
Abstract
Recently, several platforms were proposed and demonstrated a proof-of-principle for finding the global minimum of the spin Hamiltonians such as the Ising and XY models using gain-dissipative quantum and classical systems. The implementation of dynamical adjustment of the gain and coupling strengths has been established as a vital feedback mechanism for analog Hamiltonian physical systems that aim to simulate spin Hamiltonians. Based on the principle of operation of such simulators we develop a novel class of gain-dissipative algorithms for global optimisation of NP-hard problems and show its performance in comparison with the classical global optimisation algorithms. These systems can be used to study the ground state and statistical properties of spin systems and as a direct benchmark for the performance testing of the gain-dissipative physical simulators. Our theoretical and numerical estimations suggest that for large problem sizes the analog simulator when built might outperform the classical computer computations by several orders of magnitude under certain assumptions about the simulator operation.
Similar content being viewed by others
Introduction
Finding the global minimum of spin Hamiltonians has been instrumental in many areas of modern science. Such Hamiltonians have initially been introduced in condensed matter to study magnetic materials1,2 and by now they became fundamentally important in a vast spread of many other disciplines such as quantum gravity3, combinatorial optimization4, neural networks5, protein structures6, error-correcting codes7, X-ray crystallography8, diffraction imaging9, astronomical imaging10, optics11, microscopy12, biomedical applications13, percolation clustering14 and machine learning15.
The spin degrees of freedom in spin models are either discrete or continuous. In particular, we will be concerned with the XY model, where spins lie on a unit circle sj = cos θj + i sin θj, the Ising model where spins take values sj = ±1 and q-state planar Potts model where spins take q discrete values. For N spins the classical Hamiltonians for these models can be written as
where the elements Jij of matrix J define the strength of the couplings between i-th and j-th spins represented by the phases θi and θj and gi is the strength of the external field acting on spin i. For the continuous XY model θj ∈ [0, 2π), for the Ising model θj ∈ {0, π}, and for the q-state planar Potts model θj = 2πj/q, j = 1, …, q.
For a general matrix of coupling strengths, J, finding the global minimum of such problems is known to be strongly NP-complete16, meaning that an efficient way of solving them can be used to solve all problems in the complexity class NP that includes a vast number of important problems such as partitioning, travelling salesman problem, graph isomorphisms, factoring, nonlinear optimisation beyond quadratic, etc. For instance, the travelling salesman problem of a record size 85,900 has been solved by the state of the art Concorde algorithm in around 136 CPU-years17. The actual time required to find the solution also depends on the matrix structure. For instance, for positive definite matrices, finding the global minimum of the XY model remains NP-hard due to the non-convex constraints but can be effectively approximated using an SDP relaxation18 with the performance guarantee π/416. Sparsity also plays an important role: for sufficiently sparse matrices fast methods exist19. As for many other hard optimisation problems, there are three types of algorithms for minimizing spin Hamiltonian problems on a classical computer: exact methods that find the optimal solution to the machine precision, approximate algorithms that generate the solution within a performance guarantee and heuristic algorithms where suitability for solving a particular problem comes from some empirical testing20. Exact methods can be used to solve small to medium matrix instances, as they typically involve branch-and-bound algorithms and the exponential worst-case runtime. The heuristic algorithms such as simulated annealing can quickly deliver a decent, but suboptimal (and possibly infeasible) solution21. Finally, global minimization of the XY and Ising models is known to be in the APX-hard class of problems22, so no polynomial-time approximation algorithm gives the value of the objective function that is arbitrarily close to the optimal solution (unless P = NP). The problem becomes even more challenging when the task is to find not only an approximation to the global minimum of the objective function, but also the minimisers, as needed, for instance, in image reconstruction. The values of the objective functions can be very close but for the entirely different sets of minimizers.
Recently, several platforms were proposed and demonstrated a proof-of-principle of finding the global minimum of the spin Hamiltonians such as the Ising and XY models using gain-dissipative quantum and classical systems: the injection-locked lasers23, the network of optical parametric oscillators24,25, coupled lasers26, polariton condensates27, and photon condensates28. In the gain-dissipative simulators, the phase of the so-called coherent centre (CC) is mapped into the “spin” of the simulator. Such CC can be a condensate27,28 or a coherent state generated in a laser cavity25,26. The underlying operational principle of such simulators depends on a gain process that is increased from below until a nonzero occupation appears via the supercritical Hopf bifurcation and the system becomes globally coherent across many CCs. The coherence occurs at the maximum occupancy for the given gain. It was suggested and experimentally verified that the maximum occupancy of the system is related to the corresponding spin Hamiltonian27. When the heterogeneity in densities of the CCs is removed by dynamically adjusting the gain the coherence will be established at the global state of the corresponding spin Hamiltonian29. We refer to these platforms as gain-dissipative analog Hamiltonian optimisers30 that, despite having different quantum hardware, share the basic principle that suggests the convergence to the global minimum of the spin Hamiltonian.
Here, motivated by the operation of such physical systems, we develop a new class of classical gain-dissipative algorithms for solving large-scale optimisation problems based on the Fokker-Plank-Langevin gain-dissipative equations written for a set of CCs. We show how the algorithm can be modified to cover various spin models: continuous and discrete alike. We demonstrate the robustness of such iterative algorithms and show that we can tune the parameters for the algorithm to work efficiently on various sizes and coupling structures. We show that such algorithms can outperform the standard global optimiser algorithms and have a potential to become the state of the art algorithm. Most importantly, these algorithms can be used as a benchmark for the performance of the physical gain-dissipative simulators. Finally, this framework allows us to estimate the operational time for a physical realisation of such simulators to achieve the global minimum.
The paper is organised as follows. We formulate a general classical gain-dissipative algorithm for finding the global minimum of various spin Hamiltonians in Section 1. In Sections 2 and 3 we investigate its performance on global optimisations of the XY and Ising Hamiltonians by comparing it to standard built-in global optimisers of Scipy optimisation library in Python and to the results of breakout local search and GRASP algorithms. We discuss the performance of the actual physical systems in Section 4 and conclude in Section 5.
Gain-dissipative approach for minimising the spin Hamiltonians
The principle of operation of the gain-dissipative simulator with N CCs for minimisation of the spin Hamiltonians given by Eq. (1) is described by the following set of the rate equations29,31
where Ψi(t) is a classical complex function that describes the state of the i-th CC, \({\gamma }_{i}^{{\rm{inj}}}\) is the rate at which particles are injected non-resonantly into the i− state, γc is the linear rate of loosing the particles, the coupling strengths are represented by ΔijKij where we separated the effect of the particle injection that changes the strength of coupling represented by Δij from the other coupling mechanisms represented by Kij. We consider two cases Δij = 1 that physically corresponds to the site dependent dissipative coupling and \({{\rm{\Delta }}}_{ij}={\gamma }_{i}^{{\rm{inj}}}(t)+{\gamma }_{j}^{{\rm{inj}}}(t)\) appropriate for the description of the geometrically coupled condensates29. We also include the complex function Dξi(t) that represents the white noise with a diffusion coefficient D which disappears at the threshold. The coefficients hqi represent the strength of the external field with the resonance q:131. Compared to the actual physical description29,31, in writing Eq. (2) we neglected the possible self-interactions within the CC and re-scaled Ψi so that the coefficient at the nonlinear dissipation term |Ψi|2Ψi is 1 and allowed for several (n) resonant terms to be included. By writing \({{\rm{\Psi }}}_{i}=\sqrt{{\rho }_{i}}\exp [{\rm{i}}{\theta }_{i}]\) and separating real and imaginary parts in Eq. (2) we get the equations on the time evolution of the number density ρi and the phase θi
where θij = θi − θj.
As we have previously shown29,31, the individual control of the pumping rates \({\gamma }_{i}^{{\rm{inj}}}\) is required to guarantee that the fixed points of the system coincide with minima of the spin Hamiltonian given by Eq. (1). As the injection rates \({\gamma }_{i}^{{\rm{inj}}}\) raise from zero they have to be adjusted in time to bring all CCs to condense at the same specified number density ρth. Mathematically, this is achieved by
where ε controls the speed of the gain adjustments. If we take Δij = 1 we assign Kij = Jij. If Δij depends on the injection rates, the coupling strengths will be modified, so they have to be adjusted as well to bring the required coupling Jij at the fixed point by
where \(\hat{\epsilon }\) controls the rate of the coupling strengths adjustments. Equation (6) indicates that the couplings need to be reconfigured depending on the injection rate: if the coupling strength scaled by the gain at time t is lower (higher) than the objective coupling Jij, it has to be increased (decreased) at the next iteration. We shall refer to numerical realisation of Eqs (2 and 5) with Δij = 1 and Kij = Jij and Eqs (2, 5 and 6) with \({{\rm{\Delta }}}_{ij}={\gamma }_{i}^{{\rm{inj}}}(t)+{\gamma }_{j}^{{\rm{inj}}}(t)\) and Kij ≠ Jij as the ‘Gain-D algorithm’ and the ‘Gain-D-mod algorithm’ respectively.
The fixed point of Eqs (3–6) are
with the total number of particles in the system given by \(M=N{\rho }_{{\rm{th}}}={\sum }_{i}\,{\gamma }_{i}^{{\rm{inj}}}-N{\gamma }_{c}\) + \(\sum _{i,j;j\ne i}\,{J}_{ij}\,\cos \,{\theta }_{ij}\) +\(\sum _{q}\,{\rho }_{{\rm{th}}}^{\frac{q}{2}-1}\,\sum _{i}\,{h}_{qi}\,\cos \,(q{\theta }_{i})\). Such a value of the total number of particles will be first reached at the minimum of \({\sum }_{i}\,{\gamma }_{i}^{{\rm{inj}}}\), therefore, at the minimum of the spin Hamiltonian given by
Eq. (8) represents the general functional that our Gain-D and Gain-D-mod algorithms optimise. By choosing which hqi are non-zero we can emulate a variety of spin Hamiltonians. If hqi = 0, then Hs represents the XY Hamiltonian. If only h2i = h2 are non-zero with \({h}_{2} > {\sum }_{j;j\ne i}\,|{J}_{ij}|\) for any i, then the second term of the right-hand side of the Hamiltonian (8) represents the penalty, forcing phases to be 0 or π. It implies that the minima of Hs coincide with the minima of the Ising Hamiltonian. If only hqi = hq for q > 2 are non-zero, then the minima of Hs coincide with the minima of the q-state planar Potts Hamiltonian with phases restricted to discrete values θi = 2πi/q. Finally, introducing non-zero h1i together with non-zero hq for q > 1 brings the effect of an external field of strength \({g}_{i}={h}_{1i}/\sqrt{{\rho }_{{\rm{th}}}}\) in agreement with Eq. (1).
The “NP-hardness assumption” suggests that not only any classical algorithm but also any physical simulator cannot escape the exponential growth of the number of operations with the size of the problem32. In order to find the global minimum by evolving Eqs (2 and 5) one would require to span an exponentially growing number of various phase configurations. This can be achieved by either introducing an exponentially slow increase in the pumping rates when approaching the threshold, or by exploring an exponential growth in the number of runs using different noise seeds. In what follows we focus on the second option as it is more practical and corresponds to the operation of the actual physical simulators.
Global minimization of the XY Hamiltonian: h qi = 0
To find the global minimum of the XY Hamiltonian we numerically evolve Eqs (2 and 5) with hqi = 0 using the 4th-order Runge-Kutta integration scheme.
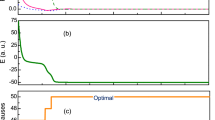
To illustrate the operational principle of the Gain-D algorithm for minimising the XY Hamiltonian we consider N = 20 nodes and the coupling strengths Jij that are randomly distributed between −10 and 10, see Fig. 1. Starting from a zero initial condition Ψi = 0, at the first stage of the evolution (while t < 120) the densities are well below the threshold (Fig. 1a), phases span various configurations (Fig. 1b), and all injection rates are the same (Fig. 1c). When the nodes start reaching, and in some cases overcoming the threshold, the injection rates are individually adjusted to bring all the nodes to the same value while phases stabilise to realise the minimum of the XY Hamiltonian.

A numerical approach for solving NP-hard optimisation problems depends on the scale of the problem: intermediate-scale problems can be solved with general programming tools while large-scale problems require sophisticated algorithms that exploit the structure of a particular type of objective function and are usually solved by iterative algorithms. Since the proposed Gain-D method based on Eqs (2 and 5) is an iterative algorithm, we aim to investigate its two main aspects. First, we conduct the global convergence analysis on small and mid-scale problems and verify that with the sufficient number of runs the algorithm finds a global minimum. The fact that the minimum is truly global we confirm by exploiting other optimisation methods. As for any heuristic iterative algorithm, such convergence properties can be established with confidence by performing numerous numerical experiments on different problems. Second, we perform the complexity analysis on large-scale problems with a focus on how fast the algorithm converges per run.
To characterise the performance of the Gain-D algorithm, we compared it to the heuristic global optimisation solvers such as direct Monte Carlo sampling (MC) and the basin-hopping (BH) algorithm. Both methods are built-in optimisation algorithms of a well-known Scipy optimisation library in Python so their performance has been carefully tested. The BH algorithm depends on a local minimisation algorithm performing the optimal decent to a local minimum at each iteration. We considered several local minimisation methods as applied to the minimisation of the XY Hamiltonians and determined that the quasi-Newton method of Broyden, Fletcher, Goldfarb, and Shanno (L-BFGS-B)33,34 has shown the best performance (see Supplementary Information). The L-BFGS-B algorithm is a local minimisation solver which is designed for large-scale problems and shows a good performance even for non-smooth optimisation problems33,34. At each run of the MC algorithm, we generate a random starting point and use L-BFGS-B algorithm to find the nearest local minimum. These minima are compared to find the global minimum. Applying simple Monte-Carlo method to the random coupling matrices allows one to understand how hard these instances are, while the hardness or the easiness of the problems is a critical issue to address for understanding the performance of a newly suggested algorithm, i.e. Gain-D algorithm. The BH algorithm is a global minimisation method that has been shown to be extremely efficient for a wide variety of problems in physics and chemistry35 and to give a better performance on the spin Hamiltonian optimisation problems than other heuristic methods such as simulated annealing36. It is an iterative stochastic algorithm that at each iteration uses a random perturbation of the coordinates with a local minimisation followed by the acceptance test of new coordinates based on the Metropolis criterion. Again L-BFGS-B algorithm has shown the best performance as a local optimiser at each step of the BH algorithm. Both BH and MC algorithms were supplied with the analytical Jacobian of the objective function for better performance results.
To confirm the global convergence, we compared the Gain-D algorithms to the BH and MC algorithms by minimizing XY Hamiltonian for various matrices. The numerical parameters and the initial conditions for the Gain-D algorithm described by Eqs (2 and 5). In particular, we generated 50 real symmetric coupling matrices J = {Jij} of two types. We considered ‘dense’ matrices with elements that are randomly distributed in [−10, 10] and ‘sparse’ matrices where each CC is randomly connected to exactly three other CCs with the coupling strengths randomly generated from the interval with the bounds that are randomly taken from {−10, −3, 3, 10}. For each such matrix, we ran the Gain-D, BH and MC algorithms starting with 500 random initial conditions for the BH and MC algorithms and with zero initial conditions and 500 different noise seeds for the Gain-D algorithm. The values of the global minimum of the objective function found by the Gain-D algorithm and the comparison methods were found to match to ten significant digits. For ‘dense’ matrices the success probabilities of the Gain-D algorithms were similar to both comparison methods. The distribution of success probabilities over various ‘dense’ matrix instances is shown in Fig. 2(a–c) for N = 50 and suggests that for such matrices the systems have very narrow spectral gap so the distributions are densely packed for probabilities over 93% for the MC, 96% for the BH, and 95% for the Gain-D algorithm. It is known that the spectrum of random matrices is simple37, so more difficult instances can be specifically constructed as illustrated in Fig. 2(d–f), where the Gain-D algorithm greatly outperforms the comparison algorithms on ‘sparse’ matrices. Thus, we established the global convergence properties of the proposed Gain-D algorithms on various problems and verified that the Gain-D algorithms finds the global minimum. The further advantages of the Gain-D algorithms over the best classical optimisers for some particular types of the coupling matrices are elucidated elsewhere38.

The success probability of (a,d) MC, (b,e) BH, and (c,f) Gain-D algorithms when minimising the XY Hamiltonian for the matrix size N = 50. The results of 500 runs are averaged over 50 real symmetric coupling matrices J with the elements randomly distributed in [−10, 10] for (a–c) ‘dense’ and (d–f) ‘sparse’ matrices described in the main text. The number of internal BH iterations was set to ten to bring about a similar performance to the Gain-D algorithm for ‘dense’ matrices.
Global minimization of the Ising Hamiltonian: h 2i = h 2 ≠ 0
To find the global minimum of the Ising Hamiltonian we solve Eqs (2 and 5) with hqi = 0 if q ≠ 2 and hqi = h2 numerically. Based on these equations we test the Gain-D algorithm by finding the maxima of MaxCut optimisation problem on the well-known G-Set instances39 and summarise our findings in Fig. 3. The optimal MaxCut values40 are plotted with coloured rectangles and the solutions of the Gain-D algorithm are shown with scatters for 100 runs for each G instance. The algorithm demonstrates good performance with the average found cuts being within 0.2–0.3% for G1–G5 and 1.1–1.8% for G6–G10 of the optimal solutions. The same numerical parameters were used for all simulations. The computational time for finding each cut has been limited by the same value of 35–40s, single core simulations on MacBook Pro, 2.7 GHz Intel Core i7, 16 GB 2133 MHz LPDDR3, 2.7 GHz Intel Core i7, 16 GB 2133 MHz LPDDR3. The time performance of the state of the art algorithms depends on a particular problem and for G1–G10 varies from 13s to 317s (A C++ implementation of BLS algorithm was run on an Intel Xeon E5440 with 2.83 GHz and 2 GB in40) and is within 100–854s for GRASP tabu search41 algorithms are programmed in C and compiled using GNU though their solutions are much less deviated from the optimal values. We also confirmed that for the coupling matrix of size N = 10000, namely, G70 problem from the G-Set, all found solutions of the MaxCut problem out of 100 runs, 1000 time iterations are within 1.1% of the global minimum from the known optimal solution40. These results are achieved with an average computational time per run of 530s compared to 11365s of the BLS algorithm. Therefore, the proposed Gain-D algorithm is highly competitive with the existing state of the art MaxCut algorithms at least regarding the computational time. The deviation of solutions from the optimal values can be further reduced by tuning the parameters ρth and ε or by investigating the extensions to the Gain-D algorithm. Among such possible modifications is the introduction of individual dynamic rates of the gain adjustments εi(t).

The performance of the Gain-D algorithm (2–5) for solving the MaxCut optimisation problem on G-Sets {G1–G10} of size N = 800. The known optimal values are plotted with coloured rectangles for each Gi. The results of the Gain-D algorithm are shown with scatters for 100 runs on each Gi. The average MaxCut values are within 0.2–0.3% (1.1–1.8%) of the optimal solution for G1–G5 (G6–G10) sets. The time per each run of the Gain-D algorithm has been fixed to around 35–40s for all G-Sets.
Projected performance of the Gain-D simulators
So far we discussed the implementation of the Gain-D algorithms on a classical computer. An actual physical implementation of these algorithms on simulators will enjoy a super-fast operation and parallelism in processing various phase configurations as the system approaches the global minimum from below even if the system behaves entirely classically. Further acceleration could be expected if quantum fluctuations and quantum superpositions contribute to scanning the phase configurations. The times involved into the hardware operation of the Gain-D simulators vary on the scale of pico- to milli-seconds. For instance, in the system of non-degenerate optical parametric oscillators (NOPO) the time-devision multiplexing method is used to connect a large number of nodes and the couplings are realised by mutually injecting with optical delay lines with the cavity round trip time being of the order of μs25, it takes an order of 100 picoseconds for the polariton graphs to condense27 and 10 ps to 1 ns for photon condensates28. The feedback mechanism can be implemented via optical delay lines (in NOPO system), by holographic reconfiguration of the injection via the spatial light modulator or mirror light masks (e.g. by DLP high-speed spatial light modulators) in solid-state condensates or by electrical injection (e.g. in the polariton lattices42).
The number of runs one needs to reliably find the global minimum grows with the size of the problem N. This growth is expected to be exponential for any algorithm (if P ≠ NP). However, we can compare how time per run grows with the problem size for considered algorithms. We perform the complexity analysis on mid- and large-scale problems and summarise the results in Fig. 4. The Gain-D algorithm demonstrates the consistent speedup over the BH algorithm for all problem sizes N in Fig. 4(a). The log plot in Fig. 4(b) indicates that both algorithms show polynomial time per run with the complexity of the Gain-D algorithm being close to O(N2.29). Note that such polynomial scaling does not preclude the exponential growth of the algorithm due to the “NP-hardness assumption”32.

The performance of the Gain-D, Gain-D-mod, and BH algorithms in minimizing the XY Hamiltonian with N up to 3000. (a) The time per instance T as a function of the problem size N. In the case of Gain-D and Gain-D-mod algorithms, T is the time averaged over 20 runs necessary to reach a stationary state. For the BH algorithm, this time consists of ten internal BH iterations necessary to have about the same success probabilities as the Gain-D algorithm. (b) T as a function of N in the logarithmic scale. The performance of the algorithms are fitted by the linear interpolation functions 2.29 log N − 13.42, 2.85 log N − 16.2, and 2.38 log N − 12.39, for the Gain-D, Gain-D-mod, and BH algorithms, respectively. The projected performance of the Gain-D simulator dominated by the dissipative (gain) coupling is shown with solid green (yellow) lines whose linear asymptotic in (b) is 0.2 log N − 2.6 (0.04 log N − 1.38).
Next we estimate the time scale on which the analog physical simulators can be expected to operate. For instance, the polariton (photon) lattices span the phases on a pico-second scale which can be neglected in comparison with the feedback and adjustment times. By taking an upper limit on this feedback time as 0.1 ms43 and counting the number of such adjustments in the Gain-D and Gain-D-mod algorithms, i.e. the average number of time iterations required to reach a fixed point per run, we can estimate the upper bound of the time needed by the physical implementation of the Gain-D simulator to find the global minimum. Since the physical simulators benefit from the built-in parallelism in choosing among various phase configurations as the system is pumped from below, we assume that the time it takes to bring the system to the threshold is independent of the number of nodes N. Under these assumptions, the estimated time-performance of the real physical simulators in minimising the Ising or XY Hamiltonians is shown in Fig. 4 by the solid green (yellow) lines for the Gain-D (Gain-D-mod) simulators. For large N from Fig. 4 we estimate the speed-up of the Gain-D simulators in comparison with the classical computations to be of the order of 10−5N2–10−7N3. Due to the adaptive setting of the coupling matrix in the Gain-D-mod algorithm, the number of time iterations grows slower with the size of problem N than for the Gain-D algorithm so that the performance of the Gain-D simulator can possibly be surpassed by the Gain-D-mod simulator for large N.
Conclusions
Motivated by a recent emergence of a new type of analog Hamiltonian optimisers – the gain-dissipative simulators – we formulate a novel gain-dissipative algorithm for solving large-scale optimisation problems which is easily parallelisable and can be efficiently simulated on classical computers. We show its computational advantages in comparison with built-in methods of Python’s Scipy optimisation library in minimising XY Hamiltonian and the state-of-the-art methods in solving MaxCut problem. We argue that the generalisation of the Gain-D algorithm for solving different classes of NP-hard problems can be done for both continuous and discrete problems and demonstrate it by solving quadratic continuous and binary optimisation problems. The Gain-D algorithm has a potential of becoming a new optimisation algorithm superior to other global optimisers. This algorithm allows us to formulate the requirement for the simulators hardware built using a system of gain-dissipative oscillators of different nature. Our algorithm, therefore, can be used to benchmark the existing gain-dissipative simulators. When the run-time of the classical algorithm is interpreted in terms of the time of the actual operation of the physical system one might expect such simulators to greatly outperform the classical computer.
Finally, we would like to comment on classical vs quantum operation of such simulators. When a condensate (a coherent state) is formed – the system behaves classically as many bosons are in the same single-particle mode and non-commutativity of the field operators can be neglected. However, the condensation process by which the global minimum of the spin models is found involves quantum effects. It was shown before, that the condensation process can be described by a fully classical evolution of the Nonlinear Schrödinger equation that takes into account only stimulated scattering effects and neglects spontaneous scattering44. The classical or quantum assignment to gain-dissipative simulators depends on whether quantum fluctuations and spontaneous scattering effects during the condensation provide a speed-up in comparison with entirely classical noise and stimulated scattering. This is an important question to address in the future research on such simulators and the comparison with the classical algorithm that we developed based on the gain-dissipative simulators architecture allows one to see if the time to find the solution scales better than with the best classical algorithms.
References
Baxter R. J. Exactly Solvable Models in Statistical Mechanics. (Academic Press Limited, 1982).
Gallavotti, G. Statistical Mechanics: A Short Treatise. (Springer Science & Business Media, 2013).
Ambjorn, J. A., Anagnostopoulos, K. N., Loll, R. & Pushinka, I. Shaken, but not stirred–Potts model coupled to quantum gravity. Nucl. Phys. B 807, 251 (2009).
Lucas, A. Ising formulations of many NP problems. Frontiers in Physics 2, 5 (2014).
Rojas, R. Neural Networks. A Systematic Introduction. (Springer-Verlag, 1996).
Bryngelson, J. D. & Wolynes, P. G. Spin glasses and the statistical mechanics of protein folding. Proc. Natl. Acad. Sci. USA 84, 7524 (1987).
Nishimori, H. Statistical Physics of Spin Glasses and Information Processing: An Introduction. (Oxford Univ. Press, 2001).
Harrison, R. W. Phase problem in crystallography. JOSA 10(5), 1046–1055 (1993).
Bunk, O. et al. Diffractive imaging for periodic samples: retrieving one-dimensional concentration profiles across microfluidic channels. Acta Crystallographica Section A: Foundations of Crystallography 63(4), 306–314 (2007).
Fienup, C. & Dainty, J. Phase retrieval and image reconstruction for astronomy. Image Recovery: Theory and Application 231, 275 (1987).
Walther, A. The question of phase retrieval in optics. Optica Acta: International Journal of Optics 10(1), 41–49 (1963).
Miao, J., Ishikawa, T., Shen, Q. & Earnest, T. Extending x-ray crystallography to allow the imaging of noncrystalline materials, cells, and single protein complexes. Annu. Rev. Phys. Chem. 59, 387–410 (2008).
Dierolf, M. et al. Ptychographic X-ray computed tomography at the nanoscale. Nature 467(7314), 436 (2010).
Nishimori, H. & Ortiz, G. Elements of Phase Transitions and Critical Phenomena. (Oxford Univ. Press, 2011).
Lokhov, A. Y. et al. Optimal structure and parameter learning of Ising models. Science Advances 4, e1700791 (2018).
Zhang, S. & Huang, Y. Complex quadratic optimization and semidefinite programming. SIAM J. Optim. 16, 871 (2006).
Applegate, D. L., Bixby, R. E., Chvatal, V. & Cook, W. J. The traveling salesman problem: a computational study. (Princeton university press, 2006).
Candes, E. J., Eldar, Y. C., Strohmer, T. & Voroninski, V. Phase retrieval via matrix completion. SIAM review 57(2), 225–251 (2015).
Shechtman, Y., Beck, A. & Eldar, Y. C. GESPAR: Efficient phase retrieval of sparse signals. IEEE transactions on signal processing 62(4), 928–938 (2014).
Dunning, I., Gupta, S. & Silberholz, J. What Works Best When? A Systematic Evaluation of Heuristics for Max-Cut and QUBO. To appear in INFORMS Journal on Computing (2018).
Kochenberger, G. et al. The unconstrained binary quadratic programming problem: a survey. J Comb. Optim. 28, 5881 (2014).
Papadimitriou, C. H. & Yannakakis, M. Optimization, approximation, and complexity classes. J. Comput. Syst. Sci. 43(3), 425440 (1991).
Utsunomiya, S., Takata, K. & Yamamoto, Y. Mapping of Ising models onto injection-locked laser systems. Opt. Express 19, 18091 (2011).
Marandi, A., Wang, Z., Takata, K., Byer, R. L. & Yamamoto, Y. Network of time-multiplexed optical parametric oscillators as a coherent Ising machine. Nat. Phot. 8, 937–942 (2014).
Takeda, Y. et al. Boltzmann sampling for an XY model using a non-degenerate optical parametric oscillator network. Quantum Science and Technology 3(1), 014004 (2017).
Nixon, M., Ronen, E., Friesem, A. A. & Davidson, N. Observing geometric frustration with thousands of coupled lasers. Phys. Rev. Lett. 110, 184102 (2013).
Berloff, N. G. et al. Realizing the classical XY Hamiltonian in polariton simulators. Nat. Mat. 16(11), 1120 (2017).
Dung, D. et al. Variable potentials for thermalized light and coupled condensates. Nat. Phot. 11(9), 565 (2017).
Kalinin, K. P. & Berloff, N. G. Networks of non-equilibrium condensates for global optimization. New J. Phys. 20, 113023 (2018).
Kalinin, K. P. & Berloff, N. G. Blockchain platform with proof-of-work based on analog Hamiltonian optimisers. arXiv:1802.10091 (2018).
Kalinin, K. P. & Berloff, N. G. Simulating Ising, Potts and external fields by gain-dissipative systems, in press by Phys. Rev. Letts. arXiv:1806.01371 (2018).
Aaronson, S. Guest column: NP-complete problems and physical reality. ACM Sigact News 36(1), 30–52 (2005).
Byrd, R. H., Lu, P., Nocedal, J. & Zhu, C. A limited memory algorithm for bound constrained optimization. SIAM Journal on Scientific Computing 16(5), 1190–1208 (1995).
Zhu, C., Byrd, R. H., Lu, P. & Nocedal, J. Algorithm 778: L-BFGS-B: Fortran subroutines for large-scale bound-constrained optimization. ACM Transactions on Mathematical Software (TOMS) 23(4), 550–560 (1997).
Wales, D. J. & Doye, J. P. Global optimization by basin-hopping and the lowest energy structures of Lennard-Jones clusters containing up to 110 atoms. The Journal of Physical Chemistry A 101(28), 5111–5116 (1997).
Kirkpatrick, S., Gelatt, C. D. & Vecchi, M. P. Optimization by simulated annealing. Science 220(4598), 671–680 (1983).
Tao, T. & Vu, V. Random matrices have simple spectrum. Combinatorica 37(3), 539–553 (2017).
Kalinin, K. P. & Berloff, N. G. Gain-dissipative simulators for large-scale hard classical optimisation. arXiv:1805.01371 (2018).
G-sets are freely available for download at, https://web.stanford.edu/yyye/yyye/Gset/?C=N;O=A.
Benlic, U. & Hao, J. K. Breakout local search for the max-cut problem. Eng. Appl. of Art. Int. 26(3), 1162–1173 (2013).
Wang, Y., Lü, Z., Glover, F. & Hao, J. K. Probabilistic GRASP-tabu search algorithms for the UBQP problem. Computers & Operations Research 40(12), 3100–3107 (2013).
Suchomel, H. et al. An electrically pumped polaritonic lattice simulator. arXiv:1803.08306 (2018).
Phillips, D. B. et al. Adaptive foveated single-pixel imaging with dynamic supersampling. Science Advances 3 (2017).
Berloff, N. G. & Svistunov, B. V. Scenario of strongly nonequilibrated Bose-Einstein condensation. Physical Review A 66(1), 013603 (2002).
Acknowledgements
N.G.B. acknowledges financial support from the NGP MIT-Skoltech. K.P.K. acknowledges the financial support from Cambridge Trust and EPSRC.
Author information
Authors and Affiliations
Contributions
N.B. devised and supervised the research, K.K. ran the computer simulations and prepared the figures. N.B. and K.K. wrote the manuscript.
Corresponding author
Ethics declarations
Competing Interests
The authors declare no competing interests.
Additional information
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kalinin, K.P., Berloff, N.G. Global optimization of spin Hamiltonians with gain-dissipative systems. Sci Rep 8, 17791 (2018). https://doi.org/10.1038/s41598-018-35416-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-018-35416-1
Keywords
This article is cited by
-
Computational complexity continuum within Ising formulation of NP problems
Communications Physics (2022)
-
Combinatorial optimization with photonics-inspired clock models
Communications Physics (2022)
-
Ising machines as hardware solvers of combinatorial optimization problems
Nature Reviews Physics (2022)
-
Polariton condensates for classical and quantum computing
Nature Reviews Physics (2022)
-
Simulated bifurcation assisted by thermal fluctuation
Communications Physics (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
