
Abstract
Few risk tools have been proposed to quantify the long-term risk of diabetes among middle-aged and elderly individuals in China. The present study aimed to develop a risk tool to estimate the 20-year risk of developing diabetes while incorporating competing risks. A three-stage stratification random-clustering sampling procedure was conducted to ensure the representativeness of the Beijing elderly. We prospectively followed 1857 community residents aged 55 years and above who were free of diabetes at baseline examination. Sub-distribution hazards models were used to adjust for the competing risks of non-diabetes death. The cumulative incidence function of twenty-year diabetes event rates was 11.60% after adjusting for the competing risks of non-diabetes death. Age, body mass index, fasting plasma glucose, health status, and physical activity were selected to form the score. The area under the ROC curve (AUC) was 0.76 (95% Confidence Interval: 0.72–0.80), and the optimism-corrected AUC was 0.78 (95% Confidence Interval: 0.69–0.87) after internal validation by bootstrapping. The calibration plot showed that the actual diabetes risk was similar to the predicted risk. The cut-off value of the risk score was 19 points, marking mark the difference between low-risk and high-risk patients, which exhibited a sensitivity of 0.74 and specificity of 0.65.
Similar content being viewed by others


Introduction
Diabetes is a well-recognized cause of premature death and disability and is associated with an increased risk of kidney failure, cardiovascular disease, lower-limb amputation and blindness1. Diabetes was directly responsible for 1.5 million deaths and 89 million disability-adjusted life years in 2012. The prevalence of diabetes is increasing in all populations worldwide, and at a particularly accelerated rate in low- and middle-income countries2. China has had the largest absolute disease burden because of its large population base3. The financial costs of diabetes-related health expenditures also pose a substantial burden on the nation’s economy. Older adults are one of the fastest growing age groups both worldwide and in Beijing city4. By the end of 2008, the total population of Beijing had reached 12.3 million, with the number of people aged over 60, over 65, and over 80 years being 2.18, 1.62, and 0.29 million, representing 17.7%, 13.2%, and 2.4% of the total population, respectively5.
However, the test generally used to identify high-risk subjects, the 2-hour oral glucose tolerance test, is limited by its invasive and time-consuming nature and its relatively high costs6. Blood glucose has a large random variation and only provides information on a subject’s current glycemic state. In the past few years, researchers have been able to construct multivariable risk tools that are intended to aid clinicians in conducting risk assessments. The application of risk assessment tools to screen high-risk subjects based on demographic and anthropometric characteristics and simple laboratory tests is both feasible and economical7.
There are a number of risk assessment tools based on readily available clinical variables that predict the development of new diabetes cases, including ones proposed by the Framingham Offspring study8, Rancho Bemardo study9, and Guangzhou Biobank Cohort study10. The available tools have been derived from European7,8,11,12,13, American6,8,9,14, Australian15, Brazilian16, Africa17, and Asian10,18,19,20,21 populations. Differences in ethnicities, locations, and lifestyles partly limit the applicability of some of the effective risk scores to the Chinese population. Despite the large number of risk tools being developed, only a very small minority are designed for middle-aged and older Asian populations, Chinese populations in particular8,10. In addition, few diabetes risk prediction models included health status, despite the fact that some studies have confirmed that health status is an important diabetes predictor22. Furthermore, current diabetes risk prediction algorithms were developed for 10-year periods or less. The increasing life expectancy and elderly population suggest the need for longer-term risk assessment tools.
Additionally, conventional statistical methods that analyse time-to-event data assume an absence of competing risks23. However, competing risks must be explicitly considered explicitly in frail populations, especially among the elderly24. Ignoring the presence of competing risks can bias estimates of the incidence of the event of interest upwards24,25,26. Specifically, the sum of the estimates of each event type’s incidence will exceed the estimates of the incidence of the composite outcome, defined as any of the event types25. To overcome this problem, sub-distribution hazards models (e.g., Fine-Gray model) were proposed, in which the cumulative incidence function (CIF) is provided to estimate the incidence of an event while accounting for the presence of competing events25. Sub-distribution hazards models permit one to assess the association of predictors on the absolute risk of DM as well as to calculate the absolute risk of DM conditionally on those predictors. Sub-distribution hazards models are being increasingly applied to predict diseases26,27. However, to the best of our knowledge, no algorithm has been proposed that quantifies the 20-year risk of diabetes among middle-aged and elderly individuals using a sub-distribution hazards model.
In this report, we develop a risk tool for estimating the 20-year risk of developing diabetes among middle-aged and elderly individuals who are free of diabetes at baseline. Our risk estimates enable an adjustment for the competing risk of non-diabetes death, and simultaneously include lifestyle behaviours, psychological factors, cognitive function and physical conditions simultaneously. The tool is based on the Beijing Longitudinal Study on Ageing, which has contributed to the development of a 10-year risk score algorithm for coronary artery disease using a sub-distribution hazards model27, and offers 20 years of rigorous surveillance data for diabetes occurrence.
Results
Baseline Characteristics and Follow-up
We followed 1857 participants who did not have diabetes at baseline for a median 10.9 (Interquartile range: 8.0–15.3)-years period. The average age at baseline was 69.00 ± 8.81 years for women and 69.88 ± 8.55 years for men at baseline. At the end of year 2012, there were 144 documented cases of incident diabetes, and 919 deaths from non-diabetes. Approximately 4.7% of the participants were lost to -follow-up (n = 87). The incidence density of diabetes was 7.908/1000 person-years. The cumulative incidence function (CIF) of incident diabetes was 11.60% after adjusting for the competing risks of non-diabetes deaths. There were differences between the incident diabetes and non-diabetes groups in the baseline distribution of age, disability, marital status, self-assessment of health status, blood lipids, and physical exercise (P < 0.05) (Table 1). The baseline characteristics of the subjects based on non-diabetes and diabetes events for men and women at the baseline are also provided in Table 1. The sensitivity analysis showed that there were no statistically significance differences in the distribution of baseline characteristics between those lost to follow-up and those retained.
Diabetes Risk Prediction Model
Univariate analyses were used to regress the sub-distribution hazard of diabetes incidence on all twelve candidate variables, and the estimated regression coefficients, estimated regression sub-hazard ratios, estimated 95% confidence intervals, and the statistical significance of the estimated regression coefficients are reported in Table 2. After accounting for competing risk events in the risk set, standard diabetes risk factors (female gender, age, overweight/obesity, IFG, poor self-assessment of health, divorced or single, and high blood lipids) were significant in the univariate analysis (P < 0.05). Then, all significant variables in the univariate analyses were entered into the multivariate prediction model; five variables were retained after backward selection (Table 2). In the multivariate prediction model, after all adjustments, a greater risk of diabetes incidence was associated with impaired FPG (SHR = 1.99, 95% CI = 1.37–2.90), poor self-assessment of health (SHR = 1.73, 95% CI = 1.19–2.51), overweight (SHR = 2.15, 95% CI = 1.44–3.21) or obesity (SHR = 1.96, 95% CI = 1.27–3.03), and less physical activity (SHR = 1.39, 95% CI = 1.01–1.91). The bootstrap-adjusted regression coefficients, SHR and score of the sub-distribution hazards model are presented in Table 3.
Calibration, Discrimination, Reclassification, and Internal Validation
The calibration plot of the sub-distribution hazards model showed good calibration (Hosmer-Lemeshow test, chi-square = 4.544, P value = 0.805), and the actual diabetes risk in the BLSA cohort was similar to the predicted risk (Fig. 1). The sub-distribution hazards model performed better in terms of discrimination and calibration than Cox proportional hazards model. The area under the ROC curve (AUC) value were 0.76 (95% CI: 0.72–0.80) and 0.73 (95% CI: 0.69–0.77) for the sub-distribution hazards model and Cox proportional hazards model, respectively (Fig. 2). The AUC values of the sub-distribution hazards model were better than those of the Cox proportional hazard model at t = 20 years (Z = 4.30, P = 0.00002). The difference value of AUCs between sub-distribution and Cox proportional hazard models were more than zero (P = 0.307) (Fig. 3). After internal validation by bootstrapping, the optimism-corrected AUC of the sub-distribution hazards model at t = 20 years was 0.78 (95% CI: 0.69–0.87), and the optimism-corrected AUC of the Cox proportional hazard model at t = 20 years were 0.74 (95% CI: 0.65–0.84), suggesting a well-validated model.

Calibration plots by deciles for diabetes prediction models of 20-year risk, adjusted for the competing risk of non-d1iabetes death: (a) the bar plot; (b) the line plot.

ROC curves for diabetes risk prediction model.

Differences curves of AUCs for 2 diabetes risk prediction models.
Additional value of self-rated health
The additional variable self-rated health was assessed by the paired difference of risk scores. The empirical distribution function of the change in estimated risk scores for subjects who had events (thick solid line) and those who were event-free (thin solid line) was assessed (Fig. 4). The difference between the areas under the two curves is IDI, and the distances between the two black dots and between the two grey dots represent the continuous NRI and median improvement, respectively. The estimations of IDI and NRI were 0.019 (95% CI: 0.002–0.054; P = 0.024) and 0.124 (95% CI: 0.032–0.236; P = 0.028), respectively, at t = 20 years. The median increment in the risk score after including self-rated health status in the prediction model was −0.002 (95% CI: −0.008–0.005; P = 0.351) at t = 20 years.

The additional value of self-assessment of health as assessed by the paired difference of risk scores at t = 20 years.
Diabetes Risk Score Tool
Finally, we developed a simple risk score tool to estimate the 20-year diabetes risk for each individual using the baseline cumulative incidence function and the bootstrap-adjusted regression coefficients of the sub-distribution hazards model (Table 4). The score ranges from −4 to 38, and is positively related to the predicted risk of developing diabetes by linear regression (P for trend < 0.001). The competing-risk-based score exhibited a reasonable sensitivity of 0.74 and specificity of 0.65, with an optimal cut-off value of 19 marking the difference between low-risk and high-risk patients at t = 20 years.
Discussion
Using a community-based sample with a 20-year follow-up, we have constructed a multivariable risk factor algorithm applying a competing risk model that can be used to predict an individual’s risk and provides a helpful guide to identifying the groups at high risk for diabetes among adults over 55 years of age. To the best of our knowledge, this is the first community-based diabetes prediction model considering competing risk to be developed for an elderly population in China.
In terms of discrimination and calibration, the competing risk model is superior to Cox proportional hazard model. The competing risk analysis and Cox proportional hazard model may show no relevant differences when the mortality rate is low. From a statistical perspective, these models are not comparable, as they model different endpoints (cumulative incidence versus cause specific hazard). The present study extends and expands on the previous general diabetes risk models by adding a new risk factor, and the prediction model including self-rated health status was superior to the model without it. A user-friendly risk score tool predicting the 20-year probability of diabetes was developed.
Currently, the Finnish Diabetes Risk Score (FINDRISK)7, Framingham DM risk score8, Cambridge Diabetes Risk Score11, and German Diabetes Risk score13 are the most widely used scores in clinical guidelines. In addition, there are a number of other important risk algorithms or functions28. However, a prediction model specifically designed for the risk of incident diabetes in the Chinese elderly population is not currently available, especially one considering the competing risk. Our risk prediction model provided a feasible tool for identifying the high-risk individuals among the elderly in Beijing.
To the best of our knowledge, this is the first community-based diabetes prediction model considering competing risk that has been developed for the elderly population in China. It should be emphasized is that the general model evaluation methods are not applicable for competing risk models, calibration plots, net reclassification index (NRI), and integrated discrimination improvement (IDI) were calculated, and these values were adjusted for the competing risk of non-diabetes death.
The AUCs of previous diabetes risk scores for elderly adults ranged from 0.71 to 0.78 in their original population9,10. Our score based on the competing risk model showed a moderately high AUC value of 0.76 (95% CI: 0.72–0.80). Of note, a model with an AUC value less than 0.80 for predicting incident diabetes may have limited clinical utility. However, all predictors included in our scores are readily available clinical variables. If further predictors related to blood test results were included, the scores would likely show an improved performance.
In our score based on the competing risk model, age is the strongest predictor of incident diabetes (a contribution of 15 points). Individuals aged 55 to 65 years have the highest risk of developing diabetes in our scores (accounting for 39.47% of the total score based on the competing risk model), followed by individuals aged ranging from 66 to 75 years. Similarly results were found in the Guangzhou Biobank Cohort Study (GBCS), which was a 4.1-year population-based follow-up of 16,043 Chinese aged 50 years or above10.
BMI is the second-strongest predictor in our scores, and has been included in most of the published scores used to predict incident diabetes10. In our scores, the FPG variable is the third-strongest predictor after BMI (a contribution of 7 points). This result is roughly consistent with previous reports9. The value representing impaired fasting glucose (IFG) has been defined to be from 6.1 to 6.9 mmol/L. It is unsurprising that individuals with IFG have a high risk of developing diabetes. The risk of incident diabetes increased with high FPG levels.
Physical activity is also an important predictors of incident diabetes, and environmental pathways may be able to account for this relationship13. It has been demonstrated that interventions that include increases in physical activity are able to reduce the incidence of diabetes in high risk adults29,30. Another reason for this finding is that participants who frequently exercise are more likely to be aware of their blood glucose levels than people who never or rarely exercise.
We are the first to include self-rated health status in a diabetes prediction score. The competing-risk-based score included the self-rated health status and was assigned 6 points. Self-rated health (SRH) is a reflection of social, psychological, and biologic dimensions; it is one of the most widely used yet poorly understood measures of health31. In the present study, SRH was based on individuals’ assessment of their health status compared with that of peers their age. Similar to our results, SRH scores provide additional valuable information for risk prediction in patients with diabetes32, and it has also been recommended as a tool for assessing cardiovascular disease risk assessment33. Thus, diabetes guidelines should extend their focus on clinical and social aspects of diabetes to include questions on patient’s SRH34.
There were some limitations to our study. First, we did not included waist circumference. However, the Guangzhou Biobank Cohort Study showed that using waist circumference or waist-to-hip ratio instead of BMI did not substantially improve the discrimination substantially10. Second, due to the long-term follow-up, follow-up biases could easily have been introduced. However, the sensitivity analysis showed that there were no statistically significant differences in the distribution of baseline characteristics between those lost to follow-up and those who remained in the study. In addition, because cases of diabetes were identified through reexamination and questionnaires, diabetes onset occurred prior to diagnosis.
Conclusion
We constructed a multivariable risk score using a community-based sample with a 20-year follow-up that can be used to predict an individual’s risk for diabetes among adults over 55 years of age. To the best of our knowledge, this is the first community-based diabetes risk score to consider competing risk developed for an elderly population in China. Further studies are needed to test this score in other population samples of China.
Methods
The BLSA study
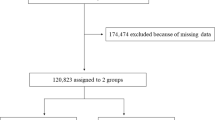
According to the 10% sampling data from Beijing in China’s fourth census, a three-stage stratification (i.e., natural living environment, education level and degree of ageing) random-clustering sampling procedure was conducted to ensure the representativeness of the elderly population in Beijing35. The communities included were located in Huairou district, Daxing district, and Xuanwu district, which are representative of the northern, middle and southern region of Beijing, respectively. Periodic health examinations were performed every 2–3 years (in year 1992, 1994, 1997, 2000, 2004, 2007, 2009 and 2012) and included questionnaire interviews, anthropometric measurements, clinical examinations, and laboratory assessments. We used complete data for the period from 1992 to 2012 in the study. A community-based cohort of 2101 people (1037 men and 1064 women, 55–96 years old) were recruited for the BLSA (Beijing Longitudinal Study on Ageing) from August 1992 to December 2012, and this study was managed by Xuanwu Hospital of Capital Medical University in Beijing, China. In total, 244 subjects were excluded because of they had either a baseline FPG level higher than 7.0 mmol/L (126 mg/dl) or a history of diabetes (as informed by a physician) or because they were taking antidiabetic medicine. This left 1857 participants (925 men and 932 women) who did not have diabetes at baseline for the analysis.
The study followed the guidelines of the Helsinki Declaration and was approved by the ethics committee of Xuanwu Hospital, Capital Medical University. Written informed consent was obtained from all participants.
Assessment of risk factors and outcomes
The candidate baseline variables presented in Table 1 were chosen for their common availability and use in previous diabetes prediction models. The demographic characteristics and information on dietary habits, lifestyle, psychological factors and physical condition were obtained using questionnaires with a high degree of reliability and accuracy36; the questionnaires were administered by hospital research doctors of the hospitals who were specifically trained for the job. The questionnaires were designed by the Beijing Geriatric Clinical and Research Centre and the Australian Geriatric Research Centre of Flinders University. The measurement and classification of each category variable have been reported elsewhere in detail35.
A food frequency questionnaire was conducted for the dietary assessment37. Then, a latent class model was constructed and the best model was selected according to the value of the Bayesian information criterion. Based on the posterior probability (representing the frequency of food intake), dietary habits were divided into three latent groups: sufficient nutrition, intermediate-type and meat-based diet. Self-reported smoking, drinking, residence, and health status and the frequency of physical activity were evaluated by questionnaires with a high degree of reliability and accuracy. If the elderly exercised almost every day, this was defined as exercising frequently. The activities included Qi Gong, TaiChi, walking, running/jogging, dancing, etc.
Age was categorized into three sub-groups: 55 to 65 years, 66 to 75 years, and ≥76 years. Marital status was divided into two categories: married and unmarried. Height, weight, hip circumference, and waist circumference (2.5 cm above the umbilicus) were measured in the standing position without heavy clothing to the nearest 0.1 cm or 0.1 kg by nurses who were responsible for annual routine health examinations. BMI was calculated according to the equation BMI = weight (kg)/height (m)2 and was classified based on the common Chinese criteria38, i.e., thin corresponding to BMI < 18.5 kg/m2, normal to 18.5 ≤ BMI < 24.0 kg/m2, overweight to 24.0 ≤ BMI < 28.0 kg/m2, and obese to BMI ≥ 28.0 kg/m2.
Blood pressure (BP) was measured twice on the left arm of the seated participants with a mercury sphygmomanometer and an appropriately sized cuff; the average of the blood pressure measurements was constituted the examination blood pressure value. The two BP measurements were obtained with a 5-minute interval. If the two measurements differed by more than 5 mmHg, an additional reading was taken, and the final, average of the readings was used for the analysis. BP was classified into two groups: high (systolic blood pressure >140 mmHg or diastolic blood pressure >90 mmHg) and normal blood pressure.
Blood samples were collected after an overnight fast of at least 12 hours. FPG (Fasting plasma glucose), total cholesterol (TC), triglycerides (TG), high-density lipoprotein cholesterol (HDL-C), and low-density lipoprotein cholesterol (LDL-C) were subsequently determined with standardized enzymatic methods. Based on the standard of impaired FPG and dyslipidaemia, a FPG level of 6.1 to 6.9 mmol/L (109.8–125.9 mg/dl) was considered to impaired fasting glucose (IFG)39. A TC level of 5.18 mmol/L (200 mg/dL) or greater, a TG level of 1.7 mmol/L (150 mg/dL) or greater, a HDL-C level less than 1.03 mmol/L (40 mg/dL) in men and 1.29 mmol/L (50 mg/dL) in women, or an LDL-C level of more than 3.35 mmol/L (130 mg/dL) were considered to indicate dyslipidemia40.
The outcome of interest was the first incidence of diabetes at follow-up. This was identified according to either a self-reported history of diabetes diagnosis, or the use of antidiabetic medicine after the baseline examination, or a measured FPG level ≥ 7.0 mmol/L (126 mg/dl) at any of the periodic examinations. The date of diagnosis (incidence) was defined as the date of the examination visit when a new case of diabetes was identified or the diagnosis date on the most recently documented diabetes history collected by the questionnaire, whichever came first. Survival status was determined through interviews with surviving household members or neighbours when surviving household members were unavailable. The information was verified by a subset of participants based on household registration records. Cause of death was determined according to the International Classification of Disease (ICD), ninth revision (ICD-9 or ICD-10). Non-diabetes death, including from cardiovascular diseases, cancers and other causes, was classified as competing events.
Statistical Analysis
Time of follow-up was calculated from the return date of the 1992 questionnaire until either incidence of diabetes, death, loss to follow-up, or the end of follow-up (December 2012), whichever came first. Considering the extensive length of the follow-up and the potential bias due to the competing risk of non-diabetes mortality, we employed a sub-distribution hazards model to adjust for the risk estimates of the competing risk of non-diabetes death as a competing risk25. The sub-distribution hazards model calculated the cumulative incidence of diabetes in the following manner:

In equation (1), the quantities under summation denote the instantaneous hazard of diabetes at event time ti and the survival rate from non-diabetes death past event time ti−1.
Sub-distribution hazards models were fitted to predict the risk of developing diabetes using package cmprsk and package crrstep in R software, which adjusted for clinical and biochemical variables. In the first step, univariate sub-distribution hazards models were used to regress the sub-distribution hazard of diabetes incidence on all nineteen candidate variables, and the variables with a statistical significance of the estimated regression coefficients of P > 0.20 were removed. Then, all significant variables were included to develop the multivariate prediction model with backward selection. In the third step, the remaining variables were included to build the final prediction model. For each model, sub-distribution hazard ratio (SHRs) and 95% confidence intervals (95% CIs) were calculated to estimate the relative risk.
Self-rated health is an important risk factor for diabetes, as confirmed in some studies22,41. However, no diabetes risk prediction models considered the impact of self-assessed of health status. Therefore, the diabetes risk prediction model in this study accounted for self-assessment of health status. We did not account for the interaction terms between the independent variables. All continuous variables included in the model were categorized, and thus the estimated contribution of these factors to diabetes risk could be expressed through simplified point scores assigned to each for the category. In addition, β-coefficients were calculated to determine points for each risk factor by multiplying the β-coefficients by 10 and rounding to the nearest integer. The sum of these points for each model was further calculated to predict the hazard of the incidence of diabetes over a mean follow-up period of 9.81 years for each person.
After the prediction models were developed, it was critical to evaluate their performance. The receiver operating characteristic (ROC) curve and areas under the ROC curves (AUCs, also referred to as C statistics) were used to evaluate the discriminative ability of the sub-distribution hazards models42 and were obtained by the ROCR package in R (R Foundation for Statistical Computing, Vienna, Austria)43. The cut-off point was estimated by calculating the value that minimizes the Euclidean distance between the ROC curve and the upper left corner of the graph. The calibration of the model was assessed graphically by comparing the predicted probability of the observed probability across the 10 deciles of predicted risk44, which was performed with the R package pec. Calibration refers to the agreement between observed outcomes and predictions. The more range there is between 10 deciles, the better discriminating the model. Hosmer-Lemeshow test was used to indicate the goodness of fit.
Additionally, internal validation was supported by estimating the potential of over- fitting and the optimism of the models45, which was performed by applying bootstrap resampling 1000 times with R package pROC. The bootstrap optimism-corrected AUC was computed by subtracting the optimism from the original AUC. Bootstrap-adjusted regression coefficients better reflect what can be expected when the model is tested or applied in new individuals from the same theoretical source population45. However, no internal validation methods can substitute for external validation.
Recently, some novel alternatives to the area under the receiver operating characteristic curve, such as net reclassification improvement (NRI) and integrated discrimination improvement (IDI), have been proposed46 to measure the improvement from the new risk factor in the prediction. The NRI and IDI are two new metrics used to the formally assess new risk factors, to supplement the improvement in the AUC, and were assessed using the R package of survIDINRI. All p-values reported were two-sided. Two-independent sample chi-square tests were in SAS software (Version 9.2, SAS Institute Inc., Cary, NC).
Additional Information
How to cite this article: Liu, X. et al. A competing-risk-based score for predicting twenty-year risk of incident diabetes: the Beijing Longitudinal Study of Ageing study. Sci. Rep. 6, 37248; doi: 10.1038/srep37248 (2016).
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
Levitan, E. B., Yiqing, S., Ford, E. S. & Liu, S. Is nondiabetic hyperglycemia a risk factor for cardiovascular disease? A meta-analysis of prospective studies. Arch Intern Med. 164, 2147–2155, doi: 10.1001/archinte.164.19.2147 (2004).
WHO. Global status report on noncommunicable diseases http://www.who.int/nmh/publications/ncd-status-report-2014/en/ (2014).
Yang, W., L. J., Weng, J. et al. Prevalence of diabetes among men and women in China. N Engl J Med. 362, 1090–1101, doi: 10.1056/NEJMoa0908292 (2010).
Pin, S. & Spini, D. Meeting the Needs of the Growing Very Old Population: Policy Implications for a Global Challenge. Journal of aging & social policy. doi: 10.1080/08959420.2016.1181972 (2016).
Chen, Z., Yu, J., Song, Y. & Chui, D. Aging Beijing: challenges and strategies of health care for the elderly. Ageing research reviews. 9 Suppl 1, S2–S5, doi: 10.1016/j.arr.2010.07.001 (2010).
Stern, M. P., Williams, K. & Haffner, S. M. Identification of persons at high risk for type 2 diabetes mellitus: do we need the oral glucose tolerance test? Ann Intern Med. 136, 575–581, doi: 10.7326/0003-4819-136-8-200204160-00006 (2002).
Lindstrom, J. & Tuomilehto, J. The diabetes risk score: a practical tool to predict type 2 diabetes risk. Diabetes Care. 26, 725–731, doi: 10.2337/diacare.26.3.725 (2003).
Wilson, P. W. et al. Prediction of incident diabetes mellitus in middle-aged adults: the Framingham Offspring Study. Arch Intern Med. 167, 1068–1074, doi: 10.1001/archinte.167.10.1068 (2007).
Kanaya, A. M. et al. Predicting the development of diabetes in older adults: the derivation and validation of a prediction rule. Diabetes Care. 28, 404–408, doi: 10.2337/diacare.28.2.404 (2005).
Xu, L. et al. Prediction of 4-year incident diabetes in older Chinese: recalibration of the Framingham diabetes score on Guangzhou Biobank Cohort Study. Preventive medicine. 69, 63–68, doi: 10.1016/j.ypmed.2014.09.004 (2014).
Rahman, M., Simmons, R. K., Harding, A. H., Wareham, N. J. & Griffin, S. J. A simple risk score identifies individuals at high risk of developing Type 2 diabetes: a prospective cohort study. Family practice. 25, 191–196, doi: 10.1093/fampra/cmn024 (2008).
Hippisley-Cox, J., Coupland, C., Robson, J., Sheikh, A. & Brindle, P. Predicting risk of type 2 diabetes in England and Wales: prospective derivation and validation of QDScore. Bmj. 338, b880, doi: 10.1136/bmj.b880 (2009).
Schulze, M. B. et al. An accurate risk score based on anthropometric, dietary, and lifestyle factors to predict the development of type 2 diabetes. Diabetes Care. 30, 510–515, doi: 10.2337/dc07-0682 (2007).
Heikes, K. E., Eddy, D. M., Arondekar, B. & Schlessinger, L. Diabetes Risk Calculator: a simple tool for detecting undiagnosed diabetes and pre-diabetes. Diabetes Care. 31, 1040–1045, doi: 10.2337/dc07-1150 (2008).
Chen, L. et al. AUSDRISK: an Australian Type 2 Diabetes Risk Assessment Tool based on demographic, lifestyle and simple anthropometric measures. The Medical journal of Australia. 192, 197–202 (2010).
Pires de Sousa, A. G. et al. Derivation and external validation of a simple prediction model for the diagnosis of type 2 diabetes mellitus in the Brazilian urban population. European journal of epidemiology. 24, 101–109, doi: 10.1007/s10654-009-9314-2 (2009).
Gao, W. G. et al. Risk prediction models for the development of diabetes in Mauritian Indians. Diabetic medicine: a journal of the British Diabetic Association. 26, 996–1002, doi: 10.1111/j.1464-5491.2009.02810.x (2009).
Lee, Y. H. et al. A simple screening score for diabetes for the Korean population: development, validation, and comparison with other scores. Diabetes Care. 35, 1723–1730, doi: 10.2337/dc11-2347 (2012).
Aekplakorn, W. et al. A risk score for predicting incident diabetes in the Thai population. Diabetes Care. 29, 1872–1877, doi: 10.2337/dc05-2141 (2006).
Chien, K. et al. A prediction model for type 2 diabetes risk among Chinese people. Diabetologia. 52, 443–450, doi: 10.1007/s00125-008-1232-4 (2009).
Al-Lawati, J. A. & Tuomilehto, J. Diabetes risk score in Oman: a tool to identify prevalent type 2 diabetes among Arabs of the Middle East. Diabetes research and clinical practice. 77, 438–444, doi: 10.1016/j.diabres.2007.01.013 (2007).
Schmitz, N. et al. Trajectories of self-rated health in people with diabetes: associations with functioning in a prospective community sample. PloS one. 8, e83088, doi: 10.1371/journal.pone.0083088 (2013).
Vimalananda, V. G. et al. Depressive symptoms, antidepressant use, and the incidence of diabetes in the Black Women’s Health Study. Diabetes Care. 37, 2211–2217, doi: 10.2337/dc13-2642 (2014).
Lau, B., Cole, S. R. & Gange, S. J. Competing risk regression models for epidemiologic data. American journal of epidemiology. 170, 244–256, doi: 10.1093/aje/kwp107 (2009).
Austin, P. C., Lee, D. S., D’Agostino, R. B. & Fine, J. P. Developing points-based risk-scoring systems in the presence of competing risks. Statistics in medicine. doi: 10.1002/sim.6994 (2016).
Austin, P. C., Lee, D. S. & Fine, J. P. Introduction to the Analysis of Survival Data in the Presence of Competing Risks. Circulation. 133, 601–609, doi: 10.1161/CIRCULATIONAHA.115.017719 (2016).
Liu, L. et al. A Novel Risk Score to the Prediction of 10-year Risk for Coronary Artery Disease Among the Elderly in Beijing Based on Competing Risk Model. Medicine. 95, e2997, doi: 10.1097/MD.0000000000002997 (2016).
Collins, G. S., Mallett, S., Omar, O. & Yu, L. M. Developing risk prediction models for type 2 diabetes: a systematic review of methodology and reporting. BMC medicine. 9, 103, doi: 10.1186/1741-7015-9-103 (2011).
Orozco, L. J. et al. Exercise or exercise and diet for preventing type 2 diabetes mellitus. The Cochrane database of systematic reviews. CD003054, doi: 10.1002/14651858.CD003054.pub3 (2008).
Pan, X. R. et al. Effects of diet and exercise in preventing NIDDM in people with impaired glucose tolerance. The Da Qing IGT and Diabetes Study. Diabetes Care. 20, 537–544 (1997).
Jylha, M. What is self-rated health and why does it predict mortality? Towards a unified conceptual model. Social science & medicine (1982). 69, 307–316, doi: 10.1016/j.socscimed.2009.05.013 (2009).
Hayes, A. J. et al. Can self-rated health scores be used for risk prediction in patients with type 2 diabetes? Diabetes Care. 31, 795–797, doi: 10.2337/dc07-1391 (2008).
May, M., Lawlor, D. A., Brindle, P., Patel, R. & Ebrahim, S. Cardiovascular disease risk assessment in older women: can we improve on Framingham? British Women’s Heart and Health prospective cohort study. Heart (British Cardiac Society). 92, 1396–1401, doi: 10.1136/hrt.2005.085381 (2006).
Nielsen, A. B. et al. Change in self-rated general health is associated with perceived illness burden: a 1-year follow up of patients newly diagnosed with type 2 diabetes. BMC public health. 15, 439, doi: 10.1186/s12889-015-1790-6 (2015).
Tang, Z. et al. Risk factors for cerebrovascular disease mortality among the elderly in Beijing: a competing risk analysis. PloS one. 9, e87884, doi: 10.1371/journal.pone.0087884 (2014).
Zhou, T. et al. Risk factors of CVD mortality among the elderly in Beijing, 1992 - 2009: an 18-year cohort study. International journal of environmental research and public health. 11, 2193–2208, doi: 10.3390/ijerph110202193 (2014).
Wang W. T. Z., Li, X. et al. Eight–year change in dietary pattern and metabolic status among the elderly people in Beijing. Journal of capital medical university. 02, 218–222 (2012).
Chen, C. & Lu, F. C. The guidelines for prevention and control of overweight and obesity in Chinese adults. Biomedical and environmental sciences: BES. 17 Suppl, 1–36 (2004).
Alberti, K. G. & Zimmet, P. Z. Definition, diagnosis and classification of diabetes mellitus and its complications. Part 1: diagnosis and classification of diabetes mellitus provisional report of a WHO consultation. Diabetic medicine: a journal of the British Diabetic Association. 15, 539–553, doi: 10.1002/(SICI)1096-9136(199807)15:7<539::AID-DIA668>3.0.CO;2-S (1998).
Catapano, A. L. et al. ESC/EAS Guidelines for the management of dyslipidaemias The Task Force for the management of dyslipidaemias of the European Society of Cardiology (ESC) and the European Atherosclerosis Society (EAS). Atherosclerosis. 217, 3–46 (2011).
Taloyan, M., Wajngot, A., Johansson, S. E., Tovi, J. & Sundquist, J. Poor self-rated health in adult patients with type 2 diabetes in the town of Sodertalje: A cross-sectional study. Scandinavian journal of primary health care. 28, 216–220, doi: 10.3109/00016349.2010.501223 (2010).
Wolbers, M., Blanche, P., Koller, M. T., Witteman, J. C. & Gerds, T. A. Concordance for prognostic models with competing risks. Biostatistics (Oxford, England). 15, 526–539, doi: 10.1093/biostatistics/kxt059 (2014).
Polterauer, S. et al. Nomogram prediction for overall survival of patients diagnosed with cervical cancer. British journal of cancer. 107, 918–924, doi: 10.1038/bjc.2012.340 (2012).
Wolbers, M., Koller, M. T., Witteman, J. C. & Steyerberg, E. W. Prognostic models with competing risks: methods and application to coronary risk prediction. Epidemiology (Cambridge, Mass.). 20, 555–561, doi: 10.1097/EDE.0b013e3181a39056 (2009).
Moons, K. G. et al. Risk prediction models: I. Development, internal validation, and assessing the incremental value of a new (bio)marker. Heart (British Cardiac Society). 98, 683–690, doi: 10.1136/heartjnl-2011-301246 (2012).
Uno, H., Tian, L., Cai, T., Kohane, I. S. & Wei, L. J. A unified inference procedure for a class of measures to assess improvement in risk prediction systems with survival data. Statistics in medicine. 32, 2430–2442, doi: 10.1002/sim.5647 (2013).
Acknowledgements
Our work was funded by National Natural Science Foundation of China (serial nos: 81530087, 81373099, and 81302516), Beijing Natural Science Foundation (Serial nos.: Z160002), National Twelfth Five-year Science and Technology Support Program (serial no.: 2011BAI08B01), and Humanities and Social Sciences Fund of the Ministry of Education, China (serial no.:13YJCZH090). The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript. We thank all the staff and participants of the BLSA study for their invaluable contributions.
Author information
Authors and Affiliations
Contributions
X.T.L. wrote the manuscript and researched data. Z.H.C., L.L., A.X.W. and researched data. J.P.F. reviewed/edited the manuscript. Z.H.C., J.G., L.X.T., G.M., and K.Y. contributed to the discussion. J.Z., S.J.T., and H.B.L. consulted references about Diabetes Risk Scores developed in other countries. K.L., Y.X.L., and F.Z. researched data and contributed to discussion. X.H.G. and Z.T. contributed to the discussion and reviewed/edited the manuscript.
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Rights and permissions
This work is licensed under a Creative Commons Attribution 4.0 International License. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in the credit line; if the material is not included under the Creative Commons license, users will need to obtain permission from the license holder to reproduce the material. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/
About this article

Cite this article
Liu, X., Chen, Z., Fine, J. et al. A competing-risk-based score for predicting twenty-year risk of incident diabetes: the Beijing Longitudinal Study of Ageing study. Sci Rep 6, 37248 (2016). https://doi.org/10.1038/srep37248
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/srep37248
This article is cited by
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
