- TECHNOLOGY FEATURE
Technologies to watch in 2019
Access options
Access Nature and 54 other Nature Portfolio journals
Get Nature+, our best-value online-access subscription
$29.99 / 30 days
cancel any time
Subscribe to this journal
Receive 51 print issues and online access
$199.00 per year
only $3.90 per issue
Rent or buy this article
Prices vary by article type
from$1.95
to$39.95
Prices may be subject to local taxes which are calculated during checkout
Nature 565, 521-523 (2019)
doi: https://doi.org/10.1038/d41586-019-00218-6
Interviews have been edited for clarity and length.
References
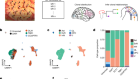
Hagai, T. et al. Nature 563, 197–202 (2018).
Haapaniemi, E. et al. Nature Med. 24, 927–930 (2018).
Kosicki, M., Tomberg, K. & Bradley, A. Nature Biotechnol. 36, 765–771 (2018).
Simhadri, V. L. et al. Mol. Ther. Meth. Clin. Dev. 10, 105–112 (2018).
Villiger, L. et al. Nature Med. 24, 1519–1525 (2018).
Bintu, B. et al. Science 362, eaau1783 (2018).
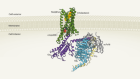
Falcon, B. et al. Nature 561, 137–140 (2018).
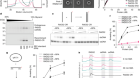
Grayson, P. C. et al. Ann. Rheum. Dis. 77, 1226–1233 (2018).
 Technology to watch in 2018
Technology to watch in 2018
 Nature’s 10
Nature’s 10
 Seven steps to boost your research career in 2019
Seven steps to boost your research career in 2019