy phASER splits large haplotypes into sub-blocks at points spanned by the fewest edges (Supplementary Figs S1c, 2c). Phasing is performed chromosome wide, with no restriction on the distance between variants, which allows phasing at the longer genomic distances spanned by RNA-seq reads.
As a gold standard we compared phASER used with high coverage RNA-seq data generated from a lymphoblastoid cell line (LCL)11 to Illumina’s NA12878 Platinum Genome, sequenced at × 200 and phased by transmission using parental data (http://www.illumina.com/platinumgenomes/), and found that with default settings phASER identified the correct phasing for 98% of the variants phased. Unlike population based phasing, read backed phasing across sequencing assays performed well for low frequency variants (Fig. 1b). Finally, we benchmarked haplotype assembly in phASER against HapCUT9 and the GATK Read Backed Phasing tool, which are designed for DNA-seq reads, using both simulated and experimental WGS data, as well as WES data. We found phASER to be similar in accuracy, runtime and haplotype length to HapCUT, while having additional features required for RNA-seq based phasing (Supplementary Fig. 3). Both phASER and HapCUT were dramatically more accurate than the GATK tool (Supplementary Fig. 3a).
Contribution of RNA-seq to variant phasing
To evaluate the increase in phasing distance facilitated by RNA-seq reads, we compared phASER results between WES, WGS and two read lengths of paired-end (PE) RNA-seq (75 bp and 250 bp) from 4 Genotype-Tissue Expression (GTEx) individuals where matched libraries were available12. As expected, long read RNA-seq yielded the greatest proportion of distantly phased variants, with an average of 4,300 equal to 5.8% of variants phased greater than 5 kb, while at this distance WES and WGS phased 0 and 7 variants respectively (Fig. 1c). At large distances the performance of RNA-seq phasing decreased as a result of read mapping errors; however this could be easily addressed by filtering reads based on alignment score (Supplementary Fig. 4a). Using RNA-seq reads phasing remained accurate over a range of read lengths (Supplementary Fig. 4b), but longer read lengths greatly increased both the distance and number of variants that could be phased (Supplementary Fig. 4c).
When population phased data are available, haplotype blocks are phased relative to each other, producing a single genome wide phase through a method we call phase anchoring. Phase anchoring uses the population phase of each variant in a block weighted by their allele frequencies to assign a genome wide phase, since common variants are more likely to have correct population phasing (Supplementary Fig. 2b). A similar approach is used by methods that integrate read backed phasing with population phasing10; however including it in our method allows this strategy to be used with RNA-seq reads and prevents the need to perform population phasing each time new sequencing data for a sample is available. Using our approach with RNA-seq from accessible tissues enabled genome wide phasing of up to 15.4% of rare coding variants (MAF≤1% in GTEx), and 21.3% when tissues were combined, while WES yielded 19% and × 5 WGS yielded 11.1% (Fig. 1d). When used in combination, the addition of combined RNA-seq data enabled a × 1.5 increase in phasing for WES and a × 2.4 increase in phasing for WGS. When considering all rare variants, WGS performed better, and the contribution of RNA-seq to WES was more significant (Fig. 1e).
Application of phASER to genetic studies
We next sought to benchmark phASER when used with RNA-seq data in the context of genetic studies. First we used GTEx data to demonstrate the number of coding variants that could be phased as a function of the number of tissues for which RNA sequencing data is available. We began with whole blood, and progressively added libraries from up to 14 other distinct tissues. With joint phasing using 14 tissues, almost 50% of all heterozygous coding variants could be phased with at least one other variant (Supplementary Fig. 5a). When used individually, the total proportion of coding variants that could be phased for a given tissue was 15–27% (Supplementary Fig. 5b), and was dependent on transcriptome diversity13 (Supplementary Fig. 5c), but not total read depth (Supplementary Fig. 5d).
We next applied phASER to assess its ability to identify cases of compound heterozygosity for damaging variants using WES and RNA-seq data from 345 1,000 Genomes individuals14,15. First we assessed the accuracy of compound heterozygote calls using population phasing compared with WES+RNA read backed phasing. As expected, protein-truncating and splice variants that are usually rare were enriched in cases where population phasing was incorrect, with cases involving stop gain variants being × 2.9 more likely to be phased incorrectly than others (Supplementary Fig. 6). Next, to demonstrate the advantage of using RNA-seq data over WES alone for phasing, we identified instances of compound heterozygosity involving at least one rare (MAF<1%) variant with predicted loss of function (LoF) or damaging protein effects16. Including RNA-seq data from only one tissue (LCLs)14 increased the number of compound heterozygotes that could be identified in the most severe class (LoF × Damaging) by × 1.3 over WES alone, and ranged between 1.19 and × 1.15 for other combinations, demonstrating the added benefit of phasing over larger distances (Fig. 2a).

(a) Instances of compound heterozygosity involving rare (MAF<0.01) loss of function (L), probably damaging (D) or possibly damaging (P) coding variants called using phase data generated by phASER with either RNA-seq reads, exome-seq reads, or both for 345 1,000 Genomes European individuals with Geuvadis LCL RNA-seq data. The fold increases in the number of compound heterozygotes resolved when RNA-seq data is included are indicated. (b) Example application of phASER to prioritize rare (alternative AF<0.01 in 1,000 Genomes) recessive alleles in a medical genetics study that includes both WES and RNA-seq in a tissue of clinical relevance17. Boxplots show the number of heterozygous alleles per individual after these successive filtering steps were applied: CADD phred score≥15, expressed in fibroblast RNA-seq data, phased with read backed phasing, involved in either trans or cis interactions with another deleterious variant (CADD≥15) using RNA and exome data (RNA+WES) or exome alone (WES). The fold increases from including RNA-seq data are indicated. (c) The difference in percentage of individuals with significant allelic imbalance (binomial test, FDR<0.05) for each gene with a known heterozygous cis expression quantitative trait loci (eQTL) calculated by either summing all single variant read counts across haplotypes using population phasing, or by summing phASER haplotype blocks phased relative to each other with phase anchoring (Supplementary Fig. 7). Genes where an increase in the percentage of individuals with significant allelic imbalance is observed when summing single variant counts are coloured red, representing false positives, while those with a decrease, representing false negatives, are coloured blue. The bar plot above indicates the percentage of the 1,118 genes where allelic expression was measured that fall into each category.
Finally, we used paired WES and fibroblast RNA-seq from 20 patients with congenital diaphragmatic hernia17 to illustrate phASER’s application to a typical medical genetics workflow to prioritize putatively causal variants and benchmark the advantage of including RNA-seq reads for phasing. Assuming that causative variants would be rare, recessive, damaging and expressed in the tissue of disease relevance, phase information generated with phASER from WES and RNA-seq reads could prioritize a median of 25 alleles involved in cases of compound heterozygosity per individual (trans), while assigning a lower priority to a median of 44 alleles, where the alleles were on the same haplotype (cis) (Fig. 2b). The inclusion of RNA-seq boosted the number of cases that could be identified by × 2.6 for trans and × 1.4 for cis interactions.
Application of phASER to allelic expression studies
Outside of medical genetics, variant phasing is important for allelic expression (AE) analysis, which aims to quantify the relative expression of one allele versus another7, and has emerged as a powerful method to study diverse biological processes including cis-regulatory variation14, parent of origin imprinting18, and protein-truncating variants19. AE is typically measured at single heterozygous variants; however the unit of interest is often a gene or transcript, which may contain many variants. Integrating read counts across phased variants can greatly improve the power to detect AE, but simply adding up allele counts can lead to double counting of reads (if variants are covered by the same read), and both false positives and negatives as a result of incorrect phasing. To address this limitation, when used with RNA-seq data, phASER quantifies and reports the expression of phased haplotypes by reporting the number of unique reads that map to each. To benchmark the impact of this utility we generated haplotypic counts at genes with known expression quantitative trait loci14 for 345 Geuvadis samples using either single variants with population based phasing alone, or phased haplotype blocks generated by phASER (Supplementary Fig. 7). By improving phase and preventing double counting phASER reduced false positives at 56.2% of genes tested, while uncovering false negatives at 7.3% (Fig. 2c).
Discussion
In summary, phASER provides scalable and high confidence variant phasing, incorporating RNA-seq and DNA-seq data with population phasing, allowing phasing over longer distances than previous read based methods. We have demonstrated that this method has direct applications in medical genetics, where improved resolution of compound heterozygotes can lead to changes in their interpretation. Furthermore, phASER improves the accuracy of haplotypic expression when integrating allelic counts across variants by reducing false positives. Our approach will complement the existing repertoire of phasing methods3 and makes use of a readily available experimental data type that has become trivial to produce, allowing for phasing of rare and distant variants at high accuracy. As RNA-seq experiments become commonplace in medical and population scale studies, phASER will become a valuable tool for rare variant phasing.
Methods
Implementation of read backed phasing in phASER
phASER is written in Python and requires the following libraries: IntervalTree, pyVCF, SciPy, NumPy. In addition it requires Samtools and Bedtools to be installed. Aligned reads (BAM format) are mapped to heterozygous variants, and for each heterozygous variant a hashed set of all overlapping reads is produced, which allows for quick comparison of overlapping reads between variants. Connections between variants are established whenever a read (or read mate) overlaps more than one variant. For each pair of connected variants, edges between alleles are defined by determining the phase that has the most read support, and a test is performed to determine if there is significant evidence of a conflicting phase (see below) (Supplementary Fig. 1a). Those edges that fail, based on a user defined significance threshold (by default nominal P<0.01) are removed. It should be noted that this test addresses instances where due to sequencing error individual bases on a read have been misread, and it does not address errors with read mapping, which can happen at sites with genetic variation. For a discussion of methods to address allelic read mapping issues please see Castel et al.7. Haplotype blocks are generated by starting with a single unphased variant and recursively adding all other variants with read connections. Block construction is completed when no further variants can be added. Once all haplotype blocks have been generated, phasing of the variants is determined using the previously defined allele edges. If the allele edges within a haplotype block resolve into two distinct groups, where each group contains only one allele of a given variant, the haplotype is considered to be conflict free and the phase is reported (Supplementary Fig. 1b). In instances where two haplotypes cannot be immediately resolved, the haplotypic configuration with the most edges supporting it is identified. This is accomplished by testing all possible haplotype configurations (2n), however runtime is prevented from exponentially increasing by splitting haplotypes into sub-blocks at positions spanned by the fewest number of edges (Supplementary Fig. 1c–d). These sub-blocks are then phased relative to one another to produce a single haplotype phase (Supplementary Fig. 1e). The maximum number of variants within a sub-block is user defined, and is 15 by default. Our simulations show that when using this approach accuracy remains high, while runtime is drastically reduced (Supplementary Fig. 2c). Read variant mapping, edge definition and haplotype assembly can all by parallelized for an increase in speed (Supplementary Fig. 3b).
Statistical test for conflicting phasing between two variants
For each SNP pair covered by at least one read a test is performed that determines if the number of reads supporting alternative phasing (any phase other than the configuration chosen by phASER) could be observed by chance from sequencing noise alone. In this test, significance indicates more conflicting reads than would be expected from noise alone, and thus suggests that there may be an error in the phase selected by phASER. A conservative approach is to filter out any variant connections with a nominal P value of <0.01 (Supplementary Fig. 2a). Less stringent P value thresholds can be used to retain more blocks, with the caveat that some may have incorrect phasing. Filtered connections will not be used during the haplotype block construction process.
The test is based on a uniform error model in which a true allele nucleotide can be substituted randomly to any other nucleotide. All pairwise substitutions in this model are assumed to be equally probable. We denote this pairwise substitution probability with ɛ. Let us assume a pair of SNPs a1|a2 and b1|b2 with a haplotype structure a1b1| a2b2. Let a1:b1 denote a read spanning alleles a1 and b1. Reads supporting the true haplotype in this case are a1:b1, and a2:b2, and any other configurations correspond to conflicting evidence. Let us only consider reads generated from the first haplotype. The probability of observing a read supporting the correct haplotype structures, ps, is (1−3ɛ)2+ɛ2, where the first term corresponds to the probability of observing a1:b1 (the case in which either of the sites being affected by noise in the read), and the second term is the probability of observing a2:b2 (the case in which both sites were altered by noise in the read and happened to have the other second allele). Binomial distribution is used to evaluate the probability of observing equal or less supporting reads for two given SNP sites:

where ns and n are the number of reads supporting the chosen haplotype structure and total number of reads respectively. The pair-wise substitution rate ɛ is calculated from over all SNP sites as:

where mismatches correspond to all cases that a nucleotide other than the reference or the alternative allele where observed at the site. Only variants where >50% of the reads come from the reference and alternative alleles are used to calculate the substitution rate to avoid inflation of noise estimates as a result of genotyping error.
Genome wide phasing using phase anchoring
When population phased data are available phASER will attempt to determine the genome wide phase for each haplotype block using phase anchoring. Phase anchoring operates on the assumption that common variants are more likely to be phased correctly using population data, so for each variant within a haplotype the genome wide phase determined by population phasing is weighted by the variant allele frequency. The genome wide phase across all variants with the most support after weighting is selected for each haplotype block.
For each haplotype block:
α (phase support for configuration 1)=Σ(MAF of variants supporting configuration 1)
β (phase support for configuration 2)=Σ(MAF of variants supporting configuration 2)
if α>β genome wide phase=configuration 1
if α<β genome wide phase=configuration 2
Anchor Phase Confidence=max(α, β)/(α+β)
phASER settings
The following settings were used unless otherwise noted. For all libraries: alignment score quantile cutoff of 0.05, BASEQ of 10, and conflicting configuration threshold of 0.01, indels ignored, and maximum block size of 15. For RNA-seq libraries: no maximum insert size, MAPQ of 255 (indicates unique in STAR). For exome-seq libraries: 500 bp maximum insert size, MAPQ of 40. For whole genome sequencing libraries: 1,000 bp maximum insert size, MAPQ of 40. All variants in HLA genes were filtered.
Code availability
Source code and complete documentation for phASER and its associated tools are available through GitHub (https://github.com/secastel/phaser). In addition to the phASER core software we provide two scripts: one which given an input VCF that has been phased using phASER will identify all interactions between alleles (phASER Annotate), and retrieve information such as allele frequency and predicted variant effect if supplied with the appropriate files, and second, a script which will use haplotypic counts produced by phASER in combination with population phasing to produce gene level haplotypic read counts for use in allelic expression studies (phASER Gene AE).
Benchmarking
Benchmarking was run on CentOS 6.5 with Java version 1.6 and Python 2.7 on an Intel Xeon CPU E7- 8830 @ 2.13 GHz, with GATK v3.4, HapCUT v0.7, and phASER v0.5. The GATK tool was run with default settings, with the exception of: min_mapping_quality_score=40, maxPhaseSites=15, min_base_quality_score=10. HapCUT was run with the following settings: maxIS=500 (WES), 1,000 (WGS), 1e6 (PE 75 RNA), mbq=10, mmq=40 (WES and WGS), mmq=255 (PE 75 RNA). phASER was run with default settings (see phASER settings). Simulated PE 75 WGS data was produced with ART Chocolate Cherry Cake 03-19-2015 (ref. 20) from a NA12878 1,000 Genomes Phase 3 population phased reference. WES and WGS libraries used were those listed above.
Data processing
For analyses involving 1,000 Genomes individuals, phase 3 genotypes and population phasing where were used with hg19 aligned exome-seq data, both downloaded from the 1,000 Genomes website (http://www.1000genomes.org). Raw (FASTQ) RNA sequencing data from 1,000 Genomes individual derived LCLs was downloaded from the European Nucleotide Archive (ERP001942), and aligned with STAR to hg19. For comparison of phase statistics between sequencing assays the following GTEx individuals were used: S32W, T5JC, T6MN, WFON. Both short and long read RNA-seq was obtained for whole blood and LCLs, and aligned using STAR to hg19. WES reads were aligned using Bowtie 2 to hg19. GTEx data is available through dbGaP for authorized users (phs000424.v6.p1). For rare variant phasing comparison, RNA-seq from whole blood, fibroblasts, sun exposed skin, and adipose were used, alongside WES and WGS libraries, from GTEx individuals X4EO, XUW1, U8XE, XOTO. GTEx individual ZAB4 was used for comparison of number phased variants versus number of RNA-seq tissues used. For comparison to transmission phasing the following data from the 1,000 Genomes individual NA12878 was used: exome-seq downloaded from 1,000 Genomes website, whole genome sequencing data (NCBI SRA ERS179577), RNA-seq from a LCL (NCBI GEO GSM1372331), transmission phased genotypes (Illumina Platinum Genome, http://www.illumina.com/platinumgenomes/). Whole genome sequencing libraries were down sampled to 5x to increase speed of analyses and ensure comparable read depths across sequencing assays.
Data availability
Data used in this study was retrieved from the 1,000 Genomes website (http://www.1000genomes.org), the European Nucleotide Archive (ERP001942), dbGaP (phs000424.v6.p1), NCBI Sequence Read Archive (ERS179577), NCBI Gene Expression Omnibus (GSM1372331), and Illumina Platinum Genome, http://www.illumina.com/platinumgenomes/).
Additional Information
How to cite this article: Castel, S.E. et al. Rare variant phasing and haplotypic expression from RNA sequencing with phASER. Nat. Commun. 7:12817 doi: 10.1038/ncomms12817 (2016).
References
Roach, J. C. et al. Chromosomal haplotypes by genetic phasing of human families. Am. J. Hum. Genet. 89, 382–397 (2011).
Delaneau, O., Marchini, J. & Zagury, J.-F. A linear complexity phasing method for thousands of genomes. Nat. Methods 9, 179–181 (2012).
Browning, S. R. & Browning, B. L. Haplotype phasing: existing methods and new developments. Nat. Rev. Genet. 12, 703–714 (2011).
Kuleshov, V. et al. Whole-genome haplotyping using long reads and statistical methods. Nat. Biotechnol. 32, 261–266 (2014).
Pendleton, M. et al. Assembly and diploid architecture of an individual human genome via single-molecule technologies. Nat. Methods 12, 780–786 (2015).
Berger, E., Yorukoglu, D. & Berger, B. in Research in Computational Molecular Biology, 9029, 28–29 (Springer International Publishing, 2015)..
Castel, S. E., Levy-Moonshine, A., Mohammadi, P., Banks, E. & Lappalainen, T. Tools and best practices for data processing in allelic expression analysis. Genome Biol. 16, 195 (2015).
Yang, W.-Y. et al. Leveraging reads that span multiple single nucleotide polymorphisms for haplotype inference from sequencing data. Bioinformatics 29, 2245–2252 (2013).
Bansal, V. & Bafna, V. HapCUT: an efficient and accurate algorithm for the haplotype assembly problem. Bioinformatics 24, i153–i159 (2008).
Delaneau, O., Howie, B., Cox, A. J., Zagury, J.-F. & Marchini, J. Haplotype estimation using sequencing reads. Am. J. Hum. Genet. 93, 687–696 (2013).
Li, X. et al. Transcriptome sequencing of a large human family identifies the impact of rare noncoding variants. Am. J. Hum. Genet. 95, 245–256 (2014).
GTEx Consortium. Human genomics. The Genotype-Tissue Expression (GTEx) pilot analysis: multitissue gene regulation in humans. Science 348, 648–660 (2015).
Melé, M. et al. Human genomics. The human transcriptome across tissues and individuals. Science 348, 660–665 (2015).
Lappalainen, T. et al. Transcriptome and genome sequencing uncovers functional variation in humans. Nature 501, 506–511 (2013).
Abecasis, G. R. et al. A global reference for human genetic variation. Nature 526, 68–74 (2015).
Adzhubei, I. A. et al. A method and server for predicting damaging missense mutations. Nat. Methods 7, 248–249 (2010).
Yu, L. et al. Increased burden of de novo predicted deleterious variants in complex congenital diaphragmatic hernia. Hum. Mol. Genet. 24, 4764–4773 (2015).
Baran, Y. et al. The landscape of genomic imprinting across diverse adult human tissues. Genome Res. 25, 927–936 (2015).
Rivas, M. A. et al. Human genomics. Effect of predicted protein-truncating genetic variants on the human transcriptome. Science 348, 666–669 (2015).
Huang, W., Li, L., Myers, J. R. & Marth, G. T. ART: a next-generation sequencing read simulator. Bioinformatics 28, 593–594 (2012).
Acknowledgements
We would like to thank the Geuvadis Consortium, the GTEx Consortium, the members of the Lappalainen lab, and the bioinformatics team of the New York Genome Center. The Genotype-Tissue Expression (GTEx) Project was supported by the Common Fund of the Office of the Director of the National Institutes of Health. Additional funds were provided by the NCI, NHGRI, NHLBI, NIDA, NIMH, and NINDS. Donors were enroled at Biospecimen Source Sites funded by NCI\SAIC-Frederick, Inc. (SAIC-F) subcontracts to the National Disease Research Interchange (10XS170), Roswell Park Cancer Institute (10XS171), and Science Care, Inc. (X10S172). The Laboratory, Data Analysis, and Coordinating Center (LDACC) was funded through a contract (HHSN268201000029C) to The Broad Institute, Inc. Biorepository operations were funded through an SAIC-F subcontract to Van Andel Institute (10ST1035). Additional data repository and project management were provided by SAIC-F (HHSN261200800001E). The Brain Bank was supported by a supplements to University of Miami grants DA006227 & DA033684 and to contract N01MH000028. Statistical Methods development grants were made to the University of Geneva (MH090941 & MH101814), the University of Chicago (MH090951, MH090937, MH101820, MH101825), the University of North Carolina - Chapel Hill (MH090936 & MH101819), Harvard University (MH090948), Stanford University (MH101782), Washington University St Louis (MH101810), and the University of Pennsylvania (MH101822).
We are thankful to all the CDH families for their generous contributions. We are grateful for the technical assistance provided by Patricia Lanzano, Jiancheng Guo, Liyong Deng, Badri Vardarajan and Jing He from Columbia University. We also thank Dr George B Mychaliska and Jeannie Kreutzman from University of Michigan; Dr Robert Cusick and Sheila Horak from University of Nebraska; Dr Douglas Potoka, Laurie Luther and Min Shi from University of Pittsburgh; Dr Gundrun Aspelund and Julia Wynn from Columbia University; Dr Marc S. Arkovitz from Tel Hashomer Medical Center; Dr Charles J. Stolar from California Pediatric Surgery Group; Dr Kenneth S. Azarow from Oregon Health Science Center for enroling participants. This work was supported by National Institute of Health grant [HD057036] and was supported in part by Columbia University's Clinical and Translational Science Award (CTSA); grant [UL1 RR024156] from National Center for Advancing Translational Sciences/National Institutes of Health (NCATS-NCRR/NIH) a grant from CHERUBS, a grant from the National Greek Orthodox Ladies Philoptochos Society, Inc. and generous donations from The Wheeler Foundation, Vanech Family Foundation, Larsen Family, Wilke Family and many other families.
Author information
Authors and Affiliations
Contributions
S.E.C. and T.L. wrote the manuscript, S.E.C. analysed the data, S.E.C. and P.M. developed the statistical model, W.K.C and Y.S. provided CDH data.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Supplementary information
Supplementary Information
Supplementary Figures 1-7 (PDF 1311 kb)
Rights and permissions
This work is licensed under a Creative Commons Attribution 4.0 International License. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in the credit line; if the material is not included under the Creative Commons license, users will need to obtain permission from the license holder to reproduce the material. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/
About this article

Cite this article
Castel, S., Mohammadi, P., Chung, W. et al. Rare variant phasing and haplotypic expression from RNA sequencing with phASER. Nat Commun 7, 12817 (2016). https://doi.org/10.1038/ncomms12817
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/ncomms12817
This article is cited by
-
A distant global control region is essential for normal expression of anterior HOXA genes during mouse and human craniofacial development
Nature Communications (2024)
-
Haplotype-aware modeling of cis-regulatory effects highlights the gaps remaining in eQTL data
Nature Communications (2024)
-
Molecular quantitative trait loci in reproductive tissues impact male fertility in cattle
Nature Communications (2024)
-
SEESAW: detecting isoform-level allelic imbalance accounting for inferential uncertainty
Genome Biology (2023)
-
Single-cell multiomics of the human retina reveals hierarchical transcription factor collaboration in mediating cell type-specific effects of genetic variants on gene regulation
Genome Biology (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
