Illustration by The Project Twins
Access options
Access Nature and 54 other Nature Portfolio journals
Get Nature+, our best-value online-access subscription
$29.99 / 30 days
cancel any time
Subscribe to this journal
Receive 51 print issues and online access
$199.00 per year
only $3.90 per issue
Rent or buy this article
Prices vary by article type
from$1.95
to$39.95
Prices may be subject to local taxes which are calculated during checkout
Nature 610, 220-221 (2022)
doi: https://doi.org/10.1038/d41586-022-03133-5
Updates & Corrections
-
Correction 04 October 2022: An earlier version of this feature incorrectly stated that Figshare is owned by Springer Nature.
References
Gabelica, M., Bojčić, R. & Puljak, L. J. Clin. Epidemiol. 150, 33–41 (2022).
Danchev, V., Min, Y., Borghi, J., Baiocchi, M. & Ioannidis, J. P. A. JAMA Netw. Open 4, e2033972 (2021).
Miyakawa, T. Mol. Brain 13, 24 (2020).
Federer, L. M. PLoS ONE 17, e0272845 (2022).
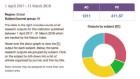
 Many researchers say they’ll share data — but don’t
Many researchers say they’ll share data — but don’t
 Why digital badges don’t work
Why digital badges don’t work
 Data sharing and how it can benefit your scientific career
Data sharing and how it can benefit your scientific career
 Data sharing: An open mind on open data
Data sharing: An open mind on open data
 NatureTech hub
NatureTech hub