
Abstract
A practical approach to protecting networks against epidemic processes such as spreading of infectious diseases, malware, and harmful viral information is to remove some influential nodes beforehand to fragment the network into small components. Because determining the optimal order to remove nodes is a computationally hard problem, various approximate algorithms have been proposed to efficiently fragment networks by sequential node removal. Morone and Makse proposed an algorithm employing the non-backtracking matrix of given networks, which outperforms various existing algorithms. In fact, many empirical networks have community structure, compromising the assumption of local tree-like structure on which the original algorithm is based. We develop an immunization algorithm by synergistically combining the Morone-Makse algorithm and coarse graining of the network in which we regard a community as a supernode. In this way, we aim to identify nodes that connect different communities at a reasonable computational cost. The proposed algorithm works more efficiently than the Morone-Makse and other algorithms on networks with community structure.
Similar content being viewed by others

Introduction
Identification of influential nodes in a network is a topic of interest in network analysis, enjoying numerous applications. For example, a removal or immunization of an influential node may suppress spreading of an infectious disease that may occur later. A viral information spreading campaign starting from an influential node may be more successful than a campaign starting from other nodes. There are various notions of influential nodes, as evinced by a multitude of definitions of node’s centrality corresponding to the aforementioned and other applications1. Among them, a major criterion of the influential node is that the removal of a node, or immunization, efficiently fragments the network into small pieces. Because the problem of finding the minimal set of nodes to be immunized to fragment the network is NP-hard2, various immunization algorithms to determine the order of the nodes to be removed to realize efficient fragmentation of the network have been proposed2,3,4,5,6,7,8,9,10,11,12, sometimes with the constraint that the information about the network is only partially available6,13,14,15,16,17. Notably, although immunizing hubs (i.e., nodes with a large degree) first is intuitive and much better than randomly selecting nodes to be immunized18,19,20, many immunization algorithms outperform the hub-first immunization algorithm.
Morone and Makse proposed a scalable and powerful algorithm to sequentially remove nodes and fragment the network into small components as early as possible9. Founded on the message passing approach and theory of non-backtracking matrices, the method calculates the so-called collective influence (CI) for each node to rank the nodes for prioritization. Their method, which is referred to as the CI algorithm, outperforms various other known methods in model and empirical networks. In the present study, we propose a new CI-based immunization algorithm that is designed to perform well when the network has community structure.
The CI algorithm assumes that the given network is locally tree-like. In fact, a majority of empirical networks are not locally tree-like. At a microscopic level, empirical networks are usually clustered, i.e., full of triangles1. At a mesoscopic level, many networks are composed of communities such that links are dense within communities and sparse across different communities21. Although the CI algorithm also seems to work efficiently in loopy networks unless loops are not excessive9, the performance of the CI algorithm on networks with community structure is unclear. Some extant immunization algorithms are explicitly or implicitly informed by community structure4,5,6,10,15,16,22,23. The immunization algorithms using the betweenness centrality are effective on networks with community structure6,7,16,22,23. However, they are not scalable due to a high computational cost of calculating the betweenness centrality24. For other immunization algorithms exploiting community structure of networks, their performance relative to the CI algorithm is unknown in general5,10 or at least for networks with community structure4,9. Yet other community-based immunization algorithms impose that only local information about the network is available, mimicking realistic constraints6,15,16. This constraint naturally limits the performance of an immunization algorithm.
We develop an immunization algorithm by formulating a CI algorithm for a coarse-grained network, in which a node represents a community, and a weighted link represents the number of links between different communities. We compare the performance of the proposed algorithm with that of the CI algorithm9, and the conventional algorithm targeting hubs18,19,20, and others5,10 when networks have community structure.
Theory
Consider an undirected and unweighted network having N nodes. The aim of an immunization algorithm is to sequentially remove nodes to fragment the network as soon as possible, i.e., with a small number of removed nodes.
Collective influence
The CI algorithm is based on the scoring of nodes according to the CI value9. The CI of node i is defined as

where

ki is the degree of node i, and  is the set of nodes at distance
is the set of nodes at distance  from node i. When
from node i. When  , the CI is equivalent to the degree as long as the rank order is concerned.
, the CI is equivalent to the degree as long as the rank order is concerned.
The CI algorithm calculates the  value of all nodes and removes the node with the largest CI value in one step. Then, the CI values of all the remaining nodes are recalculated, and the same procedure is repeated.
value of all nodes and removes the node with the largest CI value in one step. Then, the CI values of all the remaining nodes are recalculated, and the same procedure is repeated.
In fact, we use the order of nodes to be removed determined above as a tentative order. To improve the overall performance, we reorder the nodes by reinserting them as follows. We start from the situation in which the fraction of nodes in the largest connected component (LCC) is equal to or less than 0.01 for the first time. Then, we calculate for each removed node i the number of components that node i connects if it is reinserted in the current network. Next, we add back the node that connects the smallest number of connected components. We repeat this procedure until all the removed nodes are reinserted such that the initial network is restored.
The computation time of the CI algorithm is evaluated as follows9. The calculation of  requires O(1) time for one node, and hence O(N) time for all nodes. Because sorting the
requires O(1) time for one node, and hence O(N) time for all nodes. Because sorting the  values consumes O(N logN) time, each step of the CI algorithm consumes O(N logN) time. Therefore, the total computation time until O(N) nodes are removed is evaluated as O(N2 logN). However, by exploiting the fact that the CI values of only O(1) nodes are affected by the removal of a single node, one can accelerate the same algorithm with a max-heap data structure, yielding O(N logN) total computation time25.
values consumes O(N logN) time, each step of the CI algorithm consumes O(N logN) time. Therefore, the total computation time until O(N) nodes are removed is evaluated as O(N2 logN). However, by exploiting the fact that the CI values of only O(1) nodes are affected by the removal of a single node, one can accelerate the same algorithm with a max-heap data structure, yielding O(N logN) total computation time25.
Community-based collective influence
Community structure may make a network not locally tree-like. We propose an immunization algorithm by running a weighted-network variant of the CI algorithm on a coarse-grained network in which a community constitutes a supernode. We first run a community detection algorithm. Denote by NC the number of communities and by  the NC × NC coarse-grained weighted adjacency matrix whose (I, J) element is equal to the number of links that connect communities I and J (I ≠ J). We use lowercases (e.g., i, j) to denote individual nodes and uppercases (e.g., I, J) to denote supernodes, i.e., communities, throughout the text. The diagonal elements of
the NC × NC coarse-grained weighted adjacency matrix whose (I, J) element is equal to the number of links that connect communities I and J (I ≠ J). We use lowercases (e.g., i, j) to denote individual nodes and uppercases (e.g., I, J) to denote supernodes, i.e., communities, throughout the text. The diagonal elements of  are set to zero.
are set to zero.
Assume that the coarse-grained network is locally tree-like. By taking into account the fact that the coarse-grained network is generally a weighted network, we define the CI of community I in the coarse-grained network by

where  Ball
Ball  denotes the set of the communities whose distance from community I is equal to
denotes the set of the communities whose distance from community I is equal to  in the coarse-grained network.
in the coarse-grained network.
We set

This definition is analogous to zi ≡ ki − 1 in Eq. (1). With this definition of  , the CI of community I is equal to zero when I has only one neighbor, as in the original CI9,26.
, the CI of community I is equal to zero when I has only one neighbor, as in the original CI9,26.
We set

where J is a community that is at distance  from I, and J− is the community that is at distance
from I, and J− is the community that is at distance  from I and on the path between I and J (Fig. 1(a)). It should be noted that
from I and on the path between I and J (Fig. 1(a)). It should be noted that  is equal to zero if J− is the only neighbor of J. It should also be noted that, when every community consists of only one node in the original network,
is equal to zero if J− is the only neighbor of J. It should also be noted that, when every community consists of only one node in the original network,  for 1 ≤ i ≤ N. Equation (5) is ill-defined for
for 1 ≤ i ≤ N. Equation (5) is ill-defined for  . To be consistent with the original definition of the CI, we define
. To be consistent with the original definition of the CI, we define  for
for  . Then,
. Then,  is large when node I has a large degree in the coarse-grained network.
is large when node I has a large degree in the coarse-grained network.

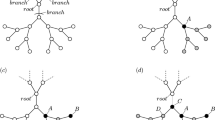
Concept of the community-based collective influence.
(a) Egocentric view of the coarse-grained network. Each circle represents a community. Two communities are adjacent by a weighted link if a node in one community is connected to at least one node in the other community. The link weight in the coarse-grained network is equal to the number of links that connect the two communities in the original network. Local tree-like structure of the coarse-grained network is assumed. (b) Illustration of  and
and  for
for  , in which case I+ = J−. A line represents a link in the original network. The dashed circle represents the Ith community. (c) Schematic of community-based reinsertion. A dashed circle represents a community. Suppose that we will reinsert either node i or j. If reinserted, node i and j would have a path to two and three communities, respectively. Therefore, we reinsert node i.
, in which case I+ = J−. A line represents a link in the original network. The dashed circle represents the Ith community. (c) Schematic of community-based reinsertion. A dashed circle represents a community. Suppose that we will reinsert either node i or j. If reinserted, node i and j would have a path to two and three communities, respectively. Therefore, we reinsert node i.
Let A = (Aij) be the adjacency matrix of the original network. Equation (3) is rewritten as

where I+ is the community adjacent to I (hence distance one from I) through which J is reached from I (Fig. 1(b)). On the basis of Eq. (6), we define the community-based collective influence (CbCI) of node i, denoted by CbCI(i), as

where node i belongs to community I. In Eq. (7), the importance of a node stems from three factors. First, CbCI(i) is proportional to  , which is essentially the number of inter-community links of the community to which i belongs. Second, CbCI(i) is large if I has many high-degree nodes at distance
, which is essentially the number of inter-community links of the community to which i belongs. Second, CbCI(i) is large if I has many high-degree nodes at distance  in the coarse-grained network (i.e., sum of
in the coarse-grained network (i.e., sum of  ). Third, CbCI(i) is large if node i has many inter-community links relative to the total number of inter-community links that community I has (i.e.,
). Third, CbCI(i) is large if node i has many inter-community links relative to the total number of inter-community links that community I has (i.e.,  ). We set
). We set  in the following numerical simulations. When
in the following numerical simulations. When  , I+ in Eqs (6) and (7) coincide with J− in Eq. (5) (Fig. 1(b)).
, I+ in Eqs (6) and (7) coincide with J− in Eq. (5) (Fig. 1(b)).
We remove the node with the largest CbCI value. If there are multiple nodes with the same largest CbCI value, we select the node having the largest degree. If there are multiple nodes with the same largest CbCI and degree, we break the tie at random. Then, we recalculate the CbCI for all remaining nodes, remove the node with the largest CbCI, and repeat the same procedure until the size of the LCC becomes equal to or less than 0.01N. We further optimize the obtained order of node removal by reinsertion, as in the CI algorithm. We use the coarse-grained network, not the original network, to inform the reinsertion process in the CbCI algorithm. In other words, the number of communities that belong to the same component as the reinserted node is measured for each tentatively reinserted node. We decide to reinsert the node whose presence connects the least number of communities (Fig. 1(c)).
Given a partitioning of the network into communities, the calculation of CbCI(i) for one node consumes O(1) time. Therefore, if we adapt the original implementation of the CI algorithm9 to the case of the CbCI, sorting of CbCI(i) dominates the computation time of the CbCI algorithm. The time complexity of the CbCI algorithm is the same as that of the CI algorithm in ref. 9, i.e., O(N2 logN), if community detection is not a bottleneck. The use of the max-heap data structure makes the CbCI algorithm run in O(N logN) time if NC = O(N) such that the CbCI values of O(1) nodes are affected by the removal of a single node. Generally speaking, the CbCI algorithm with the max-heap data structure runs in O(N logN) × O(N/NC) = O((N2/NC)logN) time.
We use the following six algorithms for community detection: (i) Infomap27,28, requiring O(M) time21, where M is the number of links, and hence O(N) time for sparse networks; (ii) Walktrap, which requires O(N2 logN) for most empirical networks29; (iii) the label-propagation algorithm, requiring nearly linear time in N ref. 30; (iv) a fast greedy algorithm for modularity maximization, requiring O(N(logN)2) time for sparse networks31; (v) modularity maximization based on simulated annealing, which is practical up to ≈104 nodes in the original paper32 and time-consuming because modularity must be maximized in a parameter-dependent manner33; (vi) the Louvain algorithm, which practically runs in O(N) time34. The last three algorithms intend to maximize the modularity, denoted by Q. The first three algorithms detect communities according to different criteria.
Except for the simulated annealing algorithm, the computational cost is at most that for the CbCI algorithm given the partitioning of the network, i.e., O(N2 logN). Therefore, if the CbCI algorithm is naively implemented, community detection is not a bottleneck in terms of the computation time when any of these five community detection algorithms is used. If NC = O(N) and we implement the CbCI algorithm using the max-heap data structure, a community detection algorithm requiring more than O(N logN) time presents a bottleneck. In this case, the Infomap when the network is sparse (i.e., M = O(N)), label-propagation algorithm, and Louvain algorithm retain O(N logN) total computation time of the CbCI algorithm. The total computation time with any of the other three community detection algorithms is governed by that of the community detection algorithm.
Results
In this section, we compare the performance of the CbCI algorithm with the CI and other immunization algorithms (see Methods) on two model networks and 12 empirical networks. Let q be the fraction of removed nodes. The size of the LCC after qN nodes have been removed, divided by N, is denoted by G(q).
Scale-free network models with and without community structure
We start by testing various immunization algorithms on a scale-free network model with built-in community structure (Methods). We sequentially remove nodes from this network according to each immunization algorithm and track the size of the LCC. We use the community structure imposed by the model to inform the CbCI and CbDI algorithms. The results for a range of immunization algorithms are shown in Fig. 2(a). Both CbCI and CbDI algorithms considerably outperform the CI algorithm. The CbCI algorithm performs better than the CbDI algorithm. The performance of the CbCI algorithm is close to the Betweenness algorithm. It should be noted that the Betweenness algorithm, while efficient, is not scalable to larger networks.

Normalized size of the LCC, G(q), plotted against the fraction of removed nodes, q, in model networks with N = 5000.
A curve corresponds to an immunization algorithm. See Methods for the abbreviations. (a) Scale-free network with prescribed community structure. (b) BA model.
Next, we consider a scale-free network without community structure, which is generated by the original BA model with N = 5000 and 〈k〉 ≈ 12 (the parameters of the model are equal to m0 = m = 6). We run the CbCI and CbDI strategies by applying a community detection algorithm to the generated network although the BA model lacks community structure. In fact, all but the label-propagation algorithm returns a partitioning result. The performance of the different immunization algorithms for this network is compared in Fig. 2(b). The CbCI algorithm combined with Infomap or Walktrap outperforms the Degree and LSP algorithms. The performance of the CbCI algorithm is close to that of the CI algorithm except in an early stage of node removal. A different community-based immunization algorithm, CbDI, lacks this feature. This result suggests that the CbCI algorithm combined with Infomap or Walktrap can work efficiently even when the network does not have community structure.
The results for the CbCI and CbDI algorithms combined with the other four community detection algorithms are shown in Fig. S2(a). The figure suggests that the CbCI algorithm combined with Infomap or Walktrap performs better than when it is combined with a different community detection algorithm.
Empirical networks
In this section, we run the CbCI and other algorithms on the following 12 empirical networks with community structure. (i) Two networks of Autonomous Systems of the Internet constructed by the University of Oregon Route Views project35,36,37: A node is an Autonomous System. The network collected on 2 January 2000 and that on 31 March 2001 are referred to as AS-1 and AS-2, respectively. (ii) Pretty Good Privacy network (PGP)38: Two persons are connected by a link if they share confidential information using the PGP encryption algorithm on the Internet. (iii) World Wide Web (WWW)39: A network of websites connected by hyperlinks, which is originally a directed network. (iv) Email-based communication network at Kiel University (referred to as email-uni)40: E-mail sending activity among students, which provides a directed link, recorded over a period of 112 days. (v) Email-based communication network in Enron Corporation (email-Enron)36,41,42: Two e-mail users in the data set are connected by an unweighted directed link if at least one e-mail has been sent from one user to the other user. (vi) Collaboration networks in General Relativity and Quantum Cosmology (CA-GrQc), Astro Physics, (CA-Astroph), and Condensed Matter, (CA-Condmat) categories36,43 and High Energy Physics – Phenomenology (CA-HepPh) and High Energy Physics – Theory (CA-HepTh) categories in arXiv35,36. By definition, two authors are adjacent if they coauthor a paper. (vii) High-energy physics citation network within the hep-th category of arXiv (HEP)44, which is originally a directed network. For each network, we removed the link weight, self-loops, and direction of the link, and submitted the LCC to the following analysis. Summary statistics of these networks including the modularity, Q, are shown in Tables S1 and S2.
We do not investigate the Betweenness immunization algorithm due to its high computational cost (i.e., O(NM) time for calculating the betweenness centrality of all nodes24, hence O(N2M) time for removing O(N) nodes).
The performance of the different immunization algorithms is compared on two empirical networks in Fig. 3. Among the 12 empirical networks that we tested, these two networks yielded the smallest and largest modularity values as maximized by the Louvain algorithm. The figure indicates that the CbCI algorithm combined with Infomap or Walktrap performs better than the previously proposed algorithms including the CI algorithm in both networks. The CbCI algorithm performs better than the CI algorithm in many other empirical networks as well (Fig. S2(b)–(m)). Furthermore, the CbCI algorithm combined with a different community detection algorithm also outperforms the CI algorithm in most of the networks (Fig. S2(b)–(m)).

Normalized size of the LCC, G(q), plotted against the fraction of removed nodes, q, in two empirical networks.
(a) E-mail communication network in Enron. (b) World Wide Web.
To be quantitative, we measure the fraction of removed nodes at which the network fragments into sufficiently small connected components, i.e.,

where we remind that G(q) is the size of the LCC normalized by N. We set θ = 0.05. We calculate qc for each combination of a network and an immunization algorithm.
The value of qc for each immunization algorithm normalized by the qc value for the CI algorithm is plotted in Fig. 4. A symbol represents a network. A small normalized value of qc implies a high efficiency of the immunization algorithm. As expected, the Degree immunization algorithm performs worse than the CI in all the tested networks (Fig. 4(c)). For the CbCI algorithm combined with Infomap, qc is smaller by 15.0% to 49.7% than that for the CI algorithm (Fig. 4(a)). The CbCI algorithm combined with Walktrap shows a similar performance for all but one networks (Fig. 4(b)). The CbCI algorithm combined with three of the other four community detection algorithms performs better than the CI algorithm for networks with relatively strong community structure (Fig. S3). The CbDI algorithm combined with Infomap performs better than the CI algorithm for all networks, but to a lesser extent than the CbCI algorithm combined with Infomap does (Fig. 4(d)). The CbDI algorithm combined with Walktrap (Fig. 4(e)) and the other four community detection algorithms (Fig. S3) performs worse than the CI algorithm. The LSP algorithm performs worse than the CI algorithm in a majority of the networks (Fig. 4(f)).

The fraction of removed nodes to fragment the network, qc, for an immunization algorithm divided by the value for the CI algorithm.
(a) CbCI combined with Infomap. (b) CbCI combined with Walktrap. (c) High degree adaptive (Degree). (d) CbDI combined with Infomap. (e) CbDI combined with Walktrap. (f) Laplacian spectral partitioning (LSP). A symbol represents a network. The cross represents the model network used in Fig. 2(a). The modularity value, Q, is determined by the Louvain algorithm.
Even if two immunization algorithms yield the same qc value on the same network, G(q) may considerably drop at a smaller q value with one immunization algorithm than the other algorithm. To quantify the performance of immunization algorithms in this sense, we measure the size of the LCC integrated over q values7,45, i.e.,

It should be noted that  is the area under the curve when G(q) is plotted against q and ranges between 0 and 1/2. A small
is the area under the curve when G(q) is plotted against q and ranges between 0 and 1/2. A small  value implies a good performance of an immunization algorithm.
value implies a good performance of an immunization algorithm.
The value of  for each immunization algorithm normalized by that for the CI algorithm is plotted in Fig. 5. The CbCI algorithm combined with Infomap outperforms the CI algorithm in 11 out of the 12 networks in terms of
for each immunization algorithm normalized by that for the CI algorithm is plotted in Fig. 5. The CbCI algorithm combined with Infomap outperforms the CI algorithm in 11 out of the 12 networks in terms of  (Fig. 5(a)). Similarly, the CbCI algorithm combined with Walktrap outperforms the CI algorithm in ten out of the 12 networks (Fig. 5(b)). The CbCI combined with any of the other four community detection algorithms outperforms the CI algorithm in roughly half of the networks and tends to be efficient for networks having large modularity values as determined by the Louvain algorithm (Fig. S4). In particular, for the three networks with the largest modularity, the CbCI algorithm combined with any of the six community detection algorithms outperforms the CI algorithm. The Degree, CbDI, and LSP algorithms are less efficient than the CI algorithm in terms of
(Fig. 5(a)). Similarly, the CbCI algorithm combined with Walktrap outperforms the CI algorithm in ten out of the 12 networks (Fig. 5(b)). The CbCI combined with any of the other four community detection algorithms outperforms the CI algorithm in roughly half of the networks and tends to be efficient for networks having large modularity values as determined by the Louvain algorithm (Fig. S4). In particular, for the three networks with the largest modularity, the CbCI algorithm combined with any of the six community detection algorithms outperforms the CI algorithm. The Degree, CbDI, and LSP algorithms are less efficient than the CI algorithm in terms of  (Figs 5(c)–(f) and S4).
(Figs 5(c)–(f) and S4).

The  value normalized by that for the CI algorithm.
value normalized by that for the CI algorithm.
(a) CbCI combined with Infomap. (b) CbCI combined with Walktrap. (c) Degree. (d) CbDI combined with Infomap. (e) CbDI combined with Walktrap. (f) LSP. The Q value is determined by the Louvain algorithm.
Why do Infomap and Walktrap marry better with the CbCI algorithm than the other community detection algorithms?
We have shown that the CbCI algorithm is more efficient when it is combined with Infomap or Walktrap, in particular Infomap, than with the other four community detection algorithms. To explore why, we start by measuring the clustering coefficient46 of the unweighted version of the coarse-grained networks. We do so because in theory the CI assumes locally tree-like networks9,47. High clustering in the coarse-grained network may discourage the CbCI algorithm. For each empirical network, we measure the Pearson correlation coefficient between the clustering coefficient and qc normalized by the value for the CI algorithm. We use the result for each community detection algorithm as a data point such that the correlation coefficient is calculated on the basis of six data points. The results are shown in Table 1. We find that the clustering coefficient is not consistently correlated with the normalized qc. The results are qualitatively the same with a weighted clustering coefficient48,49 (Table 1). We obtain similar results if  instead of qc is used as a performance measure (Table 2). It should be noted that different community detection algorithms yield sufficiently different clustering coefficient values including large values (Fig. S5(a)). We conclude that the lack of local tree-like structure in the coarse-grained networks is not a strong determinant of the performance of the CbCI algorithm. This result does not contradict those for the original CI algorithm, which assumes local tree-like networks, because the CI algorithm is practically efficient on loopy networks as well9.
instead of qc is used as a performance measure (Table 2). It should be noted that different community detection algorithms yield sufficiently different clustering coefficient values including large values (Fig. S5(a)). We conclude that the lack of local tree-like structure in the coarse-grained networks is not a strong determinant of the performance of the CbCI algorithm. This result does not contradict those for the original CI algorithm, which assumes local tree-like networks, because the CI algorithm is practically efficient on loopy networks as well9.
 for each network.
for each network.We have set  , thus ignoring the contribution of nodes in coarse-grained networks three or more hops away from a focal node. In fact, large coarse-grained networks may have a large mean path length and deteriorate the performance of the CbCI algorithm. Therefore, we calculate the correlation coefficient between NC, i.e., the number of the detected communities, and qC, and between the mean path length in the unweighted coarse-grained network and qC (Table 1). The correlation efficient between
, thus ignoring the contribution of nodes in coarse-grained networks three or more hops away from a focal node. In fact, large coarse-grained networks may have a large mean path length and deteriorate the performance of the CbCI algorithm. Therefore, we calculate the correlation coefficient between NC, i.e., the number of the detected communities, and qC, and between the mean path length in the unweighted coarse-grained network and qC (Table 1). The correlation efficient between  and either NC or the mean path length is also measured (Table 2). The tables indicate that the performance of a community detection algorithm is not consistently correlated with the mean path length. It is correlated with NC, but in the manner such that the performance of the CbCI algorithm improves as NC increases, contrary to the aforementioned postulated mechanism. Therefore, the use of
and either NC or the mean path length is also measured (Table 2). The tables indicate that the performance of a community detection algorithm is not consistently correlated with the mean path length. It is correlated with NC, but in the manner such that the performance of the CbCI algorithm improves as NC increases, contrary to the aforementioned postulated mechanism. Therefore, the use of  does not probably explain the reason why a community detection algorithm marries the CbCI algorithm better than another.
does not probably explain the reason why a community detection algorithm marries the CbCI algorithm better than another.
In fact, the CbCI algorithm performs well when the detected communities have relatively similar sizes. To show this, we measure the entropy in the partitioning, which is defined by  , where
, where  is the number of nodes in the cth community. The entropy ranges between 0 and logNC. A large entropy value implies that the partitioning of the network is relatively egalitarian. The correlation coefficient between the entropy and the normalized qc is shown in Table 1 for each network. The entropy and qc are negatively correlated with each other for all networks and strongly so for most of the networks. This result is robust when we normalize the entropy by the largest possible value, i.e., logNC (Table 1), and when the performance measure is replaced by
is the number of nodes in the cth community. The entropy ranges between 0 and logNC. A large entropy value implies that the partitioning of the network is relatively egalitarian. The correlation coefficient between the entropy and the normalized qc is shown in Table 1 for each network. The entropy and qc are negatively correlated with each other for all networks and strongly so for most of the networks. This result is robust when we normalize the entropy by the largest possible value, i.e., logNC (Table 1), and when the performance measure is replaced by  (Table 2).
(Table 2).
To assess the robustness of this finding, we calculate the same correlation coefficient between either the unnormalized or normalized entropy and one of the two performance measures, but for each community detection algorithm. Now each empirical network constitutes a data point based on which the correlation coefficient is calculated. The correlation coefficient values are shown in Table 3. Although the correlation is weaker than in the previous case, the correlation between the entropy and either the normalized qC or  is largely negative, which is consistent with the results shown in Tables 1 and 2. The correlation coefficient between Q and each of the performance measure is also shown in Table 3. The entropy provides a weaker determinant of the performance as compared to Q, which is expected because the CbCI algorithm is designed for networks with community structure. Nevertheless, the entropy provides a larger (i.e., more negative) correlation value than Q does in some cases (Table 3).
is largely negative, which is consistent with the results shown in Tables 1 and 2. The correlation coefficient between Q and each of the performance measure is also shown in Table 3. The entropy provides a weaker determinant of the performance as compared to Q, which is expected because the CbCI algorithm is designed for networks with community structure. Nevertheless, the entropy provides a larger (i.e., more negative) correlation value than Q does in some cases (Table 3).
Infomap tends to detect a large number of communities (Table S2) whose size is less heterogeneously distributed than the case of the other community detection algorithms (Fig. S5(i) and (k)). We consider that this is a main reason why Infomap is effective when combined with the CbCI algorithm. Roughly speaking, the label-propagation algorithm tends to yield a similarly large number of communities, NC (Table S2). However, the size of the community is more heterogeneously distributed with the label-propagation algorithm than with Infomap, as quantified by the entropy measures (Fig. S5(i) and (k)).
Discussion
We showed that the CbCI immunization algorithm outperforms the CI and some other algorithms when a given network has community structure. The algorithm aims to pinpoint nodes that connect different communities at a reasonable computational cost. The CbCI algorithm is in particular efficient when Infomap27,28 is used for detecting communities beforehand. Infomap runs sufficiently fast at least for sparse networks21 such that the entire CbCI algorithm runs as fast as the CI algorithm at least asymptotically in terms of the network size. The Walktrap community detection algorithm29 is the second best among the six candidates to be combined with the CbCI algorithm in terms of the quality of immunization. However, Walktrap is slower than Infomap. Walktrap consumes longer time than the main part of the CbCI algorithm, i.e., sequential node removal, when the max-heap data structure is used for implementing the CbCI algorithm. In this case, the community detection before starting the node removal is the bottleneck of the entire CbCI algorithm, and the CbCI algorithm is slower than the CI algorithm. To our numerical efforts, we recommend Infomap to be combined with the CbCI algorithm.
We argued that Infomap works better in combination with the CbCI algorithm than the other community detection algorithms do mainly because Infomap yields a relatively egalitarian distribution of the community size. However, the distribution of the community size is usually skewed even with Infomap50. The CbCI algorithm may work even better if we use a community detection algorithm that imposes that the detected communities are of the equal or similar sizes. This problem is known as k-balanced partitioning, where k refers to the number of communities. Although k-balanced partitioning for general k is notoriously hard to solve, there are various approximate algorithms for this problem51,52,53. Combining these algorithms with the CbCI algorithm may be profitable.
We partitioned the network just once in the beginning of the CbCI algorithm and used the obtained community structure throughout the node removal procedure. This property is shared by the CbDI algorithm5 and another immunization algorithm11. We may be able to improve the performance of immunization by updating the community structure during the node removal. Our preliminary numerical simulations did not yield an improvement of the CbCI algorithm with online updating of community structure (section S1 in the SI). We should also bear in mind the computational cost of community detection, which would be repeatedly applied in the case of online updating. Nevertheless, this line of improvement may be worth investigating.
The CI assumes locally tree-like networks9. Although the CI algorithm is practically efficient in moderately loopy networks as well9, many empirical networks are abundant in triangles and short cycles such that they are highly loopy1. Dense connectivity within a community implies that there tend to be many triangles and short cycles in a network with community structure54,55. Then, coarse graining effectively coalesces many triangles and short cycles into one supernode, possibly suppressing their detrimental effects. At the same time, however, coarse-grained networks tend to have a large clustering coefficient (Fig. S5(a)). We may be able to improve the performance of the CbCI algorithm by suppressing the effect of short cycles in coarse-grained networks. Recently, a method has been proposed to improve the accuracy of estimating the percolation threshold using non-backtracking matrices, where redundant paths are suppressed in the counting of the paths47. This method applied to both CI and CbCI algorithms may enhance their performance in the immunization problem.
The recently proposed collective influence propagation (CIp) algorithm, which can be interpreted as the CI algorithm in the limit of  , generally yields better solutions than the CI algorithm does25. Given that we have not implemented the CIp algorithm in the present article, we are not arguing that the CbCI algorithm is better than the CIp algorithm. It should also be noted that we may be able to combine the CbCI algorithm with the idea of the CIp algorithm (i.e., using the leading left and right eigenvectors of the non-backtracking matrix) to devise a new algorithm.
, generally yields better solutions than the CI algorithm does25. Given that we have not implemented the CIp algorithm in the present article, we are not arguing that the CbCI algorithm is better than the CIp algorithm. It should also be noted that we may be able to combine the CbCI algorithm with the idea of the CIp algorithm (i.e., using the leading left and right eigenvectors of the non-backtracking matrix) to devise a new algorithm.
Methods
Immunization algorithms to be compared
We compare the performance of the CI and CbCI algorithms against the following immunization algorithms.
-
High degree adaptive (abbreviated as Degree)18,19,20: We sequentially remove the node having the largest degree. If multiple nodes have the largest degree, we break the tie by selecting one of the largest-degree nodes at random. We recalculate the degree after each node has been removed.
-
Community-based dynamical importance (CbDI)5: This method exploits the community structure of a network, similar to the CbCI algorithm, but calculates the importance of a community in the coarse-grained network in terms of the so-called dynamical importance3. The CbDI algorithm needs a community detection algorithm. We use each of the six community detection algorithms used in the CbCI algorithm.
The CbDI algorithm runs as follows5. We denote by
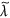 and
and 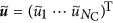 the largest eigenvalue and the corresponding eigenvector of
the largest eigenvalue and the corresponding eigenvector of  , respectively. Owing to the Perron-Frobenius theorem, it holds true that
, respectively. Owing to the Perron-Frobenius theorem, it holds true that 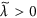 and
and 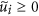 (1 ≤ i ≤ NC). The number of links between node i and the Jth community is denoted by kiJ ≡ ∑j∈communityJ Aij. We define
(1 ≤ i ≤ NC). The number of links between node i and the Jth community is denoted by kiJ ≡ ∑j∈communityJ Aij. We define  , where I is the community to which node i belongs. The CbDI of node i is defined by
, where I is the community to which node i belongs. The CbDI of node i is defined by 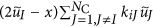 . We remove the nodes in descending order of the CbDI. If there are multiple nodes that have the same largest CbDI value, we break the tie by selecting the node that has the largest number of intra-community links. We recalculate the CbDI values of all the remaining nodes after removing each node. Once all the communities are disconnected, we sequentially remove the nodes in descending order of kiI. We recalculate kiI of all the remaining nodes after removing each node.
. We remove the nodes in descending order of the CbDI. If there are multiple nodes that have the same largest CbDI value, we break the tie by selecting the node that has the largest number of intra-community links. We recalculate the CbDI values of all the remaining nodes after removing each node. Once all the communities are disconnected, we sequentially remove the nodes in descending order of kiI. We recalculate kiI of all the remaining nodes after removing each node. -
The Laplacian spectral partitioning (LSP) algorithm runs as follows10:
-
1
For the largest connected component (LCC), calculate the Fiedler vector, i.e., the eigenvector associated with the smallest positive eigenvalue of the Laplacian, L ≡ DLCC − ALCC, where DLCC denotes the NLCC × NLCC diagonal matrix whose (i, i) element is equal to the degree of the ith node in the LCC, NLCC is the number of nodes in the LCC, and ALCC is the adjacency matrix of the LCC.
-
2
Partition the NLCC nodes into two non-empty groups by thresholding on the value of the element in the Fiedler vector. Group 1 (group 2) consists of the nodes whose corresponding element in the Fiedler vector is higher (lower) than a threshold. There are NLCC − 1 possible ways to bipartition the nodes.
-
3
Calculate
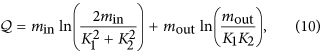
for each bipartition, where min and mout are the numbers of intra-group and inter-group links, respectively. K1 and K2 represent the sum of the nodes’ degrees in groups 1 and 2, respectively.
-
4
Find the partition that maximizes
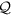 .
. -
5
Given the partition, remove the node that has the largest number of inter-group links. Then, recalculate the number of inter-group links for each remaining node. Repeat the node removal until the two groups are disconnected.
-
6
Repeat steps 1–5 until the size of the LCC becomes less than θN, where θ = 0.01.
-
1
-
High betweenness centrality adaptive (abbreviated as Betweenness)6,16,22,23: We remove the node with the largest betweenness centrality. If multiple nodes have the same largest betweenness centrality value, the node having the largest degree is removed. We recalculate the betweenness of all nodes every time we remove a node.
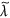 and
and 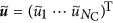 the largest eigenvalue and the corresponding eigenvector of
the largest eigenvalue and the corresponding eigenvector of  , respectively. Owing to the Perron-Frobenius theorem, it holds true that
, respectively. Owing to the Perron-Frobenius theorem, it holds true that 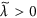 and
and 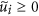 (1 ≤ i ≤ NC). The number of links between node i and the Jth community is denoted by kiJ ≡ ∑j
(1 ≤ i ≤ NC). The number of links between node i and the Jth community is denoted by kiJ ≡ ∑j , where I is the community to which node i belongs. The CbDI of node i is defined by
, where I is the community to which node i belongs. The CbDI of node i is defined by 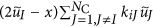 . We remove the nodes in descending order of the CbDI. If there are multiple nodes that have the same largest CbDI value, we break the tie by selecting the node that has the largest number of intra-community links. We recalculate the CbDI values of all the remaining nodes after removing each node. Once all the communities are disconnected, we sequentially remove the nodes in descending order of kiI. We recalculate kiI of all the remaining nodes after removing each node.
. We remove the nodes in descending order of the CbDI. If there are multiple nodes that have the same largest CbDI value, we break the tie by selecting the node that has the largest number of intra-community links. We recalculate the CbDI values of all the remaining nodes after removing each node. Once all the communities are disconnected, we sequentially remove the nodes in descending order of kiI. We recalculate kiI of all the remaining nodes after removing each node.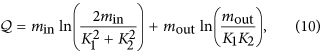
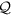 .
.We excluded the dynamical importance3 because it is less successful than the CI on various networks9 and than the CbDI on networks with community structure5. We also excluded the immunization algorithms on the basis of the PageRank, closeness centrality, and k-core, which had been shown to be outperformed by the CI algorithm9. This is because these algorithms do not particularly exploit community structure of the network such that there is no reason for believing that they would perform competitively on networks with community structure.
A scale-free network model with community structure
We constructed a scale-free network with built-in community structure as follows5. We first generate a coarse-grained network whose node is regarded as community, using the Barabási-Albert (BA) model56 having NC = 100 nodes and mean degree six. The initial network is the clique composed of m0 = 3 nodes, and each added node has m = 3 links. After generating a coarse-grained network, we assign 50 nodes to each community, resulting in N = 50 × NC = 5000 nodes in total. For each community, the intra-community network is given by the BA model with m0 = m = 4, which yields the mean within-community degree equal to  . Additionally, if communities I and J are adjacent in the coarse-grained network, then nodes i ∈ I and j ∈ J are connected with probability 〈k〉g/(6N/NC). This guarantees that a node is adjacent to 〈k〉g nodes in different communities on average. We set 〈k〉g = 1. The mean degree of the entire network is equal to
. Additionally, if communities I and J are adjacent in the coarse-grained network, then nodes i ∈ I and j ∈ J are connected with probability 〈k〉g/(6N/NC). This guarantees that a node is adjacent to 〈k〉g nodes in different communities on average. We set 〈k〉g = 1. The mean degree of the entire network is equal to  .
.
Additional Information
How to cite this article: Kobayashi, T. and Masuda, N. Fragmenting networks by targeting collective influencers at a mesoscopic level. Sci. Rep. 6, 37778; doi: 10.1038/srep37778 (2016).
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
Newman, M. E. J. Networks — An Introduction. Oxford University Press, Oxford (2010).
Altarelli, F., Braunstein, A., Dall’Asta, L., Wakeling, J. R. & Zecchina, R. Containing epidemic outbreaks by message-passing techniques. Phys. Rev. X 4, 021024 (2014).
Restrepo, J. G., Ott, E. & Hunt, B. R. Weighted percolation on directed networks. Phys. Rev. Lett. 100, 058701 (2008).
Chen, Y., Paul, G., Havlin, S., Liljeros, F. & Stanley, H. E. Finding a better immunization strategy. Phys. Rev. Lett. 101, 058701 (2008).
Masuda, N. Immunization of networks with community structure. New J. Phys. 11, 123018 (2009).
Salathé, M. & Jones, J. H. Dynamics and control of diseases in networks with community structure. PLOS Comput. Biol. 6, e1000736 (2010).
Schneider, C. M., Mihaljev, T., Havlin, S. & Herrmann, H. J. Suppressing epidemics with a limited amount of immunization units. Phys. Rev. E 84, 061911 (2011).
Zhao, D. et al. Immunization of epidemics in multiplex networks. PLOS ONE 9, e112018 (2014).
Morone, F. & Makse, H. A. Influence maximization in complex networks through optimal percolation. Nature 524, 65–68 (2015).
Zahedi, R. & Khansari, M. A new immunization algorithm based on spectral properties for complex networks. In The 7th Conference on Information and Knowledge Technology (IKT), 1–5 (2015).
Requião da Cunha, B., González-Avella, J. C. & Gonçalves, S. Fast fragmentation of networks using module-based attacks. PLOS ONE 10, e0142824 (2015).
Mugisha, S. & Zhou, H.-J. Identifying optimal targets of network attack by belief propagation. Phys. Rev. E 94, 012305 (2016).
Cohen, R., Havlin, S. & ben-Avraham, D. Efficient immunization strategies for computer networks and populations. Phys. Rev. Lett. 91, 247901 (2003).
Gallos, L. K., Liljeros, F., Argyrakis, P., Bunde, A. & Havlin, S. Improving immunization strategies. Phys. Rev. E 75, 045104(R) (2007).
Gong, K. et al. An efficient immunization strategy for community networks. PLOS ONE 8, e83489 (2013).
Hébert-Dufresne, L., Allard, A., Young, J.-G. & Dubé, L. J. Global efficiency of local immunization on complex networks. Sci. Rep. 3, 2171 (2013).
Liu, Y., Deng, Y. & Wei, B. Local immunization strategy based on the scores of nodes. Chaos 26, 013106 (2016).
Albert, R., Jeong, H. & Barabási, A.-L. Error and attack tolerance of complex networks. Nature 406, 378–382 (2000).
Callaway, D. S., Newman, M. E. J., Strogatz, S. H. & Watts, D. J. Network robustness and fragility: Percolation on random graphs. Phys. Rev. Lett. 85, 5468–5471 (2000).
Cohen, R., Erez, K., ben-Avraham, D. & Havlin, S. Breakdown of the internet under intentional attack. Phys. Rev. Lett. 86, 3682–3685 (2001).
Fortunato, S. Community detection in graphs. Phys. Rep. 486, 75–174 (2010).
Holme, P., Kim, B. J., Yoon, C. N. & Han, S. K. Attack vulnerability of complex networks. Phys Rev. E 65, 056109 (2002).
Ueno, T. & Masuda, N. Controlling nosocomial infection based on structure of hospital social networks. J. Theor. Biol. 254, 655–666 (2008).
Brandes, U. A faster algorithm for betweenness centrality. J. Math. Sociol. 25, 163–177 (2001).
Morone, F., Min, B., Bo, L., Mari, R. & Makse, H. A. Collective influence algorithm to find influencers via optimal percolation in massively large social media. Sci. Rep. 6, 30062 (2016).
Karrer, B., Newman, M. E. J. & Zdeborová, L. Percolation on sparse networks. Phys. Rev. Lett. 113, 208702 (2014).
Rosvall, M. & Bergstrom, C. T. Maps of random walks on complex networks reveal community structure. Proc. Natl. Acad. Sci. USA 105, 1118–1123 (2008).
Rosvall, M., Axelsson, D. & Bergstrom, C. T. The map equation. Eur. Phys. J. Spec. Top. 178, 13–23 (2010).
Pons, P. & Latapy, M. Computing communities in large networks using random walks. In Computer and Information Sciences-ISCIS 2005, Yolum, P., Güngör, T., Gürgen, F. & Özturan, C. editors, volume 3733 of Lecture Notes in Computer Science, 284–293. Springer Berlin Heidelberg (2005).
Raghavan, U. N., Albert, R. & Kumara, S. Near linear time algorithm to detect community structures in large-scale networks. Phys. Rev. E 76, 036106 (2007).
Clauset, A., Newman, M. E. J. & Moore, C. Finding community structure in very large networks. Phys. Rev. E 70, 066111 (2004).
Sales-Pardo, M., Guimerá, R., Moreira, A. A. & Amaral, L. A. N. Extracting the hierarchical organization of complex systems. Proc. Natl. Acad. Sci. USA 104, 15224–15229 (2007).
Lancichinetti, A. & Fortunato, S. Community detection algorithms: A comparative analysis. Phys. Rev. E 80, 056117 (2009).
Blondel, V. D., Guillaume, J.-L., Lambiotte, R. & Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. 2008, P10008 (2008).
Leskovec, J., Kleinberg, J. & Faloutsos, C. Graphs over time: densification laws, shrinking diameters and possible explanations. In Proceedings of the Eleventh ACM SIGKDD International Conference on Knowledge Discovery in Data Mining, 177–187. ACM (2005).
Jure, L. & Andrej, K. Stanford Network Analysis Project. http://snap.stanford.edu/. (Date of access: 19/01/2016).
University of Oregon Route Views Project. http://www.routeviews.org. (Date of access: 19/01/2016).
Boguñá, M., Pastor-Satorras, R., Díaz-Guilera, A. & Arenas, A. Models of social networks based on social distance attachment. Phys. Rev. E 70, 056122 (2004).
Albert, R., Jeong, H. & Barabási, A.-L. Internet: Diameter of the world-wide web. Nature 401, 130–131 (1999).
Ebel, H., Mielsch, L. I. & Bornholdt, S. Scale-free topology of e-mail networks. Phys. Rev. E 66, 035103(R) (2002).
Klimt, B. & Yang, Y. The enron corpus: A new dataset for email classification research. In Machine Learning: ECML 2004, 217–226, Springer (2004).
Leskovec, J., Lang, K. J., Dasgupta, A. & Mahoney, M. W. Community structure in large networks: Natural cluster sizes and the absence of large well-defined clusters. Internet Math. 6, 29–123 (2009).
Leskovec, J., Kleinberg, J. & Faloutsos, C. Graph evolution: Densification and shrinking diameters. ACM Trans. Knowl. Discov. Data 1, 2 (2007).
Batagelj, V. & Mrvar, A. Pajeck datasets (2006), http://vlado.fmf.uni-lj.si/pub/networks/data/. (Data of access: 19/01/2016).
Schneider, C. M., Moreira, A. A., Andrade, J. S., Havlin, S. & Herrmann, H. J. Mitigation of malicious attacks on networks. Proc. Natl. Acad. Sci. USA 108, 3838–3841 (2011).
Watts, D. J. & Strogatz, S. H. Collective dynamics of ‘small-world’ networks. Nature 393, 440–442 (1998).
Radicchi, F. & Castellano, C. Beyond the locally treelike approximation for percolation on real networks. Phys. Rev. E 93, 030302(R) (2016).
Onnela, J.-P., Saramäki, J., Kertész, J. & Kaski, K. Intensity and coherence of motifs in weighted complex networks. Phys. Rev. E 71, 065103 (2005).
Saramäki, J., Kivelä, M., Onnela, J.-P., Kaski, K. & Kertész, J. Generalizations of the clustering coefficient to weighted complex networks. Phys. Rev. E 75, 027105 (2007).
Lancichinetti, A., Kivelä, M., Saramäki, J. & Fortunato, S. Characterizing the community structure of complex networks. PLOS ONE 5, e11976 (2010).
Andreev, K. & Racke, H. Balanced graph partitioning. Theor. Comp. Sys. 39, 929–939 (2006).
Krauthgamer, R., Naor, J. S. & Schwartz, R. Partitioning graphs into balanced components. In Proceedings of the Twentieth Annual ACM-SIAM Symposium on Discrete Algorithms, SODA ‘09, 942–949 (2009).
Feldmann, A. E. & Foschini, L. Balanced partitions of trees and applications. Algorithmica 71, 354–376 (2015).
Radicchi, F., Castellano, C., Cecconi, F., Loreto, V. & Parisi, D. Defining and identifying communities in networks. Proc. Natl. Acad. Sci. USA 101, 2658–2663 (2004).
Palla, G., Derényi, I., Farkas, I. & Vicsek, T. Uncovering the overlapping community structure of complex networks in nature and society. Nature 435, 814–818 (2005).
Barabási, A.-L. & Albert, R. Emergence of scaling in random networks. Science 286, 509–512 (1999).
Acknowledgements
N.M. acknowledges the support provided through JST, CREST, and JST, ERATO, Kawarabayashi Large Graph Project. T.K. acknowledges financial support from the Japan Society for the Promotion of Science KAKENHI Grants no. 25780203, 15H01948, and 16K03551. We thank Flaviano Morone and Taro Takaguchi for providing codes for the CI algorithm.
Author information
Authors and Affiliations
Contributions
T.K. and N.M. conceived the research. T.K. conducted the analysis. T.K. and N.M. discussed the results and wrote the manuscript.
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Electronic supplementary material
Rights and permissions
This work is licensed under a Creative Commons Attribution 4.0 International License. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in the credit line; if the material is not included under the Creative Commons license, users will need to obtain permission from the license holder to reproduce the material. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/
About this article

Cite this article
Kobayashi, T., Masuda, N. Fragmenting networks by targeting collective influencers at a mesoscopic level. Sci Rep 6, 37778 (2016). https://doi.org/10.1038/srep37778
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/srep37778
This article is cited by
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
