- OUTLOOK
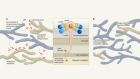
Infection forecasts powered by big data
Access options
Access Nature and 54 other Nature Portfolio journals
Get Nature+, our best-value online-access subscription
$29.99 / 30 days
cancel any time
Subscribe to this journal
Receive 51 print issues and online access
$199.00 per year
only $3.90 per issue
Rent or buy this article
Prices vary by article type
from$1.95
to$39.95
Prices may be subject to local taxes which are calculated during checkout
Nature 555, S2-S4 (2018)
doi: https://doi.org/10.1038/d41586-018-02473-5
This article is part of Nature Outlook: The future of medicine, an editorially independent supplement produced with the financial support of third parties. About this content.
 Four stories of antibacterial breakthroughs
Four stories of antibacterial breakthroughs
 The battle to tame autoimmunity
The battle to tame autoimmunity
 How CRISPR is transforming drug discovery
How CRISPR is transforming drug discovery