
Abstract
Teosinte, the wild ancestor of maize (Zea mays subsp. mays), has three times the seed protein content of most modern inbreds and hybrids, but the mechanisms that are responsible for this trait are unknown1,2. Here we use trio binning to create a contiguous haplotype DNA sequence of a teosinte (Zea mays subsp. parviglumis) and, through map-based cloning, identify a major high-protein quantitative trait locus, TEOSINTE HIGH PROTEIN 9 (THP9), on chromosome 9. THP9 encodes an asparagine synthetase 4 enzyme that is highly expressed in teosinte, but not in the B73 inbred, in which a deletion in the tenth intron of THP9-B73 causes incorrect splicing of THP9-B73 transcripts. Transgenic expression of THP9-teosinte in B73 significantly increased the seed protein content. Introgression of THP9-teosinte into modern maize inbreds and hybrids greatly enhanced the accumulation of free amino acids, especially asparagine, throughout the plant, and increased seed protein content without affecting yield. THP9-teosinte seems to increase nitrogen-use efficiency, which is important for promoting a high yield under low-nitrogen conditions.
This is a preview of subscription content, access via your institution
Access options
Access Nature and 54 other Nature Portfolio journals
Get Nature+, our best-value online-access subscription
$29.99 / 30 days
cancel any time
Subscribe to this journal
Receive 51 print issues and online access
$199.00 per year
only $3.90 per issue
Buy this article
- Purchase on Springer Link
- Instant access to full article PDF
Prices may be subject to local taxes which are calculated during checkout





Similar content being viewed by others


Data availability
All sequencing data for creation of the Ames 21814 haplotype have been deposited at the National Genomics Data Center (NGDC; https://ngdc.cncb.ac.cn/) under the BioProject number PRJCA011706, in which the PacBio HiFi data are under the accession number SAMC874385, the Hi-C data are under the accession number SAMC873392, the PacBio isoform sequencing data are under the accession number SAMC873393 and the Illumina WGS data are under the accession numbers SAMC874386 and SAMC874387. The final assembled genome sequence data reported in this paper have been deposited under accession number GWHBKHM00000000 that is publicly accessible at https://ngdc.cncb.ac.cn/gwh. The RNA-sequencing data of Ames 21814, B73 × Ames 21814 and B73 (roots and leaves at flowering stage) are under the accession numbers SAMC874334–SAMC874357. Source data are provided with this paper.
References
Karn, A., Gillman, J. D. & Flint-Garcia, S. A. Genetic analysis of teosinte alleles for kernel composition traits in maize. G3 7, 1157–1164 (2017).
Flint-Garcia, S. A., Bodnar, A. L. & Scott, M. P. Wide variability in kernel composition, seed characteristics, and zein profiles among diverse maize inbreds, landraces, and teosinte. Theor. Appl. Genet. 119, 1129–1142 (2009).
Han, C., Zhen, S., Zhu, G., Bian, Y. & Yan, Y. Comparative metabolome analysis of wheat embryo and endosperm reveals the dynamic changes of metabolites during seed germination. Plant Physiol. Biochem. 115, 320–327 (2017).
De Lumen, B. O. Molecular approaches to improving the nutritional and functional properties of plant seeds as food sources: developments and comments. J. Agric. Food Chem. 38, 1779–1788 (1990).
Palacios‐Rojas, N. et al. Mining maize diversity and improving its nutritional aspects within agro‐food systems. Comp. Rev. Food Sci. Food Saf. 19, 1809–1834 (2020).
Doebley, J. F., Gaut, B. S. & Smith, B. D. The molecular genetics of crop domestication. Cell 127, 1309–1321 (2006).
Matsuoka, Y. et al. A single domestication for maize shown by multilocus microsatellite genotyping. Proc. Natl Acad. Sci. USA 99, 6080–6084 (2002).
Whitt, S. R., Wilson, L. M., Tenaillon, M. I., Gaut, B. S. & Buckler, E. S. Genetic diversity and selection in the maize starch pathway. Proc. Natl Acad. Sci. USA 99, 12959–12962 (2002).
Duvick, D. N. in Advances in Agronomy Vol. 86 (ed. Sparks, D.) 83–145 (Academic, 2005).
Wani, S. H. et al. Nitrogen use efficiency (NUE): elucidated mechanisms, mapped genes and gene networks in maize (Zea mays L.). Physiol. Mol. Biol. Plants 27, 2875–2891 (2021).
Ciampitti, I. A. & Lemaire, G. From use efficiency to effective use of nitrogen: a dilemma for maize breeding improvement. Sci. Total Environ. 826, 154125 (2022).
Day, L. Proteins from land plants—potential resources for human nutrition and food security. Trends Food Sci. Technol. 32, 25–42 (2013).
Lee, S. et al. OsASN1 overexpression in rice increases grain protein content and yield under nitrogen-limiting conditions. Plant Cell Physiol. 61, 1309–1320 (2020).
Wu, Y. & Messing, J. in Achieving Sustainable Cultivation of Maize Vol 1 (ed. Watson, D.) Ch. 4 (Burleigh Dodds, 2017).
Esen, A. A proposed nomenclature for the alcohol-soluble proteins (zeins) of maize (Zea mays L.). J. Cereal Sci. 5, 117–128 (1987).
Thompson, G. & Larkins, B. in The Maize Handbook (eds Freeling, M. & Walbot, V.) 639–647 (Springer, 1994).
Koren, S. et al. De novo assembly of haplotype-resolved genomes with trio binning. Nat. Biotechnol. 36, 1174–1182 (2018).
Cheng, H., Concepcion, G. T., Feng, X., Zhang, H. & Li, H. Haplotype-resolved de novo assembly using phased assembly graphs with hifiasm. Nat. Methods 18, 170–175 (2021).
Hufford, M. B. et al. De novo assembly, annotation, and comparative analysis of 26 diverse maize genomes. Science 373, 655–662 (2021).
Simao, F. A., Waterhouse, R. M., Ioannidis, P., Kriventseva, E. V. & Zdobnov, E. M. BUSCO: assessing genome assembly and annotation completeness with single-copy orthologs. Bioinformatics 31, 3210–3212 (2015).
Albert, P. S., Gao, Z., Danilova, T. V. & Birchler, J. A. Diversity of chromosomal karyotypes in maize and its relatives. Cytogenet. Genome Res. 129, 6–16 (2010).
Ou, S., Chen, J. & Jiang, N. Assessing genome assembly quality using the LTR Assembly Index (LAI). Nucleic Acids Res. 46, e126 (2018).
Chen, J. et al. Dynamic transcriptome landscape of maize embryo and endosperm development. Plant Physiol. 166, 252–264 (2014).
Moose, S. P., Dudley, J. W. & Rocheford, T. R. Maize selection passes the century mark: a unique resource for 21st century genomics. Trends Plant Sci. 9, 358–364 (2004).
Goldman, I., Rocheford, T. & Dudley, J. Quantitative trait loci influencing protein and starch concentration in the Illinois long term selection maize strains. Theor. Appl. Genet. 87, 217–224 (1993).
Lea, P. J., Sodek, L., Parry, M. A. J., Shewry, P. R. & Halford, N. G. Asparagine in plants. Ann. Appl. Biol. 150, 1–26 (2007).
Jiang, L. et al. Analysis of gene regulatory networks of maize in response to nitrogen. Genes 9, 151 (2018).
Gaufichon, L. et al. Arabidopsis thaliana ASN2 encoding asparagine synthetase is involved in the control of nitrogen assimilation and export during vegetative growth. Plant Cell Environ. 36, 328–342 (2013).
Gaufichon, L. et al. ASN1-encoded asparagine synthetase in floral organs contributes to nitrogen filling in Arabidopsis seeds. Plant J. 91, 371–393 (2017).
Lam, H.-M. et al. Overexpression of the ASN1 gene enhances nitrogen status in seeds of Arabidopsis. Plant Physiol. 132, 926–935 (2003).
Luo, L. et al. OsASN1 plays a critical role in asparagine-dependent rice development. Int. J. Mol. Sci. 20, 130 (2018).
Ohashi, M. et al. Asparagine synthetase1, but not asparagine synthetase 2, is responsible for the biosynthesis of asparagine following the supply of ammonium to rice roots. Plant Cell Physiol. 56, 769–778 (2015).
Curtis, T. Y., Bo, V., Tucker, A. & Halford, N. G. Construction of a network describing asparagine metabolism in plants and its application to the identification of genes affecting asparagine metabolism in wheat under drought and nutritional stress. Food Energy Secur. 7, e00126 (2018).
Raffan, S. et al. Wheat with greatly reduced accumulation of free asparagine in the grain, produced by CRISPR/Cas9 editing of asparagine synthetase gene TaASN2. Plant Biotechnol. J. 19, 1602–1613 (2021).
Avila-Ospina, L., Marmagne, A., Talbotec, J., Krupinska, K. & Masclaux-Daubresse, C. The identification of new cytosolic glutamine synthetase and asparagine synthetase genes in barley (Hordeum vulgare L.), and their expression during leaf senescence. J. Exp. Bot. 66, 2013–2026 (2015).
Seebauer, J. R., Moose, S. P., Fabbri, B. J., Crossland, L. D. & Below, F. E. Amino acid metabolism in maize earshoots. Implications for assimilate preconditioning and nitrogen signaling. Plant Physiol. 136, 4326–4334 (2004).
Todd, J. et al. Identification and characterization of four distinct asparagine synthetase (AsnS) genes in maize (Zea mays L.). Plant Sci. 175, 799–808 (2008).
Raffan, S. & Halford, N. G. Cereal asparagine synthetase genes. Ann. Appl. Biol. 178, 6–22 (2021).
The, S. V., Snyder, R. & Tegeder, M. Targeting nitrogen metabolism and transport processes to improve plant nitrogen use efficiency. Front. Plant Sci. 11, 628366 (2021).
Sieciechowicz, K. A., Joy, K. W. & Ireland, R. J. The metabolism of asparagine in plants. Phytochemistry 27, 663–671 (1988).
Moison, M. et al. Three cytosolic glutamine synthetase isoforms localized in different-order veins act together for N remobilization and seed filling in Arabidopsis. J. Exp. Bot. 69, 4379–4393 (2018).
Liu, X., Hu, B. & Chu, C. Nitrogen assimilation in plants: current status and future prospects. J. Genet. Genomics 49, 394–404 (2021).
Congreves, K. A. et al. Nitrogen use efficiency definitions of today and tomorrow. Front. Plant Sci. 12, 637108 (2021).
Silva, I. T. et al. Biochemical and genetic analyses of N metabolism in maize testcross seedlings: 2. Roots. Theor. Appl. Genet. 131, 1191–1205 (2018).
Gallais, A. & Hirel, B. An approach to the genetics of nitrogen use efficiency in maize. J. Exp. Bot. 55, 295–306 (2004).
Hirel, B. et al. Towards a better understanding of the genetic and physiological basis for nitrogen use efficiency in maize. Plant Physiol. 125, 1258–1270 (2001).
Zhang, N. et al. Genome-wide association of carbon and nitrogen metabolism in the maize nested association mapping population. Plant Physiol. 168, 575–583 (2015).
Liu, Q. et al. Improving crop nitrogen use efficiency toward sustainable green revolution. Annu. Rev. Plant Biol. 73, 523–551 (2022).
Hou, M., Yu, M., Li, Z., Ai, Z. & Chen, J. Molecular regulatory networks for improving nitrogen use efficiency in rice. Int. J. Mol. Sci. 22, 9040 (2021).
Xuan, W., Beeckman, T. & Xu, G. Plant nitrogen nutrition: sensing and signaling. Curr. Opin. Plant Biol. 39, 57–65 (2017).
Durand, N. C. et al. Juicer provides a one-click system for analyzing loop-resolution Hi-C experiments. Cell Syst. 3, 95–98 (2016).
Durand, N. C. et al. Juicebox provides a visualization system for Hi-C contact maps with unlimited zoom. Cell Syst. 3, 99–101 (2016).
Ou, S. et al. Benchmarking transposable element annotation methods for creation of a streamlined, comprehensive pipeline. Genome Biol. 20, 275 (2019).
Bruna, T., Hoff, K. J., Lomsadze, A., Stanke, M. & Borodovsky, M. BRAKER2: automatic eukaryotic genome annotation with GeneMark-EP+ and AUGUSTUS supported by a protein database. NAR Genom. Bioinform. 3, lqaa108 (2021).
Kim, D., Paggi, J. M., Park, C., Bennett, C. & Salzberg, S. L. Graph-based genome alignment and genotyping with HISAT2 and HISAT-genotype. Nat. Biotechnol. 37, 907–915 (2019).
Li, W. & Godzik, A. Cd-hit: a fast program for clustering and comparing large sets of protein or nucleotide sequences. Bioinformatics 22, 1658–1659 (2006).
Zhang, Z., Yang, J. & Wu, Y. Transcriptional regulation of zein gene expression in maize through the additive and synergistic action of opaque2, prolamine-box binding factor, and O2 heterodimerizing proteins. Plant Cell 27, 1162–1172 (2015).
Bates, D., Mächler, M., Bolker, B. & Walker, S. Fitting linear mixed-effects models using lme4. J. Stat. Softw. 67, 1–48 (2015).
Bukowski, R. et al. Construction of the third-generation Zea mays haplotype map. Gigascience 7, gix134 (2018).
Zhou, X. & Stephens, M. Genome-wide efficient mixed-model analysis for association studies. Nat. Genet. 44, 821–824 (2012).
Chen, S., Zhou, Y., Chen, Y. & Gu, J. fastp: an ultra-fast all-in-one FASTQ preprocessor. Bioinformatics 34, i884–i890 (2018).
Li, H. & Durbin, R. Fast and accurate short read alignment with Burrows-Wheeler transform. Bioinformatics 25, 1754–1760 (2009).
McKenna, A. et al. The Genome Analysis Toolkit: a MapReduce framework for analyzing next-generation DNA sequencing data. Genome Res. 20, 1297–1303 (2010).
Mansfeld, B. N. & Grumet, R. QTLseqr: an R package for bulk segregant analysis with next-generation sequencing. Plant Genome 11, 180006 (2018).
Dong, J. et al. Analysis of tandem gene copies in maize chromosomal regions reconstructed from long sequence reads. Proc. Natl Acad. Sci. USA 113, 7949–7956 (2016).
Acknowledgements
We thank Y. Xiao, H. Zhan, B. Lin, Y. Gu, T. Zhang, X. Song and D. An for help with BSA sequencing and related analysis; K. Liu for help with the high-protein QTL analysis and gene mapping; C. Li from Anhui Agricultural University for help with the bioinformatics analysis; J. Shi and W. Li for help with the analysis of teosinte domestication and sequence variation; and Z. Wang, L. Zhang, X. Zeng and Y. Zhou for help with material planting in Harbin. This research was supported by the Chinese Academy of Sciences (XDB27010201 to Y.W.), the National Natural Science Foundation of China (31830063 and 31925030 to Y.W.; 32072008 to W.W.), the China Postdoctoral Science Foundation (2020M681412 to Y.H.) and the Shanghai ‘Super Postdoctoral’ Incentive Program (2020456 to Y.H.).
Author information
Authors and Affiliations
Contributions
Y.W., W.W., Y.H. and H.W. designed the research, analysed the data and supervised the project. Y.W., Y.H., H.W., Y. Zhu, X.H. and H.L. created genetic populations and materials. Y.H., H.W., Y. Zhu, X.H., Y. Zhao, L.Q., Y.J., Y.C., Q.X., Q.W., J.W., H.L. and X.L. performed experiments. W.W., S.L., X.W., Z.B. and Y.H. performed teosinte Ames 21814 haplotype sequencing, assembly and annotation. G.M. and X.Y. performed the GWAS analysis. Y.W., X.L., Y.H., H.W. and Y. Zhu performed the field NUE tests in Sanya. Y.W., W.W., Y.H., H.W. and B.A.L. explained the data, drafted and edited the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature thanks Shujun Ou, Jianming Yu and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data figures and tables
Extended Data Fig. 1 Content of total nitrogen and free amino acids in roots, stems and leaves of Ames 21814 and B73 and SDS–PAGE of zein and non-zein proteins in B73 and 10 teosinte lines.
a, Nitrogen content in roots, stems, leaves and seeds of B73 determined by acid hydrolysis and the Dumas method. Data are presented as mean ± s.d. (n = 6 biologically independent samples for each method). b, Total nitrogen content in roots, stems, and leaves of Ames 21814 and B73. Data are presented as mean ± s.d. (n = 10 biologically independent samples). c, Content of individual free amino acids in roots (the top panel), stems (the middle panel), and leaves (the bottom panel) of Ames 21814 and B73. Data are presented as mean ± s.d. (n = 6 biologically independent samples). d, SDS–PAGE of zein and non-zein proteins in B73 and 10 teosinte lines. The apparent size in kDa of each protein band is indicated on the left. M, protein markers. γ27, 27-kDa γ-zein; α22, 22-kDa α-zein; α19, 19-kDa α-zein; γ16, 16-kDa γ-zein; γ15, 15-kDa γ-zein; δ10, 10-kDa δ-zein. 3 times the SDS–PAGE analysis experiment were repeated independently with similar results. In a and b, a two-tailed Student’s t-test was used to determine P values, see Source Data.
Extended Data Fig. 2 Ames 21814 haplotype assembled by trio binning.
a, Phenotypes of teosinte Zea mays subsp. parviglumis (accession number: Ames 21814), B73 x Ames 21814 and B73. Scale bar, 35 cm. b, Teosinte haplotype genome assembly flow chart. To perform a de novo assembly of the teosinte haplotype, we sequenced and assembled its haplotype by integrating three technologies: HiFi long reads with the PacBio Sequel platform, paired-end sequencing with the Illumina HiSeq platform, high-throughput chromatin conformation capture (Hi-C). We completed assembly of the teosinte haplotype based on the trio-binning strategy because of the characteristics of high heterozygosity of Ames 21814. c, Whole genome Hi-C interaction heat map of 2.5 Mb windows. Each blue number indicates the corresponding chromosome. Each cluster represents a chromosome in the haplotype. In a set of chromosomes, the bottom cluster represents the hap1 (teosinte Ames 21814) chromosome, the top cluster represents the hap2 (B73) chromosome. d, Each chromosomes Hi-C contact map, Ames 21814 (Teo). e, Dot plot of B73 genome assembly (hap2, this study) and B73_v5 genome assembly. Alignment less than 20 kb was filtered out. f, Dot plot of Ames 21814 haplotype (hap1) and B73 haplotype (hap2). Alignment less than 20 kb was filtered out. g, Haplotype-specific inversions supported by the Hi-C contact map. Fourteen inversions larger than 1 Mb were selected for Hi-C zoom-in inspection by excluding those caused by tandem repeat arrays (CentC or knob). Thirteen inversions were correctly verified, while the Chr1: 235 Mb inversion is a misscaffold contig.
Extended Data Fig. 3 Variation in α-zein gene copies between Ames 21814 and maize inbreds.
a, Copy numbers of α-zein genes in Ames 21814, B73 and W22. Gene numbers of α19 (z1A1, z1A2, z1B and z1D) and α22 (z1C1 and z1C2) are indicated beside each locus. b, Statistical analysis of copy number of α19 (z1A1, z1A2, z1B and z1D) and α22 (z1C1 and z1C2) in Ames 21814, B73 and W22.
Extended Data Fig. 4 Diagram showing how the genetic populations were created and measurement of protein content in backcrossing populations.
a, The population size for each generation is indicated. b, SDS–PAGE showing zein accumulation in B73, teosinte (Ames 2184), and B73 x Ames 21814 seeds. c, Nitrogen content in roots of B73 and F1 plants of B73 x Ames 21814. Data are presented as mean ± s.d. (n = 6 biologically independent samples for each method). d, Nitrogen content in stems of B73 and F1 plants of B73 x Ames 21814. Data are presented as mean ± s.d. (n = 6 biologically independent samples for each method). e, Nitrogen content in leaves of B73 and F1 plants of B73 x Ames 21814. Data are presented as mean ± s.d. (n = 6 biologically independent samples for each method). f, SDS–PAGE of zein accumulation in 10 F2 seeds of B73 x Ames 21814. B73 seed was used as the control. g, SDS–PAGE of zein accumulation in seeds from 12 different BC2 eras. B73 seed was used as the control. h, SDS–PAGE of zein accumulations in 12 BC2 seeds from a single high-protein ear. B73 seed was used as the control. i, Protein content in seeds from 30 different BC3 ears. j, Protein content in 8 high-protein ears in the BC3 population. Seven single seeds for each ear were measured. B73 was used as the control. k, The protein content in seeds from 30 different BC4 ears. l, The protein content in 8 high-protein ears in the BC4 population. Seven single seeds for each ear were measured. B73 was used as the control. In b, f-h, more than three times the SDS–PAGE analysis experiment were repeated independently with similar results. In c-e, a two-tailed Student’s t-test was used to determine P values, see Source Data.
Extended Data Fig. 5 Mapping THP9 by BSA sequencing of three populations of BC4, BC6 and BC8 and deep resequencing of five high-protein and five low-protein BC6F4 lines.
a, Phenotyping high- and low-protein ears by SDS–PAGE of zein (upper panel) and non-zein protein (lower panel) accumulation in the BC4 population. M, protein mol wt markers. γ27, 27-kDa γ-zein; α22, 22-kDa α-zein; α19, 19-kDa α-zein; γ16, 16-kDa γ-zein; γ15, 15-kDa γ-zein; δ10, 10-kDa δ-zein. b, Gene introgression analysis based on BSA sequencing of the BC4 population. c, Frequency distribution analysis of seed protein content in the BC6 population. A group of 1,314 ears were phenotyped and classified. d, Gene introgression analysis based on BSA sequencing of the BC6 population. e, Frequency distribution analysis of protein content in the BC8 population. A group of 1,344 ears was phenotyped and classified. f, Gene introgression analysis by BSA sequencing of the BC8 population. Bottom is the differential expression of introgressed genes based on RNA-Seq analysis of BC8 leaves. g, A total of 10 lines were analysed for gene introgression by resequencing. The high-protein lines are S2528, S2590, S2591, S2592 and S2596, and the low-protein lines are S2468, S2513, S2529, S2605 and S2609. The peak of introgressed teosinte DNA fragments in these lines was based on the B73 genome (B73_v4) coordinates are 13 Mb-143 Mb in S2528, 22.7 Mb-144.4 Mb in S2590, S2591, S2592 and S2596, 13 Mb-99 Mb in S2529, 22.7 Mb-135.5 Mb in S2605 and S2609. The smallest common region of the candidate interval is located between 135.5 and 143 Mb as indicated by the dotted box.
Extended Data Fig. 6 Three genes annotated in the 150-kb fine-mapping region and ASN4 transcript analysis.
a, Gene structure of Zm00001d047732 and SNPs in the coding sequences in B73 and Ames 21814. b, Expression fold change of the three genes in roots and leaves of NILB73 and NILTeo based on our RNA-Seq data. c, Schematic representation of ASN4 transcripts in B73 and Ames 21814. d,TPM mean analysis of ASN4 transcripts in B73 and Ames 21814 leaves and roots based on the RNA-seq data. TPM, Transcripts Per Million. Data are mean ± s.d. (n = 3 biologically independent samples). e, RNA-seq reads of THP9 in NILB73 (upper panel) and NILTeo (lower panel) leaves. The number refers to the number of reads across the junction. f, Expression of the ASN4 promoter sequences amplified from Ames 21814 and B73 compared by dual-luciferase (LUC) assay. Data are presented as mean ± s.d. P values, a two-tailed Student’s t-test was used to determine P values, see Source Data.
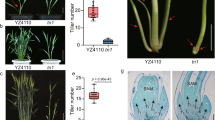
Extended Data Fig. 7 Linkage of THP9-T with high asparagine and high protein contents in the BC7F3 population and phenotypic comparison of NILTeo and NILB73.
a, Phenotypes of three representative BC7F3 ears with maternal genotypes that are homozygous THP9-B, heterozygous THP9-H (T/B) and homozygous THP9-T, respectively. b, Free asparagine content in THP9-B, THP9-H and THP9-T roots in the BC7F3 population. Data are mean ± s.d. (n = 10 biologically independent samples). c, Protein content in seeds from self-pollinated THP9-B, THP9-H and THP9-T plants in the BC7F3 population. Each ear was used as one unit. Data are mean ± s.d. (n = more than 20 biologically independent samples). d, Plant phenotypes of NILTeo and NILB73. Scale bar, 30cm. e, Plant height of NILTeo and NILB73. The plants were grown in Sanya in 2021. Data are mean ± s.d. (n = 18 biologically independent samples). f, Plant fresh weight (root and aboveground mass) of NILTeo and NILB73. Data are mean ± s.d. (n = 6 biologically independent samples). g, Association analysis of seed protein content with total stem nitrogen content in the BC8 population. The corresponding seed protein content and stem nitrogen content of the same plant are connected by a solid grey line (n = 1334 biologically independent samples). h, The total nitrogen content in NILTeo and NILB73 roots, stems, and leaves. Data are mean ± s.d. (n = 33, 41 and 20 biologically independent samples, respectively). i, Total free amino acid content in NILTeo and NILB73 roots and leaves. Data are mean ± s.d. (n = 20 biologically independent samples, respectively). In b-c, different letters indicate significant differences (P < 0.01, one-way ANOVA and further Tukey’s test, see Source Data). In e, f and h, i, a two-tailed Student’s t-test was used to determine P values, see Source Data.
Extended Data Fig. 8 NILB73 and NILTeo under normal and low-nitrogen conditions.
a-c, Construction of four aboveground concrete containers with plastic film covering the containers. d, NILB73 and NILTeo grown in container without nitrogen fertilizer application. e, The nitrogen content of soil in containers with and without nitrogen application. Data are mean ± s.d. (n = 16 biologically independent samples). f, Plant phenotypes of NILB73 and NILTeo with and without nitrogen application. Scale bar, 20 cm. g, Root phenotypes of NILB73 and NILTeo with and without nitrogen application. Scale bar, 5 cm. h, Plant height of NILTeo and NILB73. Data are mean ± s.d. (n = 8 biologically independent samples). i, qRT–PCR analysis of THP9 expression in NILB73 and NILTeo roots with and without nitrogen application. Data are mean ± s.d. (n = 3 biologically independent samples). j, Root fresh weight of NILB73 and NILTeo with and without nitrogen application. Data are mean ± s.d. (n = 8 biologically independent samples). k, Aboveground biomass of NILB73 and NILTeo with and without nitrogen application. Data are mean ± s.d. (n = 14 biologically independent samples). l. Total nitrogen content in NILB73 and NILTeo roots with and without nitrogen application. Data are mean ± s.d. (n = 6 biologically independent samples). m, Total nitrogen content in NILB73 and NILTeo stems with and without nitrogen application. Data are mean ± s.d. (n = 10 biologically independent samples). n, Total nitrogen content in NILB73, and NILTeo leaves with and without nitrogen application. Data are mean ± s.d. (n = 6 biologically independent samples). o, Protein content in NILB73 and NILTeo seeds with and without nitrogen application. Data are mean ± s.d. (n = 20 biologically independent samples). In e and h-o, letters indicate significant differences (P < 0.01, one-way ANOVA and further Tukey’s test).
Extended Data Fig. 9 Wild-type B73 and THP9-OE2 under normal and low-nitrogen conditions.
a, Plant phenotypes of WT (B73), NILTeo and THP9-OE2 with and without nitrogen application. Scale bar, 20 cm. b, Root phenotypes of WT, NILTeo and THP9-OE2 with and without nitrogen application. Scale bar, 5 cm. c, The nitrogen content of soil in containers with and without nitrogen application. Data are mean ± s.d. (n = 8 biologically independent samples). d, Plant height of WT and THP9-OE2. Data are mean ± s.d. (n = 8 biologically independent samples). e, The root fresh weight of WT and THP9-OE2 with and without nitrogen application. Data are mean ± s.d. (n = 14 biologically independent samples). f, The aboveground biomass of WT and THP9-OE2 with and without nitrogen application. Data are mean ± s.d. (n = 14 biologically independent samples). g. Total nitrogen content in WT and THP9-OE2 roots with and without nitrogen application. Data are mean ± s.d. (n = 12 biologically independent samples). h, Total nitrogen content in WT and THP9-OE2 stems with and without nitrogen application. Data are mean ± s.d. (n = 12 biologically independent samples). i, Total nitrogen content in WT and THP9-OE2 leaves with and without nitrogen application. Data are mean ± s.d. (n = 12 biologically independent samples). j, Protein content in WT and THP9-OE2 seeds with and without nitrogen application. Data are mean ± s.d. (n = 20 biologically independent samples). In c-g, letters indicate significant differences (P < 0.01, one-way ANOVA and further Tukey’s test).
Extended Data Fig. 10 Seed protein content of NILTeo × Mo17 and Zhengdan 958-T hybrids.
a, Seed protein content in Zhengdan 958-B and Zhengdan 958-T seeds. Data are presented as mean ± s.d. (n = 20 biologically independent samples). Protein content in F2 seeds of NILB73 x Mo17 and NILTeo x Mo17. Data are presented as mean ± s.d. (n = 30 biologically independent samples). In a,b, a two-tailed Student’s t-test was used to determine P values, see Source Data.
Supplementary information
Supplementary Information
This file contains Supplementary Figs. 1–5, the extended SDS–PAGE analysis of protein and the original source images for the western blots, and Supplementary Tables 1–7.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Huang, Y., Wang, H., Zhu, Y. et al. THP9 enhances seed protein content and nitrogen-use efficiency in maize. Nature 612, 292–300 (2022). https://doi.org/10.1038/s41586-022-05441-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41586-022-05441-2
This article is cited by
-
Cytoplasmic genome contributions to domestication and improvement of modern maize
BMC Biology (2024)
-
Recent Advancements in Nitrogen Use Efficiency in Crop Plants Achieved by Genomics and Targeted Genetic Engineering Approaches
Plant Molecular Biology Reporter (2024)
-
Tissue distribution of metabolites in Cordyceps cicadae determined by DESI-MSI analysis
Analytical and Bioanalytical Chemistry (2024)
-
geneHapR: an R package for gene haplotypic statistics and visualization
BMC Bioinformatics (2023)
-
The genetic architecture of prolificacy in maize revealed by association mapping and bulk segregant analysis
Theoretical and Applied Genetics (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
