
Abstract
We model a social-encounter network where linked nodes match for reproduction in a manner depending probabilistically on each node’s attractiveness. The developed model reveals that increasing either the network’s mean degree or the “choosiness” exercised during pair formation increases the strength of positive assortative mating. That is, we note that attractiveness is correlated among mated nodes. Their total number also increases with mean degree and selectivity during pair formation. By iterating over the model’s mapping of parents onto offspring across generations, we study the evolution of attractiveness. Selection mediated by exclusion from reproduction increases mean attractiveness, but is rapidly balanced by skew in the offspring distribution of highly attractive mated pairs.
Similar content being viewed by others

Introduction
Most animals assort positively for mating1; that is, values of a phenotypic or genotypic trait correlate positively across a population’s mated pairs2,3. The strength of assortment varies among taxonomic groups and categorical traits. But phenotypic similarity between paired females and males, often with respect to body size or visual signals, occurs far more often that does negative assortment or random mating1,4. Humans are not an exception5. Mate choice in humans produces partner similarity with respect to several traits, including age, social attitudes, height and attractiveness6. Our study focuses on attractiveness, which we invoke as a surrogate for any genetically variant, continuous trait correlating positively across pairs.
Assortative mating is sometimes adaptive. Under disruptive selection, individuals may adaptively avoid producing lower-fitness intermediates by assorting positively for reproduction7. However, in many cases assortative mating arises because of some other ecological process. For example, if a phenotypic trait covaries spatially or temporally with habitat in both sexes, the population’s spatio-temporal structure can induce assortative mating in the absence of selection on mate choice1. Importantly, trait similarity within mating pairs may drive the evolution of that trait, independently of the reason for assortative mating8,9.
Several disciplines, including population genetics and social psychology, have explored relationships involving individual pair-bonding preferences, assortative mating, and the evolutionary consequences of homogamy10,11,12,13. Certain models include the realism of stochasticity in encounters between potential mates, and in both pair formation and dissociation14,15. However, most available models for assortative mating assume fully-connected social structure. That is, every female may encounter every male in the same population. Realistically however, any individual has social contact with a limited number of potential mates, which can be characterized by the degree distribution of a bipartite network (females and males)15,16. The network topology has a profound impact on many properties of social networks17,18,19,20,21. In this case, it can govern many aspects of a system such as the number of mated nodes in a population and the strength of assortative mating across those mated nodes14,15.
Our analysis extends this line of inquiry. We assume assortative mating with respect to attractiveness, and vary the degree of “choosiness” or selectivity exercised during pair formation. We show how the strength of assortative mating increases with an encounter network’s average degree. We also find, contrary to intuition that the number of mated nodes in a large population increases as this population becomes more selective during pairing, if the system has sufficient time to complete interactions. Finally, we assume that attractiveness is a heritable trait, and show how the population-level distribution of attractiveness evolves under assortative mating.
Methods
Throughout this work, we assume that each discrete generation has the same size, and that the sex ratio is unity. Selectivity acts on individuals through access to reproduction. All successfully paired individuals have the same mean number of offspring, independently of their attractiveness; any remaining individuals leave no offspring. This assumption lets us focus on how network topology and attractiveness interactively affect breeding inclusion vs. exclusion.
The Encounter Network
We construct a bipartite graph with 2N nodes divided equally between subsets A and B. Each node is assigned links according to a degree distribution P(k); a node’s links connect it to nodes of the other subset. The network’s average degree is then  . To explore assortative mating in sparse networks, we employ an Erdös-Rényi graph22,23 which is arguably the simplest network with random topology. Each node Ai ∈ A has a weight aI ∈ [0, 1] which is a continuous random variable that represents the node’s attractiveness. In this work, we initialize these variables as uniform random variables on [0, 1] Nodes in subset B are assigned their weights in the same way. We then link nodes stochastically based on the degree distribution and denote the set of all links as L. The links enable nodes for interaction and eventually pairing.
. To explore assortative mating in sparse networks, we employ an Erdös-Rényi graph22,23 which is arguably the simplest network with random topology. Each node Ai ∈ A has a weight aI ∈ [0, 1] which is a continuous random variable that represents the node’s attractiveness. In this work, we initialize these variables as uniform random variables on [0, 1] Nodes in subset B are assigned their weights in the same way. We then link nodes stochastically based on the degree distribution and denote the set of all links as L. The links enable nodes for interaction and eventually pairing.
Pair formation dynamics
To begin, consider the pairing dynamics described in ref. 15 (which we modify below). If nodes Ai and Bj are linked, we denote that link as li,j = {Ai, Bj} ∈ L and has an associated weight defined by its endpoints as:

In the model, all links are initially in the potential state. There are two other states of a link, temporary and permanent. Only three transitions are possible, from potential to the temporary state and from temporary to either the potential or permanent state, the permanent state being an absorbing state. The general flow of the pair formation dynamics goes as follows:
1. A random link li,j = {Ai, Bj} is chosen from set L.
2. A uniform random number r ∈ U(0,1) is generated and if r < (wi,j)β (where the exponent β ≥ 0 controls the strength of selectivity (see next section for details)), the pairing condition is met and one of two transitions occurs.
3a. If li.j is in the potential state, it transitions to a temporary state and every other link in a temporary state with one of its endpoints being Ai or Bj returns to the potential state.
3b. If li,j is in the temporary state, it transitions to the permanent state. Its endpoints, which term a mated pair, are then placed in the set M, and all of their links are removed from the graph.
4. The simulation time is increased by  where q ∈ U(0,1).
where q ∈ U(0,1).
5. This repeats until subsets A and B are empty or contain only isolated nodes.
Iteration of the process results in M containing all mated pairs with all other nodes discarded.
Note that the pair formation dynamics implies that the average attractiveness in subsets A and B prior to pair formation can differ from the average attractiveness among individuals that become mated pairs. Below we refer to this difference as the selection differential. First, we specify how pair formation might depend on “choosiness,” or partner selectivity.
Matching Selectivity
The criterion for meeting the pairing condition (step 2 of the pair formation dynamics) has been generalized compared to15 in which β = 1. As a convenience, we refer to β as selectivity; as β increases, the randomly selected link is less likely to meet the pairing condition when sampled. Of course, if β = 0, every sampled link meets the pairing condition, and β = 1 corresponds to the original step 2 above. One can analytically show that the introduction of β is similar to transforming the initial population to a new distribution. Supplementary Information presents a derivation of the continuous random variable Y, with realizations  29.
29.
Increased selectivity should extend the time elapsing before all nodes in subsets A and B are removed or isolated. Ecologically, the time available for pair-bonding may be constrained, in which case greater selectivity might exclude more individuals from breeding4. Our pair formation dynamics does not take into account this constraint, but selectivity still can affect the likelihood a node of given degree forming a pair. It is worth noting that nodes in A and B are assigned attractiveness and connectivity by the same random process and are drawn from the same distributions. It follows that sets A and B have statistically equivalent properties of attractiveness and inter-connectivity.
Computational Procedures
The degree distribution for an Erdös-Rényi graph will approximate a truncated Poisson probability function with average degree  for large number of nodes22,23,24. Hence, nodes of high degree occur rarely. The graph is constructed by selecting two random nodes, one from subset A and the other from subset B. These nodes become linked so long as the selected nodes do not already have a link connecting them. The created link is then added to L. This process is continued until
for large number of nodes22,23,24. Hence, nodes of high degree occur rarely. The graph is constructed by selecting two random nodes, one from subset A and the other from subset B. These nodes become linked so long as the selected nodes do not already have a link connecting them. The created link is then added to L. This process is continued until  .
.
Rejection-free simulation
During pair formation, changes occur, that is the system’s history is updated, only when the pairing condition is met. Advancing the simulation so that we skip the events in which the pairing condition is not met offers a computational advantage, as when β increases the frequency of failure to meet the pairing condition increases. Therefore, we model pairing as the sequence of events generated by |L| independent Poisson processes employing a rejection-free scheme25,26,27.
First, we construct the probability distribution for choosing which link will next meet the pairing condition. The probability that any given link will be chosen in step 1 of the pair formation dynamics is  . It follows that the probability that a given link li,j will meet the pairing condition stated above is
. It follows that the probability that a given link li,j will meet the pairing condition stated above is  . By excluding the outcomes where the pairing condition is not met, the probability distribution for which link will meet the pairing condition is as follows:
. By excluding the outcomes where the pairing condition is not met, the probability distribution for which link will meet the pairing condition is as follows:

This distribution remains static until the network structure changes. The transition from a potential to temporary state does not affect the transition rates of any link in the system. Only a transition to a permanent state causes the distribution to be updated. For a rejection-free scheme, we modify the following in the pair formation dynamics. In step 1, a link is selected by generating a uniformly distributed random number r ∈ U(0, 1) and mapping it into the inverse of the cumulative distribution function associated with Eq. 2 to identify the selected link li,j, which by definition meets the pairing condition of step 2. Step 4 is also modified so that the time elapsed between consecutive pairing conditions is the random variable ΔT defined by the following:

where q is a uniformly distributed random number on (0, 1).
Our implementation serves primarily to accelerate simulation. It also helps to explain the limiting case of β → ∞. Let wmax be the maximum link weight in the population and nmax ≥ 1 be the number of links with such weight. After dividing the numerator and denominator in Eq. 2 by  in the limit of β → ∞ the denominator
in the limit of β → ∞ the denominator  tends to nmax because all terms corresponding to links with less than the maximum weight will be reduced to 0. Likewise, the numerator
tends to nmax because all terms corresponding to links with less than the maximum weight will be reduced to 0. Likewise, the numerator  will go to either 1 if wi,j = wmax or 0 otherwise. Hence, we will have a constant probability of 1/nmax to select a link with the maximum weight. This choice becomes deterministic if there is only one such link. Note that when wmax < 1, using this limit causes the time between each pairing conditions to become infinite. In such a case, we cannot use Eq. 3 to analyze the time series unless we normalize the link weights
will go to either 1 if wi,j = wmax or 0 otherwise. Hence, we will have a constant probability of 1/nmax to select a link with the maximum weight. This choice becomes deterministic if there is only one such link. Note that when wmax < 1, using this limit causes the time between each pairing conditions to become infinite. In such a case, we cannot use Eq. 3 to analyze the time series unless we normalize the link weights  . This produces a very trivial time series as the denominator summation in Eq. 3 will tend to nmax and become independent of which link is chosen.
. This produces a very trivial time series as the denominator summation in Eq. 3 will tend to nmax and become independent of which link is chosen.
Reproduction and Offspring Attractiveness
Once pair formation has ended, we use the mated pairs in set M to produce the next generation of nodes. A(g) and B(g) represent the subsets of nodes in generation g, prior to that generation’s pair formation. Initially by definition, we have A(0) ≡ A and B(0) ≡ B. We define a(g) and b(g) as attractiveness values before pair formation in generation g with their initial values being a(0) ≡ a and b(0) = b. Pair formation in generation g constructs the set M(g) with its attractiveness-pairs a(g), b(g). Thereafter, the mated pairs in set M(g) produce the next generation’s A(g+1) and B(g+1). We assume that any offspring of a given pair in M(g) has attractiveness x sampled from a truncated normal density with moments conditioned on the parents’ attractiveness levels. That is, offspring attractiveness has the conditional probability density:

we also introduce G, the offspring variance, to control the standard deviation σ in the offspring attractiveness probability density. The normal distribution requires that σ > 0, so it follows that G is always positive. Reproduction proceeds for N steps as follows.
- 1
Randomly choose a mated pair
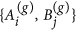 in set M(g).
in set M(g). - 2
Generate a node in each of the subsets A(g+1) and B(g+1), and for each node generated, sample its attractiveness from f(x|μ, σ) with
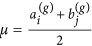 and
and  .
. - 3
Repeat this process until 2N nodes are generated so the population size is the same for every generation.
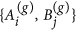 in set M(g).
in set M(g).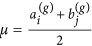 and
and  .
.After all nodes have been generated, we assign links to them in the same way links were assigned to their parents (using the same distribution and parameters), but completely independently. This process preserves the statistical properties of each generation in terms of attractiveness and inter-connectivity between sets A(g) and B(g).
Several assumptions introduced here require elaboration. We restrict attractiveness to the unit interval. Even though quantitative genetic models commonly treat unbounded phenotypic traits28 it is easy to map a set of unbounded traits of a phenotype into restricted attractiveness. Yet, bounded attractiveness does introduce an obvious complication under positive assortative mating. If μ < 0.5 then the offspring distribution density is symmetric only in the range [0, 2μ] and has an asymmetric non-zero distribution density in the range [2μ, 1] (see Fig. 1). As a result, the average offpsring attractiveness in this case is higher than the attractiveness of the midpoint μ, which we refer to as a positive offspring attractiveness skew. The opposite, negative attractiveness skew, arises when μ > 0.5. The end result is that parents will tend to have offspring with attractiveness closer to the interior values of attractiveness than their parent’s midpoint with this result becoming stronger as the midpoint becomes farther from 0.5.

This distribution is skewed for all values of μ ≠ 0.5 due to the boundary conditions. For instance, for μ = 0.98 (μ = 0.02) most offspring have phenotypes with attractiveness less (more) than that of the mid-parent. σ = 0.1.
We assume that the mean and the (approximate) variance of the offspring attractiveness distribution depend on the parents ‘phenotypes. Most quantitative genetic models assume, as a convenience, an offspring trait variance independent of the parents’ trait values, termed the segregation variance28,29. However, we can anticipate that a quantitative trait’s variability among a given pair’s offspring will increase with the difference between parental trait values. Hence, we let the variance of the offspring distribution increase with factor inherent to sexual reproduction (G) and with the difference between parental attractiveness.
Selection: Differential and Response
In our model, the selection differential Sg is the difference between mean attractiveness among individuals of generation g that pair for reproduction and mean attractiveness among members of the same generation at birth. Sg ≠ 0 implies that average attractiveness differs between individuals who attract a mate and those that do not. We have:

Our model’s response to selection Rg is the difference between mean attractiveness among individuals of generation (g + 1) at birth and mean attractiveness among their parents at birth. We have:

By definition, the population evolves when Rg ≠ 0.
Results
Assortative Mating: Selectivity and Degree
First, we consider the distribution of mated pairs  formed during simulation, as selectivity β and average number of links per node
formed during simulation, as selectivity β and average number of links per node  are varied. Each simulation included 2N = 2 × 104 nodes. Using the same initial conditions (uniformly distributed attractiveness values), we conducted 20 simulations and averaged results.
are varied. Each simulation included 2N = 2 × 104 nodes. Using the same initial conditions (uniformly distributed attractiveness values), we conducted 20 simulations and averaged results.
Figure 2 shows the relative frequencies of attractiveness values for mated pairs. Fixing  , increasing selectivity promotes the strength of assortative mating. Fixing β while increasing the network’s average degree increases the strength of assortment. For β < 1, the effect of greater average degree is relatively small, since encounters so readily lead to pairing. Indeed, the combination of low β and small
, increasing selectivity promotes the strength of assortative mating. Fixing β while increasing the network’s average degree increases the strength of assortment. For β < 1, the effect of greater average degree is relatively small, since encounters so readily lead to pairing. Indeed, the combination of low β and small  (upper left panel) generates mated pairs with attractiveness close to uniformly distributed over all levels. High selectivity and large degree (lower right panel) nearly eliminate bonding of mated pairs with a large difference in attractiveness, and matching is highly assortative. These results on pair formation accord with intuition, and motivate us to apply the model to the evolution of attractiveness.
(upper left panel) generates mated pairs with attractiveness close to uniformly distributed over all levels. High selectivity and large degree (lower right panel) nearly eliminate bonding of mated pairs with a large difference in attractiveness, and matching is highly assortative. These results on pair formation accord with intuition, and motivate us to apply the model to the evolution of attractiveness.

Each mated pair is binned into a 0.02 by 0.02 bin according to the pair’s attractiveness set. Each distribution is normalized and then averaged, and the bins are smoothed for visual purposes. The top row corresponds to β = 0.5, middle row β = 1, and bottom row β = 4. The left column corresponds to  , middle column
, middle column  , and right column
, and right column  .
.
Note that in each panel of Fig. 2, the most frequent mated pairs involve two highly attractive individuals. As described above, these matches tend to form earlier during the pair formation process; highly attractive individuals are unlikely to be excluded from reproduction.
Number of Mated Pairs Formed
The total number of mated pairs formed, |M| = n, increases in a decelerating manner as the mean node degree increases (Fig. 3a). Not surprisingly, increasing the total number of feasible encounters results in fewer individuals excluded from reproduction.

1000 realizations are produced for various values of average node degree and selectivity. (a) The number of mated pairs n. (b) The relative changes in the number of matches is defined as Δn = n(<k>, β) − n(<k>, 0). (c) The matching efficiency R, which is the average ratio of the number of matches for a given system over the maximum possible number of matches for that same system. (d) The relative changes in the matching efficiency is defined as ΔR = R(<k>, β) − R(<k>, 0). A one-to-one correspondence is not present between (b,d) due to each realization of the matching having its own ratio and that ratio being averaged, rather than dividing the average number of matches by the average maximum number of matches.
Fixing  , we find that greater selectivity results in an increased number of mated pairs (Fig. 3b). The effect of selectivity is strongest in networks of low average degree
, we find that greater selectivity results in an increased number of mated pairs (Fig. 3b). The effect of selectivity is strongest in networks of low average degree  . Interestingly, the ratio of n to the maximal number of mated pairs that could form (in the same network) is minimal where the effect of selectivity on n is maximal (Fig. 3c,d). That is, where network topology results in the greatest proportional exclusion of individuals from mating, the increase in pairing due to greater selectivity attains a maximum. Averaged over attractiveness, increased selectivity during pair formation reduces the likelihood that an individual will be excluded from mating.
. Interestingly, the ratio of n to the maximal number of mated pairs that could form (in the same network) is minimal where the effect of selectivity on n is maximal (Fig. 3c,d). That is, where network topology results in the greatest proportional exclusion of individuals from mating, the increase in pairing due to greater selectivity attains a maximum. Averaged over attractiveness, increased selectivity during pair formation reduces the likelihood that an individual will be excluded from mating.
To explain this observation, Figure S1 shows that nodes of low degree, averaged over attractiveness, have a greater probability of becoming a part of a mated pair as β → ∞. This is because increasing selectivity increases the strength of assortative mating, and that mated pairs of mutually high-attractiveness form earliest for any  -combination. Figure S1 suggests that greater selectivity causes nodes with low degree, but high attractiveness to have an increased chance of becoming a mated pair, decreasing the number of links removed when this happens. Fewer nodes of intermediate (or low) attractiveness then need be excluded from mating due to more links being available, therefore n increases.
-combination. Figure S1 suggests that greater selectivity causes nodes with low degree, but high attractiveness to have an increased chance of becoming a mated pair, decreasing the number of links removed when this happens. Fewer nodes of intermediate (or low) attractiveness then need be excluded from mating due to more links being available, therefore n increases.
Time to Match
Contrary to real life, the model does not contain a universal time limit to find a match. It may be the case that there exists a maximum time allowed for nodes in a population to find a match. Figure 4 shows the number of matches as a function of time for various  at constant β. Figure 5 shows similar plots, but for various β at constant
at constant β. Figure 5 shows similar plots, but for various β at constant  .
.

The average number of matches  vs time averaged over twenty trials. The top figure corresponds to a constant β = 0.1, middle β = 1, and bottom β = 4.
vs time averaged over twenty trials. The top figure corresponds to a constant β = 0.1, middle β = 1, and bottom β = 4.

The average number of matches  vs time averaged over twenty trials. The top row corresponds to a constant
vs time averaged over twenty trials. The top row corresponds to a constant  , middle row
, middle row  , and bottom row
, and bottom row  . The right column magnifies the left column regions that contain intersections of functions.
. The right column magnifies the left column regions that contain intersections of functions.
We observe that for a given average node degree, the time required to match increases by orders of magnitude as selectivity increases. This is expected as increased selectivity in general increases the time between successful pairing conditions. As shown above with sufficient time, higher selectivities eventually catch up to lower selectivity in terms of the number of matches. In addition, there is an overhead time before any system can begin producing mated pairs which exists in all realizations. This is due to the courtship mechanism where all links need to meet the pairing condition at least twice. Because there is a low chance to randomly select a given link, it on average takes a significant amount of time for the first mated pair to form.
Attractiveness Evolution
To address phenotypic evolution, we first fix selectivity β, and vary the network’s mean degree. Figure S2 shows how the bivariate distribution of mated pairs changes from an initial to post third round of pair formation, with β = 1. The distribution of mated pair attractiveness levels becomes more condensed after each generation in each case. The dispersion of the distribution looks similar for various  , but is statistically different. Since assortative mating increases with
, but is statistically different. Since assortative mating increases with  , the distribution’s small dependence on
, the distribution’s small dependence on  suggests that the distribution of phenotypes at birth rapidly changes from generation to generation.
suggests that the distribution of phenotypes at birth rapidly changes from generation to generation.
Even though individuals with higher attractiveness will have a lower chance of being excluded from reproduction (directional selection), we find a bias towards phenotypic values near the center of the distribution. This is because there is one primary and one secondary factor that counteract the directional selection. The primary factor is the negative attractiveness skew of the offspring distribution for high-attractiveness parents causing offspring to have lower attractiveness than their parents. This increases the number of nodes close to the interior values, and triggers the secondary factor of increased probability that a high attractiveness node will mate with a node with attractiveness close to the interior values. This lowers the average attractiveness of nodes with high attractiveness parents even more. This effect is reduced for larger β as nodes will be more likely to have a self-similar mate (see below).
Fixing  , we show effects of increasing selectivity in Fig. 6. Again, the bivariate distribution of mated pairs begins to converge quickly.
, we show effects of increasing selectivity in Fig. 6. Again, the bivariate distribution of mated pairs begins to converge quickly.

Each mated pair is binned into a 0.02 by 0.02 bin according to the pair’s attractiveness set. Each distribution is normalized and then averaged, and the bins are then smoothed for visual purposes. From the top row going down, the rows use β = 0, β = 0.5, β = 1, β = 4, and β = ∞. The left column corresponds to generation zero, middle column generation one, and right column generation two. All distributions were generated with  and G = 0.75.
and G = 0.75.
For β = 0, the distribution’s radial symmetry, most prominent in generation three, indicates an absence of assortative mating (see upper rightmost subfigure of Fig. 6). Indeed, the distributions of attractiveness of nodes ai < 0.5 and 1.0 − ai are identical, and a node’s mate in the mated pair is chosen independently of whether that node has an attractiveness of ai or 1.0 − ai.
When β > 0, the radial symmetry is broken, but all distributions have bilateral symmetry because of the statistical equivalence sets A and B possess. The distributions show presence of assertive mating, and the most frequent pairings are between two highly attractive nodes. This is a consequence of the underlying evolution of the attractiveness to a higher mean which grows with increasing β.
We briefly note that increasing G, which increases the variance of the offspring-trait distribution for any mated pair  , increases the dispersion of the bivariate distribution of mated pairs (Figure S3).
, increases the dispersion of the bivariate distribution of mated pairs (Figure S3).
Iterating the selective pair formation process and subsequent reproduction will drive the population to statistical equilibrium; that is, Rg → 0 as g → ∞. At or near equilibrium, the expected increase in mean attractiveness per generation balances the decrease due to the negative skew in the offspring-production distribution f(x|μ, σ).
Figure 7 shows a temporal series of univariate attractiveness distributions for several different selectivity values. Mean attractiveness increases with β; recall Fig. 6. The variance of the distribution appears independent of selectivity, since dispersion depends strongly on G.

Sampled probability density P(a) for a node to have attractiveness a. P(a) is sampled only from the set A of nodes (because A and B are statistically equivalent) for each generation then binned with a bin size of 0.001. The distribution is then averaged over twenty realizations. (a) β = 0. (b) β = 1. (c) β = 4. All distributions correspond to  and G = 1.
and G = 1.
To find the long-term behavior, we look at 100 generations for various parameter values. The mean and variance of these distributions can be seen in Figure S5. Both metrics reach a statistical equilibrium after a sufficient number of generations.
Offspring Number of Matches
The number of matches is examined as a function of generation. Figure S4 shows an interesting decline in the number of matches. Because all other factors known to change the number of matches are constant, this indicates that the number of matches is dependent on the attractiveness distribution of the population.
This can be caused by the input distributions for the matching process approaching a similar value. As mentioned above, selectivity can also mathematically be thought as modifying the input distribution for the matching process. For β = 0, the input distribution is a singularity at one, which corresponds to all individuals possessing the same attractiveness. For later generations, the distributions are narrowing. This approach to distributions where all nodes possess the same attractiveness is likely causing this decrease, as there are too few low degree, high attractiveness nodes to increase the number of matches.
Discussion
Our initial focus is on variation in assortative mating with respect to attractiveness. Increasing either the encounter network’s mean degree or pair formation selectivity increases assortment across mated pairs. In agreement with these intuitive results, we find that the earliest and most frequent mated pairs involve two highly attractive individuals.
Our results indicate that increasing mean degree increases the number of mated pairs formed within a generation. Counter-intuitively, we find that increased selectivity increases the number of mated pairs. Hence, fewer individuals are excluded from reproduction when the pair formation dynamics exhibit greater selectivity. The latter effect is associated, statistically, with nodes of low degree.
With selectivity fully analyzed, we focus on the evolution of mean attractiveness under assortative mating. Selection mediated by exclusion from breeding can increase mean attractiveness. Reproductive variance led to production of enough moderate phenotypes to balance any selective advantage of high attractiveness. For β < 1 (weak selectivity) evolution over several generations reduced assortative mating. However, for β > 1 (strong selectivity) the evolving population retained positive assortment by attractiveness.
Additional Information
How to cite this article: Dipple, S. et al. Assortative Mating: Encounter-Network Topology and the Evolution of Attractiveness. Sci. Rep. 7, 45107; doi: 10.1038/srep45107 (2017).
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
Jiang, Y., Bolnick, D. I. & Kirkpatrick, M. Assortative Mating in Animals. The American Naturalist 181 (2013).
Alpern, S. & Reyniers, D. Strategic Mating with Homotypic Preferences. Journal of Theoretical Biology 198, 71–88 (1999).
Shine, R., O’connor, D., Lemaster, M. & Mason, R. Pick on someone your own size: ontogenetic shifts in mate choice by male garter snakes result in size-assortative mating. Animal Behaviour 61, 1133–1141 (2001).
Janetos, A. C. Strategies of female mate choice: A theoretical analysis. Behavioral Ecology and Sociobiology 7, 107–112 (1980).
Berscheid, E., Dion, K., Walster, E. & Walster, G. Physical attractiveness and dating choice: A test of the matching hypothesis. Journal of Experimental Social Psychology 7, 173–189 (1971).
Zietsch, B. P., Verweij, K. J. H., Heath, A. C. & Martin, N. G. Variation in Human Mate Choice: Simultaneously Investigating Heritability, Parental Influence, Sexual Imprinting, and Assortative Mating. The American Naturalist 177, 605–616 (2011).
Orr, H. A., Masly, J. P. & Presgraves, D. C. Speciation genes. Current Opinion in Genetics & Development 14, 675–679 (2004).
Lynch, M. & Walsh, B. Genetics and Analysis of Quantitative Traits. Sinauer Press. Genetical Research 72, 73–75 (1998).
Bolnick, D. I. & Kirkpatrick, M. The relationship between intraspecific assortative mating and reproductive isolation between divergent populations. Current Zoology 58, 484–492 (2012).
Kalick, S. M. & Hamilton, T. E. The matching hypothesis reexamined. Journal of Personality and Social Psychology 51, 673–682 (1986).
Kondrashov, A. S. & Shpak, M. On the origin of species by means of assortative mating. Proceedings of the Royal Society B: Biological Sciences 265, 2273–2278 (1998).
Mcpherson, M., Smith-Lovin, L. & Cook, J. M. Birds of a Feather: Homophily in Social Networks. Annual Review of Sociology 27, 415–444 (2001).
Bearhop, S. et al. Assortative Mating as a Mechanism for Rapid Evolution of a Migratory Divide. Science 310, 502–504 (2005).
Zhou, B., He, Z., Jiang, L.-L., Wang, N.-X. & Wang, B.-H. Bidirectional selection between two classes in complex social networks. Scientific Reports 4, 7577 (2014).
Jia, T., Spivey, R. F., Szymanski, B. & Korniss, G. An Analysis of the Matching Hypothesis in Networks. Plos One 10 (2015).
Coviello, L., Franceschetti, M., Mccubbins, M. D., Paturi, R. & Vattani, A. Human Matching Behavior in Social Networks: An Algorithmic Perspective. Plos One 7 (2012).
Barabási, A. Emergence of Scaling in Random Networks. Science 286, 509–512 (1999).
Watts, D. J. & Strogatz, S. H. Collective dynamics of ‘small-world’ networks. Nature 393, 440–442 (1998).
Jia, T. & Kulkarni, R. V. On the structural properties of small-world networks with range-limited shortcut links. Physica A: Statistical Mechanics and its Applications 392, 6118–6124 (2013).
Singh, P., Sreenivasan, S., Szymanski, B. K. & Korniss, G. Threshold-limited spreading in social networks with multiple initiators. Scientific Reports 3 (2013).
Karampourniotis, P. D., Sreenivasan, S., Szymanski, B. K. & Korniss, G. The Impact of Heterogeneous Thresholds on Social Contagion with Multiple Initiators. Plos One 10 (2015).
Erdös, P. & Rényi, A. On random graphs. Publ. Math. Debrecen 6, 290–297 (1959).
Erdös, P. & Rényi, A. On the evolution of random graphs. Publ. Math. Inst. Hung. Acad. Sci. 5, 17 (1960).
Albert R. & Barabási A. Statistical mechanics of complex networks. Rev. Mod. Phys. 74, 47 (2002).
Bortz, A., Kalos, M. & Lebowitz, J. A new algorithm for Monte Carlo simulation of Ising spin systems. Journal of Computational Physics 17, 10–18 (1975).
Gillespie, D. T. A general method for numerically simulating the stochastic time evolution of coupled chemical reactions. Journal of Computational Physics 22, 403–434 (1976).
Gilmer, G. Growth on imperfect crystal faces. Journal of Crystal Growth 36, 15–28 (1976).
Slatkin, M. & Lande, R. Niche Width in a Fluctuating Environment-Density Independent Model. The American Naturalist 110, 31–55 (1976).
Springer, M. D. The algebra of random variables(Wiley, 1979).
Acknowledgements
This research was supported in part by the Office of Naval Research Grant No. N00014-15-1-2640, and the Army Research Laboratory under Cooperative Agreement Number W911NF-09-2-0053 (the ARL Network Science CTA). T.J. is also supported by the Natural Science Foundation of China (No. 61603309) and CCF-Tencent RAGR (No. 20160107). B.K. Szymanski is also supported by the European Commission under the 7th Framework Programme, Agreement Number 316097, and by the Polish National Science Centre, the decision no. DEC-2013/09/B/ST6/02317. The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the Army Research Laboratory or the US Government.
Author information
Authors and Affiliations
Contributions
B.K.S. conceived the research; S.D., T.J., T.C., G.K., and B.K.S. designed the research; S.D. and T.J. implemented and performed numerical experiments and simulations; S.D., T.J., T.C., G.K., and B.K.S. analyzed data and discussed results; S.D., T.J., T.C., G.K., and B.K.S. wrote, reviewed, and revised the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Supplementary information
Rights and permissions
This work is licensed under a Creative Commons Attribution 4.0 International License. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in the credit line; if the material is not included under the Creative Commons license, users will need to obtain permission from the license holder to reproduce the material. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/
About this article

Cite this article
Dipple, S., Jia, T., Caraco, T. et al. Assortative Mating: Encounter-Network Topology and the Evolution of Attractiveness. Sci Rep 7, 45107 (2017). https://doi.org/10.1038/srep45107
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/srep45107
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
