- TECHNOLOGY FEATURE
Exposed: cells’ sugary secrets
Access options
Access Nature and 54 other Nature Portfolio journals
Get Nature+, our best-value online-access subscription
$29.99 / 30 days
cancel any time
Subscribe to this journal
Receive 51 print issues and online access
$199.00 per year
only $3.90 per issue
Rent or buy this article
Prices vary by article type
from$1.95
to$39.95
Prices may be subject to local taxes which are calculated during checkout
Nature 579, 459-461 (2020)
doi: https://doi.org/10.1038/d41586-020-00769-z
References
Srivastava, J., Sunthar, P. & Balaji, P. V. Preprint at bioRxiv https://doi.org/10.1101/2020.01.15.908491 (2020).
Hong, S. et al. Angew. Chem. Int. Edn 58, 14327–14333 (2019).
Xu, R. et al. Science 342, 1230–1235 (2013).
Pilobello, K. T., Krishnamoorthy, L., Slawek D. & Mahal, L. K. Chembiochem. 6, 985–989 (2005).
Black, A. P. et al. Anal. Chem. 91, 8429–8435 (2019).
Narimatsu, Y. et al. Mol. Cell. 75, 394–407 (2019).
De Leoz, M. L. A. et al. Mol. Cell. Prot. 19, 11–30 (2020).
Ye, Z., Mao, Y., Clausen, H. & Vakhrushev, S. Y. Nature Meth. 16, 902–910 (2019).
Kopec, M., Imiela, A. & Abramczyk, H. Sci. Rep. 9, 166 (2019).
 No added sugar: Antibody makers find an upside to ‘no fucose’
No added sugar: Antibody makers find an upside to ‘no fucose’
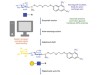 Robots command enzymes
Robots command enzymes
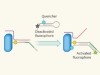 DNA tags used to image sugar-bearing proteins on cells
DNA tags used to image sugar-bearing proteins on cells
 NatureTech hub
NatureTech hub