
Abstract
Bacteria of the class Dehalococcoidia (DEH), phylum Chloroflexi, are widely distributed in the marine subsurface, yet metabolic properties of the many uncultivated lineages are completely unknown. This study therefore analysed genomic content from a single DEH cell designated ‘DEH-J10’ obtained from the sediments of Aarhus Bay, Denmark. Real-time PCR showed the DEH-J10 phylotype was abundant in upper sediments but was absent below 160 cm below sea floor. A 1.44 Mbp assembly was obtained and was estimated to represent up to 60.8% of the full genome. The predicted genome is much larger than genomes of cultivated DEH and appears to confer metabolic versatility. Numerous genes encoding enzymes of core and auxiliary beta-oxidation pathways were identified, suggesting that this organism is capable of oxidising various fatty acids and/or structurally related substrates. Additional substrate versatility was indicated by genes, which may enable the bacterium to oxidise aromatic compounds. Genes encoding enzymes of the reductive acetyl-CoA pathway were identified, which may also enable the fixation of CO2 or oxidation of organics completely to CO2. Genes encoding a putative dimethylsulphoxide reductase were the only evidence for a respiratory terminal reductase. No evidence for reductive dehalogenase genes was found. Genetic evidence also suggests that the organism could synthesise ATP by converting acetyl-CoA to acetate by substrate-level phosphorylation. Other encoded enzymes putatively conferring marine adaptations such as salt tolerance and organo-sulphate sulfohydrolysis were identified. Together, these analyses provide the first insights into the potential metabolic traits that may enable members of the DEH to occupy an ecological niche in marine sediments.
Similar content being viewed by others


Introduction
Marine subsurface sediments harbour immense quantities of microbial cells with the most recent estimate suggesting that they contain prokaryotic cell numbers equivalent to those estimated for the ocean water column and terrestrial soils, separately (Kallmeyer et al., 2012). These vast numbers suggest that microbes in the marine subsurface are key catalysts in global biogeochemical cycles, especially on geological timescales (D'Hondt et al., 2002; Wellsbury et al., 2002; D'Hondt et al., 2004). To date, numerous investigations have shed light on the phylogenetic composition of microbial life within marine subsurface sediments. From these investigations, it has repeatedly emerged that bacteria affiliated with the phylum Chloroflexi are widely distributed and in some cases represent up to 80% of the bacterial 16S rRNA gene sequences in deep sediments (Parkes et al., 2005), and average ∼17% of the bacterial 16S rRNA gene sequences recovered from various sites and depths (Fry et al., 2008). Chloroflexi are hence of particular interest in terms of understanding microbial life and biogeochemical cycles within the marine subsurface. In spite of this, essentially nothing is known about the metabolic properties or ecological roles of marine subsurface Chloroflexi because these bacteria continue to evade cultivation in the laboratory (D'Hondt et al., 2004; Toffin et al., 2004; Batzke et al., 2007; Webster et al., 2011).
Among the Chloroflexi, sequences affiliated with a distinct class-level clade known as the Dehalococcoidia (DEH) (previously known as the Dehalococcoidetes) (Löffler et al., 2012) are the most widespread and frequently detected in the marine subsurface (Inagaki et al., 2003; Parkes et al., 2005; Inagaki et al., 2006; Webster et al., 2006; Biddle et al., 2008; Nunoura et al., 2009; Blazejak and Schippers 2010; Biddle et al., 2011). To date, our knowledge about the metabolic properties of members of this clade is derived from several closely related cultivated strains, that is, Dehalococcoides mccartyi strains (Löffler et al., 2012), Dehalogenimonas lykanthroporepellens strains (Moe et al., 2009), Dehalogenimonas alkenigignens strains (Bowman et al., 2012) and ‘Dehalobium chlorocoercia’ strain DF-1 (May et al., 2008). These isolates are unified by their ability to grow via organohalide respiration, that is, they use halogenated organic compounds as terminal electron acceptors while using hydrogen as an electron donor in an anaerobic respiration (Tas et al., 2010). In addition, other relatively closely related DEH, including some marine phylotypes, have been implicated in organohalide respiration by enrichment or stable-isotope probing experiments (Fagervold et al., 2005; Watts et al., 2005; Bedard et al., 2007; Fagervold et al., 2007; Kittelmann and Friedrich 2008a, 2008b). Nevertheless, there are numerous 16S rRNA gene sequences within the whole DEH clade that are considerably divergent from these organohalide-respiring organisms. For these diverse and divergent phylotypes, assumptions about their metabolic properties, such as organohalide respiration on the basis of their 16S rRNA phylogeny, are not possible. It is therefore critical that attempts to understand the metabolic properties of these ‘unknown’ DEH are made.
In this study, a single-cell genomics approach was used to gain access to the genomic content of a marine subsurface DEH bacterium. Methods for single-cell genomics are now well-established and have been applied to microbial cells from various environments (Marcy et al., 2007; Woyke et al., 2009; Swan et al., 2011; Martinez-Garcia et al., 2012; Lloyd et al., 2013). Such an approach is therefore well suited for the study of uncultivated subsurface DEH because it can provide insights into their metabolic potential without the need for cultivation in the laboratory. To this end, we sequenced a large portion of a genome from an uncultivated member of this clade, which was obtained from sediments of Aarhus Bay, Denmark. This enabled us to predict key metabolic and phenotypic properties of the bacterium. It also serves as a reference for other related and unknown DEH organisms, and as a source to understand evolutionary aspects of DEH, such as the distribution of the genetic potential for organohalide respiration and the evolution of central metabolic pathways.
Materials and methods
Sampling, single-cell sorting, whole-genome amplification and PCR screening
All procedures for sediment sampling, extraction of microbial cells from sediments and separation of cells from sediment particles were performed as previously described (Lloyd et al., 2013) and during the same sampling expedition. Marine sediment was collected with a gravity corer on 22 March 2011, from an area of Aarhus Bay (56°9′35.889N, 10°28′7.893 E) characterised by shallow methane gas accumulations below ∼160 cm below sea floor (cmbsf) (Jensen and Bennike, 2009). The water depth at the sampling site was 16.3 m and the water had an in situ temperature of 2.5 °C at the sea floor. Sediment from a depth of 10 cmbsf was used for cell extraction and subsequent single-cell sorting. Procedures for single-cell sorting of fluorescently stained cells, cell lysis, whole-genome amplification and PCR screening of single amplified genomes were previously described (Lloyd et al., 2013). The sample processing described in this report were performed during the same sample processing run as reported previously (Lloyd et al., 2013), at the Bigelow Laboratory Single Cell Genomics Center (SCGC, www.bigelow.org/scgc). To outline the main steps of these procedures, cells were extracted from the sediment by diluting 1:5 in 1 × phosphate-buffered saline to form a slurry. The slurry was treated by sonication on ice for 2 × 20 s by placing the sonicating probe in the ice outside of the tube. The sonicated slurry was further diluted 1:8 with 1 × phosphate-buffered saline, vortexed briefly, and larger sediment particles were allowed to settle for 10 min. The supernatant was collected and sediment particles were further removed by a density gradient centrifugation step, whereby 0.75 ml of a 60% Nycodenz solution (w/v) was injected below the cell suspension with a fine needle and syringe, and was followed by centrifugation 10500 × g for 60 min at 4 °C. The upper phase was then collected, and 1 × TE and 5% w/v glycerol (final concentration) was added. The collected cells were stored at −80 °C and sent on dry ice for single-cell sorting in April 2011.
At the SCGC, cells were were diluted 1000 × in DNA-free Sargasso Sea water and filtered through a 40 μm mesh-size cell strainer (BD Biosciences, San Jose, CA, USA). Cells were stained for up to 120 min with SYTO-9 DNA stain (5 μM; Invitrogen, Carlsbad, CA, USA) and sorted by a MoFlo (Beckman Coulter, Carpenteria, CA, USA) flow cytometer using a 488 nm argon laser for excitation, a 70 μm nozzle orifice and a CyClone robotic arm for droplet deposition. Cells were sorted based on nucleic acid fluorescence and side-scatter, and using the ‘purify 0.5 drop’ mode for maximal purity. Gates with high fluorescence signals were sorted to minimise the chances of sorting autofluorescent sediment particles. Sorted cells were deposited into 384-well plates containing 600 nl 1 × TE buffer per well and stored at −80 °C until being subjected to lysis. For each of the 384 wells plate, 315 were used for single cells, 66 were dedicated as negative controls (no droplet deposition) and three received 10 cells each (positive controls).
Sorted cells were lysed by an initial freeze-thawing treatment (five cycles) and further lysed and, DNA was denatured by a cold alkaline KOH solution according to Raghunathan et al. (2005). Genomic DNA from the lysed cells was amplified using multiple displacement amplification (MDA) in 10 μl final volume with Repliphi polymerase (Epicentre, Madison, WI, USA). The MDA reactions were incubated at 30 °C for 12–16 h and inactivated at 65 °C for 15 min. Kinetics of MDA reactions was monitored by measuring the SYTO-9 fluorescence using a FLUOstar Omega microplate fluorescence reader (BMG Labtech, Cary, NC, USA).
Decontamination procedures for workspaces at the SCGC were performed as previously described (Stepanauskas and Sieracki, 2007) and included bleaching of sheath lines and subsequent flushing with DNA-free deionized water. Ultraviolet treatment of MDA reagents was used to remove high-molecular weight DNA contaminants (Woyke et al., 2011). Cell sorting and MDA setup were performed in a high-efficiency particulate air-filtered environment.
The PCR screening of MDA-derived DNA was performed using PCR with the primers 27F (5′-AGRGTTYGATYMTGGCTCAG-3′) and 907R (5′-CCGTCAATTCMTTTRAGTTT-3′) that target most bacteria (Lane 1991). Sequencing of products was aided by adding sequencing primers M13F (5′-GTAAAACGACGGCCAGT-3′) and M13R (5′-CAGGAAACAGCTATGACC-3′) to the general bacterial primers and using these for priming sequencing reactions (Lloyd et al., 2013). From the 630 sorted ‘single cells’, 71 high-quality 16S rRNA gene sequences were obtained and one well was selected for further analysis. This well contained Chloroflexi-related DNA. The full systematic name of the studied single amplified genome is ‘DEH bacterium SCGC AB-539-J10’, which we abbreviated to ‘DEH-J10’ throughout this report.
Sequencing of DNA, quality control of sequencing reads and genome assemblies
In order to obtain a sufficient quantity of DNA for shotgun sequencing, the single-cell MDA-derived DNA was reamplified in a second round of MDA, that is, eight replicate 125 μl reactions were performed and then pooled together. Barcoded sequencing was performed by GATC Biotech AG, Konstanz, Germany. Pyrosequencing using 454 chemistry was performed using the Genome Sequencer FLX System (Roche, Branford, CT, USA) generating 119 Mbp (340706 reads). Illumina sequencing was performed using the HiSeq2000 system (Illumina Inc., San Diego, CA, USA) in 50-bp single read mode generating 1.71 Gbp (33.5 M reads).
Unassembled Illumina sequence reads were analysed to identify reads coding for 16S rRNA genes of potentially contaminating microorganisms as described by Lloyd et al. (2013). Three reads carrying 16S rRNA gene fragments derived from other single-cell genomes that were sequenced in parallel were detected. Raw 454-pyrosequence reads were also checked, yet no foreign 16S rRNA gene fragments were detected in the 454-pyrosequence data. This suggested a post-sequencing mis-assignment of Illumina reads, that is, bioinformatic mis-assignment of barcoded reads into incorrect data sets due to sequencing errors within barcodes, as opposed to contamination of the original DNA, reagents or materials. Identification of mis-assigned Illumina reads, as well as their removal from the DEH-J10 data set, was conducted as previously detailed (Lloyd et al., 2013). In brief, this involved all-against-all BLASTN searches for all contigs from parallel sequenced single-cell assemblies to identify contigs present in multiple assemblies. These contigs were then inspected for read coverage values, which showed that for the few contigs found in multiple single-cell assemblies, read coverage values were always high for each contig in only one assembly and substantially lower in other assemblies. The assemblies which harboured contigs with high-coverage values were therefore considered the original source of each contig. Mis-assigned reads were removed by mapping reads from the single-cell genome assembly to mis-assigned contigs using Bowtie 2 (Langmead and Salzberg, 2012). After mis-assigned reads were removed, the remaining Illumina reads were assembled using SPAdes assembler version 2.3.0 (Bankevich et al., 2012) (parameters: -k 21,33,45 —sc). The 454-pyrosequence reads were dereplicated using cd-hit-454 (Niu et al., 2010) with a 98% similarity cutoff and assembled using GS De Novo Assembler version 2.6 (gsAssembler, Roche) (parameters: -mi 98 -ml 50). The two assemblies were finally combined using Sequencher version 5.0.1 (Genecodes) (Lloyd et al., 2013).
Gene annotations
Automatic gene annotations were initially performed using the MicroScope annotation pipeline (http://www.genoscope.cns.fr/agc/microscope/) (Vallenet et al., 2013) and the RAST server (Aziz et al., 2008). All predicted protein sequences were also extracted from the software platforms and were analysed by BLASTP comparisons against protein sequences from previously annotated reference DEH strains, that is, all DEH-J10 proteins were compared against custom databases of total protein sequences from D. mccartyi strain CBDB1, strain 195 and D. lykanthroporepellens BL-DC-9, separately, using an e-value threshold of 10−10. All DEH-J10 annotations for protein sequences that provided positive hits and revealed the same annotation as the previously annotated reference protein sequences were kept, whereas discrepancies were manually inspected and edited. All proteins that were not automatically assigned a function by the automatic annotation platforms were also analysed by BLASTP comparisons against the NCBI non-redundant database in order to assign tentative putative functions to proteins. Protein sequences described in this study were also heavily scrutinised with regards to local genomic context and synteny by manual inspections. Gene annotations described in the Results sections are listed in Supplementary Table 2, and gene numbers are prefixed by ‘DEHJ-10’. For many short contigs, the automatic open reading frame (ORF) prediction software did not call complete ORFs and therefore these contigs were binned into a ‘fragment’ data set. This fragment data set was analysed by BLASTX against the NCBI non-redundant database using an e-value threshold of 10−5.
Additional DNA contamination controls
PCR and sequencing of rRNA genes were also used to check the MDA-derived DNA for contamination by exogenous DNA. MDA-derived DNA from the single cell was diluted 1:50 and screened with primers 27F (5′-AGAGTTTGATCMTGGCTCAG-3′) and 907R (5′-CCGTCAATTCMTTTGAGTTT-3′) targeting 16S rRNA genes of most Bacteria (Lane, 1991), primers ARC-8F (5′-TCCGGTTGATCCTGCC-3′) and ARC-1492R (5′-GGCTACCTTGTTACGACTT-3′) targeting 16S rRNA genes of most Archaea (Teske et al., 2002) and primers A (5′-GAAACTGCGAATGGCTCATT-3′) and B (5′-CCTTCTGCAGGTTCACCTAC-3′) targeting 18S rRNA genes of Eukarya (Medlin et al., 1988). PCR products from positive reactions were cloned into pGEM-T Easy Vector System (Promega, Mannheim, Germany) and sequenced via the Sanger method.
In order to assess the genomic origin of assembled contigs, all contigs which had at least one complete ORF predicted (that is, all non ‘fragment’ data) were examined for the relatedness of their genetic content to genetic content derived from known DEH and other Chloroflexi genomes. All predicted proteins and ribosomal genes predicted by the annotation software (see above) were examined by BLASTP or BLASTN analyses (using an e-value threshold of 10−5), respectively, against the whole NCBI non-redundant database. Contigs were classified as ‘DEH-affiliated’ if hits were identified in the top five hits to the genera Dehalococcoides, Dehalogenimonas, Caldilinea, Anaerolinea, Ktedonobacter, Chloroflexus, Roseiflexus, Oscillochloris, Sphaerobacter, Thermobaculum or Thermomicrobium. If contigs did not harbour genetic content that gave a top five hits to any DEH or Chloroflexi, they were classified as ‘non-affiliated’.
Estimation of genome recovery and genome size
The total genome size was estimated based on conserved single copy gene and tRNA analyses (Woyke et al., 2009). To identify relevant conserved single copy genes for the DEH-J10 genome, the genomes of D. mccartyi strains CBDB1, 195, BAV1, GT and VS, and D. lykanthroporepellens BL-DC-9, that were available in January 2012 on the Joint Genome Institute’s Integrated Microbial Genomes website (http://img.jgi.doe.gov/cgi-bin/pub/main.cgi) (Markowitz et al., 2009), were included in the analysis. In total, we identified 462 conserved single copy gene in the reference genomes. The number of corresponding conserved single copy genes present in the DEH-J10 genomic content was then used to estimate the genome size. A second estimation was done by comparing tRNA gene numbers of DEH-J10 with the numbers of tRNA genes in the above described reference genomes.
Real-time PCR for quantification of DEH-J10 phylotype in Aarhus Bay sediments
DNA used in the real-time PCR assays was extracted from marine sediments in triplicate using a FastDNA Spin for Soil Kit (MP Biomedicals, Solon, OH, USA) following the manufacturer’s instructions with the following exceptions: 0.8 g of sediment was added to the initial tube containing the beads, and 780 μl of sodium phosphate buffer was added. After the DNA-binding step, the silica matrix and bound DNA was allowed to settle for 30 min. Each sample was eluted in 50 μl of supplied DNA elution solution water and combined.
Real-time PCR assays were performed using an ABI Prism 7000 Sequence Detection System (Applied Biosystems, Foster City, CA, USA). Quantification of total Bacteria was conducted using primers 341f (5′-CCTACGGGAGGCAGCAG-3′) and 534r (5′-ATTACCGCGGCTGCTGGCA-3′), which complement highly conserved regions in a highly diverse range of bacterial 16S rRNA genes (Wang and Qian 2009). The primers J10-16S-F (5′-GAGAGTGTAGGCGGCTCCCT-3′) and J10-16S-R (5′-GGTCGATACCTCCTATATCT-3′), which were designed in this study to specifically target the 16S rRNA gene of DEH-J10 and closely related phylotypes, were used for the quantification of DEH-J10. PCR reactions (total volume of 20 μl) contained 10 μl of 2 × SensiMix SYBR Kit PCR Master Mix (Bioline, Luckenwalde, Germany), 1 and 5 μM of each primer for bacterial and DEH-J10 assays, respectively, 1.0 μl of DNA template and deionized water up to 20 μl. PCR cycling conditions included an initial ‘enzyme activation’ step at 95 °C for 10 min, a short touchdown programme over five cycles consisting of 95 °C for 30 s, 64 °C (−1.0 °C per cycle until a final temperature of 59 °C was reached) for 30 s and 72 °C for 30 s, and this was followed by an additional 35 cycles of 95 °C for 30 s, 59 °C for 30 s and 72 °C for 30 s. Acquisition of fluorescence signal was performed during the 72 °C extension step of each cycle. Melt-curve analyses were performed after each run and PCR products were also checked by standard agarose gel electrophoresis. The DNA standards used in real-time PCR assays consisted of a serial dilution of purified PCR product derived from a cloned DEH-J10 16S rRNA gene, and a cloned DEH 16S rRNA previously retrieved in our laboratory from sediments of the Chilean margin were used for the DEH-10 and ‘total Bacteria’ assays, respectively. These gene sequences were PCR amplified directly from colonies using M13 vector-specific primers, checked using standard agarose gel electrophoresis, extracted and gel purified using a Wizard SV Gel and PCR Clean-Up Kit (Promega) according to the manufacturer’s instructions. DNA concentrations were determined using a NanoDrop ND1000 (NanoDrop Technologies, Wilmington, DE, USA) in triplicate. Measured concentrations of purified PCR product were then converted to copies per microliter, and the concentration was adjusted to 1 × 1011 copies μl−1 before performing 10-fold serial dilutions. A standard curve (1 × 106 to 1.0 × 102 copies per reaction) was generated and included in each run in triplicate. The detection limit was therefore also set at 1.0 × 102 copies per reaction for the DEH-J10 assay. Data and copy numbers were analysed using the real-time PCR systems accompanying software (STEPONE version 2.0, Applied Biosystems) following the manufacturers guidelines. The specificity of the assay using primers J10-16S-F and J10-16S-R was evaluated by comparing the primers ability with amplify DNA derived from other phylogenetically distinct DEH single cells, and by cloning and sequencing (12 clones) of the amplification products from the primers. A distance matrix of aligned sequences obtained was produced by Mega5 version 5.02 (Tamura et al., 2011) and revealed the maximum amount of sequence divergence among the obtained sequences was 1%. This suggests that the quantitative PCR assay is highly specific for 16S rRNA genes with ⩾99% sequence identity.
PCR assays for the detection of reductive dehalogenase genes
MDA-derived DNA was examined for the presence of genes encoding reductive dehalogenases by PCR assays with established primers and PCR conditions (Hölscher et al., 2004; Chow et al., 2010). MDA-derived DNA used as template in PCR assays was used undiluted or diluted 1:20 and 1:50.
Sequence accession
The obtained 16S rRNA gene was deposited in the GenBank database under the accession number KC880080 and the genomic data (contigs >200 bp) are present as BioProject PRJNA196991 in the GenBank database.
Results and discussion
Isolation of the single cell ‘DEH-J10’ and quantification in Aarhus Bay sediment
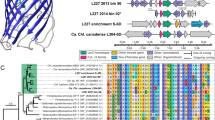
Sediments from Aarhus Bay, Denmark, were sampled from a depth of 10 cmbsf and used to obtain single cells by flow cytometric sorting of fluorescently stained cells. After cell lysis, MDA of the DNA and sequencing of 16S rRNA gene amplicons from sorted cells, a single cell designated ‘DEH-J10’ was selected for genome sequencing based on its high degree of divergence from cultivated strains and its unique phylogenetic position within the DEH (Figure 1). The closest cultivated strain was D. lykanthroporepellens strain BL-DC-9, which had only 86% sequence identity with the 16S rRNA gene of DEH-J10. The 16S rRNA gene of DEH-J10 phylogenetically affiliates with the previously termed ‘subphylum II’ clade of the Chloroflexi (Inagaki et al., 2006).

Phylogenetic tree based on 16S rRNA genes to examine the phylogeny of the single cell DEH-J10 (highlighted) compared with cultivated and uncultivated members of the Dehalococcoidia and other major groups of the Chloroflexi. The tree is based on the neighbor-joining algorithm with bootstrap resampling (1000 times). Nodes with bootstrap values ⩾50% are indicated by filled circles (●) and nodes with bootstrap values of ⩾90% are indicated by open circles (○). Deinococcus frigens (GenBank no. AJ585982) was used as an outgroup to root the tree. The scale bar represents 10% sequence divergence. Previously defined Chloroflexi subphylums ‘II’ and ‘IV’ (Inagaki et al, 2006) are also indicated for comparative purposes.
Quantitative real-time PCR analysis of the DEH-J10 16S rRNA gene phylotype in the Aarhus Bay core showed that it was detectable at around 105 copies per gram at 10 cmbsf and numbers were slightly increased at 40 cmbsf (Figure 2). The numbers then gradually decreased with sediment depth in an almost linear fashion and the phylotype was not detectable below 160 cmbsf, whereas copy numbers of ‘total’ Bacteria were still above 108 copies g−1 at this depth. The DEH-J10 phylotype should therefore be regarded as a relatively ‘shallow’ subsurface phylotype that may represent DEH inhabiting the shallow subsurface, but not the deep subsurface.

Quantification of ‘total’ bacterial 16S rRNA genes and genes amplified by specific primers designed for the 16S rRNA gene of the single cell DEH-J10 through depths of the Aarhus Bay sediment core. ‘Total’ Bacteria are represented by filled circles (●), DEH-J10 by open circles (○).
General description of the genomic data obtained from the single cell DEH-J10
A combination of 454-pyrosequence and Illumina reads were assembled into 1.44 Mbp distributed across 629 contigs (Table 1). This assembled data were separated into two data sets: (i) the first ‘primary’ data set included contigs that had at least one complete ORF called by the ORF prediction software; and (ii) a second ‘fragment’ data set that encompassed contigs for which no full ORFs were called by the ORF prediction software and was therefore examined separately by BLASTX. Only encoded proteins from the fragment data set that were predicted to perform functions fitting into the context of metabolic pathways identified from primary data set are discussed and specified in the text with respect to their origins.
Because DNA contamination from exogenous sources was a major concern, various procedures to assess the degree of genomic purity were performed. The 16S rRNA gene sequence obtained by PCR when screening MDA products with broad-range 16S rRNA gene targeting primers before genome sequencing was identical to the sequence identified in the genome assembly. Further, PCR using broad-range bacterial 16S rRNA gene primers and MDA-derived DNA as template, cloning and sequencing of the amplicons, revealed that all 83 clones with good quality sequence reads were almost identical to the 16S rRNA gene identified in the assembly, with few single base pair differences in some sequences likely due to PCR or sequencing errors. PCR using broad-range Eukarya-specific 18S rRNA or Archaea-specific 16S rRNA gene primers did not give amplification products. As an additional bioinformatic means to assess the genomic purity, BLASTP and BLASTN analyses were also used to examine all contigs from the primary assembly for evidence of genetic content related to known DEH or other Chloroflexi. This analysis showed that the vast majority of contigs (harbouring 89.75% of the primary data set) could be directly linked to genetic content related to known DEH or other Chloroflexi. Together, these analyses strongly indicate that the genetic material described in this study was derived from the genome of a single DEH cell.
The analysis of the numbers of conserved single copy and tRNA genes in comparison with known DEH suggested that the 1.44 Mbp assembly represented 50.65–60.86% of the whole DEH-J10 genome (Table 1). On the basis of this information, an estimated genome size of 2.36–2.84 Mbp was deduced. When comparing all encoded proteins from the primary data set with the NCBI non-redundant database by BLASTP, 19.1% of the proteins had best hits to proteins from cultivated DEH and 3.6% to other Chloroflexi (Supplementary Table 1). Many best BLASTP hits were to proteins derived from other anaerobic groups such as Deltaproteobacteria (6.5%), Firmicutes (4.2%), methanogenic Archaea (4.2%) and syntrophic bacteria (1.5%). BLASTP analyses against protein sequences from known DEH genomes using an e-value threshold of 10−10 revealed overall protein sequence identities of 44.1–45.7% for positive hits. The genomes of sequenced D. mccartyi strains contain two high-plasticity regions around the origin of replication that harbour the vast majority of putative terminal reductases required for organohalide respiration (Kube et al., 2005; McMurdie et al., 2009). BLAST comparisons of DEH-J10 proteins with several D. mccartyi genomes revealed that genes from DEH-J10 are highly underrepresented in these regions and hits were generally weaker than hits to other regions of the genomes (Supplementary Figure 1). Together, the data strongly suggest that although the DEH-J10 genome shares most similarity with genomes of previously sequenced DEH of the genera Dehalococcoides and Dehalogenimonas, it harbours a larger genome and appears considerably different in terms of overall gene content and arrangement.
Central carbon metabolism
Central metabolic pathways predicted from the genome annotations are depicted in Figure 3. Possible carbon assimilation paths include the uptake of organic compounds, carbon dioxide fixation via the reductive acetyl-CoA (Wood-Ljungdahl) pathway and carboxylation reactions. Three subunits of the carboxylating pyruvate:ferredoxin oxidoreductase were encoded and may provide a link between the reductive acetyl-CoA pathway and other anabolic pathways. In addition, a gene encoding a membrane subunit of a sodium-translocating oxaloacetate carboxylase was present, possibly involved in Na+-dependent pyruvate carboxylation to oxaloacetate. In addition, this enzyme could operate in the opposite direction as a bifunctional priopionyl-CoA/oxaloacetate transcarboxylase, which could transfer the carboxyl group from oxaloacetate to propionyl-CoA and thereby perform a necessary step of the methylmalonyl pathway (described below) (Kosaka et al., 2006).

Schematic depiction of the overall metabolic and phenotypic features of single cell DEH-J10, as predicted from single-cell genome sequencing and gene annotations. BCAA, branched chain amino acids; ETF, electron transfer protein complex; HDR, heterodisulfide reductase-like proteins; mvhD, methyl-violgen-reducing hydrogenase delta subunit; DMSO, dimethyl sulfoxide; DMS, dimethyl sulphide. X–unknown electron carrier.
The genome of DEH-J10 encoded several key gluconeogenesis functions, that is, phosphoenolpyruvate synthase, phosphoglucerate mutase, a ‘type V’ bifunctional fructose-1,6-bisphosphate aldolase/fructose-1,6-bisphosphatase enzyme, an additional ‘type II’ fructose-1,6-bisphosphatase and glucose-6-P isomerase (Supplementary Table 2). The bifunctional fructose-1,6-bisphosphate aldolase/fructose-1,6-bisphosphatase is typical of strict anaerobes and may confer unidirectionality to gluconeogenesis (Say and Fuchs, 2010). Its presence indicates that DEH-J10 is not able to catalyse glycolysis and therefore is not able to grow on sugars, similarly as described for cultivated DEH. Genes encoding enzymes of the tricarboxylic acid cycle were detected and are likely used for anabolic purposes, for example, for amino-acids biosynthesis.
Enzymes required for cobalamin salvage were encoded (cobS, cobT, cobU and cobC) and may enable the organism to remodel cobinamids to a functional cobalamin (Yi et al., 2012). Functional cobalamins would therefore be available to act as cofactors for methyltransferases required for the reductive acetyl-CoA pathway, as well as methylmalonyl-CoA mutases and reductive dehalogenases, all of which are discussed below.
Acetyl-CoA synthetases
Several genes encoding enzymes with highest sequence similarities to ADP-forming acetyl-CoA synthetases and succinyl-CoA synthetases were identified (Supplementary Table 2). Most of the top BLASTP hits for these predicted proteins were to proteins from the archaeal genera Pyrococcus and Thermococcus, which are known to catalyse the one-step formation of acetate from acetyl-CoA with the concomitant phosphorylation of ADP to ATP (Bräsen et al., 2008). The predicted beta-subunit of at least one of the putative acetyl-CoA synthetases contained a conserved histidine residue typical of well characterised acetyl-CoA synthetases that specifically form acetate and differentiate them from other structurally related succinyl-CoA synthetases (Bräsen et al., 2008). DEH-J10 may therefore gain ATP by substrate-level phosphorylation during the conversion of acetyl-CoA to acetate (McInerney et al., 2007; Bräsen et al., 2008).
Reductive acetyl-CoA (Wood-Ljungdahl) pathway
The DEH-J10 bacterium harboured almost all genes required for the reductive acetyl-CoA pathway (Wood-Ljungdahl pathway), which is present only in strictly anaerobic prokaryotes (Figure 3 and Supplementary Table 2). This is in contrast to D. mccartyi strains, which lack genes encoding methylene-tetrahydrofolate reductase and the beta-subunit of the carbon monoxide dehydrogenase/acetyl-CoA decarbonylase-synthase complex (CODH/ACDS) (Seshadri et al., 2005), but is similar to D. lykanthroporepellens strain BL-DC-9 which also contains these genes. The only gene missing in DEH-J10 is the gene for 10-formyl tetrahydrofolate synthase. This gene is present in the genomes of all known DEH, suggesting that it was missed owing to the incomplete genome recovery. The reductive acetyl-CoA pathway may enable the bacterium to assimilate CO2 and other C1-compounds (Berg, 2011; Fuchs, 2011). Because this pathway runs close to thermodynamic equilibrium, it can also operate in the opposite direction for the complete oxidation of organics via acetyl CoA to CO2 (Berg, 2011; Fuchs, 2011). It has also been shown that the pathway can function in both directions within a single organism using the same enzymatic machinery, depending on the physiological conditions (Schauder et al., 1986; Hattori et al., 2005). Such a metabolic feature would enable DEH-J10 to switch metabolic strategy if environmental conditions necessitate.
Intriguingly, the genetic information for the carbonyl-branch of the reductive acetyl-CoA pathway appears to be of archaeal origin, which is in contrast to corresponding genes in known DEH genomes. Two separate gene clusters (referred to as ‘A’ and ‘B’) contained genes for two different enzyme complexes constituting the bifunctional CODH/ACDS complex. CODH/ACDS gene cluster A contained genes for all five subunits of the complex, whereas cluster B did not contain genes for gamma and delta subunits. The contig harbouring cluster B was, however, truncated in the vicinity of these genes and therefore genes for the gamma and delta subunits may be present in the missing genomic content. Both CODH/ACDS gene clusters contained genes encoding epsilon subunits that are characteristic of archaeal CODH/ACDS complexes (Lindahl and Chang, 2001), and phylogenetic analysis of the catalytic alpha-subunit protein sequences affiliated both with archaeal-derived proteins (Supplementary Figure 2). These facts suggest that both gene clusters may have been horizontally transferred from an archaeon, which has also been previously described for the subsurface bacterium Desulforudis audaxviator MP104C (Chivian et al., 2008). In addition, genes encoding subunits of a formylmethanofuran dehydrogenase (subunits B, D and G) were associated with CODH/ACDS gene cluster B. These are suggestive that an archaeal-like reductive acetyl-CoA pathway may operate, in which most of the typical methanogenic pathway could be used for conversions of acetyl-CoA to and from CO2 (Klenk et al., 1997; Anderson et al., 2011; Berg, 2011). No genes for a methyl-CoM reductase or other coenzymes and prosthetic groups required for CO2 reduction to methane by methanogens (Kaster et al., 2011a) were detected. The absence of genes for such features suggests that the reductive acetyl-CoA pathway might only be used for the fixation of CO2 or oxidation of acetyl-CoA.
Electron donating and processing reactions
Beta-oxidation of hydrocarbons
Numerous genes encoding enzymes of the beta-oxidation pathway are present in the genome of DEH-J10 (Figure 3 and Supplementary Table 2). Beta-oxidation pathways typically enable the oxidation of fatty acids and structurally related compounds such as alkanes or alkenes of varying chain lengths (after activation), aromatics (after dearomatising) or branched-chain amino acids. A variety of genes encoding putative enzymes with CoA-transferase activities were identified, indicating that various organic substrates could be activated for beta-oxidation (Supplementary Table 2). Most CoA-transferases were related to ‘family III’ type enzymes, which are typically highly substrate specific (Heider 2001). Genes encoding enzymes of the methylmalonyl-CoA pathway were detected and included at least eight copies of methylmalonyl-CoA mutases in the primary data set and a propionyl-CoA carboxylase in the fragment data set (Supplementary Table 2). The methylmalonyl-CoA pathway can be used for the oxidation of activated odd-chain fatty acids and propionyl-CoA. One gene cluster contained a gene encoding an alpha-methylacyl-CoA racemase, in association with various genes for typical beta-oxidation enzymes, as well as methylmalonyl-CoA mutase subunits. This particular enzyme may suggest that the organism could use modified fatty acids such as methyl-branched fatty acids (Sakai et al., 2004).
Genes predicted to encode both alpha and beta subunits of an electron transfer flavoprotein complex were present. These may serve as an electron acceptor for acyl-CoA dehydrogenases (Beckmann and Frerman, 1985; Husain and Steenkamp, 1985; Zhang et al., 2004), such as those present in the beta-oxidation pathways. The reducing equivalents could then be transferred to an electron carrier before being transferred to an electron transport chain and could therefore provide a means for linking the oxidation of organics by beta-oxidation to energy conserving mechanisms.
Many of the genes for beta-oxidation enzymes were located in the vicinity of gene clusters encoding ‘ABC’ or ‘branched-chain amino acid’ transporters. This suggests functional associations, that is, uptake of defined molecules by specific transporters, followed by the activation through ligation with CoA and subsequent beta-oxidation. Such genomic linkages have been previously observed, for example, in the short-chain fatty acid utilising bacterium Syntrophobacter acidotrophicus (McInerney et al., 2007). All together, the genetic information related to beta-oxidation constitute a notable portion of the genomic content that differentiates DEH-J10 from known DEH and may suggest that beta-oxidation pathways represent an important metabolic route to obtain carbon and reducing equivalents for DEH-J10.
Catabolism of aromatics
Genes predicted to encode subunits of a class I benzoyl-CoA reductase were identified (Supplementary Table 2). Benzoyl-CoA reductases are key enzymes in the central metabolism of aromatic compounds (Löffler et al., 2011). Two subunits (gamma and beta) were present on one contig, whereas genes for possible alpha and delta subunits were present on a separate contig. The alpha and delta subunits contain ATP-binding sites of the acetate kinase/sugar kinase/Hsp70 actin family domains and therefore an ATP-dependent reduction of an aromatic ring typical of facultative anaerobes could be hypothesised (Selesi et al., 2010). The only other gene predicted to encode an enzyme involved in the oxidation of aromatic compounds to acetyl-CoA was a gene annotated as a subunit of succinyl-CoA:benzylsuccinate CoA-transferase. The presence of such genes suggests that the DEH-J10 may also have the capacity to oxidise substituted aromatics.
Hydrogenases and associated proteins
Multiple genes and operons encoding hydrogenases and accessory proteins, for example, a hydrogenase assembly chaperon and a cofactor insertion complex, were identified (Supplementary Table 2). All these genes had high sequence identities to genes from known DEH strains. The hydrogenase encoding genes included genes for cytoplasmic HymABC subunits and so-called ‘periplasmic’ NiFe ‘hup’ hydrogenases found in known DEH. The hup hydrogenase has been previously discussed to be a good candidate for shuttling electrons into the electron transport chain in cultivated Dehalococcoides strains (Seshadri et al., 2005). However, despite having high overall amino acid similarity to hup hydrogenases from known DEH, the hup small subunit in DEH-J10 does not contain a twin-arginine translocation export signal peptide or a transmembrane helix, as it appears to be truncated at the N terminus in comparison with these subunits in known DEH. Further, a gene encoding a putatively membrane-bound iron-sulfur-cluster binding domain-containing protein, which is typically directly adjacent to genes for subunits of the hup hydrogenases in known DEH, is absent in DEH-J10. Together, this data suggest that this protein complex is not membrane associated and is therefore not a key respiratory enzyme complex for electron input. Alternatively, this hydrogenase may be involved in proton/hydrogen processing within the cytoplasm.
Heterodisulfide reductase and associated proteins
A cluster of genes encoding two heterodisulfide reductase-like ‘alpha’ subunits, four putative methyl viologen-reducing hydrogenase delta subunits and two formate dehydrogenase-like ‘beta’ subunits, was identified (Supplementary Figure 3 and Supplementary Table 2). This cluster was one of the longest and most obvious stretches of ORFs identified (encoding at least 20 ORFs) in our data set, whereby no homologues in known DEH could be identified by BLASTP analyses, yet was downstream of known DEH genes. We hypothesise that the heterodisulfide reductase-like enzymes have important roles in cytoplasmic electron transfer and energy conserving mechanisms, like in other anaerobes such as sulphate reducers, acetogens and methanogens (Stojanowic et al., 2003; Strittmatter et al., 2009; Kaster et al., 2011b; Callaghan et al., 2012). These complexes might be especially important for transferring reducing equivalents released during beta-oxidation and/or conversions of succinate to acetyl-CoA (via the methylmalonyl-CoA pathway), to and from ferredoxins or NADH, possibly by electron bifurcating/confurcating mechanisms that may be linked to other metabolic steps (Buckel and Thauer, 2012; Grein et al., 2012). The truncation of the contig containing these genes precluded linking the predicted proteins directly to other related mechanisms by genomic associations, and the exact mechanisms of such complexes are not understood in many other microorganisms. Nevertheless, its presence indicates the capacity for energy processing mechanisms unique to DEH-J10 in comparison with known DEH.
Electron accepting reactions
Potential terminal reductases
Genes predicted to encode terminal reductases included four genes encoding subunits of complex iron-sulfur molybdoenzyme family proteins (Supplementary Table 2). Phylogenetic analysis of the three different catalytic subunit A protein sequences placed them in a distinct branch containing dimethyl sulfoxide (DMSO) reductases, which also often have activity towards trimethylamine N-oxide (Supplementary Figure 4). In addition to the genes for subunit A proteins, a gene encoding one copy of a ‘four-cluster protein’ subunit (subunit B) was identified, whereas no genes were identified for putative homologues of complex iron-sulfur molybdoenzyme subunit C proteins, which typically act as membrane anchors for many multimeric complex iron-sulfur molybdoenzyme complexes (Rothery et al., 2008). Further, twin-arginine translocation translocation signal peptides were not identified for the predicted A or B subunits, and together, suggest that this complex may be cytoplasmic or interacting with other membrane-bound respiratory proteins by unknown mechanisms. It is important to note that some complex iron-sulfur molybdoenzyme terminal reductases are known to lack the membrane-bound C subunits while retaining activity (McEwan et al., 2002). DMSO is widely distributed in pelagic marine environments and may be deposited to sediments in association with sinking particulate matter (Hatton 2002) and can then be utilised as an electron acceptor in reduced marine sediments (Kiene and Capone, 1988; López and Duarte, 2004). It could therefore represent an effective electron acceptor for bacteria living in the shallow subsurface, as the redox potential of DMSO (+160 mV) (Wood, 1981) is between the redox potentials of other favourable anaerobic electron acceptors typically used in the shallow subsurface, such as Mn(IV) and Fe(III). Compounds such as DMSO and trimethylamine N-oxide may be especially useful to test as a terminal electron acceptor for further enrichment attempts.
No genes encoding homologues of reductive dehalogenase enzymes, associated membrane-bound anchor proteins or transcriptional regulators, which are required for respiration with organohalide compounds, were detected in the genomic data. Further, genes for reductive dehalogenases were not detected with PCR using primers targeting these genes using MDA-derived DNA as template. Considering there is speculation that some marine subsurface DEH-affiliated bacteria could perform reductive dehalogenation (Adrian, 2009; Futagami et al., 2009; Valentine, 2010; Durbin and Teske, 2011; Wagner et al., 2012), the apparent absence of genes encoding reductive dehalogenases is worthy to note because this is the first genomic data from relatives of known organohalide-respiring DEH. Even if genes for reductive dehalogenases were in the missing genomic content, the DEH-J10 bacterium is considerably different to cultivated DEH because it does not appear to harbour a high proportion of genetic material dedicated to organohalide respiration. This can be assumed because if DEH-J10 harboured high copy numbers of genes for reductive dehalogenase homologues like in analogy to cultivated DEH (for example, up to 36 copies in D. mccartyi strains) (Kube et al., 2005; Seshadri et al., 2005; McMurdie et al., 2009; Siddaramappa et al., 2012), the chances of detecting these genes would be high even if a partial genome was recovered. Together with the indications for other energy conserving mechanisms described above, this strongly suggests that the DEH-J10 bacterium does not depend on organohalide respiration as a means of energy conservation like cultivated DEH. It also provides a first indication that it is not a conserved trait within the class DEH to harbour high proportions of genomic content dedicated to organohalide respiration.
Environmental adaptations
Osmoprotection
A gene cluster was identified that encodes enzymes possibly involved in the synthesis of osmoprotectants such as trehalose and alpha-mannosylglycerate (Styrvold and Strom, 1991; Empadinhas et al., 2004), and in the regulation of cellular osmolarity (Supplementary Table 2). The genetic potential for trehalose synthesising enzymes appears unique to DEH-J10 in comparison with known DEH, whereas genes for alpha-mannosylglycerate synthesising enzymes are present in terrestrial DEH (Styrvold and Strom, 1991; Empadinhas et al., 2004) and may possibly represent an evolutionary remnant of a marine DEH strain, or even an adaptation to osmotic fluctuations in terrestrial environments. Downstream were genes encoding a potassium uptake transporter that gave best BLASTP hits to proteins from marine methanogens and halotolerant microorganisms. This transporter might also be involved in the regulation of cytoplasmic osmotic strength by regulation of potassium ion concentrations (Roberts, 2004).
Oxygen protection
The presence of genes for enzymes related to oxygen and/or reactive oxygen species protection such as superoxide reductase/desulfoferrodoxin, superoxide dismutase and catalase (Supplementary Table 2), which are all absent in cultivated DEH, might represent adaptations to growth in shallow marine sediments, where organisms in sediments subject to bioturbation may be periodically exposed to oxygen.
Sulfatases (sulfohydrolases)
Several genes predicted to encode enzymes with sulfatase activity were detected on two separate contigs (Supplementary Table 2). In addition, a gene encoding a sulfatase-maturating enzyme was identified, which is critical for post-translational modification and functionality of sulfatases (Benjdia et al., 2011). Sulfatases catalyse the removal of sulphate groups from organic molecules and thereby enable further catabolism of the carbon backbones of various organic compounds (Kertesz, 2000; Glöckner et al., 2003; Woebken et al., 2007). Organosulphur compounds can be particularly abundant in the pelagic marine environment (Glöckner et al., 2003) and may further arise from sulphurisation of organic compounds through diagenetic reactions during burial in marine sediments (Schmidt et al., 2009). Genes encoding sulfatases are well represented in marine sediment metagenomes (Quaiser et al., 2011) and are highly represented in the genomes of marine versus freshwater Planctomycetes (Woebken et al., 2007). Sulfatases may therefore be a particular adaptation of DEH-J10 to organosulphur compounds found in marine sediment environments. Interestingly, most genes encoding sulfatases in DEH-J10 were most related to genes derived from pelagic bacteria, suggesting a degree of genetic continuity exists between pelagic and subsurface microorganisms.
Cell wall formation
No indications for peptidoglycan formation were found in the genomic data, suggesting that the analysed cell did not contain a rigid cell wall. This is in line with known DEH that also do not encode the enzymatic machinery for peptidoglycan cell wall biosynthesis, yet are known to contain proteinaceous surface layers (S-layers) (Maymó-Gatell et al., 1997; Adrian et al., 2000). It has also been suggested that the monoderm nature of the Chloroflexi is evolutionary conserved throughout the whole phylum (Sutcliffe, 2011). In contrast to known DEH, however, the capacity to glycosylate S-layer proteins was suggested by a gene cluster encoding various enzymes putatively involved in the synthesis of glycan chains (Supplementary Table 2). These genes mostly had high similarity to genes from other organisms with S-layers. Glycosylated S-layers could have ecological implications such as providing protection against proteolytic enzymes, improvement of cell wall integrity or alter surface charges and thereby influence interactions with other microorganisms or sediment particles.
Concluding remarks
This study provides the first insights into the genome of a bacterium belonging to the marine DEH-affiliated Chloroflexi, as revealed by partial sequencing of a single-cell genome. Although to date such single-cell genome approaches are limited in that complete genomes are rarely retrieved, the considerable portion of the genome obtained in this study provides invaluable information about the metabolic potential of an organism for which nothing was previously known. The data indicate that the DEH-J10 genome likely confers metabolic versatility to the organism, much more than previously found for organohalide-respiring DEH. It appears that DEH-J10 could employ the beta-oxidation pathway to use various organics as a source for carbon and reducing equivalents. The organism could use the reductive acetyl-CoA pathway to completely oxidise the organics processed via beta-oxidation pathways, or it could use this same pathway to obtain carbon by autotrophy. In contrast to known DEH, the DEH-J10 bacterium likely does not rely on organohalide respiration for energy conservation and might instead use DMSO as an electron acceptor. The organism may also generate ATP in a non-respiratory manner via conversions of acetyl-CoA to acetate. The observation that populations of the DEH-J10 phylotype are restricted to relatively shallow subsurface sediments together with the genomic data suggests that the bacterium is linked to the degradation of organic matter in the upper sediments of the Aarhus Bay site. Because of the pronounced diversity within the class DEH, further studies will be required to unravel the properties of other DEH genotypes from the many other divergent phylogenetic clusters of the DEH.
Accession codes
References
Adrian L, Szewzyk U, Wecke J, Görisch H . (2000). Bacterial dehalorespiration with chlorinated benzenes. Nature 408: 580–583.
Adrian L . (2009). ERC-group microflex: microbiology of Dehalococcoides-like Chloroflexi. Rev Environ Sci Biotechnol 8: 225–229.
Anderson I, Risso C, Holmes D, Lucas S, Copeland A, Lapidus A et al (2011). Complete genome sequence of Ferroglobus placidus AEDII12DO. Stand Genomic Sci 5: 50–60.
Aziz RK, Bartels D, Best AA, DeJongh M, Disz T, Edwards RA et al (2008). The RAST server: rapid annotations using subsystems technology. BMC Genomics 9: 75.
Bankevich A, Nurk S, Antipov D, Gurevich AA, Dvorkin M, Kulikov AS et al (2012). SPAdes: a new genome assembly algorithm and its applications to single-cell sequencing. J Comput Biol 19: 455–477.
Batzke A, Engelen B, Sass H, Cypionka H . (2007). Phylogenetic and physiological diversity of cultured deep-biosphere bacteria from Equatorial Pacific Ocean and Peru Margin sediments. Geomicrobiol J 24: 261–273.
Beckmann JD, Frerman FE . (1985). Reaction of electron-transfer flavoprotein with electron-transfer flavoprotein-ubiquinone oxidoreductase. Biochemistry 24: 3922–3925.
Bedard DL, Ritalahti KM, Löffler FE . (2007). The Dehalococcoides population in sediment-free mixed cultures metabolically dechlorinates the commercial polychlorinated biphenyl mixture aroclor 1260. Appl Environ Microbiol 73: 2513–2521.
Benjdia A, Martens EC, Gordon JI, Berteau O . (2011). Sulfatases and a radical S-adenosyl-L-methionine (AdoMet) enzyme are key for mucosal foraging and fitness of the prominent human gut symbiont, Bacteroides thetaiotaomicron. J Biol Chem 286: 25973–25982.
Berg IA . (2011). Ecological aspects of the distribution of different autotrophic CO2 fixation pathways. Appl Environ Microbiol 77: 1925–1936.
Biddle JF, Fitz-Gibbon S, Schuster SC, Brenchley JE, House CH . (2008). Metagenomic signatures of the Peru Margin subseafloor biosphere show a genetically distinct environment. Proc Natl Acad Sci USA 105: 10583–10588.
Biddle JF, White JR, Teske AP, House CH . (2011). Metagenomics of the subsurface Brazos-Trinity Basin (IODP site 1320): comparison with other sediment and pyrosequenced metagenomes. ISME J 5: 1038–1047.
Blazejak A, Schippers A . (2010). High abundance of JS-1- and Chloroflexi-related bacteria in deeply buried marine sediments revealed by quantitative, real-time PCR. FEMS Microbiol Ecol 72: 198–207.
Bowman KS, Nobre MF, da Costa MS, Rainey FA, Moe WM . (2012). Dehalogenimonas alkenigignens sp. nov., a chlorinated alkane dehalogenating bacterium isolated from groundwater. Int J Syst Evol Microbiol 63: 1492–1498.
Bräsen C, Schmidt M, Grötzinger J, Schönheit P . (2008). Reaction mechanism and structural model of ADP-forming Acetyl-CoA synthetase from the hyperthermophilic archaeon Pyrococcus furiosus: evidence for a second active site histidine residue. J Biol Chem 283: 15409–15418.
Buckel W, Thauer RK . (2012). Energy conservation via electron bifurcating ferredoxin reduction and proton/Na(+) translocating ferredoxin oxidation. Biochim Biophys Acta 1827: 94–113.
Callaghan AV, Morris BE, Pereira IA, McInerney MJ, Austin RN, Groves JT et al (2012). The genome sequence of Desulfatibacillum alkenivorans AK-01: a blueprint for anaerobic alkane oxidation. Environ Microbiol 14: 101–113.
Chivian D, Brodie EL, Alm EJ, Culley DE, Dehal PS, DeSantis TZ et al (2008). Environmental genomics reveals a single-species ecosystem deep within Earth. Science 322: 275–278.
Chow WL, Cheng D, Wang S, He J . (2010). Identification and transcriptional analysis of trans-DCE-producing reductive dehalogenases in Dehalococcoides species. ISME J 4: 1020–1030.
D'Hondt S, Rutherford S, Spivack AJ . (2002). Metabolic activity of subsurface life in deep-sea sediments. Science 295: 2067–2070.
D'Hondt S, Jørgensen BB, Miller DJ, Batzke A, Blake R, Cragg BA et al (2004). Distributions of microbial activities in deep subseafloor sediments. Science 306: 2216–2221.
Durbin AM, Teske A . (2011). Microbial diversity and stratification of South Pacific abyssal marine sediments. Environ Microbiol 13: 3219–3234.
Empadinhas N, Albuquerque L, Costa J, Zinder SH, Santos MA, Santos H et al (2004). A gene from the mesophilic bacterium Dehalococcoides ethenogenes encodes a novel mannosylglycerate synthase. J Bacteriol 186: 4075–4084.
Fagervold SK, Watts JE, May HD, Sowers KR . (2005). Sequential reductive dechlorination of meta-chlorinated polychlorinated biphenyl congeners in sediment microcosms by two different Chloroflexi phylotypes. Appl Environ Microbiol 71: 8085–8090.
Fagervold SK, May HD, Sowers KR . (2007). Microbial reductive dechlorination of aroclor 1260 in Baltimore harbor sediment microcosms is catalyzed by three phylotypes within the phylum Chloroflexi. Appl Environ Microbiol 73: 3009–3018.
Fry JC, Parkes RJ, Cragg BA, Weightman AJ, Webster G . (2008). Prokaryotic biodiversity and activity in the deep subseafloor biosphere. FEMS Microbiol Ecol 66: 181–196.
Fuchs G . (2011). Alternative pathways of carbon dioxide fixation: insights into the early evolution of life? Annu Rev Microbiol 65: 631–658.
Futagami T, Morono Y, Terada T, Kaksonen AH, Inagaki F . (2009). Dehalogenation activities and distribution of reductive dehalogenase homologous genes in marine subsurface sediments. Appl Environ Microbiol 75: 6905–6909.
Glöckner FO, Kube M, Bauer M, Teeling H, Lombardot T, Ludwig W et al (2003). Complete genome sequence of the marine planctomycete Pirellula sp. strain 1. Proc Natl Acad Sci USA 100: 8298–8303.
Grein F, Ramos AR, Venceslau SS, Pereira IA . (2012). Unifying concepts in anaerobic respiration: Insights from dissimilatory sulfur metabolism. Biochim Biophys Acta 1827: 145–160.
Hatton AD . (2002). DMSP removal and DMSO production in sedimenting particulate matter in the northern North Sea. Deep-Sea Res II 49: 3053–3065.
Hattori S, Galushko AS, Kamagata Y, Schink B . (2005). Operation of the CO dehydrogenase/acetyl coenzyme A pathway in both acetate oxidation and acetate formation by the syntrophically acetate-oxidizing bacterium Thermacetogenium phaeum. J Bacteriol 187: 3471–3476.
Heider J . (2001). A new family of CoA-transferases. FEBS Lett 509: 345–349.
Hölscher T, Krajmalnik-Brown R, Ritalahti KM, Von Wintzingerode F, Görisch H, Löffler FE et al (2004). Multiple nonidentical reductive-dehalogenase-homologous genes are common in Dehalococcoides. Appl Environ Microbiol 70: 5290–5297.
Husain M, Steenkamp DJ . (1985). Partial purification and characterization of glutaryl-coenzyme A dehydrogenase, electron transfer flavoprotein, and electron transfer flavoprotein-Q oxidoreductase from Paracoccus denitrificans. J Bacteriol 163: 709–715.
Inagaki F, Suzuki M, Takai K, Oida H, Sakamoto T, Aoki K et al (2003). Microbial communities associated with geological horizons in coastal subseafloor sediments from the sea of Ohkotsk. Appl Environ Microbiol 69: 7224–7235.
Inagaki F, Nunoura T, Nakagawa S, Teske A, Lever M, Lauer A et al (2006). Biogeographical distribution and diversity of microbes in methane hydrate-bearing deep marine sediments on the Pacific Ocean Margin. Proc Natl Acad Sci USA 103: 2815–2820.
Jensen JB, Bennike O . (2009). Geological setting as background for methane distribution in Holocene mud deposits, Aarhus Bay, Denmark. Continental Shelf Research 29: 775–784.
Kallmeyer J, Pockalny R, Adhikaria AA, Smith DC, D’Hondt S . (2012). Global distribution of microbial abundance and biomass in subseafloor sediment. Proc Natl Acad Sci USA 109: 16213–16216.
Kaster AK, Goenrich M, Seedorf H, Liesegang H, Wollherr A, Gottschalk G et al (2011a). More than 200 genes required for methane formation from H2 and CO2 and energy conservation are present in Methanothermobacter marburgensis and Methanothermobacter thermautotrophicus. Archaea 2011: 973848.
Kaster AK, Moll J, Parey K, Thauer RK . (2011b). Coupling of ferredoxin and heterodisulfide reduction via electron bifurcation in hydrogenotrophic methanogenic archaea. Proc Natl Acad Sci USA 108: 2981–2986.
Kertesz MA . (2000). Riding the sulfur cycle-metabolism of sulfonates and sulfate esters in gram-negative bacteria. FEMS Microbiol Rev 24: 135–175.
Kiene RP, Capone DG . (1988). Microbial transformations of methylated sulfur compounds in anoxic salt marsh sediments. Microb Ecol 15: 275–291.
Kittelmann S, Friedrich MW . (2008a). Identification of novel perchloroethene-respiring microorganisms in anoxic river sediment by RNA-based stable isotope probing. Environ Microbiol 10: 31–46.
Kittelmann S, Friedrich MW . (2008b). Novel uncultured Chloroflexi dechlorinate perchloroethene to trans-dichloroethene in tidal flat sediments. Environ Microbiol 10: 1557–1570.
Klenk HP, Clayton RA, Tomb JF, White O, Nelson KE, Ketchum KA et al (1997). The complete genome sequence of the hyperthermophilic, sulphate-reducing archaeon Archaeoglobus fulgidus. Nature 390: 364–370.
Kosaka T, Uchiyama T, Ishii S, Enoki M, Imachi H, Kamagata Y et al (2006). Reconstruction and regulation of the central catabolic pathway in the thermophilic propionate-oxidizing syntroph Pelotomaculum thermopropionicum. J Bacteriol 188: 202–210.
Kube M, Beck A, Zinder SH, Kuhl H, Reinhardt R, Adrian L . (2005). Genome sequence of the chlorinated compound-respiring bacterium Dehalococcoides species strain CBDB1. Nat Biotechnol 23: 1269–1273.
Lane DJ . (1991). 16S/23S rRNA sequencing. In: Stackebrandt E, Goodfellow M (eds) Nucleic Acid Techniques in Bacterial Systematics. John Wiley and Sons: Chichester, UK, pp 115–175.
Langmead B, Salzberg SL . (2012). Fast gapped-read alignment with Bowtie 2. Nat Methods 9: 357–359.
Lindahl PA, Chang B . (2001). The evolution of acetyl-CoA synthase. Orig Life Evol Biosph 31: 403–434.
Lloyd KG, Schreiber L, Petersen DG, Kjeldsen KU, Lever MA, Stepanauskas R et al (2013). Predominant archaea in marine sediments degrade detrital proteins. Nature 496: 215–218.
Löffler C, Kuntze K, Vazquez JR, Rugor A, Kung JW, Böttcher A et al (2011). Occurrence, genes and expression of the W/Se-containing class II benzoyl-coenzyme A reductases in anaerobic bacteria. Environ Microbiol 13: 696–709.
Löffler FE, Yan J, Ritalahti KM, Adrian L, Edwards EA, Konstantinidis KT et al (2012). Dehalococcoides mccartyi gen. nov., sp. nov., obligately organohalide-respiring anaerobic bacteria relevant to halogen cycling and bioremediation, belong to a novel bacterial class, Dehalococcoidia classis nov., order Dehalococcoidales ord. nov. and family Dehalococcoidaceae fam. nov., within the phylum Chloroflexi. Int J Syst Evol Microbiol 63: 625–635.
López NI, Duarte CM . (2004). Dimethyl sulfoxide (DMSO) reduction potential in Mediterranean seagrass (Posidonia oceanica) sediments. J Sea Res 51: 11–20.
Marcy Y, Ishoey T, Lasken RS, Stockwell TB, Walenz BP, Halpern AL et al (2007). Nanoliter reactors improve multiple displacement amplification of genomes from single cells. PLoS Genet 3: 1702–1708.
Markowitz VM, Mavromatis K, Ivanova NN, Chen IM, Chu K, Kyrpides NC . (2009). IMG ER: a system for microbial genome annotation expert review and curation. Bioinformatics 25: 2271–2278.
Martinez-Garcia M, Swan BK, Poulton NJ, Gomez ML, Masland D, Sieracki ME et al (2012). High-throughput single-cell sequencing identifies photoheterotrophs and chemoautotrophs in freshwater bacterioplankton. ISME J 6: 113–123.
May HD, Miller GS, Kjellerup BV, Sowers KR . (2008). Dehalorespiration with polychlorinated biphenyls by an anaerobic ultramicrobacterium. Appl Environ Microbiol 74: 2089–2094.
Maymó-Gatell X, Chien Y, Gossett JM, Zinder SH . (1997). Isolation of a bacterium that reductively dechlorinates tetrachloroethene to ethene. Science 276: 1568–1571.
McEwan AG, Ridge JP, McDevitt CA, Hugenholtz P . (2002). The DMSO Reductase family of microbial molybdenum enzymes; molecular properties and role in the dissimilatory reduction of toxic elements. Geomicrobiol J 19: 3–21.
McInerney MJ, Rohlin L, Mouttaki H, Kim U, Krupp RS, Rios-Hernandez L et al (2007). The genome of Syntrophus aciditrophicus: life at the thermodynamic limit of microbial growth. Proc Natl Acad Sci USA 104: 7600–7605.
McMurdie PJ, Behrens SF, Muller JA, Goke J, Ritalahti KM, Wagner R et al (2009). Localized plasticity in the streamlined genomes of vinyl chloride respiring Dehalococcoides. PLoS Genet 5: e1000714.
Medlin L, Elwood HJ, Stickel S, Sogin ML . (1988). The characterization of enzymatically amplified eukaryotic 16S-like rRNA-coding regions. Gene 71: 491–499.
Moe WM, Yan J, Nobre MF, da Costa MS, Rainey FA . (2009). Dehalogenimonas lykanthroporepellens gen. nov., sp. nov., a reductively dehalogenating bacterium isolated from chlorinated solvent-contaminated groundwater. Int J Syst Evol Microbiol 59: 2692–2697.
Niu B, Fu L, Sun S, Li W . (2010). Artificial and natural duplicates in pyrosequencing reads of metagenomic data. BMC Bioinformatics 11: 187.
Nunoura T, Soffientino B, Blazejak A, Kakuta J, Oida H, Schippers A et al (2009). Subseafloor microbial communities associated with rapid turbidite deposition in the Gulf of Mexico continental slope (IODP Expedition 308). FEMS Microbiol Ecol 69: 410–424.
Parkes RJ, Webster G, Cragg BA, Weightman AJ, Newberry CJ, Ferdelman TG et al (2005). Deep sub-seafloor prokaryotes stimulated at interfaces over geological time. Nature 436: 390–394.
Quaiser A, Zivanovic Y, Moreira D, Lopez-Garcia P . (2011). Comparative metagenomics of bathypelagic plankton and bottom sediment from the Sea of Marmara. ISME J 5: 285–304.
Raghunathan A, Ferguson HR, Bornarth CJ, Song W, Driscoll M, Lasken RS . (2005). Genomic DNA amplification from a single bacterium. Appl Environ Microbiol 71: 3342–3347.
Roberts MF . (2004). Osmoadaptation and osmoregulation in archaea: update 2004. Front Biosci 9: 1999–2019.
Rothery RA, Workun GJ, Weiner JH . (2008). The prokaryotic complex iron-sulfur molybdoenzyme family. Biochim Biophys Acta 1778: 1897–1929.
Sakai Y, Takahashi H, Wakasa Y, Kotani T, Yurimoto H, Miyachi N et al (2004). Role of alpha-methylacyl coenzyme A racemase in the degradation of methyl-branched alkanes by Mycobacterium sp. strain P101. J Bacteriol 186: 7214–7220.
Say RF, Fuchs G . (2010). Fructose 1,6-bisphosphate aldolase/phosphatase may be an ancestral gluconeogenic enzyme. Nature 464: 1077–1081.
Schauder R, Eikmanns B, Thauer RK, Widdel F, Fuchs G . (1986). Acetate oxidation to CO2 in anaerobic bacteria via a novel pathway not involving reactions of the citric acid cycle. Arch Microbiol 145: 162–172.
Schmidt F, Elvert M, Koch BP, Witt M, Hinrichs K-U . (2009). Molecular characterization of dissolved organic matter in pore water of continental shelf sediments. Geochim Cosmochim Acta 73: 3337–3358.
Selesi D, Jehmlich N, von Bergen M, Schmidt F, Rattei T, Tischler P et al (2010). Combined genomic and proteomic approaches identify gene clusters involved in anaerobic 2-methylnaphthalene degradation in the sulfate-reducing enrichment culture N47. J Bacteriol 192: 295–306.
Seshadri R, Adrian L, Fouts DE, Eisen JA, Phillippy AM, Methe BA et al (2005). Genome sequence of the PCE-dechlorinating bacterium Dehalococcoides ethenogenes. Science 307: 105–108.
Siddaramappa S, Challacombe JF, Delano SF, Green LD, Daligault H, Bruce D et al (2012). Complete genome sequence of Dehalogenimonas lykanthroporepellens type strain (BL-DC-9T) and comparison to "Dehalococcoides" strains. Stand Genomic Sci 6: 251–264.
Stepanauskas R, Sieracki ME . (2007). Matching phylogeny and metabolism in the uncultured marine bacteria, one cell at a time. Proc Natl Acad Sci USA 104: 9052–9057.
Stojanowic A, Mander GJ, Duin EC, Hedderich R . (2003). Physiological role of the F420-non-reducing hydrogenase (Mvh) from Methanothermobacter marburgensis. Arch Microbiol 180: 194–203.
Strittmatter AW, Liesegang H, Rabus R, Decker I, Amann J, Andres S et al (2009). Genome sequence of Desulfobacterium autotrophicum HRM2, a marine sulfate reducer oxidizing organic carbon completely to carbon dioxide. Environ Microbiol 11: 1038–1055.
Styrvold OB, Strom AR . (1991). Synthesis, accumulation, and excretion of trehalose in osmotically stressed Escherichia coli K-12 strains: influence of amber suppressors and function of the periplasmic trehalase. J Bacteriol 173: 1187–1192.
Sutcliffe IC . (2011). Cell envelope architecture in the Chloroflexi: a shifting frontline in a phylogenetic turf war. Environ Microbiol 13: 279–282.
Swan BK, Martinez-Garcia M, Preston CM, Sczyrba A, Woyke T, Lamy D et al (2011). Potential for chemolithoautotrophy among ubiquitous bacteria lineages in the dark ocean. Science 333: 1296–1300.
Tamura K, Peterson D, Peterson N, Stecher G, Nei M, Kumar S . (2011). MEGA5: molecular evolutionary genetics analysis using maximum likelihood, evolutionary distance, and maximum parsimony methods. Mol Biol Evol 28: 2731–2739.
Tas N, van Eekert MH, de Vos WM, Smidt H . (2010). The little bacteria that can—diversity, genomics and ecophysiology of 'Dehalococcoides' spp. in contaminated environments. Microb Biotechnol 3: 389–402.
Teske A, Hinrichs KU, Edgcomb V, de Vera Gomez A, Kysela D, Sylva SP et al (2002). Microbial diversity of hydrothermal sediments in the Guaymas basin: evidence for anaerobic methanotrophic communities. Appl Environ Microbiol 68: 1994–2007.
Toffin L, Webster G, Weightman AJ, Fry JC, Prieur D . (2004). Molecular monitoring of culturable bacteria from deep-sea sediment of the Nankai Trough, Leg 190 Ocean Drilling Program. FEMS Microbiol Ecol 48: 357–367.
Valentine DL . (2010). Emerging topics in marine methane biogeochemistry. Annu Rev Mar Sci 3: 147–171.
Vallenet D, Belda E, Calteau A, Cruveiller S, Engelen S, Lajus A et al (2013). MicroScope—an integrated microbial resource for the curation and comparative analysis of genomic and metabolic data. Nucleic Acids Res 41: D636–D647.
Wagner A, Cooper M, Ferdi S, Seifert J, Adrian L . (2012). Growth of Dehalococcoides mccartyi strain CBDB1 by reductive dehalogenation of brominated benzenes to benzene. Environ Sci Technol 46: 8960–8968.
Wang Y, Qian PY . (2009). Conservative fragments in bacterial 16S rRNA genes and primer design for 16S ribosomal DNA amplicons in metagenomic studies. PLoS One 4: e7401.
Watts JE, Fagervold SK, May HD, Sowers KR . (2005). A PCR-based specific assay reveals a population of bacteria within the Chloroflexi associated with the reductive dehalogenation of polychlorinated biphenyls. Microbiol 151: 2039–2046.
Webster G, Parkes RJ, Cragg BA, Newberry CJ, Weightman AJ, Fry JC . (2006). Prokaryotic community composition and biogeochemical processes in deep subseafloor sediments from the Peru Margin. FEMS Microbiol Ecol 58: 65–85.
Webster G, Sass H, Cragg BA, Gorra R, Knab NJ, Green CJ et al (2011). Enrichment and cultivation of prokaryotes associated with the sulphate-methane transition zone of diffusion-controlled sediments of Aarhus Bay, Denmark, under heterotrophic conditions. FEMS Microbiol Ecol 77: 248–263.
Wellsbury P, Mather I, Parkes RJ . (2002). Geomicrobiology of deep, low organic carbon sediments in the Woodlark Basin, Pacific Ocean. FEMS Microbiol Ecol 42: 59–70.
Woebken D, Teeling H, Wecker P, Dumitriu A, Kostadinov I, Delong EF et al (2007). Fosmids of novel marine Planctomycetes from the Namibian and Oregon coast upwelling systems and their cross-comparison with planctomycete genomes. ISME J 1: 419–435.
Wood PM . (1981). The redox potential for dimethyl sulphoxide reduction to dimethyl sulphide: evaluation and biochemical implications. FEBS Lett 124: 11–14.
Woyke T, Xie G, Copeland A, Gonzalez JM, Han C, Kiss H et al (2009). Assembling the marine metagenome, one cell at a time. PLoS One 4: e5299.
Woyke T, Sczyrba A, Lee J, Rinke C, Tighe D, Clingenpeel S et al (2011). Decontamination of MDA reagents for single cell whole genome amplification. PLoS One 6: e26161.
Yi S, Seth EC, Men YJ, Stabler SP, Allen RH, Alvarez-Cohen L et al (2012). Versatility in corrinoid salvaging and remodeling pathways supports corrinoid-dependent metabolism in Dehalococcoides mccartyi. Appl Environ Microbiol 78: 7745–7752.
Zhang C, Liu X, Dong X . (2004). Syntrophomonas curvata sp. nov., an anaerobe that degrades fatty acids in co-culture with methanogens. Int J Syst Evol Microbiol 54: 969–973.
Acknowledgements
We thank the captain and crew of the R/V Tyra for assisting with sampling and the Laboratory of Bioinformatics Analyses for Genomics and Metabolism (LABGeM) of France Genomique for hosting the MaGe genome annotation platform. The project was funded by the European Research Council (ERC), Project Microflex (to LA), the Danish National Research Foundation, the German Max Planck Society, The Danish Council for Independent Research – Natural Sciences (DGP), the Villum Kann Rasmussen Foundation, and the US National Science Foundation (RS).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The authors declare no conflict of interest.
Additional information
Supplementary Information accompanies this paper on The ISME Journal website
Rights and permissions
About this article
Cite this article
Wasmund, K., Schreiber, L., Lloyd, K. et al. Genome sequencing of a single cell of the widely distributed marine subsurface Dehalococcoidia, phylum Chloroflexi. ISME J 8, 383–397 (2014). https://doi.org/10.1038/ismej.2013.143
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/ismej.2013.143
Keywords
This article is cited by
-
Long-read assembled metagenomic approaches improve our understanding on metabolic potentials of microbial community in mangrove sediments
Microbiome (2023)
-
Anaerobic degradation of organic carbon supports uncultured microbial populations in estuarine sediments
Microbiome (2023)
-
Genome-centric metagenomic insights into the role of Chloroflexi in anammox, activated sludge and methanogenic reactors
BMC Microbiology (2023)
-
Cultivation of marine bacteria of the SAR202 clade
Nature Communications (2023)
-
Assessment of prokaryotic communities in Southwestern Atlantic deep-sea sediments reveals prevalent methanol-oxidising Methylomirabilales
Scientific Reports (2023)
